Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel wird gezeigt, wie Sie NVIDIA GPU-Workloads mit Azure Red Hat OpenShift (ARO) verwenden.
Voraussetzungen
- OpenShift CLI
- jq-, moreutils- und gettext-Paket
- Azure Red Hat OpenShift 4.10
Wenn Sie einen ARO-Cluster installieren müssen, erhalten Sie weitere Informationen unter Tutorial: Erstellen eines Azure Red Hat OpenShift 4-Clusters. ARO-Cluster müssen Version 4.10.x oder höher aufweisen.
Hinweis
Ab ARO 4.10 ist es nicht mehr erforderlich, Berechtigungen zum Verwenden des NVIDIA-Operators einzurichten. Dies vereinfacht die Einrichtung des Clusters für GPU-Workloads erheblich.
Linux:
sudo dnf install jq moreutils gettext
macOS
brew install jq moreutils gettext
Anfordern eines GPU-Kontingents
Alle GPU-Kontingente in Azure sind standardmäßig 0. Sie müssen sich am Azure-Portal anmelden und ein GPU-Kontingent anfordern. Aufgrund des Wettbewerbs um GPU-Worker müssen Sie möglicherweise einen ARO-Cluster in einer Region bereitstellen, in der Sie GPUs tatsächlich reservieren können.
ARO unterstützt die folgenden GPU-Worker:
- NC4as T4 v3
- NC6s v3
- NC8as T4 v3
- NC12s v3
- NC16as T4 v3
- NC24s v3
- NC24rs v3
- NC64as T4 v3
Die folgenden Instanzen werden auch in zusätzlichen MachineSets unterstützt:
- Standard_ND96asr_v4
- NC24ads_A100_v4
- NC48ads_A100_v4
- NC96ads_A100_v4
- ND96amsr_A100_v4
Hinweis
Denken Sie beim Anfordern des Kontingents daran, dass Azure pro Kern eingerichtet wird. Um einen einzelnen NC4as T4 v3-Knoten anzufordern, müssen Sie Kontingent in Gruppen von 4 anfordern. Wenn Sie einen NC16as T4 v3-Knoten anfordern möchten, müssen Sie ein Kontingent von 16 anfordern.
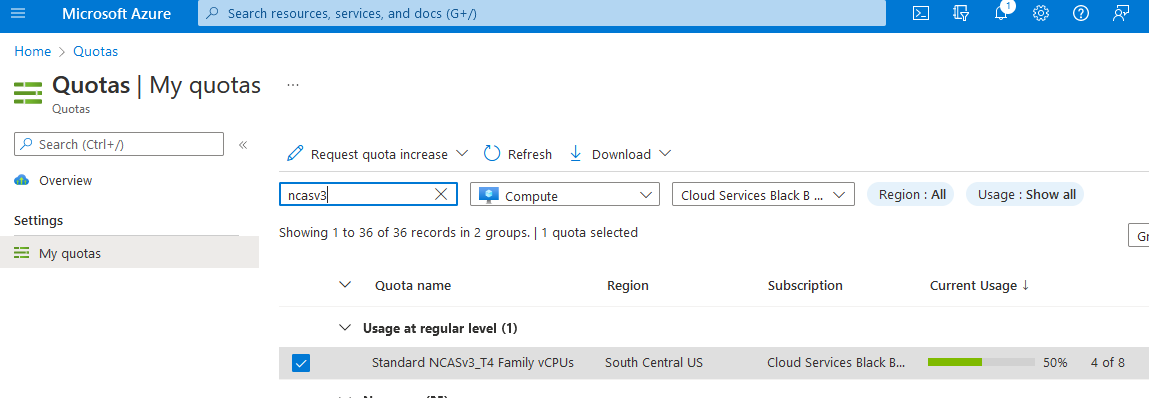
Melden Sie sich beim Azure-Portal an.
Geben Sie Kontingente in das Suchfeld ein, und wählen Sie dann Compute aus.
Geben Sie im Suchfeld NCAsv3_T4 ein, aktivieren Sie das Kontrollkästchen für die Region, in der sich Ihr Cluster befindet, und wählen Sie dann Kontingenterhöhung anfordern aus.
Konfigurieren Sie das Kontingent.
