Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Zusammenfassung: Azure Synapse Analytics ist eine grenzenlose Analyseplattform von Microsoft, die Data Warehousing und Big Data-Verarbeitung für Unternehmen in eine einzelne verwaltete Umgebung integriert, ohne dass eine Systemintegration erforderlich ist. Azure Synapse stellt die End-to-End-Tools für Ihren Analyselebenszyklus mit folgenden Funktionen zur Verfügung:
- Pipelines für Datenintegration.
- Apache Spark-Pool für die Big Data-Verarbeitung.
- Daten-Explorerfür Protokoll- und Zeitreihenanalysen.
- Serverloser SQL-Pool für Datenuntersuchung über Azure Data Lake.
- Dedizierter SQL-Pool (früher SQL DW) für Data Warehousing für Unternehmen.
- Umfassende Integration in Power BI, Azure Cosmos DB und Azure Machine Learning.
Datensicherheit und Datenschutz in Azure Synapse sind nicht verhandelbar. Der Zweck dieses Whitepapers besteht darin, eine umfassende Übersicht über die Sicherheitsfeatures von Azure Synapse zu geben, die für Unternehmen geeignet und branchenweit führend sind. Das Whitepaper besteht aus einer Serie von Artikeln, die die folgenden fünf Sicherheitsebenen abdecken:
- Datenschutz
- Zugriffssteuerung
- Authentifizierung
- Netzwerksicherheit
- Bedrohungsschutz
Dieses Whitepaper richtet sich an alle an der Unternehmenssicherheit Beteiligten. Hierzu Sicherheitsadministratoren, Netzwerkadministratoren, Azure-Administratoren, Arbeitsbereichsadministratoren und Datenbankadministratoren.
Autor*innen: Vengatesh Parasuraman, Fretz Nuson, Ron Dunn, Khendr'a Reid, John Hoang, Nithesh Krishnappa, Mykola Kovalenko, Brad Schacht, Pedro Matinez, Mark Pryce-Maher und Arshad Ali.
Technische Redaktion: Nandita Valsan, Rony Thomas, Abhishek Narain, Daniel Crawford und Tammy Richter Jones.
Gilt für: Azure Synapse Analytics, dedizierter SQL-Pool (früher SQL DW), serverloser SQL-Pool und Apache Spark-Pool.
Wichtig
Dieses Whitepaper gilt nicht für Azure SQL-Datenbank, Azure SQL Managed Instance, Azure Machine Learning oder Azure Databricks.
Einführung
Häufige Überschriften über Datenschutzverletzungen, Infektionen mit Schadsoftware und Einfügung von böswilligem Code gehören zu einer umfangreichen Liste von Sicherheitsaspekten für Unternehmen, die sich mit Cloudmodernisierung befassen. Unternehmenskunden benötigen einen Cloudanbieter oder eine Servicelösung, der bzw. die ihre Probleme lösen, da sie es sich nicht leisten können, hierbei Fehler zu begehen.
Einige der häufig gestellten Sicherheitsfragen sind:
- Wie kann ich kontrollieren, wer welche Daten sehen kann?
- Welche Optionen gibt es zum Überprüfen der Identität eines Benutzers?
- Wie werden meine Daten geschützt?
- Welche Netzwerksicherheitstechnologie kann ich verwenden, um die Integrität, Vertraulichkeit und den Zugriff auf meine Netzwerke und Daten zu schützen?
- Welche Tools können Bedrohungen erkennen und mich benachrichtigen?
Der Zweck dieses Whitepapers besteht darin, Antworten auf diese häufig gestellten Sicherheitsfragen und viele andere zu geben.
Komponentenarchitektur
Azure Synapse ist ein Plattform-as-a-Service-Analysedienst (PaaS), der mehrere unabhängige Komponenten wie dedizierte SQL-Pools, serverlose SQL-Pools, Apache Spark-Pools und Datenintegrationspipelines zusammenführt. Diese Komponenten sind so konzipiert, dass sie zusammenarbeiten, um eine nahtlose analytische Plattformoberfläche bereitzustellen.
Dedizierte SQL-Pools sind bereitgestellte Cluster, die in Unternehmen Funktionen für Data Warehousing für SQL-Workloads bereitstellen. Daten werden in verwaltetem Speicher von Azure Storage erfasst, wobei es sich ebenfalls um einen PaaS-Dienst handelt. Die Datenverarbeitung erfolgt getrennt vom Speicher, sodass Kund*innen die Rechenleistung unabhängig von ihren Daten skalieren können. Dedizierte SQL-Pools bieten auch die Möglichkeit, Datendateien direkt über kundenverwaltete Azure Storage-Konten mithilfe externer Tabellen abzufragen.
