Einrichten von Pacemaker unter Red Hat Enterprise Linux in Azure
In diesem Artikel wird beschrieben, wie Sie einen einfachen Pacemaker-Cluster unter Red Hat Enterprise Server (RHEL) konfigurieren. Die Anweisungen beziehen sich auf RHEL 7, RHEL 8 und RHEL 9.
Voraussetzungen
Lesen Sie zuerst die folgenden SAP-Hinweise und Artikel:
RHEL High Availability-Dokumentation
- Konfigurieren und Verwalten von Clustern mit Hochverfügbarkeit
- Unterstützungsrichtlinien für RHEL High Availability-Cluster – sbd und fence_sbd
- Unterstützungsrichtlinien für RHEL High Availability-Cluster – fence_azure_arm
- Durch Software emulierter Watchdog: Bekannte Einschränkungen
- Untersuchen der Komponenten von RHEL High Availability – sbd und fence_sbd
- Entwurfsleitfaden für RHEL High Availability-Cluster – Überlegungen zu sbd
- Überlegungen zur Einführung von RHEL 8 – Hochverfügbarkeit und Cluster
Azure-spezifische RHEL-Dokumentation
RHEL-Dokumentation für SAP-Angebote
- Unterstützungsrichtlinien für RHEL High Availability-Cluster – Verwalten von SAP S/4HANA in einem Cluster
- Konfigurieren von SAP S/4HANA ASCS/ERS mit Standalone Enqueue Server 2 (ENSA2) in Pacemaker
- Konfigurieren der SAP HANA-Systemreplikation im Pacemaker-Cluster
- Red Hat Enterprise Linux-HA-Lösung für horizontale SAP HANA-Skalierung und -Systemreplikation
Übersicht
Wichtig
Pacemaker-Cluster, die sich über mehrere virtuelle Netzwerke (VNets) bzw. Subnetze erstrecken, sind nicht durch Standardsupportrichtlinien abgedeckt.
Es gibt zwei Optionen in Azure zum Konfigurieren des Fencing in einem Pacemaker-Cluster für RHEL: den Azure-Fence-Agent, der einen Knoten über die Azure-APIs neu startet, bei dem ein Fehler aufgetreten ist, oder Sie können ein SBD-Gerät verwenden.
Wichtig
In Azure verwendet RHEL High Availability Cluster mit speicherbasiertem Fencing (fence_sbd) den durch Software emulierten Watchdog. Es ist wichtig, Durch Software emulierter Watchdog: Bekannte Einschränkungen und Unterstützungsrichtlinien für RHEL High Availability-Cluster – sbd und fence_sbd zu lesen, wenn Sie SBD als Fencingmechanismus auswählen.
Verwenden Sie ein SBD-Gerät
Hinweis
Der Fencingmechanismus mit SBD wird unter RHEL 8.8 und höher sowie RHEL 9.0 und höher unterstützt.
Sie können das SBD-Gerät mit einer der beiden folgenden Optionen konfigurieren:
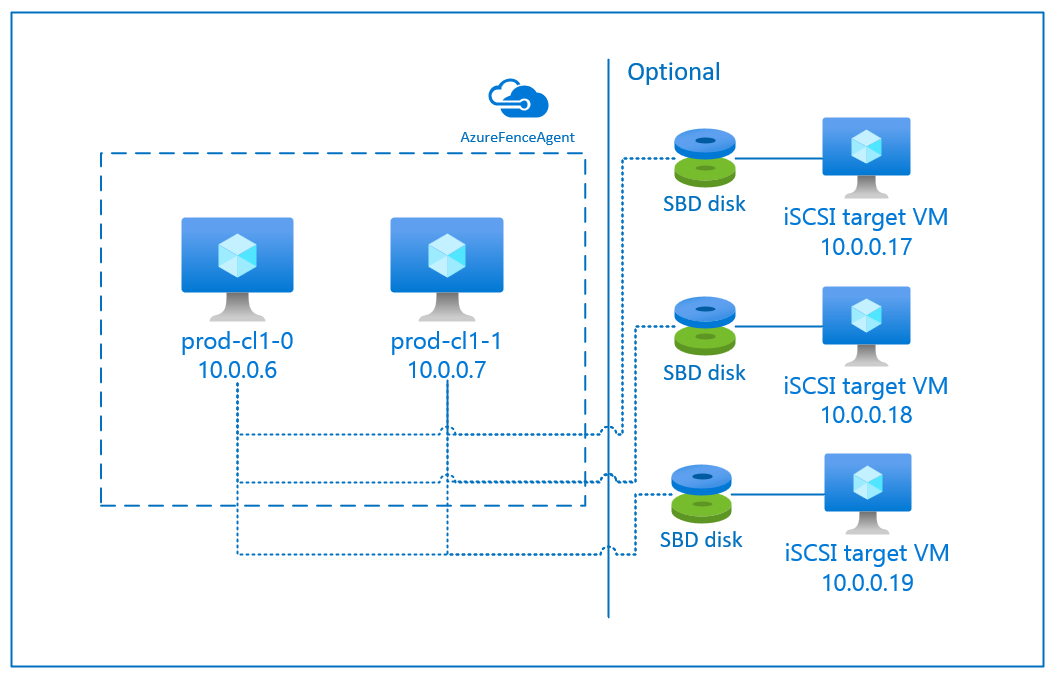
SBD mit einem iSCSI-Zielserver
Das SBD-Gerät erfordert mindestens eine zusätzliche virtuelle Maschine (VM), die als iSCSI-Zielserver (Internet Small Computer System Interface) fungiert und ein SBD-Gerät bereitstellt. Diese iSCSI-Zielserver können jedoch für andere Pacemaker-Cluster freigegeben werden. Die Verwendung eines SBD-Geräts hat den Vorteil, dass bei lokaler Verwendung von SBD-Geräten keine Änderungen am Betrieb des Pacemaker-Clusters erforderlich sind.
Sie können für einen Pacemaker-Cluster bis zu drei SBD-Geräte verwenden, um ein SBD-Gerät verfügbar zu machen, z. B. während des Betriebssystempatchings des iSCSI-Zielservers. Wenn Sie pro Pacemaker mehr als ein SBD-Gerät verwenden möchten, müssen Sie sicherstellen, dass mehrere iSCSI-Zielserver bereitgestellt werden und von jedem eine Verbindung mit einem SBD-Gerät hergestellt wird. Es wird empfohlen, entweder ein SBD-Gerät oder drei SBD-Geräte zu verwenden. Pacemaker kann einen Clusterknoten nicht automatisch umgrenzen, wenn nur zwei SBD-Geräte konfiguriert sind und eines davon nicht verfügbar ist. Wenn Sie in der Lage sein möchten, einen Clusterknoten bei einem inaktiven iSCSI-Zielserver zu umgrenzen, müssen Sie drei SBD-Geräte und folglich drei iSCSI-Zielserver verwenden. Das ist die resilienteste Konfiguration, wenn Sie SBDs verwenden.
Wichtig
Wenn Sie Linux-Pacemaker-Clusterknoten und SBD-Geräte bereitstellen und konfigurieren möchten, lassen Sie das Routing zwischen Ihren VMs und den VMs, auf denen die SBD-Geräte gehostet werden, nicht über andere Geräte laufen, wie z. B. ein virtuelles Netzwerkgerät (NVA).
Wartungsereignisse und andere Probleme mit dem NVA können sich negativ auf die Stabilität und Zuverlässigkeit der gesamten Clusterkonfiguration auswirken. Weitere Informationen finden Sie unter Benutzerdefinierte Routingregeln.
