Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Azure Stream Analytics kann Daten im JSON-Format an Azure Cosmos DB ausgeben. Dies ermöglicht eine Datenarchivierung und latenzarme Abfragen unstrukturierter JSON-Daten. In diesem Artikel werden einige der besten Praktiken für die Implementierung dieser Konfiguration (von Stream Analytics zu Cosmos DB) behandelt. Wenn Sie mit Azure Cosmos DB nicht vertraut sind, lesen Sie zum Einstieg die Azure Cosmos DB-Dokumentation.
Hinweis
- Derzeit unterstützt Stream Analytics die Verbindung mit Azure Cosmos DB nur über die SQL-API. Andere Azure Cosmos DB-APIs werden noch nicht unterstützt. Wenn Sie Stream Analytics auf mit anderen APIs erstellte Azure Cosmos DB-Konten verweisen, werden die Daten unter Umständen nicht richtig gespeichert.
- Wenn Sie Azure Cosmos DB als Ausgabe verwenden, empfiehlt es sich, den Auftrag auf den Kompatibilitätsgrad 1.2 festzulegen.
Grundlagen von Azure Cosmos DB als Ausgabeziel
Die Azure Cosmos DB-Ausgabe in Stream Analytics ermöglicht das Schreiben der Ergebnisse Ihrer Datenstromverarbeitung als JSON-Ausgabe in Ihre(n) Azure Cosmos DB-Container. Stream Analytics erstellt keine Container in Ihrer Datenbank. Stattdessen müssen Sie sie vorher erstellen. Auf diese Weise können Sie die Abrechnungskosten für Azure Cosmos DB Container steuern. Ferner können Sie die Leistung, Konsistenz und Kapazität ihrer Container auch direkt mithilfe der Azure Cosmos DB-APIs optimieren. In den folgenden Abschnitten werden einige der Containeroptionen für Azure Cosmos DB ausführlich erläutert.
Optimieren von Konsistenz, Verfügbarkeit und Latenz
Entsprechend Ihren Anwendungsanforderungen lässt Azure Cosmos DB das Optimieren der Datenbank und Container sowie Kompromisse zwischen Konsistenz, Verfügbarkeit, Latenz und Durchsatz zu.
Abhängig von den Lesekonsistenzebenen, die Ihr Szenario hinsichtlich Lese- und Schreiblatenz benötigt, können Sie in Ihrem Datenbankkonto eine Konsistenzebene wählen. Sie können den Durchsatz verbessern, indem Sie Anforderungseinheiten (Request Units, RUs) für den Container hochskalieren. Standardmäßig aktiviert Azure Cosmos DB für jeden CRUD-Vorgang in Ihrem Container die synchrone Indizierung. Dies ist eine weitere nützliche Option zum Steuern der Schreib-/Leseleistung in Azure Cosmos DB. Weitere Informationen finden Sie im Artikel Ändern der Datenbank- und Abfragekonsistenzebenen.
Einfügen/Aktualisieren über Stream Analytics
Die Stream Analytics-Integration mit Azure Cosmos DB ermöglicht das Einfügen oder Aktualisieren von Datensätzen in Ihrem Container auf der Grundlage einer angegebenen Dokument-ID-Spalte. Dieser Vorgang wird auch als Upsert bezeichnet. Stream Analytics verwendet einen optimistischen Upsert-Ansatz. Updates werden nur durchgeführt, wenn bei einem Einfügen ein Fehler aufgrund eines Dokument-ID-Konflikts auftritt.
Beim Kompatibilitätsgrad 1.0 führt Stream Analytics dieses Update als PATCH-Vorgang aus, sodass Teilupdates des Dokuments möglich sind. Stream Analytics fügt neue Eigenschaften hinzu oder ersetzt eine vorhandene Eigenschaft inkrementell. Änderungen der Werte von Arrayeigenschaften in Ihrem JSON-Dokument führen jedoch zu einem Überschreiben des gesamten Arrays. Das heißt, das Array wird nicht zusammengeführt.
Für Kompatibilitätsgrad 1.2 wurde das Upsert-Verhalten so geändert, dass das Dokument eingefügt oder ersetzt wird. Im Abschnitt zum Kompatibilitätsgrad 1.2 weiter unten wird dieses Verhalten beschrieben.
Wenn im eingehenden JSON-Dokument ein ID-Feld vorhanden ist, wird dieses Feld automatisch als Spalte Dokument-ID in Azure Cosmos DB verwendet. Alle nachfolgenden Schreibvorgänge werden als solche verarbeitet, was zu einer der folgenden Situationen führen kann:
- Eindeutige IDs führen zum Einfügen.
