Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel werden die Optionen für den Kompatibilitätsgrad in Azure Stream Analytics beschrieben.
Stream Analytics ist ein verwalteter Dienst mit regelmäßigen Funktionsupdates und Leistungsverbesserungen. Bei den meisten Dienstruntimes sind Updates automatisch und unabhängig vom Kompatibilitätsgrad für Endbenutzer verfügbar. Wenn eine neue Funktionalität jedoch zu Veränderungen beim Verhalten von vorhandenen Aufträgen oder der Art und Weise führt, wie Daten in laufenden Aufträgen genutzt werden, führen wir diese Änderung unter einem neuen Kompatibilitätsgrad ein. Sie können Ihre vorhandenen Stream Analytics-Aufträge ohne wesentliche Änderungen weiter ausführen, indem Sie einen niedrigen Kompatibilitätsgrad festlegen. Wenn Sie bereit für das neueste Laufzeitverhalten sind, können Sie sich dafür entscheiden, indem Sie das Kompatibilitätsniveau erhöhen.
Auswählen eines Kompatibilitätsgrads
Der Kompatibilitätsgrad steuert das Laufzeitverhalten eines Stream Analytics-Auftrags.
Azure Stream Analytics unterstützt zurzeit drei Kompatibilitätsgrade:
- 1.2 – neuestes Verhalten mit den neuesten Verbesserungen
- 1.1 – Vorheriges Verhalten
- 1.0 – Ursprünglicher Kompatibilitätsgrad, der mit der allgemeinen Verfügbarkeit von Azure Stream Analytics vor einigen Jahren eingeführt wurde
Wenn Sie einen neuen Stream Analytics-Auftrag erstellen, gilt es als bewährte Methode, diesen mit dem neuesten Kompatibilitätsgrad zu erstellen. Starten Sie Ihren Arbeitsentwurf mit den neuesten Verhaltensweisen, um spätere zusätzliche Änderungen und damit verbundene Komplexität zu vermeiden.
Festlegen des Kompatibilitätsgrads
Sie können den Kompatibilitätsgrad für einen Stream Analytics-Auftrag über das Azure-Portal oder mithilfe des REST-API-Aufrufs „create job“ festlegen.
So aktualisieren Sie den Kompatibilitätsgrad des Auftrags im Azure-Portal
- Navigieren Sie im Azure-Portal zu Ihrem Stream Analytics-Auftrag.
- Beenden Sie den Auftrag, bevor Sie den Kompatibilitätsgrad aktualisieren. Der Kompatibilitätsgrad kann nicht aktualisiert werden, wenn der Auftrag ausgeführt wird.
- Wählen Sie unter der Überschrift Konfigurieren die Option Kompatibilitätsgrad aus.
- Wählen Sie den gewünschten Wert für den Kompatibilitätsgrad aus.
- Wählen Sie unten auf der Seite Speichern aus.
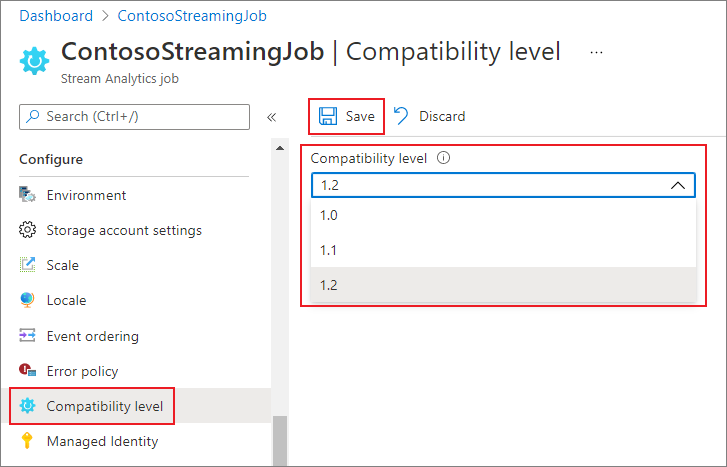
Wenn Sie den Kompatibilitätsgrad aktualisieren, überprüft der T-Compiler den Auftrag mit der Syntax, die dem ausgewählten Kompatibilitätsgrad entspricht.
Kompatibilitätsgrad 1.2
Beim Kompatibilitätsgrad 1.2 wurden die folgenden grundlegenden Änderungen eingeführt:
AMQP-Messagingprotokoll
Ebene 1.2: Azure Stream Analytics verwendet das Nachrichtenprotokoll Advanced Message Queueing Protocol (AMQP), um in Service Bus-Warteschlangen und -Themen zu schreiben. AMQP gibt Ihnen die Möglichkeit, plattformübergreifende Hybridanwendungen mit einem offenen Standard zu erstellen.