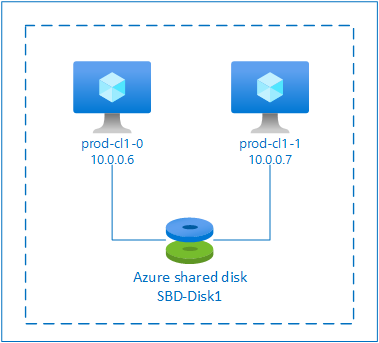
SBD mit einem freigegebenen Azure-Datenträger
Zum Konfigurieren eines SBD-Geräts muss mindestens ein freigegebener Azure-Datenträger an alle VMs angefügt werden, die Teil des Pacemaker-Clusters sind. Der Vorteil von SBD-Geräten mit freigegebenem Azure-Datenträger besteht darin, dass Sie keine zusätzlichen VMs bereitstellen und konfigurieren müssen.
Hier sind einige wichtige Überlegungen zu SBD-Geräten beim Konfigurieren mit einem freigegebenen Azure-Datenträger:
- Ein freigegebener Azure-Datenträger mit SSD Premium wird als SBD-Gerät unterstützt.
- SBD-Geräte, die einen freigegebenen Azure-Datenträger verwenden, werden unter RHEL 8.8 und höher unterstützt.
- SBD-Geräte mit freigegebenem Azure Premium-Datenträger werden auf lokal redundantem Speicher (LRS) und zonenredundantem Speicher (ZRS) unterstützt.
- Wählen Sie abhängig vom Typ Ihrer Bereitstellung den geeigneten redundanten Speicher für einen freigegebenen Azure-Datenträger als SBD-Gerät aus.
- Ein SBD-Gerät mit LRS für freigegebene Azure Premium-Datenträger (skuName: Premium_LRS) wird nur bei regionaler Bereitstellung in einer Verfügbarkeitsgruppe unterstützt.
- Ein SBD-Gerät mit ZRS für freigegebene Azure Premium-Datenträger (skuName: Premium_ZRS) wird für eine zonale Bereitstellung wie z. B. in Verfügbarkeitszonen oder Skalierungsgruppen mit FD=1 empfohlen.
- Ein ZRS für verwaltete Datenträger ist derzeit in den Regionen verfügbar, die im Dokument Regionale Verfügbarkeit aufgeführt sind.
- Der freigegebene Azure-Datenträger, den Sie für SBD-Geräte verwenden, muss nicht groß sein. Der Wert maxShares bestimmt, von wie vielen Clusterknoten der freigegebene Datenträger verwendet werden kann. In Clustern mit zwei Knoten wie SAP ASCS/ERS oder SAP-HANA-Hochskalierung können beispielsweise P1- oder P2-Datenträgergrößen für das SBD-Gerät verwendet werden.
- Für horizontale HANA-Skalierung mit HANA-Systemreplikation (HSR) und Pacemaker kann aufgrund des aktuellen Grenzwerts von maxShares ein freigegebener Azure-Datenträger für SBD-Geräte in Clustern mit bis zu fünf Knoten pro Replikationsstandort verwendet werden.
- Es wird nicht empfohlen, ein SBD-Gerät mit freigegebenem Azure-Datenträger an Pacemaker-Cluster anzufügen.
- Wenn Sie mehrere SBD-Geräte mit freigegebenem Azure-Datenträger verwenden, überprüfen Sie den Grenzwert für die maximale Anzahl von Datenträgern, die an eine VM angefügt werden können.
- Weitere Informationen zu Einschränkungen für freigegebene Azure-Datenträger finden Sie im Abschnitt "Einschränkungen" der Dokumentation zu freigegebenen Azure-Datenträgern.
Verwenden Sie einen Azure-Fence-Agent
Sie können Fencing mithilfe eines Azure-Fence-Agents einrichten. Der Azure-Fence-Agent erfordert verwaltete Identitäten für die Cluster-VMs, einen Dienstprinzipal oder eine verwaltete Systemidentität (MSI), mit denen der Neustart ausgefallener Knoten über Azure-APIs verwaltet wird. Der Azure-Fence-Agent erfordert keine Bereitstellung zusätzlicher VMs.
SBD mit einem iSCSI-Zielserver
Befolgen Sie die Anweisungen in den nächsten Abschnitten, um ein SBD-Gerät zu verwenden, das einen iSCSI-Zielserver für Fencing verwendet.
Einrichten des iSCSI-Zielservers
Sie müssen zunächst die virtuellen Computer für das iSCSI-Ziel erstellen. Sie können iSCSI-Zielserver für mehrere Pacemaker-Cluster freigeben.
Stellen Sie virtuelle Computer bereit, die auf der unterstützten RHEL-Betriebssystemversion ausgeführt werden, und stellen Sie eine Verbindung über SSH her. Die virtuellen Computer müssen nicht groß sein. VM-Größen wie Standard_E2s_v3 oder Standard_D2s_v3 sind ausreichend. Stellen Sie sicher, dass Sie für den Betriebssystemdatenträger Storage Premium verwenden.
Es ist nicht erforderlich, RHEL für SAP mit Hochverfügbarkeit und Update Services oder RHEL für ein Betriebssystemimage für SAP-Apps für den iSCSI-Zielserver zu verwenden. Stattdessen kann ein RHEL-Standard-Betriebssystemimage verwendet werden. Beachten Sie jedoch, dass der Unterstützungslebenszyklus zwischen verschiedenen Betriebssystem-Produktversionen variiert.
Führen Sie auf allen virtuellen iSCSI-Zielcomputern folgende Befehle aus.
Aktualisieren Sie RHEL.
sudo yum -y updateHinweis
Möglicherweise müssen Sie den Knoten nach einem Update oder Upgrade des Betriebssystems neu starten.
Installieren Sie das iSCSI-Zielpaket.
sudo yum install targetcliStarten und Konfigurieren des Ziels für den Beginn am Startzeitpunkt.
sudo systemctl start target sudo systemctl enable targetÖffnen von Port
3260in der Firewallsudo firewall-cmd --add-port=3260/tcp --permanent sudo firewall-cmd --add-port=3260/tcp
Erstellen Sie ein iSCSI-Gerät auf dem iSCSI-Zielserver
Führen Sie zum Erstellen der iSCSI-Datenträger für Ihre SAP-Systemcluster die folgenden Befehle auf jedem virtuellen iSCSI-Zielcomputer aus. Das Beispiel veranschaulicht die Erstellung von SBD-Geräten für mehrere Cluster mit einem einzelnen iSCSI-Zielservers für mehrere Cluster. Das SBD-Gerät ist auf dem Betriebssystemdatenträger konfiguriert. Stellen Sie daher sicher, dass genügend Speicherplatz vorhanden ist.
- ascsnw1: stellt den ASCS/ERS-Cluster von NW1 dar
- dbhn1: stellt den Datenbankcluster von HN1 dar
- sap-cl1 und sap-cl2: Hostnamen der NW1 ASCS/ERS-Clusterknoten
- hn1-db-0 und hn1-db-1: Hostnamen der Datenbankclusterknoten
Ändern Sie in den folgenden Anweisungen den Befehl bei Bedarf mit Ihren spezifischen Hostnamen und SIDs.
