Hochverfügbarkeit von IBM DB2 LUW auf virtuellen Azure-Computern unter Red Hat Enterprise Linux Server
IBM Db2 für Linux, UNIX und Windows (LUW) in einer HADR-Konfiguration (Hochverfügbarkeit und Notfallwiederherstellung) besteht aus einem Knoten, auf dem eine primäre Datenbankinstanz ausgeführt wird, und mindestens einem Knoten, auf dem eine sekundäre Datenbankinstanz ausgeführt wird. Änderungen an der primären Datenbankinstanz werden, abhängig von Ihrer Konfiguration, synchron oder asynchron in eine sekundäre Datenbankinstanz repliziert.
Hinweis
In diesem Artikel werden Begriffe verwendet, die von Microsoft nicht mehr genutzt werden. Sobald diese Begriffe aus der Software entfernt wurden, werden sie auch aus diesem Artikel gelöscht.
Dieser Artikel beschreibt die Bereitstellung und Konfiguration der virtuellen Azure-Computer (VMs), die Installation des Clusterframeworks und die Installation von IBM Db2 LUW mit HADR-Konfiguration.
In diesem Artikel wird nicht behandelt, wie IBM Db2 LUW mit HADR installiert und konfiguriert wird oder die oder SAP-Softwareinstallation erfolgt. Um Ihnen bei der Bewältigung dieser Aufgaben zu helfen, stellen wir Ihnen Verweise auf SAP- und IBM-Installationshandbücher zur Verfügung. Der Schwerpunkt dieses Artikels liegt auf Vorgehensweisen, die speziell für die Azure-Umgebung gelten.
IBM Db2 wird in der Version 10.5 und höher unterstützt, wie im SAP-Hinweis 1928533 dokumentiert.
Bevor Sie mit einer Installation beginnen, lesen Sie zunächst die folgenden SAP-Hinweise und die -Dokumentation:
| SAP-Hinweis | BESCHREIBUNG |
|---|---|
| 1928533 | SAP-Anwendungen in Azure: Unterstützte Produkte und Azure-VM-Typen |
| 2015553 | SAP in Azure: Supportvoraussetzungen |
| 2178632 | Wichtige Überwachungsmetriken für SAP in Azure |
| 2191498 | SAP unter Linux mit Azure: Erweiterte Überwachung |
| 2243692 | Linux auf Azure-VM (IaaS): SAP-Lizenzprobleme |
| 2002167 | Red Hat Enterprise Linux 7.x: Installation und Upgrade |
| 2694118 | Hochverfügbarkeits-Add-On für Red Hat Enterprise Linux in Azure |
| 1999351 | Problembehandlung für die erweiterte Azure-Überwachung für SAP |
| 2233094 | DB6: SAP-Anwendungen in Azure mit IBM Db2 für Linux, UNIX und Windows – weitere Informationen |
| 1612105 | DB6: Häufig gestellte Fragen zu Db2 mit HADR |
Übersicht
Um Hochverfügbarkeit zu erreichen, wird IBM Db2 LUW mit HADR auf mindestens zwei Azure-VMs installiert, die in einer VM-Skalierungsgruppe mit flexibler Orchestrierung über Verfügbarkeitszonen oder in einer Verfügbarkeitsgruppe bereitgestellt werden.
Die folgenden Grafiken zeigen eine Konfiguration von zwei auf virtuellen Azure-Computern installierten Datenbankservern. Jeder dieser auf einem virtuellen Azure-Computer installierten Datenbankserver hat seinen eigenen zugeordneten Speicher und ist aktiv und wird ausgeführt. In HADR hat eine Datenbankinstanz auf einem der virtuellen Azure-Computer die Rolle der primären Instanz. Alle Clients werden mit der primären Instanz verbunden. Alle in Datenbanktransaktionen vorgenommenen Änderungen werden lokal im Db2-Transaktionsprotokoll gespeichert. Da die Transaktionsprotokolldatensätze lokal gespeichert werden, werden die Datensätze über TCP/IP an die Datenbankinstanz auf dem zweiten Datenbankserver übertragen, der als Standbyserver oder Standbyinstanz bezeichnet wird. In der Standbyinstanz wird die lokale Datenbank aktualisiert, indem ein Rollforward mit den übertragenen Transaktionsprotokolldatensätzen ausgeführt wird. Auf diese Weise bleibt der Standbyserver mit dem primären Server synchronisiert.
HADR ist nur eine Replikationsfunktionalität. Sie bietet weder Fehlererkennung noch automatische Übernahme noch Failoverkomponenten. Eine Übernahme durch den oder Übertragung an den Standbyserver muss manuell von einem Datenbankadministrator initiiert werden. Um eine automatische Übernahme und Fehlererkennung zu erreichen, können Sie den Linux-Clusterressourcen-Manager Pacemaker verwenden. Pacemaker überwacht die beiden Datenbankserverinstanzen. Wenn die primäre Datenbankserverinstanz abstürzt, initiiert Pacemaker eine automatische HADR-Übernahme durch den Standbyserver. Der Herzschrittmacher stellt auch sicher, dass die virtuelle IP-Adresse dem neuen primären Server zugewiesen wird.
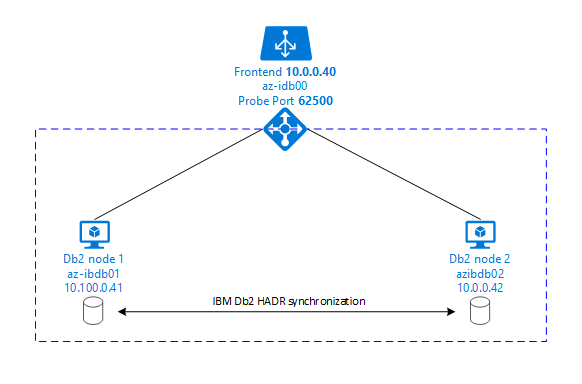
Damit SAP-Anwendungsservern eine Verbindung mit einer primären Datenbank herstellen können, benötigen Sie einen virtuellen Hostnamen und eine virtuelle IP-Adresse. Nach einem Failover werden die SAP-Anwendungsserver mit der neuen primären Datenbankinstanz verbunden. In einer Azure-Umgebung ist ein Azure Load Balancer erforderlich, um eine virtuelle IP-Adresse so zu verwenden, wie dies für HADR von IBM Db2 erforderlich ist.
Damit Sie vollständig verstehen zu können, wie IBM Db2 LUW mit HADR und Pacemaker in die Konfiguration eines hochverfügbaren SAP-Systems passen, enthält die folgende Abbildung eine Übersicht über ein hochverfügbares SAP-System, das auf einer IBM Db2-Datenbank basiert. In diesem Artikel geht es nur um IBM Db2, es werden jedoch Verweise auf andere Artikel zum Einrichten anderer Komponenten eines SAP-Systems bereitgestellt.