- Doppelte IDs und die Angabe ID für Dokument-ID lösen einen Upsertvorgang aus
- Doppelte IDs und eine nicht angegebene Dokument-ID lösen nach dem ersten Dokument einen Fehler aus.
Wenn Sie alle Dokumente speichern möchten, einschließlich derjenigen mit einer doppelten ID, benennen Sie das ID-Feld in der Abfrage um (mit dem Schlüsselwort AS). Lassen Sie Azure Cosmos DB das ID-Feld erstellen, oder ersetzen Sie die ID durch den Wert einer anderen Spalte (mithilfe des Schlüsselworts AS oder der Einstellung Dokument-ID).
Partitionierung von Daten in Azure Cosmos DB
Azure Cosmos DB skaliert Partitionen automatisch auf der Grundlage Ihrer Workload. Daher empfiehlt es sich, unbegrenzte Container für die Partitionierung Ihrer Daten zu verwenden. Beim Schreiben in unbegrenzte Container verwendet Stream Analytics so viele parallele Writer wie im vorherigen Abfrageschritt oder im eingegebenen Partitionierungsschema.
Hinweis
Azure Stream Analytics unterstützt nur unbegrenzte Container mit Partitionsschlüsseln auf der obersten Ebene. Beispielsweise wird /region unterstützt. Geschachtelte Partitionsschlüssel (z. B. /region/name) werden nicht unterstützt.
Abhängig von Ihrer Partitionsschlüsselauswahl wird möglicherweise diese Warnung angezeigt:
CosmosDB Output contains multiple rows and just one row per partition key. If the output latency is higher than expected, consider choosing a partition key that contains at least several hundred records per partition key.
Es ist wichtig, eine Partitionsschlüsseleigenschaft zu wählen, die viele unterschiedliche Werte aufweist und es Ihnen ermöglicht, Ihre Workload gleichmäßig auf diese Werte zu verteilen. Als natürliches Artefakt der Partitionierung werden Anfragen mit dem gleichen Partitionsschlüssel durch den maximalen Durchsatz einer einzelnen Partition begrenzt.
Die Speichergröße für Dokumente mit dem gleichen Partitionsschlüsselwert ist auf 20 GB beschränkt. (Die Größenbeschränkung für die physische Partition beträgt 50 GB.) Ein idealer Partitionsschlüssel ist ein Schlüssel, der in Ihren Abfragen häufig als Filter verwendet wird und eine ausreichende Kardinalität besitzt, um die Skalierbarkeit Ihrer Lösung sicherzustellen.
Partitionsschlüssel, die für Stream Analytics-Abfragen und Azure Cosmos DB verwendet werden, müssen nicht identisch sein. Bei vollständig parallelen Topologien wird die Verwendung eines Eingabepartitionsschlüssels (PartitionId) als Partitionsschlüssel der Stream Analytics-Abfrage empfohlen. Bei Azure Cosmos DB-Containern ist dies aber möglicherweise nicht zu empfehlen.
Ein Partitionsschlüssel ist auch die Grenze für Transaktionen in gespeicherten Prozeduren und Triggern für Azure Cosmos DB. Sie sollten den Partitionsschlüssel so auswählen, dass Dokumente, die gemeinsam in Transaktionen auftreten, denselben Partitionsschlüsselwert haben. Der Artikel Partitionierung in Azure Cosmos DB bietet ausführlichere Informationen zur Auswahl eines Partitionsschlüssels.
Bei festen Azure Cosmos DB-Containern lässt Stream Analytics kein Hoch- oder Aufskalieren zu, nachdem diese voll sind. Sie haben eine Obergrenze von 10 GB und einen Durchsatz von 10.000 RU/s. Zum Migrieren der Daten aus einem festen Container zu einem unbegrenzten Container (beispielsweise mit mindestens 1.000 RU/s und einem Partitionsschlüssel) verwenden Sie das Datenmigrationstool oder die Änderungsfeedbibliothek.
Die Möglichkeit, in mehrere feststehende Container zu schreiben, wird eingestellt. Wir empfehlen diese Möglichkeit für das horizontale Skalieren von Stream Analytics-Aufträgen nicht.
Verbesserter Durchsatz mit Kompatibilitätsgrad 1.2
Bei Kompatibilitätsgrad 1.2 unterstützt Stream Analytics die native Integration für das Massenschreiben in Azure Cosmos DB. Diese Integration ermöglicht ein effektives Schreiben in Azure Cosmos DB bei zugleich maximierter Durchsatzleistung und effizientem Umgang mit Drosselungsanforderungen.
Der verbesserte Schreibmechanismus ist aufgrund eines Unterschieds im Upsertverhalten unter einem neuen Kompatibilitätsgrad verfügbar. Bei Kompatibilitätsgraden vor 1.2 sieht das Upsertverhalten ein Einfügen oder Zusammenführen des Dokuments vor. Für Kompatibilitätsgrad 1.2 wurde das Upsert-Verhalten so geändert, dass das Dokument eingefügt oder ersetzt wird.
