Ausführen oder Zurücksetzen von Indexern, Qualifikationen oder Dokumenten
In Azure KI Search gibt es mehrere Möglichkeiten, einen Indexer auszuführen:
- Ausführen beim Erstellen eines Indexers, unter der Voraussetzung, dass er nicht im „deaktivierten“ Modus erstellt wird.
- Ausführen nach einem Zeitplan, um die Ausführung in regelmäßigen Intervallen aufzurufen.
- Ausführen nach Bedarf, mit oder ohne „Zurücksetzen“.
Dieser Artikel erläutert das On-Demand-Ausführen von Indexern mit und ohne Zurücksetzen. Außerdem werden die Indexerausführung, ihre Dauer und die Parallelität beschrieben.
Herstellen einer Verbindung zwischen Indexern und Azure-Ressourcen
Indexer sind eines der wenigen Subsysteme, die offene ausgehende Anrufe an andere Azure-Ressourcen tätigen. In Bezug auf Azure-Rollen haben Indexer keine separaten Identitäten: eine Verbindung von der Suchmaschine zu einer anderen Azure-Ressource wird über die system- oder benutzerseitig zugewiesene verwaltete Identität eines Suchdienstes hergestellt. Wenn der Indexer eine Verbindung zu einer Azure-Ressource in einem virtuellen Netzwerk herstellt, sollten Sie eine gemeinsame private Verbindung dafür erstellen. Weitere Informationen zu sicheren Verbindungen finden Sie unter Sicherheit für die Azure KI-Suche.
Indexer-Ausführung
Ein Suchdienst führt einen Indexerauftrag pro Sucheinheit aus. Jeder Suchdienst beginnt mit einer Sucheinheit, aber jede neue Partition oder jedes Replikat erhöht die Anzahl der Sucheinheiten Ihres Diensts. Sie können die Anzahl der Sucheinheiten im Portal im Abschnitt „Grundlagen“ auf der Seite Übersicht überprüfen. Wenn Sie die gleichzeitige Verarbeitung benötigen, stellen Sie sicher, dass Sie über ausreichende Replikate verfügen. Indexer werden nicht im Hintergrund ausgeführt, sodass Sie möglicherweise eine höhere Abfragedrosselung erkennen als üblich, wenn der Dienst stark ausgelastet ist.
Der folgende Screenshot zeigt die Anzahl der Sucheinheiten, die bestimmt, wie viele Indexer gleichzeitig ausgeführt werden können.

Nachdem die Indexerausführung gestartet wurde, können Sie sie nicht mehr anhalten oder beenden. Die Indexerausführung wird beendet, wenn keine Dokumente geladen oder aktualisiert werden müssen oder wenn der Grenzwert für die maximale Laufzeit erreicht ist.
Sie können mehrere Indexer gleichzeitig ausführen, sofern ausreichend Kapazität vorhanden ist, aber jeder Indexer ist selbst eine Einzelinstanz. Wenn Sie eine neue Instanz starten, während der Indexer bereits ausgeführt wird, tritt der folgende Fehler auf: "Failed to run indexer "<indexer name>" error: "Another indexer invocation is currently in progress; concurrent invocations are not allowed."
Ein Indexerauftrag wird in einer verwalteten Ausführungsumgebung ausgeführt. Aktuell gibt es zwei Umgebungen. Welche Umgebung verwendet wird, können Sie nicht steuern oder konfigurieren. Azure KI-Suche bestimmt die Umgebung auf der Grundlage der Auftragszusammensetzung und der Fähigkeit des Diensts, einen Indexerauftrag auf einen Inhaltsprozessor zu verschieben (einige Sicherheitsfeatures blockieren die mehrinstanzenfähige Umgebung).
Zu den Umgebungen für die Indexerausführung gehören:
Eine private Ausführungsumgebung, die auf Suchknoten ausgeführt wird und für Ihren Suchdienst spezifisch ist.
