Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Die Eingabeüberprüfung ist ein Verfahren, mit dem die Hauptabfragelogik vor nicht wohlgeformten oder unerwarteten Ereignissen geschützt wird. Die Abfrage wird erweitert, sodass sie Datensätze explizit verarbeitet und überprüft, damit sie die Hauptlogik nicht unterbrechen können.
Um die Eingabeüberprüfung zu implementieren, fügen wir einer Abfrage zwei Anfangsschritte hinzu. Zunächst stellen wir sicher, dass das an die Kerngeschäftslogik übermittelte Schema den Erwartungen entspricht. Anschließend werden Ausnahmen selektiert und optional ungültige Datensätze an eine sekundäre Ausgabe weitergeleitet.
Eine Abfrage mit Eingabeüberprüfung wird wie folgt strukturiert:
WITH preProcessingStage AS (
SELECT
-- Rename incoming fields, used for audit and debugging
field1 AS in_field1,
field2 AS in_field2,
...
-- Try casting fields in their expected type
TRY_CAST(field1 AS bigint) as field1,
TRY_CAST(field2 AS array) as field2,
...
FROM myInput TIMESTAMP BY myTimestamp
),
triagedOK AS (
SELECT -- Only fields in their new expected type
field1,
field2,
...
FROM preProcessingStage
WHERE ( ... ) -- Clauses make sure that the core business logic expectations are satisfied
),
triagedOut AS (
SELECT -- All fields to ease diagnostic
*
FROM preProcessingStage
WHERE NOT (...) -- Same clauses as triagedOK, opposed with NOT
)
-- Core business logic
SELECT
...
INTO myOutput
FROM triagedOK
...
-- Audit output. For human review, correction, and manual re-insertion downstream
SELECT
*
INTO BlobOutput -- To a storage adapter that doesn't require strong typing, here blob/adls
FROM triagedOut
Ein umfassendes Beispiel für eine Abfrage, die mit Eingabeüberprüfung eingerichtet wurde, finden Sie im Abschnitt Beispiel für eine Abfrage mit Eingabeüberprüfung.
In diesem Artikel wird die Implementierung dieser Technik veranschaulicht.
Kontext
Azure Stream Analytics-Aufträge (ASA) verarbeiten Daten aus Streams. Streams sind Sequenzen von Rohdaten, die serialisiert übertragen werden (CSV, JSON, AVRO...). Um aus einem Stream lesen zu können, muss eine Anwendung das spezifische verwendete Serialisierungsformat kennen. In ASA muss das Ereignisserialisierungsformat beim Konfigurieren einer Streamingeingabe definiert werden.
Nachdem die Daten deserialisiert wurden, muss ein Schema angewendet werden, um ihnen Bedeutung zu geben. Als Schema werden die Liste der Felder im Stream und deren jeweilige Datentypen bezeichnet. Bei ASA muss das Schema der eingehenden Daten nicht auf der Eingabeebene festgelegt werden. ASA unterstützt stattdessen nativ dynamische Eingabeschemas. Es wird erwartet, dass sich die Liste der Felder (Spalten) und deren Typen zwischen Ereignissen (Zeilen) ändern. ASA leitet auch Datentypen ab, wenn keine explizit bereitgestellt werden, und versucht bei Bedarf, Typen implizit umzuwandeln.
Die dynamische Schemabehandlung ist ein leistungsstarkes Feature, das die Verarbeitung von Datenströmen ermöglicht. Datenströme enthalten häufig Daten aus mehreren Quellen mit mehreren Ereignistypen, die jeweils ein eindeutiges Schema haben. Zum Routen, Filtern und Verarbeiten von Ereignissen in solchen Streams muss ASA alle Ereignisse unabhängig von ihrem Schema aufnehmen.
