Konfigurationsoptionen zum Minimieren der Netzwerklatenz mit SAP-Anwendungen
Wichtig
Im November 2021 haben wir erhebliche Änderungen an der Verwendung von Näherungsplatzierungsgruppen mit SAP-Workload in zonenbezogenen Bereitstellungen vorgenommen.
SAP-Anwendungen, die auf der SAP NetWeaver- oder SAP S/4HANA-Architektur basieren, sind von der Netzwerklatenz zwischen der SAP-Anwendungsschicht und der SAP-Datenbankschicht abhängig. Diese Abhängigkeit ist das Ergebnis davon, dass der größte Teil der Geschäftslogik in der Anwendungsschicht ausgeführt wird. Da die SAP-Anwendungsschicht die Geschäftslogik ausführt, gibt sie mit einer hohen Frequenz Abfragen an die Datenbankschicht aus (tausende oder zehntausende von Abfragen pro Sekunde). In den meisten Fällen handelt es sich um einfache Abfragen. Sie können oft in 500 Mikrosekunden oder noch kürzerer Zeit in der Datenbankschicht ausgeführt werden.
Die Zeit, die im Netzwerk verbracht wird, um eine solche Abfrage von der Anwendungsschicht an die Datenbankschicht zu senden, und das zurückgesendete Ergebnis beeinflussen maßgeblich die Zeit, die zur Ausführung von Geschäftsprozessen benötigt wird. Diese Empfindlichkeit gegenüber Netzwerklatenzen ist der Grund, warum es sinnvoll ist, in SAP-Bereitstellungsprojekten eine bestimmte minimale Netzwerklatenz zu erreichen. Weitere Informationen finden Sie im SAP-Hinweis 1100926 – Häufig gestellte Fragen: Netzwerkleistung. Dort finden Sie einige Richtlinien zum Klassifizieren der Netzwerklatenz.
In vielen Azure-Regionen ist die Zahl der Rechenzentren gestiegen. Gleichzeitig nutzen Kunden, insbesondere für High-End-SAP-Systeme, speziellere VM-Familien wie Mv2 oder Mv3-Familie und neuer. Diese Azure-VM-Typen sind nicht immer in jedem der Rechenzentren verfügbar, die in einer Azure-Region gesammelt werden. Diese Tatsachen können die Chance eröffnen, die Netzwerklatenz zwischen der SAP-Anwendungsschicht und der SAP DBMS-Schicht zu optimieren.
Azure bietet verschiedene Bereitstellungsoptionen für SAP-Workloads. Für den ausgewählten Bereitstellungstyp haben Sie bei Bedarf Optionen zum Optimieren der Netzwerklatenz. Detaillierte Informationen zu jeder Option werden in den folgenden Abschnitten dieses Artikels ausführlich beschrieben:
Näherungsplatzierungsgruppen
Näherungsplatzierungsgruppen ermöglichen die Gruppierung verschiedener VM-Typen unter einem einzelnen Netzwerk-Rückgrat, wodurch eine optimale niedrige Netzwerklatenz zwischen ihnen gewährleistet wird. Wenn die erste VM in einer Näherungsplatzierungsgruppe bereitgestellt wird, wird diese VM an ein bestimmtes Netzwerk-Rückgrat gebunden. Wie alle anderen VMs, die in derselben Näherungsplatzierungsgruppe bereitgestellt werden sollen, werden diese VMs unter demselben Netzwerk-Rückgrat gruppiert. So reizvoll diese Aussicht klingt, die Nutzung dieses Konstrukts bringt auch einige Einschränkungen und Nachteile mit sich:
- Sie können nicht davon ausgehen, dass alle Azure-VM-Typen in allen Azure-Rechenzentren oder in jedem Netzwerkrückgrat verfügbar sind. Das hat zur Folge, dass die Kombination verschiedener VM-Typen innerhalb einer Näherungsplatzierungsgruppe stark eingeschränkt sein kann. Diese Einschränkungen treten auf, weil die Hosthardware, die zum Ausführen eines bestimmten VM-Typs benötigt wird, möglicherweise nicht im Rechenzentrum oder unter dem Netzwerk-Rückgrat vorhanden ist, dem die Näherungsplatzierungsgruppe zugewiesen wurde.
- Wenn Sie die Größe von Teilen der VMs ändern, die sich in einer Näherungsplatzierungsgruppe befinden, können Sie nicht automatisch davon ausgehen, dass der neue VM-Typ in allen Fällen im selben Rechenzentrum oder unter dem Netzwerkrückgrat verfügbar ist, dem die Näherungsplatzierungsgruppe zugewiesen wurde.
