Sie möchten sich über Service Fabric informieren?
Azure Service Fabric ist eine Plattform für verteilte Systeme, die das Packen, Bereitstellen und Verwalten skalierbarer und zuverlässiger Microservices vereinfacht. Service Fabric bietet allerdings eine große Oberfläche, und es gibt viel darüber zu erfahren. Dieser Artikel enthält eine Zusammenfassung von Service Fabric und beschreibt die grundlegenden Konzepte, Programmiermodelle, Cluster, den Anwendungslebenszyklus und die Systemüberwachung. Eine Einführung und eine Anleitung zum Erstellen von Microservices mit Service Fabric finden Sie unter Übersicht und Was sind Microservices?. Dieser Artikel enthält keine umfassende Liste der Inhalte, aber Links zu Artikeln zur Übersicht und zu den ersten Schritten für die einzelnen Bereiche von Service Fabric.
Wichtige Konzepte
Die Artikel Übersicht über Service Fabric-Terminologie, Modellieren von Anwendungen in Service Fabric und Übersicht über die Service Fabric-Programmiermodelle enthalten weitere Konzepte und Beschreibungen, aber hier geht es um die Grundlagen.
- Service Fabric-Cluster: Unter diesem Link finden Sie ein Schulungsvideo mit einer Einführung in die Service Fabric-Architektur und ihre grundlegenden Konzepte und erhalten Informationen zu zahlreichen Service Fabric-Features.
- Runtimekonzepte: Unter diesem Link finden Sie ein Schulungsvideo mit Informationen zu Runtimekonzepten und Best Practices in Service Fabric.
- Konzepte für Entwurfstypen: Unter diesem Link finden Sie ein Schulungsvideo mit Informationen zur Anwendung, Paketerstellung und Bereitstellung. Sie erfahren außerdem etwas über wichtige Terminologie, Abstraktionen und Konzepte von Service Fabric.
Entwurfszeit: Diensttyp, Dienstpaket und -manifest, Anwendungstyp, Anwendungspaket und -manifest
Eine Diensttyp ist der Name oder die Version, der bzw. die den Code-, Daten- und Konfigurationspaketen eines Diensts zugewiesen wird. Dies wird in der Datei „ServiceManifest.xml“ definiert. Der Diensttyp besteht aus ausführbarem Code und Dienstkonfigurationseinstellungen, die zur Laufzeit geladen werden, sowie aus statischen Daten, die vom Dienst genutzt werden.
Ein Dienstpaket ist ein Datenträgerverzeichnis mit der Datei „ServiceManifest.xml“ des Diensttyps, in der auf die Pakete mit dem Code, den statischen Daten und der Konfiguration für den Diensttyp verwiesen wird. Ein Dienstpaket kann beispielsweise auf den Code, die statischen Daten und die Konfigurationspakete verweisen, die zusammen einen Datenbankdienst bilden.
Ein Anwendungstyp ist der Name oder die Version, der bzw. die einer Sammlung von Diensttypen zugewiesen ist. Dies wird in der Datei „ApplicationManifest.xml“ definiert.
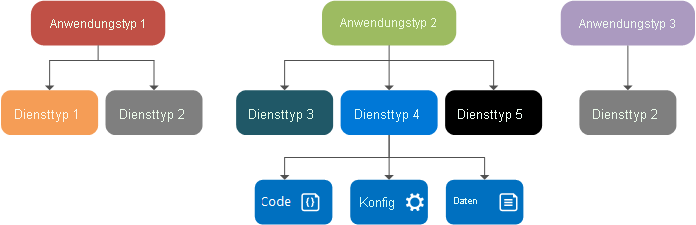
Das Anwendungspaket ist ein Datenträgerverzeichnis, das die Datei „ApplicationManifest.xml“ des Anwendungstyps enthält, in der auf die Dienstpakete für jeden Diensttyp verwiesen wird, aus dem der Anwendungstyp besteht. Ein Anwendungspaket für einen E-Mail-Anwendungstyp kann beispielsweise Verweise auf ein Warteschlangendienstpaket, ein Front-End-Dienstpaket und ein Datenbankdienstpaket enthalten.
Die Dateien im Anwendungspaketverzeichnis werden in den Imagespeicher des Service Fabric-Clusters kopiert. Anschließend können Sie aus diesem Anwendungstyp eine benannte Anwendung erstellen, die dann im Cluster ausgeführt wird. Nach der Erstellung einer benannten Anwendung kann ein benannter Dienst aus einem der Diensttypen des Anwendungstyps erstellt werden.