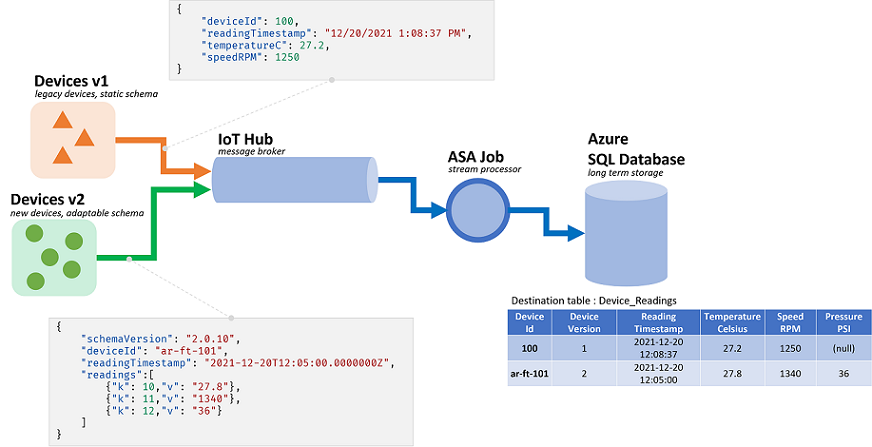
Die Funktionen der dynamischen Schemabehandlung haben jedoch einen potenziellen Nachteil. Unerwartete Ereignisse können durch die Hauptabfragelogik fließen und sie beschädigen. Als Beispiel können wir ROUND für ein Feld vom Typ NVARCHAR(MAX) verwenden. ASA konvertiert es implizit in float, damit es mit der Signatur von ROUND übereinstimmt. Hier erwarten oder hoffen wir, dass dieses Feld immer numerische Werte enthält. Wenn wir jedoch ein Ereignis empfangen, bei dem das Feld auf "NaN" festgelegt ist, oder wenn das Feld vollständig fehlt, kann beim Auftrag ein Fehler auftreten.
Mit der Eingabeüberprüfung fügen wir unserer Abfrage vorläufige Schritte hinzu, um solche nicht wohlgeformten Ereignisse zu behandeln. Wir verwenden in erster Linie WITH und TRY_CAST, um sie zu implementieren.
Szenario: Eingabeüberprüfung für unzuverlässige Ereignisquellen
Wir erstellen einen neuen ASA-Auftrag, der Daten von einem einzelnen Event Hub erfasst. Wie in den meisten Fällen sind wir nicht für die Datenproduzenten verantwortlich. Hier handelt es sich bei den Produzenten um IoT-Geräte, die von mehreren Hardwareanbietern verkauft werden.
Bei der Besprechung mit den Projektbeteiligten einigen wir uns auf ein Serialisierungsformat und ein Schema. Alle Geräte pushen solche Nachrichten an einen gemeinsamen Event Hub, die Eingabe des ASA-Auftrags.
Der Schemavertrag ist wie folgt definiert:
| Feldname | Feldtyp | Feldbeschreibung |
|---|---|---|
deviceId |
Integer | Eindeutige Geräte-ID |
readingTimestamp |
Datetime | Nachrichtenzeit, generiert von einem zentralen Gateway |
readingStr |
String | |
readingNum |
Numeric | |
readingArray |
Ein Zeichenfolgenarray. |
Davon erhalten wir wiederum die folgende Beispielmeldung unter JSON-Serialisierung:
{
"deviceId" : 1,
"readingTimestamp" : "2021-12-10T10:00:00",
"readingStr" : "A String",
"readingNum" : 1.7,
"readingArray" : ["A","B"]
}
Es ist bereits eine Abweichung zwischen dem Schemavertrag und seiner Implementierung zu erkennen. Im JSON-Format gibt es keinen Datentyp für datetime. Es wird als Zeichenfolge übertragen (siehe readingTimestamp oben). ASA kann das Problem mühelos beheben, zeigt aber die Notwendigkeit, Typen zu überprüfen und explizit umzuwandeln. Dies ist noch wichtiger für Daten, die in CSV serialisiert sind, da dann alle Werte als Zeichenfolge übertragen werden.