- Wenn Azure Hardware außer Betrieb nimmt, werden bestimmte VMs einer Näherungsplatzierungsgruppe möglicherweise in ein anderes Azure-Rechenzentrum oder Netzwerk-Rückgrat gezwungen. Ausführliche Informationen zu diesem Fall finden Sie im Dokument Näherungsplatzierungsgruppen
Wichtig
Als Ergebnis der potenziellen Einschränkungen sollten diese Regeln nur für die Verwendung von Näherungsplatzierungsgruppen beachtet werden:
- Bei Bedarf in bestimmten Szenarien (siehe weiter unten)
- Wenn die Netzwerklatenz zwischen Anwendungsebene und DBMS-Ebene zu hoch ist und sich auf die Workload auswirkt
- Nur im Detailgrad eines einzelnen SAP-Systems einsetzen, nicht für eine gesamte Systemlandschaft oder eine gesamte SAP-Landschaft
- So einsetzen, dass die verschiedenen VM-Typen und die Anzahl der VMs innerhalb einer Näherungsplatzierungsgruppe so gering wie möglich gehalten wird
Die Szenarien, in denen Näherungsplatzierungsgruppen verwendet werden können, um die Netzwerklatenz zu optimieren:
- Sie möchten die kritischen Ressourcen Ihrer SAP-Arbeitslast in verschiedenen Verfügbarkeitszonen bereitstellen und benötigen andererseits VMs der Anwendungsschicht, die über verschiedene Fehlerdomänen verteilt sind, indem Sie Verfügbarkeitsgruppen in jeder der Zonen verwenden. In diesem Fall, wie später in dem Dokument beschrieben, sind die Näherungsplatzierungsgruppen das nötige Verbindungsstück.
- Sie stellen die SAP-Workload mit Verfügbarkeitssätzen bereit. Dabei wurden die SAP-Datenschicht, die SAP-Logikschicht und ASCS/SCS-VMs in drei verschiedenen Verfügbarkeitsgruppen gruppiert. In einem solchen Fall sollten Sie sicherstellen, dass die Verfügbarkeitsgruppen nicht auf die gesamte Azure-Region verteilt sind, da dies abhängig von der Azure-Region zu Netzwerklatenz führen kann, die sich negativ auf die SAP-Workload auswirken könnte.
- Mit Proximity-Platzierungsgruppen gruppieren Sie VMs, um eine möglichst geringe Netzwerklatenz zwischen den in den VMs gehosteten Services zu erreichen. Die Latenz innerhalb einer Verfügbarkeitszone allein erfüllt beispielsweise nicht die Anwendungsanforderungen.
Wie bei Bereitstellungsszenario 2 ist in vielen Regionen, insbesondere in Regionen ohne Verfügbarkeitszonen und den meisten Regionen mit Verfügbarkeitszonen, die Netzwerklatenz unabhängig davon, wo die VMs landen, akzeptabel. Es gibt jedoch einige Azure-Regionen, die ohne Anordnung der drei verschiedenen Verfügbarkeitsgruppen mithilfe von Näherungsplatzierungsgruppen keine ausreichend gute Erfahrung bieten können.
Was sind Näherungsplatzierungsgruppen?
Eine Azure-Näherungsplatzierungsgruppe ist ein logisches Konstrukt. Wenn eine Näherungsplatzierungsgruppe definiert wird, wird sie an eine Azure-Region und eine Azure-Ressourcengruppe gebunden. Wenn VMs bereitgestellt werden, wird wie folgt auf eine Azure-Näherungsplatzierungsgruppe verwiesen:
- Die erste Azure-VM, die unter einem Netzwerk-Rückgrat bereitgestellt wird, ist mit vielen Azure-Compute-Einheiten und geringer Netzwerklatenz ausgestattet. Ein solches Netzwerk entspricht häufig einem einzelnen Azure-Rechenzentrum. Sie können sich die erste VM als „Bereichs-VM“ vorstellen, der in einer Compute-Skalierungseinheit basierend auf Azure-Zuteilungsalgorithmen bereitgestellt wird, die schließlich mit Bereitstellungsparametern kombiniert werden.
- Alle nachfolgenden bereitgestellten VMs, die auf die Näherungsplatzierungsgruppe verweisen, werden unter demselben Netzwerk-Rückgrat bereitgestellt wie der erste virtuelle Computer.
Hinweis
Wenn keine Hosthardware vorhanden ist, auf der ein bestimmter VM-Typ unter dem Netzwerkspine ausgeführt werden kann, auf dem die erste VM platziert wurde, ist die Bereitstellung des angeforderten VM-Typs nicht erfolgreich. Sie erhalten eine Zuteilungsfehlermeldung, die angibt, dass die VM im Umkreis der Näherungsplatzierungsgruppe nicht unterstützt werden kann.
Um dieses Risiko zu verringern, wird empfohlen, beim Erstellen der Näherungsplatzierungsgruppe die Option „intent“ zu verwenden. Mithilfe der Option „intent“ können Sie die VM-Typen auflisten, die Sie in die Näherungsplatzierungsgruppe einschließen möchten. Diese Liste der VM-Typen wird verwendet, um das beste Rechenzentrum zu finden, das diese VM-Typen hostet. Wird ein solches Rechenzentrum gefunden, wird die Näherungsplatzierungsgruppe für das Rechenzentrum erstellt, das die SKU-Anforderungen der VMs erfüllt. Wird kein solches Rechenzentrum gefunden, schlägt die Erstellung der Näherungsplatzierungsgruppe fehl. Weitere Informationen finden Sie in der Dokumentation Näherungsplatzierungsgruppen: Verwenden des Parameters „intent“ zum Angeben von VM-Größen. Beachten Sie, dass die tatsächliche Kapazitätssituation bei den durch die Option „intent“ ausgelösten Prüfungen nicht berücksichtigt wird. Infolgedessen kann es weiterhin zu Zuweisungsfehlern kommen, die auf eine unzureichende Kapazität zurückzuführen sind.
