Debuggen eines Azure KI Search-Skillsets im Azure-Portal
Starten Sie eine portalbasierte Debugsitzung, um Fehler zu identifizieren und zu beheben, Änderungen zu überprüfen und dann mithilfe von Push an ein veröffentlichtes Skillset in Ihrem Azure KI Search-Dienst zu übertragen.
Eine Debugsitzung ist eine zwischengespeicherte Indexer- und Skillsetausführung, die auf ein einzelnes Dokument festgelegt ist und mit der Sie Ihre Änderungen interaktiv bearbeiten und testen können. Wenn Sie mit dem Debuggen fertig sind, können Sie Ihre Änderungen im Skillset speichern.
Hintergrundinformationen zur Funktionsweise einer Debugsitzung finden Sie unter Debugsitzungen in der Azure KI-Suche. Informationen zur praktischen Verwendung eines Debugworkflows mit einem Beispieldokument finden Sie unter Tutorial: Debuggen eines Skillsets mithilfe von Debugsitzungen.
Voraussetzungen
Eine vorhandene Anreicherungspipeline, einschließlich einer Datenquelle, eines Skillsets, eines Indexers und eines Indexes.
Die Rollenzuweisung Mitwirkender im Suchdienst.
Ein Azure Storage-Konto zum Speichern des Sitzungszustands
Eine Rollenzuweisung Mitwirkende an Storage Blobdaten in Azure Storage, wenn Sie eine systemseitig verwaltete Identität verwenden. Andernfalls planen Sie die Verwendung einer Verbindungszeichenfolge mit vollem Zugriff für die Debugsitzungsverbindung zu Azure Storage.
Wenn sich das Azure Storage-Konto hinter einer Firewall befindet, konfigurieren Sie diese so, dass der Zugriff auf den Suchdienst zugelassen ist.
Begrenzungen
Debugsitzungen funktionieren mit allen allgemein verfügbaren Indexerdatenquellen und den meisten Vorschaudatenquellen. Ausnahmen finden Sie in der folgenden Liste:
Azure Cosmos DB for MongoDB wird derzeit nicht unterstützt.
Azure Cosmos DB for NoSQL: Wenn während der Indizierung bei einer Zeile ein Fehler auftritt und keine entsprechenden Metadaten vorhanden sind, wird in der Debugsitzung möglicherweise nicht die richtige Zeile ausgewählt.
SQL-API von Azure Cosmos DB: Wenn eine partitionierte Sammlung vorher nicht partitioniert war, wird das Dokument in der Debugsitzung nicht gefunden.
Für benutzerdefinierte Skills wird eine benutzerseitig zugewiesene verwaltete Identität für eine Debugsitzungsverbindung mit Azure Storage nicht unterstützt. Wie in den Voraussetzungen angegeben, können Sie eine systemseitig verwaltete Identität verwenden oder eine Vollzugriffsverbindungszeichenfolge angeben, die einen Schlüssel enthält. Weitere Informationen finden Sie unter Verbinden eines Suchdiensts für andere Azure-Ressourcen mithilfe einer verwalteten Identität.
Das Portal unterstützt keine kundenseitig verwalteter Schlüsselverschlüsselung (CMK), was bedeutet, dass Portaloberflächen wie Debugsitzungen keine CMK-verschlüsselten Verbindungszeichenfolgen oder andere verschlüsselte Metadaten haben können. Wenn Ihr Suchdienst für die CMK-Erzwingung konfiguriert ist, funktionieren Debugsitzungen nicht.
Erstellen einer Debugsitzung
Melden Sie sich beim Azure-Portal an, und suchen Sie den Suchdienst.
Wählen Sie auf der linken Navigationsseite Debugsitzungen aus.
Wählen Sie in der Aktionsleiste oben die Option Debugsitzung hinzufügen aus.
