Zuverlässigkeit in Azure Traffic Manager
Dieser Artikel enthält spezifische Zuverlässigkeitsempfehlungen für Azure Traffic Manager sowie Unterstützung für regionsübergreifende Notfallwiederherstellung und Geschäftskontinuität für Azure Traffic Manager.
Eine ausführlichere Übersicht über die Zuverlässigkeitsprinzipien in Azure finden Sie unter Azure-Zuverlässigkeit.
Zuverlässigkeitsempfehlungen
Dieser Abschnitt enthält Empfehlungen für das Erreichen von Resilienz und Verfügbarkeit. Jede Empfehlung fällt in eine von zwei Kategorien:
Integritätselemente umfassen Bereiche wie Konfigurationselemente und die ordnungsgemäße Funktion der Hauptkomponenten, aus denen Ihr Azure-Workload besteht, wie z. B. Konfigurationseinstellungen der Azure-Ressourcen oder Abhängigkeiten von anderen Diensten.
Risikoelemente umfassen Bereiche wie Verfügbarkeits- und Wiederherstellungsanforderungen, Tests, Überwachung, Bereitstellung und andere Elemente, die die Wahrscheinlichkeit von Problemen in der Umgebung erhöhen, wenn sie nicht gelöst werden.
Prioritätsmatrix der Zuverlässigkeitsempfehlungen
Jede Empfehlung wird gemäß der folgenden Prioritätsmatrix gekennzeichnet:
| Image | Priority | BESCHREIBUNG |
|---|---|---|
| High | Sofortige Korrektur erforderlich. | |
| Mittel | Korrektur innerhalb von 3-6 Monaten. | |
| Niedrig | Muss überprüft werden. |
Zusammenfassung der Zuverlässigkeitsempfehlungen
Verfügbarkeit
 Der Traffic Manager-Überwachungsstatus sollte „Online“ lauten.
Der Traffic Manager-Überwachungsstatus sollte „Online“ lauten.
Der Überwachungsstatus sollte „Online“ sein, um ein Failover für die Anwendungsworkloads zu ermöglichen. Wenn für die Integrität von Traffic Manager der Status Heruntergestuft angezeigt wird, lautet auch der Status einer oder mehrerer Endpunkte u. U. Heruntergestuft:
Weitere Informationen zur Traffic Manager-Endpunktüberwachung finden Sie unter Traffic Manager-Endpunktüberwachung.
Informationen zur Problembehandlung des Status „Heruntergestuft“ in Azure Traffic Manager finden Sie unter Problembehandlung beim Status "Heruntergestuft" in Traffic Manager.
Traffic Manager-Profile sollten mehrere Endpunkte haben.
Beim Konfigurieren von Azure Traffic Manager sollten Sie mindestens zwei Endpunkte bereitstellen, um ein Failover für die Workload in einer anderen Instanz auszuführen.
Weitere Informationen zu Traffic Manager-Endpunkttypen finden Sie unter Traffic Manager-Endpunkte.
Systemeffizienz
 Der TTL-Wert für Benutzerprofile sollte 60 Sekunden betragen.
Der TTL-Wert für Benutzerprofile sollte 60 Sekunden betragen.
Die Gültigkeitsdauer (TTL) beeinflusst, wie aktuell eine Antwort ist, die ein Client erhält, wenn er eine Anforderung an Azure Traffic Manager stellt. Wenn Sie den TTL-Wert verringern, wird der Client im Falle eines Failovers schneller an einen funktionierenden Endpunkt weitergeleitet. Konfigurieren Sie die Gültigkeitsdauer auf 60 Sekunden, um Datenverkehr so schnell wie möglich an einen Integritätsendpunkt weiterzuleiten
Weitere Informationen zum Konfigurieren der DNS-TTL finden Sie unter Konfigurieren der DNS-Gültigkeitsdauer.
Notfallwiederherstellung
Konfigurieren Sie mindestens einen Endpunkt in einer anderen Region.
Profile sollten mehr als einen Endpunkt umfassen, um bei einem Ausfall eines Endpunkts Verfügbarkeit zu gewährleisten. Außerdem wird empfohlen, Endpunkte in verschiedenen Regionen zu platzieren.
Weitere Informationen zu Traffic Manager-Endpunkttypen finden Sie unter Traffic Manager-Endpunkte.
