Hochverfügbarkeit (Zuverlässigkeit) für Azure Database for PostgreSQL – Flexible Server
GILT FÜR:  Azure Database for PostgreSQL – Flexibler Server
Azure Database for PostgreSQL – Flexibler Server
In diesem Artikel wird die hohe Verfügbarkeit in der Azure-Datenbank für PostgreSQL – Flexibler Server beschrieben, der Verfügbarkeitszonen und regionsübergreifende Wiederherstellung und Geschäftskontinuität umfasst. Eine ausführlichere Übersicht über die Zuverlässigkeit in Azure finden Sie unter Azure-Zuverlässigkeit.
Azure-Datenbank für PostgreSQL - Flexible Server bietet Unterstützung für hohe Verfügbarkeit, indem physisches primäres und Standby-Replikat entweder innerhalb derselben Verfügbarkeitszone (zonal) oder in allen Verfügbarkeitszonen (zonenredundant) bereitgestellt wird. Dieses Hochverfügbarkeitsmodell ist so konzipiert, dass zugesicherte Daten bei Fehlern nie verloren gehen. Das Modell ist auch so konzipiert, dass die Datenbank nicht zu einem einzigen Fehlerpunkt in Ihrer Softwarearchitektur wird. Weitere Informationen zur Hochverfügbarkeit und zur Unterstützung von Verfügbarkeitszonen finden Sie unter Unterstützung von Verfügbarkeitszonen.
Unterstützung für Verfügbarkeitszonen
Azure-Verfügbarkeitszonen sind mindestens drei physisch getrennte Gruppen von Rechenzentren innerhalb jeder Azure-Region. Die Rechenzentren innerhalb jeder Zone sind mit unabhängiger Stromversorgung, Kühlung und Netzwerkinfrastruktur ausgestattet. Bei einem Fehler in der lokalen Zone sind Verfügbarkeitszonen so konzipiert, dass regionale Dienste, Kapazität und Hochverfügbarkeit von den verbleibenden beiden Zonen unterstützt werden, wenn eine Zone betroffen ist.
Ausfälle können von Software- und Hardwareausfällen bis hin zu Ereignissen wie Erdbeben, Überflutungen und Bränden reichen. Fehlertoleranz wird durch Redundanz und logische Isolierung von Azure-Diensten erreicht. Ausführlichere Informationen zu Verfügbarkeitszonen in Azure finden Sie unter Regionen und Verfügbarkeitszonen.
Azure-Dienste mit Unterstützung von Verfügbarkeitszonen bieten das richtige Maß an Zuverlässigkeit und Flexibilität. Für die Konfiguration gibt es zwei Möglichkeiten. Sie können entweder zonenredundant mit automatischer zonenübergreifender Replikation oder zonenbasiert mit Instanzen sein, die an eine bestimmte Zone angeheftet werden. Sie können diese Ansätze auch kombinieren. Weitere Informationen zur zonalen im Vergleich zur zonenredundanten Architektur finden Sie unter Empfehlungen für die Verwendung von Verfügbarkeitszonen und Regionen.
Azure-Datenbank für PostgreSQL – Flexible Server unterstützt sowohl zonenredundante als auch zonale Modelle zur Konfigurationen mit hoher Verfügbarkeit. Beide Hochverfügbarkeitskonfigurationen ermöglichen ein automatisches Failover ohne Datenverlust während geplanten als auch ungeplanten Ereignissen.
Zonenredundant. Mit der zonenredundanten Hochverfügbarkeit wird ein Standbyreplikat in einer anderen Zone mit automatischer Failoverfunktion bereitgestellt. Zonenredundanz bietet den höchsten Verfügbarkeitsgrad, erfordert aber eine zonenübergreifende Konfiguration der Anwendungsredundanz. Wählen Sie daher Zonenredundanz aus, wenn Sie sich vor Ausfällen auf Verfügbarkeitszonenebene schützen möchten und die verfügbarkeitszonenübergreifende Latenz akzeptabel ist.
Sie können die Region sowie die Verfügbarkeitszonen für sowohl den primären Server als auch den Standbyserver auswählen. Der Standbyreplikatserver wird in der ausgewählten Verfügbarkeitszone in derselben Region mit einer ähnlichen Compute-, Speicher- und Netzwerkkonfiguration wie der primäre Server bereitgestellt. Daten- und Transaktionsprotokolldateien (Write-Ahead-Logs oder WAL) werden in lokal redundantem Speicher (LRS) innerhalb jeder Verfügbarkeitszone gespeichert, in dem automatisch drei Datenkopien gespeichert werden. Eine zonenredundante Konfiguration ermöglicht eine physische Isolierung des gesamten Stapels zwischen primären und Standbyservern.