Anmelden bei Ihrem ARO-Cluster
Melden Sie sich bei OpenShift mit einem Benutzerkonto mit Clusteradministratorberechtigungen an. Im folgenden Beispiel wird ein Konto namens kubadmin verwendet:
oc login <apiserver> -u kubeadmin -p <kubeadminpass>
Pullgeheimnis (bedingt)
Aktualisieren Sie Ihr Pullgeheimnis, um sicherzustellen, dass Sie Operatoren installieren und eine Verbindung mit cloud.redhat.com herstellen können.
Hinweis
Überspringen Sie diesen Schritt, wenn Sie bereits ein vollständiges Pullgeheimnis mit aktivierter Option cloud.redhat.com neu erstellt haben.
Melden Sie sich bei cloud.redhat.com an.
Navigieren Sie zu https://cloud.redhat.com/openshift/install/azure/aro-provisioned.
Wählen Sie Pullgeheimnis herunterladen aus, und speichern Sie das Pullgeheimnis als
pull-secret.txt.Von Bedeutung
Die verbleibenden Schritte in diesem Abschnitt müssen im gleichen Arbeitsverzeichnis wie
pull-secret.txtausgeführt werden.Exportieren Sie das vorhandene Pullgeheimnis.
oc get secret pull-secret -n openshift-config -o json | jq -r '.data.".dockerconfigjson"' | base64 --decode > export-pull.jsonMergen Sie das heruntergeladene Pullschgeheimnis mit dem Systempullgeheimnis, um
cloud.redhat.comhinzuzufügen.jq -s '.[0] * .[1]' export-pull.json pull-secret.txt | tr -d "\n\r" > new-pull-secret.jsonLaden Sie die neue Geheimnisdatei hoch.
oc set data secret/pull-secret -n openshift-config --from-file=.dockerconfigjson=new-pull-secret.jsonMöglicherweise müssen Sie ungefähr eine Stunde warten, bis alles mit cloud.redhat.com synchronisiert wurde.
Dient zum Löschen von Geheimnissen.
rm pull-secret.txt export-pull.json new-pull-secret.json
GPU-Computersatz
ARO verwendet Kubernetes MachineSet zum Erstellen von Computersätzen. Im folgenden Verfahren wird erläutert, wie Sie den ersten Computersatz in einem Cluster exportieren und diesen als Vorlage verwenden, um einen einzelnen GPU-Computer zu erstellen.
Zeigen Sie vorhandene Computersätze an.
Um die Einrichtung zu vereinfachen, wird in diesem Beispiel der erste Computersatz als der zu klonende verwendet, um einen neuen GPU-Computersatz zu erstellen.
MACHINESET=$(oc get machineset -n openshift-machine-api -o=jsonpath='{.items[0]}' | jq -r '[.metadata.name] | @tsv')Speichern Sie eine Kopie des Beispielcomputersatzes.
oc get machineset -n openshift-machine-api $MACHINESET -o json > gpu_machineset.jsonÄndern Sie das
.metadata.name-Feld in einen neuen eindeutigen Namen.jq '.metadata.name = "nvidia-worker-<region><az>"' gpu_machineset.json| sponge gpu_machineset.jsonStellen Sie sicher, dass
spec.replicasmit der gewünschten Replikatanzahl für den Computersatz übereinstimmt.jq '.spec.replicas = 1' gpu_machineset.json| sponge gpu_machineset.jsonÄndern Sie das
.spec.selector.matchLabels.machine.openshift.io/cluster-api-machineset-Feld so, dass es dem.metadata.name-Feld entspricht.jq '.spec.selector.matchLabels."machine.openshift.io/cluster-api-machineset" = "nvidia-worker-<region><az>"' gpu_machineset.json| sponge gpu_machineset.jsonÄndern Sie das
.spec.template.metadata.labels.machine.openshift.io/cluster-api-machinesetso, dass die Angabe dem.metadata.name-Feld entspricht.jq '.spec.template.metadata.labels."machine.openshift.io/cluster-api-machineset" = "nvidia-worker-<region><az>"' gpu_machineset.json| sponge gpu_machineset.jsonÄndern Sie
spec.template.spec.providerSpec.value.vmSizeso, dass der Wert dem gewünschten GPU-Instanztyp aus Azure entspricht.Der in diesem Beispiel verwendete Computer ist Standard_NC4as_T4_v3.