Stellen Sie sicher, dass der Endpunkt für geografische Profile als „Alle (Welt)“ konfiguriert ist.
Für das geografische Routing wird Datenverkehr basierend auf definierten Regionen an Endpunkte geleitet. Wenn eine Region ausfällt, ist kein vordefiniertes Failover verfügbar. Durch das Konfigurieren eines Endpunkts mit der regionalen Gruppierung „Alle (Welt)“ für geografische Profile werden „schwarze Löcher“ im Datenverkehr vermieden, und es wird Dienstverfügbarkeit Kunden gewährleistet.
Informationen zum Hinzufügen und Konfigurieren eines Endpunkts finden Sie unter Hinzufügen, Deaktivieren, Aktivieren, Löschen oder Verschieben von Endpunkten.
Regionsübergreifende Notfallwiederherstellung und Geschäftskontinuität
Bei der Notfallwiederherstellung (DR) geht es um die Wiederherstellung nach Ereignissen mit schwerwiegenden Auswirkungen, z. B. Naturkatastrophen oder fehlerhaften Bereitstellungen, die zu Downtime und Datenverlust führen. Unabhängig von der Ursache ist das beste Mittel gegen einen Notfall ein gut definierter und getesteter Notfallplan und ein Anwendungsdesign, die Notfallwiederherstellung aktiv unterstützt. Bevor Sie mit der Erstellung Ihres Notfallwiederherstellungsplans beginnen, lesen Sie die Empfehlungen zum Entwerfen einer Notfallwiederherstellungsstrategie.
Bei DR verwendet Microsoft das Modell der gemeinsamen Verantwortung. In einem Modell der gemeinsamen Verantwortung stellt Microsoft sicher, dass die grundlegenden Infrastruktur- und Plattformdienste verfügbar sind. Gleichzeitig replizieren viele Azure-Dienste nicht automatisch Daten oder greifen automatisch auf eine ausgefallene Region zurück, um eine regionsübergreifende Replikation in eine andere aktivierte Region durchzuführen. Für diese Dienste sind Sie dafür verantwortlich, einen Notfallwiederherstellungsplan zu erstellen, der für Ihre Workload geeignet ist. Die meisten Dienste, die auf Azure Platform as a Service (PaaS)-Angeboten laufen, bieten Funktionen und Anleitungen zur Unterstützung von Notfallwiederherstellung und Sie können dienstspezifische Funktionen zur Unterstützung einer schnellen Wiederherstellung nutzen, um Ihren Notfallwiederherstellungsplan zu entwickeln.
Azure Traffic Manager ist ein DNS-basierter Lastenausgleich, mit dem Sie den Datenverkehr auf Ihre öffentlichen Anwendungen in den globalen Azure-Regionen verteilen können. Darüber hinaus bietet Traffic Manager Hochverfügbarkeit und kurze Reaktionszeiten für Ihre öffentlichen Endpunkte.
Traffic Manager verwendet DNS, um die Clientanforderungen auf der Grundlage einer Datenverkehrsrouting-Methode an den passenden Dienstendpunkt weiterzuleiten. Des Weiteren bietet Traffic Manager auch eine Integritätsüberwachung für jeden Endpunkt. Der Endpunkt kann ein beliebiger Dienst mit Internetzugriff sein, der innerhalb oder außerhalb von Azure gehostet wird. Traffic Manager bietet eine Reihe von Datenverkehrsrouting-Methoden und Endpunktüberwachungsoptionen, die verschiedene Anwendungsanforderungen erfüllen sowie automatisches Failover ermöglichen. Traffic Manager zeichnet sich durch eine geringe Fehleranfälligkeit aus, selbst wenn es zu einem Ausfall einer ganzen Azure-Region kommt.
Notfallwiederherstellung für mehrere Regionen
DNS ist einer der effizientesten Mechanismen zum Umleiten von Netzwerkdatenverkehr. DNS ist effizient, da DNS häufig global ist und sich außerhalb des Rechenzentrums befindet. DNS ist außerdem von Ausfällen auf regionaler Ebene oder Verfügbarkeitszonenebene isoliert.