Es gibt eine weitere Diskrepanz. ASA verwendet ein eigenes Typsystem, das nicht mit dem eingehenden System übereinstimmt. Wenn ASA über integrierte Typen für integer (bigint), datetime, string (nvarchar(max)) und Arrays verfügt, wird nur numerisch über float unterstützt. Dieser Konflikt ist für die meisten Anwendungen kein Problem. In bestimmten Grenzfällen kann dies jedoch zu geringfügigen Abweichungen bei der Genauigkeit führen. In diesem Fall konvertieren wir den numerischen Wert als Zeichenfolge in ein neues Feld. Anschließend verwenden wir ein System, das feste Dezimalzahlen unterstützt, um potenzielle Abweichungen zu erkennen und zu korrigieren.
Zurück zu unserer Abfrage – hier haben wir Folgendes vor:
readingStran eine JavaScript-UDF übergeben- Anzahl der Datensätze im Array zählen
readingNumauf die zweite Dezimalstelle runden- Die Daten in eine SQL-Tabelle einfügen
Die SQL-Zieltabelle hat folgendes Schema:
CREATE TABLE [dbo].[readings](
[Device_Id] int NULL,
[Reading_Timestamp] datetime2(7) NULL,
[Reading_String] nvarchar(200) NULL,
[Reading_Num] decimal(18,2) NULL,
[Array_Count] int NULL
) ON [PRIMARY]
Es ist eine bewährte Methode, jedem Feld die Ereignisse zuzuordnen, denen es während des Ablaufs des Auftrags unterliegt:
| Feld | Eingabe (JSON) | Geerbter Typ (ASA) | Ausgabe (Azure SQL) | Kommentar |
|---|---|---|---|---|
deviceId |
number | BIGINT | integer | |
readingTimestamp |
Zeichenfolge | nvarchar(Max) | datetime2 | |
readingStr |
Zeichenfolge | nvarchar(Max) | nvarchar(200) | von der UDF verwendet |
readingNum |
number | float | decimal(18,2) | wird gerundet |
readingArray |
array(string) | Array von nvarchar(MAX) | integer | wird gezählt |
Voraussetzungen
Wir entwickeln die Abfrage in Visual Studio Code mithilfe der ASA Tools-Erweiterung. Die ersten Schritte dieses Tutorials führen Sie durch die Installation der erforderlichen Komponenten.
In VS Code verwenden wir lokale Ausführungen mit lokaler Eingabe/Ausgabe, um Kosten zu vermeiden und die Debugschleife zu beschleunigen. Wir müssen nicht einen Event Hub oder eine Azure SQL-Datenbank einrichten.
Basisabfrage
Beginnen wir mit einer grundlegenden Implementierung ohne Eingabeüberprüfung. Wir fügen sie im nächsten Abschnitt hinzu.
In VS Code erstellen wir ein neues ASA-Projekt.
Im Ordner input erstellen wir eine neue JSON-Datei namens data_readings.json und fügen ihr die folgenden Datensätze hinzu:
[
{
"deviceId" : 1,
"readingTimestamp" : "2021-12-10T10:00:00",
"readingStr" : "A String",
"readingNum" : 1.7145,
"readingArray" : ["A","B"]
},
{
"deviceId" : 2,
"readingTimestamp" : "2021-12-10T10:01:00",
"readingStr" : "Another String",
"readingNum" : 2.378,
"readingArray" : ["C"]
},
{
"deviceId" : 3,
"readingTimestamp" : "2021-12-10T10:01:20",
"readingStr" : "A Third String",
"readingNum" : -4.85436,
"readingArray" : ["D","E","F"]
},
{
"deviceId" : 4,
"readingTimestamp" : "2021-12-10T10:02:10",
"readingStr" : "A Forth String",
"readingNum" : 1.2126,
"readingArray" : ["G","G"]
}
]
Anschließend definieren wir eine lokale Eingabe namens readings, die auf die oben erstellte JSON-Datei verweist.