jq '.spec.template.spec.providerSpec.value.vmSize = "Standard_NC4as_T4_v3"' gpu_machineset.json | sponge gpu_machineset.jsonÄndern Sie
spec.template.spec.providerSpec.value.zoneso, dass der Wert der gewünschten Zone aus Azure entspricht.jq '.spec.template.spec.providerSpec.value.zone = "1"' gpu_machineset.json | sponge gpu_machineset.jsonLöschen Sie den Abschnitt
.statusder YAML-Datei.jq 'del(.status)' gpu_machineset.json | sponge gpu_machineset.jsonÜberprüfen Sie die anderen Daten in der YAML-Datei.
Sicherstellen, dass die richtige SKU festgelegt ist
Je nach dem für den Computersatz verwendeten Image müssen beide Werte für image.sku und image.version entsprechend festgelegt werden. Dadurch wird sichergestellt, ob virtuelle Computer der Generation 1 oder 2 für Hyper-V verwendet werden. Weitere Informationen finden Sie hier.
Beispiel:
Bei Verwendung von Standard_NC4as_T4_v3 werden beide Versionen unterstützt. Wie in der Featureunterstützung erwähnt. In diesem Fall sind keine Änderungen erforderlich.
Bei Verwendung von Standard_NC24ads_A100_v4 werden nur VM der Generation 2unterstützt.
In diesem Fall muss der image.sku-Wert der entsprechenden v2-Version des Images entsprechen, das dem ursprünglichen image.sku des Clusters entspricht. In diesem Beispiel lautet der Wert v410-v2.
Dies finden Sie mit dem folgenden Befehl:
az vm image list --architecture x64 -o table --all --offer aro4 --publisher azureopenshift
Filtered output:
SKU VERSION
------- ---------------
v410-v2 410.84.20220125
aro_410 410.84.20220125
Wenn der Cluster mit dem Basis-SKU-Image aro_410 erstellt wurde und derselbe Wert im Computersatz beibehalten wird, schlägt er mit dem folgenden Fehler fehl:
failure sending request for machine myworkernode: cannot create vm: compute.VirtualMachinesClient#CreateOrUpdate: Failure sending request: StatusCode=400 -- Original Error: Code="BadRequest" Message="The selected VM size 'Standard_NC24ads_A100_v4' cannot boot Hypervisor Generation '1'.
Erstellen eines GPU-Computersatzes
Verwenden Sie die folgenden Schritte, um den neuen GPU-Computer zu erstellen. Es kann 10 bis 15 Minuten dauern, bis ein neuer GPU-Computer bereitgestellt wird. Wenn dieser Schritt fehlschlägt, melden Sie sich am Azure-Portal an, und stellen Sie sicher, dass keine Verfügbarkeitsprobleme vorliegen. Navigieren Sie dazu zu Virtual Machines, und suchen Sie nach dem zuvor erstellten Workernamen, um den Status der VMs anzuzeigen.
Erstellen Sie den GPU-Computersatz.
oc create -f gpu_machineset.jsonDie Ausführung dieses Befehls dauert einige Minuten.
Überprüfen Sie den GPU-Computersatz.
Computer sollten bereitgestellt werden. Sie können den Status des Computersatzes mit den folgenden Befehlen anzeigen:
oc get machineset -n openshift-machine-api oc get machine -n openshift-machine-apiSobald die Computer bereitgestellt werden (dies kann 5 bis 15 Minuten dauern), werden sie als Knoten in der Knotenliste angezeigt:
oc get nodesSie sollten einen Knoten mit dem Namen
nvidia-worker-southcentralus1sehen, der zuvor erstellt wurde.