Einer einzelnen Azure-Ressourcengruppe können mehrere Näherungsplatzierungsgruppen zugewiesen werden. Eine Näherungsplatzierungsgruppe kann jedoch nur einer Azure-Ressourcengruppe zugeordnet werden.
Weitere Informationen und Bereitstellungsbeispiele für Näherungsplatzierungsgruppen finden Sie in der verfügbaren Dokumentation.
Näherungsplatzierungsgruppen mit zonenbezogenen Bereitstellungen
Es ist wichtig, eine relativ geringe Netzwerklatenz zwischen der SAP-Anwendungsebene und der DBMS-Ebene bereitzustellen. In den meisten Fällen erfüllt eine zonale Bereitstellung allein diese Anforderung. Bei einer begrenzten Menge von Szenarien erfüllt eine zonale Bereitstellung allein möglicherweise nicht die Anforderungen an die Anwendungslatenz. In solchen Situationen ist eine VM-Platzierung so nah wie möglich erforderlich, und sie aktivieren eine relativ geringe Netzwerklatenz, eine Azure-Näherungsgruppe kann für ein solches SAP-System definiert werden.
Eine Bündelung mehrerer SAP-Produktions- oder -Nicht-Produktionssysteme in einer einzigen Näherungsplatzierungsgruppe sollte vermieden werden. Vermeiden Sie SAP-Systembündelungen: Je mehr Systeme Sie in einer Näherungsplatzierungsgruppe gruppieren, desto höher ist die Wahrscheinlichkeit für Folgendes:
- Sie benötigen einen VM-Typ, der unter dem Netzwerk-Rückgrat, dem die Näherungsplatzierungsgruppe zugewiesen wurde, nicht verfügbar ist.
- Diese Ressourcen nichtgängiger VMs, z. B. der M-Serie, könnten schließlich nicht mehr erfüllt werden, wenn Sie die Anzahl der VMs im Laufe der Zeit in eine Näherungsplatzierungsgruppe erweitern müssen.
Auf der Grundlage zahlreicher Verbesserungen, die Microsoft in den Azure-Regionen vorgenommen hat, um die Netzwerklatenz innerhalb einer Azure-Verfügbarkeitszone zu verringern, sieht die Anleitung zur Bereitstellung bei Verwendung von Proximity-Platzierungsgruppen für zonale Bereitstellungen wie folgt aus:
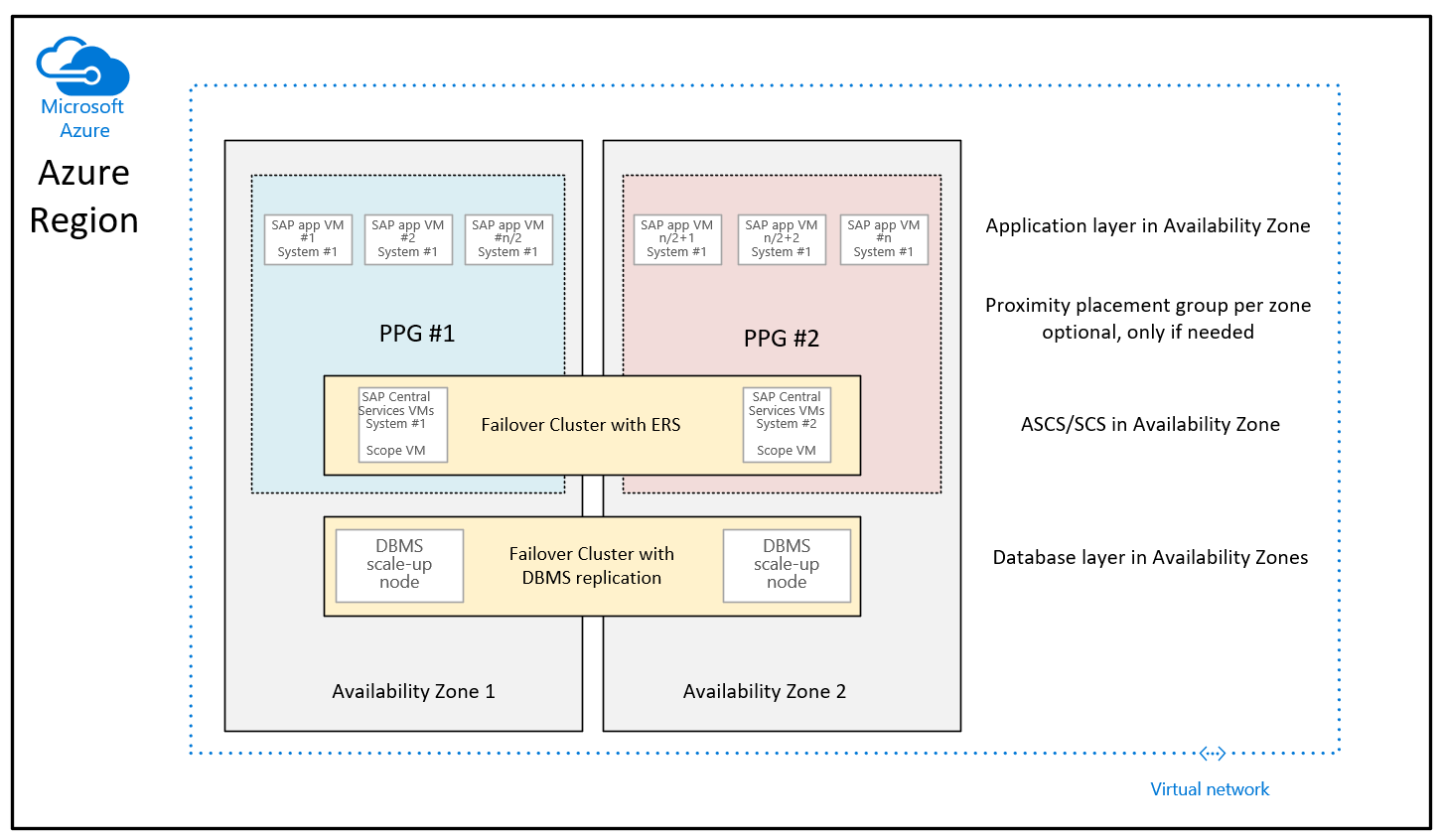