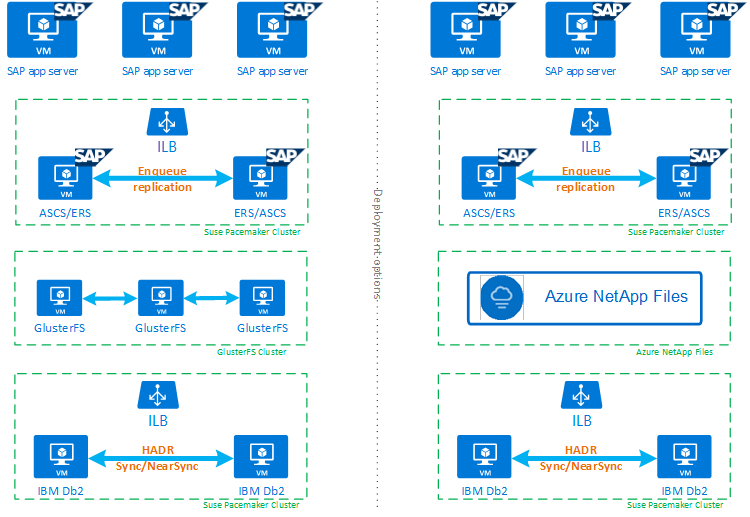
Allgemeine Übersicht über die erforderlichen Schritte
Um eine IBM Db2-Konfiguration bereitzustellen, müssen die folgenden Schritte ausgeführt werden:
- Planen der Umgebung.
- Stellen Sie die VMs bereit.
- Aktualisieren von RHEL Linux und Konfigurieren von Dateisystemen.
- Installieren und Konfigurieren von Pacemaker.
- Einrichten des glusterfs-Clusters oder von Azure NetApp Files.
- Installieren von ASCS/ERS in einem separaten Cluster.
- Installieren einer IBM Db2-Datenbank mit der Distributed/High Availability-Option (SWPM).
- Installieren und Erstellen eines sekundären Datenbankknotens und einer sekundären Datenbankinstanz und Konfigurieren von HADR.
- Bestätigen, dass HADR funktioniert.
- Anwenden der Pacemaker-Konfiguration, um IBM Db2 zu steuern.
- Konfigurieren von Azure Load Balancer.
- Installieren des primären Servers und der Dialog Application-Server.
- Überprüfen und Anpassen der Konfiguration der SAP-Anwendungsserver.
- Ausführen von Failover und Übernahmetests.
Planen der Azure-Infrastruktur zum Hosten von IBM Db2 LUW mit HADR.
Abschließen des Planungsprozesses, bevor Sie die Bereitstellung ausführen. Planung bildet die Grundlage für die Bereitstellung einer Konfiguration von Db2 mit HADR in Azure. Schlüsselelemente, die in der Planung für IMB Db2 LUW (Datenbankteil der SAP-Umgebung) berücksichtigt werden müssen, werden in der folgenden Tabelle aufgeführt.
| Thema | Kurze Beschreibung |
|---|---|
| Definieren von Azure-Ressourcengruppen | Ressourcengruppen, in denen Sie die VM, das virtuelle Netzwerk, Azure Load Balancer und andere Ressourcen bereitstellen. Können vorhanden oder neu sein. |
| Definition von virtuellem Netzwerk/Subnetz | Umgebung, in der virtuelle Computer für IBM Db2 und Azure Load Balancer bereitgestellt werden. Kann vorhanden sein oder neu erstellt werden. |
| Virtuelle Computer zum Hosten von IBM Db2 LUW | Größe, Speicher, Netzwerke, IP-Adressen der virtuellen Computer. |
| Virtueller Hostname und virtuelle IP-Adresse für die IBM Db2-Datenbank. | Die virtuelle IP oder der Hostname, die bzw. der für die Verbindung von SAP-Anwendungsservern verwendet wird. db-virt-hostname, db-virt-ip. |
| Azure-Umgrenzung | Methode zum Verhindern von Split Brain-Situationen. |
| Azure Load Balancer | Verwendung von Standard (empfohlen), Testport für die Db2-Datenbank (unsere Empfehlung ist 62500) probe-port. |
| Namensauflösung | Funktionsweise der Namensauflösung in der Umgebung. DNS-Dienst wird dringend empfohlen. Lokale hosts-Datei kann verwendet werden. |
Weitere Informationen zu Linux Pacemaker in Azure finden Sie unter Einrichten von Pacemaker unter Red Hat Enterprise Linux in Azure.
Wichtig
Für Db2-Versionen 11.5.6 und höher wird dringend eine integrierte Lösung empfohlen, die Pacemaker von IBM verwendet.
Bereitstellung unter Red Hat Enterprise Linux
Der Ressourcen-Agent für IBM Db2 für LUW ist im Hochverfügbarkeits-Add-On für Red Hat Enterprise Linux Server enthalten. Für das in diesem Dokument beschriebene Setup sollten Sie Red Hat Enterprise Linux für SAP verwenden. Der Azure Marketplace enthält ein Image für Red Hat Enterprise Linux 7.4 für SAP oder höher, mit dem Sie neue virtuelle Azure-Computer bereitstellen können. Beachten Sie die verschiedenen Support- oder Servicemodelle, die Red Hat über den Azure Marketplace anbietet, wenn Sie ein VM-Image im Azure-VM-Marketplace auswählen.
Hosts: DNS-Updates
Erstellen Sie eine Liste aller Hostnamen, einschließlich der Namen virtueller Hosts, und aktualisieren Sie Ihre DNS-Server, um die richtige Auflösung von IP-Adressen in Hostnamen zu aktivieren. Wenn kein DNS-Server vorhanden ist oder Sie keine DNS-Einträge aktualisieren und erstellen können, müssen Sie die lokalen host-Dateien der einzelnen VMs verwenden, die an diesem Szenario teilnehmen. Wenn Sie Einträge aus host-Dateien verwenden, stellen Sie sicher, dass die Einträge auf alle virtuellen Computer in der SAP-Systemumgebung angewendet werden. Allerdings empfehlen wir, dass Sie Ihr DNS verwenden, das im Idealfall in Azure erweitert wird.
Manuelle Bereitstellung
Vergewissern Sie sich, dass das ausgewählte Betriebssystem von IBM/SAP für IBM Db2 LUW unterstützt wird. Die Liste der unterstützten Betriebssystemversionen für virtuelle Azure-Computer und Db2-Versionen finden Sie im SAP-Hinweis 1928533. Die Liste der Betriebssystemversionen zu den einzelnen Db2-Releases ist in der SAP-Produktverfügbarkeitsmatrix verfügbar. Wir empfehlen Ihnen, mindestens Red Hat Enterprise Linux 7.4 für SAP zu verwenden, weil diese Version bzw. höhere Red Hat Enterprise Linux-Versionen Leistungsverbesserungen für Azure aufweisen.
