Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Ein Notebook in Azure Synapse Analytics (ein Synapse-Notebook) ist eine Webschnittstelle, die Sie zum Erstellen von Dateien verwenden, die Livecode, Visualisierungen und beschreibenden Text enthalten. Notebooks sind ein guter Ausgangspunkt, um Ideen zu überprüfen und schnelle Experimente zu verwenden, um Erkenntnisse aus Ihren Daten zu gewinnen. Notebooks werden auch häufig für Datenvorbereitung, Datenvisualisierung, Machine Learning und andere Big Data-Szenarien verwendet.
Mit einem Synapse-Notebook können Sie:
- Ohne Einrichtungsaufwand sofort loslegen.
- Schützen Sie Daten mit integrierten Features für Unternehmenssicherheit.
- Analysieren Sie Daten in Rohformaten (z. B. CSV, TXT und JSON), verarbeiteten Sie Dateiformate (z. B. Parkett, Delta Lake und ORC) und tabellarische SQL-Datendateien gegen Spark und SQL.
- Produktiv sein mit erweiterten Funktionen zur Dokumenterstellung und integrierter Datenvisualisierung.
In diesem Artikel wird beschrieben, wie Notebooks in Synapse Studio verwendet werden.
Erstellen eines Notebooks
Sie können ein neues Notebook erstellen oder ein vorhandenes Notebook aus Objekt-Explorer in einen Synapse-Arbeitsbereich importieren. Wählen Sie das Menü Entwickeln aus. Klicken Sie auf die Schaltfläche +, wählen Sie Notebook aus, und klicken Sie mit der rechten Maustaste auf Notebooks, und wählen Sie dann Neues Notebook oder Importieren aus. Synapse-Notebooks erkennen Standard Jupyter Notebook IPYNB-Dateien.
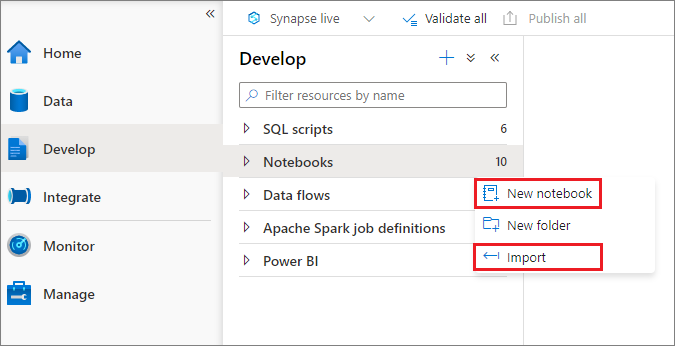
Entwickeln von Notebooks
Notebooks bestehen aus Zellen, bei denen es sich um einzelne Code- oder Textblöcke handelt, die Sie unabhängig oder als Gruppe ausführen können.
In den folgenden Abschnitten werden die Vorgänge für die Entwicklung von Notebooks beschrieben:
- Hinzufügen einer Zelle
- Festlegen einer primären Sprache
- Verwenden mehrerer Sprachen
- Verwenden von temporären Tabellen zum Verweisen auf Daten in verschiedenen Sprachen
- Verwenden von IntelliSense im IDE-Stil
- Verwenden von Codeausschnitten
- Formatieren von Textzellen mithilfe von Symbolleistenschaltflächen
- Rückgängigmachen oder Wiederholen eines Zellenvorgangs
- Kommentieren auf einer Codezelle
- Verschieben einer Zelle
- Zelle kopieren
- Löschen einer Zelle
- Reduzieren der Zelleneingabe
- Reduzieren der Zellenausgabe
- Verwenden einer Notebook-Gliederung
Hinweis
In den Notebooks wird automatisch eine SparkSession-Instanz für Sie erstellt und in einer Variable mit dem Namen spark gespeichert. Es gibt auch eine Variable für SparkContext mit dem Namen sc. Benutzer können direkt auf diese Variablen zugreifen, sollten aber die Werte dieser Variablen nicht ändern.