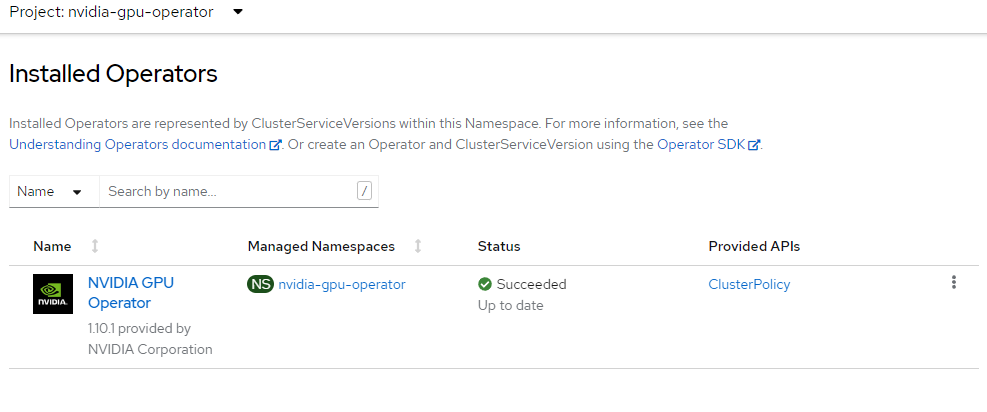
Installieren des NVIDIA-GPU-Operators
In diesem Abschnitt wird erläutert, wie Sie den nvidia-gpu-operator-Namespace erstellen, die Operatorgruppe einrichten und den NVIDIA-GPU-Operator installieren.
Erstellen Sie den NVIDIA-Namespace.
cat <<EOF | oc apply -f - apiVersion: v1 kind: Namespace metadata: name: nvidia-gpu-operator EOFErstellen Sie die Operatorgruppe.
cat <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: nvidia-gpu-operator-group namespace: nvidia-gpu-operator spec: targetNamespaces: - nvidia-gpu-operator EOFRufen Sie den neuesten NVIDIA-Kanal mithilfe des folgenden Befehls ab:
CHANNEL=$(oc get packagemanifest gpu-operator-certified -n openshift-marketplace -o jsonpath='{.status.defaultChannel}')
Hinweis
Wenn Ihr Cluster erstellt wurde, ohne das Pullgeheimnis bereitzustellen, enthält der Cluster keine Beispiele oder Operatoren von Red Hat oder von zertifizierten Partnern. Daraufhin wird folgende Fehlermeldung angezeigt:
Fehler vom Server (NotFound): packagemanifests.packages.operators.coreos.com „gpu-operator-certified“ nicht gefunden.
Wenn Sie Ihren Red Hat-Pullgeheimnis zu einem Azure Red Hat OpenShift-Cluster hinzufügen möchten, befolgen Sie diese Anleitung.
Rufen Sie das neueste NVIDIA-Paket mithilfe des folgenden Befehls ab:
PACKAGE=$(oc get packagemanifests/gpu-operator-certified -n openshift-marketplace -ojson | jq -r '.status.channels[] | select(.name == "'$CHANNEL'") | .currentCSV')Erstellen Sie das Abonnement.
envsubst <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: gpu-operator-certified namespace: nvidia-gpu-operator spec: channel: "$CHANNEL" installPlanApproval: Automatic name: gpu-operator-certified source: certified-operators sourceNamespace: openshift-marketplace startingCSV: "$PACKAGE" EOFWarten Sie, bis die Installation des Operators abgeschlossen wurde.
Fahren Sie erst fort, nachdem Sie bestätigt haben, dass der Operator die Installation abgeschlossen hat. Stellen Sie außerdem sicher, dass Ihr GPU-Worker online ist.
Installieren des Knotenfeature-Ermittlungsoperators
Der Knotenfeature-Ermittlungsoperator erkennt die GPU auf Ihren Knoten und bezeichnet die Knoten entsprechend, damit Sie sie für Workloads gezielt ansprechen können.
In diesem Beispiel wird der NFD-Operator im openshift-ndf-Namespace installiert und das „Abonnement“ erstellt, das die Konfiguration für NFD ist.
Offizielle Dokumentation zum Installieren des Knotenfeature-Ermittlungsoperators.
Richten Sie
Namespaceein.cat <<EOF | oc apply -f - apiVersion: v1 kind: Namespace metadata: name: openshift-nfd EOFErstellen Sie
OperatorGroup.cat <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: generateName: openshift-nfd- name: openshift-nfd namespace: openshift-nfd EOFErstellen Sie
Subscription.cat <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: nfd namespace: openshift-nfd spec: channel: "stable" installPlanApproval: Automatic name: nfd source: redhat-operators sourceNamespace: openshift-marketplace EOFWarten Sie, bis die Installation der Knotenfeatureermittlung abgeschlossen wurde.