Es gibt zwei technische Aspekte, die bei der Einrichtung Ihrer Notfallwiederherstellungs-Architektur berücksichtigt werden müssen:
Verwenden eines Bereitstellungsmechanismus zum Replizieren von Instanzen, Daten und Konfigurationen zwischen primären und Standbyumgebungen. Diese Art der Notfallwiederherstellung kann nativ über Azure Site Recovery erfolgen, siehe hierzu Azure Site Recovery-Dokumentation über Anwendungen/Dienste von Microsoft Azure-Partnern wie Veritas oder NetApp.
Entwickeln einer Lösung zum Umleiten von Netzwerkdaten-/Webdatenverkehr vom primären Standort zum Standbystandort. Diese Art von Notfallwiederherstellung kann über Azure DNS, Azure Traffic Manager (DNS) oder globale Lastenausgleichsmodule von Drittanbietern erreicht werden.
Dieser Artikel konzentriert sich speziell auf die Planung der Azure Traffic Manager-Notfallwiederherstellung.
Erkennung, Benachrichtigung und Verwaltung von Ausfällen
Während eines Notfalls wird der primäre Endpunkt getestet, der Status ändert sich in Beeinträchtigt und der Notfallwiederherstellungsstandort bleibt Online. Standardmäßig sendet Traffic Manager den gesamten Datenverkehr an den primären Endpunkt (mit der höchsten Priorität). Wenn der primäre Endpunkt als beeinträchtigt angezeigt wird, leitet Traffic Manager den Datenverkehr an den zweiten Endpunkt, solange dieser fehlerfrei ist. Sie können weitere Endpunkte innerhalb von Traffic Manager konfigurieren, die als zusätzliche Failoverendpunkte oder als Lastenausgleichsmodule zur Lastverteilung zwischen den Endpunkten dienen können.
Einrichten der Notfallwiederherstellung und Ausfallerkennung
Wenn Sie über komplexe Architekturen und mehrere Ressourcensätzen verfügen, die dieselbe Funktion ausführen können, können Sie den Azure Traffic Manager (basierend auf DNS) konfigurieren, um die Integrität Ihrer Ressourcen zu überprüfen und den Datenverkehr von der fehlerhaften zur fehlerfreien Ressource zu leiten.
Im folgenden Beispiel verfügen sowohl die primäre als auch die sekundäre Region über eine vollständige Bereitstellung. Diese Bereitstellung umfasst die Clouddienste und eine synchronisierte Datenbank.
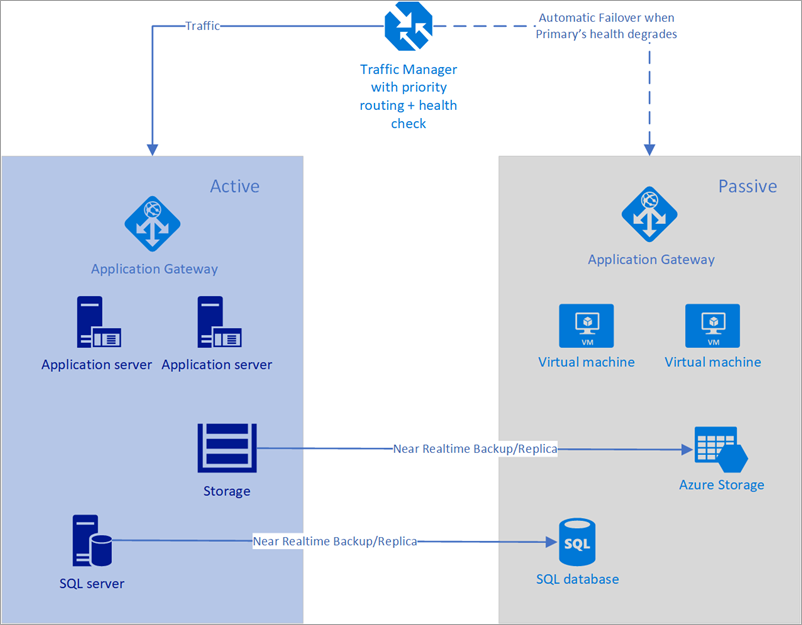
Abbildung – Automatisches Failover mit Azure Traffic Manager
Allerdings werden nur in der primären Region aktiv Netzwerkanforderungen der Benutzer verarbeitet. Die sekundäre Region wird nur aktiv, wenn in der primären Region eine Dienstunterbrechung auftritt. In diesem Fall werden alle neuen Netzwerkanforderungen an die sekundäre Region weitergeleitet. Da die Sicherung der Datenbank nahezu sofort erfolgt, beide Lastenausgleichsmodule über IPs verfügen, deren Integrität überprüft werden kann, und auch die Instanzen immer einsatzbereit sind, bietet diese Topologie die Möglichkeit, eine niedrige RTO zu verwenden und ein Failover ohne manuelle Eingriffe durchzuführen. Die sekundäre Failoverregion muss unmittelbar nach einem Ausfall der primären Region einsatzbereit sein.