Der Unterschied zur bisherigen Empfehlung besteht darin, dass die Datenbank-VMs in den beiden Zonen nicht mehr Teil der Näherungsplatzierungsgruppen sind. Die Näherungsplatzierungsgruppen pro Zone sind jetzt auf die Bereitstellung der VM, auf der die SAP-ASCS/SCS-Instanzen ausgeführt werden, zugewiesen. Dies bedeutet auch, dass für die Regionen, in denen Verfügbarkeitszonen von mehreren Rechenzentren gesammelt werden, die ASCS/SCS-Instanz und die Logikschicht unter einem Netzwerk-Rückgrat ausgeführt werden können und die Datenbank-VMs unter einem anderen Netzwerk-Rückgrat ausgeführt werden können. Obwohl die Netzwerkverbesserungen vorgenommen wurden, sollte die Netzwerklatenz zwischen der SAP-Logikschicht und der DBMS-Ebene weiterhin ausreichen, um eine ausreichend gute Leistung und einen ausreichend guten Durchsatz zu erzielen. Der Vorteil dieser neuen Konfiguration besteht darin, dass Sie mehr Flexibilität bei der Größenänderung von VMs oder beim Wechsel zu neuen VM-Typen mit der DBMS-Ebene oder/und der Anwendungsebene des SAP-Systems haben.
Für den speziellen Fall der Verwendung von Azure NetApp Files für die DBMS-Umgebung und die auf Azure NetApp Files bezogenen Funktionen von Azure NetApp Files-Anwendungsvolumegruppen für SAP HANA und die damit verbundene Notwendigkeit für Näherungsplatzierungsgruppen finden Sie im Dokument NFS v4.1-Volumes unter Azure NetApp Files für SAP HANA.
Näherungsplatzierungsgruppen mit Bereitstellungen von Verfügbarkeitsgruppen
In diesem Fall besteht der Zweck darin, Näherungsplatzierungsgruppen zu verwenden, um die VMs zu anzuordnen, die über verschiedene Verfügbarkeitsgruppen bereitgestellt werden. In diesem Verwendungsszenario verwenden Sie keine kontrollierte Bereitstellung für verschiedene Verfügbarkeitszonen in einer Region. Stattdessen möchten Sie das SAP-System mithilfe von Verfügbarkeitsgruppen bereitstellen. Daher verfügen Sie mindestens über eine