Sie können sich bei Ihrer OpenShift-Konsole anmelden, um Operatoren anzuzeigen, oder einfach einige Minuten warten. Wenn Sie nicht warten,bis die Installation des Operators abgeschlossen ist, führt dies im nächsten Schritt zu einem Fehler.
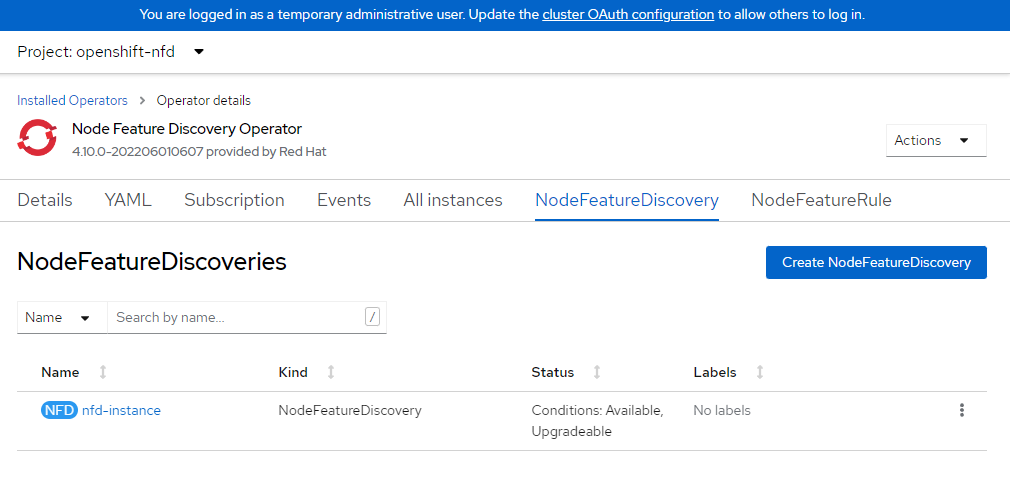
Erstellen Sie die NFD-Instanz.
cat <<EOF | oc apply -f - kind: NodeFeatureDiscovery apiVersion: nfd.openshift.io/v1 metadata: name: nfd-instance namespace: openshift-nfd spec: customConfig: configData: | # - name: "more.kernel.features" # matchOn: # - loadedKMod: ["example_kmod3"] # - name: "more.features.by.nodename" # value: customValue # matchOn: # - nodename: ["special-.*-node-.*"] operand: image: >- registry.redhat.io/openshift4/ose-node-feature-discovery@sha256:07658ef3df4b264b02396e67af813a52ba416b47ab6e1d2d08025a350ccd2b7b servicePort: 12000 workerConfig: configData: | core: # labelWhiteList: # noPublish: false sleepInterval: 60s # sources: [all] # klog: # addDirHeader: false # alsologtostderr: false # logBacktraceAt: # logtostderr: true # skipHeaders: false # stderrthreshold: 2 # v: 0 # vmodule: ## NOTE: the following options are not dynamically run-time ## configurable and require a nfd-worker restart to take effect ## after being changed # logDir: # logFile: # logFileMaxSize: 1800 # skipLogHeaders: false sources: # cpu: # cpuid: ## NOTE: attributeWhitelist has priority over attributeBlacklist # attributeBlacklist: # - "BMI1" # - "BMI2" # - "CLMUL" # - "CMOV" # - "CX16" # - "ERMS" # - "F16C" # - "HTT" # - "LZCNT" # - "MMX" # - "MMXEXT" # - "NX" # - "POPCNT" # - "RDRAND" # - "RDSEED" # - "RDTSCP" # - "SGX" # - "SSE" # - "SSE2" # - "SSE3" # - "SSE4.1" # - "SSE4.2" # - "SSSE3" # attributeWhitelist: # kernel: # kconfigFile: "/path/to/kconfig" # configOpts: # - "NO_HZ" # - "X86" # - "DMI" pci: deviceClassWhitelist: - "0200" - "03" - "12" deviceLabelFields: # - "class" - "vendor" # - "device" # - "subsystem_vendor" # - "subsystem_device" # usb: # deviceClassWhitelist: # - "0e" # - "ef" # - "fe" # - "ff" # deviceLabelFields: # - "class" # - "vendor" # - "device" # custom: # - name: "my.kernel.feature" # matchOn: # - loadedKMod: ["example_kmod1", "example_kmod2"] # - name: "my.pci.feature" # matchOn: # - pciId: # class: ["0200"] # vendor: ["15b3"] # device: ["1014", "1017"] # - pciId : # vendor: ["8086"] # device: ["1000", "1100"] # - name: "my.usb.feature" # matchOn: # - usbId: # class: ["ff"] # vendor: ["03e7"] # device: ["2485"] # - usbId: # class: ["fe"] # vendor: ["1a6e"] # device: ["089a"] # - name: "my.combined.feature" # matchOn: # - pciId: # vendor: ["15b3"] # device: ["1014", "1017"] # loadedKMod : ["vendor_kmod1", "vendor_kmod2"] EOFStellen Sie sicher, dass NFD bereit ist.
