Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Um robuste und erfolgreiche Clientanwendungen zu erstellen, ist es wichtig, das Failover im Azure Managed Redisservice zu verstehen. Ein Failover kann Teil geplanter Verwaltungsvorgänge sein oder durch ungeplante Hardware- oder Netzwerkausfälle verursacht werden. Eine häufige Verwendung des Cache-Failovers tritt auf, wenn der Verwaltungsdienst die Azure Managed Redis-Binärdateien aktualisiert.
Im vorliegenden Artikel finden Sie Antworten auf die folgenden Fragen:
- Was ist ein Failover?
- Wie erfolgt das Failover während eines Patchvorgangs?
- Wie erstelle ich eine resiliente Clientanwendung?
Was ist ein Failover?
Lassen Sie uns mit einer Übersicht über das Failover für Azure Managed Redis beginnen.
Kurze Zusammenfassung der Cachearchitektur
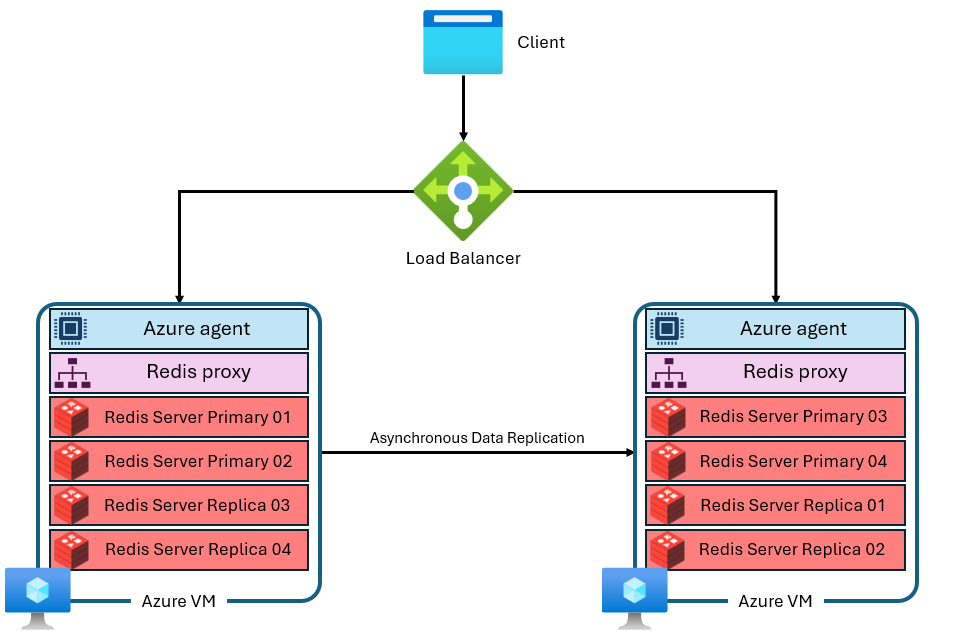
Ein Cache wird aus mehreren virtuellen Computern mit separaten und privaten IP-Adressen erstellt. Jede virtuelle Maschine (oder „Knoten“) führt mehrere Redis-Serverprozesse (sogenannte „Shards“) parallel aus. Mehrere Shards bieten die Möglichkeit, die vCPUs jeder virtuellen Maschine effizienter zu nutzen und die Leistung zu steigern. Nicht alle primären Redis Shards befinden sich auf derselben VM/demselben Knoten. Stattdessen sind primäre und Replik-Shards auf beide Knoten verteilt. Da primäre Shards mehr CPU-Ressourcen verbrauchen als Replik-Shards, ermöglicht dieser Ansatz, dass mehr primäre Shards parallel ausgeführt werden können. Jeder Knoten verfügt über einen leistungsfähigen Proxy-Prozess, der die Shards verwaltet, die Verwaltung der Verbindungen handhabt und Self-Healing triggert. Ein Shard kann ausgefallen sein, während die anderen verfügbar bleiben.
Ausführliche Informationen zur Azure Managed Redis Architecture finden Sie here.
Erläuterung eines Failovers
Ein Failover tritt auf, wenn ein oder mehrere Replikatshards sich selbst zu primären Shards heraufstufen und die alten primären Shards vorhandene Verbindungen schließen. Ein Failover kann geplant oder ungeplant sein.