Verfügbarkeitsgruppe für die DBMS-VMs, ASCS/SCS-VMs und die Logikschicht-VMs. Da es nicht möglich ist, zum Zeitpunkt der Bereitstellung einer VM eine Verfügbarkeitsgruppen UND eine Verfügbarkeitszone anzugeben, können Sie nicht steuern, wo die VMs in den verschiedenen Verfügbarkeitsgruppen zugeordnet werden. Dies kann dazu führen, dass die Netzwerklatenz zwischen verschiedenen VMs in einigen Azure-Regionen immer noch zu hoch ist, um eine ausreichend gute Leistung zu erzielen. Die resultierende Architektur würde also wie folgt aussehen:
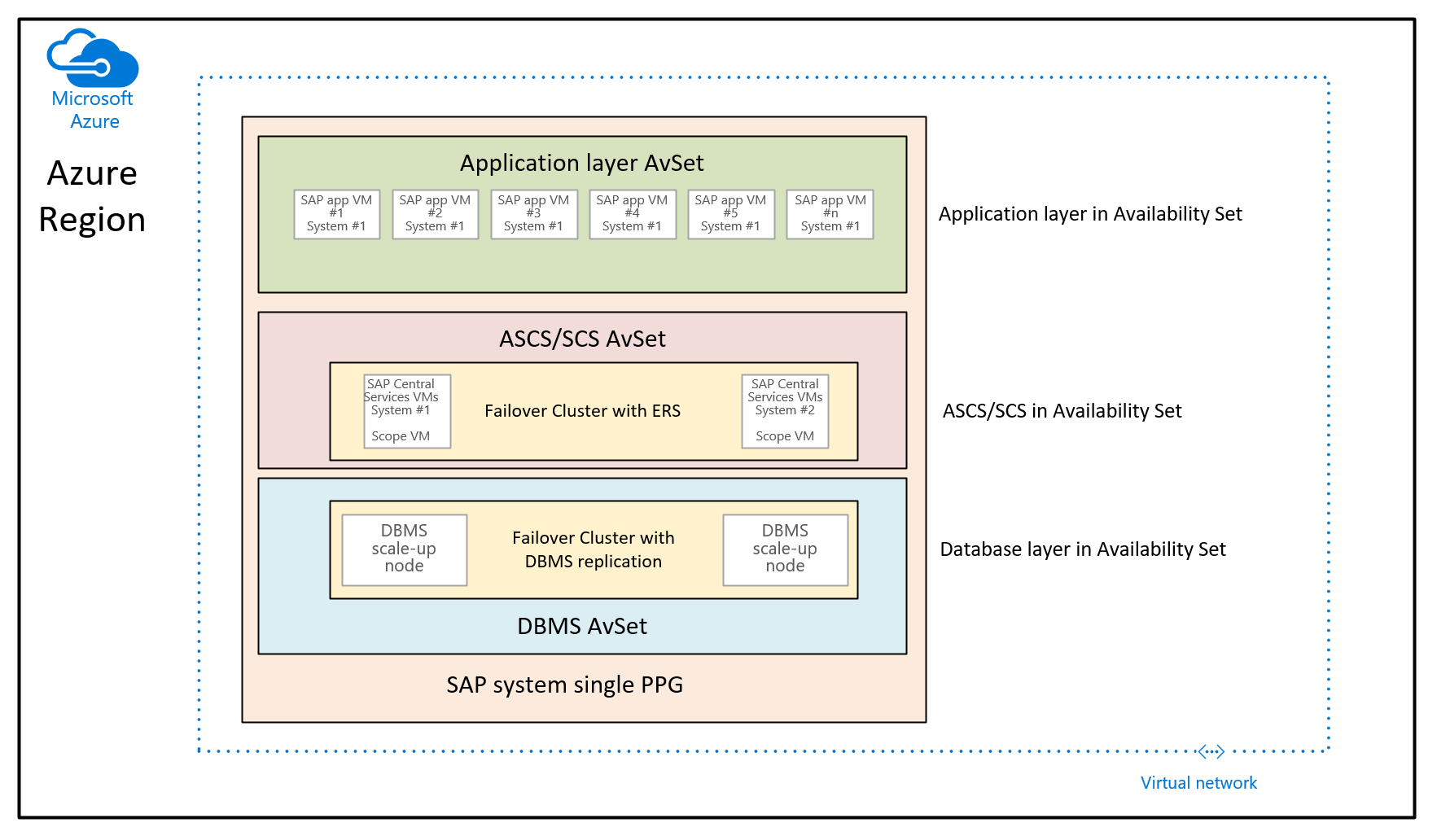
In dieser Grafik wird einem einzelnen SAP-System eine einzelne Näherungsplatzierungsgruppe zugewiesen. Diese PPG wird den drei Verfügbarkeitsgruppen zugewiesen. Der Bereich der Näherungsplatzierungsgruppe wird dann durch Bereitstellen der ersten VMs der Datenbankschicht in der DBMS-Verfügbarkeitsgruppe festgelegt. Mit dieser Architekturempfehlung werden alle virtuellen Computer unter demselben Netzwerk-Rückgrat angeordnet. Damit werden die bereits erwähnten Einschränkungen eingeführt. Daher sollte die Näherungsplatzierungsgruppenarchitektur nur selten verwendet werden.
Kombinieren von Verfügbarkeitsgruppen und Verfügbarkeitszonen mit Näherungsplatzierungsgruppen
Eines der Probleme bei der Verwendung von Verfügbarkeitszonen für SAP-Systembereitstellungen besteht darin, dass Sie die SAP-Logikschicht nicht mit Verfügbarkeitsgruppen innerhalb der jeweiligen Verfügbarkeitszone bereitstellen können. Sie möchten, dass die SAP-Logikschicht in denselben Zonen wie die SAP-ASCS/SCS-VMs bereitgestellt wird. Das Verweisen auf eine Verfügbarkeitszone und eine Verfügbarkeitsgruppe beim Bereitstellen einer einzelnen VM ist derzeit nicht möglich. Wenn Sie jedoch nur eine VM bereitstellen, die eine Verfügbarkeitszone anweisen soll, können Sie nicht mehr sicherstellen, dass die VMs der Anwendungsebene auf verschiedene Update- und Fehlerdomänen verteilt sind.
