Zuordnen von Daten in Azure Synapse Analytics
Was ist das Datenzuordnungstool?
Das Datenzuordnungstool ist ein geführter Prozess, mit dem Benutzer ETL-Zuordnungen und Zuordnungsdatenflüsse zwischen Ihren Quelldaten und Synapse-Lake-Datenbanktabellen erstellen können, ohne Code schreiben zu müssen. Dieser Prozess beginnt damit, dass der Benutzer die Zieltabellen in Synapse Lake-Datenbanken auswählt und dann seine Quelldaten diesen Tabellen zuordnet.
Weitere Informationen zu Synapse-Lake-Datenbanken finden Sie unter Übersicht über Azure Synapse-Datenbankvorlagen – Azure Synapse Analytics | Microsoft-Dokumentation.
Das Datenzuordnungstool bietet eine geführte Erfahrung, in der Benutzer schnell einen Zuordnungsdatenfluss generieren können, ohne ganz von vorne anfangen zu müssen. Anschließend können Sie schnell einen skalierbaren Zuordnungsdatenfluss generieren, der in Synapse-Pipelines ausgeführt werden kann.
Erste Schritte
Das Datenzuordnungstool wird innerhalb der Synapse-Lake-Datenbankumgebung gestartet. Hier können Sie das Datenzuordnungstool auswählen, um den Prozess zu starten.
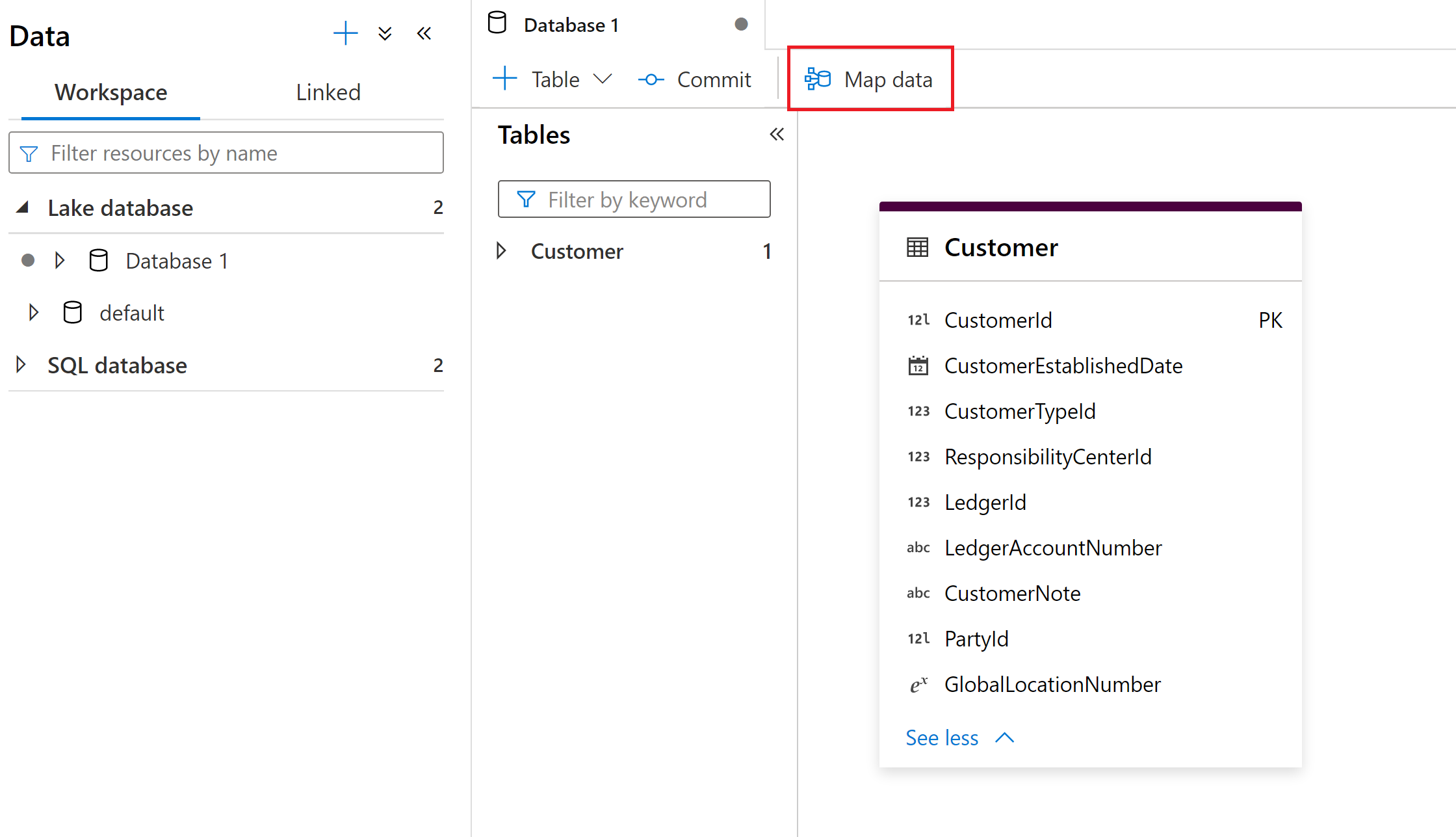
Für die Datenzuordnung müssen Compute-Ressourcen verfügbar sein, um Benutzer beim Anzeigen einer Datenvorschau sowie beim Lesen des Schemas ihrer Quelldateien unterstützen zu können. Wenn Sie das Datenzuordnungstool zum ersten Mal in einer Sitzung verwenden, müssen Sie einen Cluster aufwärmen.

