Instance Metadata Service: Scheduled Events für Linux-VMs
Gilt für: ✔️ Linux-VMs ✔️ Flexible Skalierungsgruppen ✔️ Einheitliche Skalierungsgruppen
Scheduled Events ist ein Azure-Metadatendienst, der Ihren Anwendungen Zeit zur Vorbereitung auf die Wartung virtueller Computer gibt. Er stellt Informationen zu geplanten Wartungsereignissen (z.B. Neustart) bereit, damit Ihre Anwendung sich darauf vorbereiten und Unterbrechungen begrenzen kann. Der Dienst steht für alle Azure-VM-Typen zur Verfügung, einschließlich PaaS und IaaS unter Windows und Linux.
Informationen zu geplanten Ereignissen unter Windows finden Sie unter Geplante Ereignisse für virtuelle Windows-Computer.
Geplante Ereignisse bieten proaktive Benachrichtigungen zu bevorstehenden Ereignissen. Reaktive Informationen zu Ereignissen, die bereits stattgefunden haben, finden Sie unter VM-Verfügbarkeitsinformationen in Azure Resource Graph und Erstellen einer Verfügbarkeitsbenachrichtigungsregel für die virtuellen Azure-VM.
Hinweis
Scheduled Events ist in allen Azure-Regionen allgemein verfügbar. Informationen zu aktuellen Releases finden Sie unter Version und regionale Verfügbarkeit.
Was spricht für die Verwendung geplanter Ereignisse?
Viele Anwendungen können von der Vorbereitungszeit auf die VM-Wartung profitieren. Die Zeit kann genutzt werden, um anwendungsspezifische Aufgaben durchzuführen, die die Verfügbarkeit, Zuverlässigkeit und Wartungsfreundlichkeit verbessern. Dazu gehören u.a.:
- Prüfpunkt und Wiederherstellung
- Verbindungsausgleich
- Failover des primären Replikats
- Entfernung aus einem Lastenausgleichspool
- Ereignisprotokollierung
- Ordnungsgemäßes Herunterfahren
Mit dem Feature für geplante Ereignisse kann Ihre Anwendung erkennen, wann eine Wartung erfolgt, und so Aufgaben auslösen, um die Auswirkungen abzumildern.
Geplante Ereignisse umfasst Ereignisse in den folgenden Anwendungsfällen:
- Von der Plattform ausgelöste Wartung (z. B. VM-Neustart, Livemigration oder Updates für den Host mit Speicherbeibehaltung).
- Die VM wird auf heruntergestufter Hosthardware ausgeführt, deren baldiger Ausfall erwartet wird.
- Die VM wurde auf einem Host ausgeführt, bei dem ein Hardwarefehler aufgetreten ist.
- Vom Benutzer eingeleitete Wartung (z. B. Neustart oder erneute Bereitstellung einer VM durch den Benutzer).
- Instanzentfernungen von Spot-VM und Spot-Skalierungsgruppen
Die Grundlagen
Der Metadatendienst macht Informationen zu ausgeführten virtuellen Computern mithilfe eines innerhalb einer VM zugänglichen REST-Endpunkts verfügbar. Die Informationen stehen über eine nicht routingfähige IP-Adresse bereit und werden außerhalb der VM nicht verfügbar gemacht.
Bereich
Geplante Ereignisse werden einem der folgenden Empfänger zugestellt und können von diesem bestätigt werden:
- Eigenständige virtuelle Computer
- Alle VMs in einem Azure-Clouddienst (klassisch).
- Alle VMs in einer Verfügbarkeitsgruppe
- Alle VMs in einer Gruppe für die Skalierungsgruppenplatzierung
Geplante Ereignisse für alle virtuellen Computer (VMs) in einem gesamten Verfügbarkeitssatz oder einer Platzierungsgruppe für einen Skalierungssatz für virtuelle Computer werden unabhängig von der Verfügbarkeitszone-Nutzung festgelegt oder an alle anderen virtuellen Computer in derselben Gruppe übermittelt.
Überprüfen Sie deshalb anhand des Felds Resources in einem Ereignis, welche VMs betroffen sein werden.
Hinweis
VMs mit GPU-Beschleunigung in einer Skalierungsgruppe mit einer Fehlerdomäne (FD = 1) erhalten nur geplante Ereignisse für die betroffene Ressource. Die Ereignisse werden nicht an alle VMs in derselben Platzierungsgruppe übertragen.