Durch die Verwendung von Näherungsplatzierungsgruppen können Sie diese Einschränkung umgehen. Dies ist die Bereitstellungssequenz:
- Erstellen Sie eine Näherungsplatzierungsgruppe.
- Stellen Sie Ihre Anker-VM (empfohlen als ASCS/SCS-VM) durch Verweisen auf eine Verfügbarkeitszone zur bereit.
- Erstellen Sie ein Availability Set, das auf die Azure Proximity-Platzierungsgruppe verweist. (Siehe den Befehl weiter unten in diesem Artikel.)
- Stellen Sie die VMs der Anwendungsschicht bereit, indem Sie auf die Verfügbarkeitsgruppe und die Näherungsplatzierungsgruppe verweisen.
Wichtig
Es ist wichtig zu verstehen, dass Datenträger der VMs auf Anwendungsebene nicht garantiert in derselben Verfügbarkeitszone zugewiesen werden, da die VMs zur Verwendung der Näherungsplatzierungsgruppe geleitet werden. Das Ergebnis der Bereitstellung, die in den nächsten Schritten gezeigt wird, kann sein, dass die virtuellen Computer in demselben Netzwerk-Rückgrat und mit der gleichen Verfügbarkeitszone wie die Anker-VM zugewiesen werden. Die jeweiligen Datenträger (Basis-VHD und bereitgestellte Azure-Blockspeicherdatenträger) werden jedoch möglicherweise nicht unter demselben Netzwerk-Rückgrat oder sogar derselben Verfügbarkeitszone zugewiesen. Stattdessen können die Datenträger dieser virtuellen Computer in einem der Rechenzentren der jeweiligen Region zugeordnet werden. Allerdings werden die Datenträger der Anker-VM, die durch Definieren einer Zone bereitgestellt wurden, in derselben Zone bereitgestellt wie die VM.
Anstatt die erste VM wie im vorherigen Abschnitt gezeigt bereitzustellen, verweisen Sie beim Bereitstellen der VM auf eine Verfügbarkeitszone und die Näherungsplatzierungsgruppe:
New-AzVm -ResourceGroupName "ppgexercise" -Name "centralserviceszone1" -Location "westus2" -OpenPorts 80,3389 -Zone "1" -ProximityPlacementGroup "collocate" -Size "Standard_E8s_v4"
Eine erfolgreiche Bereitstellung dieses virtuellen Computers würde die ASCS/SCS-Instanz des SAP-Systems in einer Verfügbarkeitszone hosten. In diesem Fall werden die VM und die Basis-VHD des virtuellen Computers und potenziell bereitgestellte Azure-Blockspeicherdatenträger innerhalb derselben Verfügbarkeitszone zugewiesen. Der Bereich der Näherungsplatzierungsgruppe ist auf eines der Netzwerk-Rückgrate festgelegt, die sich in der von Ihnen definierten Verfügbarkeitszone befinden.
Im nächsten Schritt müssen Sie die Verfügbarkeitsgruppen erstellen, die Sie für die Anwendungsschicht des SAP-Systems verwenden möchten.
Definieren und erstellen Sie die Näherungsplatzierungsgruppe. Der Befehl zum Erstellen der Verfügbarkeitsgruppe erfordert einen zusätzlichen Verweis auf die ID der Näherungsplatzierungsgruppe (nicht den Namen). Sie können die ID der Näherungsplatzierungsgruppe abrufen, indem Sie den folgenden Befehl verwenden:
Get-AzProximityPlacementGroup -ResourceGroupName "ppgexercise" -Name "collocate"
Beim Erstellen der Verfügbarkeitsgruppe müssen Sie zusätzliche Parameter berücksichtigen, wenn Sie verwaltete Datenträger (Standard, sofern nicht anders angegeben) und Näherungsplatzierungsgruppen verwenden:
New-AzAvailabilitySet -ResourceGroupName "ppgexercise" -Name "ppgavset" -Location "westus2" -ProximityPlacementGroupId "/subscriptions/my very long ppg id string" -sku "aligned" -PlatformUpdateDomainCount 3 -PlatformFaultDomainCount 2
Im Idealfall sollten Sie drei Fehlerdomänen verwenden. Die Anzahl der unterstützten Fehlerdomänen kann jedoch je nach Region unterschiedlich sein. In diesem Fall beträgt die maximal mögliche Anzahl von Fehlerdomänen für die einzelnen Regionen zwei Domänen. Für die Bereitstellung von Anwendungsschicht-VMs müssen Sie einen Verweis auf den Namen der Verfügbarkeitsgruppe und den Namen der Näherungsplatzierungsgruppe hinzufügen, wie hier gezeigt:
New-AzVm -ResourceGroupName "ppgexercise" -Name "appinstance1" -Location "westus2" -OpenPorts 80,3389 -AvailabilitySetName "myppgavset" -ProximityPlacementGroup "collocate" -Size "Standard_E16s_v4"
Hinweis
Die Datenträger der VMs, die in der obigen Verfügbarkeitsgruppe eingesetzt werden, müssen nicht zwangsläufig derselben Verfügbarkeitszone zugeordnet werden wie die VM selbst. Obwohl Sie erreicht haben, dass die Anwendungsschicht-VMs über verschiedene Fehlerdomänen unter demselben Netzwerk-Rückgrat verteilt sind, wie die Anker-VM zugewiesen ist, können die Datenträger, obwohl ebenfalls in verschiedenen Fehlerdomänen zugewiesen, an verschiedenen Orten in einem regionsweiten Umfang zugewiesen sein.