Eine mehrinstanzenfähige Umgebung mit Inhaltsprozessoren, die von Microsoft ohne zusätzliche Kosten verwaltet und geschützt wird. Diese Umgebung wird verwendet, um rechenintensive Verarbeitungen auszulagern, sodass dienstspezifische Ressourcen für Routineoperationen verfügbar bleiben. Die meisten Indexeraufträge werden nach Möglichkeit immer in der mehrinstanzenfähigen Umgebung ausgeführt.
Indexergrenzwerte unterscheiden sich nach den einzelnen Umgebungen:
| Workload | Maximale Dauer | Maximale Anzahl von Aufträgen | Ausführungsumgebung |
|---|---|---|---|
| Private Ausführung | 24 Stunden | Ein Indexerauftrag pro Sucheinheit1. | Die Indizierung wird nicht im Hintergrund durchgeführt. Stattdessen werden alle Indizierungsaufträge mit laufenden Abfragen und Objektverwaltungsaktionen (beispielsweise Erstellen oder Aktualisieren von Indizes) abgestimmt. Beim Ausführen von Indexern mit großem Indizierungsvolumen muss mit einer gewissen Wartezeit bei Abfragen gerechnet werden. |
| Mehrere Mandanten | 2 Stunden 2 | Unbestimmt 3 | Da der Inhaltsverarbeitungscluster mehrere Mandanten hat, werden Knoten hinzugefügt, um den Bedarf zu erfüllen. Wenn bei der bedarfsbasierten oder geplanten Ausführung eine Verzögerung auftritt, liegt dies wahrscheinlich daran, dass das System entweder Knoten hinzufügt oder auf die Verfügbarkeit eines Knotens wartet. |
1 Sucheinheiten können flexible Kombinationen aus Partitionen und Replikaten sein, jedoch sind die Indexeraufträge weder an das eine noch an das andere gebunden. Wenn Sie also über 12 Einheiten verfügen, können 12 Indexeraufträge gleichzeitig in privater Ausführung ausgeführt werden, unabhängig davon, wie die Sucheinheiten bereitgestellt wurden.
2 Wenn mehr als zwei Stunden benötigt werden, um alle Daten zu verarbeiten, aktivieren Sie die Änderungserkennung, und planen Sie die Ausführung des Indexers in Abständen von zwei Stunden. Weitere Strategien finden Sie unter Indizieren eines großen Datasets.
3 „Unbestimmt“ bedeutet, dass das Limit nicht durch die Anzahl der Aufträge quantifiziert wird. Einige Workloads, z. B. die Verarbeitung von Skillsets, können parallel ausgeführt werden, was zu vielen Aufträgen führen kann, obwohl nur ein Indexer beteiligt ist. Zwar erlegt die Umgebung keine Einschränkungen auf, trotzdem gelten für Ihren Suchdienst Indexergrenzwerte.
Ausführen ohne Zurücksetzen
Ein Vorgang Indexer ausführen erkennt und verarbeitet nur, was zum Synchronisieren des Suchindex mit Änderungen an der zugrundeliegenden Datenquelle erforderlich ist. Bei der inkrementellen Indizierung wird zunächst nach einer internen Obergrenze gesucht, um das zuletzt aktualisierte Suchdokument zu finden. Dieses wird zum Ausgangspunkt für die Indexerausführung für neue und aktualisierte Dokumente in der Datenquelle.
Die Änderungserkennung ist wichtig, um zu bestimmen, was an der Datenquelle neu ist oder aktualisiert wurde. Indexer verwenden die Funktionen zur Änderungserkennung der zugrunde liegenden Datenquelle, um zu bestimmen, was an der Datenquelle neu ist oder aktualisiert wurde.
Azure Storage verfügt über eine integrierte Änderungserkennung in Form der Eigenschaft „LastModified“.
Andere Datenquellen wie Azure SQL oder Azure Cosmos DB müssen für die Änderungserkennung konfiguriert werden, damit der Indexer neue und aktualisierte Zeilen lesen kann.