Nach der Konfiguration sollte es wie folgt aussehen:
{
"InputAlias": "readings",
"Type": "Data Stream",
"Format": "Json",
"FilePath": "data_readings.json",
"ScriptType": "InputMock"
}
Mit Vorschaudaten können wir beobachten, dass unsere Datensätze ordnungsgemäß geladen werden.
Wir erstellen eine neue JavaScript-UDF namens udfLen, indem wir mit der rechten Maustaste auf den Ordner Functions klicken und ASA: Add Function auswählen. Der Code, den wir verwenden, ist:
// Sample UDF that returns the length of a string for demonstration only: LEN will return the same thing in ASAQL
function main(arg1) {
return arg1.length;
}
In lokalen Ausführungen müssen wir keine Ausgaben definieren. Wir müssen nicht einmal INTO verwenden, es sei denn, es gibt mehrere Ausgaben. In der .asaql-Datei können wir die vorhandene Abfrage durch Folgendes ersetzen:
SELECT
r.deviceId,
r.readingTimestamp,
SUBSTRING(r.readingStr,1,200) AS readingStr,
ROUND(r.readingNum,2) AS readingNum,
COUNT(a.ArrayValue) AS arrayCount
FROM readings AS r TIMESTAMP BY r.readingTimestamp
CROSS APPLY GetArrayElements(r.readingArray) AS a
WHERE UDF.udfLen(r.readingStr) >= 2
GROUP BY
System.Timestamp(), --snapshot window
r.deviceId,
r.readingTimestamp,
r.readingStr,
r.readingNum
Wir gehen schnell die von uns übermittelte Abfrage durch:
- Um die Anzahl der Datensätze in jedem Array zu zählen, müssen sie zunächst entpackt werden. Wir verwenden CROSS APPLY und GetArrayElements() (weitere Beispiele finden Sie hier).
- Dabei werden zwei Datensätze in der Abfrage angezeigt: die ursprüngliche Eingabe und die Arraywerte. Um sicherzustellen, dass wir keine Felder verwechseln, definieren wir Aliase (
AS r) und verwenden sie überall. - Um dann die Arraywerte tatsächlich zu zählen (
COUNT), müssen wir sie mit GROUP BY aggregieren. - Dazu müssen wir ein Zeitfenster definieren. Da wir hier keines für unsere Logik benötigen, ist das Momentaufnahmefenster die richtige Wahl.
- Dabei werden zwei Datensätze in der Abfrage angezeigt: die ursprüngliche Eingabe und die Arraywerte. Um sicherzustellen, dass wir keine Felder verwechseln, definieren wir Aliase (
- Außerdem müssen wir
GROUP BYauf alle Felder anwenden und sie inSELECTprojizieren. Die explizite Projektion von Feldern ist eine bewährte Methode, daSELECT *Fehler von der Eingabe zur Ausgabe fließen lässt.- Wenn wir ein Zeitfenster definieren, können wir mit TIMESTAMP BY einen Zeitstempel definieren. Hier ist es zur Funktion unserer Logik nicht erforderlich. Bei lokalen Ausführungen werden ohne
TIMESTAMP BYalle Datensätze in einem einzigen Zeitstempel geladen, der Startzeit der Ausführung.
- Wenn wir ein Zeitfenster definieren, können wir mit TIMESTAMP BY einen Zeitstempel definieren. Hier ist es zur Funktion unserer Logik nicht erforderlich. Bei lokalen Ausführungen werden ohne
- Wir verwenden die UDF, um Lesewerte zu filtern, bei denen
readingStrweniger als zwei Zeichen enthält. Wir hätten hier LEN verwenden müssen. Eine UDF verwenden wir hier nur zu Demonstrationszwecken.