Serverlose SQL-Pools sind On-Demand-Cluster, die eine SQL-Schnittstelle zum Abfragen und Analysieren von Daten direkt über kundenverwaltete Azure Storage-Konten bereitstellen. Da sie serverlos sind, gibt es keinen verwalteten Speicher, und die Serverknoten skalieren automatisch auf die Abfrageworkload.
Apache Spark in Azure Synapse ist eine der cloudbasierten Apache Spark-Open-Source-Implementierungen von Microsoft. Spark-Instanzen werden bei Bedarf anhand der in den Spark-Pools definierten Metadatenkonfigurationen bereitgestellt. Alle Benutzer*innen erhalten eine dedizierte Spark-Instanz, um Aufträge auszuführen. Die von den Spark-Instanzen verarbeiteten Datendateien werden von Kund*innen in eigenen Azure Storage-Konten verwaltet.
Pipelines sind eine logische Gruppierung von Aktivitäten, die Datenverschiebungen und Datentransformationen in großem Umfang durchführen. Der Datenfluss ist eine Transformationsaktivität in einer Pipeline, die mithilfe einer Benutzeroberfläche mit wenig Code entwickelt wird. Sie kann Datentransformationen in großem Umfang ausführen. Im Hintergrund verwenden Datenflüsse Apache Spark-Cluster von Azure Synapse, um automatisch generierten Code auszuführen. Pipelines und Datenflüsse sind reine Verarbeitungsdienste, denen kein verwalteter Speicher zugeordnet ist.
Pipelines verwenden die Integration Runtime (IR) als skalierbare Computeinfrastruktur für die Durchführung von Datenverschiebungs- und Dispatchaktivitäten. Datenverschiebungsaktivitäten werden auf der IR ausgeführt, während die Dispatchaktivitäten auf verschiedenen Compute-Engines ausgeführt werden, einschließlich Azure SQL-Datenbank, Azure HDInsight, Azure Databricks, Apache Spark-Cluster von Azure Synapse und anderen. Azure Synapse unterstützt zwei Arten von IR: Azure Integration Runtime und selbstgehostete Integration Runtime. Azure IR bietet eine vollständig verwaltete, skalierbare und bedarfsgesteuerte Computeinfrastruktur. Die selbstgehostete IR wird von Kund*innen in ihren eigenen Netzwerken installiert und konfiguriert, entweder auf lokalen Computern oder auf virtuellen Azure-Computern.
Kund*innen können ihren Synapse-Arbeitsbereich einem virtuellen Netzwerk des verwalteten Arbeitsbereichs zuordnen. Wenn sie mit einem virtuellen Netzwerk für verwaltete Arbeitsbereiche verbunden sind, werden Azure IRs und Apache Spark-Cluster, die von Pipelines, Datenflüssen und Apache Spark-Pools verwendet werden, innerhalb des virtuellen Netzwerks für verwaltete Arbeitsbereiche bereitgestellt. Dieses Setup stellt die Netzwerkisolation zwischen den Arbeitsbereichen für Pipelines und Apache Spark-Workloads sicher.
Im folgenden Diagramm werden die verschiedenen Komponenten von Azure Synapse dargestellt.