- Erstellen Sie eine Ressourcengruppe, oder wählen Sie eine Ressourcengruppe aus.
- Erstellen Sie ein virtuelles Netzwerks und ein Subnetz, oder wählen Sie vorhandene Ressourcen aus.
- Wählen Sie einen geeigneten Bereitstellungstyp für SAP-VMs aus. In der Regel eine VM-Skalierungsgruppe mit flexibler Orchestrierung.
- Erstellen Sie den virtuellen Computer 1.
- Verwenden Sie das Red Hat Enterprise Linux für SAP-Image im Azure Marketplace.
- Wählen Sie die Skalierungsgruppe, die Verfügbarkeitszone oder die Verfügbarkeitsgruppe aus, die Sie in Schritt 3 erstellt haben.
- Erstellen Sie den virtuellen Computer 2.
- Verwenden Sie das Red Hat Enterprise Linux für SAP-Image im Azure Marketplace.
- Wählen Sie die Skalierungsgruppe, die Verfügbarkeitszone oder die Verfügbarkeitsgruppe aus, die Sie in Schritt 3 erstellt haben (nicht dieselbe Zone wie in Schritt 4).
- Fügen Sie den virtuellen Computern Datenträger hinzu. Prüfen Sie dann die Empfehlung für die Dateisystemkonfiguration, die Sie im Artikel Azure Virtual Machines – IBM DB2-DBMS-Bereitstellung für SAP-Workload finden.
Installieren von IBM Db2 LUW und der SAP-Umgebung
Bevor Sie mit der Installation einer SAP-Umgebung beginnen, die auf IBM Db2 LUW aufsetzt, sollten Sie die folgende Dokumentation lesen:
- Azure-Dokumentation.
- SAP-Dokumentation.
- IBM-Dokumentation.
Links zu dieser Dokumentation werden in der Einleitung dieses Artikels bereitgestellt.
Lesen Sie die SAP-Installationshandbücher, um zu erfahren, wie NetWeaver-basierte Anwendungen für IBM Db2 LUW installiert werden. Sie finden die Handbücher im SAP-Hilfeportal über die Handbuchsuche für SAP NetWeaver und ABAP-Plattform (Guide Finder for SAP NetWeaver and ABAP Platform).
Sie können die Anzahl der im Portal angezeigten Leitfäden verringern, indem Sie die folgenden Filter festlegen:
- Ich möchte: Installieren eines neuen Systems.
- Meine Datenbank: IBM Db2 für Linux, Unix und Windows.
- Zusätzliche Filter für SAP NetWeaver-Versionen, Stapelkonfiguration oder Betriebssystem.
Red Hat-Firewallregeln
Für Red Hat Enterprise Linux ist die Firewall standardmäßig aktiviert.
#Allow access to SWPM tool. Rule is not permanent.
sudo firewall-cmd --add-port=4237/tcp
Installationshinweise für das Einrichten von IBM Db2 LUW mit HADR
So richten Sie die primäre IBM Db2 LUW-Datenbankinstanz ein:
- Verwenden Sie die Option für Hochverfügbarkeit oder für Verteilung (Distributed).
- Installieren Sie SAP ASCS/ERS und die Datenbankinstanz.
- Erstellen Sie eine Sicherung der neu installierten Datenbank.
Wichtig
Notieren Sie sich den „Database Communication port“, den Sie während der Installation festgelegt haben. Für beide Datenbankinstanzen muss dieselbe Portnummer verwendet werden.
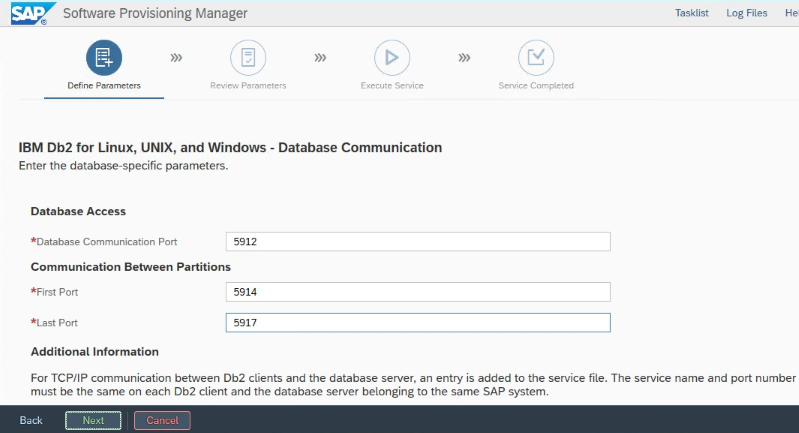
IBM Db2-Einstellungen zu Hochverfügbarkeit und Notfallwiederherstellung für Azure
Wenn Sie einen Azure Pacemaker-Fencing-Agent verwenden, legen Sie die folgenden Parameter fest:
- HADR-Peerfensterdauer (Sekunden) (HADR_PEER_WINDOW) = 240
- HADR-Timeoutwert (HADR_TIMEOUT) = 45
Wie empfehlen die oben genannten Parameterwerte basierend auf dem anfänglichen Testen für Failover/Übernahme. Es ist zwingend erforderlich, die ordnungsgemäße Funktionalität von Übernahme und Failover mit diesen Parametereinstellungen zu testen. Da die einzelne Konfigurationen variieren können, müssen diese Parameter möglicherweise angepasst werden.
Hinweis
Spezifisch für IBM Db2 mit HADR-Konfiguration mit normalem Start: Die sekundäre oder Standbydatenbankinstanz muss aktiv sein und ausgeführt werden, bevor Sie die primäre Datenbankinstanz starten können.
Hinweis
Installation und Konfiguration speziell für Azure und Pacemaker: Während der Installation durch SAP Software Provisioning Manager gibt es eine explizite Frage zu Hochverfügbarkeit für IBM Db2 LUW:
- Wählen Sie nicht IBM Db2 pureScale aus.
- Wählen Sie nicht Install IBM Tivoli System Automation for Multiplatforms aus.
- Wählen Sie nicht Generate cluster configration files aus.