Wir können eine Ausführung starten und beobachten, wie die Daten verarbeitet werden:
| deviceId | readingTimestamp | readingStr | readingNum | arrayCount |
|---|---|---|---|---|
| 1 | 2021-12-10T10:00:00 | Eine Zeichenfolge | 1,71 | 2 |
| 2 | 2021-12-10T10:01:00 | Eine andere Zeichenfolge | 2,38 | 1 |
| 3 | 2021-12-10T10:01:20 | Eine dritte Zeichenfolge | -4.85 | 3 |
| 1 | 2021-12-10T10:02:10 | Eine vierte Zeichenfolge | 1.21 | 2 |
Da wir nun wissen, dass unsere Abfrage funktioniert, testen wir sie mit weiteren Daten. Ersetzen wir nun den Inhalt von data_readings.json durch die folgenden Datensätze:
[
{
"deviceId" : 1,
"readingTimestamp" : "2021-12-10T10:00:00",
"readingStr" : "A String",
"readingNum" : 1.7145,
"readingArray" : ["A","B"]
},
{
"deviceId" : 2,
"readingTimestamp" : "2021-12-10T10:01:00",
"readingNum" : 2.378,
"readingArray" : ["C"]
},
{
"deviceId" : 3,
"readingTimestamp" : "2021-12-10T10:01:20",
"readingStr" : "A Third String",
"readingNum" : "NaN",
"readingArray" : ["D","E","F"]
},
{
"deviceId" : 4,
"readingTimestamp" : "2021-12-10T10:02:10",
"readingStr" : "A Forth String",
"readingNum" : 1.2126,
"readingArray" : {}
}
]
Hier sehen wir folgende Probleme:
- Gerät 1 hat alles richtig gemacht.
- Gerät 2 hat vergessen, ein
readingStreinzufügen. - Gerät 3 hat
NaNals Zahl gesendet. - Gerät 4 hat anstelle eines Arrays einen leeren Datensatz gesendet.
Die Ausführung des Auftrags sollte jetzt nicht gut enden. Wir erhalten eine der folgenden Fehlermeldungen:
Von Gerät 2 erhalten wir:
[Error] 12/22/2021 10:05:59 PM : **System Exception** Function 'udflen' resulted in an error: 'TypeError: Unable to get property 'length' of undefined or null reference' Stack: TypeError: Unable to get property 'length' of undefined or null reference at main (Unknown script code:3:5)
[Error] 12/22/2021 10:05:59 PM : at Microsoft.EventProcessing.HostedRuntimes.JavaScript.JavaScriptHostedFunctionsRuntime.
Von Gerät 3 erhalten wir:
[Error] 12/22/2021 9:52:32 PM : **System Exception** The 1st argument of function round has invalid type 'nvarchar(max)'. Only 'bigint', 'float' is allowed.
[Error] 12/22/2021 9:52:32 PM : at Microsoft.EventProcessing.SteamR.Sql.Runtime.Arithmetics.Round(CompilerPosition pos, Object value, Object length)
Von Gerät 4 erhalten wir:
[Error] 12/22/2021 9:50:41 PM : **System Exception** Cannot cast value of type 'record' to type 'array' in expression 'r . readingArray'. At line '9' and column '30'. TRY_CAST function can be used to handle values with unexpected type.
[Error] 12/22/2021 9:50:41 PM : at Microsoft.EventProcessing.SteamR.Sql.Runtime.Cast.ToArray(CompilerPosition pos, Object value, Boolean isUserCast)
Jedes Mal konnten nicht wohlgeformte Datensätze von der Eingabe in die Hauptabfragelogik übertragen werden konnten, ohne überprüft zu werden. Nun erkennen wir den Wert der Eingabeüberprüfung.
Implementieren der Eingabeüberprüfung
Wir erweitern unsere Abfrage, um die Eingabe zu überprüfen.