Geofunktionen
Vorherige Ebenen: In Azure Stream Analytics wurden geografische Berechnungen verwendet.
Ebene 1.2: Mit Azure Stream Analytics können Sie projizierte geometrische Geo-Koordinaten berechnen. Es gibt keine Änderung in der Signatur der Geofunktionen. Ihre Semantik ist jedoch etwas anders, sodass eine genauere Berechnung ermöglicht wird als bisher.
Azure Stream Analytics unterstützt die Indizierung von räumlichen Verweisdaten. Verweisdaten, die Geoelemente enthalten, können für eine schnellere Berechnung von Verknüpfungen indiziert werden.
Die aktualisierten Geofunktionen ermöglichen die volle Ausdrucksfähigkeit des Geoformats Well Known Text (WKT). Sie können andere Geokomponenten angeben, die bisher mit GeoJson nicht unterstützt wurden.
Weitere Informationen finden Sie unter Updates to geospatial features in Azure Stream Analytics – Cloud and IoT Edge (Aktualisierungen für Geofunktionen in Azure Stream Analytics – Cloud und IoT Edge).
Ausführung paralleler Abfragen für Eingabequellen mit mehreren Partitionen
Vorherige Ebenen: Für Azure Stream Analytics-Abfragen war die Verwendung der Klausel „PARTITION BY“ erforderlich, um die Verarbeitung von Abfragen in Partitionen von Eingabequellen zu parallelisieren.
Ebene 1.2: Wenn die Abfragelogik in Partitionen von Eingabequellen parallelisiert werden kann, werden in Azure Stream Analytics separate Abfrageinstanzen erstellt und Berechnungen parallel ausgeführt.
Native API-Massenintegration in Azure Cosmos DB-Ausgabe
Vorherige Ebenen: Das Upsert-Verhalten war Einfügen oder Zusammenführen.
Ebene 1.2: Durch die native API-Massenintegration in die Azure Cosmos DB-Ausgabe werden der Durchsatz maximiert und Drosselungsanforderungen effizient verarbeitet. Weitere Informationen finden Sie auf der Seite zur Azure Stream Analytics-Ausgabe an Azure Cosmos DB.
Das Upsertverhalten lautet Einfügen oder Ersetzen.
DateTimeOffset beim Schreiben in die SQL-Ausgabe
Vorherige Ebenen:DateTimeOffset-Typen wurden an UTC angepasst.
Ebene 1.2: DateTimeOffset wird nicht mehr angepasst.
Long beim Schreiben in SQL-Ausgabe
Vorherige Ebenen: Werte wurden je nach Zieltyp gekürzt.
Ebene 1.2: Werte, die nicht in den Zieltyp passen, werden gemäß der Richtlinie für Ausgabefehler behandelt.
Datensatz- und Arrayserialisierung beim Schreiben in die SQL-Ausgabe
Vorherige Ebenen: Datensätze wurden als „Datensatz“ und Arrays als „Array“ geschrieben.
Ebene 1.2: Datensätze und Arrays werden im JSON-Format serialisiert.
Strikte Überprüfung des Präfixes von Funktionen
Vorherige Ebenen: Es wurde keine strikte Überprüfung von Funktionspräfixen durchgeführt.
Ebene 1.2: In Azure Stream Analytics erfolgt eine strikte Überprüfung von Funktionspräfixen. Das Hinzufügen eines Präfixes zu einer integrierten Funktion verursacht einen Fehler.
myprefix.ABS(…) wird beispielsweise nicht unterstützt.
Auch das Hinzufügen eines Präfixes zu integrierten Aggregaten führt zu einem Fehler.
myprefix.SUM(…) wird beispielsweise nicht unterstützt.
Die Verwendung des Präfixes „system“ für benutzerdefinierte Funktionen führt zu einem Fehler.
Verwendung von „Array“ und „Object“ als Schlüsseleigenschaften im Azure Cosmos DB-Ausgabeadapter verbieten
Vorherige Ebenen: Die Typen „Array“ und „Object“ wurden als Schlüsseleigenschaft unterstützt.
Ebene 1.2: Die Typen „Array“ und „Object“ werden nicht mehr als Schlüsseleigenschaft unterstützt.