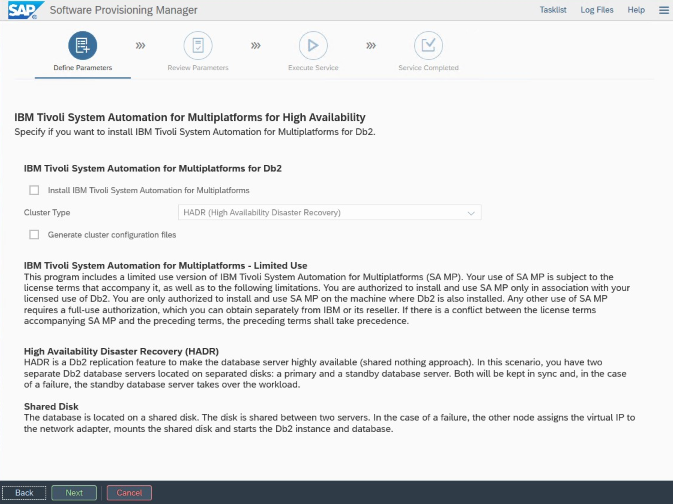
Um den Standbydatenbankserver mit der SAP-Prozedur „Homogeneous System Copy“ einzurichten, führen Sie die folgenden Schritte aus:
- Verwenden Sie die Option System copy>Target systems>Distributed>Datenbankinstanz.
- Wählen Sie als Kopiermethode die Option Homogeneous System aus, damit Sie „backup“ verwenden können, um eine Sicherung auf der Standbyserverinstanz wiederherstellen zu können.
- Wenn Sie den Schritt erreichen, in dem für „Homogeneous System Copy“ das Wiederherstellen beendet werden soll, beenden Sie das Installationsprogramm. Stellen Sie die Datenbank aus einer Sicherung des primären Hosts wieder her. Alle weiteren Installationsphasen wurden bereits auf dem primären Datenbankserver ausgeführt.
Red Hat-Firewallregeln für Db2 (Hochverfügbarkeit und Notfallwiederherstellung)
Fügen Sie Firewallregeln hinzu, damit Datenverkehr an Db2 und für Db2 für Hochverfügbarkeit und Notfallwiederherstellung fließen kann:
- Port für die Datenbankkommunikation. Wenn Sie Partitionen verwenden, müssen Sie die entsprechenden Ports ebenfalls hinzufügen.
- HADR-Port (Wert des DB2-Parameters HADR_LOCAL_SVC).
- Azure-Testport.
sudo firewall-cmd --add-port=<port>/tcp --permanent
sudo firewall-cmd --reload
IBM Db2 HADR-Überprüfung
Für Demonstrationszwecke und für die Vorgehensweisen, die in diesem Artikel beschrieben werden, lautet die Datenbank-SID ID2.
Nachdem Sie HADR konfiguriert haben und der Status PEER und CONNECTED für den primären und die Standbyknoten lautet, führen Sie die folgende Überprüfung durch:
Execute command as db2<sid> db2pd -hadr -db <SID>
#Primary output:
Database Member 0 -- Database ID2 -- Active -- Up 1 days 15:45:23 -- Date 2019-06-25-10.55.25.349375
HADR_ROLE = PRIMARY
REPLAY_TYPE = PHYSICAL
HADR_SYNCMODE = NEARSYNC
STANDBY_ID = 1
LOG_STREAM_ID = 0
HADR_STATE = PEER
HADR_FLAGS =
PRIMARY_MEMBER_HOST = az-idb01
PRIMARY_INSTANCE = db2id2
PRIMARY_MEMBER = 0
STANDBY_MEMBER_HOST = az-idb02
STANDBY_INSTANCE = db2id2
STANDBY_MEMBER = 0
HADR_CONNECT_STATUS = CONNECTED
HADR_CONNECT_STATUS_TIME = 06/25/2019 10:55:05.076494 (1561460105)
HEARTBEAT_INTERVAL(seconds) = 7
HEARTBEAT_MISSED = 5
HEARTBEAT_EXPECTED = 52
HADR_TIMEOUT(seconds) = 30
TIME_SINCE_LAST_RECV(seconds) = 5
PEER_WAIT_LIMIT(seconds) = 0
LOG_HADR_WAIT_CUR(seconds) = 0.000
LOG_HADR_WAIT_RECENT_AVG(seconds) = 598.000027
LOG_HADR_WAIT_ACCUMULATED(seconds) = 598.000
LOG_HADR_WAIT_COUNT = 1
SOCK_SEND_BUF_REQUESTED,ACTUAL(bytes) = 0, 46080
SOCK_RECV_BUF_REQUESTED,ACTUAL(bytes) = 0, 369280
PRIMARY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
STANDBY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
HADR_LOG_GAP(bytes) = 132242668
STANDBY_REPLAY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
STANDBY_RECV_REPLAY_GAP(bytes) = 0
PRIMARY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_REPLAY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_RECV_BUF_SIZE(pages) = 2048
STANDBY_RECV_BUF_PERCENT = 0
STANDBY_SPOOL_LIMIT(pages) = 1000
STANDBY_SPOOL_PERCENT = 0
STANDBY_ERROR_TIME = NULL
PEER_WINDOW(seconds) = 300
PEER_WINDOW_END = 06/25/2019 11:12:03.000000 (1561461123)
READS_ON_STANDBY_ENABLED = N
#Secondary output:
Database Member 0 -- Database ID2 -- Standby -- Up 1 days 15:45:18 -- Date 2019-06-25-10.56.19.820474
HADR_ROLE = STANDBY
REPLAY_TYPE = PHYSICAL
HADR_SYNCMODE = NEARSYNC
STANDBY_ID = 0
LOG_STREAM_ID = 0
HADR_STATE = PEER
HADR_FLAGS =
PRIMARY_MEMBER_HOST = az-idb01
PRIMARY_INSTANCE = db2id2
PRIMARY_MEMBER = 0
STANDBY_MEMBER_HOST = az-idb02
STANDBY_INSTANCE = db2id2
STANDBY_MEMBER = 0
HADR_CONNECT_STATUS = CONNECTED
HADR_CONNECT_STATUS_TIME = 06/25/2019 10:55:05.078116 (1561460105)
HEARTBEAT_INTERVAL(seconds) = 7
HEARTBEAT_MISSED = 0
HEARTBEAT_EXPECTED = 10
HADR_TIMEOUT(seconds) = 30
TIME_SINCE_LAST_RECV(seconds) = 1
PEER_WAIT_LIMIT(seconds) = 0
LOG_HADR_WAIT_CUR(seconds) = 0.000
LOG_HADR_WAIT_RECENT_AVG(seconds) = 598.000027
LOG_HADR_WAIT_ACCUMULATED(seconds) = 598.000
LOG_HADR_WAIT_COUNT = 1
SOCK_SEND_BUF_REQUESTED,ACTUAL(bytes) = 0, 46080
SOCK_RECV_BUF_REQUESTED,ACTUAL(bytes) = 0, 367360
PRIMARY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
STANDBY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
HADR_LOG_GAP(bytes) = 0
STANDBY_REPLAY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
STANDBY_RECV_REPLAY_GAP(bytes) = 0
PRIMARY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_REPLAY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_RECV_BUF_SIZE(pages) = 2048
STANDBY_RECV_BUF_PERCENT = 0
STANDBY_SPOOL_LIMIT(pages) = 1000
STANDBY_SPOOL_PERCENT = 0
STANDBY_ERROR_TIME = NULL
PEER_WINDOW(seconds) = 1000
PEER_WINDOW_END = 06/25/2019 11:12:59.000000 (1561461179)
READS_ON_STANDBY_ENABLED = N
Konfigurieren von Azure Load Balancer
Während der VM-Konfiguration können Sie im Abschnitt „Netzwerk“ einen Lastenausgleich erstellen oder einen vorhandenen Lastenausgleich auswählen. Führen Sie die folgenden Schritte aus, um den Standardlastenausgleich für das Hochverfügbarkeitssetup der DB2-Datenbank einzurichten.