Laufzeit: Cluster und Knoten, benannte Anwendungen, benannte Dienste, Partitionen und Replikate
Ein Service Fabric-Cluster enthält eine per Netzwerk verbundene Gruppe von virtuellen oder physischen Computern, auf denen Ihre Microservices bereitgestellt und verwaltet werden. Cluster können auf Tausende von Computern skaliert werden.
Ein Computer oder ein virtueller Computer, der Teil eines Clusters ist, wird als Knoten bezeichnet. Jeder Knoten erhält einen Knotennamen (Zeichenfolge). Knoten weisen Merkmale wie etwa Platzierungseigenschaften auf. Jeder Computer oder virtuelle Computer verfügt über einen Windows-Dienst für den automatischen Start (FabricHost.exe), der beim Start ausgeführt wird und seinerseits zwei ausführbare Dateien startet: Fabric.exe und FabricGateway.exe. Diese zwei ausführbaren Dateien bilden zusammen den Knoten. In Entwicklungs- oder Testszenarien können Sie mehrere Knoten auf einem einzelnen Computer oder virtuellen Computer hosten, indem Sie mehrere Instanzen von Fabric.exe und FabricGateway.exe ausführen.
Eine benannte Anwendung ist eine Sammlung von benannten Diensten, die eine bzw. mehrere bestimmte Funktionen ausführen. Ein Dienst führt eine vollständige und eigenständige Funktion aus (er kann unabhängig von anderen Diensten gestartet und ausgeführt werden) und besteht aus Code, Konfiguration und Daten. Nach dem Kopieren eines Anwendungspakets in den Imagespeicher können Sie eine Instanz der Anwendung im Cluster erstellen, indem Sie den Anwendungstyp des Anwendungspakets (unter Verwendung seines Namens/seiner Version) angeben. Jeder Anwendungstypinstanz wird ein URI-Name zugewiesen, der wie folgt aussieht: fabric:/MyNamedApp. Innerhalb eines Clusters können Sie mehrere benannte Anwendungen aus einem einzelnen Anwendungstyp erstellen. Sie können auch benannte Applikationen aus verschiedenen Anwendungstypen erstellen. Jede benannte Anwendung wird unabhängig verwaltet und versioniert.
Nach der Erstellung einer benannten Anwendung können Sie eine Instanz eines Diensttyps (benannter Dienst) im Cluster erstellen, indem Sie den Diensttyp (unter Verwendung seines Namens/seiner Version) angeben. Jeder Diensttypinstanz wird ein URI-Name zugewiesen, der dem URI der benannten Anwendung zugeordnet ist. Wenn Sie beispielsweise den benannten Dienst „MyDatabase“ in der benannten Anwendung „MyNamedApp“ erstellen, sieht der URI wie folgt aus: fabric:/MyNamedApp/MyDatabase. Innerhalb einer benannten Anwendung können Sie einen oder mehrere benannte Dienste erstellen. Jeder benannte Dienst kann ein eigenes Partitionsschema und eigene Werte für die Instanzen-/Replikatanzahl besitzen.
Es gibt zwei Arten von Diensten: zustandslos und zustandsbehaftet. Zustandslose Dienste speichern den Zustand nicht innerhalb des Diensts. Zustandslose Dienste verfügen nicht über beständigen Speicher bzw. speichern keinen beständigen Zustand in einem externen Speicherdienst wie Azure Storage, Azure SQL-Datenbank oder Azure Cosmos DB. Ein zustandsbehafteter Dienst speichert den Status innerhalb des Diensts und verwendet Reliable Collections- oder Reliable Actors-Programmiermodelle, um den Zustand zu verwalten.
Bei der Erstellung eines benannten Diensts geben Sie ein Partitionsschema an. Dienste mit großen Zustandsdatenmengen teilen die Daten auf verschiedene Partitionen auf. Jede Partition ist für einen Teil der gesamten Zustands des Diensts verantwortlich, der auf die Knoten des Clusters verteilt wird.
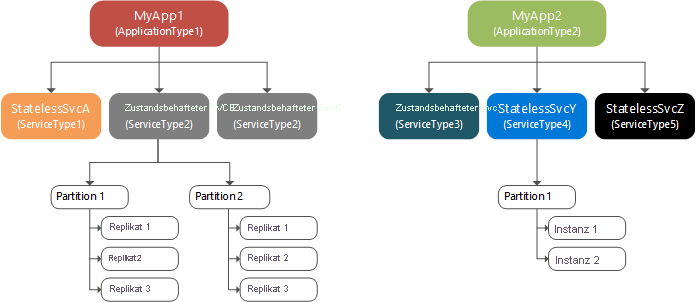
Die folgende schematische Darstellung zeigt die Beziehung zwischen Anwendungen und Dienstinstanzen, Partitionen und Replikaten.