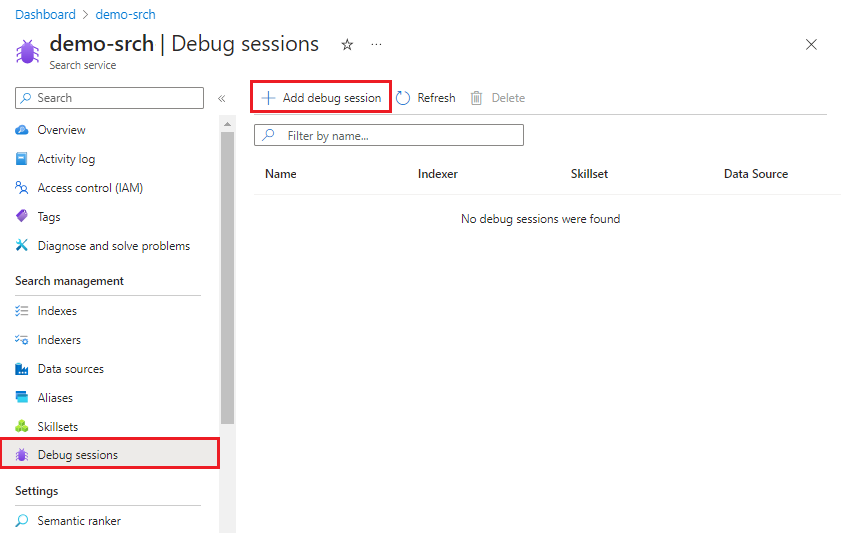
Geben Sie unter Name der Debugsitzung einen Namen an, der Ihnen hilft, sich zu merken, um welches Skillset, welchen Indexer und welche Datenquelle es sich bei der Debugsitzung handelt.
Suchen Sie unter Speicherverbindung ein universelles Speicherkonto für die Zwischenspeicherung der Debugsitzung. Sie werden aufgefordert, einen Blobcontainer in Blob Storage oder Azure Data Lake Storage Gen2 auszuwählen und optional zu erstellen. Sie können denselben Container für alle nachfolgenden Debugsitzungen wiederverwenden, die Sie erstellen. Ein hilfreicher Containername könnte „cognitive-search-debug-sessions“ sein.
Wählen Sie unter Authentifizierung der verwalteten IdentitätKeine aus, wenn die Verbindung mit Azure Storage keine verwaltete Identität verwendet. Wählen Sie andernfalls die verwaltete Identität aus, der Sie Berechtigungen für Mitwirkende an Storage Blobdaten erteilt haben.
Wählen Sie in der Indexervorlage den Indexer aus, der das Skillset steuert, das Sie debuggen möchten. Kopien von Indexer und Skillset werden zur Initialisierung der Sitzung verwendet.