Endpunktermittlung
Für virtuelle Computer in VNETs ist der Metadatendienst über eine statische, nicht routingfähige IP-Adresse (169.254.169.254) verfügbar. Der vollständige Endpunkt für die neueste Version von Scheduled Events ist wie folgt:
http://169.254.169.254/metadata/scheduledevents?api-version=2020-07-01
Wenn die VM nicht in einem virtuellen Netzwerk erstellt wird (Standard für Clouddienste und klassische VMs), ist zusätzliche Logik erforderlich, um die zu verwendende IP-Adresse zu ermitteln. In diesem Beispiel erfahren Sie, wie Sie den Hostendpunkt ermitteln.
Version und regionale Verfügbarkeit
Das Feature für geplante Ereignisse ist versionsspezifisch. Die Versionen sind obligatorisch. Die aktuelle Version ist 2020-07-01.
| Version | Releasetyp | Regions | Versionsinformationen |
|---|---|---|---|
| 2020-07-01 | Allgemeine Verfügbarkeit | All | |
| 2019-08-01 | Allgemeine Verfügbarkeit | All | |
| 01.04.2019 | Allgemeine Verfügbarkeit | All | |
| 2019-01-01 | Allgemeine Verfügbarkeit | All | |
| 2017-11-01 | Allgemeine Verfügbarkeit | All | |
| 2017-08-01 | Allgemeine Verfügbarkeit | All | |
| 2017-03-01 | Vorschau | All |
Hinweis
In früheren Vorschauversionen von geplanten Ereignissen wird {latest} als „api-version“ unterstützt. Dieses Format wird nicht mehr unterstützt und wird zukünftig veraltet sein.
Aktivieren und Deaktivieren von Scheduled Events
Scheduled Events wird für Ihren Dienst aktiviert, wenn Sie zum ersten Mal Ereignisse anfordern. Beim ersten Aufruf müssen Sie bei der Antwort mit einer Verzögerung von bis zu zwei Minuten rechnen, und erhalten innerhalb von fünf Minuten erste Ereignisse. Scheduled Events wird für Ihren Dienst deaktiviert, wenn 24 Stunden lang keine Anforderung an den Endpunkt gesendet wird.
Vom Benutzer ausgelöste Wartung
Eine vom Benutzer über das Azure-Portal, die API, die CLI oder PowerShell initiierte Wartung eines virtuellen Computers führt zu einem geplanten Ereignis. Sie können anschließend die Logik zur Vorbereitung auf Wartungsmaßnahmen in Ihrer Anwendung testen und Ihre Anwendung auf die vom Benutzer initiierte Wartung vorbereiten.
Wenn Sie eine VM neu starten, wird ein Ereignis vom Typ Reboot geplant. Wenn Sie eine VM neu bereitstellen, wird ein Ereignis vom Typ Redeploy geplant. In der Regel können Ereignisse mit einer Benutzerereignisquelle sofort genehmigt werden, um eine Verzögerung bei vom Benutzer eingeleiteten Aktionen zu vermeiden. Wir empfehlen, eine primäre und eine sekundäre VM zu verwenden, die miteinander kommunizieren und vom Benutzer generierte geplante Ereignisse genehmigen, falls die primäre VM nicht mehr reagiert. Das sofortige Genehmigen von Ereignissen verhindert Verzögerungen bei der Wiederherstellung eines fehlerfreien Zustands Ihrer Anwendung.
Geplante Ereignisse für Gastbetriebssystem-Upgrades oder -Reimagings für VM-Skalierungsgruppen werden für universelle VM-Größen unterstützt, die nur speichererhaltende Updates unterstützen. Ausnahmen sind lediglich die G-, M-, N- und H-Serie. Geplante Ereignisse sind für Gastbetriebssystem-Upgrades oder -Reimagings für VM-Skalierungsgruppen standardmäßig deaktiviert. Um geplante Ereignisse für diese Vorgänge für unterstütze VM-Größen zu aktivieren, führen Sie zunächst eine Aktivierung über das OSImageNotificationProfile durch.