Führen Sie die unter Erstellen eines Lastenausgleichs beschriebenen Schritte aus, um über das Azure-Portal einen Standardlastenausgleich für ein SAP-Hochverfügbarkeitssystem einzurichten. Berücksichtigen Sie beim Einrichten des Lastenausgleichs die folgenden Punkte:
- Front-End-IP-Konfiguration: Erstellen Sie eine IP-Adresse für das Front-End. Wählen Sie das gleiche virtuelle Netzwerk und Subnetz aus wie für Ihre virtuellen Datenbankcomputer.
- Back-End-Pool: Erstellen Sie einen Back-End-Pool, und fügen Sie virtuelle Datenbankcomputer hinzu.
- Regeln für eingehenden Datenverkehr: Erstellen Sie eine Lastenausgleichsregel. Führen Sie die gleichen Schritte für beide Lastenausgleichsregeln aus.
- Front-End-IP-Adresse: Wählen Sie eine Front-End-IP-Adresse aus.
- Back-End-Pool: Wählen Sie einen Back-End-Pool aus.
- Hochverfügbarkeitsports: Wählen Sie diese Option aus.
- Protokoll: Wählen Sie TCP.
- Integritätstest: Erstellen Sie einen Integritätstest mit folgenden Details:
- Protokoll: Wählen Sie TCP.
- Port: Beispielsweise 625<Instanznr.>
- Intervall: Geben Sie 5 ein.
- Testschwellenwert: Geben Sie 2 ein.
- Leerlauftimeout (Minuten): Geben Sie 30 ein.
- Floating IP aktivieren: Wählen Sie diese Option aus.
Hinweis
Die Konfigurationseigenschaft numberOfProbes für Integritätstests (im Portal als Fehlerschwellenwert bezeichnet) wird nicht berücksichtigt. Legen Sie die Eigenschaft probeThreshold auf 2 fest, um die Anzahl erfolgreicher oder nicht erfolgreicher aufeinanderfolgender Integritätstests zu steuern. Diese Eigenschaft kann derzeit nicht über das Azure-Portal festgelegt werden. Verwenden Sie daher entweder die Azure CLI oder den PowerShell-Befehl.
Wichtig
Floating IP wird bei einer NIC-Sekundär-IP-Konfiguration in Load-Balancing-Szenarien nicht unterstützt. Weitere Informationen finden Sie unter Azure Load Balancer-Beschränkungen. Wenn Sie zusätzliche IP-Adressen für die VM benötigen, stellen Sie eine zweite NIC bereit.
Hinweis
Wenn VMs ohne öffentliche IP-Adressen in den Back-End-Pool einer internen (keine öffentliche IP-Adresse) Azure Load Balancer Standard-Instanz platziert werden, gibt es keine ausgehende Internetkonnektivität, es sei denn, es werden weitere Konfigurationen vorgenommen, um das Routing zu öffentlichen Endpunkten zu ermöglichen. Weitere Informationen zur Erzielung von ausgehender Konnektivität finden Sie unter Konnektivität öffentlicher Endpunkte für VMs, die Azure Load Balancer Standard in SAP-Hochverfügbarkeitsszenarien verwenden.
Wichtig
Aktivieren Sie keine TCP-Zeitstempel auf Azure-VMs, die sich hinter Azure Load Balancer befinden. Das Aktivieren von TCP-Zeitstempeln kann zu Fehlern bei Integritätstests führen. Setzen Sie den Parameter net.ipv4.tcp_timestamps auf 0. Weitere Informationen finden Sie unter Lastenausgleichs-Integritätstests.
[A] Hinzufügen der Firewallregel für den Testport:
sudo firewall-cmd --add-port=<probe-port>/tcp --permanent
sudo firewall-cmd --reload
Erstellen eines Pacemaker-Clusters
Informationen zum Erstellen eines grundlegenden Pacemaker-Clusters für diesen IBM Db2-Server finden Sie unter Einrichten von Pacemaker unter Red Hat Enterprise Linux in Azure.
Db2 Pacemaker-Konfiguration
Wenn Sie Pacemaker für automatisches Failover im Fall eines Knotenausfalls verwenden, müssen Sie Ihre Db2-Instanzen und Pacemaker entsprechend konfigurieren. In diesem Abschnitt werden die zugehörigen Konfigurationsschritte beschrieben.
Die folgenden Elemente haben eines der folgenden Präfixe:
- [A] : Gilt für alle Knoten
- [1] : Gilt nur für Knoten 1
- [2] : Gilt nur für Knoten 2
[A] Voraussetzung für die Pacemaker-Konfiguration:
Fahren Sie beide Datenbankserver mit Benutzer „db2<sid>“ mit „db2stop“ herunter.