Partitionierung, Skalierung und Verfügbarkeit
Die Partitionierung ist nicht nur auf Service Fabric beschränkt. Eine bekannte Form der Partitionierung ist die Datenpartitionierung bzw. das Sharding. Zustandsbehaftete Dienste mit großen Zustandsdatenmengen teilen die Daten auf verschiedene Partitionen auf. Jede Partition ist für einen Teil der gesamten Zustands des Diensts verantwortlich.
Die Replikate der einzelnen Partitionen sind auf die Clusterknoten verteilt, wodurch der Zustand Ihres benannten Diensts skaliert werden kann. Wenn die Daten zunehmen müssen, werden die Partitionen vergrößert, und Service Fabric verteilt die Partitionen neu über die Knoten, um die Hardwareressourcen effektiv zu nutzen. Wenn Sie dem Cluster neue Knoten hinzufügen, verteilt Service Fabric die Partitionsreplikate auf die erhöhte Anzahl von Knoten neu, um sie auszugleichen. Die Gesamtleistung der Anwendung verbessert sich und Konflikte beim Speicherzugriff werden reduziert. Wenn die Knoten im Cluster nicht effizient genutzt werden, können Sie die Anzahl der Knoten im Cluster verringern. Service Fabric gleicht die Partitionsreplikate erneut über die verringerte Anzahl von Knoten aus, um die Hardware der einzelnen Knoten besser zu nutzen.
Innerhalb einer Partition besitzen zustandslose benannte Dienste Instanzen, wohingegen zustandsbehaftete benannte Dienste Replikate besitzen. Zustandslose benannte Dienste verfügen in der Regel nur über eine Partition, da sie keinen internen Zustand aufweisen. Es gibt jedoch auch Ausnahmen. Die Partitionsinstanzen sorgen für Verfügbarkeit. Wenn eine Instanz ausfällt, werden andere Instanzen weiterhin normal ausgeführt, und Service Fabric erstellt eine neue Instanz. Zustandsbehaftete benannte Dienste behalten ihren Zustand in Replikaten bei, und jede Partition verfügt über eine eigene Replikatgruppe. Lese- und Schreibvorgänge erfolgen im selben Replikat (primäres Replikat). Änderungen des Zustands aufgrund von Schreibvorgängen werden in mehreren anderen Replikaten (aktive sekundäre Replikate) repliziert. Fällt ein Replikat aus, erstellt Service Fabric aus den vorhandenen Replikaten ein neues Replikat.
Zustandslose und zustandsbehaftete Microservices für Service Fabric
Service Fabric ermöglicht es Ihnen, Anwendungen zu erstellen, die aus Microservices oder Containern bestehen. Zustandslose Microservices (z.B. Protokollgateways und Webproxys) behalten über die Anforderung und ihre Antwort vom Dienst hinaus keinen veränderbaren Zustand bei. Ein zustandsloser Dienst ist zum Beispiel die Workerrolle in Azure Cloud Services. Zustandsbehaftete Microservices (z.B. Benutzerkonten, Datenbanken, Geräte, Einkaufswagen und Warteschlangen) behalten einen veränderbaren, autoritativen Zustand über die Anforderung und ihre Antwort hinaus bei. Heutige Internetanwendungen bestehen aus einer Kombination aus zustandslosen und zustandsbehafteten Microservices.
Ein zentraler Unterschied von Service Fabric ist der starke Fokus auf der Erstellung zustandsbehafteter Dienste. Dies kann entweder über integrierte Programmiermodelle oder zustandsbehaftete Dienste in Containern erfolgen. Die Anwendungsszenarios beschreiben die Szenarios, in denen zustandsbehaftete Dienste verwendet werden.
Warum sollte man sowohl zustandsbehaftete als auch zustandslose Microservices haben? Die beiden wichtigsten Gründe sind:
- Sie können fehlertolerante OLTP-Dienste (Online Transaction Processing) mit hohem Durchsatz und niedriger Latenz erstellen, indem Code und Daten nah beieinander auf dem gleichen Computer vorgehalten werden. Beispiele hierfür sind interaktive Geschäfte, Suchfunktionen, IoT-Systeme (Internet der Dinge), Handelssysteme, Kreditkartenverarbeitungssysteme, Betrugserkennungssysteme und Verwaltung personenbezogener Datensätze.