Verwenden der API
Allgemeine Übersicht
Es gibt zwei Hauptkomponenten zur Behandlung von Scheduled Events: Vorbereitung und Wiederherstellung. Alle aktuellen geplanten Ereignisse, die sich auf einen virtuellen Computer auswirken, stehen zum Lesen über den Endpunkt für geplante IMDS-Ereignisse zur Verfügung. Wenn das Ereignis einen Endzustand erreicht hat, wird es aus der Liste der Ereignisse entfernt. Das folgende Diagramm zeigt die verschiedenen Statusübergänge, die bei einem einzelnen geplanten Ereignis auftreten können:
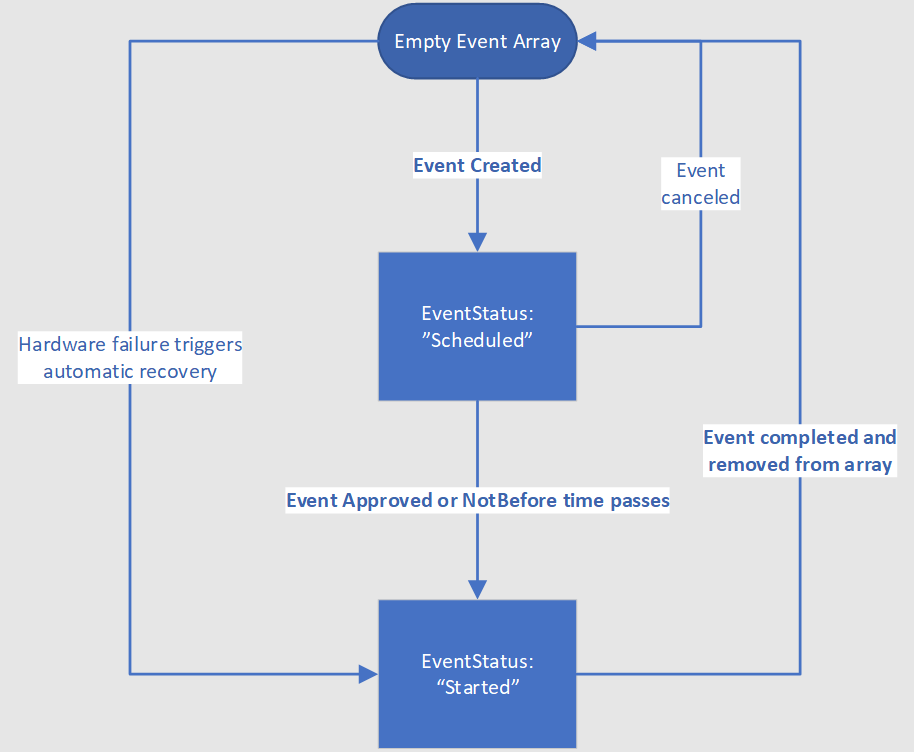
Für Ereignisse im Status EventStatus: „Geplant“ müssen Sie Schritte zur Vorbereitung Ihres Workload ausführen. Sobald die Vorbereitung abgeschlossen ist, sollten Sie das Ereignis mithilfe der Scheduled Events-API genehmigen. Andernfalls wird das Ereignis automatisch genehmigt, wenn der „NotBefore“-Zeitpunkt erreicht wird. Wenn sich der virtuelle Computer in einer freigegebenen Infrastruktur befindet, wartet das System darauf, dass alle anderen Mandanten auf derselben Hardware den Auftrag oder das Timeout ebenfalls genehmigen. Sobald Genehmigungen von allen betroffenen VMs gesammelt worden sind, oder die „NotBefore“-Zeit erreicht worden ist, generiert Azure einen neuen geplante Ereignispayload mit dem Status EventStatus:„Started“ und löst das Wartungsereignis aus. Wenn das Ereignis einen Endzustand erreicht hat, wird es aus der Liste der Ereignisse entfernt. Dies dient als Signal für den Kunden, seine VMs wiederherzustellen.
Im Folgenden finden Sie Pseudocode, der einen Prozess zum Lesen und Verwalten geplanter Ereignisse in Ihrer Anwendung veranschaulicht:
current_list_of_scheduled_events = get_latest_from_se_endpoint()
#prepare for new events
for each event in current_list_of_scheduled_events:
if event not in previous_list_of_scheduled_events:
prepare_for_event(event)
#recover from completed events
for each event in previous_list_of_scheduled_events:
if event not in current_list_of_scheduled_events:
receover_from_event(event)
#prepare for future jobs
previous_list_of_scheduled_events = current_list_of_scheduled_events
Da geplante Ereignisse häufig für Anwendungen verwendet werden, für die Hochverfügbarkeit erforderlich ist, sollten einige Ausnahmefälle berücksichtigt werden:
- Sobald ein geplantes Ereignis abgeschlossen und aus dem Array entfernt wurde, gibt es ohne ein neues Ereignis (einschließlich eines weiteren EventStatus:“Scheduled“-Ereignisses) keine weiteren Auswirkungen.