Hinzufügen einer Zelle
Es gibt mehrere Möglichkeiten, Ihrem Notebook eine neue Zelle hinzuzufügen:
Zeigen Sie mit dem Mauszeiger auf den Bereich zwischen zwei Zellen, und wählen Sie Code oder Markdown aus.
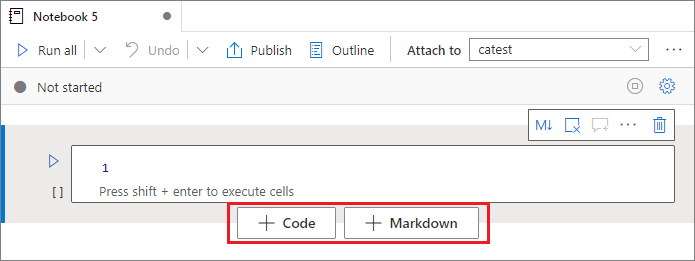
Verwenden Sie Tastenkombinationen im Befehlsmodus. Wählen Sie die A-Taste aus, um eine Zelle oberhalb der aktiven Zelle einzufügen. Wählen Sie die B-Taste aus, um eine Zelle unterhalb der aktiven Zelle einzufügen.
Festlegen einer primären Sprache
Synapse-Notebooks unterstützen vier Apache Spark-Sprachen:
- PySpark (Python)
- Spark (Scala)
- Spark SQL
- .NET Spark (C#)
- SparkR (R)
Sie können die primäre Sprache für neu hinzugefügte Zellen aus der Dropdownliste Sprache in der oberen Befehlsleiste festlegen.
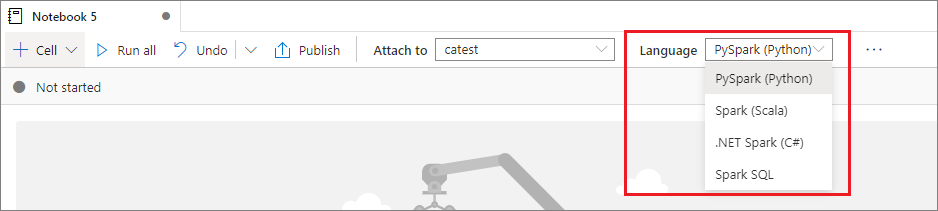
Verwenden mehrerer Sprachen
Sie können in einem Notebook mehrere Sprachen verwenden, indem Sie den richtigen Magic-Befehl für die Sprache am Anfang einer Zelle angeben. In der folgenden Tabelle werden die Magic-Befehle zum Wechseln von Zellensprachen aufgelistet.
| Magic-Befehl | Sprache | Beschreibung |
|---|---|---|
%%pyspark |
Python | Ausführen einer Python-Abfrage gegen SparkContext. |
%%spark |
Scala | Ausführen einer Skala-Abfrage gegen SparkContext. |
%%sql |
Spark SQL | Ausführen einer Spark SQL-Abfrage gegen SparkContext. |
%%csharp |
.NET für Spark (C#) | Ausführen einer .NET für Spark C#-Abfrage gegen SparkContext. |
%%sparkr |
R | Ausführen einer R-Abfrage gegen SparkContext. |
Die folgende Abbildung zeigt ein Beispiel dafür, wie Sie eine PySpark-Abfrage mit dem Magic-Befehl %%pyspark schreiben können, oder eine Spark SQL-Abfrage mit dem Magic-Befehl %%sql in einem Spark (Scala)-Notebook. Die primäre Sprache für das Notebook ist auf PySpark festgelegt.