- Sie können den Anwendungsentwurf vereinfachen. Mit zustandsbehafteten Microservices werden zusätzliche Warteschlangen und Caches überflüssig, die bislang erforderlich waren, um Verfügbarkeits- und Latenzanforderungen einer rein zustandslosen Anwendung zu erfüllen. Zustandsbehaftete Dienste sind normalerweise bereits hochverfügbar und bieten eine niedrige Latenz, sodass der Verwaltungsaufwand in Ihrer Anwendung insgesamt geringer ausfällt.
Unterstützte Programmiermodelle
Service Fabric bietet verschiedene Methoden zum Schreiben und Verwalten von Diensten. Dienste können die Service Fabric-APIs verwenden, um Features und Anwendungsframeworks der Plattform umfassend zu nutzen. Ein Dienste kann außerdem ein beliebiges kompiliertes ausführbares Programm sein, das in einer beliebigen Sprache geschrieben und auf einem Service Fabric-Cluster gehostet wird. Weitere Informationen finden Sie unter Unterstützte Programmiermodelle.
Container
Standardmäßig werden Dienste von Service Fabric als Prozesse bereitgestellt und aktiviert. Service Fabric kann Dienste auch in Containern bereitstellen. Wichtig ist, dass Sie in derselben Anwendung Dienste in Prozessen und Dienste in Containern mischen können. Service Fabric unterstützt die Bereitstellung von Linux-Containern sowie von Windows-Containern unter Windows Server 2016. Sie können vorhandene Anwendungen, zustandslose Dienste oder zustandsbehaftete Dienste in Containern bereitstellen.
Reliable Services
Reliable Services ist ein schlankes Framework zum Schreiben von Diensten, die sich in die Service Fabric-Plattform integrieren lassen und von allen Features der Plattform profitieren. Reliable Services können zustandslos sein (ähnlich wie die meisten Dienstplattformen, z.B. Webserver oder Workerrollen in Azure Cloud Services). Der Zustand wird in einer externen Lösung, z.B. Azure DB oder Azure Table Storage, gespeichert. Reliable Services können auch zustandsbehaftet sein, wobei der Zustand mithilfe von Reliable Collections direkt im Dienst gespeichert wird. Der Status wird durch Replikation als hochverfügbar festgelegt und durch Partitionierung verteilt. Die Verwaltung erfolgt automatisch durch Service Fabric.
Reliable Actors
Das Reliable Actor-Anwendungsframework setzt auf Reliable Services auf und implementiert das „Virtual Actor“-Muster basierend auf dem Entwurfsmuster für Akteure. Das Reliable Actor-Framework verwendet unabhängige Compute- und Statuseinheiten mit Singlethreadausführung, die als Akteure bezeichnet werden. Das Reliable Actor-Framework bietet integrierte Kommunikation für Akteure sowie voreingestellte Statuspersistenz und horizontal hochskalierbare Konfigurationen.
ASP.NET Core
Service Fabric integriert mit ASP.NET Core ein erstklassiges Programmiermodell zum Erstellen von Web- und API-Anwendungen. ASP.NET Core kann in Service Fabric auf zwei unterschiedliche Arten verwendet werden:
- Gehostet als ausführbare Gastanwendungsdatei. Diese Methode wird hauptsächlich verwendet, um bereits vorhandene ASP.NET Core-Anwendungen ohne Codeänderungen unter Service Fabric auszuführen.
- Im Rahmen eines zuverlässigen Diensts. Diese Methode ermöglicht eine bessere Integration in die Service Fabric-Laufzeit und die Verwendung zustandsbehafteter ASP.NET Core-Dienste.
Ausführbare Gastanwendungsdateien
Bei einer ausführbaren Gastanwendungsdatei handelt es sich um eine vorhandene, beliebig ausführbare Datei (die in einer beliebigen Sprache geschrieben sein kann), die neben anderen Diensten auf einem Service Fabric-Cluster gehostet wird. Ausführbare Gastanwendungsdateien lassen sich nicht direkt in Service Fabric-APIs integrieren. Sie profitieren jedoch weiterhin von den angebotenen Features der Plattform. Hierzu zählen beispielsweise Integritäts- und Auslastungsberichte und die Auffindbarkeit von Diensten durch Aufrufen von REST-APIs. Außerdem wird der Anwendungslebenszyklus vollständig unterstützt.