Wählen Sie zunächst Ihre Datenquelle aus, die Sie Ihren Lake-Datenbanktabellen zuordnen möchten. Derzeit werden Azure Data Lake Storage Gen2-Datenbanken und Synapse-Lake-Datenbanken unterstützt.

Optionen für den Dateityp
Wenn Sie einen Dateispeicher wie Azure Data Lake Storage Gen2 auswählen, werden folgende Dateitypen unterstützt:
- Common Data Model
- Durch Trennzeichen getrennter Text
- Parquet
Erstellen einer Datenzuordnung
Konfigurieren Sie Ihre Datenzuordnung mit Ihrem ausgewählten Quelltyp.

Hinweis
Sie können einen Ordner oder eine einzelne Datei auswählen. Wenn Sie einen Ordner auswählen, können Sie mehrere Dateien Ihren Lake-Datenbanktabellen zuordnen. Wenn Sie einen Ordner auswählen, werden Sie nach der Auswahl von „Weiter“ außerdem aufgefordert, nur bestimmte Dateien einzuschließen, falls gewünscht.
Benennen Sie Ihre Datenzuordnung, und wählen Sie das Synapse-Lake-Datenbankziel aus.

Zuordnen der Quelle zum Ziel
Wählen Sie eine primäre Quelltabelle aus, die der Zieltabelle der Synapse-Lake-Datenbank zugeordnet werden soll.

Neue Zuordnung
Verwenden Sie die Schaltfläche „Neue Zuordnung“, um eine Zuordnungsmethode für die Erstellung einer Zuordnung oder Transformation hinzuzufügen.
„Additional source“ (Zusätzliche Quelle)
Verwenden Sie die Schaltfläche „Additional source“ (Zusätzliche Quelle), um eine Verknüpfung einzurichten und Ihrer Zuordnung eine weitere Quelle hinzuzufügen.
Datenvorschau
Auf der Registerkarte Datenvorschau wird eine interaktive Momentaufnahme der Daten der jeweiligen Transformation angezeigt. Weitere Informationen finden Sie unter Datenvorschau im Debugmodus.
Zuordnungsmethoden
Folgende Zuordnungsmethoden werden unterstützt:
- Direkt
- Ersatzschlüssel
- Suche
- Entpivotieren
-
Aggregat
- Sum
- Minimum
- Maximum
- First (Erster)
- Last (Letzter)
- Standardabweichung
- Average
- Mittelwert
-
Abgeleitete Spalte
- Glätten
- Upper
- Geringer
- Fortgeschrittene
Erstellen der Pipeline
Wenn Sie mit den Transformationen für die Datenzuordnung fertig sind, können Sie die Schaltfläche „Pipeline erstellen“ auswählen, um einen Zuordnungsdatenfluss und eine Pipeline zum Debuggen und Ausführen der Transformation zu generieren.