Erstellen Sie den Stammordner für alle SBD-Geräte.
sudo mkdir /sbdErstellen Sie das SBD-Gerät für die ASCS/ERS-Server des Systems NW1.
sudo targetcli backstores/fileio create sbdascsnw1 /sbd/sbdascsnw1 50M write_back=false sudo targetcli iscsi/ create iqn.2006-04.ascsnw1.local:ascsnw1 sudo targetcli iscsi/iqn.2006-04.ascsnw1.local:ascsnw1/tpg1/luns/ create /backstores/fileio/sbdascsnw1 sudo targetcli iscsi/iqn.2006-04.ascsnw1.local:ascsnw1/tpg1/acls/ create iqn.2006-04.sap-cl1.local:sap-cl1 sudo targetcli iscsi/iqn.2006-04.ascsnw1.local:ascsnw1/tpg1/acls/ create iqn.2006-04.sap-cl2.local:sap-cl2Erstellen Sie das SBD-Gerät für den Datenbankcluster des Systems HN1.
sudo targetcli backstores/fileio create sbddbhn1 /sbd/sbddbhn1 50M write_back=false sudo targetcli iscsi/ create iqn.2006-04.dbhn1.local:dbhn1 sudo targetcli iscsi/iqn.2006-04.dbhn1.local:dbhn1/tpg1/luns/ create /backstores/fileio/sbddbhn1 sudo targetcli iscsi/iqn.2006-04.dbhn1.local:dbhn1/tpg1/acls/ create iqn.2006-04.hn1-db-0.local:hn1-db-0 sudo targetcli iscsi/iqn.2006-04.dbhn1.local:dbhn1/tpg1/acls/ create iqn.2006-04.hn1-db-1.local:hn1-db-1Speichern Sie die targetcli-Konfiguration.
sudo targetcli saveconfigÜberprüfen Sie, ob alles korrekt eingerichtet wurde.
sudo targetcli ls o- / ......................................................................................................................... [...] o- backstores .............................................................................................................. [...] | o- block .................................................................................................. [Storage Objects: 0] | o- fileio ................................................................................................. [Storage Objects: 2] | | o- sbdascsnw1 ............................................................... [/sbd/sbdascsnw1 (50.0MiB) write-thru activated] | | | o- alua ................................................................................................... [ALUA Groups: 1] | | | o- default_tg_pt_gp ....................................................................... [ALUA state: Active/optimized] | | o- sbddbhn1 ................................................................... [/sbd/sbddbhn1 (50.0MiB) write-thru activated] | | o- alua ................................................................................................... [ALUA Groups: 1] | | o- default_tg_pt_gp ....................................................................... [ALUA state: Active/optimized] | o- pscsi .................................................................................................. [Storage Objects: 0] | o- ramdisk ................................................................................................ [Storage Objects: 0] o- iscsi ............................................................................................................ [Targets: 2] | o- iqn.2006-04.dbhn1.local:dbhn1 ..................................................................................... [TPGs: 1] | | o- tpg1 ............................................................................................... [no-gen-acls, no-auth] | | o- acls .......................................................................................................... [ACLs: 2] | | | o- iqn.2006-04.hn1-db-0.local:hn1-db-0 .................................................................. [Mapped LUNs: 1] | | | | o- mapped_lun0 ............................................................................... [lun0 fileio/sbdhdb (rw)] | | | o- iqn.2006-04.hn1-db-1.local:hn1-db-1 .................................................................. [Mapped LUNs: 1] | | | o- mapped_lun0 ............................................................................... [lun0 fileio/sbdhdb (rw)] | | o- luns .......................................................................................................... [LUNs: 1] | | | o- lun0 ............................................................. [fileio/sbddbhn1 (/sbd/sbddbhn1) (default_tg_pt_gp)] | | o- portals .................................................................................................... [Portals: 1] | | o- 0.0.0.0:3260 ..................................................................................................... [OK] | o- iqn.2006-04.ascsnw1.local:ascsnw1 ................................................................................. [TPGs: 1] | o- tpg1 ............................................................................................... [no-gen-acls, no-auth] | o- acls .......................................................................................................... [ACLs: 2] | | o- iqn.2006-04.sap-cl1.local:sap-cl1 .................................................................... [Mapped LUNs: 1] | | | o- mapped_lun0 ........................................................................... [lun0 fileio/sbdascsers (rw)] | | o- iqn.2006-04.sap-cl2.local:sap-cl2 .................................................................... [Mapped LUNs: 1] | | o- mapped_lun0 ........................................................................... [lun0 fileio/sbdascsers (rw)] | o- luns .......................................................................................................... [LUNs: 1] | | o- lun0 ......................................................... [fileio/sbdascsnw1 (/sbd/sbdascsnw1) (default_tg_pt_gp)] | o- portals .................................................................................................... [Portals: 1] | o- 0.0.0.0:3260 ..................................................................................................... [OK] o- loopback ......................................................................................................... [Targets: 0]
Richten Sie das SBD-Gerät mit iSCSI-Zielserver ein
[A]: Gilt für alle Knoten. [1]: Gilt nur für Knoten 1. [2]: Gilt nur für Knoten 2.
Verbinden Sie auf den Clusterknoten das iSCSI-Gerät, das im vorherigen Abschnitt erstellt wurde, und ermitteln Sie es. Führen Sie die folgenden Befehle für die zu erstellenden Knoten des neuen Clusters aus.
[A] Installieren oder Aktualisieren Sie iSCSI-Initiatoren auf allen Clusterknoten.
sudo yum install -y iscsi-initiator-utils[A] Installieren Sie Cluster- und SBD-Pakete auf allen Clusterknoten.
sudo yum install -y pcs pacemaker sbd fence-agents-sbd[A] Aktivieren Sie den iSCSI-Dienst.
sudo systemctl enable iscsid iscsi[1] Ändern Sie den Initiatornamen auf dem ersten Knoten des Clusters.
sudo vi /etc/iscsi/initiatorname.iscsi # Change the content of the file to match the access control ists (ACLs) you used when you created the iSCSI device on the iSCSI target server (for example, for the ASCS/ERS servers) InitiatorName=iqn.2006-04.sap-cl1.local:sap-cl1[2] Ändern Sie den Initiatornamen auf dem zweiten Knoten des Clusters.
sudo vi /etc/iscsi/initiatorname.iscsi # Change the content of the file to match the access control ists (ACLs) you used when you created the iSCSI device on the iSCSI target server (for example, for the ASCS/ERS servers) InitiatorName=iqn.2006-04.sap-cl2.local:sap-cl2[A] Starten Sie den iSCSI-Dienst neu, um die Änderung zu übernehmen.
sudo systemctl restart iscsid sudo systemctl restart iscsi[A] Stellen Sie eine Verbindung mit den iSCSI-Geräten her. Im folgenden Beispiel ist 10.0.0.17 die IP-Adresse des iSCSI-Zielservers und 3260 der Standardport. Der Zielname
iqn.2006-04.ascsnw1.local:ascsnw1wird beim Ausführen des ersten Befehlsiscsiadm -m discoveryaufgelistet.sudo iscsiadm -m discovery --type=st --portal=10.0.0.17:3260 sudo iscsiadm -m node -T iqn.2006-04.ascsnw1.local:ascsnw1 --login --portal=10.0.0.17:3260 sudo iscsiadm -m node -p 10.0.0.17:3260 -T iqn.2006-04.ascsnw1.local:ascsnw1 --op=update --name=node.startup --value=automatic[A] Wenn Sie mehrere SBD-Geräte verwenden, stellen Sie auch eine Verbindung mit dem zweiten iSCSI-Zielserver her.
sudo iscsiadm -m discovery --type=st --portal=10.0.0.18:3260 sudo iscsiadm -m node -T iqn.2006-04.ascsnw1.local:ascsnw1 --login --portal=10.0.0.18:3260 sudo iscsiadm -m node -p 10.0.0.18:3260 -T iqn.2006-04.ascsnw1.local:ascsnw1 --op=update --name=node.startup --value=automatic[A] Wenn Sie mehrere SBD-Geräte verwenden, stellen Sie auch eine Verbindung mit dem dritten iSCSI-Zielserver her.