Wenn der zugrunde liegende Inhalt unverändert ist, hat ein Ausführungsvorgang keine Auswirkung. In diesem Fall weist der Indexerausführungsverlauf 0\0 verarbeitete Dokumente aus.
Sie müssen den Indexer zurücksetzen, wie im nächsten Abschnitt erläutert, um ihn vollständig neu zu verarbeiten.
Zurücksetzen von Indexern
Nach der ersten Ausführung verfolgt ein Indexer über eine interne obere Grenze, welche Suchdokumente indiziert wurden. Der Marker wird nie verfügbar gemacht, intern weiß der Indexer aber, wo er zuletzt angehalten wurde.
Wenn Sie einen Index ganz oder teilweise neu erstellen müssen, können Sie die Obergrenze des Indexers mittels Zurücksetzen löschen. Rücksetz-APIs sind in der Objekthierarchie auf abnehmenden Ebenen verfügbar:
- Reset Indexers (Indexer zurücksetzen) löscht die Obergrenze und führt eine vollständige Neuindizierung aller Dokumente durch.
- Reset Documents (preview) (Dokumente zurücksetzen (Vorschauversion)) indiziert ein bestimmtes Dokument oder eine Liste von Dokumenten neu.
- Reset Skills (preview) (Skills zurücksetzen (Vorschauversion)) ruft die Skillverarbeitung für einen bestimmten Skill auf.
Führen Sie nach dem Zurücksetzen einen Ausführungsbefehl aus, um neue und vorhandene Dokumente erneut zu verarbeiten. Verwaiste Suchdokumente ohne Entsprechung in der Datenquelle können nicht durch Zurücksetzen/Ausführen entfernt werden. Informationen zum Löschen von Dokumenten finden Sie unter Hinzufügen, Aktualisieren oder Löschen von Dokumenten (Azure Cognitive Search-REST-API).
Zurücksetzen und Ausführen von Indexern
Durch das Zurücksetzen wird die Obergrenze gelöscht. Alle Dokumente im Suchindex werden für vollständiges Überschreiben ohne Inlineaktualisierungen oder Zusammenführung mit vorhandenen Inhalten gekennzeichnet. Bei Indexern mit einem Skillset und Anreicherungszwischenspeicherung wird durch das Zurücksetzen des Index implizit auch das Skillset zurückgesetzt.
Die eigentliche Arbeit beginnt erst, wenn Sie nach dem Zurücksetzen einen Ausführungsbefehl ausführen:
- Alle neuen Dokumente, die in der zugrunde liegenden Quelle gefunden werden, werden dem Suchindex hinzugefügt.
- Alle Dokumente, die sowohl in der Datenquelle als auch im Suchindex enthalten sind, werden im Suchindex überschrieben.
- Alle angereicherten Inhalte, die auf der Grundlage des Skillsets erstellt wurden, werden neu erstellt. Ist ein Anreicherungscache aktiviert, wird dieser aktualisiert.
Wie bereits erwähnt, ist das Zurücksetzen ein passiver Vorgang: Zur Neuerstellung des Index muss eine Ausführungsanforderung ausgeführt werden.
Zurücksetzungs-/Ausführungsvorgänge gelten für einen Suchindex oder einen Wissensspeicher, für bestimmte Dokumente oder Projektionen und für zwischengespeicherte Anreicherungen, wenn eine Zurücksetzung explizit oder implizit Skills enthält.
Das Zurücksetzen betrifft außerdem Erstellungs- und Aktualisierungsvorgänge. Es löst keine Löschung oder Bereinigung verwaister Dokumente im Suchindex aus. Weitere Informationen zum Löschen von Dokumenten finden Sie unter Hinzufügen, Aktualisieren oder Löschen von Dokumenten (Azure Cognitive Search-REST-API).
Das Zurücksetzen eines Indexers kann nicht rückgängig gemacht werden.