Deserialisieren boolescher Typen in JSON, AVRO und PARQUET
Vorherige Stufen: Azure Stream Analytics deserialisiert boolesche Werte in den Typ BIGINT - false ordnet 0 zu und true ordnet 1 zu. Die Ausgabe erstellt boolesche Werte in JSON, AVRO und PARQUET nur dann, wenn Sie Ereignisse explizit in BIT konvertieren.
Beispielsweise wird eine Pass-Through-Abfrage wie SELECT value INTO output1 FROM input1, die ein JSON { "value": true } aus Eingabe1 liest, einen JSON-Wert { "value": 1 } in die Ausgabe1 schreiben.
Ebene 1.2: Azure Stream Analytics deserialisiert den booleschen Wert in den Typ BIT. FALSCH wird 0 zugeordnet, WAHR 1. Eine Pass-Through-Abfrage wie SELECT value INTO output1 FROM input1, die ein JSON { "value": true } aus Eingabe1 liest, wird einen JSON-Wert { "value": true } in die Ausgabe1 schreiben. Sie können den Wert in den Typ BIT in der Abfrage umwandeln, um sicherzustellen, dass sie in der Ausgabe für Formate, die boolesche Typen unterstützen, als WAHR und FALSCH angezeigt werden.
Kompatibilitätsgrad 1.1
Beim Kompatibilitätsgrad 1.1 wurden die folgenden grundlegenden Änderungen eingeführt:
Service Bus-XML-Format
Ebene 1.0: Azure Stream Analytics verwendete DataContractSerializer, damit der Inhalt der Meldung XML-Tags enthielt. Beispiel:
@\u0006string\b3http://schemas.microsoft.com/2003/10/Serialization/\u0001{ "SensorId":"1", "Temperature":64\}\u0001
Ebene 1.1: Der Nachrichteninhalt enthält den Datenstrom direkt und ohne weitere Tags. Beispiel: { "SensorId":"1", "Temperature":64}
Beibehalten von Groß-/Kleinbuchstaben für Feldnamen
Ebene 1.0: Feldnamen wurden in Kleinbuchstaben umgewandelt, wenn sie vom Azure Stream Analytics-Modul verarbeitet wurden.
1.1 Level: Groß- und Kleinschreibung wird für Feldnamen beibehalten, wenn sie von der Azure Stream Analytics Engine verarbeitet werden.
Hinweis
Das Beibehalten der Groß- und Kleinschreibung ist für Stream Analytics-Aufträge, die mithilfe der Edge-Umgebung gehostet werden, noch nicht verfügbar. Daher werden alle Feldnamen in Kleinbuchstaben konvertiert, wenn der Auftrag auf Edge gehostet wird.
FloatNaN-Deserialisierung deaktiviert
Ebene 1.0: Der Befehl CREATE TABLE filterte nicht nach NaN-Ereignissen (Not a Number, keine Zahl; Beispiel: Infinity, -Infinity) in einer Spalte vom Typ FLOAT, da diese sich außerhalb des dokumentierten Bereichs für diese Zahlen befinden.
Ebene 1.1: CREATE TABLE erlaubt die Angabe eines festen Schemas. Das Stream Analytics-Modul überprüft, ob die Daten diesem Schema entsprechen. Mit diesem Modell kann der Befehl Ereignisse mit NaN-Werten filtern.
Deaktivieren Sie die automatische Umwandlung von Datumszeit-Zeichenfolgen in den DateTime-Typ bei der JSON-Eingabe
Ebene 1.0: Der JSON-Parser würde automatisch Zeichenfolgenwerte mit Datums-/Uhrzeit-/Zoneninformationen beim Eingang in den DATETIME-Typ konvertieren, sodass der Wert sofort seine ursprünglichen Formatierungs- und Zeitzoneninformationen verliert. Da dies beim Eingang erfolgt, selbst wenn dieses Feld nicht in der Abfrage verwendet wurde, wird der Wert in UTC-DateTime konvertiert.
Ebene 1.1: Es erfolgt keine automatische Umwandlung von Zeichenfolgenwerten mit Datums-/Uhrzeit-/Zoneninformationen in den Typ DATETIME. Folglich werden Zeitzoneninformationen und die ursprüngliche Formatierung beibehalten. Wenn jedoch das Feld NVARCHAR(MAX) in der Abfrage als Teil eines DATETIME-Ausdrucks (z. B. DATEADD-Funktion) verwendet wird, wird es in den DATETIME-Typ konvertiert, um die Berechnung auszuführen, und verliert sein ursprüngliches Format.