sudo iscsiadm -m discovery --type=st --portal=10.0.0.19:3260 sudo iscsiadm -m node -T iqn.2006-04.ascsnw1.local:ascsnw1 --login --portal=10.0.0.19:3260 sudo iscsiadm -m node -p 10.0.0.19:3260 -T iqn.2006-04.ascsnw1.local:ascsnw1 --op=update --name=node.startup --value=automatic[A] Stellen Sie sicher, dass die iSCSI-Geräte verfügbar sind, und notieren Sie sich den Gerätenamen. Im folgenden Beispiel werden drei iSCSI-Geräte ermittelt, indem der Knoten mit drei iSCSI-Zielservern verbunden wird.
lsscsi [0:0:0:0] disk Msft Virtual Disk 1.0 /dev/sde [1:0:0:0] disk Msft Virtual Disk 1.0 /dev/sda [1:0:0:1] disk Msft Virtual Disk 1.0 /dev/sdb [1:0:0:2] disk Msft Virtual Disk 1.0 /dev/sdc [1:0:0:3] disk Msft Virtual Disk 1.0 /dev/sdd [2:0:0:0] disk LIO-ORG sbdascsnw1 4.0 /dev/sdf [3:0:0:0] disk LIO-ORG sbdascsnw1 4.0 /dev/sdh [4:0:0:0] disk LIO-ORG sbdascsnw1 4.0 /dev/sdg[A] Rufen Sie die IDs der iSCSI-Geräte ab.
ls -l /dev/disk/by-id/scsi-* | grep -i sdf # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-1LIO-ORG_sbdhdb:85d254ed-78e2-4ec4-8b0d-ecac2843e086 -> ../../sdf # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2 -> ../../sdf # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-SLIO-ORG_sbdhdb_85d254ed-78e2-4ec4-8b0d-ecac2843e086 -> ../../sdf ls -l /dev/disk/by-id/scsi-* | grep -i sdh # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-1LIO-ORG_sbdhdb:87122bfc-8a0b-4006-b538-d0a6d6821f04 -> ../../sdh # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d -> ../../sdh # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-SLIO-ORG_sbdhdb_87122bfc-8a0b-4006-b538-d0a6d6821f04 -> ../../sdh ls -l /dev/disk/by-id/scsi-* | grep -i sdg # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-1LIO-ORG_sbdhdb:d2ddc548-060c-49e7-bb79-2bb653f0f34a -> ../../sdg # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65 -> ../../sdg # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-SLIO-ORG_sbdhdb_d2ddc548-060c-49e7-bb79-2bb653f0f34a -> ../../sdgMit dem Befehl werden für jedes SBD-Gerät drei Geräte-IDs aufgelistet. Es wird empfohlen, die ID zu verwenden, die mit scsi-3 beginnt. Im vorherigen Beispiel lauten die IDs:
- /dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2
- /dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d
- /dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65
[1] Erstellen Sie das SBD-Gerät.
Verwenden Sie die Geräte-ID der iSCSI-Geräte, um die neuen SBD-Geräte auf dem ersten Clusterknoten zu erstellen.
sudo sbd -d /dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2 -1 60 -4 120 createErstellen Sie auch das zweite und dritte SBD-Gerät, wenn Sie mehr als eins verwenden möchten.
sudo sbd -d /dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d -1 60 -4 120 create sudo sbd -d /dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65 -1 60 -4 120 create
[A] Passen Sie die SDB-Konfiguration an.
Öffnen Sie die SBD-Konfigurationsdatei.
sudo vi /etc/sysconfig/sbdÄndern Sie die Eigenschaft des SBD-Geräts, aktivieren Sie die Pacemaker-Integration, und ändern Sie den Startmodus von SBD.
[...] SBD_DEVICE="/dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2;/dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d;/dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65" [...] SBD_PACEMAKER=yes [...] SBD_STARTMODE=always [...] SBD_DELAY_START=yes [...]
[A] Führen Sie den folgenden Befehl aus, um das Modul
softdogzu laden.modprobe softdog[A] Führen Sie den folgenden Befehl aus, um sicherzustellen, dass
softdognach einem Knotenneustart automatisch geladen wird.echo softdog > /etc/modules-load.d/watchdog.conf systemctl restart systemd-modules-load[A] Der SBD-Diensttimeoutwert ist standardmäßig auf 90 s festgelegt. Wenn der
SBD_DELAY_START-Wert jedoch aufyesfestgelegt ist, verzögert der SBD-Dienst den Start bis nach demmsgwait-Timeout. Daher sollte der Wert des SBD-Diensttimeouts dasmsgwait-Timeout überschreiten, wennSBD_DELAY_STARTaktiviert ist.sudo mkdir /etc/systemd/system/sbd.service.d echo -e "[Service]\nTimeoutSec=144" | sudo tee /etc/systemd/system/sbd.service.d/sbd_delay_start.conf sudo systemctl daemon-reload systemctl show sbd | grep -i timeout # TimeoutStartUSec=2min 24s # TimeoutStopUSec=2min 24s
SBD mit einem freigegebenen Azure-Datenträger
Dieser Abschnitt gilt nur, wenn Sie ein SBD-Gerät mit einem freigegebenen Azure-Datenträger verwenden möchten.
Konfigurieren eines freigegebenen Azure-Datenträgers mit PowerShell
Führen Sie die folgende Anweisung aus, um einen freigegebenen Azure-Datenträger mit PowerShell zu erstellen und anzufügen. Wenn Sie Ressourcen mithilfe der Azure CLI oder des Azure-Portal bereitstellen möchten, finden Sie unter Bereitstellen eines ZRS-Datenträgers weitere Informationen.
$ResourceGroup = "MyResourceGroup"
$Location = "MyAzureRegion"
$DiskSizeInGB = 4
$DiskName = "SBD-disk1"
$ShareNodes = 2
$LRSSkuName = "Premium_LRS"
$ZRSSkuName = "Premium_ZRS"
$vmNames = @("prod-cl1-0", "prod-cl1-1") # VMs to attach the disk
# ZRS Azure shared disk: Configure an Azure shared disk with ZRS for a premium shared disk
$zrsDiskConfig = New-AzDiskConfig -Location $Location -SkuName $ZRSSkuName -CreateOption Empty -DiskSizeGB $DiskSizeInGB -MaxSharesCount $ShareNodes
$zrsDataDisk = New-AzDisk -ResourceGroupName $ResourceGroup -DiskName $DiskName -Disk $zrsDiskConfig
# Attach ZRS disk to cluster VMs
foreach ($vmName in $vmNames) {
$vm = Get-AzVM -ResourceGroupName $resourceGroup -Name $vmName
Add-AzVMDataDisk -VM $vm -Name $diskName -CreateOption Attach -ManagedDiskId $zrsDataDisk.Id -Lun 0
Update-AzVM -VM $vm -ResourceGroupName $resourceGroup -Verbose
}
# LRS Azure shared disk: Configure an Azure shared disk with LRS for a premium shared disk
$lrsDiskConfig = New-AzDiskConfig -Location $Location -SkuName $LRSSkuName -CreateOption Empty -DiskSizeGB $DiskSizeInGB -MaxSharesCount $ShareNodes
$lrsDataDisk = New-AzDisk -ResourceGroupName $ResourceGroup -DiskName $DiskName -Disk $lrsDiskConfig
# Attach LRS disk to cluster VMs
foreach ($vmName in $vmNames) {
$vm = Get-AzVM -ResourceGroupName $resourceGroup -Name $vmName
Add-AzVMDataDisk -VM $vm -Name $diskName -CreateOption Attach -ManagedDiskId $lrsDataDisk.Id -Lun 0
Update-AzVM -VM $vm -ResourceGroupName $resourceGroup -Verbose
}
Richten Sie ein SBD-Gerät mit freigegebenem Azure-Datenträger ein
[A] Installieren Sie Cluster- und SBD-Pakete auf allen Clusterknoten.