- Azure überwacht Wartungsvorgänge in der gesamten Flotte und stellt in seltenen Fällen fest, dass ein Wartungsvorgang zu riskant ist, um angewendet zu werden. In diesem Fall wird das geplante Ereignis mit dem Status „Geplant“ direkt aus dem Ereignisarray entfernt.
- Im Falle eines Hardwarefehlers umgeht Azure den Status „Geplant“ und wechselt sofort in den Status „EventStatus:"Started"“.
- Während sich das Ereignis noch im Status „EventStatus:"Started"“ befindet, kann es zusätzliche Auswirkungen mit einer kürzeren Dauer geben als im geplanten Ereignis angekündigt wurde.
Im Rahmen der Verfügbarkeitsgarantie von Azure sind VMs in verschiedenen Fehlerdomänen nicht gleichzeitig von routinemäßigen Wartungsvorgängen betroffen. Es kann jedoch vorkommen, dass Vorgänge nacheinander serialisiert wurden. VMs in einer Fehlerdomäne können geplante Ereignisse mit EventStatus:„Scheduled“ empfangen, kurz nachdem die Wartung einer anderen Fehlerdomäne abgeschlossen ist. Unabhängig davon, welche Architektur Sie gewählt haben, sollten Sie stets überprüfen, ob neue Ereignisse für Ihre VMs ausstehen.
Obwohl die genauen Zeitpunkte von Ereignissen variieren, bietet das folgende Diagramm einen groben Leitfaden für den Verlauf eines typischen Wartungsvorgangs:
- EventStatus:„Scheduled“ bis Genehmigungstimeout: 15 Minuten
- Auswirkungsdauer: 7 Sekunden
- EventStatus:”Started“ bis zum Abschluss (das Ereignis wird aus dem Ereignisarray entfernt): 10 Minuten
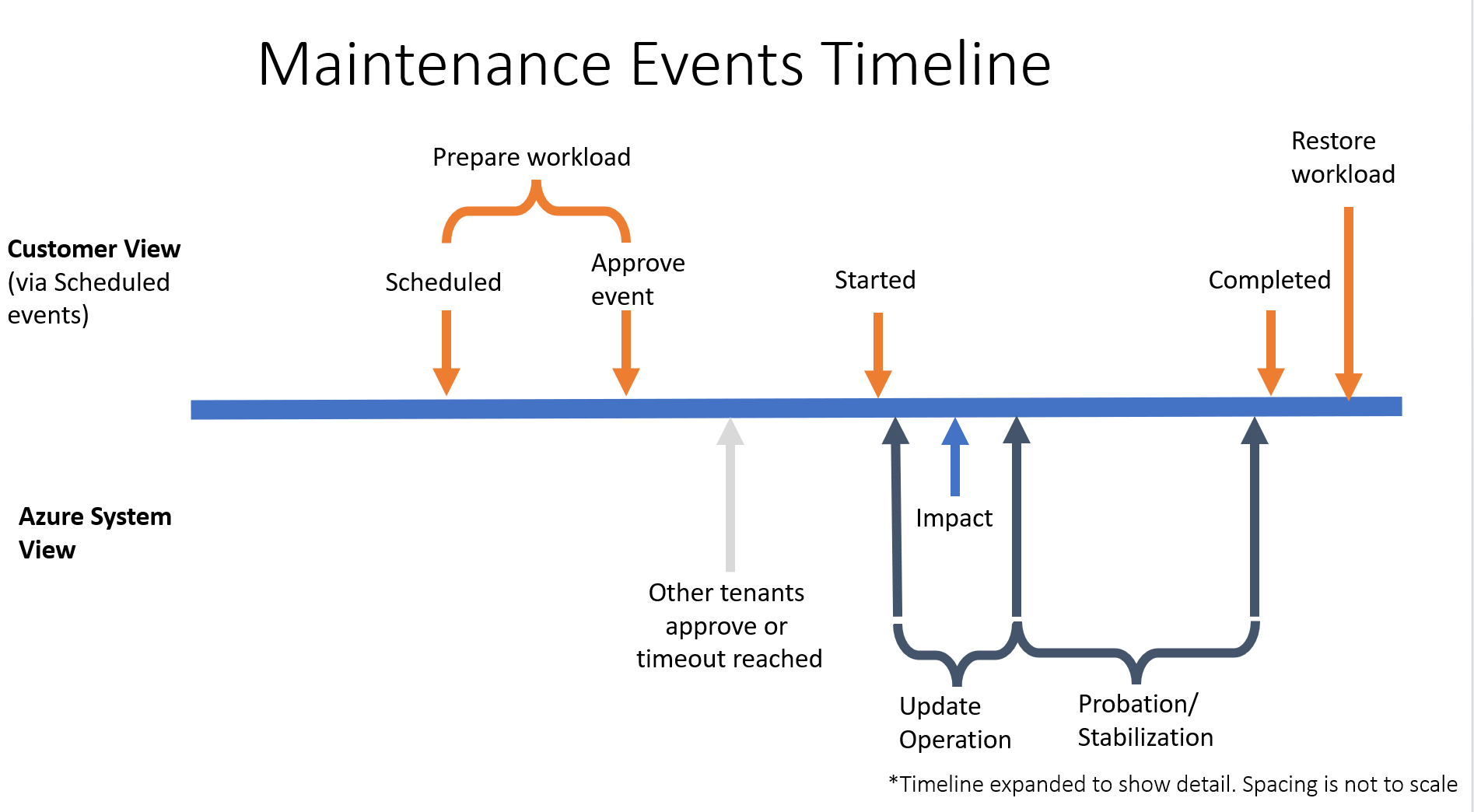