Der Status dieses Operators sollte als Verfügbar angezeigt werden.
Anwenden der NVIDIA-Clusterkonfiguration
In diesem Abschnitt wird erläutert, wie Sie die NVIDIA-Clusterkonfiguration anwenden. Lesen Sie die NVIDIA-Dokumentation zum Anpassen dieses Vorgangs, wenn Sie über eigene private Repositorys oder spezifische Einstellungen verfügen. Dieser Vorgang kann mehrere Minuten dauern.
Wenden Sie die Clusterkonfiguration an.
cat <<EOF | oc apply -f - apiVersion: nvidia.com/v1 kind: ClusterPolicy metadata: name: gpu-cluster-policy spec: migManager: enabled: true operator: defaultRuntime: crio initContainer: {} runtimeClass: nvidia deployGFD: true dcgm: enabled: true gfd: {} dcgmExporter: config: name: '' driver: licensingConfig: nlsEnabled: false configMapName: '' certConfig: name: '' kernelModuleConfig: name: '' repoConfig: configMapName: '' virtualTopology: config: '' enabled: true use_ocp_driver_toolkit: true devicePlugin: {} mig: strategy: single validator: plugin: env: - name: WITH_WORKLOAD value: 'true' nodeStatusExporter: enabled: true daemonsets: {} toolkit: enabled: true EOFÜberprüfen Sie die Clusterrichtlinie.
Melden Sie sich bei der OpenShift-Konsole an, und navigieren Sie zu den Operatoren. Stellen Sie sicher, dass Sie sich im
nvidia-gpu-operator-Namespace befinden. Er sollte so lauten:State: Ready once everything is complete.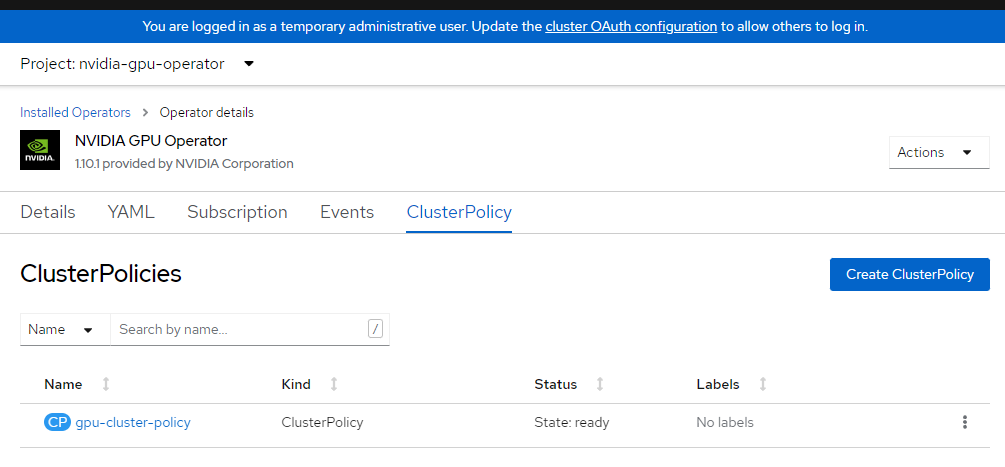
Überprüfen der GPU
Es kann einige Zeit dauern, bis der NVIDIA-Operator und NFD vollständig installiert wurden und die Computer selbständig identifizieren. Führen Sie die folgenden Befehle aus, um zu überprüfen, ob alles wie erwartet ausgeführt wird:
Stellen Sie sicher, dass NFD Ihre GPU(s) sehen kann.