Anwendungslebenszyklus
Ähnlich wie auf anderen Plattformen durchläuft eine Anwendung auf Service Fabric normalerweise die folgenden Phasen: Entwurf, Entwicklung, Test, Bereitstellung, Upgrade, Wartung und Deinstallation. Service Fabric bietet erstklassige Unterstützung für den gesamten Anwendungslebenszyklus von Cloudanwendungen: von der Entwicklung über die Bereitstellung, die tägliche Verwaltung und die Wartung bis zur endgültigen Außerbetriebnahme. Das Dienstmodell ermöglicht die unabhängige Beteiligung verschiedener Rollen am Anwendungslebenszyklus. Service Fabric-Anwendungslebenszyklus bietet eine Übersicht über die APIs und wie sie von den verschiedenen Rollen während der Phasen des Service Fabric-Anwendungslebenszyklus verwendet werden.
Der gesamte App-Lebenszyklus kann mithilfe von PowerShell-Cmdlets, CLI-Befehle, C#-APIs, Java-APIs und REST-APIs. verwaltet werden. Sie können auch Continuous Integration-/Continuous Deployment-Pipelines mit Tools wie Azure Pipelines oder Jenkins einrichten.
Testen von Anwendungen und Diensten
Zum Erstellen echter Dienste für die Cloud müssen Sie unbedingt sicherstellen, dass Ihre Anwendungen und Dienste für die in der Praxis auftretenden Fehler gerüstet sind. Der Fault Analysis Service ist auf das Testen von Diensten ausgelegt, die in Service Fabric erstellt werden. Mit dem Fault Analysis Service können Sie aussagekräftige Fehler auslösen und vollständige Testszenarien für Ihre Anwendungen ausführen. Mit diesen Fehlern und Szenarien werden die verschiedenen Zustände und Übergänge durchgespielt und überprüft, die während der Lebensdauer eines Diensts auftreten – und zwar auf kontrollierte, sichere und einheitliche Weise.
Aktionen sind auf einen Dienst zum Testen ausgerichtet, bei dem individuelle Fehler verwendet werden. Ein Dienstentwickler kann sie als Bausteine zum Schreiben komplizierter Szenarien verwenden. Beispiele für simulierte Fehler sind:
- Starten Sie einen Knoten neu, um eine beliebige Anzahl von Situationen zu simulieren, in denen ein Computer oder ein virtueller Computer neu gestartet wird.
- Verschieben Sie ein Replikat Ihres zustandsbehafteten Diensts, um Lastenausgleich, Failover oder ein Anwendungsupgrade zu simulieren.
- Lösen Sie einen Quorumverlust für einen zustandsbehafteten Dienst aus, um zu bewirken, dass Schreibvorgänge nicht fortgesetzt werden können, weil nicht genügend Backupreplikate oder sekundäre Replikate zum Aufnehmen neuer Daten vorhanden sind.
- Lösen Sie einen Datenverlust für einen zustandsbehafteten Dienst aus, um eine Situation zu schaffen, in der alle In-Memory-Zustände vollständig entfernt werden.
Szenarien sind komplexe Vorgänge, die aus einem oder mehreren Vorgängen bestehen. Der Fault Analysis Services stellt zwei integrierte, vollständige Szenarien bereit:
- Mithilfe von Chaosszenarien werden im Cluster über längere Zeiträume hinweg fortlaufende verschachtelte Fehler simuliert (sowohl ordnungsgemäß als auch nicht ordnungsgemäß).
- Das Failovertestszenario ist eine Version des Chaostestszenarios für eine bestimmte Dienstpartition, während andere Dienste nicht betroffen sind.
Cluster
Ein Service Fabric-Cluster enthält eine per Netzwerk verbundene Gruppe von virtuellen oder physischen Computern, auf denen Ihre Microservices bereitgestellt und verwaltet werden. Cluster können auf Tausende von Computern skaliert werden. Ein Computer oder ein virtueller Computer, der Teil eines Clusters ist, wird als Clusterknoten bezeichnet. Jeder Knoten erhält einen Knotennamen (Zeichenfolge). Knoten weisen Merkmale wie etwa Platzierungseigenschaften auf. Jeder Computer bzw. virtuelle Computer verfügt über einen automatisch gestarteten Dienst, FabricHost.exe, für den die Ausführung beim Hochfahren gestartet wird und mit dem dann zwei ausführbare Dateien gestartet werden: „Fabric.exe“ und „FabricGateway.exe“. Diese zwei ausführbaren Dateien bilden zusammen den Knoten. In Testszenarien können Sie mehrere Knoten auf einem einzelnen Computer oder virtuellen Computer hosten, indem Sie mehrere Instanzen von Fabric.exe und FabricGateway.exe ausführen.