Alle Vorgänge, die sich auf die Verfügbarkeit von VMs auswirken, führen zu einem geplanten Ereignis, aber nicht alle geplanten Ereignisse werden auf anderen Azure-Benutzeroberflächen wie Azure-Aktivitätsprotokollen oder Resource Health angezeigt. Indem Sie geplante Ereignisse regelmäßig überprüfen, stellen Sie sicher, dass Sie über die aktuellsten Informationen zu bevorstehenden Auswirkungen auf Ihre VMs verfügen.
Header
Beim Abfragen des Metadatendiensts müssen Sie den Header Metadata:true angeben, um sicherzustellen, dass die Anforderung nicht unbeabsichtigt umgeleitet wurde. Der Header Metadata:true ist für alle Anforderungen für Geplante Ereignisse erforderlich. Wird der Header nicht in die Anforderung eingefügt, erhalten Sie vom Metadatendienst die Antwort „Ungültige Anforderung“.
Abfragen von Ereignissen
Sie können geplante Ereignisse abfragen, indem Sie den folgenden Aufruf ausführen:
Bash-Beispiel
curl -H Metadata:true http://169.254.169.254/metadata/scheduledevents?api-version=2020-07-01
PowerShell-Beispiel
Invoke-RestMethod -Headers @{"Metadata"="true"} -Method GET -Uri "http://169.254.169.254/metadata/scheduledevents?api-version=2020-07-01" | ConvertTo-Json -Depth 64
Python-Beispiel
import json
import requests
metadata_url ="http://169.254.169.254/metadata/scheduledevents"
header = {'Metadata' : 'true'}
query_params = {'api-version':'2020-07-01'}
def get_scheduled_events():
resp = requests.get(metadata_url, headers = header, params = query_params)
data = resp.json()
return data
Eine Antwort enthält ein Array geplanter Ereignisse. Ein leeres Array bedeutet, dass derzeit keine Ereignisse geplant sind. Sofern geplante Ereignisse vorliegen, enthält die Antwort ein Array mit Ereignissen.