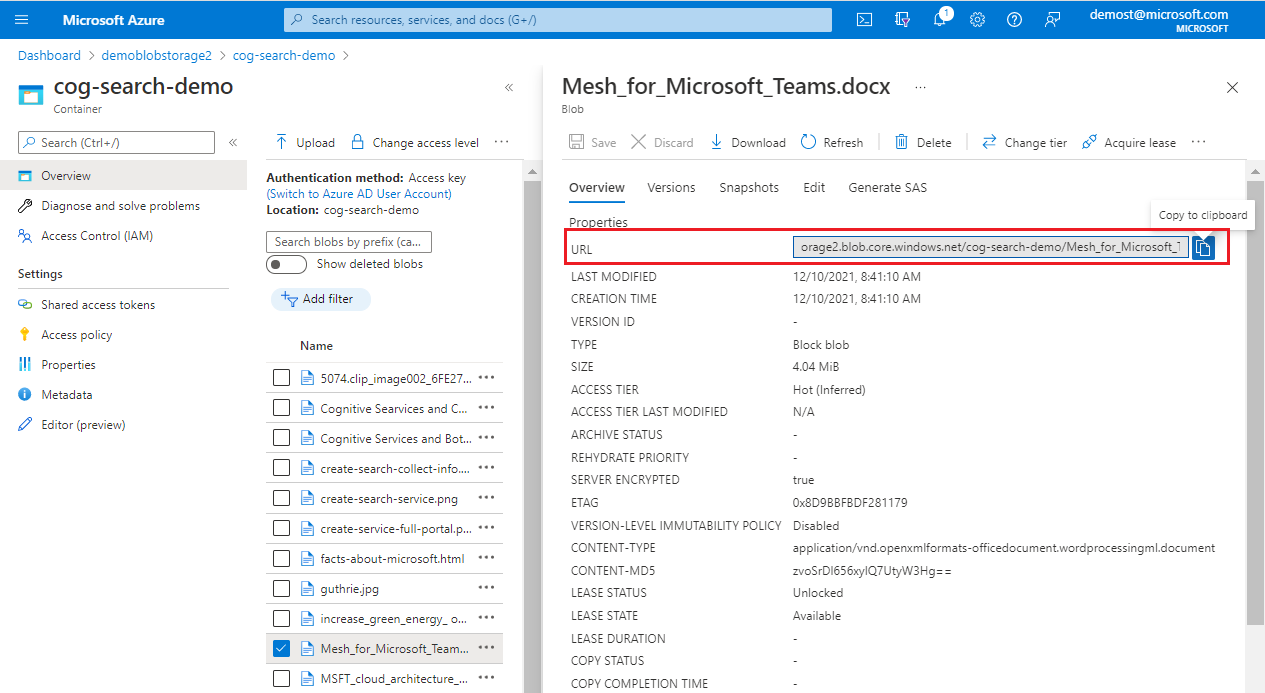
Wählen Sie unter Zu debuggendes Dokument das erste Dokument im Index oder ein bestimmtes Dokument aus. Wenn Sie ein bestimmtes Dokument auswählen, werden Sie, je nach Datenquelle, nach einer URI oder einer Zeilen-ID gefragt.
Wenn Ihr spezifisches Dokument ein Blob ist, geben Sie die Blob-URI an. Sie finden die URI auf der Blobeigenschaftsseite im Portal.
Optional können Sie unter Indexereinstellungen alle Ausführungseinstellungen für den Indexer festlegen, die zum Erstellen der Sitzung verwendet werden. Die Einstellungen sollten die vom tatsächlichen Indexer verwendeten Einstellungen imitieren. Alle Indexeroptionen, die Sie in einer Debugsitzung angeben, haben keine Auswirkungen auf den Indexer selbst.
Ihre Konfiguration sollte in etwa wie in diesem Screenshot aussehen. Wählen Sie Sitzung speichern aus, um zu beginnen.
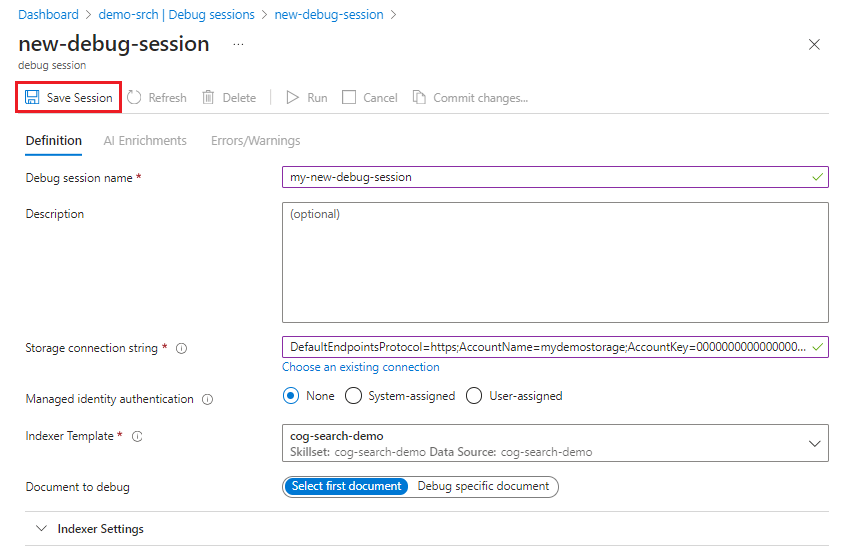
Die Debugsitzung beginnt mit der Ausführung des Indexers und Skillsets für das ausgewählte Dokument. Der Inhalt und die erstellten Metadaten des Dokuments werden angezeigt und sind in der Sitzung verfügbar.