Zonal. Wählen Sie eine zonale Bereitstellung, wenn Sie die bestmögliche Verfügbarkeit innerhalb einer einzelnen Verfügbarkeitszone aber mit der geringstmöglichen Netzwerklatenz erzielen möchten. Sie können die Region und Verfügbarkeitszone auswählen, um beide Ihrer primären Datenbankserver bereitzustellen. Ein Standbyreplikatserver wird automatisch in derselben Verfügbarkeitszone mit einer ähnlichen Compute-, Speicher- und Netzwerkkonfiguration wie der primäre Server bereitgestellt und verwaltet. Eine Zonalkonfiguration schützt Ihre Datenbank vor Fehlern auf Knotenebene und hilft auch bei der Reduzierung der Downtime von Anwendungen während geplanter und ungeplanter Downtimeereignisse. Die Daten vom primären Server werden im synchronen Modus auf das Standbyreplikat repliziert. Im Falle einer Unterbrechung des primären Servers erfolgt automatisch ein Failover für den Server auf das Standbyreplikat.



Hinweis
Sowohl zonale als auch zonenredundante Bereitstellungsmodelle verhalten sich architektonisch identisch. Verschiedene Erörterungen in den folgenden Abschnitten gelten für beide (sofern nicht anders angegeben).
Voraussetzungen
Zonenredundanz:
Die Option Zonenredundanz gibt es nur in Regionen, die Verfügbarkeitszonen unterstützen.
Zonenredundanz wird nicht unterstützt für:
- Azure Database for PostgreSQL: Einzelserver SKU.
- Burstfähige Computeebene.
- Regionen mit einer Zonenverfügbarkeit.
Zonal:
- Die Zonalbereitstellungsoption ist in allen Azure-Regionen verfügbar, in denen Flexible Server bereitgestellt werden kann.
Hochverfügbarkeitsfeatures
Ein Standbyreplikat wird in derselben VM-Konfiguration bereitgestellt – einschließlich vCores, Speicher, Netzwerkeinstellungen – als primärer Server.
Sie können die Verfügbarkeitszonenunterstützung für einen vorhandenen Datenbankserver hinzufügen.
Sie können das Standbyreplikat entfernen, indem Sie Hochverfügbarkeit deaktivieren.
Sie können die Verfügbarkeitszonen für den primären Datenbankserver und den Standbydatenbankserver für die zonenredundante Verfügbarkeit auswählen.
Vorgänge wie Beenden, Starten und Neustarten werden auf primären und Standbydatenbankservern gleichzeitig ausgeführt.
In zonenredundanten und zonalen Modellen werden automatische Sicherungen regelmäßig vom primären Datenbankserver ausgeführt. Gleichzeitig werden die Transaktionsprotokolle kontinuierlich im Sicherungsspeicher aus dem Standbyreplikat archiviert. Wenn die Region Verfügbarkeitszonen unterstützt, werden Sicherungsdaten in zonenredundantem Speicher (ZRS) gespeichert. Wenn die Region keine Verfügbarkeitszonen unterstützt, werden Sicherungsdaten in lokal redundantem Speicher (LRS) gespeichert.
Clients stellen stets eine Verbindung mit dem Hostnamen des primären Datenbankservers her.
Alle Änderungen an den Serverparametern werden auch auf das Standbyreplikat angewendet.
Möglichkeit, den Server neu zu starten, sodass alle Änderungen an statischen Serverparametern übernommen werden.
Regelmäßige Wartungsaktivitäten wie Nebenversionsupgrades erfolgen zuerst im Standby-Modus. Um Ausfallzeiten zu reduzieren, wird der Standby-Modus als primär hochgestuft, sodass die Arbeitsauslastungen beibehalten werden können, während die Wartungsaufgaben auf den verbleibenden Knoten gemacht werden.
Überwachen der Hochverfügbarkeitsintegrität
Durch das Überwachen des Integritätsstatus der Hochverfügbarkeit in Azure Database for PostgreSQL – Flexibler Server behalten Sie eine kontinuierliche Übersicht über die Integrität und Bereitschaft von Instanzen mit Hochverfügbarkeit. Dieses Überwachungsfeature nutzt das Azure Resource Health Check-Framework (RHC), um Probleme, die sich auf die Failoverbereitschaft Ihrer Datenbank oder die allgemeine Verfügbarkeit auswirken können, zu erkennen und darüber zu benachrichtigen. Durch die Bewertung wichtiger Metriken wie Verbindungsstatus, Failoverstatus und Datenreplikationsintegrität ermöglicht die Überwachung der Hochverfügbarkeitsintegrität eine proaktive Problembehandlung und hilft dabei, die Betriebszeit und Leistung Ihrer Datenbank aufrechtzuerhalten.
Kunden können die Überwachung der Hochverfügbarkeitsintegrität für Folgendes verwenden:
- Abrufen von Echtzeiterkenntnissen zur Integrität von primären und Standby-Replikaten mit Statusindikatoren, die potenzielle Probleme anzeigen, z. B. ein Leistungsabfall oder Netzwerksperren
- Konfigurieren von Warnungen, um rechtzeitig über Änderungen des Hochverfügbarkeitsstatus informiert zu werden und sofortige Maßnahmen zur Behebung potenzieller Störungen durchzuführen
- Optimieren der Failoverbereitschaft durch die Ermittlung und Behandlung von Problemen, bevor sie sich auf Datenbankvorgänge auswirken
Einen ausführlichen Leitfaden zum Konfigurieren und Interpretieren von Integritätsstatus im Zusammenhang mit Hochverfügbarkeit finden Sie im Hauptartikel Überwachung der Hochverfügbarkeitsintegritätsstatus für Azure Database for PostgreSQL – Flexibler Server.