{
"DocumentIncarnation": {IncarnationID},
"Events": [
{
"EventId": {eventID},
"EventType": "Reboot" | "Redeploy" | "Freeze" | "Preempt" | "Terminate",
"ResourceType": "VirtualMachine",
"Resources": [{resourceName}],
"EventStatus": "Scheduled" | "Started",
"NotBefore": {timeInUTC},
"Description": {eventDescription},
"EventSource" : "Platform" | "User",
"DurationInSeconds" : {timeInSeconds},
}
]
}
Ereigniseigenschaften
| Eigenschaft | BESCHREIBUNG |
|---|---|
| Document Incarnation | Integerwert, der erhöht wird, wenn sich das Ereignisarray ändert. Dokumente mit der gleichen Inkarnation enthalten die gleichen Ereignisinformationen, und die Inkarnation wird erhöht, wenn sich ein Ereignis ändert. |
| EventId | Global eindeutiger Bezeichner für dieses Ereignis Beispiel:
|
| EventType | Auswirkungen dieses Ereignisses Werte:
|
| ResourceType | Typ der Ressource, auf die sich dieses Ereignis auswirkt. Werte:
|
| Ressourcen | Liste der Ressourcen, auf die sich dieses Ereignis auswirkt. Beispiel:
|
| EventStatus | Status dieses Ereignisses Werte:
Completed oder ein ähnlicher Status wird nie angegeben. Das Ergebnis wird nicht länger zurückgegeben, wenn es abgeschlossen wurde. |
| NotBefore | Zeitpunkt, nach dem dieses Ereignis gestartet werden kann. Das Ereignis wird garantiert nicht vor dieser Zeit beginnen. Ist leer, wenn das Ereignis bereits gestartet wurde. Beispiel:
|
| Beschreibung | Beschreibung dieses Ereignisses. Beispiel:
|
| EventSource | Initiator des Ereignisses. Beispiel:
|
| DurationInSeconds | Die erwartete Dauer der durch das Ereignis verursachten Unterbrechung. Während des Auswirkungsfensters können sekundäre Auswirkungen einer kürzeren Dauer auftreten. Beispiel:
|
Ereignisplanung
Jedes Ereignis wird, basierend auf dem Ereignistyp, mit einer minimalen Vorlaufzeit geplant. Diese Zeit ist in der NotBefore-Eigenschaft eines Ereignisses angegeben.
| EventType | Mindestzeitspanne |
|---|---|
| Freeze | 15 Minuten |
| Reboot | 15 Minuten |
| Erneute Bereitstellung | 10 Minuten |
| Terminate | Vom Benutzer konfigurierbar: 5 bis 15 Minuten |
Dies bedeutet, dass Sie einen zukünftigen Zeitplan mindestens mit der Mindestbenachrichtigungszeit als Vorlauf erkennen können, bevor das Ereignis eintritt. Wenn ein Ereignis geplant ist, wird es in den Zustand Started versetzt, nachdem es genehmigt wurde oder nachdem der Zeitraum NotBefore verstrichen ist. In seltenen Fällen wird der Vorgang jedoch von Azure abgebrochen, bevor er beginnt. In diesem Fall wird das Ereignis aus dem Ereignisarray entfernt, und es kommt nicht zu den geplanten Auswirkungen.
Hinweis
In einigen Fällen kann Azure den Hostausfall aufgrund von heruntergestufter Hardware vorhersagen und versucht, die Unterbrechung Ihres Diensts durch Planen einer Migration zu minimieren. Betroffene virtuelle Computer erhalten ein geplantes Ereignis mit einer NotBefore-Angabe, die in der Regel einige Tage in der Zukunft liegt. Der tatsächliche Zeitpunkt variiert je nach der vorhergesagten Risikobewertung des Ausfalls. Azure versucht, wenn möglich 7 Tage im Voraus zu benachrichtigen, aber der tatsächliche Zeitpunkt variiert und kann früher sein, wenn die Vorhersage lautet, dass eine hohe Wahrscheinlichkeit besteht, dass die Hardware bald ausfallen wird. Um das Risiko für Ihren Dienst zu verringern, falls vor der vom System initiierten Migration die Hardware ausfällt, empfehlen wir Ihnen, Ihren virtuellen Computer so bald wie möglich selbst erneut bereitzustellen.
Hinweis
Wenn der Hostknoten von einem Hardwarefehler betroffen ist, umgeht Azure die Mindestfrist und beginnt sofort mit der Wiederherstellung der betroffenen virtuellen Computer. Dies verkürzt die Wiederherstellungszeit für den Fall, dass die betroffenen VMs nicht mehr reagieren können. Während des Wiederherstellungsvorgangs wird ein Ereignis für alle betroffenen VMs mit EventType = Reboot und EventStatus = Started erstellt.