Eine Debugsitzung kann während der Ausführung mithilfe der Schaltfläche Abbrechen abgebrochen werden. Wenn Sie auf die Schaltfläche Abbrechen klicken, sollten Sie in der Lage sein, Teilergebnisse zu analysieren.
Es ist zu erwarten, dass die Ausführung einer Debugsitzung länger dauert als die des Indexers, da sie eine zusätzliche Verarbeitung durchläuft.
Beginnen mit Fehlern und Warnungen
Der Indexerausführungsverlauf im Portal enthält die vollständige Fehler- und Warnungsliste für alle Dokumente. In einer Debugsitzung sind die Fehler und Warnungen auf ein Dokument beschränkt. Sie arbeiten diese Liste durch, nehmen Änderungen vor und kehren dann zur Liste zurück, um zu überprüfen, ob die Probleme behoben wurden.
Um die Meldungen anzuzeigen, wählen Sie unter KI-Anreicherung > Skillgraph einen Skill aus, und klicken Sie dann im Detailbereich auf Fehler/Warnungen.
Als bewährte Methode sollten Sie Probleme mit Eingaben beheben, bevor Sie mit den Ausgaben fortfahren.
Um nachzuweisen, ob eine Änderung einen Fehler behebt, führen Sie die folgenden Schritte aus:
Klicken Sie im Detailbereich für den Skill auf Speichern, um Ihre Änderungen zu speichern.
Klicken Sie im Sitzungsfenster auf Ausführen, um die Skillsetausführung mithilfe der geänderten Definition aufzurufen.
Wechseln Sie zurück zu Fehler/Warnungen, um herauszufinden, ob die Anzahl reduziert wurde. Die Liste wird erst aktualisiert, wenn Sie die Registerkarte öffnen.
Anzeigen des Inhalts von Anreicherungsknoten
KI-Anreicherungspipelines extrahieren Informationen und Strukturen aus Quelldokumenten oder leiten diese ab, um ein angereichertes Dokument zu erstellen. Ein angereichertes Dokument wird zuerst während der Dokumententschlüsselung erstellt und mit einem Stammknoten (/document) plus Knoten für alle Inhalte aufgefüllt, die direkt aus der Datenquelle heraufgestuft werden, etwa einem Dokumentschlüssel und Metadaten. Weitere Knoten werden während der Skillausführung durch Skills erstellt, wobei jede Skillausgabe der Anreicherungsstruktur einen neuen Knoten hinzufügt.
Angereicherte Dokumente sind intern, aber eine Debugsitzung bietet Ihnen Zugriff auf den Inhalt, der während der Skillausführung erstellt wird. Führen Sie die folgenden Schritte aus, um den Inhalt oder die Ausgabe der einzelnen Skills anzuzeigen:
Beginnen Sie mit den Standardansichten KI-Anreicherung > Skillgraph, wobei der Graphtyp auf Abhängigkeitsdiagramm festgelegt ist.
Wählen Sie einen Skill aus.