Der erste Schritt der Eingabeüberprüfung besteht darin, die Schemaerwartungen der Kerngeschäftslogik zu definieren. Wenn wir auf die ursprüngliche Anforderung zurückblicken, soll unsere Hauptlogik:
readingStran eine JavaScript-UDF übergeben, um dessen Länge zu messen- Anzahl der Datensätze im Array zählen
readingNumauf die zweite Dezimalstelle runden- Die Daten in eine SQL-Tabelle einfügen
Für jeden Punkt können wir die Erwartungen auflisten:
- Die UDF benötigt ein Argument vom Typ string (hier nvarchar(max)), das nicht NULL sein darf.
GetArrayElements()benötigt ein Argument vom Typ Array oder einen NULL-WertRoundbenötigt ein Argument vom Typ bigint oder float oder einen NULL-Wert- Anstatt uns auf die implizite Umwandlung von ASA zu verlassen, sollten wir dies selbst durchführen und Typkonflikte in der Abfrage behandeln.
Eine Möglichkeit besteht darin, die Hauptlogik anzupassen, um diese Ausnahmen zu behandeln. In diesem Fall glauben wir jedoch, dass unsere Hauptlogik perfekt ist. Überprüfen wir also stattdessen die eingehenden Daten.
Zunächst fügen wir mit WITH der Abfrage eine Eingabeüberprüfungsebene hinzu. Wir verwenden TRY_CAST, um Felder in ihren erwarteten Typ zu konvertieren, und legen sie auf NULL fest, wenn bei der Konvertierung ein Fehler auftritt:
WITH readingsValidated AS (
SELECT
-- Rename incoming fields, used for audit and debugging
deviceId AS in_deviceId,
readingTimestamp AS in_readingTimestamp,
readingStr AS in_readingStr,
readingNum AS in_readingNum,
readingArray AS in_readingArray,
-- Try casting fields in their expected type
TRY_CAST(deviceId AS bigint) as deviceId,
TRY_CAST(readingTimestamp AS datetime) as readingTimestamp,
TRY_CAST(readingStr AS nvarchar(max)) as readingStr,
TRY_CAST(readingNum AS float) as readingNum,
TRY_CAST(readingArray AS array) as readingArray
FROM readings TIMESTAMP BY readingTimestamp
)
-- For debugging only
SELECT * FROM readingsValidated
Mit der zuletzt verwendeten (Fehler enthaltenden) Eingabedatei gibt diese Abfrage den folgenden Satz zurück:
| in_deviceId | in_readingTimestamp | in_readingStr | in_readingNum | in_readingArray | deviceId | readingTimestamp | readingStr | readingNum | readingArray |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2021-12-10T10:00:00 | Eine Zeichenfolge | 1.7145 | ["A","B"] | 1 | 2021-12-10T10:00:00Z | Eine Zeichenfolge | 1.7145 | ["A","B"] |
| 2 | 2021-12-10T10:01:00 | NULL | 2.378 | ["C"] | 2 | 2021-12-10T10:01:00Z | NULL | 2.378 | ["C"] |
| 3 | 2021-12-10T10:01:20 | Eine dritte Zeichenfolge | NaN | ["D","E","F"] | 3 | 2021-12-10T10:01:20Z | Eine dritte Zeichenfolge | NULL | ["D","E","F"] |
| 4 | 2021-12-10T10:02:10 | Eine vierte Zeichenfolge | 1.2126 | {} | 4 | 2021-12-10T10:02:10Z | Eine vierte Zeichenfolge | 1.2126 | NULL |
Wir sehen bereits, dass zwei unserer Fehler behoben wurden. Wir haben NaN und {} in NULL transformiert. Nun sind wir sicher, dass diese Datensätze ordnungsgemäß in die SQL-Zieltabelle eingefügt werden.
Wir müssen nun entscheiden, wie die Datensätze mit fehlenden oder ungültigen Werten behandelt werden sollen. Nach einigen Diskussionen entscheiden wir uns, Datensätze mit einem leeren/ungültigen readingArray oder einem fehlenden readingStr abzulehnen.
Daher fügen wir eine zweite Ebene hinzu, die Datensätze zwischen der Überprüfungs- und der Hauptlogik aussondert:
WITH readingsValidated AS (
...