Hochverfügbarkeit – Einschränkungen
Aufgrund der synchronen Replikation zum Standbyserver, insbesondere bei einer zonenredundanten Konfiguration, kann es zu einer erhöhten Schreib- und Commitlatenz für Anwendungen kommen.
Standbyreplikate können nicht für Leseabfragen verwendet werden.
Je nach Workload und Aktivität auf dem primären Server kann der Failoverprozess aufgrund der Wiederherstellung im Standbyreplikat länger als 120 Sekunden dauern, bevor es höher gestuft werden kann.
Der Standbyserver stellt WAL-Dateien in der Regel mit 40 MB/s wieder her. Wenn Ihre Workload diesen Grenzwert überschreitet, kann die Wiederherstellung entweder während des Failovers oder nach dem Einrichten eines neuen Standbyservers länger dauern.
Die Konfiguration für Verfügbarkeitszonen führt zu einer gewissen Wartezeit bei Schreibvorgängen und Commits, aber ohne Auswirkungen auf Leseabfragen. Die Auswirkungen auf die Leistung variieren je nach Workload. Eine allgemeine Faustregel lautet: Für Schreib- und Lesevorgänge kann sich eine Beeinträchtigung von ca. 20 bis 30 % ergeben.
Ein Neustart des primären Datenbankservers führt auch zu einem Neustart des Standbyreplikats.
Das Konfigurieren eines zusätzlichen Standbymodus wird nicht unterstützt.
Das Konfigurieren vom Kunden ausgelöster Verwaltungsaufgaben kann im verwalteten Wartungsfenster nicht geplant werden.
Geplante Ereignisse wie das Skalieren von Compute- und Speicherkapazität finden zuerst auf dem Standby- und dann auf dem primären Server statt. Der Server führt derzeit für diese geplanten Vorgänge kein Failover aus.
Wenn die logische Decodierung oder logische Replikation mit einem verfügbarkeitskonfigurierten flexiblen Server konfiguriert ist, werden die logischen Replikationsslots bei einem Failover auf den Standbyserver nicht auf den Standbyserver kopiert. Um logische Replikations-Slots zu erhalten und die Datenkonsistenz nach einem Failover zu gewährleisten, wird empfohlen, die Erweiterung PG Failover Slots zu verwenden. Weitere Informationen zum Aktivieren dieser Erweiterung finden Sie in der Dokumentation.
Das Konfigurieren von Verfügbarkeitszonen zwischen privatem (VNET) und öffentlichem Zugriff mit privaten Endpunkten wird nicht unterstützt. Sie müssen Verfügbarkeitszonen in einem VNET (übergreifend für Verfügbarkeitszonen einer Region) oder für den öffentlichen Zugriff mit privaten Endpunkten konfigurieren.
Verfügbarkeitszonen werden nur innerhalb einer einzelnen Region konfiguriert. Verfügbarkeitszonen können nicht über Regionen hinweg konfiguriert werden.
SLA
Zonales Modell bietet eine Uptime- SLA von 99,95 %.
Zonen-Redundanz-Modell bietet eine Uptime- SLA von 99,99 %.
Erstellen einer Azure-Datenbank für PostgreSQL – Flexibler Server mit aktivierter Verfügbarkeitszone
Informationen zum Erstellen einer Azure-Datenbank für PostgreSQL – Flexibler Server für hohe Verfügbarkeit mit Verfügbarkeitszonen finden Sie in der Schnellstartanleitung: Erstellen einer Azure-Datenbank für PostgreSQL – Flexibler Server im Azure-Portal.
Erneute Bereitstellung und Migration von Verfügbarkeitszonen
Informationen zum Aktivieren oder Deaktivieren der Konfiguration mit hoher Verfügbarkeit in Ihrem flexiblen Server in zonenredundanten und zonalen Bereitstellungsmodellen finden Sie unter Verwalten von Hochverfügbarkeit in Flexibler Server.
Komponenten und Workflows mit hoher Verfügbarkeit
Abschluss der Transaktion
Von der Anwendungstransaktion ausgelöste Schreib- und Commitvorgänge werden zuerst auf dem primären Server im WAL protokolliert. Anschließend werden sie mit dem Postgres-Streamingprotokoll an den Standbyserver übertragen. Sobald die Protokolle im Speicher des Standbyservers gespeichert wurden, erhält der primäre Server eine Bestätigung, dass der Schreibvorgang abgeschlossen wurde. Erst dann wird der Commit der Transaktion bestätigt. Dieser zusätzliche Roundtrip erhöht die Latenz Ihrer Anwendung. Die prozentuale Auswirkungen hängt von der Anwendung ab. Dieser Bestätigungsprozess wartet nicht, bis die Protokolle auf dem Standbyserver übernommen wurden. Der Standbyserver befindet sich dauerhaft im Wiederherstellungsmodus, bis zum Primärserver hochgestuft wird.