Wählen Sie im Detailbereich auf der rechten Seite Ausführungen und eine AUSGABE aus, und öffnen Sie dann die Ausdrucksauswertung (
</>), um den Ausdruck und dessen Ergebnis anzuzeigen.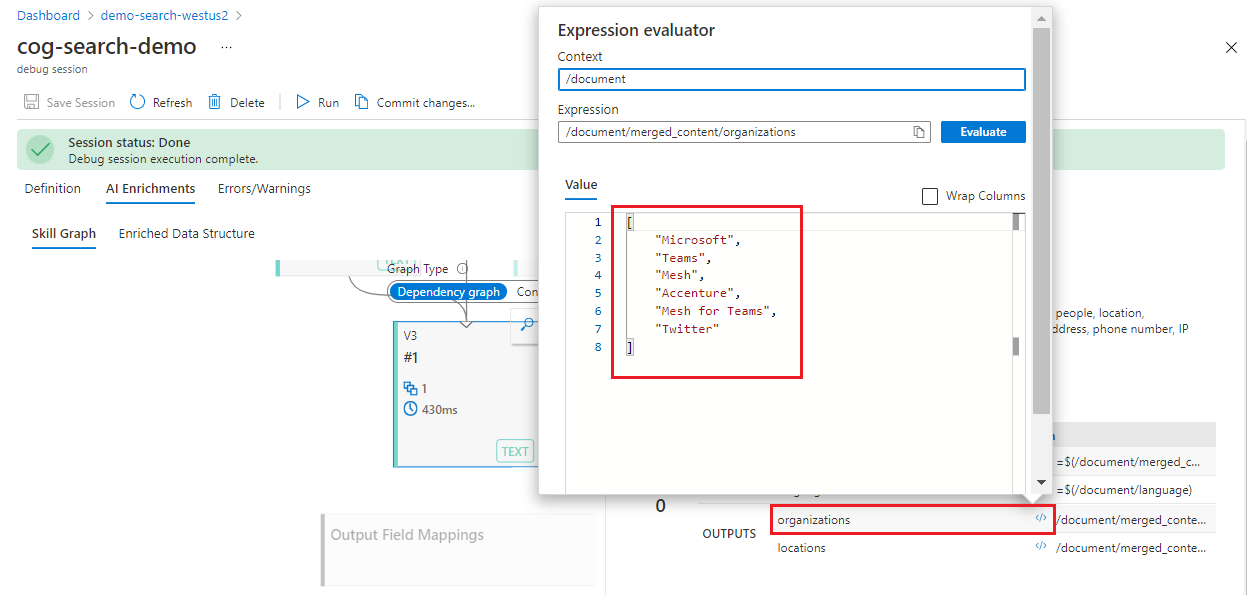
Öffnen Sie alternativ AI enrichment > Enriched Data Structure („KI-Anreicherung“ > „Angereicherte Datenstruktur“), um in der Liste der Knoten nach unten zu scrollen. Die Liste enthält potenzielle und tatsächliche Knoten mit einer Spalte für die Ausgabe und eine weitere Spalte, die das Upstreamobjekt angibt, das zum Generieren der Ausgabe verwendet wird.
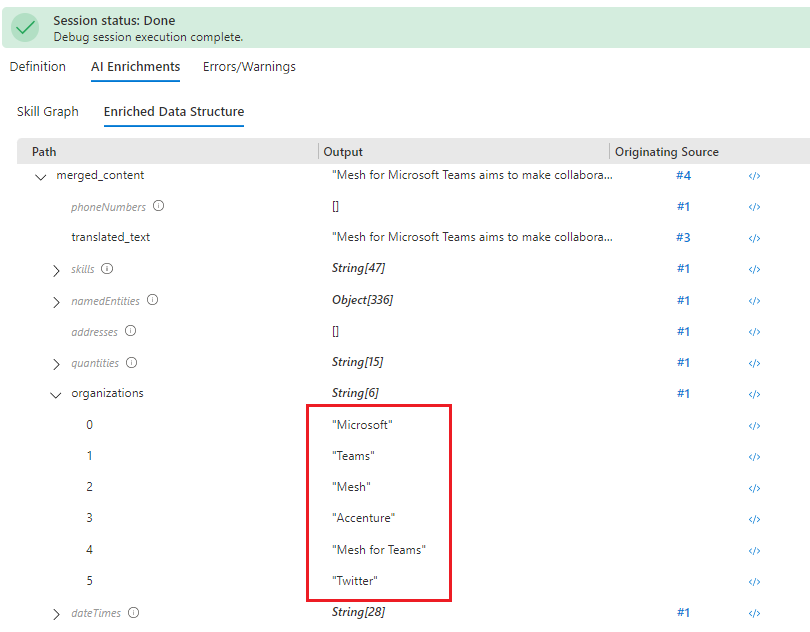
Bearbeiten von Skilldefinitionen
Wenn die Feldzuordnungen richtig sind, überprüfen Sie die einzelnen Skills auf Konfiguration und Inhalt. Wenn ein Skill keine Ausgabe erzeugt, fehlt möglicherweise eine Eigenschaft oder ein Parameter, die durch Fehler- und Validierungsmeldungen ermittelt werden können.