Service Fabric-Cluster können auf virtuellen oder physischen Computern erstellt werden, auf denen Windows Server oder Linux ausgeführt wird. Es lassen sich Service Fabric-Anwendungen in jeder lokalen oder cloudbasierten Umgebung oder in einer Microsoft Azure-Umgebung bereitstellen und ausführen, in der sich miteinander verbundene Computer mit Windows Server oder Linux befinden.
Cluster in Azure
Das Ausführen von Service Fabric-Clustern unter Azure ermöglicht die Integration anderer Azure-Features und -Dienste, die den Betrieb und die Verwaltung des Clusters vereinfachen und zuverlässiger machen. Ein Cluster ist eine Azure Resource Manager-Ressource, daher können Sie Cluster wie alle anderen Ressourcen in Azure modellieren. Resource Manager ermöglicht auch eine einfache Verwaltung aller Ressourcen, die vom Cluster als einzelne Einheit verwendet werden. Cluster unter Azure werden mit Azure-Diagnose und Azure Monitor-Protokollen integriert. Clusterknotentypen sind Skalierungsgruppen für virtuelle Computer, daher sind automatische Skalierungsfunktionen bereits integriert.
Sie können einen Cluster über das Azure-Portal, mithilfe einer Vorlage oder mit Visual Studio in Azure erstellen.
Service Fabric unter Linux ermöglicht Ihnen, hoch verfügbare und skalierbare Anwendungen unter Linux (genauso wie unter Windows) zu erstellen, bereitzustellen und zu verwalten. Neben C# (.NET Core) stehen Service Fabric-Frameworks (Reliable Services und Reliable Actors) in Java unter Linux zur Verfügung. Sie können auch ausführbare Gastdienste mit jeder beliebigen Sprache und jedem beliebigen Framework erstellen. Orchestrierung von Docker-Containern wird ebenfalls unterstützt. Docker-Container können ausführbare Gastanwendungsdateien oder native Service Fabric-Dienste ausführen, die die Service Fabric-Frameworks nutzen. Weitere Informationen finden Sie unter Service Fabric unter Linux.
Einige Features werden unter Windows unterstützt, aber nicht unter Linux. Weitere Informationen finden Sie unter Unterschiede zwischen Service Fabric unter Linux und Windows.
Eigenständige Cluster
Service Fabric verfügt über ein Installationspaket, mit dem Sie eigenständige Service Fabric-Cluster lokal oder bei einem Cloudanbieter erstellen können. Eigenständige Cluster bieten Ihnen die Möglichkeit zum Hosten von Clustern an beliebigen Orten. Wenn Ihre Daten der Konformität oder gesetzlichen Einschränkungen unterliegen oder Sie Ihre Daten lokal speichern möchten, können Sie Ihre eigenen Cluster und Anwendungen hosten. Service Fabric-Anwendungen können ohne Änderungen in mehreren Hostumgebungen ausgeführt werden. Daher lassen sich Ihre Kenntnisse über das Erstellen von Anwendungen von einer Hostumgebung in die andere übertragen.
Erstellen Ihres ersten eigenständigen Service Fabric-Clusters
Eigenständige Linux-Clustern werden noch nicht unterstützt.
Clustersicherheit
Cluster müssen immer gesichert werden, um zu verhindern, dass nicht autorisierte Benutzer eine Verbindung mit dem Cluster herstellen können, insbesondere dann, wenn im Cluster Produktionsworkloads ausgeführt werden. Es ist zwar möglich, einen nicht gesicherten Cluster zu erstellen, allerdings kann in diesem Fall jeder anonyme Benutzer eine Verbindung herstellen, wenn der Cluster Verwaltungsendpunkte im öffentlichen Internet verfügbar macht. Es ist nicht möglich, die Sicherheit auf einem ungesicherten Cluster später zu aktivieren: Clustersicherheit wird zum Zeitpunkt der Erstellung des Clusters aktiviert.
Die Szenarien für die Clustersicherheit sind:
- Knoten-zu-Knoten-Sicherheit
- Client-zu-Knoten-Sicherheit
- Rollenbasierte Service Fabric-Zugriffssteuerung
Weitere Informationen hierzu finden Sie unter Schützen eines Clusters.