Integritätsprüfung
Flexible Serverintegritätsüberwachung überprüft regelmäßig sowohl den primären als auch den Standbystatus. Wenn die Integritätsüberwachung nach mehreren Pings erkennt, dass ein primärer Server nicht erreichbar ist, initiiert der Dienst dann ein automatisches Failover auf den Standbyserver. Der Systemüberwachungs-Algorithmus basiert auf mehreren Datenpunkten, um Falsch-Positiv-Situationen zu vermeiden.
Failovermodi
Der flexible Server unterstützt zwei Failovermodi: Geplantes Failover und nicht geplantes Failover. Sobald die Replikation deaktiviert wurde, führt der Standbyserver in beiden Modi die Wiederherstellung aus, bevor er zum primären Server hochgestuft und für Lese-/Schreibzugriffe geöffnet wird. Nachdem automatische DNS-Einträgen mit dem neuen primären Serverendpunkt aktualisiert wurden, können Anwendungen über diesen Endpunkt eine Verbindung mit dem Server herstellen. Im Hintergrund wird ein neuer Standbyserver eingerichtet, sodass Ihre Anwendung die Konnektivität aufrecht erhalten kann.
Hochverfügbarkeitsstatus
Die Integrität des primären und Standbyservers wird ständig überwacht, und es werden geeignete Maßnahmen ergriffen, um Probleme zu beheben, einschließlich des Auslösens eines Failover auf den Standbyserver. In der folgenden Tabelle sind die möglichen Status für hohe Verfügbarkeit aufgeführt:
| Status | Beschreibung |
|---|---|
| Initialisieren | Ein neuer Standbyserver wird aktuell erstellt. |
| Replizieren von Daten | Nach Erstellung des Standbyservers wird er mit dem primären Server synchronisiert. |
| Healthy | Die Replikation ist stabil und fehlerfrei. |
| Ausführen eines Failovers | Der Datenbankserver führt ein Failover auf den Standbyserver durch. |
| Standby wird aufgehoben | Der Standbyserver wird gerade gelöscht. |
| Nicht aktiviert | Hohe Verfügbarkeit ist nicht aktiviert. |
Hinweis
Sie können Hochverfügbarkeit auch während der Servererstellung oder zu einem späteren Zeitpunkt aktivieren. Wenn Sie Hochverfügbarkeit in der Phase nach der Erstellung aktivieren oder deaktivieren, empfiehlt es sich, den Vorgang durchzuführen, wenn die Aktivität auf dem primären Server gering ist.
Vorgänge mit stabilem Zustand
PostgreSQL-Clientanwendungen sind mit dem primären Server über den Namen des Datenbankservers verbunden. Anwendungslesevorgänge werden direkt vom primären Server bereitgestellt. Gleichzeitig werden Commits und Schreibvorgänge für die Anwendung bestätigt, nachdem die Protokolldaten sowohl auf dem primären Server als auch auf dem Standbyreplikat gespeichert wurden. Aufgrund dieses zusätzlichen Roundtrips ist bei Anwendungen mit einer höheren Latenz für Schreib- und Commitvorgänge zu rechnen. Sie können die Integrität der Hochverfügbarkeit im Portal überwachen.
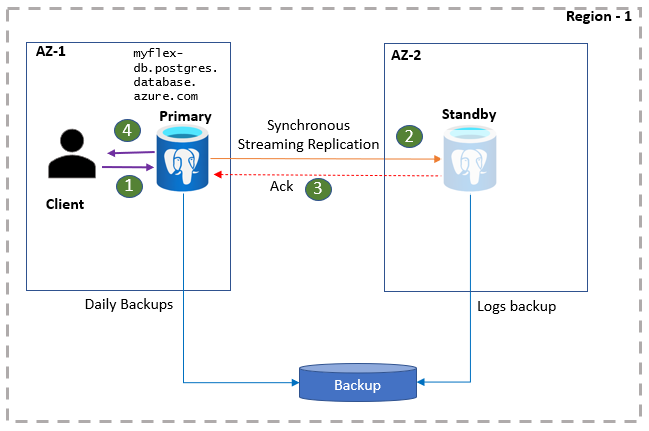
- Clients stellen eine Verbindung mit der Flexible Server-Instanz her und führen Schreibvorgänge aus.
- Änderungen werden an den Standbystandort repliziert.
- Der primäre Server empfängt eine Bestätigung.
- Schreib-/Commitvorgänge werden bestätigt.