Andere Probleme wie ein ungültiger Kontext oder ein ungültiger Eingabeausdruck können schwieriger zu beheben sein, da der Fehler Sie darüber informiert, was das Problem ist, aber nicht, wie Sie es beheben können. Hilfe zur Kontext- und Eingabesyntax finden Sie unter Verweisen auf Anmerkungen in einem Azure KI-Suche-Skillset. Informationen zu einzelnen Meldungen finden Sie unter Beheben von häufigen Fehler und Warnungen bei Suchindexern in Azure Cognitive Search.
In den folgenden Schritten wird gezeigt, wie Sie Informationen zu einem Skill abrufen.
Wählen Sie unter KI-Anreicherung > Skillgraph einen Skill aus. Auf der rechten Seite wird der Bereich „Skilldetails“ geöffnet.
Bearbeiten Sie eine Skilldefinition mit einem dieser Ansätze:
- Skilleinstellungen, wenn Sie einen visuellen Editor bevorzugen
- Skill-JSON-Editor zum direkten Bearbeiten des JSON-Dokuments
Überprüfen Sie die Pfadsyntax zum Verweisen auf Knoten in einer Anreicherungsstruktur. Im Folgenden finden Sie einige der gängigsten Eingabepfade:
/document/contentfür Textblöcke. Dieser Knoten wird über die Inhaltseigenschaft des Blobs aufgefüllt./document/merged_contentfür Textblöcke in Skillsets, die den Skill für die Textzusammenführung enthalten/document/normalized_images/*für Text, der erkannt oder von Bildern abgeleitet wird
Überprüfen von Feldzuordnungen
Wenn Skills eine Ausgabe erzeugen, der Suchindex jedoch leer ist, überprüfen Sie die Feldzuordnungen. Feldzuordnungen geben an, wie Inhalt aus der Pipeline in einen Suchindex bewegt wird.
Beginnen Sie mit den Standardansichten KI-Anreicherung > Skillgraph, wobei der Graphtyp auf Abhängigkeitsdiagramm festgelegt ist.
Klicken Sie oben auf Feldzuordnungen. Es sollte mindestens der Dokumentschlüssel angezeigt werden, der jedes Suchdokument im Suchindex eindeutig identifiziert und dem Quelldokument in der Datenquelle zuordnet.
Wenn Sie unformatierten Inhalt direkt aus der Datenquelle importieren und die Anreicherung umgehen, sollten diese Felder unter Feldzuordnungen angezeigt werden.
Klicken Sie unten im Graphen auf Ausgabefeldzuordnungen. Hier werden die Zuordnungen von Skillausgaben zu Zielfeldern im Suchindex angezeigt. Sofern Sie den Datenimport-Assistenten nicht verwendet haben, werden Ausgabefeldzuordnungen manuell definiert und können unvollständig oder falsch typisiert sein.
Überprüfen Sie, ob die Felder unter Ausgabefeldzuordnungen im Suchindex wie angegeben vorhanden sind, und überprüfen Sie die Rechtschreibung und die Syntax für Anreicherungsknotenpfade.