Dieses Szenario ist ideal für den Einsatz von Azure Traffic Manager, der über eingebaute Tests für verschiedene Arten von Integritätsprüfungen wie http/https und TCP verfügt. Azure Traffic Manager verfügt außerdem über eine Regel-Engine, die so konfiguriert werden kann, dass das Failover bei einem Ausfall wie unten beschrieben erfolgt. Betrachten wir die folgende Lösung mit Traffic Manager:
- Der Kunde hat den Endpunkt Region #1 mit der prod.contoso.com und einer statischen IP 100.168.124.44 und einen Endpunkt Region #2 mit der Bezeichnung dr.contoso.com und einer statischen IP 100.168.124.43.
- Jede dieser Umgebungen wird über eine öffentliche Eigenschaft wie z.B. ein Lastenausgleichsmodul nach außen verfügbar gemacht. Das Lastenausgleichsmodul kann mit einem DNS-basierten Endpunkt oder einem vollqualifizierten Domänenname (FQDN) konfiguriert werden, wie unten dargestellt.
- Alle Instanzen in Region 2 sind nahezu in Echtzeit mit Region 1 repliziert. Darüber hinaus sind die Computerimages auf dem neuesten Stand, und alle Software-/Konfigurationsdaten sind gepatcht und entsprechen Region 1.
- Die automatische Skalierung wurde im Voraus vorkonfiguriert.
So konfigurieren Sie das Failover mit Azure Traffic Manager
Erstellen Sie ein neues Azure Traffic Manager-Profil mit dem Namen „contoso123“, und wählen Sie die Routingmethode „Priorität“. Wenn Sie eine bereits existierende Ressourcengruppe haben, die Sie zuordnen möchten, können Sie eine vorhandene Ressourcengruppe auswählen, andernfalls können Sie eine neue Ressourcengruppe anlegen.
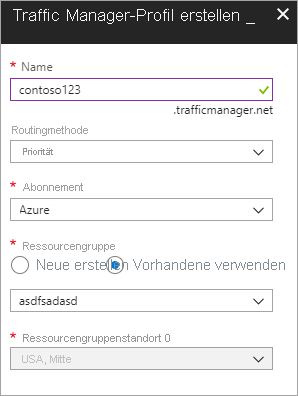
Abbildung – Erstellen eines Traffic Manager-Profils
Erstellen von Endpunkten innerhalb des Traffic Manager-Profils
In diesem Schritt erstellen Sie Endpunkte, die auf die Produktions- und Notfallwiederherstellungsstandorten verweisen. Wählen Sie hier den Typ als externen Endpunkt. Wenn die Ressource allerdings in Azure gehostet wird, können Sie auch Azure-Endpunkt auswählen. Wenn Sie Azure-Endpunkt auswählen, wählen Sie anschließend eine Zielressource, bei der es sich entweder um einen App Service oder eine Öffentliche IP handelt, die von Azure zugewiesen wird. Die Priorität wird auf 1 festgelegt, da es sich um den primären Dienst für die Region 1 handelt. Auf ähnliche Weise erstellen Sie auch den Notfallwiederherstellungs-Endpunkt in Traffic Manager.