Point-in-Time-Wiederherstellung von Hochverfügbarkeitsservern
Bei mit Hochverfügbarkeit konfigurierten flexiblen Servern werden Protokolldaten in Echtzeit auf den Standbyserver repliziert. Benutzerfehler auf dem primären Server, z. B. versehentliches Löschen einer Tabelle oder fehlerhafte Datenaktualisierungen, werden in das Standbyreplikat repliziert. Daher können Sie den Standbyserver nicht zur Behebung solcher logischen Fehler einsetzen. Um diese Fehler zu beheben, müssen Sie eine Zeitpunktwiederherstellung aus einer Sicherungen durchführen. Dank der Möglichkeit einer Zeitpunktwiederherstellung für die Flexible Server-Instanz können Sie eine Wiederherstellung zu einem Zeitpunkt vor dem Fehler durchführen. Ein neuer Datenbankserver wird als flexibler Server mit einer einzelnen Zone und einem neuen vom Benutzer angegebenen Servernamen bei mit Hochverfügbarkeit konfigurierten Datenbanken wiederhergestellt. Sie können den wiederhergestellten Server für einige Anwendungsfälle verwenden:
Sie können den wiederhergestellten Server für die Produktion verwenden und optional hohe Verfügbarkeit mit Standby-Replikaten in derselben Zone oder einer anderen Zone in derselben Region aktivieren.
Wenn Sie ein Objekt wiederherstellen möchten, exportieren Sie das Objekt vom wiederhergestellten Datenbankserver und importieren es in Ihren Produktionsdatenbankserver.
Wenn Sie Ihren Datenbankserver für Test- und Entwicklungszwecke klonen oder für andere Zwecke wiederherstellen möchten, können Sie auch eine Zeitpunktwiederherstellung durchführen.
Informationen zum Ausführen einer Zeitpunktwiederherstellung eines flexiblen Servers finden Sie unter Zeitpunktwiederherstellung eines flexiblen Servers.
Failoverunterstützung
Geplantes Failover
Zu den geplanten Ausfallzeiten zählen regelmäßige geplante Softwareupdates und Upgrades von Nebenversionen in Azure. Sie können auch ein geplantes Failover verwenden, um den primären Server an eine bevorzugte Verfügbarkeitszone zurückzugeben. Bei konfigurierter Hochverfügbarkeit erfolgen diese Vorgänge zunächst für das Standbyreplikat, während die Anwendungen weiterhin auf den primären Server zugreifen. Nachdem das Standbyreplikat aktualisiert wurde, werden die Verbindungen des primären Servers ausgeglichen. Dabei wird ein Failover ausgelöst, durch das das Standbyreplikat als primärer Server mit identischem Datenbankservernamen aktiviert wird. Clientanwendungen müssen sich mit dem gleichen Namen des Datenbankservers wieder mit dem neuen primären Server verbinden und können ihren Betrieb fortsetzen. In der Zone des ehemaligen primären Servers wird ein neuer Standbyserver erstellt.
Bei anderen vom Benutzer eingeleiteten Vorgängen, wie z. B. Skalieren der Compute- oder Speicherkapazität, erfolgen die Änderungen zuerst auf dem Standby- und dann auf dem primären Server. Derzeit erfolgt kein Failover des Diensts auf den Standbyserver. Während der Skalierungsvorgang auf dem primären Server erfolgt, kommt es daher bei Anwendungen zu einer kurzen Ausfallzeit.
Sie können diese Funktion auch für ein Failover auf den Standby-Server mit geringerer Ausfallzeit nutzen. Beispielsweise könnte sich Ihr Primärserver nach einem ungeplanten Failover in einer anderen Verfügbarkeitszone befinden als die Anwendung. Sie sollten den primären Server in die vorherige Zone zurückbringen, um ihn mit Ihrer Anwendung zu verknüpfen.
Bei der Ausführung dieses Features wird der Standbyserver zunächst vorbereitet, um sicherzustellen, dass er mit den jüngsten Transaktionen auf dem gleichen Stand ist, damit die Anwendung weiterhin Lese- und Schreibvorgänge durchführen kann. Der Standbyserver wird anschließend höher gestuft, und die Verbindungen mit dem primären Server werden getrennt. Ihre Anwendung kann weiterhin Daten auf den primären Server schreiben, während im Hintergrund ein neuer Standbyserver eingerichtet wird. Im Folgenden werden die Schritte für ein geplantes Failover beschrieben:
| Schritt | Beschreibung | Sind Ausfallzeiten für Apps zu erwarten? |
|---|---|---|
| 1 | Warten Sie, bis der Standbyserver mit dem Primärserver auf dem gleichen Stand ist. | Nein |
| 2 | Das interne Überwachungssystem leitet den Failoverworkflow ein. | Nein |
| 3 | Schreibvorgänge der Anwendung werden blockiert, wenn sich der Standbyserver nahe bei der primären Protokollfolgenummer (LSN) befindet. | Ja |
| 4 | Der Standbyserver wird zu einem unabhängigen Server höher gestuft. | Ja |
| 5 | Der DNS-Eintrag wird mit der IP-Adresse des neuen Standbyservers aktualisiert. | Ja |
| 6 | Die Anwendung stellt die Verbindung wieder her und setzt ihre Lese-/Schreibvorgänge mit dem neuen primären Server fort. | Nein |
| 7 | Es wird ein neuer Standbyserver in einer anderen Zone eingerichtet. | Nein |
| 8 | Der Standbyserver beginnt mit der Wiederherstellung von Protokollen (aus Azure Blob Storage), die er während seiner Einrichtung verpasst hat. | Nein |
| 9 | Zwischen dem primären und Standbyserver wird ein konstanter Zustand eingerichtet. | Nein |
| 10 | Der geplante Failoverprozess ist abgeschlossen. | Nein |
Die Ausfallzeit der Anwendung beginnt bei Schritt 3, und der Betrieb kann nach Schritt 5 fortgesetzt werden. Die übrigen Schritte erfolgen im Hintergrund, ohne die Schreib- und Commitvorgänge der Anwendung zu beeinträchtigen.