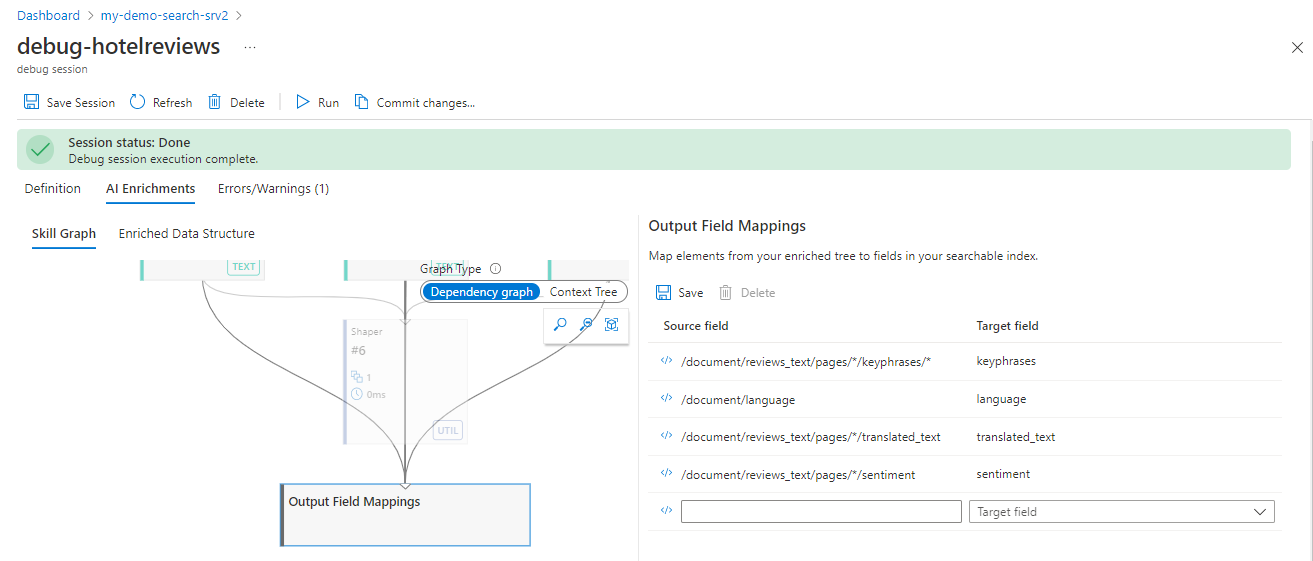
Lokales Debuggen eines benutzerdefinierten Skills
Das Debuggen benutzerdefinierter Skills kann schwieriger sein, da der Code extern ausgeführt wird, sodass die Debugsitzung nicht verwendet werden kann, um sie zu debuggen. In diesem Abschnitt wird beschrieben, wie Sie Ihren benutzerdefinierten Web-API-Skill, Debugsitzung, Visual Studio Code und ngrok oder Tunnelmole lokal debuggen. Diese Technik kann für benutzerdefinierte Skills verwendet werden, die in Azure Functions oder einem anderen lokal ausgeführten Webframework ausgeführt werden (z. B. FastAPI).
Abrufen einer öffentlichen URL
Verwenden von Tunnelmole
Tunnelmole ist ein Open-Source-Tunnelingtool, mit dem Sie eine öffentliche URL erstellen können, die Anforderungen an Ihren lokalen Computer durch einen Tunnel weiterleitet.
Installieren von Tunnelmole:
- npm:
npm install -g tunnelmole - Linux:
curl -s https://tunnelmole.com/sh/install-linux.sh | sudo bash - Mac:
curl -s https://tunnelmole.com/sh/install-mac.sh --output install-mac.sh && sudo bash install-mac.sh - Windows: Installation mithilfe von npm. Oder wenn Sie NodeJS nicht installiert haben, laden Sie die vorkompilierte EXE-Datei für Windows herunter und legen Sie sie irgendwo in Ihrem PATH ab.
- npm:
Führen Sie diesen Befehl aus, um einen neuen Tunnel zu erstellen:
tmole 7071Die Antwort sollte in etwa wie folgt aussehen:
http://m5hdpb-ip-49-183-170-144.tunnelmole.net is forwarding to localhost:7071 https://m5hdpb-ip-49-183-170-144.tunnelmole.net is forwarding to localhost:7071Im vorherigen Beispiel leitet
https://m5hdpb-ip-49-183-170-144.tunnelmole.netan Port7071auf Ihrem lokalen Computer weiter. Dies ist der Standardport, an dem Azure-Funktionen verfügbar gemacht werden.