sudo yum install -y pcs pacemaker sbd fence-agents-sbd[A] Vergewissern Sie sich, dass der angefügte Datenträger verfügbar ist.
lsblk # NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT # sda 8:0 0 4G 0 disk # sdb 8:16 0 64G 0 disk # ├─sdb1 8:17 0 500M 0 part /boot # ├─sdb2 8:18 0 63G 0 part # │ ├─rootvg-tmplv 253:0 0 2G 0 lvm /tmp # │ ├─rootvg-usrlv 253:1 0 10G 0 lvm /usr # │ ├─rootvg-homelv 253:2 0 1G 0 lvm /home # │ ├─rootvg-varlv 253:3 0 8G 0 lvm /var # │ └─rootvg-rootlv 253:4 0 2G 0 lvm / # ├─sdb14 8:30 0 4M 0 part # └─sdb15 8:31 0 495M 0 part /boot/efi # sr0 11:0 1 1024M 0 rom lsscsi # [0:0:0:0] disk Msft Virtual Disk 1.0 /dev/sdb # [0:0:0:2] cd/dvd Msft Virtual DVD-ROM 1.0 /dev/sr0 # [1:0:0:0] disk Msft Virtual Disk 1.0 /dev/sda # [1:0:0:1] disk Msft Virtual Disk 1.0 /dev/sdc[A] Rufen Sie die Geräte-ID des angefügten freigegebenen Datenträgers ab.
ls -l /dev/disk/by-id/scsi-* | grep -i sda # lrwxrwxrwx 1 root root 9 Jul 15 22:24 /dev/disk/by-id/scsi-14d534654202020200792c2f5cc7ef14b8a7355cb3cef0107 -> ../../sda # lrwxrwxrwx 1 root root 9 Jul 15 22:24 /dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107 -> ../../sdaDies ist die Geräte-ID in der Befehlsliste für den angefügten freigegebenen Datenträger. Es wird empfohlen, die ID zu verwenden, die mit scsi-3 beginnt. In diesem Beispiel lautet die ID /dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107.
[1] Erstellen Sie das SBD-Gerät.
# Use the device ID from step 3 to create the new SBD device on the first cluster node sudo sbd -d /dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107 -1 60 -4 120 create[A] Passen Sie die SDB-Konfiguration an.
Öffnen Sie die SBD-Konfigurationsdatei.
sudo vi /etc/sysconfig/sbdÄndern Sie die Eigenschaft des SBD-Geräts, aktivieren Sie die Pacemaker-Integration, und ändern Sie den Startmodus von SBD.
[...] SBD_DEVICE="/dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107" [...] SBD_PACEMAKER=yes [...] SBD_STARTMODE=always [...] SBD_DELAY_START=yes [...]
[A] Führen Sie den folgenden Befehl aus, um das Modul
softdogzu laden.modprobe softdog[A] Führen Sie den folgenden Befehl aus, um sicherzustellen, dass
softdognach einem Knotenneustart automatisch geladen wird.echo softdog > /etc/modules-load.d/watchdog.conf systemctl restart systemd-modules-load[A] Der SBD-Diensttimeoutwert ist standardmäßig auf 90 s festgelegt. Wenn der
SBD_DELAY_START-Wert jedoch aufyesfestgelegt ist, verzögert der SBD-Dienst den Start bis nach demmsgwait-Timeout. Daher sollte der Wert des SBD-Diensttimeouts dasmsgwait-Timeout überschreiten, wennSBD_DELAY_STARTaktiviert ist.sudo mkdir /etc/systemd/system/sbd.service.d echo -e "[Service]\nTimeoutSec=144" | sudo tee /etc/systemd/system/sbd.service.d/sbd_delay_start.conf sudo systemctl daemon-reload systemctl show sbd | grep -i timeout # TimeoutStartUSec=2min 24s # TimeoutStopUSec=2min 24s
Konfiguration des Azure-Fence-Agents
Das Fencinggerät verwendet entweder eine verwaltete Identität für Azure-Ressourcen oder einen Dienstprinzipal zur Autorisierung für Azure. Je nach Identitätsverwaltungsmethode folgen Sie den entsprechenden Verfahren:
Konfigurieren der Identitätsverwaltung
Verwenden Sie eine verwaltete Identität oder einen Dienstprinzipal.
Zum Erstellen einer verwalteten Identität (MSI) erstellen Sie eine systemseitig zugewiesene verwaltete Identität für jeden virtuellen Computer im Cluster. Sollte bereits eine systemseitig zugewiesene verwaltete Identität vorhanden sein, wird diese verwendet. Verwenden Sie vorerst keine benutzerseitig zugewiesenen verwalteten Identitäten mit Pacemaker. Ein auf einer verwalteten Identität basierendes Fencinggerät wird unter RHEL 7.9 und RHEL 8.x/RHEL 9.x unterstützt.
Erstellen einer benutzerdefinierten Rolle für den Fence-Agent
Weder die verwaltete Identität noch der Dienstprinzipal verfügt standardmäßig über Zugriffsberechtigungen für Ihre Azure-Ressourcen. Sie müssen der verwalteten Identität oder dem Dienstprinzipal Berechtigungen zum Starten und Beenden (Ausschalten) aller VMs im Cluster erteilen. Wenn Sie die benutzerdefinierte Rolle noch nicht erstellt haben, können Sie sie mithilfe von PowerShell oder mithilfe der Azure CLI erstellen.
Verwenden Sie folgenden Inhalt für die Eingabedatei. Sie müssen den Inhalt an Ihre Abonnements anpassen. Ersetzen Sie also
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxundyyyyyyyy-yyyy-yyyy-yyyy-yyyyyyyyyyyydurch die IDs Ihres Abonnements. Wenn Sie nur über ein einzelnes Abonnement verfügen, entfernen Sie den zweiten Eintrag inAssignableScopes.{ "Name": "Linux Fence Agent Role", "description": "Allows to power-off and start virtual machines", "assignableScopes": [ "/subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "/subscriptions/yyyyyyyy-yyyy-yyyy-yyyy-yyyyyyyyyyyy" ], "actions": [ "Microsoft.Compute/*/read", "Microsoft.Compute/virtualMachines/powerOff/action", "Microsoft.Compute/virtualMachines/start/action" ], "notActions": [], "dataActions": [], "notDataActions": [] }Zuweisen der benutzerdefinierten Rolle
Verwenden Sie eine verwaltete Identität oder einen Dienstprinzipal.
Weisen Sie die benutzerdefinierte Rolle
Linux Fence Agent Role, die im letzten Abschnitt erstellt wurde, jeder verwalteten Identität der Cluster-VMs zu. Jeder systemseitig zugewiesenen verwalteten Identität muss die Rolle für jede Cluster-VM-Ressource zugewiesen werden. Weitere Informationen finden Sie unter Zuweisen des Zugriffs einer verwalteten Identität auf eine Ressource über das Azure-Portal. Vergewissern Sie sich, dass die Rollenzuweisung der verwalteten Identitäten der einzelnen VMs alle Cluster-VMs enthält.Wichtig
Beachten Sie, dass sich die Zuweisung und Aufhebung der Autorisierung mit verwalteten Identitäten bis zum Inkrafttreten verzögern kann.
Clusterinstallation
Befehls- oder Konfigurationsunterschiede zwischen RHEL 7 und RHEL 8 bzw. RHEL 9 sind im Dokument markiert.
[A] Installieren Sie das RHEL-Hochverfügbarkeits-Add-On.
sudo yum install -y pcs pacemaker nmap-ncat[A] Installieren Sie unter RHEL 9.x die Ressourcen-Agents für die Cloudbereitstellung.
sudo yum install -y resource-agents-cloud[A] Installieren Sie das Paket fence-agents, wenn Sie ein Fencinggerät verwenden, das auf dem Azure-Fence-Agent basiert.
sudo yum install -y fence-agents-azure-armWichtig
Es wird empfohlen, mindestens die folgenden Versionen des Azure-Fence-Agents für Kunden zu verwenden, die verwaltete Identitäten für Azure-Ressourcen anstelle von Dienstprinzipalnamen für den Fence-Agent verwenden möchten.