Dies ist das Ergebnis dieser Bereitstellung:
- Zentrale Dienste für Ihr SAP-System, die sich in einer bestimmten Verfügbarkeitszone oder mehreren Verfügbarkeitszonen befinden.
- Eine SAP-Anwendungsebene, die sich über Verfügbarkeitsgruppen im selben Netzwerk befindet wie die SAP-(ASCS/SCS-)VM oder -VMs der zentralen Dienste.
Hinweis
Da Sie eine DBMS-VM und ASCS/SCS-VMs in einer Zone und die zweite DBMS-VM und ASCS/SCS-VMs in eine anderer Zone bereitstellen, um eine Hochverfügbarkeitskonfiguration zu erhalten, benötigen Sie für jede der Zonen eine andere Näherungsplatzierungsgruppe. Das gleiche gilt für jede Verfügbarkeitsgruppe, die Sie verwenden.
Ändern der Konfigurationen der Näherungsplatzierungsgruppe eines vorhandenen Systems
Wenn Sie Näherungsplatzierungsgruppen als die bisher angegebenen Empfehlungen implementiert haben und sie an die neue Konfiguration anpassen möchten, können Sie dies mit den in den folgenden Artikeln beschriebenen Methoden tun:
- Bereitstellen von VMs für Näherungsplatzierungsgruppen mit Azure CLI
- Bereitstellen von VMs für Näherungsplatzierungsgruppen mit PowerShell
Sie können diese Befehle auch in Fällen verwenden, in denen Sie Zuweisungsfehler erhalten, weil Sie nicht zu einem neuen VM-Typ mit einer vorhandenen VM in der Näherungsplatzierungsgruppe wechseln können.
VM-Skalierungsgruppe mit flexibler Orchestrierung
Um die Einschränkungen zu vermeiden, die mit der Näherungsplatzierungsgruppe verbunden sind, wird empfohlen, SAP-Workload über Verfügbarkeitszonen hinweg bereitzustellen, indem Sie eine flexible Skalierungsgruppe mit FD=1 verwenden. Diese Bereitstellungsstrategie stellt sicher, dass virtuelle Computer, die in jeder Zone bereitgestellt werden, nicht auf ein einzelnes Rechenzentrum oder ein Netzwerk-Rückgrat beschränkt sind, und alle SAP-Systemkomponenten, z. B. Datenbanken, ASCS/ERS und Anwendungsebene, werden innerhalb einer Zone festgelegt. Da alle SAP-Systemkomponenten auf zonaler Ebene festgelegt werden, muss die Netzwerklatenz zwischen verschiedenen Komponenten eines einzelnen SAP-Systems ausreichend sein, um eine zufriedenstellende Leistung und einen zufriedenstellenden Durchsatz zu gewährleisten. Der Hauptvorteil dieser neuen Bereitstellungsoption mit flexibler Skalierungsgruppe mit FD=1 besteht darin, dass sie mehr Flexibilität beim Ändern der Größe von VMs oder beim Wechsel zu neuen VM-Typen für alle SAP-Systemebenen bietet. Außerdem würde die Skalierungsgruppe VMs über mehrere Fehlerdomänen innerhalb einer einzelnen Zone zuordnen, was ideal für das Ausführen mehrerer VMs der Anwendungsebene in jeder Zone ist. Weitere Informationen finden Sie im Dokument VM-Skalierungsgruppe für SAP-Workload.
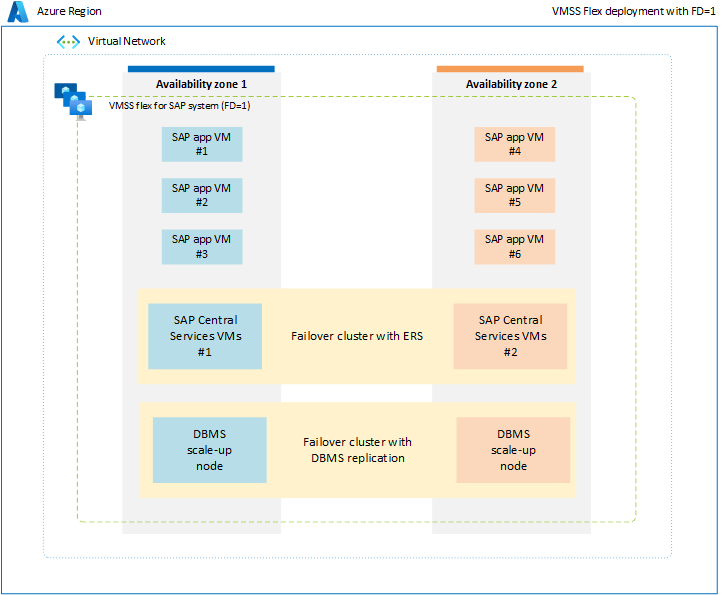
In einer Nichtproduktions- oder Nicht-HA-Umgebung ist es möglich, alle SAP-Systemkomponenten, einschließlich Datenbank, ASCS und Anwendungsebene, innerhalb einer einzelnen Zone mithilfe einer flexiblen Skalierungsgruppe mit FD=1 bereitzustellen.