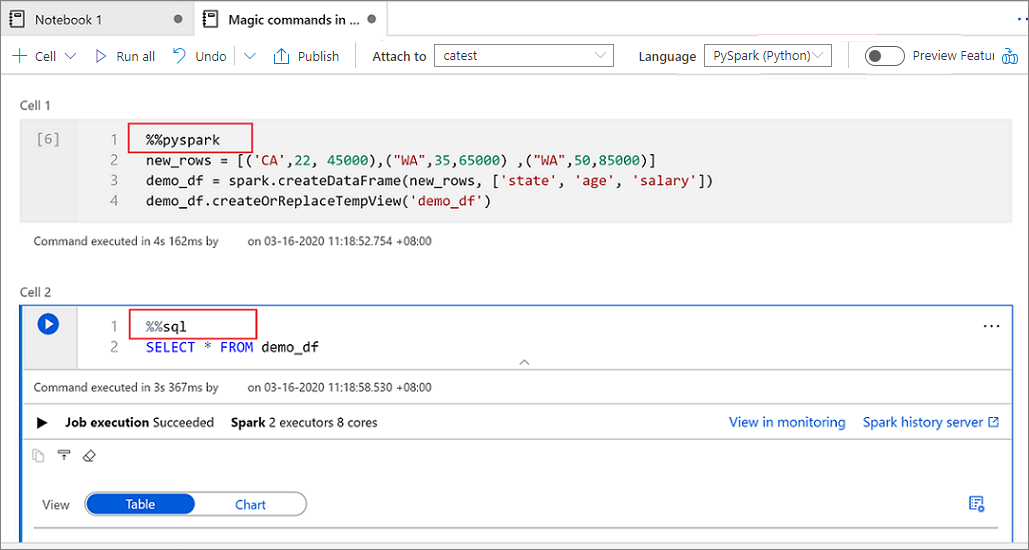
Verwenden von temporären Tabellen zum Verweisen auf Daten in verschiedenen Sprachen
Sie können in einem Synapse-Notebook nicht direkt auf Daten oder Variablen in verschiedenen Sprachen verweisen. In Spark können Sie auf eine temporäre Tabelle in verschiedenen Sprachen verweisen. Hier ist ein Beispiel für das Lesen eines Scala DataFrame in PySpark und Spark SQL mithilfe einer temporären Spark-Tabelle als Workaround:
Lesen Sie in Zelle 1 ein DataFrame von einem SQL-Poolconnector mithilfe von Scala, und erstellen Sie eine temporäre Tabelle:
%%spark val scalaDataFrame = spark.read.sqlanalytics("mySQLPoolDatabase.dbo.mySQLPoolTable") scalaDataFrame.createOrReplaceTempView( "mydataframetable" )In Zelle 2 fragen Sie die Daten mithilfe von Spark SQL ab:
%%sql SELECT * FROM mydataframetableIn Zelle 3 verwenden Sie die Daten in PySpark:
%%pyspark myNewPythonDataFrame = spark.sql("SELECT * FROM mydataframetable")
Verwenden von IntelliSense im IDE-Stil
Synapse-Notebooks sind in den Monaco-Editor integriert, um den Zellen-Editor mit IDE-style IntelliSense auszustatten. Die Features der Syntax-Hervorhebung, der Fehlermarkierung und der automatischem Codevervollständigung helfen Ihnen beim Schreiben von Code und bei der schnelleren Identifizierung von Problemen.
Die IntelliSense-Funktionen befinden sich in unterschiedlichen Stadien der Entwicklung für verschiedene Sprachen. In der folgenden Tabelle können Sie sehen, was unterstützt wird.
| Languages | Syntaxhervorhebung | Syntaxfehlermarkierungen | Codevervollständigung für Syntax | Codevervollständigung für Variablen | Codevervollständigung für Systemfunktionen | Codevervollständigung für Benutzerfunktionen | Intelligenter Einzug | Codefaltung |
|---|---|---|---|---|---|---|---|---|
| PySpark (Python) | Ja | Ja | Ja | Ja | Ja | Ja | Ja | Ja |
| Spark (Scala) | Ja | Ja | Ja | Ja | Ja | Ja | Nein | Ja |
| Spark SQL | Ja | Ja | Ja | Ja | Ja | Nr. | Nr. | No |
| .NET für Spark (C#) | Ja | Ja | Ja | Ja | Ja | Ja | Ja | Ja |
Eine aktive Spark-Sitzung ist erforderlich, um von der Codevervollständigung für Variablen, der Codevervollständigung für Systemfunktionen und der Codevervollständigung für Benutzerfunktionen für .NET für Spark (C#) zu profitieren.