),
readingsToBeProcessed AS (
SELECT
deviceId,
readingTimestamp,
readingStr,
readingNum,
readingArray
FROM readingsValidated
WHERE
readingStr IS NOT NULL
AND readingArray IS NOT NULL
),
readingsToBeRejected AS (
SELECT
*
FROM readingsValidated
WHERE -- Same clauses as readingsToBeProcessed, opposed with NOT
NOT (
readingStr IS NOT NULL
AND readingArray IS NOT NULL
)
)
-- For debugging only
SELECT * INTO Debug1 FROM readingsToBeProcessed
SELECT * INTO Debug2 FROM readingsToBeRejected
Es ist eine bewährte Methode, eine einzelne WHERE-Klausel für beide Ausgaben zu schreiben und NOT (...) in der zweiten zu verwenden. Auf diese Weise können keine Datensätze von beiden Ausgaben ausgeschlossen werden und verloren gehen.
Nun erhalten wir zwei Ausgaben. Debug1 enthält die Datensätze, die an die Hauptlogik gesendet werden:
| deviceId | readingTimestamp | readingStr | readingNum | readingArray |
|---|---|---|---|---|
| 1 | 2021-12-10T10:00:00Z | Eine Zeichenfolge | 1.7145 | ["A","B"] |
| 3 | 2021-12-10T10:01:20Z | Eine dritte Zeichenfolge | NULL | ["D","E","F"] |
Debug2 enthält die Datensätze, die abgelehnt werden:
| in_deviceId | in_readingTimestamp | in_readingStr | in_readingNum | in_readingArray | deviceId | readingTimestamp | readingStr | readingNum | readingArray |
|---|---|---|---|---|---|---|---|---|---|
| 2 | 2021-12-10T10:01:00 | NULL | 2.378 | ["C"] | 2 | 2021-12-10T10:01:00Z | NULL | 2.378 | ["C"] |
| 4 | 2021-12-10T10:02:10 | Eine vierte Zeichenfolge | 1.2126 | {} | 4 | 2021-12-10T10:02:10Z | Eine vierte Zeichenfolge | 1.2126 | NULL |
Im letzten Schritt fügen wir die Hauptlogik wieder hinzu. Wir fügen auch die Ausgabe hinzu, die Ablehnungen sammelt. Hier ist es am besten, einen Ausgabeadapter zu verwenden, der keine starke Eingabe erzwingt, z. B. ein Speicherkonto.
Die vollständige Abfrage finden Sie im letzten Abschnitt.
WITH
readingsValidated AS (...),
readingsToBeProcessed AS (...),
readingsToBeRejected AS (...)
SELECT
r.deviceId,
r.readingTimestamp,
SUBSTRING(r.readingStr,1,200) AS readingStr,
ROUND(r.readingNum,2) AS readingNum,
COUNT(a.ArrayValue) AS arrayCount
INTO SQLOutput
FROM readingsToBeProcessed AS r
CROSS APPLY GetArrayElements(r.readingArray) AS a
WHERE UDF.udfLen(r.readingStr) >= 2
GROUP BY
System.Timestamp(), --snapshot window
r.deviceId,
r.readingTimestamp,
r.readingStr,
r.readingNum
SELECT
*
INTO BlobOutput
FROM readingsToBeRejected
So erhalten wir den folgenden Satz für SQLOutput ohne möglichen Fehler:
| deviceId | readingTimestamp | readingStr | readingNum | readingArray |
|---|---|---|---|---|
| 1 | 2021-12-10T10:00:00Z | Eine Zeichenfolge | 1.7145 | 2 |
| 3 | 2021-12-10T10:01:20Z | Eine dritte Zeichenfolge | NULL | 3 |
Die anderen beiden Datensätze werden zur Überprüfung durch Personen und Nachbearbeitung an ein BlobOutput gesendet. Unsere Abfrage ist jetzt sicher.