- RHEL 8.4: fence-agents-4.2.1-54.el8.
- RHEL 8.2: fence-agents-4.2.1-41.el8_2.4
- RHEL 8.1: fence-agents-4.2.1-30.el8_1.4
- RHEL 7.9: fence-agents-4.2.1-41.el7_9.4.
Wichtig
Unter RHEL 9 sollten mindestens die folgenden Paketversionen verwendet werden, um Probleme mit dem Azure-Fence-Agent zu vermeiden:
- fence-agents-4.10.0-20.el9_0.7
- fence-agents-common-4.10.0-20.el9_0.6
- ha-cloud-support-4.10.0-20.el9_0.6.x86_64.rpm
Überprüfen Sie die Version des Azure Fence-Agent. Führen Sie bei Bedarf eine Aktualisierung auf die erforderliche Mindestversion oder auf eine höhere Version durch.
# Check the version of the Azure Fence Agent sudo yum info fence-agents-azure-armWichtig
Wenn Sie den Azure-Fence-Agent aktualisieren müssen und eine benutzerdefinierte Rolle verwenden, müssen Sie die benutzerdefinierte Rolle so aktualisieren, dass sie die Aktion powerOff beinhaltet. Weitere Informationen finden Sie unter Erstellen einer benutzerdefinierten Rolle für den Fence-Agent.
[A] Einrichten der Auflösung des Hostnamens.
Sie können entweder einen DNS-Server verwenden oder die Datei
/etc/hostsauf allen Knoten ändern. In diesem Beispiel wird die Verwendung der Datei/etc/hostsgezeigt. Ersetzen Sie die IP-Adresse und den Hostnamen in den folgenden Befehlen.Wichtig
Wenn Sie Hostnamen in der Clusterkonfiguration verwenden, ist eine zuverlässige Hostnamenauflösung unerlässlich. Die Clusterkommunikation ist nicht erfolgreich, wenn die Namen nicht verfügbar sind. Dies kann zu Verzögerungen bei Clusterfailovern führen.
Durch die Verwendung von
/etc/hostswird Ihr Cluster vom DNS (einem weiteren möglichen Single Point of Failure) unabhängig.sudo vi /etc/hostsFügen Sie in
/etc/hostsdie folgenden Zeilen ein. Ändern Sie die IP-Adresse und den Hostnamen Ihrer Umgebung entsprechend.# IP address of the first cluster node 10.0.0.6 prod-cl1-0 # IP address of the second cluster node 10.0.0.7 prod-cl1-1[A] Ändern Sie das
hacluster-Kennwort in das gleiche Kennwort.sudo passwd hacluster[A] Fügen Sie Firewallregeln für Pacemaker hinzu.
Fügen Sie jeglicher Clusterkommunikation zwischen den Clusterknoten die folgenden Firewallregeln hinzu.
sudo firewall-cmd --add-service=high-availability --permanent sudo firewall-cmd --add-service=high-availability[A] Aktivieren Sie grundlegende Clusterdienste.
Führen Sie die folgenden Befehle aus, um den Pacemaker-Dienst zu aktivieren und zu starten.
sudo systemctl start pcsd.service sudo systemctl enable pcsd.service[1] Erstellen Sie einen Pacemaker-Cluster.
Führen Sie die folgenden Befehle aus, um die Knoten zu authentifizieren und den Cluster zu erstellen. Legen Sie das Token auf „30.000“ fest, um die Wartung mit Speicherbeibehaltung zu ermöglichen. Weitere Informationen finden Sie in diesem Artikel für Linux.
Wenn Sie einen Cluster auf RHEL 7.x aufbauen, verwenden Sie die folgenden Befehle:
sudo pcs cluster auth prod-cl1-0 prod-cl1-1 -u hacluster sudo pcs cluster setup --name nw1-azr prod-cl1-0 prod-cl1-1 --token 30000 sudo pcs cluster start --allWenn Sie einen Cluster unter RHEL 8.x/RHEL 9.x erstellen, verwenden Sie die folgenden Befehle:
sudo pcs host auth prod-cl1-0 prod-cl1-1 -u hacluster sudo pcs cluster setup nw1-azr prod-cl1-0 prod-cl1-1 totem token=30000 sudo pcs cluster start --allÜberprüfen Sie den Clusterstatus, indem Sie den folgenden Befehl ausführen:
# Run the following command until the status of both nodes is online sudo pcs status # Cluster name: nw1-azr # WARNING: no stonith devices and stonith-enabled is not false # Stack: corosync # Current DC: prod-cl1-1 (version 1.1.18-11.el7_5.3-2b07d5c5a9) - partition with quorum # Last updated: Fri Aug 17 09:18:24 2018 # Last change: Fri Aug 17 09:17:46 2018 by hacluster via crmd on prod-cl1-1 # # 2 nodes configured # 0 resources configured # # Online: [ prod-cl1-0 prod-cl1-1 ] # # No resources # # Daemon Status: # corosync: active/disabled # pacemaker: active/disabled # pcsd: active/enabled[A] Legen Sie die erwarteten Stimmen fest.
# Check the quorum votes pcs quorum status # If the quorum votes are not set to 2, execute the next command sudo pcs quorum expected-votes 2Tipp
Wenn Sie einen Cluster mit mehreren Knoten (also einen Cluster mit mehr als zwei Knoten) erstellen, legen Sie die Stimmen nicht auf „2“ fest.
[1] Lassen Sie gleichzeitige Fence-Aktionen zu.
sudo pcs property set concurrent-fencing=true
Erstellen eines Fencinggeräts im Pacemaker-Cluster
Tipp
- Um Fence Races innerhalb eines Pacemaker-Clusters mit zwei Knoten zu vermeiden, können Sie die Clustereigenschaft
priority-fencing-delaykonfigurieren. Diese Eigenschaft führt zu einer zusätzlichen Verzögerung beim Einfassen eines Knotens mit einer höheren Gesamtressourcenpriorität, wenn ein Split-Brain-Szenario auftritt. Weitere Informationen finden Sie unter Kann Pacemaker den Clusterknoten mit den wenigsten ausgeführten Ressourcen einfassen?. - Die Eigenschaft
priority-fencing-delaygilt ab der Pacemaker-Version 2.0.4-6.el8 und in einem Cluster mit zwei Knoten. Wenn Sie die Clustereigenschaftpriority-fencing-delaykonfigurieren, müssen Sie die Eigenschaftpcmk_delay_maxnicht festlegen. Wenn die Pacemaker-Version allerdings niedriger als 2.0.4-6.el8 ist, muss die Eigenschaftpcmk_delay_maxfestgelegt werden. - Eine Anleitung zum Festlegen der Clustereigenschaft
priority-fencing-delayfinden Sie in den entsprechenden SAP ASCS/ERS- und SAP HANA-Hochverfügbarkeitsdokumenten für die Hochskalierung.
Befolgen Sie basierend auf dem ausgewählten Fencingmechanismus nur einen Abschnitt für relevante Anweisungen: SBD als Fencinggerät oder Azure-Fence-Agent als Fencinggerät.