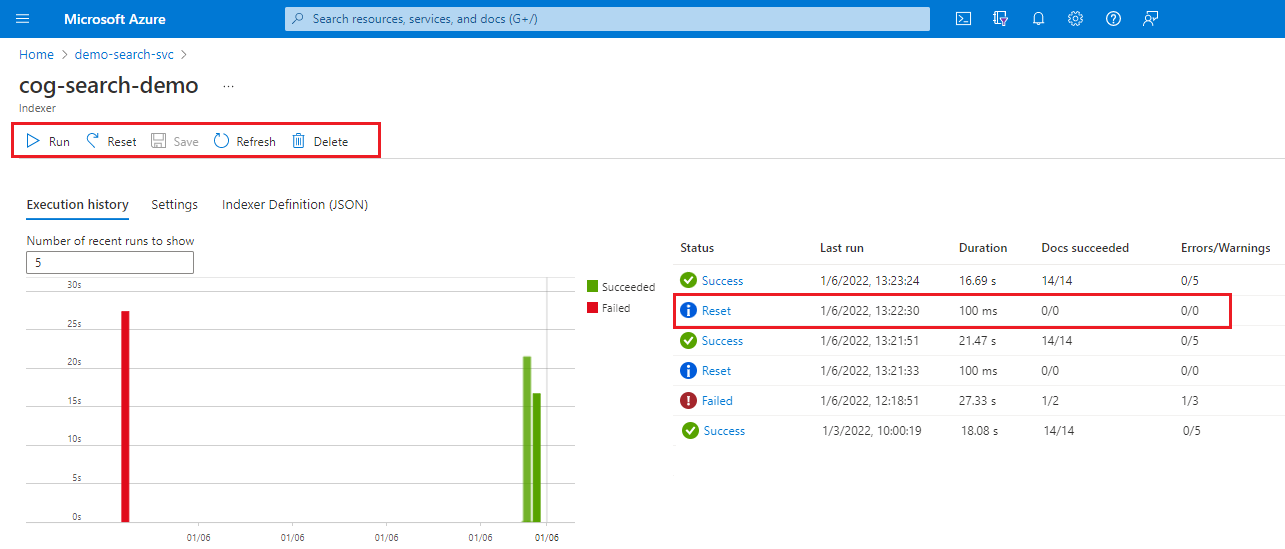
Melden Sie sich beim Azure-Portal an, und öffnen Sie die Seite des Suchdiensts.
Wählen Sie auf der Seite Übersicht die Registerkarte Indizes aus.
Wählen Sie einen Indexer aus.
Wählen Sie den Befehl Zurücksetzen und anschließend Ja aus, um die Aktion zu bestätigen.
Aktualisieren Sie die Seite, um den Status anzuzeigen. Sie können das Element auswählen, um die zugehörigen Details anzuzeigen.
Wählen Sie Ausführen aus, um die Indexerverarbeitung zu starten, oder warten Sie auf die nächste geplante Ausführung.
Zurücksetzen von Skills (Vorschau)
Bei Indexern mit Skillsets können bestimmte Skills zurückgesetzt werden, um die Verarbeitung des spezifischen Skills und aller nachgelagerten Skills zu erzwingen, die von dessen Ausgabe abhängen. Falls der Anreicherungscache aktiviert wurde, wird er ebenfalls aktualisiert.
Reset Skills (Skills zurücksetzen) ist derzeit nur REST-basiert und über api-version=2020-06-30-Previewoder höher verfügbar.
POST /skillsets/[skillset name]/resetskills?api-version=2020-06-30-Preview
{
"skillNames" : [
"#1",
"#5",
"#6"
]
}
Sie können individuelle Fertigkeiten angeben, wie im obigen Beispiel gezeigt, aber wenn eine dieser Fertigkeiten eine Ausgabe aus nicht aufgelisteten Fertigkeiten (2 bis 4) erfordert, werden nicht aufgelistete Fertigkeiten ausgeführt, sofern der Cache die erforderlichen Informationen nicht bereitstellen kann. Damit dies zutrifft, dürfen zwischengespeicherte Anreicherungen für Fertigkeiten 2 bis 4 keine Abhängigkeit von 1 (für die Zurücksetzung aufgelistet) aufweisen.