Tipp
Beim flexiblen Server können Sie optional von Azure eingeleitete Wartungsaktivitäten planen, indem Sie ein 60-minütiges Fenster für einen gewünschten Tag wählen, an dem die Aktivitäten in den Datenbanken voraussichtlich gering sein werden. Azure-Wartungsaufgaben wie Patchen oder Upgrades von Nebenversionen erfolgen dann in diesem Zeitfenster. Wenn Sie kein benutzerdefiniertes Fenster auswählen, wird für Ihren Server ein vom System zugeteiltes einstündiges Fenster zwischen 23:00 Uhr und 07:00 Uhr Ortszeit ausgewählt. Diese von Azure initiierten Wartungsaktivitäten werden auch im Standbyreplikat für flexible Server ausgeführt, die mit Verfügbarkeitszonen konfiguriert sind.
Eine Liste der möglichen geplanten Ausfallzeiten finden Sie unter Geplante Ausfallzeiten.
Ungeplantes Failover
Ungeplante Downtimes können aufgrund von unvorhergesehenen Unterbrechungen auftreten, darunter Fehler in der zugrunde liegenden Hardware, Netzwerkprobleme und Softwarefehler. Wenn der mit Hochverfügbarkeit konfigurierte Datenbankserver unerwartet ausfällt, wird das Standbyreplikat aktiviert, und die Clients können ihren Betrieb fortsetzen. Wenn er nicht mit Hochverfügbarkeit konfiguriert wurde, wird bei Fehlschlagen des Neustartversuchs automatisch ein neuer Datenbankserver bereitgestellt. Ungeplante Downtime lässt sich zwar nicht vollständig vermeiden, wird aber vom flexiblen Server durch automatisches Ausführen von Wiederherstellungsvorgängen minimiert, ohne dass ein Eingreifen durch einen Benutzer erforderlich ist.
Informationen zu ungeplanten Failovers und Ausfallzeiten, einschließlich möglicher Szenarien, finden Sie unter Entschärfung ungeplanter Ausfallzeiten.
Failovertests (erzwungenes Failover)
Mit einem erzwungenen Failover können Sie das Szenario eines ungeplanten Ausfalls simulieren, während Ihr Workload in der Produktion läuft, und die Ausfallzeiten Ihrer Anwendung beobachten. Sie können auch ein erzwungenes Failover verwenden, wenn der primäre Server nicht mehr reagiert.
Ein erzwungenes Failover fährt den primären Server herunter und leitet den Failoverworkflow ein, in dem das Höherstufen des Standbyservers erfolgt. Sobald der Standbyserver den Wiederherstellungsvorgang bis zu den letzten Commitdaten abgeschlossen hat, wird er zum primären Server höher gestuft. DNS-Einträge werden aktualisiert, und Ihre Anwendung kann eine Verbindung mit dem höher gestuften primären Server herstellen. Ihre Anwendung kann weiterhin Daten auf den primären Server schreiben, während im Hintergrund ein neuer Standbyserver eingerichtet wird. Dies wirkt sich nicht auf die Betriebszeit aus.
Während des erzwungenen Failovers werden die folgenden Schritte ausgeführt:
| Schritt | Beschreibung | Sind Ausfallzeiten für Apps zu erwarten? |
|---|---|---|
| 1 | Der primäre Server wird kurz nach Empfang der Failoveranforderung beendet. | Ja |
| 2 | Bei der Anwendung kommt es zu Ausfallzeiten, da der primäre Server ausgefallen ist. | Ja |
| 3 | Das interne Überwachungssystem erkennt den Ausfall und leitet ein Failover auf den Standbyserver ein. | Ja |
| 4 | Der Standbyserver wird in den Wiederherstellungsmodus versetzt, bevor er vollständig als unabhängiger Server höher gestuft wird. | Ja |
| 5 | Der Failoverprozess wartet auf den Abschluss der Standbywiederherstellung. | Ja |
| 6 | Sobald der Server wieder in Betrieb ist, wird der DNS-Eintrag mit demselben Hostnamen, aber unter Verwendung der IP-Adresse des Standbyservers aktualisiert. | Ja |
| 7 | Die Anwendung kann erneut eine Verbindung mit dem neuen primären Server herstellen und den Vorgang fortsetzen. | Nein |
| 8 | Ein Standbyserver wird in der bevorzugten Zone eingerichtet. | Nein |
| 9 | Der Standbyserver beginnt mit der Wiederherstellung von Protokollen (aus Azure Blob Storage), die er während seiner Einrichtung verpasst hat. | Nein |
| 10 | Zwischen dem primären und Standbyserver wird ein konstanter Zustand eingerichtet. | Nein |
| 11 | Der erzwungene Failoverprozess ist abgeschlossen. | Nein |
Es wird erwartet, dass die Ausfallzeit der Anwendung nach Schritt 1 beginnt und bis zum Abschluss von Schritt 6 anhält. Die übrigen Schritte erfolgen im Hintergrund, ohne die Schreib- und Commitvorgänge der Anwendung zu beeinträchtigen.