Abrufhäufigkeit
Sie können den Endpunkt beliebig häufig (oder selten) auf Updates abfragen. Je mehr Zeit zwischen den Anforderungen vergeht, desto mehr Zeit verlieren Sie möglicherweise für das Reagieren auf ein bevorstehendes Ereignis. Die meisten Ereignisse werden 5 bis 15 Minuten im Voraus angekündigt, manchmal bleibt jedoch nur ein Vorlauf von 30 Sekunden. Damit Sie so viel Zeit wie möglich haben, um Abhilfemaßnahmen zu ergreifen, empfiehlt es sich, den Dienst einmal pro Sekunde abzufragen.
Starten eines Ereignisses
Nachdem Sie von einem anstehenden Ereignis erfahren und Ihre Logik für ein ordnungsgemäßes Herunterfahren vervollständigt haben, können Sie das ausstehende Ereignis genehmigen, indem Sie einen Aufruf des Typs POST an den Metadatendienst mit der EventId ausführen. Dieser Aufruf informiert Azure darüber, dass die minimale Benachrichtigungszeit verkürzt werden kann (falls möglich). Das Ereignis beginnt möglicherweise nicht sofort nach der Genehmigung. In einigen Fällen erfordert Azure die Genehmigung aller auf dem Knoten gehosteten VMs, bevor mit dem Ereignis fortgefahren wird.
Das folgende JSON-Beispiel wird im POST-Anforderungstext erwartet. Die Anforderung sollte eine Liste mit StartRequests enthalten. Jede StartRequest enthält die EventId für das Ereignis, das Sie beschleunigen möchten:
{
"StartRequests" : [
{
"EventId": {EventId}
}
]
}
Der Dienst gibt immer einen Erfolgscode von 200 zurück, wenn ihm eine gültige Ereignis-ID übergeben wird, auch wenn eine andere VM das Ereignis bereits genehmigt hat. Ein Fehlercode von 400 gibt an, dass der Anforderungsheader oder die Nutzdaten falsch formatiert wurden.
Hinweis
Ereignisse werden erst dann fortgesetzt, wenn sie entweder über eine POST-Nachricht genehmigt wurden oder die NotBefore-Zeit verstrichen ist. Dies schließt vom Benutzer ausgelöste Ereignisse wie z. B. VM-Neustarts über das Azure-Portal ein.
Bash-Beispiel
curl -H Metadata:true -X POST -d '{"StartRequests": [{"EventId": "f020ba2e-3bc0-4c40-a10b-86575a9eabd5"}]}' http://169.254.169.254/metadata/scheduledevents?api-version=2020-07-01
PowerShell-Beispiel
Invoke-RestMethod -Headers @{"Metadata" = "true"} -Method POST -body '{"StartRequests": [{"EventId": "5DD55B64-45AD-49D3-BBC9-F57D4EA97BD7"}]}' -Uri http://169.254.169.254/metadata/scheduledevents?api-version=2020-07-01 | ConvertTo-Json -Depth 64
Python-Beispiel
import json
import requests
def confirm_scheduled_event(event_id):
# This payload confirms a single event with id event_id
payload = json.dumps({"StartRequests": [{"EventId": event_id }]})
response = requests.post("http://169.254.169.254/metadata/scheduledevents",
headers = {'Metadata' : 'true'},
params = {'api-version':'2020-07-01'},
data = payload)
return response.status_code
Hinweis
Durch das Bestätigen eines Ereignisses kann dieses für alle Resources im Ereignis fortgesetzt werden, nicht nur für die VM, die das Ereignis bestätigt. Daher können Sie einen Leiter zur Koordinierung der Bestätigung auswählen, beispielsweise einfach den ersten Computer im Feld Resources.
Beispielantworten
Die folgenden Ereignisse sind Beispiele, die von zwei VMs beobachtet wurden, die live zu einem anderen Knoten migriert wurden.
Die DocumentIncarnation ändert sich jedes Mal, wenn neue Informationen in Events vorhanden sind. Eine Genehmigung des Ereignisses würde es ermöglichen, das Einfrieren sowohl für WestNO_0 als auch für WestNO_1 fortzusetzen. Der DurationInSeconds-Wert -1 gibt an, dass die Plattform nicht weiß, wie lange der Vorgang dauert.