Wenn keine Fertigkeiten angegeben werden, wird das gesamte Skillset ausgeführt, und wenn das Zwischenspeichern aktiviert ist, wird der Cache ebenfalls aktualisiert.
Denken Sie daran, anschließend den Indexer auszuführen, um die eigentliche Verarbeitung aufzurufen.
Zurücksetzen von Dokumenten (Vorschau)
Die API zum Zurücksetzen von Dokumenten akzeptiert eine Liste von Dokumentschlüsseln, damit Sie bestimmte Dokumente aktualisieren können. Wenn angegeben, sind die Rücksetzungsparameter unabhängig von anderen Änderungen in den zugrunde liegenden Daten allein dafür ausschlaggebend, was verarbeitet wird. Wenn z. B. seit der letzten Indexerausführung 20 Blobs hinzugefügt oder aktualisiert wurden, Sie aber nur ein Dokument zurücksetzen, wird nur dieses eine Dokument verarbeitet.
Auf Dokumentbasis werden alle Felder in diesem Suchdokument mit Werten aus der Datenquelle aktualisiert. Sie können nicht auswählen, welche Felder aktualisiert werden sollen.
Wenn das Dokument durch ein Skillset angereichert wird und zwischengespeicherte Daten enthält, wird das Skillset nur für die angegebenen Dokumente aufgerufen, und der Cache wird für die neu verarbeiteten Dokumente aktualisiert.
Wenn Sie diese API zum ersten Mal testen, können Sie mithilfe der folgenden APIs die Verhaltensweisen validieren und testen:
Rufen Sie den Vorgang zum Abrufen des Indexerstatus mit der API-Version
api-version=2020-06-30-Preview(oder höher) auf, um den Status der Zurücksetzung und den Ausführungsstatus zu überprüfen. Informationen über die Rücksetzungsanforderung finden Sie am Ende der Statusantwort.Rufen Sie den Vorgang zum Zurücksetzen von Dokumenten mit der API-Version
api-version=2020-06-30-Preview(oder höher) auf, um anzugeben, welche Dokumente verarbeitet werden sollen.POST https://[service name].search.windows.net/indexers/[indexer name]/resetdocs?api-version=2020-06-30-Preview { "documentKeys" : [ "1001", "4452" ] }Die in der Anforderung bereitgestellten Dokumentschlüssel sind Werte aus dem Suchindex, die sich von den entsprechenden Feldern in der Datenquelle unterscheiden können. Wenn Sie sich hinsichtlich des Schlüsselwerts nicht sicher sind, senden Sie eine Abfrage, um den Wert zurückzugeben. Sie können
selectverwenden, um nur das Dokumentschlüsselfeld zurückzugeben.Für Blobs, die in mehreren Suchdokumenten analysiert werden (wenn parsingMode auf jsonLines oder jsonArrays bzw. delimitedText festgelegt wird), wird der Dokumentschlüssel vom Indexer generiert und ist Ihnen möglicherweise unbekannt. In diesem Szenario gibt eine Abfrage für den Dokumentschlüssel den richtigen Wert zurück.
Rufen Sie den Vorgang zum Ausführen des Indexers (beliebige API-Version) auf, um die von Ihnen angegebenen Dokumente zu verarbeiten. Nur diese spezifischen Dokumente werden indiziert.
Rufen Sie den Vorgang zum Ausführen des Indexers ein zweites Mal auf, um die Verarbeitung ab der letzten Obergrenze durchzuführen.
Rufen Sie den Vorgang zum Durchsuchen von Dokumenten auf, um nach aktualisierten Werten zu suchen und um Dokumentschlüssel zurückzugeben, wenn Sie sich bei deren Wert nicht sicher sind. Verwenden Sie
"select": "<field names>", wenn Sie einschränken möchten, welche Felder in der Antwort angezeigt werden.