Bei Graden vor 1.2 verwendet Stream Analytics eine benutzerdefinierte gespeicherte Prozedur, um ein Massenupsert von Dokumenten pro Partitionsschlüssel in Azure Cosmos DB durchzuführen. In diesem Fall wird ein Batch als Transaktion abgewickelt. Selbst bei einem vorübergehenden Fehler bei einem einzelnen Datensatz (Drosselung) muss der ganze Batch wiederholt werden. Durch dieses Verhalten werden selbst Szenarien mit mäßiger Drosselung vergleichsweise langsam.
Das folgende Beispiel zeigt zwei identische Stream Analytics-Aufträge, die aus der gleichen Azure Event Hubs-Eingabe lesen. Beide Stream Analytics-Aufträge sind vollständig partitioniert, weisen eine Passthrough-Abfrage auf und schreiben in identische Azure Cosmos DB-Container. Die auf der linken Seite angezeigten Metriken stammen aus dem Auftrag, der mit Kompatibilitätsstufe 1.0 konfiguriert ist. Die Metriken auf der rechten Seite wurden mit 1.2 konfiguriert. Der Partitionsschlüssel von Azure Cosmos DB-Containern ist eine eindeutige GUID, die aus dem Eingabeereignis stammt.
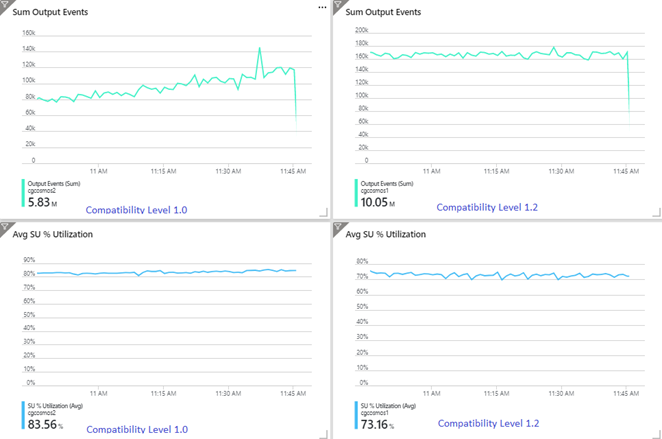
Die Rate der in Event Hubs eingehenden Ereignisse ist zweimal höher als die der Azure Cosmos DB-Container (20.000 RUs), die für die Aufnahme konfiguriert sind, weshalb in Azure Cosmos DB mit Drosselung zu rechnen ist. Der Auftrag mit Kompatibilitätsgrad 1.2 schreibt jedoch konsistent mit einem höheren Durchsatz (Ausgabeereignisse pro Minute) und mit einer niedrigeren durchschnittlichen Auslastung von Speichereinheiten (SUs in %). Wie groß der Unterschied in Ihrer Umgebung ist, hängt von einigen weiteren Faktoren ab. Zu diesen Faktoren zählen das gewählte Ereignisformat, die Größe von Eingabeereignissen/Nachrichten, die Partitionsschlüssel und die Abfrage.
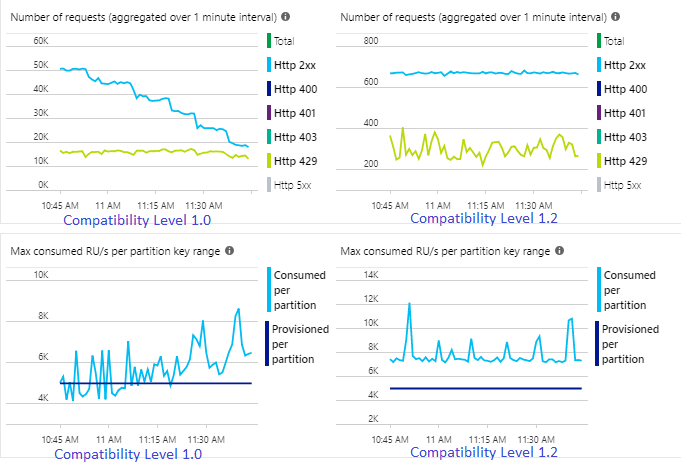
Beim Kompatibilitätsgrad 1.2 kann Stream Analytics den verfügbaren Durchsatz in Azure Cosmos DB intelligenter zu 100 Prozent nutzen (mit wenigen erneuten Übermittlungen aufgrund von Drosselung oder Ratenbegrenzung). Dieses Verhalten ermöglicht eine bessere Erfahrung für andere Workloads, z. B. Abfragen, die gleichzeitig für den Container ausgeführt werden. Wenn Sie sehen möchten, wie Stream Analytics mit Azure Cosmos DB als Senke für 1.000 bis 10.000 Nachrichten pro Sekunde skaliert, probieren Sie dieses Azure-Beispielprojekt aus.