Zuvor empfohlene Bereitstellungsoptionen
Dieser Abschnitt enthält Details zu zuvor empfohlenen Bereitstellungsoptionen zur Optimierung der Netzwerklatenz für SAP. Mit neuen Features und Azure-Wachstum im Laufe der Zeit sollten Details in diesem Abschnitt nur in seltenen Fällen angewendet werden.
Näherungsplatzierungsgruppen für das gesamte SAP-System mit zonalen Bereitstellungen
Die Verwendung der Näherungsplatzierungsgruppe, die wir bisher empfohlen haben, sieht wie in dieser Grafik aus.

Sie haben in jeder der beiden Verfügbarkeitszonen, in denen Sie Ihr SAP-System bereitgestellt haben, eine Näherungsplatzierungsgruppe (Proximity Placement Group, PPG) erstellt. Alle VMs einer bestimmten Zone sind Teil der einzelnen Näherungsplatzierungsgruppe dieser bestimmten Zone. Sie begannen in jeder Zone mit der Bereitstellung der DBMS-VM, um die PPG zu erfassen, und stellten dann die ASCS-VM in derselben Zone und PPG bereit. In einem dritten Schritt haben Sie eine Azure-Verfügbarkeitsgruppen erstellt, die Verfügbarkeitsgruppen der bereichsgebundenen Näherungsplatzierungsgruppe zugewiesen und die SAP-Anwendungsebene darin bereitgestellt. Der Vorteil dieser Konfiguration bestand darin, dass alle Komponenten unter demselben Netzwerk-Rückgrat gut ausgerichtet waren. Der große Nachteil besteht darin, dass Ihre Flexibilität bei der VM-Größenänderung eingeschränkt werden kann.
Basierend auf vielen Verbesserungen, die von Microsoft in den Azure-Regionen bereitgestellt wurden, um die Netzwerklatenz innerhalb einer Azure-Verfügbarkeitszone zu reduzieren, sieht der aktuelle Bereitstellungsleitfaden für zonenbezogene Bereitstellungen wie folgt aus:
Näherungsplatzierungsgruppen und HANA Large Instances
Wenn einige Ihrer SAP-Systeme auf HANA Large Instances als Anwendungsschicht angewiesen sind, können erhebliche Verbesserungen in der Netzwerklatenz zwischen HANA Large Instances und Azure-VMs erzielt werden, wenn HANA Large Instances-Einheiten verwendet werden, die in Reihen oder Stempeln der Version 4 bereitgestellt werden. Eine der Verbesserungen besteht darin, dass HANA Large Instances-Einheiten direkt bei der Bereitstellung eine Näherungsplatzierungsgruppe erhalten. Sie können diese Näherungsplatzierungsgruppe verwenden, um VMs der Anwendungsschicht bereitzustellen. Folglich werden diese VMs im selben Rechenzentrum bereitgestellt, in dem sich auch die HANA Large Instances-Einheit befindet.
Um zu erkennen, ob Ihre HANA Large Instances-Einheit in einem Stempel oder einer Reihe der Revision 4 bereitgestellt wird, lesen Sie den Artikel Steuerung von HANA Large Instances in Azure über das Azure-Portal. In der Attributübersicht Ihrer HANA Large Instances-Einheit können Sie auch den Namen der Näherungsplatzierungsgruppe ermitteln, da sie bei der Bereitstellung Ihrer HANA Large Instances-Einheit erstellt wurde. Der in der Attributübersicht angezeigte Name ist der Name der Näherungsplatzierungsgruppe, in der Sie VMs der Anwendungsschicht bereitstellen sollten.
Im Vergleich zu SAP-Systemen, die nur virtuelle Azure-Computer verwenden, haben Sie bei Verwendung von HANA Large Instances weniger Flexibilität bei der Entscheidung, wie viele Azure-Ressourcengruppen Sie verwenden möchten. Alle HANA-Einheiten eines HANA Large Instances-Mandanten werden wie in diesem Artikel beschrieben in einer einzigen Ressourcengruppe zusammengefasst. Wenn Sie die Bereitstellung nicht auf verschiedene Mandanten aufteilen, um z.B. Produktions- und Nicht-Produktionssysteme oder andere Systeme zu trennen, werden alle Ihre HANA Large Instances-Einheiten in einem HANA Large Instances-Mandanten bereitgestellt. Dieser Mandant weist eine 1:1-Beziehung mit einer Ressourcengruppe auf. Für jede einzelne Einheit wird jedoch eine separate Näherungsplatzierungsgruppe definiert.
Infolgedessen sehen die Beziehungen zwischen Azure-Ressourcengruppen und Näherungsplatzierungsgruppen für einen einzelnen Mandanten wie hier gezeigt aus:

Nächste Schritte
Weitere Informationen finden Sie in der Dokumentation: