Apache Spark Advisor in Azure Synapse Analytics (Vorschau)
Der Apache Spark Advisor analysiert Befehle und Code, die von Spark ausgeführt werden, und zeigt Echtzeitempfehlungen für Notebookausführungen an. Der Spark Advisor verfügt über integrierte Muster, um Benutzern dabei zu helfen, häufige Fehler zu vermeiden, Empfehlungen für die Codeoptimierung anzubieten, Fehleranalysen durchzuführen und die Grundursache von Fehlern zu ermitteln.
Integrierte Empfehlung
Kann bei Verwendung von „randomSplit“ inkonsistente Ergebnisse zurückgeben
Beim Arbeiten mit den Ergebnissen der „randomSplit“-Methode können inkonsistente oder ungenaue Ergebnisse zurückgegeben werden. Verwenden Sie Apache Spark (RDD)-Caching, bevor Sie die Methode „randomSplit“ verwenden.
Die Methode randomSplit() entspricht der mehrfachen Ausführung einer Stichprobe() auf Ihrem Datenrahmen, wobei bei jeder Stichprobe der Datenrahmen innerhalb der Partitionen neu geholt, partitioniert und sortiert wird. Die Datenverteilung über Partitionen und die Sortierreihenfolge ist sowohl für randomSplit() als auch für sample() wichtig. Wenn sich einer der Werte beim erneuten Abrufen der Daten ändert, kann es zu Duplikaten oder fehlenden Werten über Teilungen hinweg kommen, und dieselbe Stichprobe mit demselben Seed kann zu unterschiedlichen Ergebnissen führen.
Diese Inkonsistenzen treten möglicherweise nicht bei jedem Lauf auf, aber um sie vollständig zu beseitigen, cachen Sie Ihren Datenrahmen, partitionieren Sie eine oder mehrere Spalten neu oder wenden Sie Aggregatfunktionen wie groupBy an.
Der Name der Tabelle/Ansicht wird bereits verwendet
Es existiert bereits eine Ansicht mit demselben Namen wie die erstellte Tabelle oder eine Tabelle mit demselben Namen wie die erstellte Ansicht. Wenn dieser Name in Abfragen oder Anwendungen verwendet wird, wird nur die Ansicht zurückgegeben, unabhängig davon, was zuerst erstellt wurde. Um Konflikte zu vermeiden, benennen Sie entweder die Tabelle oder die Ansicht um.
Hinweis kann nicht erkannt werden
Die ausgewählte Abfrage enthält einen Hinweis, der nicht erkannt wird. Überprüfen Sie, ob der Hinweis richtig geschrieben ist.
spark.sql("SELECT /*+ unknownHint */ * FROM t1")
Der/die angegebene(n) Beziehungsname(n) konnte(n) nicht gefunden werden
Die im Hinweis angegebene(n) Beziehung(en) konnte(n) nicht gefunden werden. Überprüfen Sie, ob die Beziehung(en) richtig geschrieben und im Rahmen des Hinweises zugänglich sind.
spark.sql("SELECT /*+ BROADCAST(unknownTable) */ * FROM t1 INNER JOIN t2 ON t1.str = t2.str")
Ein Hinweis in der Abfrage verhindert die Anwendung eines anderen Hinweises
Die ausgewählte Abfrage enthält einen Hinweis, der die Anwendung eines anderen Hinweises verhindert.
spark.sql("SELECT /*+ BROADCAST(t1), MERGE(t1, t2) */ * FROM t1 INNER JOIN t2 ON t1.str = t2.str")
Aktivieren Sie „spark.advise.divisionExprConvertRule.enable“, um die Ausbreitung von Rundungsfehlern zu reduzieren
Diese Abfrage enthält den Ausdruck mit dem Typ Double. Wir empfehlen, dass Sie die Konfiguration „spark.advise.divisionExprConvertRule.enable“ aktivieren, die dabei helfen kann, die Divisionsausdrücke zu reduzieren und die Ausbreitung von Rundungsfehlern zu reduzieren.
"t.a/t.b/t.c" convert into "t.a/(t.b * t.c)"
Aktivieren Sie „spark.advise.nonEqJoinConvertRule.enable“, um die Abfrageleistung zu verbessern
Diese Abfrage enthält aufgrund der „Oder“-Bedingung in der Abfrage zeitaufwändige Verknüpfungen. Wir empfehlen, die Konfiguration „spark.advise.nonEqJoinConvertRule.enable“ zu aktivieren, die dabei helfen kann, den durch die „Oder“-Bedingung ausgelösten Join in SMJ oder BHJ umzuwandeln, um diese Abfrage zu beschleunigen.
Optimieren der Delta-Tabelle mit Komprimierung zu kleinen Dateien
Diese Abfrage befindet sich in einer Delta-Tabelle mit vielen kleinen Dateien. Führen Sie den Befehl OPTIMIZE für die Delta-Tabelle aus, um die Leistung von Abfragen zu verbessern. Weitere Informationen finden Sie in diesem Artikel.
Optimieren der Delta-Tabelle mit ZOrder
Diese Abfrage befindet sich in einer Delta-Tabelle und enthält einen sehr selektiven Filter. Führen Sie den Befehl OPTIMIZE ZORDER BY für die Delta-Tabelle aus, um die Leistung von Abfragen zu verbessern. Weitere Informationen finden Sie in diesem Artikel.
Benutzererfahrung
Der Apache Spark Advisor zeigt die Empfehlungen, einschließlich Informationen, Warnungen und Fehler, bei der Notebookzellenausgabe in Echtzeit an.
Info
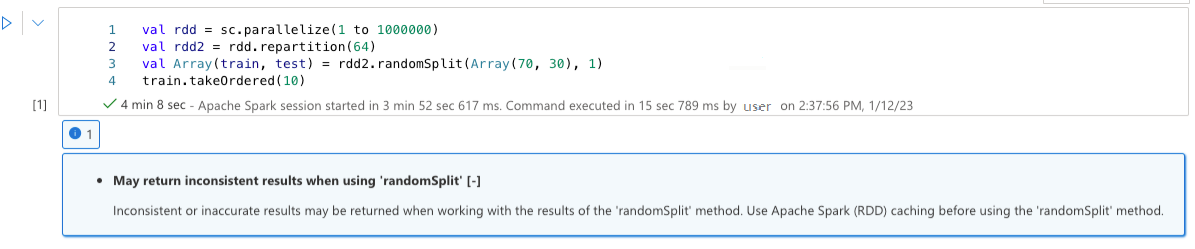
Warnung

Errors
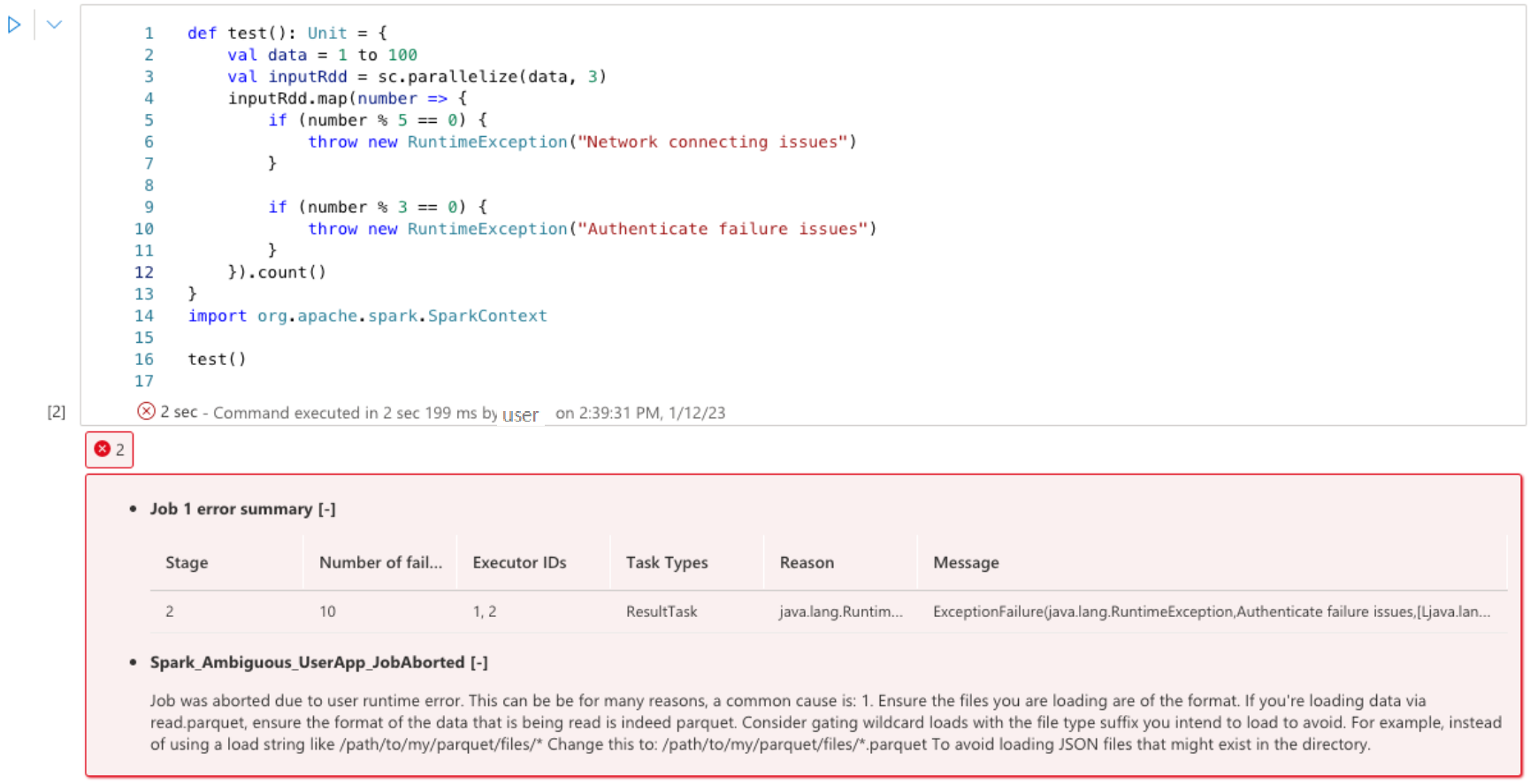
Nächste Schritte
Weitere Informationen zum Überwachen von Apache Spark-Anwendungen finden Sie im Artikel Überwachen von Apache Spark-Anwendungen mit Synapse Studio.
Weitere Informationen zum Erstellen eines Notebooks finden Sie unter Erstellen, Entwickeln und Verwalten von Synapse-Notebooks in Azure Synapse Analytics.