Skalierung
Wenn Sie dem Cluster neue Knoten hinzufügen, verteilt Service Fabric die Partitionsreplikate und Instanzen auf die erhöhte Anzahl von Knoten neu, um sie auszugleichen. Die Gesamtleistung der Anwendung verbessert sich und Konflikte beim Speicherzugriff werden reduziert. Wenn die Knoten im Cluster nicht effizient genutzt werden, können Sie die Anzahl der Knoten im Cluster verringern. Service Fabric gleicht die Partitionsreplikate und Instanzen erneut über die verringerte Anzahl von Knoten aus, um die Hardware der einzelnen Knoten besser zu nutzen. Sie können Cluster in Azure entweder manuell oder programmgesteuert skalieren. Eigenständige Cluster können manuell skaliert werden.
Clusterupgrades
Es werden Regelmäßig neue Versionen der Service Fabric-Runtime veröffentlicht. Führen Sie Runtime-Upgrades (oder Fabric-Upgrades) auf Ihrem Cluster aus, damit Sie immer eine unterstützte Version ausführen. Zusätzlich zu Fabric-Upgrades können Sie auch die Clusterkonfiguration aktualisieren, z. B. Zertifikate oder Anwendungsports.
Ein Service Fabric-Cluster ist eine Ressource, die Sie besitzen, die jedoch teilweise von Microsoft verwaltet wird. Microsoft ist für das Patchen des zugrunde liegenden Betriebssystems und das Durchführen von Fabric-Upgrades auf dem Cluster zuständig. Sie können Ihren Cluster so konfigurieren, dass er Fabric-Upgrades entweder automatisch erhält oder wenn Microsoft eine neue Version veröffentlicht. Alternativ können Sie eine gewünschte unterstützte Fabric-Version auswählen. Fabric- und Konfigurationsupgrades können über das Azure-Portal oder über Resource Manager festgelegt werden. Weitere Informationen finden Sie unter Upgrade von Service Fabric-Clustern.
Ein eigenständiger Cluster ist eine Ressource, die Sie vollständig besitzen. Sie sind für das Patchen des zugrunde liegenden Betriebssystems und das Starten von Fabric-Upgrades zuständig. Wenn Ihr Cluster eine Verbindung mit https://www.microsoft.com/download herstellen kann, können Sie für Ihren Cluster das automatische Herunterladen und Bereitstellen des neuen Service Fabric-Runtimepakets festlegen. Sie würden dann das Upgrade starten. Wenn Ihr Cluster nicht auf https://www.microsoft.com/download zugreifen kann, können Sie das neue Runtimepaket manuell auf einen mit dem Internet verbundenen Computer herunterladen und dann das Upgrade starten. Weitere Informationen finden Sie unter Upgrade eines eigenständigen Service Fabric-Clusters.
Systemüberwachung
Service Fabric bietet ein Integritätsmodell, das fehlerhafte Cluster- und Anwendungsbedingungen auf bestimmten Entitäten kennzeichnet (z. B. Clusterknoten und Dienstreplikate). Das Integritätsmodell verwendet Integritäts-Reporter (Systemkomponenten und Watchdogs). Das Ziel ist die einfache und schnelle Diagnose und Reparatur. Dienstgeneratoren müssen sich im Vorfeld Gedanken zur Integrität und zum Design der Integritätsberichte machen. Jede Bedingung, die zur Beeinträchtigung der Integrität führen kann, sollte gemeldet werden, insbesondere wenn damit die Ursachen von Problemen ermittelt werden können. Diese Integritätsinformationen können beim Debuggen und Untersuchen Zeit und Arbeit sparen, sobald der Dienst ordnungsgemäß in der Produktionsumgebung ausgeführt wird.
Die Service Fabric-Berichterstatter überwachen Bedingungen, die von Bedeutung sind. Sie erstatten basierend auf ihrer lokalen Anzeige Bericht über diese Bedingungen. Der Integritätsspeicher aggregiert die von allen Reportern gesendeten Integritätsdaten, um die globale Integrität der Entitäten zu ermitteln. Das Modell ist umfassend, flexibel und einfach anzuwenden. Die Qualität der Integritätsberichte bestimmt die Genauigkeit der Integritätsanzeige des Clusters. Falsch positive Ergebnisse, die irrtümlicherweise Fehler anzeigen, können Upgrades oder andere Dienste beeinträchtigen, die Integritätsdaten verwenden. Beispiele für solche Dienste sind Reparaturdienste und Alarmmechanismen. Daher sind einige Überlegungen erforderlich, um Bericht bereitzustellen, die wichtige Bedingungen auf bestmögliche Weise erfassen.
Die Berichterstellung kann von folgenden Orten aus erfolgen:
- Vom überwachten Service Fabric-Dienstreplikat oder einer Instanz.