oc describe node | egrep 'Roles|pci-10de' | grep -v masterDie Ausgabe sollte in etwa folgendermaßen aussehen:
Roles: worker feature.node.kubernetes.io/pci-10de.present=trueÜberprüfen Sie Knotenbezeichnungen.
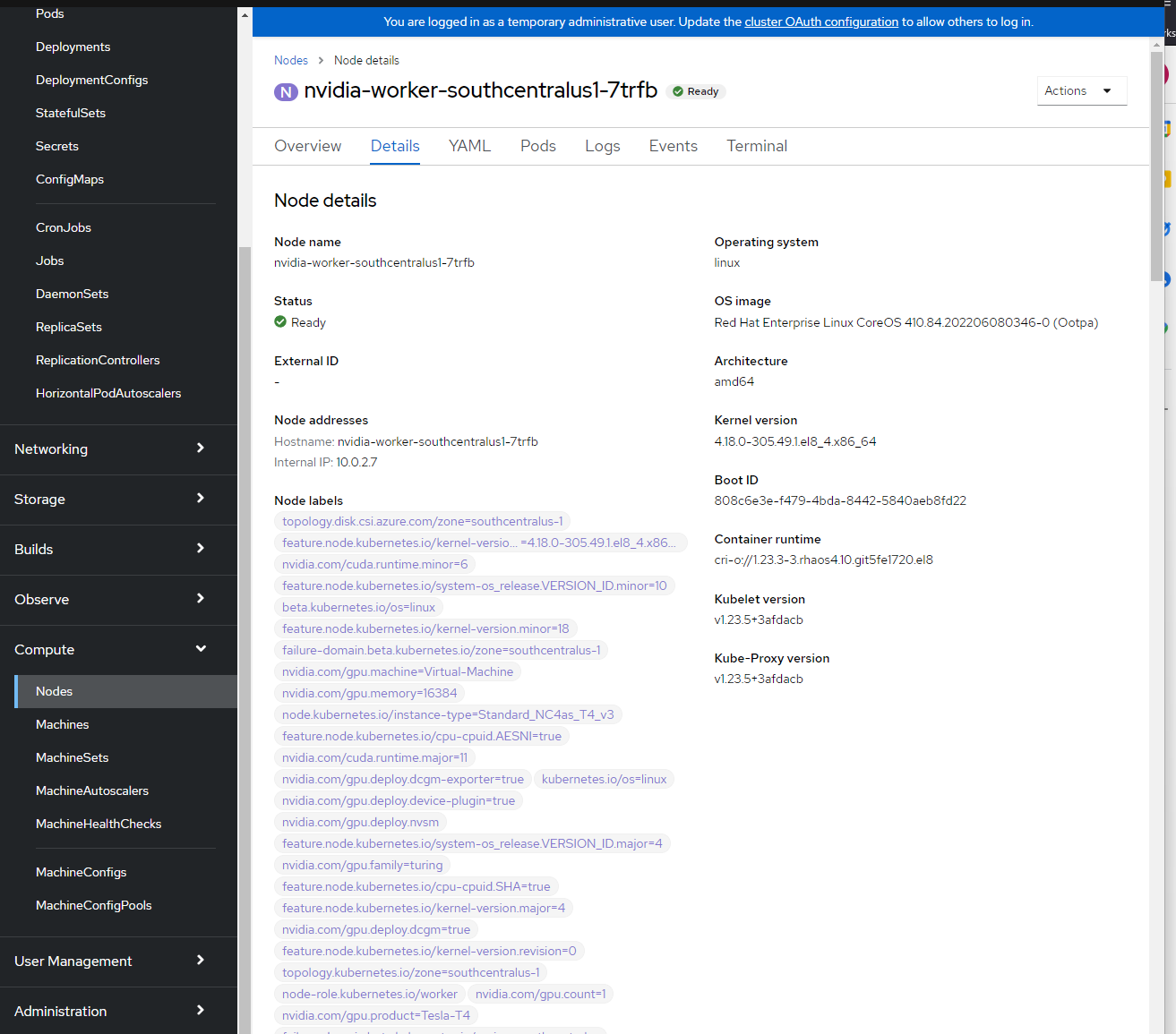
Sie können die Knotenbezeichnungen anzeigen, indem Sie sich bei der OpenShift-Konsole anmelden und > Compute > Knoten > nvidia-worker-southcentralus1- verwenden. Sie sollten mehrere NVIDIA-GPU-Bezeichnungen und das pci-10de-Gerät von oben sehen.