Verwenden von ngrok
ngrok ist eine beliebte, plattformübergreifende Closed-Source-Anwendung, die eine Tunneling- oder Weiterleitungs-URL erstellen kann, sodass Internetanforderungen Ihren lokalen Computer erreichen. Verwenden Sie ngrok, um Anforderungen aus einer Anreicherungspipeline in Ihrem Suchdienst an Ihren Computer weiterzuleiten, um das lokale Debuggen zu ermöglichen.
Installieren Sie ngrok.
Öffnen Sie ein Terminal, und wechseln Sie zum Ordner mit der ausführbaren ngrok-Datei.
Führen Sie ngrok mit dem folgenden Befehl aus, um einen neuen Tunnel zu erstellen:
ngrok http 7071Hinweis
Standardmäßig wird Azure Functions an 7071 verfügbar gemacht. Andere Tools und Konfigurationen erfordern möglicherweise, dass Sie einen anderen Port bereitstellen.
Wenn ngrok gestartet wird, kopieren und speichern Sie die Weiterleitungs-URL für den nächsten Schritt. Die Weiterleitungs-URL wird zufällig generiert.
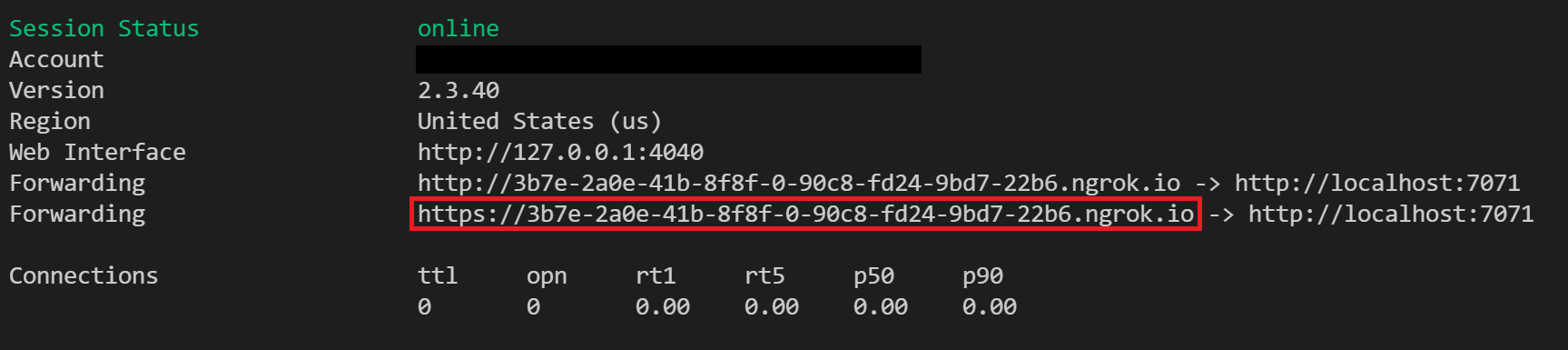
Konfigurieren im Azure-Portal
Ändern Sie in der Debugsitzung Ihren benutzerdefinierten Web-API-Skill-URI, um die Tunnelmole- oder ngrok-Weiterleitungs-URL aufzurufen. Bei Verwendung von Azure Function zum Ausführen des Skillsetcodes müssen Sie„/api/FunctionName“ anfügen.
Sie können die Definition des Skills im Portal bearbeiten.
Testen Ihres Codes
An diesem Punkt sollten neue Anforderungen aus Ihrer Debugsitzung jetzt an Ihre lokale Azure Function-Instanz gesendet werden. Sie können in Ihrem Visual Studio Code Breakpoints verwenden, um Ihren Code zu debuggen oder schrittweise auszuführen.
Nächste Schritte
Nachdem Sie sich nun mit dem Layout und den Funktionen des visuellen Editors für Debugsitzungen vertraut gemacht haben, schließen Sie das Tutorial ab, um praktische Erfahrung zu sammeln.