Ändern Sie die Shellumgebung für „db2<sid> Benutzer“ in /bin/ksh:
# Install korn shell: sudo yum install ksh # Change users shell: sudo usermod -s /bin/ksh db2<sid>
Pacemaker-Konfiguration
[1] IBM Db2 HADR-spezifische Pacemaker-Konfiguration:
# Put Pacemaker into maintenance mode sudo pcs property set maintenance-mode=true[1] Erstellen Sie IBM Db2-Ressourcen:
Wenn Sie einen Cluster unter RHEL 7.x erstellen, müssen Sie die Paketressourcen-Agents auf die Version
resource-agents-4.1.1-61.el7_9.15oder höher aktualisieren. Verwenden Sie die folgenden Befehle, um die Clusterressourcen zu erstellen:# Replace bold strings with your instance name db2sid, database SID, and virtual IP address/Azure Load Balancer. sudo pcs resource create Db2_HADR_ID2 db2 instance='db2id2' dblist='ID2' master meta notify=true resource-stickiness=5000 #Configure resource stickiness and correct cluster notifications for master resoruce sudo pcs resource update Db2_HADR_ID2-master meta notify=true resource-stickiness=5000 # Configure virtual IP - same as Azure Load Balancer IP sudo pcs resource create vip_db2id2_ID2 IPaddr2 ip='10.100.0.40' # Configure probe port for Azure load Balancer sudo pcs resource create nc_db2id2_ID2 azure-lb port=62500 #Create a group for ip and Azure loadbalancer probe port sudo pcs resource group add g_ipnc_db2id2_ID2 vip_db2id2_ID2 nc_db2id2_ID2 #Create colocation constrain - keep Db2 HADR Master and Group on same node sudo pcs constraint colocation add g_ipnc_db2id2_ID2 with master Db2_HADR_ID2-master #Create start order constrain sudo pcs constraint order promote Db2_HADR_ID2-master then g_ipnc_db2id2_ID2Wenn Sie einen Cluster unter RHEL 8.x erstellen, müssen Sie die Paketressourcen-Agents auf die Version
resource-agents-4.1.1-93.el8oder höher aktualisieren. Ausführliche Informationen finden Sie unter Red Hat KBA im Artikel Adb2resource with HADR fails promote with statePRIMARY/REMOTE_CATCHUP_PENDING/CONNECTED. Verwenden Sie die folgenden Befehle, um die Clusterressourcen zu erstellen:# Replace bold strings with your instance name db2sid, database SID, and virtual IP address/Azure Load Balancer. sudo pcs resource create Db2_HADR_ID2 db2 instance='db2id2' dblist='ID2' promotable meta notify=true resource-stickiness=5000 #Configure resource stickiness and correct cluster notifications for master resoruce sudo pcs resource update Db2_HADR_ID2-clone meta notify=true resource-stickiness=5000 # Configure virtual IP - same as Azure Load Balancer IP sudo pcs resource create vip_db2id2_ID2 IPaddr2 ip='10.100.0.40' # Configure probe port for Azure load Balancer sudo pcs resource create nc_db2id2_ID2 azure-lb port=62500 #Create a group for ip and Azure loadbalancer probe port sudo pcs resource group add g_ipnc_db2id2_ID2 vip_db2id2_ID2 nc_db2id2_ID2 #Create colocation constrain - keep Db2 HADR Master and Group on same node sudo pcs constraint colocation add g_ipnc_db2id2_ID2 with master Db2_HADR_ID2-clone #Create start order constrain sudo pcs constraint order promote Db2_HADR_ID2-clone then g_ipnc_db2id2_ID2[1] Starten Sie IBM Db2-Ressourcen:
Nehmen Sie Pacemaker aus dem Wartungsmodus.
# Put Pacemaker out of maintenance-mode - that start IBM Db2 sudo pcs property set maintenance-mode=false[1] Stellen Sie sicher, dass der Clusterstatus „OK“ ist und alle Ressourcen gestartet sind. Es ist nicht wichtig, auf welchem Knoten die Ressourcen ausgeführt werden.
sudo pcs status 2 nodes configured 5 resources configured Online: [ az-idb01 az-idb02 ] Full list of resources: rsc_st_azure (stonith:fence_azure_arm): Started az-idb01 Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2] Masters: [ az-idb01 ] Slaves: [ az-idb02 ] Resource Group: g_ipnc_db2id2_ID2 vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb01 nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb01 Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
Wichtig
Sie müssen die geclusterte Db2-Instanz von Pacemaker mithilfe von Pacemaker-Tools verwalten. Wenn Sie db2-Befehle wie db2stop verwenden, erkennt Pacemaker die Aktion als Fehler der Ressource. Wenn Sie Wartungsarbeiten durchführen, können Sie die Knoten oder Ressourcen in den Wartungsmodus versetzen. Pacemaker hält die Überwachung von Ressourcen an, und anschließend können Sie normale db2-Verwaltungsbefehle verwenden.
Ändern des SAP-Profils, damit die virtuelle IP-Adresse für Verbindungen verwendet wird
Um Verbindungen mit der primären Instanz der HADR-Konfiguration herzustellen, muss die SAP-Anwendungsschicht die virtuelle IP-Adresse verwenden, die Sie für Azure Load Balancer definiert und konfiguriert haben. Die folgenden Änderungen sind erforderlich:
/sapmnt/<SID>/profile/DEFAULT.PFL
SAPDBHOST = db-virt-hostname
j2ee/dbhost = db-virt-hostname
/sapmnt/<SID>/global/db6/db2cli.ini
Hostname=db-virt-hostname
Installieren des primären und des Dialog Application-Servers
Wenn Sie den primären und den Dialog Application-Server für eine Db2 HADR-Konfiguration installieren, verwenden Sie den virtuellen Hostnamen, den Sie für die Konfiguration ausgewählt haben.
Wenn Sie die Installation vor der Erstellung der Db2 HADR-Konfiguration durchgeführt haben, nehmen Sie die Änderungen wie im vorherigen Abschnitt beschrieben und für SAP Java-Stapel wie folgt vor.
JDBC-URL-Prüfung für ABAP + Java- oder Java-Stapel-Systeme
Verwenden Sie das Konfigurationstool J2EE, um die JDBC-URL zu überprüfen oder zu aktualisieren. Da das Konfigurationstool J2EE ein grafisches Tool ist, muss ein X-Server installiert sein:
Melden Sie sich beim primären Anwendungsserver der J2EE-Instanz an, und führen Sie Folgendes aus:
sudo /usr/sap/*SID*/*Instance*/j2ee/configtool/configtool.shWählen Sie im linken Bereich die Option security store aus.
Wählen Sie im rechten Bereich den Schlüssel
jdbc/pool/\<SAPSID>/urlaus.Ändern Sie den Hostnamen in der JDBC-URL in den virtuellen Hostnamen.
jdbc:db2://db-virt-hostname:5912/TSP:deferPrepares=0Wählen Sie Hinzufügen.
Um die Änderungen zu speichern, klicken Sie auf das Datenträgersymbol in der oberen linken Ecke.
Schließen Sie das Konfigurationstool.
Starten Sie die Java-Instanz neu.
Konfigurieren von Protokollarchivierung für die HADR-Einrichtung
Um die Db2-Protokollarchivierung für die HADR-Einrichtung zu konfigurieren, empfiehlt es sich, dass Sie sowohl die primäre als auch die Standbydatenbank so konfigurieren, dass sie automatisch Protokolle aus allen Protokollspeicherorten abrufen können. Sowohl die primäre als auch die Standbydatenbank müssen in der Lage sein, Protokollarchivdateien aus allen Protokollarchivspeicherorten abrufen zu können, in denen eine der Datenbankinstanzen Protokolldateien archivieren könnte.