Beispiel für eine Abfrage mit Eingabeüberprüfung
WITH readingsValidated AS (
SELECT
-- Rename incoming fields, used for audit and debugging
deviceId AS in_deviceId,
readingTimestamp AS in_readingTimestamp,
readingStr AS in_readingStr,
readingNum AS in_readingNum,
readingArray AS in_readingArray,
-- Try casting fields in their expected type
TRY_CAST(deviceId AS bigint) as deviceId,
TRY_CAST(readingTimestamp AS datetime) as readingTimestamp,
TRY_CAST(readingStr AS nvarchar(max)) as readingStr,
TRY_CAST(readingNum AS float) as readingNum,
TRY_CAST(readingArray AS array) as readingArray
FROM readings TIMESTAMP BY readingTimestamp
),
readingsToBeProcessed AS (
SELECT
deviceId,
readingTimestamp,
readingStr,
readingNum,
readingArray
FROM readingsValidated
WHERE
readingStr IS NOT NULL
AND readingArray IS NOT NULL
),
readingsToBeRejected AS (
SELECT
*
FROM readingsValidated
WHERE -- Same clauses as readingsToBeProcessed, opposed with NOT
NOT (
readingStr IS NOT NULL
AND readingArray IS NOT NULL
)
)
-- Core business logic
SELECT
r.deviceId,
r.readingTimestamp,
SUBSTRING(r.readingStr,1,200) AS readingStr,
ROUND(r.readingNum,2) AS readingNum,
COUNT(a.ArrayValue) AS arrayCount
INTO SQLOutput
FROM readingsToBeProcessed AS r
CROSS APPLY GetArrayElements(r.readingArray) AS a
WHERE UDF.udfLen(r.readingStr) >= 2
GROUP BY
System.Timestamp(), --snapshot window
r.deviceId,
r.readingTimestamp,
r.readingStr,
r.readingNum
-- Rejected output. For human review, correction, and manual re-insertion downstream
SELECT
*
INTO BlobOutput -- to a storage adapter that doesn't require strong typing, here blob/adls
FROM readingsToBeRejected
Erweitern der Eingabeüberprüfung
GetType kann zur expliziten Überprüfung auf einen Typ hin verwendet werden. Es funktioniert gut mit CASE in der Projektion oder mit WHERE in der Einstellungsebene. GetType kann auch verwendet werden, um das eingehende Schema dynamisch anhand eines Metadatenrepositorys zu überprüfen. Das Repository kann über ein Referenzdataset geladen werden.
Komponententests sind eine bewährte Methode, um sicherzustellen, dass unsere Abfrage resilient ist. Wir erstellen eine Reihe von Tests, die aus Eingabedateien und deren erwarteter Ausgabe bestehen. Unsere Abfrage muss mit der Ausgabe übereinstimmen, die sie generiert, um sie zu übergeben. In ASA werden Komponententests über das npm-Modul asa-streamanalytics-cicd durchgeführt. Testfälle mit verschiedenen nicht wohlgeformten Ereignissen sollten in der Bereitstellungspipeline erstellt und getestet werden.
Schließlich können wir einige einfache Integrationstests in VS Code durchführen. Wir können Datensätze über eine lokale Ausführung mit Liveausgabe in die SQL-Tabelle einfügen.
Support
Weitere Unterstützung finden Sie auf der Frageseite von Microsoft Q&A (Fragen und Antworten) zu Azure Stream Analytics.
Nächste Schritte
- Einrichten von CI/CD-Pipelines und Komponententests mithilfe des npm-Pakets
- Übersicht über lokale Stream Analytics-Ausführungen in Visual Studio Code mit ASA-Tools
- Lokales Testen von Stream Analytics-Abfragen mit Beispieldaten mithilfe von Visual Studio Code
- Lokales Testen von Stream Analytics-Abfragen unter Verwendung einer Livestreameingabe mithilfe von Visual Studio Code
- Erkunden von Azure Stream Analytics mit Visual Studio Code (Vorschauversion)