SBD als Fencinggerät
[A] Aktivieren Sie den SBD-Dienst.
sudo systemctl enable sbd[1] Führen Sie die folgenden Befehle aus, wenn das konfigurierte SBD-Gerät iSCSI-Zielserver oder einen freigegebenen Azure-Datenträger verwendet.
sudo pcs property set stonith-timeout=144 sudo pcs property set stonith-enabled=true # Replace the device IDs with your device ID. pcs stonith create sbd fence_sbd \ devices=/dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2,/dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d,/dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65 \ op monitor interval=600 timeout=15[1] Starten Sie den Cluster neu.
sudo pcs cluster stop --all # It would take time to start the cluster as "SBD_DELAY_START" is set to "yes" sudo pcs cluster start --allHinweis
Wenn beim Starten des Pacemaker-Clusters folgender Fehler auftritt, können Sie die Meldung ignorieren. Alternativ können Sie den Cluster mit dem Befehl
pcs cluster start --all --request-timeout 140starten.Fehler: Alle Knoten node1/node2 können nicht gestartet werden: Es kann keine Verbindung mit node1/node2 hergestellt werden, überprüfen Sie, ob pcsd dort ausgeführt wird, oder versuchen Sie, ein höheres Timeout mit
--request-timeout-Option festzulegen (Timeout nach 60.000 Millisekunden mit 0 empfangenen Bytes)
Azure-Fence-Agent als Fencinggerät
[1] Nachdem Sie beiden Clusterknoten Rollen zugewiesen haben, können Sie die Fencinggeräte im Cluster konfigurieren.
sudo pcs property set stonith-timeout=900 sudo pcs property set stonith-enabled=true[1] Führen Sie je nachdem, ob Sie eine verwaltete Identität oder einen Dienstprinzipal für den Azure-Fence-Agent verwenden, den entsprechenden Befehl aus.
Hinweis
Wenn Sie die Azure Government-Cloud verwenden, müssen Sie beim Konfigurieren des Fence-Agents die Option
cloud=angeben. Für die Azure-Cloud „US Government“ ist dies z. B.cloud=usgov. Ausführliche Informationen zum Red Hat-Support in der Azure Government-Cloud finden Sie unter Unterstützungsrichtlinien für RHEL-Hochverfügbarkeitscluster: Microsoft Azure Virtual Machines als Clustermitglieder.Tipp
Die Option
pcmk_host_mapwird im Befehl nur benötigt, wenn die RHEL-Hostnamen und die Namen der Azure-VMs nicht identisch sind. Geben Sie die Zuordnung im Format hostname:vm-name an. Weitere Informationen finden Sie unter Welches Format sollte ich verwenden, um Knotenzuordnungen für Fencinggeräte in „pcmk_host_map“ anzugeben?.Verwenden Sie für RHEL 7.xden folgenden Befehl, um das Fencinggerät zu konfigurieren:
sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \ subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \ power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 pcmk_delay_max=15 \ op monitor interval=3600Verwenden Sie für RHEL 8.x/9.x den folgenden Befehl, um das Fencinggerät zu konfigurieren:
# Run following command if you are setting up fence agent on (two-node cluster and pacemaker version greater than 2.0.4-6.el8) OR (HANA scale out) sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \ subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \ power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 \ op monitor interval=3600 # Run following command if you are setting up fence agent on (two-node cluster and pacemaker version less than 2.0.4-6.el8) sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \ subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \ power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 pcmk_delay_max=15 \ op monitor interval=3600
Wenn Sie ein Fencinggerät basierend auf einer Dienstprinzipalkonfiguration verwenden, lesen Sie Wechseln von SPN zu MSI für Pacemaker-Cluster mit Azure-Fencing, um zu erfahren, wie Sie zu einer Konfiguration mit verwalteter Identität konvertieren.
Die Überwachungs- und Fencingvorgänge sind deserialisiert. Das bedeutet: Wenn ein länger andauernder Überwachungsvorgang und ein gleichzeitiges Fencingereignis vorliegen, kommt es zu keiner Verzögerung beim Clusterfailover, da der Überwachungsvorgang bereits ausgeführt wird.
Tipp
Der Azure-Fence-Agent benötigt ausgehende Konnektivität mit öffentlichen Endpunkten. Weitere Informationen sowie mögliche Lösungen finden Sie unter Konnektivität öffentlicher Endpunkte für VMs, die Azure Load Balancer Standard in SAP-Hochverfügbarkeitsszenarien verwenden.
Konfigurieren Sie Pacemaker für geplante Azure-Ereignisse
Azure verfügt über geplante Ereignisse. Geplante Ereignisse werden über den Metadatendienst gesendet und ermöglichen es der Anwendung, sich auf solche Ereignisse vorzubereiten.
Der Pacemaker-Ressourcen-Agent azure-events-az wird zur Überwachung auf geplante Azure-Ereignisse verwendet. Wenn Ereignisse erkannt werden und der Ressourcenagent feststellt, dass ein anderer Clusterknoten verfügbar ist, wird ein Clusterintegritätsattribut festgelegt.
Wenn das Clusterintegritätsattribut für einen Knoten festgelegt wird, wird die Standorteinschränkung ausgelöst, und alle Ressourcen, deren Name nicht mit health- beginnt, werden mit dem geplanten Ereignis vom Knoten weg migriert. Sobald der betroffene Clusterknoten frei von ausgeführten Clusterressourcen ist, wird das geplante Ereignis bestätigt und kann seine Aktion (beispielsweise einen Neustart) ausführen.
[A] Stellen Sie sicher, dass das Paket für den
azure-events-az-Agent bereits installiert und auf dem neuesten Stand ist.RHEL 8.x: sudo dnf info resource-agents RHEL 9.x: sudo dnf info resource-agents-cloudMindestversionsanforderungen:
- RHEL 8.4:
resource-agents-4.1.1-90.13 - RHEL 8.6:
resource-agents-4.9.0-16.9 - RHEL 8.8:
resource-agents-4.9.0-40.1 - RHEL 9.0:
resource-agents-cloud-4.10.0-9.6 - Ab RHEL 9.2:
resource-agents-cloud-4.10.0-34.1
- RHEL 8.4:
[1] Konfigurieren Sie die Ressourcen in Pacemaker.
#Place the cluster in maintenance mode sudo pcs property set maintenance-mode=true[1] Legen Sie die Strategie und Einschränkung für den Pacemaker-Clusterintegritätsknoten fest.
sudo pcs property set node-health-strategy=custom sudo pcs constraint location 'regexp%!health-.*' \ rule score-attribute='#health-azure' \ defined '#uname'Wichtig
Definieren Sie keine anderen, mit
health-beginnenden Ressourcen im Cluster (außer denjenigen, die in den nächsten Schritten beschrieben werden).[1] Legen Sie den Anfangswert der Clusterattribute fest. Führen Sie diesen Schritt für jeden Clusterknoten und für Umgebungen mit horizontaler Skalierung aus (einschließlich der Majority Maker-VM).
sudo crm_attribute --node prod-cl1-0 --name '#health-azure' --update 0 sudo crm_attribute --node prod-cl1-1 --name '#health-azure' --update 0[1] Konfigurieren Sie die Ressourcen in Pacemaker. Achten Sie darauf, dass die Ressourcen mit
health-azurebeginnen.sudo pcs resource create health-azure-events \ ocf:heartbeat:azure-events-az \ op monitor interval=10s timeout=240s \ op start timeout=10s start-delay=90s sudo pcs resource clone health-azure-events allow-unhealthy-nodes=true failure-timeout=120sBeenden Sie den Wartungsmodus für den Pacemaker-Cluster.
sudo pcs property set maintenance-mode=falseBeseitigen Sie alle Fehler während der Aktivierung, und vergewissern Sie sich, dass die
health-azure-events-Ressourcen erfolgreich auf allen Clusterknoten gestartet wurden.sudo pcs resource cleanupDie erste Abfrageausführung für geplante Ereignisse kann bis zu zwei Minuten dauern. Pacemaker-Tests mit geplanten Ereignissen können Aktionen für Neustart oder erneutes Bereitstellen für die Cluster-VMs verwenden. Weitere Informationen finden Sie unter Geplante Ereignisse.