Die Protokollarchivierung wird nur von der primären Datenbank ausgeführt. Wenn Sie die HADR-Rollen der Datenbankserver ändern, oder wenn ein Fehler auftritt, ist die neue primäre Datenbank für die Protokollarchivierung verantwortlich. Wenn Sie mehrere Speicherorte für das Protokollarchiv eingerichtet haben, werden Ihre Protokolle möglicherweise zwei Mal archiviert. Im Falle eines lokalen oder Remoteabgleichs müssen Sie möglicherweise auch die archivierten Protokolle vom alten primären Server manuell in den aktiven Protokollspeicher des neuen primären Servers kopieren.
Es empfiehlt sich, eine allgemeine NFS-Freigabe oder ein GlusterFS zu konfigurieren, in die bzw. das Protokolle beider Knoten geschrieben werden. Die NFS-Freigabe oder das GlusterFS müssen hoch verfügbar sein.
Sie können vorhandene hoch verfügbare NFS-Freigaben oder GlusterFS für Datentransporte oder ein Profilverzeichnis verwenden. Weitere Informationen finden Sie unter
- GlusterFS auf Azure-VMs unter Red Hat Enterprise Linux für SAP NetWeaver
- Hochverfügbarkeit von SAP NetWeaver auf Azure-VMs unter Red Hat Enterprise Linux mit Azure NetApp Files für SAP-Anwendungen
- Azure NetApp Files (zum Erstellen von NFS-Freigaben)
Testen der Clustereinrichtung
In diesem Abschnitt ist beschrieben, wie Sie Ihre Db2 HADR-Einrichtung testen können. Bei jedem Test wird vorausgesetzt, dass die primäre IBM Db2-Einheit auf dem virtuellen Computer az-idb01 ausgeführt wird. Es muss ein Benutzer mit sudo-Berechtigungen oder root-Zugriff (nicht empfohlen) verwendet werden.
Hier ist der Anfangsstatus für alle Testfälle beschrieben: („crm_mon -r“ oder „pcs status“)
- pcs status ist eine Momentaufnahme des Pacemaker-Status zum Ausführungszeitpunkt.
- crm_mon -r ist eine kontinuierliche Ausgabe des Pacemaker-Status.
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb01
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb01 ]
Slaves: [ az-idb02 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb01
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb01
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
Der ursprüngliche Status in einem SAP-System ist in „Transaction DBACOCKPIT > Configuration > Overview“ dokumentiert, wie die folgende Abbildung zeigt:
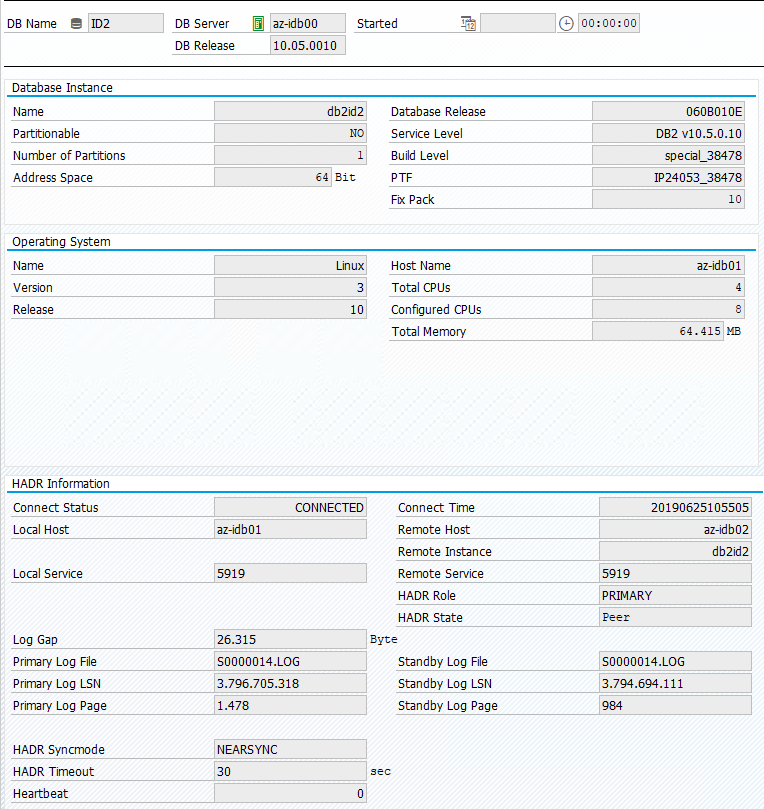
Testübernahme von IBM Db2
Wichtig
Bevor Sie den Test zu starten, stellen Sie Folgendes sicher:
Pacemaker keine fehlerhaften Aktionen (pcs status) aufweist.
Es gibt keine Ortseinschränkungen (Überbleibsel von Migrationstests).
Die IBM Db2-HADR-Synchronisierung funktioniert. Führen Sie die Überprüfung mit dem Benutzerkonto „db2<sid>“ durch.
db2pd -hadr -db <DBSID>
Migrieren Sie den Knoten, auf dem die primäre Db2-Datenbank ausgeführt wird, indem Sie folgenden Befehl ausführen:
# On RHEL 7.x
sudo pcs resource move Db2_HADR_ID2-master
# On RHEL 8.x
sudo pcs resource move Db2_HADR_ID2-clone --master
Nachdem die Migration abgeschlossen ist, sieht die Ausgabe von „crm status“ wie folgt aus:
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb01
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Stopped: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
Der ursprüngliche Status in einem SAP-System ist in „Transaction DBACOCKPIT > Configuration > Overview“ dokumentiert, wie die folgende Abbildung zeigt:
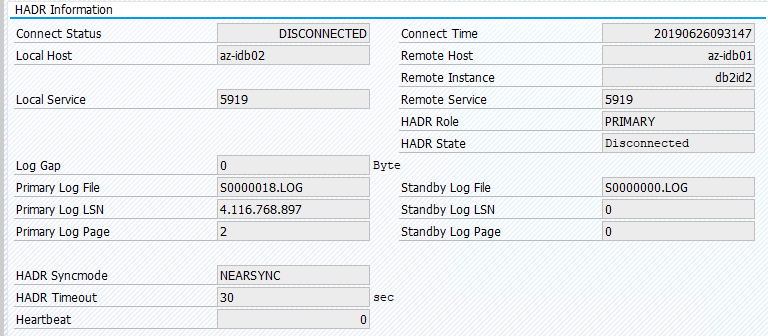
Die Ressourcenmigration mit „pcs resource move“ führt zu Ortseinschränkungen. Ortseinschränkungen führen in diesem Fall dazu, dass die Ausführung einer IBM Db2-Instanz auf az-idb01 verhindert wird. Wenn die Ortseinschränkungen nicht gelöscht werden, kann für die Ressource kein Fallback ausgeführt werden.
Entfernen Sie die Ortseinschränkung. Der Standbyknoten wird auf „az-idb01“ gestartet.