Überschreiben der Dokumentschlüsselliste
Wenn Sie die API zum Zurücksetzen von Dokumenten mehrmals mit unterschiedlichen Schlüsseln aufrufen, werden die neuen Schlüssel am Ende der Liste der zurückgesetzten Dokumentschlüssel hinzugefügt. Wenn Sie beim Aufrufen der API den Parameter overwrite auf „true“ festlegen, wird die aktuelle Liste mit der neuen Liste überschrieben:
POST https://[service name].search.windows.net/indexers/[indexer name]/resetdocs?api-version=2020-06-30-Preview
{
"documentKeys" : [
"200",
"630"
],
"overwrite": true
}
Überprüfen des Zurücksetzungsstatus „currentState“
Wenn Sie den Zurücksetzungsstatus überprüfen und ermitteln möchten, welche Dokumentschlüssel zur Verarbeitung in die Warteschlange eingereiht wurden, gehen Sie wie folgt vor:
Rufen Sie den Vorgang zum Abrufen des Indexerstatus mit
api-version=06-30-2020-Preview(oder höher) auf.Von der Vorschau-API wird der Abschnitt
currentStatezurückgegeben. Dieser befindet sich am Ende der Antwort."currentState": { "mode": "indexingResetDocs", "allDocsInitialTrackingState": "{\"LastFullEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"LastAttemptedEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"NameHighWaterMark\":null}", "allDocsFinalTrackingState": "{\"LastFullEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"LastAttemptedEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"NameHighWaterMark\":null}", "resetDocsInitialTrackingState": null, "resetDocsFinalTrackingState": null, "resetDocumentKeys": [ "200", "630" ] }Überprüfen Sie die Angabe für den Modus (mode):
Für das Zurücksetzen von Skills muss der Modus auf
indexingAllDocsfestgelegt sein, da bei den Feldern, die durch die KI-Anreicherung aufgefüllt werden, potenziell alle Dokumente betroffen sind.Für das Zurücksetzen von Dokumenten muss der Modus auf
indexingResetDocsfestgelegt sein. Der Indexer behält diesen Status so lange bei, bis alle Dokumentschlüssel im Aufruf zum Zurücksetzen der Dokumente verarbeitet sind. Während dieser Zeit werden keine anderen Indexeraufträge ausgeführt. Um alle Dokumente in der Dokumentschlüsselliste zu finden, muss jedes Dokument zum Suchen und Abgleichen mit dem Schlüssel geöffnet werden. Dies kann bei großen Datasets einige Zeit in Anspruch nehmen. Wenn ein Blobcontainer Hunderte von Blobs enthält und sich die zurückzusetzenden Dokumente am Ende befinden, findet der Indexer die entsprechenden Blobs erst, wenn alle anderen zuerst geprüft wurden.Rufen Sie nach der erneuten Verarbeitung der Dokumente noch einmal den Indexerstatus ab. Der Indexer kehrt zum Modus
indexingAllDocszurück und verarbeitet neue oder aktualisierte Dokumente bei der nächsten Ausführung.
Nächste Schritte
Rücksetz-APIs werden verwendet, um über den Umfang der nächsten Indexerausführung zu informieren. Zur eigentlichen Verarbeitung müssen Sie eine bedarfsgesteuerte Indexerausführung aufrufen oder einen geplanten Auftrag zum Abschließen der Arbeit zulassen. Nachdem die Ausführung abgeschlossen ist, kehrt der Indexer unabhängig davon, ob es sich um eine Verarbeitung nach Zeitplan oder eine bedarfsgesteuerte Verarbeitung handelt, zur normalen Verarbeitung zurück.
Nachdem Sie Indexeraufträge zurückgesetzt und erneut ausgeführt haben, können Sie den Status vom Suchdienst aus überwachen oder ausführliche Informationen über die Diagnoseprotokollierung abrufen.