Ein geplantes Failover kann zu zwei verschiedenen Zeitpunkten stattfinden:
- Bei Systemupdates, wie z. B. dem Aufspielen von Redis-Patches oder Betriebssystemupgrades.
- Bei Verwaltungsvorgängen, wie z. B. Skalierungen und Neustarts.
Da die Knoten eine Vorabbenachrichtigung zum Update erhalten, können die Rollen getauscht werden, und der Load Balancer kann schnell entsprechend der Änderung aktualisiert werden. Ein geplantes Failover wird normalerweise in weniger als einer Sekunde abgeschlossen.
Ein ungeplanter Failover kann aufgrund eines Hardwareausfalls, eines Netzwerkausfalls oder anderer unerwarteter Ausfälle eines oder mehrerer Knoten im Cluster auftreten. Die Replikatshards auf dem/den verbleibenden Knoten werden sich selbst zu primär höherstufen, um die Verfügbarkeit aufrechtzuerhalten, der Prozess dauert jedoch länger. Ein Replikatshard muss zunächst erkennen, dass der zugehörige primäre Shard nicht verfügbar ist, bevor der Failoverprozess gestartet werden kann. Der Replikatshard muss außerdem überprüfen, ob dieser ungeplante Ausfall nicht vorübergehend oder lokal ist, um ein unnötiges Failover zu vermeiden. Diese Verzögerung bei der Erkennung bedeutet, dass ein ungeplantes Failover normalerweise innerhalb von 10 bis 15 Sekunden abgeschlossen ist.
Wie erfolgt das Patchen?
Der Azure Managed Redis-Dienst aktualisiert Ihren Cache regelmäßig mit den neuesten Plattformfeatures und -fixes. Zum Patchen eines Caches führt der Dienst die folgenden Schritte aus:
- Der Dienst erstellt neue aktuelle VMs, um alle VMs zu ersetzen, die gepatcht werden.
- Dann ernennt er eine der neuen VMs zum Cluster-Leader.
- Nach und nach werden alle Knoten, die gepatcht werden, aus dem Cluster entfernt. Alle Shards auf diesen VMs werden degradiert und auf eine der neuen VMs migriert.
- Schließlich werden alle VMs, die ersetzt wurden, gelöscht.
Jeder Shard eines gruppierten Caches wird separat gepatcht und schließt keine Verbindungen mit einem anderen Shard.
Hinweis
Mehrere Caches in derselben Region können gleichzeitig gepatcht werden. Wenn sich dies auf Ihre Anwendung auswirkt, konfigurieren Sie Wartungszeitpläne so, dass jeder Cache zu einem anderen Zeitpunkt gepatcht wird.
Da vor der Wiederholung des Prozesses eine vollständige Datensynchronisierung stattfindet, ist ein Datenverlust für Ihren Cache unwahrscheinlich. Sie können Datenverlusten weiter vorbeugen, indem Sie die Daten exportieren und die Datenpersistenz aktivieren.
Zusätzliche Cacheauslastung
Bei jedem Failover müssen die Caches Daten von einem Knoten auf den anderen replizieren. Diese Replikation führt zu einer gewissen Erhöhung der Auslastung von Serverspeicher und Server-CPU. Wenn die Cache-Instanz bereits stark ausgelastet ist, können Clientanwendungen eine höhere Latenz aufweisen. Im Extremfall treten in Clientanwendungen möglicherweise Timeoutausnahmen auf.
Wie wirkt sich ein Failover auf meine Clientanwendung aus?
Clientanwendungen können einige Fehler aus ihrer Azure verwalteten Redis-Instanz erhalten. Die Anzahl der Fehler, die eine Clientanwendung verzeichnet, hängt davon ab, wie viele Vorgänge zum Zeitpunkt des Failovers in dieser Verbindung ausstanden. Bei jeder Verbindung, die über den Knoten weitergeleitet wird, dessen Verbindungen geschlossen wurden, treten Fehler auf.
Viele Clientbibliotheken können bei Verbindungsabbrüchen verschiedene Arten von Fehlern auslösen, darunter:
- Timeoutausnahmen
- Verbindungsausnahmen
- Socketausnahmen
Anzahl und Typ der Ausnahmen hängen davon ab, wo sich die Anforderung im Codepfad befindet, wenn der Cache die Verbindungen schließt. Beispielsweise tritt bei einem Vorgang, bei dem eine Anforderung gesendet wird, für die zum Zeitpunkt des Failovers jedoch noch keine Antwort zurückgegeben wurde, möglicherweise eine Timeoutausnahme auf. Bei neuen Anforderungen für das geschlossene Verbindungsobjekt treten Verbindungsausnahmen auf, bis die Verbindung erfolgreich wiederhergestellt wird.