{
"DocumentIncarnation": 1,
"Events": [
]
}
{
"DocumentIncarnation": 2,
"Events": [
{
"EventId": "C7061BAC-AFDC-4513-B24B-AA5F13A16123",
"EventStatus": "Scheduled",
"EventType": "Freeze",
"ResourceType": "VirtualMachine",
"Resources": [
"WestNO_0",
"WestNO_1"
],
"NotBefore": "Mon, 11 Apr 2022 22:26:58 GMT",
"Description": "Virtual machine is being paused because of a memory-preserving Live Migration operation.",
"EventSource": "Platform",
"DurationInSeconds": 5
}
]
}
{
"DocumentIncarnation": 3,
"Events": [
{
"EventId": "C7061BAC-AFDC-4513-B24B-AA5F13A16123",
"EventStatus": "Started",
"EventType": "Freeze",
"ResourceType": "VirtualMachine",
"Resources": [
"WestNO_0",
"WestNO_1"
],
"NotBefore": "",
"Description": "Virtual machine is being paused because of a memory-preserving Live Migration operation.",
"EventSource": "Platform",
"DurationInSeconds": 5
}
]
}
{
"DocumentIncarnation": 4,
"Events": [
]
}
Python-Beispiel
Im folgenden Beispiel fragt der Metadatenserver geplante Ereignisse ab und genehmigt jedes ausstehende Ereignis:
#!/usr/bin/python
import json
import requests
from time import sleep
# The URL to access the metadata service
metadata_url ="http://169.254.169.254/metadata/scheduledevents"
# This must be sent otherwise the request will be ignored
header = {'Metadata' : 'true'}
# Current version of the API
query_params = {'api-version':'2020-07-01'}
def get_scheduled_events():
resp = requests.get(metadata_url, headers = header, params = query_params)
data = resp.json()
return data
def confirm_scheduled_event(event_id):
# This payload confirms a single event with id event_id
# You can confirm multiple events in a single request if needed
payload = json.dumps({"StartRequests": [{"EventId": event_id }]})
response = requests.post(metadata_url,
headers= header,
params = query_params,
data = payload)
return response.status_code
def log(event):
# This is an optional placeholder for logging events to your system
print(event["Description"])
return
def advanced_sample(last_document_incarnation):
# Poll every second to see if there are new scheduled events to process
# Since some events may have necessarily short warning periods, it is
# recommended to poll frequently
found_document_incarnation = last_document_incarnation
while (last_document_incarnation == found_document_incarnation):
sleep(1)
payload = get_scheduled_events()
found_document_incarnation = payload["DocumentIncarnation"]
# We recommend processing all events in a document together,
# even if you won't be actioning on them right away
for event in payload["Events"]:
# Events that have already started, logged for tracking
if (event["EventStatus"] == "Started"):
log(event)
# Approve all user initiated events. These are typically created by an
# administrator and approving them immediately can help to avoid delays
# in admin actions
elif (event["EventSource"] == "User"):
confirm_scheduled_event(event["EventId"])
# For this application, freeze events less that 9 seconds are considered
# no impact. This will immediately approve them
elif (event["EventType"] == "Freeze" and
int(event["DurationInSeconds"]) >= 0 and
int(event["DurationInSeconds"]) < 9):
confirm_scheduled_event(event["EventId"])
# Events that may be impactful (for example, reboot or redeploy) may need custom
# handling for your application
else:
#TODO Custom handling for impactful events
log(event)
print("Processed events from document: " + str(found_document_incarnation))
return found_document_incarnation
def main():
# This will track the last set of events seen
last_document_incarnation = "-1"
input_text = "\
Press 1 to poll for new events \n\
Press 2 to exit \n "
program_exit = False
while program_exit == False:
user_input = input(input_text)
if (user_input == "1"):
last_document_incarnation = advanced_sample(last_document_incarnation)
elif (user_input == "2"):
program_exit = True
if __name__ == '__main__':
main()
Nächste Schritte
- Überprüfen Sie die Codebeispiele für Scheduled Events im GitHub-Repository „Azure Instance Metadata Scheduled Events“.
- Sehen Sie sich die Codebeispiele für Node.js Scheduled Events im GitHub-Repository mit Azure-Beispielen an.
- Erfahren Sie mehr über die verfügbaren APIs im Instanz-Metadatendienst.
- Erfahren Sie mehr über Geplante Wartung für virtuelle Linux-Computer in Azure.
- Erfahren Sie, wie Sie geplante Ereignisse mithilfe von Azure Event Hubs im GitHub-Repository mit Azure-Beispielen protokollieren.