Wichtig
Der End-to-End-Failoverprozess umfasst (a) das Failover auf den Standbyserver nach dem Ausfall des primären Servers und (b) das Einrichten eines neuen Standbyservers in einem stabilen Zustand. Da für Ihre Anwendung so lange Ausfallzeiten auftreten, bis das Failover auf den Standbyserver abgeschlossen ist, messen Sie die Ausfallzeit aus Anwendungs-/Clientperspektive anstelle des gesamten End-to-End-Failoverprozesses.
Überlegungen beim Ausführen erzwungener Failovers
Die Gesamtdauer des Vorgangs kann länger sein als die tatsächliche Ausfallzeit der Anwendung.
Wichtig
Messen Sie die Ausfallzeit immer aus Sicht der Anwendung!
Führen Sie nicht sofort ein erneutes Failover durch. Warten Sie mindestens 15 bis 20 Minuten zwischen Failovers, damit der neue Standbyserver vollständig eingerichtet werden kann.
Es wird empfohlen, ein erzwungenes Failover während eines Zeitraums mit geringer Aktivität durchzuführen, um Ausfallzeiten zu reduzieren.
Bewährte Methoden für PostgreSQL-Statistiken nach einem Failover
Nach einem PostgreSQL-Failover ist für den primären Mechanismus zur Aufrechterhaltung der optimalen Datenbankleistung ein Verständnis der unterschiedlichen Rollen der Tabellen pg_statistic und pg_stat_* erforderlich. Die Tabelle pg_statistic enthält Optimiererstatistiken, die für den Abfrageplaner von entscheidender Bedeutung sind. Diese Statistiken umfassen Datenverteilungen innerhalb von Tabellen und bleiben nach einem Failover intakt, um sicherzustellen, dass der Abfrageplaner die Abfrageausführung basierend auf genauen, historischen Datenverteilungsinformationen effektiv optimieren kann.
Im Gegensatz dazu werden die Tabellen pg_stat_*, in denen Aktivitätsstatistiken wie die Anzahl der Scans, gelesene Tupel und Updates erfasst werden, beim Failover zurückgesetzt. Ein Beispiel für eine solche Tabelle ist pg_stat_user_tables, die die Aktivität für benutzerdefinierte Tabellen nachverfolgt. Diese Zurücksetzung soll den betriebstechnischen Zustand des neuen primären Replikats genau widerspiegeln, bedeutet aber auch den Verlust historischer Aktivitätsmetriken, auf denen der Autovacuumprozess und andere betriebliche Effizienzen aufbauen können.
Angesichts dieser Unterscheidung besteht die bewährte Methode nach einem PostgreSQL-Failover darin, ANALYZE auszuführen. Mit dieser Aktion werden die Tabellen pg_stat_* wie etwa pg_stat_user_tables mit neuen Aktivitätsstatistiken aktualisiert, wodurch der Autovacuumprozess unterstützt und sichergestellt wird, dass die Datenbankleistung in ihrer neuen Rolle optimal bleibt. Dieser proaktive Schritt überbrückt die Lücke zwischen der Beibehaltung wesentlicher Optimiererstatistiken und der Aktualisierung von Aktivitätsmetriken, um den aktuellen Zustand der Datenbank auszurichten.
Zonenausfall
Zonal Um einen Fehler auf Zonenebene wiederherzustellen, können Sie mithilfe der Sicherung eine Point-in-Time-Wiederherstellung durchführen. Sie können einen benutzerdefinierten Wiederherstellungspunkt mit der neuesten Uhrzeit auswählen, um die neuesten Daten wiederherzustellen. Ein neuer flexibler Server wird in einer anderen nicht betroffenen Zone bereitgestellt. Die für die Wiederherstellung benötigte Zeit hängt von der vorherigen Sicherung und dem Volume der wiederherzustellenden Transaktionsprotokolle ab.
Weitere Informationen zur Point-in-Time-Wiederherstellung finden Sie unter Sicherung und Wiederherstellung in der Azure-Datenbank für PostgreSQL-Flexible Server.
Zonenredundant: Für den flexiblen Server erfolgt automatisch ein Failover auf den Standbyserver innerhalb von 60–120 Sekunden ohne Datenverlust.