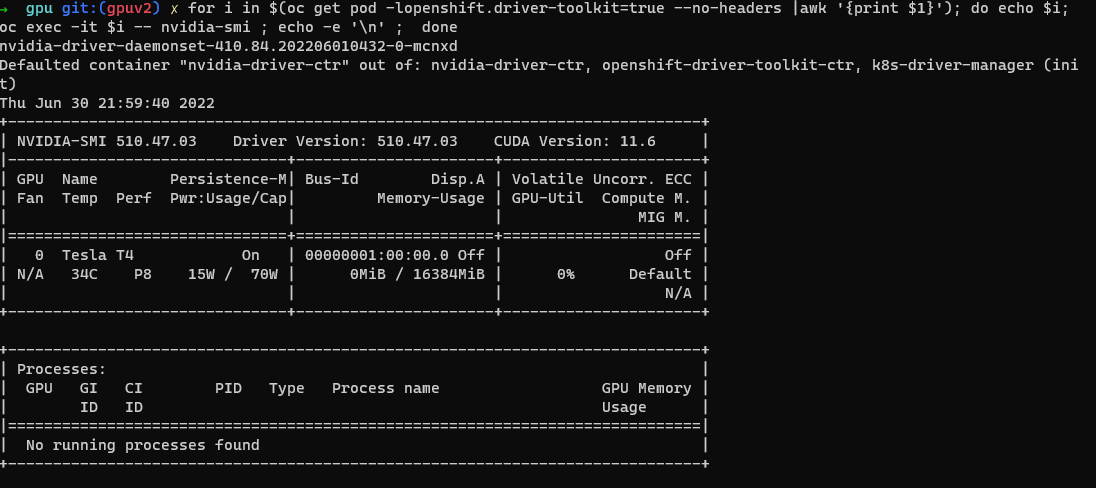
Überprüfen Sie das NVIDIA SMI-Tool.
oc project nvidia-gpu-operator for i in $(oc get pod -lopenshift.driver-toolkit=true --no-headers |awk '{print $1}'); do echo $i; oc exec -it $i -- nvidia-smi ; echo -e '\n' ; doneSie sollten eine Ausgabe sehen, die wie in diesem Beispielscreenshot die GPUs angibt, die auf dem Host verfügbar sind. (Variiert je nach GPU-Workertyp)
Erstellen eines Pods zum Ausführen einer GPU-Workload
oc project nvidia-gpu-operator cat <<EOF | oc apply -f - apiVersion: v1 kind: Pod metadata: name: cuda-vector-add spec: restartPolicy: OnFailure containers: - name: cuda-vector-add image: "quay.io/giantswarm/nvidia-gpu-demo:latest" resources: limits: nvidia.com/gpu: 1 nodeSelector: nvidia.com/gpu.present: true EOFZeigen Sie die Protokolle an.
oc logs cuda-vector-add --tail=-1
Hinweis
Wenn Sie einen Fehler Error from server (BadRequest): container "cuda-vector-add" in pod "cuda-vector-add" is waiting to start: ContainerCreatingerhalten, versuchen Sie, oc delete pod cuda-vector-add auszuführen, und führen Sie dann die oben beschriebene create-Anweisung erneut aus.
Die Ausgabe sollte ungefähr wie das folgende Beispiel (abhängig von der GPU) aussehen:
[Vector addition of 5000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Done
Bei Erfolg kann der Pod gelöscht werden:
oc delete pod cuda-vector-add