- Von internen Watchdogs, die als Service Fabric-Dienste bereitgestellt werden (etwa ein zustandsloser Service Fabric-Dienst, der Bedingungen überwacht und Berichte ausgibt). Watchdogs können auf allen Knoten bereitgestellt oder dem überwachten Dienst zugeordnet werden.
- Von internen Watchdogs, die auf den Service Fabric-Knoten ausgeführt werden, jedoch nicht als Service Fabric-Dienste implementiert werden.
- Von externen Watchdogs, die die Ressource von außerhalb des Service Fabric-Clusters überwachen (etwa ein Überwachungsdienst wie Gomez).
Für Service Fabric-Komponenten werden für alle Entitäten im Cluster standardmäßig Integritätsberichte erstellt. Die Systemintegritätsberichte sorgen für Transparenz in Bezug auf die Cluster- und Anwendungsfunktionen und weisen auf Probleme mit der Integrität hin. Für Anwendungen und Dienste wird mit den Systemintegritätsberichten überprüft, ob Entitäten implementiert sind und sich aus Sicht der Service Fabric-Runtime richtig verhalten. Die Berichte umfassen keine Integritätsüberwachung der Geschäftslogik des Diensts und keine Erkennung von Prozessen, die nicht mehr reagieren. Implementieren Sie benutzerdefinierte Integritätsberichte in Ihre Dienste, um für Ihre Dienstlogik spezifische Integritätsinformationen hinzuzufügen.
Service Fabric bietet mehrere Möglichkeiten, um Integritätsberichte anzuzeigen, die im Integritätsspeicher aggregiert werden:
- Service Fabric Explorer oder andere Visualisierungstools.
- Integritätsabfragen (über PowerShell, CLI, FabricClient-APIs von C# und FabricClient-APIs von Java oder REST-APIs).
- Allgemeine Abfragen, die eine Liste mit Entitäten zurückgeben, von denen eine der Eigenschaften die Integrität ist (über PowerShell, CLI, APIs oder REST).
Überwachung und Diagnose
Überwachung und Diagnose sind wichtig für Entwicklung und Tests sowie die Bereitstellung von Anwendungen und Diensten in allen Umgebungen. Service Fabric-Lösungen funktionieren am besten, wenn Sie die Überwachung und Diagnose planen und implementieren. So stellen Sie sicher, dass Anwendungen und Dienste in einer lokalen Entwicklungsumgebung oder in der Produktionsumgebung wie erwartet ausgeführt werden.
Die Hauptziele der Überwachung und Diagnose sind:
- Erkennen und Diagnostizieren von Hardware- und Infrastrukturproblemen
- Erkennen von Software- und App-Problemen, Verringern von Dienstausfallzeiten
- Verstehen des Ressourcenverbrauchs und Hilfe bei betrieblichen Entscheidungen
- Optimieren der Leistung von Anwendung, Dienst und Infrastruktur
- Generieren von geschäftlichen Einblicken und Identifizieren von Verbesserungspotenzialen
Der allgemeine Workflow für die Überwachung und Diagnose besteht aus drei Schritten:
- Ereignisgenerierung: Dies schließt Ereignisse (Protokolle, Ablaufverfolgungen, benutzerdefinierte Ereignisse) auf Infrastruktur- (Cluster-), Plattform- und Anwendungs-/Dienstebene ein.
- Ereignisaggregation: Die generierten Ereignisse müssen gesammelt und aggregiert werden, bevor sie angezeigt werden können.
- Analyse: Die Ereignisse müssen visualisiert und in einem Format verfügbar sein, das die Analyse und Anzeige je nach Bedarf ermöglicht.
Mehrere Produkte sind erhältlich, die alle drei Bereiche abdecken. Zudem können Sie für jeden Bereich unterschiedliche Technologien auswählen. Weitere Informationen finden Sie unter Überwachung und Diagnose für Azure Service Fabric.
Nächste Schritte
- Informieren Sie sich, wie Sie einen Cluster in Azure oder einen eigenständigen Cluster in Windows erstellen.
- Versuchen Sie, einen Dienst zu erstellen, indem Sie das Programmiermodell Reliable Services oder Reliable Actors verwenden.
- Informieren Sie sich über das Migrieren aus Cloud Services.
- Informieren Sie sich über Lokales Überwachen und Diagnostizieren von Diensten.
- Informieren Sie sich über das Testen von Apps und Diensten.
- Informieren Sie sich über das Verwalten und Orchestrieren von Clusterressourcen.
- Betrachten Sie die verschiedenen Service Fabric-Beispiele.
- Informieren Sie sich über Service Fabric-Supportoptionen.
- Lesen Sie Artikel und Ankündigungen im Teamblog.