Konfigurationen ohne Verfügbarkeitszonen
Obwohl es nicht empfohlen wird, können Sie Ihren flexiblen Server konfigurieren, ohne dass eine hohe Verfügbarkeit aktiviert ist. Für flexible Server, die ohne Hochverfügbarkeit konfiguriert sind, bietet der Dienst lokalen redundanten Speicher mit drei Kopien der Daten, zonenredundante Sicherungen (in Regionen, in denen diese unterstützt werden) und integrierte Serverresilienz, um einen abgestürzten Server automatisch neu zu starten und den Server auf einen anderen physischen Knoten zu verlagern. Die Uptime-SLA über 99,9 % wird in dieser Konfiguration angeboten. Wenn der Server bei geplanten oder ungeplanten Failoverereignissen ausfällt, gewährleistet der Dienst die Verfügbarkeit der Server mit dem folgenden automatisierten Verfahren:
- Eine neue Computeressource in Form einer Linux-VM wird bereitgestellt.
- Der Speicher mit Datendateien wird dem neuen virtuellen Computer zugeordnet.
- Die PostgreSQL-Datenbank-Engine wird auf dem neuen virtuellen Computer online geschaltet.
Die folgende Abbildung zeigt den Übergang zwischen VM und Speicherfehlern.

Regionsübergreifende Notfallwiederherstellung und Geschäftskontinuität
Im Falle einer regionsweiten Katastrophe kann Azure mithilfe einer Notfallwiederherstellung Schutz vor regionalen oder großen geografischen Katastrophen bereitstellen, indem eine andere Region verwendet wird. Weitere Informationen zur Architektur der Azure-Notfallwiederherstellung finden Sie unter Architektur der Notfallwiederherstellung von Azure zu Azure.
Der flexible Server bietet Features, die Daten schützen und Downtimes für Ihre unternehmenskritischen Datenbanken während geplanter und ungeplanter Downtimes reduzieren. Der flexible Server baut auf der Azure-Infrastruktur auf, die robuste Resilienz und Verfügbarkeit bietet, und er stellt Features für die Geschäftskontinuität bereit, die zusätzlichen Fehlerschutz bieten, Anforderungen an die Wiederherstellungszeit erfüllen und die Gefahr von Datenverlusten verringern. Wenn Sie die Architektur Ihrer Anwendungen entwerfen, sollten Sie die Downtimetoleranz – die Recovery Time Objective (RTO) – und die Datenverlustgefahr – die Recovery Point Objective (RPO) – berücksichtigen. Beispielsweise müssen für Ihre unternehmenskritische Datenbank strengere Uptimeanforderungen erfüllt werden als bei einer Testdatenbank.
Notfallwiederherstellung für mehrere Regionen
Georedundante Sicherung und Wiederherstellung
Georedundante Sicherung und Wiederherstellung bieten die Möglichkeit, Ihren Server im Falle eines Ereignisses in einer anderen Region wiederherzustellen. Sie bietet zudem eine Dauerhaftigkeit der Sicherungsobjekte von mindestens 99,99999999999999 Prozent (16 Neunen) für die Dauer eines Jahres.
Georedundante Sicherungen können nur zum Zeitpunkt der Servererstellung konfiguriert werden. Wenn der Server mit georedundanten Sicherungen konfiguriert ist, werden die Sicherungsdaten und Transaktionsprotokolle mithilfe der Speicherreplikation asynchron in die gekoppelte Region kopiert.
Weitere Informationen zur georedundanten Sicherung und Wiederherstellung finden Sie unter Georedundante Sicherung und Wiederherstellung.
Lesereplikate
Regionsübergreifende Lesereplikate können bereitgestellt werden, um Ihre Datenbanken vor Ausfällen auf Regionsebene zu schützen. Lesereplikate werden mithilfe der physischen Replikationstechnologie von PostgreSQL asynchron aktualisiert und können damit zu Verzögerungen auf dem primären Server führen. Lesereplikate unterstützen auf den Computeebenen „Allgemeiner Zweck“ und „Arbeitsspeicheroptimiert“.
Weitere Informationen über Funktionen und Überlegungen zu Lesereplikaten finden Sie unter Lesereplikate.
Erkennung, Benachrichtigung und Verwaltung von Ausfällen
Wenn Ihr Server mit georedundanter Sicherung konfiguriert ist, können Sie die Geowiederherstellung in der gekoppelten Region durchführen. Ein neuer Server wird bereitgestellt und mit den letzten verfügbaren Daten wiederhergestellt, die in diese Region kopiert wurden.
Sie können auch regionsübergreifende Lesereplikate verwenden. Bei einem Regionsausfall können Sie einen Notfallwiederherstellungsvorgang durchführen, indem Sie Ihr Lesereplikat zu einem eigenständigen Server mit Lese- und Schreibzugriff heraufstufen. Als RPO wird ein Wert von bis zu 5 Minuten erwartet (Datenverlust möglich), mit Ausnahme eines schwerwiegenden regionalen Fehlers, bei dem die RPO zum Zeitpunkt des Fehlers nahe an der Replikationsverzögerung liegen kann.
Weitere Informationen zur Entschärfung ungeplanter Downtime und zur Wiederherstellung nach einer regionalen Störung finden Sie unter Entschärfung ungeplanter Downtime.