Die meisten Clientbibliotheken versuchen, erneut eine Verbindung mit dem Cache herzustellen, wenn sie entsprechend konfiguriert sind. Durch unvorhergesehene Fehler können die Bibliotheksobjekte jedoch gelegentlich in einen nicht wiederherstellbaren Zustand gesetzt werden. Wenn Fehler länger als eine vorkonfigurierte Zeitspanne andauern, sollte das Verbindungsobjekt neu erstellt werden. In Microsoft.NET und anderen objektorientierten Sprachen können Sie die Verbindung neu erstellen, ohne die Anwendung neu zu starten, mithilfe eines ForceReconnect-Musters.
Welche Updates sind unter Wartung enthalten?
Wartung umfasst folgende Updates:
- Redis Server-Updates: Alle Updates oder Patches der Redis Server-Binärdateien.
- Updates für den virtuellen Computer (Virtual Machine, VM): Alle Updates des virtuellen Computers, auf dem der Redis-Dienst gehostet wird. VM-Updates reichen von Patches für Softwarekomponenten in der Hostumgebung über Upgrades von Netzwerkkomponenten bis hin zur Außerbetriebnahme.
Wird der Wartungsverlauf im Azure Portal angezeigt?
Informationen zum Wartungsverlauf im Azure-Portal finden Sie im Azure Activity-Protokoll für Ihre Cacheinstanz. Das Ereignis "healthevent" wird ausgegeben, wenn die Wartung beginnt.
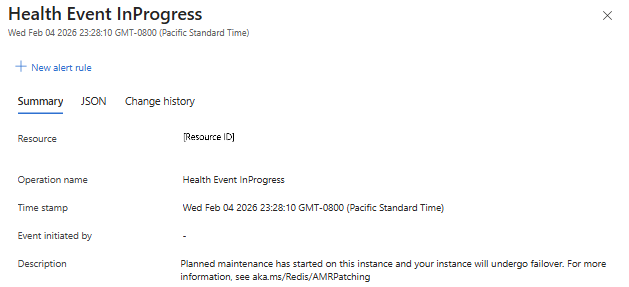
Richten Sie eine Warnung bei Aktivitätsprotokollereignissen ein, um automatisch benachrichtigt zu werden.
Änderungen der Clientnetzwerkkonfiguration
Bestimmte Änderungen der clientseitigen Netzwerkkonfiguration können Fehler vom Typ Keine Verbindung verfügbar auslösen. Dies betrifft beispielsweise folgende Änderungen:
- Austauschen der virtuellen IP-Adresse einer Clientanwendung zwischen Staging- und Produktionsslots
- Skalieren der Größe oder Anzahl der Instanzen der Anwendung
Diese Änderungen können zu einem Verbindungsproblem führen, das in der Regel weniger als eine Minute dauert. Ihre Clientanwendung verliert wahrscheinlich die Verbindung mit anderen externen Netzwerkressourcen, aber auch mit dem Azure Verwalteten Redis-Dienst.
Erstellen von Resilienz
Failover lassen sich nicht ganz vermeiden. Schreiben Sie Ihre Clientanwendungen daher so, dass sie gegenüber Verbindungsunterbrechungen und nicht erfolgreichen Anforderungen resilient sind. Von den meisten Clientbibliotheken wird zwar automatisch erneut eine Verbindung mit dem Cacheendpunkt hergestellt, aber nur wenige versuchen, nicht erfolgreiche Anforderungen zu wiederholen. Je nach Anwendungsszenario ist es möglicherweise sinnvoll, Wiederholungslogik mit Backoff zu verwenden.
Wie mache ich meine Anwendung resilient?
Die folgenden Entwurfsmustern helfen Ihnen bei der Erstellung robuster Clients. Das gilt insbesondere für die Trennschalter- und Wiederholungsmuster:
- Zuverlässigkeitsmuster - Cloud Design Patterns
- Wiederholungsanleitung für Azure-Dienste – Bewährte Methoden für Cloud-Anwendungen
- Implementieren von Wiederholungen mit exponentiellem Backoff