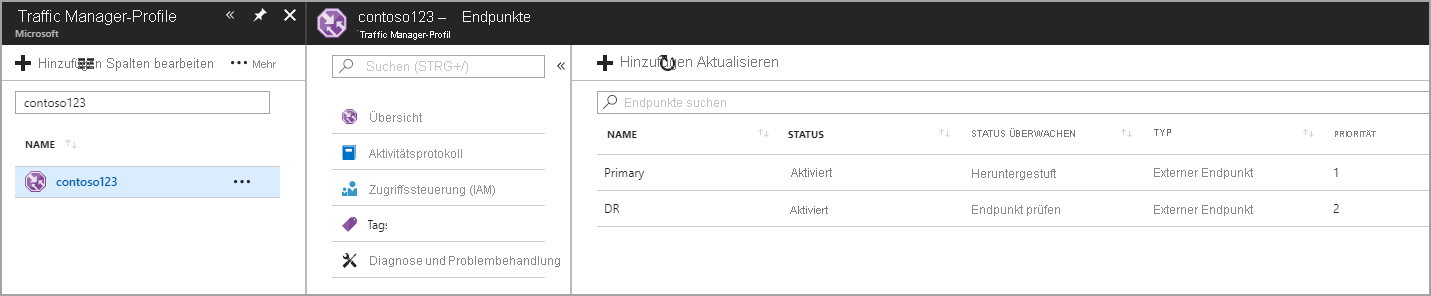
Abbildung – Erstellen von Notfallwiederherstellungs-Endpunkten
Einrichten der Integritätsprüfungen und der Failoverkonfiguration
In diesem Schritt legen Sie die DNS-TTL auf 10 Sekunden, die von den meisten rekursiven Resolvern mit Internetzugriff berücksichtigt wird. Diese Konfigurationen bedeutet, dass ein DNS-Resolver die Informationen für maximal 10 Sekunden zwischenspeichert.
Für die Einstellungen des Endpunktmonitors ist der Pfad aktuell auf / oder Stamm eingestellt, aber Sie können die Endpunkteinstellungen anpassen, um einen Pfad auszuwerten, z. B. prod.contoso.com/index.
Das nachfolgende Beispiel isthttps das Testprotokoll. Sie können jedoch auch http oder tcp auswählen. Die Wahl des Protokolls hängt von der Endanwendung ab. Das Testintervall ist auf 10 Sekunden festgelegt, sodass schnelle Tests möglich sind, und die Anzahl der Wiederholungen ist auf 3 gesetzt. Folglich führt Traffic Manager ein Failover auf den zweiten Endpunkt durch, wenn in drei aufeinander folgenden Intervallen ein Fehler registriert wird.
Die folgende Formel definiert die Gesamtzeit für ein automatisches Failover:
Time for failover = TTL + Retry * Probing intervalUnd in diesem Fall ist der Wert 10 + 3 × 10 = 40 Sekunden (max).
Wenn die Anzahl der Wiederholungen auf 1 sowie die TTL auf 10 Sekunden festgelegt ist, beträgt die Zeit für das Failover 10 + 1 * 10 = 20 Sekunden.
Leben Sie die Anzahl der Wiederholungen auf einen Wert von mehr als 1 fest, um die Wahrscheinlichkeit von Failovers aufgrund von falsch positiven Werten oder kleineren Netzwerk-Blips zu vermeiden.
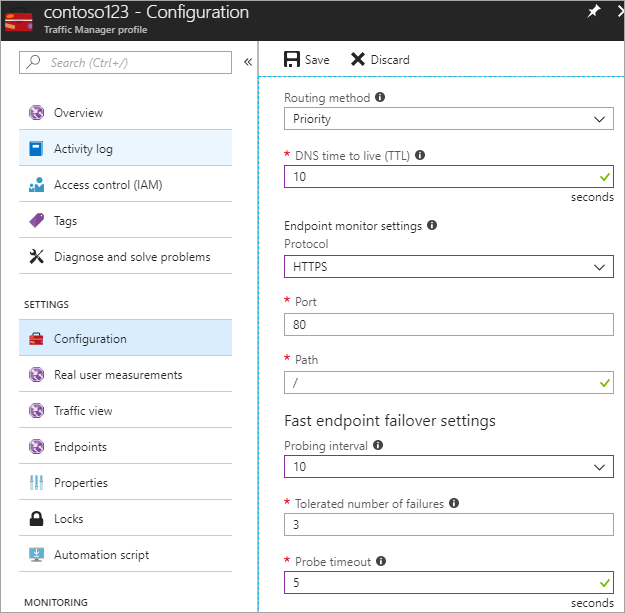
Abbildung – Einrichten der Integritätsprüfungen und der Failoverkonfiguration
Nächste Schritte
Weitere Informationen zu Azure Traffic Manager.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für