# On RHEL 7.x
sudo pcs resource clear Db2_HADR_ID2-master
# On RHEL 8.x
sudo pcs resource clear Db2_HADR_ID2-clone
Außerdem ändert sich der Clusterstatus in:
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb01
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Slaves: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
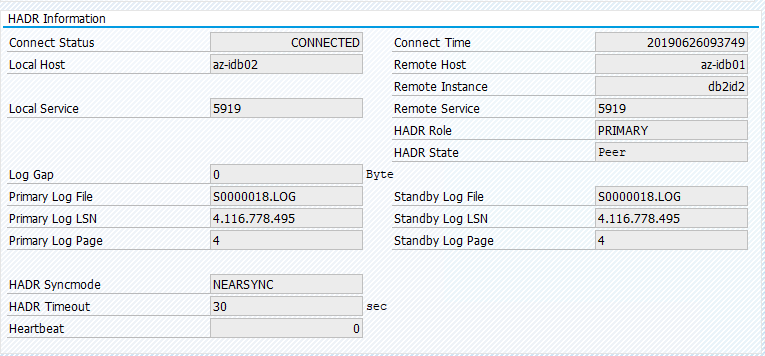
Migrieren Sie die Ressourcen zurück zu az-idb01, und löschen Sie die Ortseinschränkungen.
# On RHEL 7.x
sudo pcs resource move Db2_HADR_ID2-master az-idb01
sudo pcs resource clear Db2_HADR_ID2-master
# On RHEL 8.x
sudo pcs resource move Db2_HADR_ID2-clone --master
sudo pcs resource clear Db2_HADR_ID2-clone
- Unter RHEL 7.x:
pcs resource move <resource_name> <host>erstellt Ortseinschränkungen und kann Probleme bei Übernahmen verursachen. - Unter RHEL 8.x:
pcs resource move <resource_name> --mastererstellt Ortseinschränkungen und kann Probleme bei Übernahmen verursachen. pcs resource clear <resource_name>: löscht Ortseinschränkungen.pcs resource cleanup <resource_name>: löscht alle Fehler der Ressource.
Testen einer manuellen Übernahme
Sie können eine manuelle Übernahme testen, indem Sie den Pacemaker-Dienst auf dem Knoten az-idb01 beenden:
systemctl stop pacemaker
status on az-ibdb02
2 nodes configured
5 resources configured
Node az-idb01: pending
Online: [ az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Stopped: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
Nach dem Failover können Sie den Dienst auf az-idb01 wieder starten.
systemctl start pacemaker
Beenden des Db2-Prozesses auf dem Knoten, auf dem die primäre HADR-Datenbank ausgeführt wird
#Kill main db2 process - db2sysc
[sapadmin@az-idb02 ~]$ sudo ps -ef|grep db2sysc
db2ptr 34598 34596 8 14:21 ? 00:00:07 db2sysc 0
[sapadmin@az-idb02 ~]$ sudo kill -9 34598
Die Db2-Instanz fällt aus, und Pacemaker verschiebt den Masterknoten und meldet den folgenden Status:
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Stopped: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
Failed Actions:
* Db2_HADR_ID2_demote_0 on az-idb01 'unknown error' (1): call=49, status=complete, exitreason='none',
last-rc-change='Wed Jun 26 09:57:35 2019', queued=0ms, exec=362ms
Pacemaker startet die primäre Db2-Datenbankinstanz auf demselben Knoten neu oder führt ein Failover auf den Knoten aus, auf dem die sekundäre Datenbankinstanz ausgeführt wird. Danach wird ein Fehler gemeldet.
Beenden des Db2-Prozesses auf den Knoten, auf dem die sekundäre Datenbankinstanz ausgeführt wird
[sapadmin@az-idb02 ~]$ sudo ps -ef|grep db2sysc
db2id2 23144 23142 2 09:53 ? 00:00:13 db2sysc 0
[sapadmin@az-idb02 ~]$ sudo kill -9 23144
Der Knoten wird in den Status „Ausgefallen“ versetzt, und es wird ein Fehler gemeldet.
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb01 ]
Slaves: [ az-idb02 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb01
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb01
Failed Actions:
* Db2_HADR_ID2_monitor_20000 on az-idb02 'not running' (7): call=144, status=complete, exitreason='none',
last-rc-change='Wed Jun 26 10:02:09 2019', queued=0ms, exec=0ms
Die Db2-Instanz wird in der sekundären Rolle neu gestartet, die ihr zuvor zugewiesen war.
Beenden von Db2 durch „db2stop force“ auf dem Knoten, auf dem die primäre HADR-Datenbankinstanz ausgeführt wird
Führen Sie als Benutzer „db2<sid>“ den Befehl „db2stop force“ aus:
az-idb01:db2ptr> db2stop force
Fehler erkannt:
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Slaves: [ az-idb02 ]
Stopped: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Stopped
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Stopped
Failed Actions:
* Db2_HADR_ID2_demote_0 on az-idb01 'unknown error' (1): call=110, status=complete, exitreason='none',
last-rc-change='Wed Jun 26 14:03:12 2019', queued=0ms, exec=355ms
Die sekundäre Db2 HADR-Datenbankinstanz wurde auf die primäre Rolle hochgestuft.
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Slaves: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
Failed Actions:
* Db2_HADR_ID2_demote_0 on az-idb01 'unknown error' (1): call=110, status=complete, exitreason='none',
last-rc-change='Wed Jun 26 14:03:12 2019', queued=0ms, exec=355ms
Absturz des virtuellen Computers, auf dem die primäre HADR-Datenbankinstanz ausgeführt wird, mit „halt“
#Linux kernel panic.
sudo echo b > /proc/sysrq-trigger
In diesem Fall erkennt Pacemaker, dass der Knoten, auf dem die primäre Datenbankinstanz ausgeführt wird, nicht antwortet.
2 nodes configured
5 resources configured
Node az-idb01: UNCLEAN (online)
Online: [ az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb01 ]
Slaves: [ az-idb02 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb01
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb01
Der nächste Schritt besteht darin zu prüfen, ob eine Split Brain-Situation vorliegt. Sobald der weiterhin funktionsfähige Knoten ermittelt hat, dass der Knoten, auf dem die primäre Datenbankinstanz zuletzt ausgeführt wurde, nicht mehr verfügbar ist, wird ein Failover der Ressourcen ausgeführt.
2 nodes configured
5 resources configured
Online: [ az-idb02 ]
OFFLINE: [ az-idb01 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Stopped: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
Bei einem Kernel Panic-Status wird der ausgefallene Knoten vom Fencing-Agent neu gestartet. Wenn sich der ausgefallene Knoten wieder im Onlinezustand befindet, müssen Sie den Pacemaker-Cluster starten.
sudo pcs cluster start
Die Db2-Instanz wird für die sekundäre Rolle gestartet.
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Slaves: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02