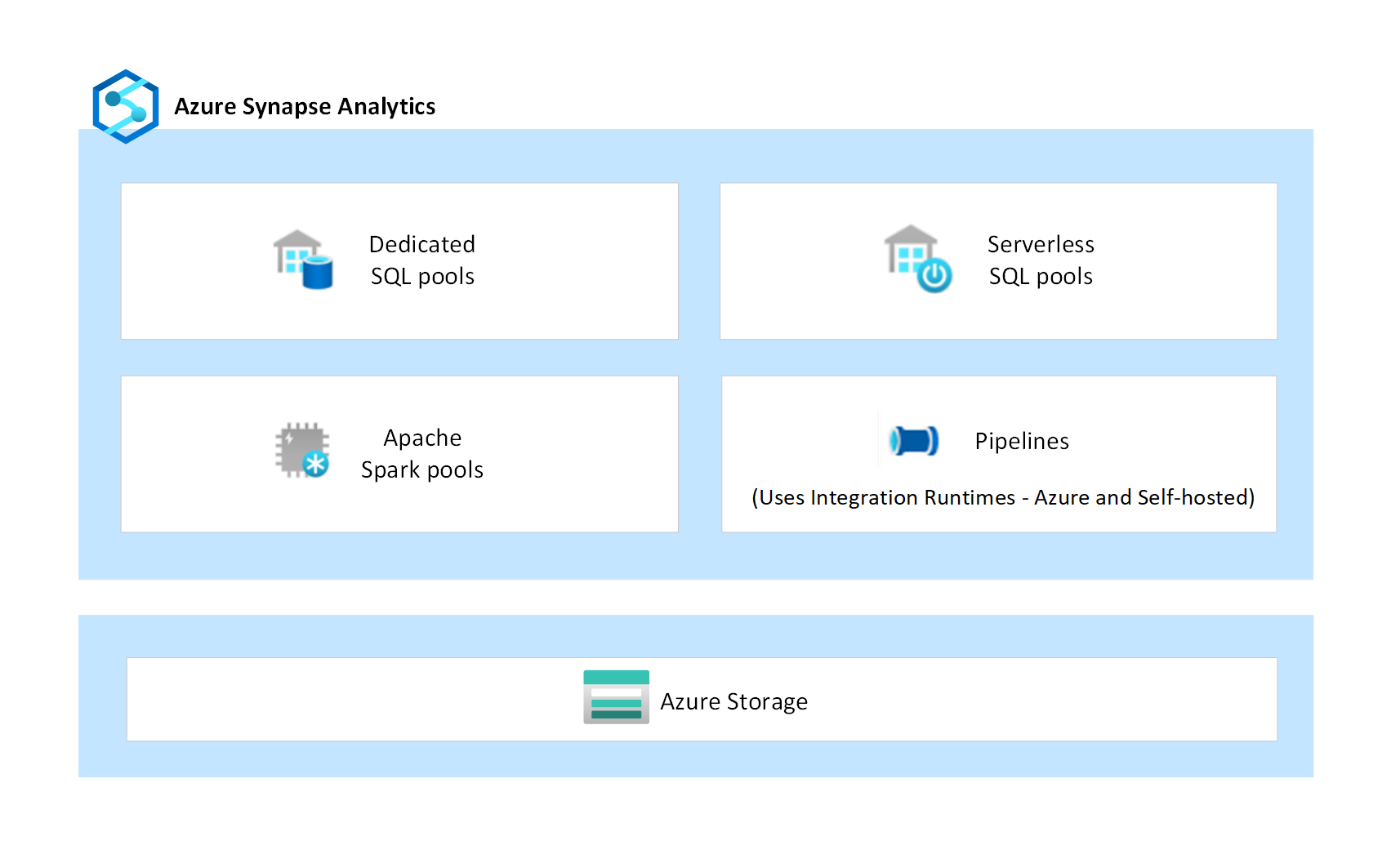
Komponentenisolation
Jede einzelne Komponente von Azure Synapse, die im Diagramm dargestellt wird, bietet eigene Sicherheitsfeatures. Sicherheitsfeatures bieten Datenschutz, Zugriffssteuerung, Authentifizierung, Netzwerksicherheit und Bedrohungsschutz für die Sicherung der Computevorgänge und der zugeordneten Daten, die verarbeitet werden. Darüber hinaus bietet Azure Storage als PaaS-Dienst zusätzliche Sicherheit, die von Kund*innen in ihren eigenen Speicherkonten eingerichtet und verwaltet wird. Dieser Grad der Komponentenisolation begrenzt und minimiert das Risiko durch mögliche Sicherheitslücken in einer der Komponenten.
Sicherheitsebenen
Azure Synapse implementiert eine mehrschichtige Sicherheitsarchitektur für den End-to-End-Schutz Ihrer Daten. Es gibt fünf Ebenen:
- Datenschutz um vertrauliche Daten zu identifizieren und klassifizieren sowie ruhende und in Übertragung befindliche Daten zu verschlüsseln.
- Zugriffssteuerung, um das Recht eines Benutzers auf Interaktion mit Daten zu ermitteln.
- Authentifizierung zum Nachweis der Identität von Benutzern und Anwendungen.
- Netzwerksicherheit zum Isolieren von Netzwerkdatenverkehr mit privaten Endpunkten und virtuellen privaten Netzwerken.
- Bedrohungsschutz, um potenzielle Sicherheitsbedrohungen zu identifizieren, z. B. ungewöhnliche Zugriffsorte, Angriffe durch Einschleusung von SQL-Befehlen, Authentifizierungsangriffe und mehr.
Nächste Schritte
Im nächsten Artikel dieser Whitepaperserie erfahren Sie mehr über Datenschutz.