Der Durchsatz der Azure Cosmos DB-Ausgabe ist bei 1.0 und 1.1 identisch. Es wird dringend empfohlen, in Stream Analytics Azure Cosmos DB Kompatibilitätsgrad 1.2 zu verwenden.
Azure Cosmos DB-Einstellungen für die JSON-Ausgabe
Beim Verwenden von Azure Cosmos DB als Ausgabe in Stream Analytics wird die folgende Aufforderung zur Eingabe von Informationen generiert.
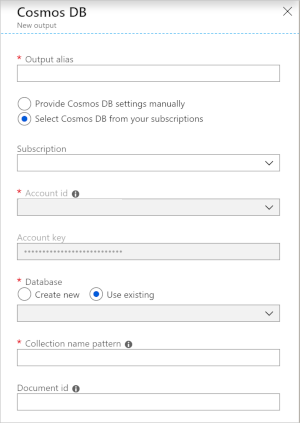
| Feld | BESCHREIBUNG |
|---|---|
| Ausgabealias | Ein Alias zum Verweisen auf diese Ausgabe in Ihrer Stream Analytics-Abfrage. |
| Abonnement | Das Azure-Abonnement. |
| Konto-ID | Der Name oder Endpunkt-URI des Azure Cosmos DB-Kontos. |
| Kontoschlüssel | Der Schlüssel für den gemeinsamen Zugriff für das Azure Cosmos DB-Konto. |
| Datenbank | Der Name der Azure Cosmos DB-Datenbank. |
| Containername | Der Name des Containers, wie etwa MyContainer. Ein Container mit dem Namen MyContainer muss vorhanden sein. |
| Dokument-ID | Optional. Der Spaltenname in Ausgabeergebnissen, der als eindeutiger Schlüssel verwendet wird, auf dem Einfüge- oder Aktualisierungsvorgänge basieren müssen. Wenn Sie das Feld leer lassen, werden alle Ereignisse ohne Option zum Aktualisieren eingefügt. |
Nach dem Konfigurieren der Azure Cosmos DB-Ausgabe können Sie sie in der Abfrage als Ziel einer INTO-Anweisung verwenden. Wenn Sie eine Azure Cosmos DB-Ausgabe in dieser Weise verwenden, muss ein Partitionsschlüssel explizit festgelegt werden.
Der Ausgabedatensatz muss eine Spalte mit Berücksichtigung der Groß-/Kleinschreibung enthalten, die nach dem Partitionsschlüssel in Azure Cosmos DB benannt ist. Für eine bessere Parallelisierung erfordert die Anweisung möglicherweise eine PARTITION BY-Klausel, die die gleiche Spalte verwendet.
Dies ist eine Beispielabfrage:
SELECT TollBoothId, PartitionId
INTO CosmosDBOutput
FROM Input1 PARTITION BY PartitionId
Fehlerbehandlung und Wiederholungsversuche
Falls ein vorübergehender Fehler, eine Nichtverfügbarkeit oder eine Drosselung des Diensts auftritt, während Stream Analytics Ereignisse an Azure Cosmos DB sendet, unternimmt Stream Analytics unbegrenzt viele Wiederholungsversuche, um den Vorgang erfolgreich abzuschließen. Bei den folgenden Fehlern werden jedoch keine Wiederholungsversuche unternommen:
- Nicht autorisiert (HTTP-Fehlercode 401)
- NotFound (HTTP-Fehlercode 404)
- Verboten (HTTP-Fehlercode 403)
- BadRequest (HTTP-Fehlercode 400)
Häufige Probleme
Der Sammlung wird eine Einschränkung für eindeutige Indizes hinzugefügt, und diese Einschränkung wird von den Stream Analytics-Ausgabedaten nicht erfüllt. Stellen Sie sicher, dass die Ausgabedaten von Stream Analytics Eindeutigkeitseinschränkungen erfüllen, oder entfernen Sie Einschränkungen. Weitere Informationen finden Sie unter Einschränkungen für eindeutige Schlüssel in Azure Cosmos DB.
Die Spalte
PartitionKeyist nicht vorhanden.Die Spalte
Idist nicht vorhanden.
Nächste Schritte
- Grundlegendes zu den Ausgaben von Azure Stream Analytics
- Azure Stream Analytics-Ausgabe in die Azure SQL-Datenbank
- Benutzerdefinierte Blobausgabepartitionierung in Azure Stream Analytics