Optionale Fencingkonfiguration
Tipp
Dieser Abschnitt ist nur relevant, wenn Sie das spezielle Fencinggerät fence_kdump konfigurieren möchten.
Wenn Diagnoseinformationen innerhalb der VM gesammelt werden müssen, kann es hilfreich sein, ein weiteres Fencinggerät basierend auf dem Fence-Agent fence_kdump zu konfigurieren. Der fence_kdump-Agent kann erkennen, ob ein Knoten in die kdump-Absturzwiederherstellung eingetreten ist, und den Abschluss des Absturzwiederherstellungsdiensts ermöglichen, bevor andere Fencingmethoden aufgerufen werden. Beachten Sie, dass fence_kdump kein Ersatz für herkömmliche Fencingmechanismen ist, beispielsweise für SBD oder den Azure-Fence-Agent bei Verwendung von Azure-VMs.
Wichtig
Wenn fence_kdump als Fencinggerät der ersten Ebene konfiguriert ist, führt dies zu Verzögerungen bei den Fencingvorgängen bzw. zu Verzögerungen beim Failover der Anwendungsressourcen.
Bei erfolgreicher Erkennung eines Absturzabbilds wird das Fencing verzögert, bis der Absturzwiederherstellungsdienst ausgeführt wurde. Wenn der fehlerhafte Knoten nicht erreichbar ist oder nicht antwortet, wird das Fencing auf der Grundlage der ermittelten Zeit, der konfigurierten Anzahl von Iterationen und des fence_kdump-Timeouts verzögert. Weitere Informationen finden Sie unter Konfigurieren von „fence_kdump“ in einem Red Hat-Pacemaker-Cluster.
Das vorgeschlagene fence_kdump-Timeout muss möglicherweise an die jeweilige Umgebung angepasst werden.
Es wird empfohlen, das fence_kdump-Fencing nur dann zu konfigurieren, wenn es zur Erfassung von Diagnoseinformationen innerhalb der VM erforderlich ist, und immer nur in Kombination mit herkömmlichen Fencingmethoden wie SBD oder dem Azure-Fence-Agent.
Die folgenden Red Hat-KB-Artikel enthalten wichtige Informationen zum Konfigurieren des fence_kdump-Fencings:
- Konfigurieren von „fence_kdump“ in einem Red Hat-Pacemaker-Cluster
- Konfigurieren/Verwalten von Fencingebenen im RHEL-Cluster mit Pacemaker
- fence_kdump-Fehler „Timeout nach X Sekunden“ in einem RHEL 6- oder RHEL 7-Hochverfügbarkeitscluster mit „kexec-tools“ vor Version 2.0.14
- Informationen zum Ändern des Standardtimeouts finden Sie unter Konfigurieren von „kdump“ zur Verwendung mit dem Hochverfügbarkeits-Add-On für RHEL 6, 7, 8.
- Informationen zum Verringern der Failoververzögerung bei Verwendung von
fence_kdumpfinden Sie unter Kann ich beim Hinzufügen der fence_kdump-Konfiguration die erwartete Failoververzögerung verringern?.
Führen Sie die folgenden optionalen Schritte aus, um fence_kdump zusätzlich zur Azure-Fence-Agent-Konfiguration als Fencingkonfiguration der ersten Ebene hinzuzufügen.
[A] Vergewissern Sie sich, dass
kdumpaktiv ist und konfiguriert wurde.systemctl is-active kdump # Expected result # active[A] Installieren Sie den Fence-Agent
fence_kdump.yum install fence-agents-kdump[1] Erstellen Sie ein Fencinggerät vom Typ
fence_kdumpim Cluster.pcs stonith create rsc_st_kdump fence_kdump pcmk_reboot_action="off" pcmk_host_list="prod-cl1-0 prod-cl1-1" timeout=30[1] Konfigurieren Sie Fencingebenen so, dass der Fencingmechanismus
fence_kdumpzuerst aktiviert wird.pcs stonith create rsc_st_kdump fence_kdump pcmk_reboot_action="off" pcmk_host_list="prod-cl1-0 prod-cl1-1" pcs stonith level add 1 prod-cl1-0 rsc_st_kdump pcs stonith level add 1 prod-cl1-1 rsc_st_kdump # Replace <stonith-resource-name> to the resource name of the STONITH resource configured in your pacemaker cluster (example based on above configuration - sbd or rsc_st_azure) pcs stonith level add 2 prod-cl1-0 <stonith-resource-name> pcs stonith level add 2 prod-cl1-1 <stonith-resource-name> # Check the fencing level configuration pcs stonith level # Example output # Target: prod-cl1-0 # Level 1 - rsc_st_kdump # Level 2 - <stonith-resource-name> # Target: prod-cl1-1 # Level 1 - rsc_st_kdump # Level 2 - <stonith-resource-name>[A] Lassen Sie die erforderlichen Ports für
fence_kdumpin der Firewall zu.firewall-cmd --add-port=7410/udp firewall-cmd --add-port=7410/udp --permanent[A] Führen Sie die
fence_kdump_nodes-Konfiguration in/etc/kdump.confdurch, umfence_kdump-Timeoutfehler für einige Versionen vonkexec-toolszu vermeiden. Weitere Informationen finden Sie unter fence_kdump-Timeout, wenn „fence_kdump_nodes“ nicht mit kexec-tools, Version 2.0.15 oder höher angegeben wird sowie unter fence_kdump-Fehler „Timeout nach X Sekunden“ in einem RHEL 6- oder RHEL 7-Hochverfügbarkeitscluster mit „kexec-tools“ vor Version 2.0.14. Hier wird die Beispielkonfiguration für einen Cluster mit zwei Knoten gezeigt. Nachdem Sie eine Änderung in/etc/kdump.confvorgenommen haben, muss das kdump-Image neu generiert werden. Starten Sie dazu denkdump-Dienst neu.vi /etc/kdump.conf # On node prod-cl1-0 make sure the following line is added fence_kdump_nodes prod-cl1-1 # On node prod-cl1-1 make sure the following line is added fence_kdump_nodes prod-cl1-0 # Restart the service on each node systemctl restart kdump[A] Stellen Sie sicher, dass die
initramfs-Imagedatei die Dateienfence_kdumpundhostsenthält. Weitere Informationen finden Sie unter Konfigurieren von „fence_kdump“ in einem Red Hat-Pacemaker-Cluster.lsinitrd /boot/initramfs-$(uname -r)kdump.img | egrep "fence|hosts" # Example output # -rw-r--r-- 1 root root 208 Jun 7 21:42 etc/hosts # -rwxr-xr-x 1 root root 15560 Jun 17 14:59 usr/libexec/fence_kdump_sendTesten Sie die Konfiguration, indem Sie einen Knoten zum Absturz bringen. Weitere Informationen finden Sie unter Konfigurieren von „fence_kdump“ in einem Red Hat-Pacemaker-Cluster.
Wichtig
Wenn der Cluster bereits in der Produktion genutzt wird, planen Sie den Test entsprechend, da ein Absturz eines Knotens Auswirkungen auf die Anwendung hat.
echo c > /proc/sysrq-trigger
Nächste Schritte
- Siehe Azure Virtual Machines – Planung und Implementierung für SAP.
- Siehe Bereitstellung von Azure Virtual Machines für SAP.
- Siehe Azure Virtual Machines – DBMS-Bereitstellung für SAP.
- Wie Sie Hochverfügbarkeit einrichten und eine Notfallwiederherstellung von SAP HANA auf Azure-VMs planen, erfahren Sie unter Hochverfügbarkeit von SAP HANA auf virtuellen Azure-Computern.