Verwenden von Codeschnipseln
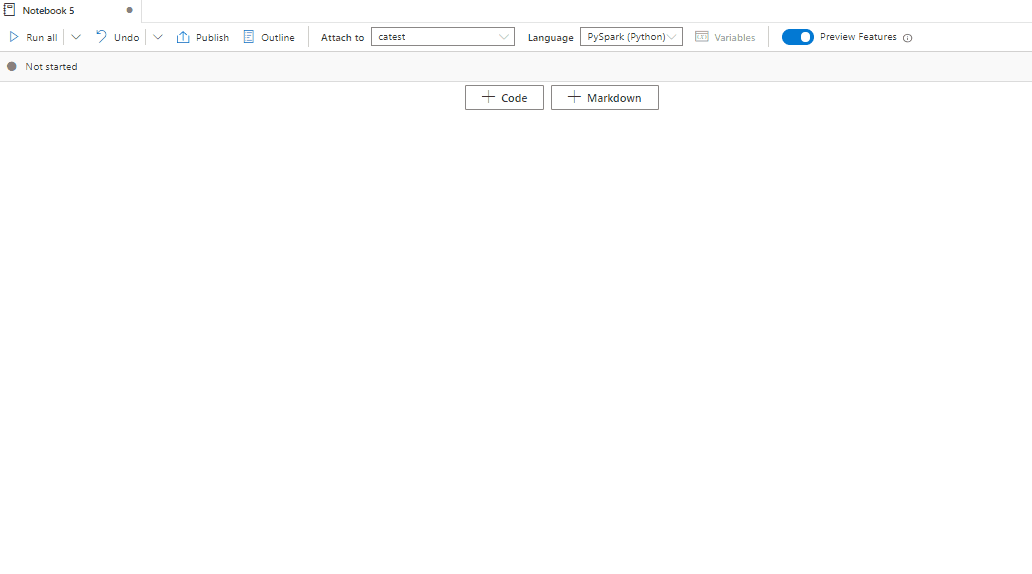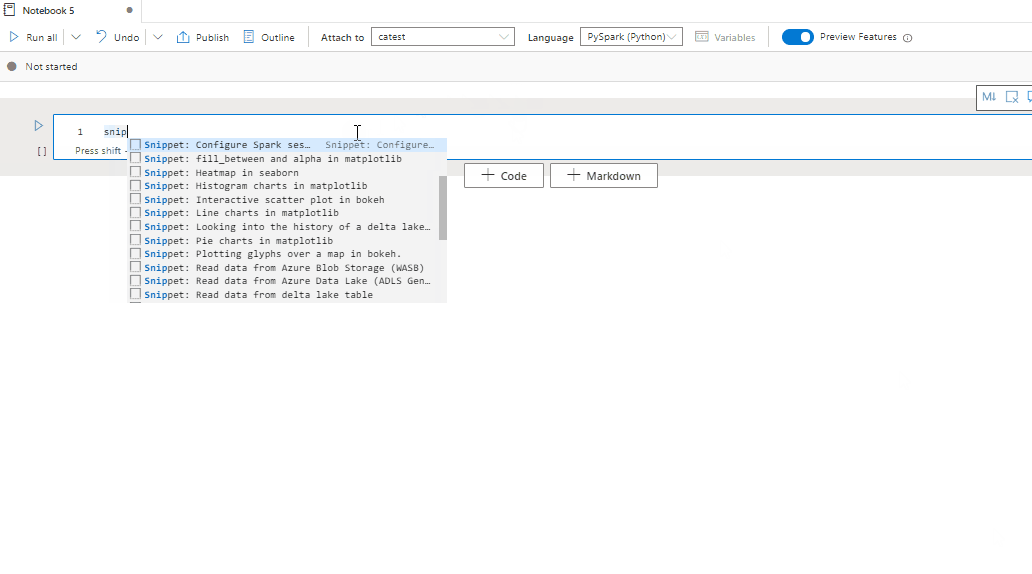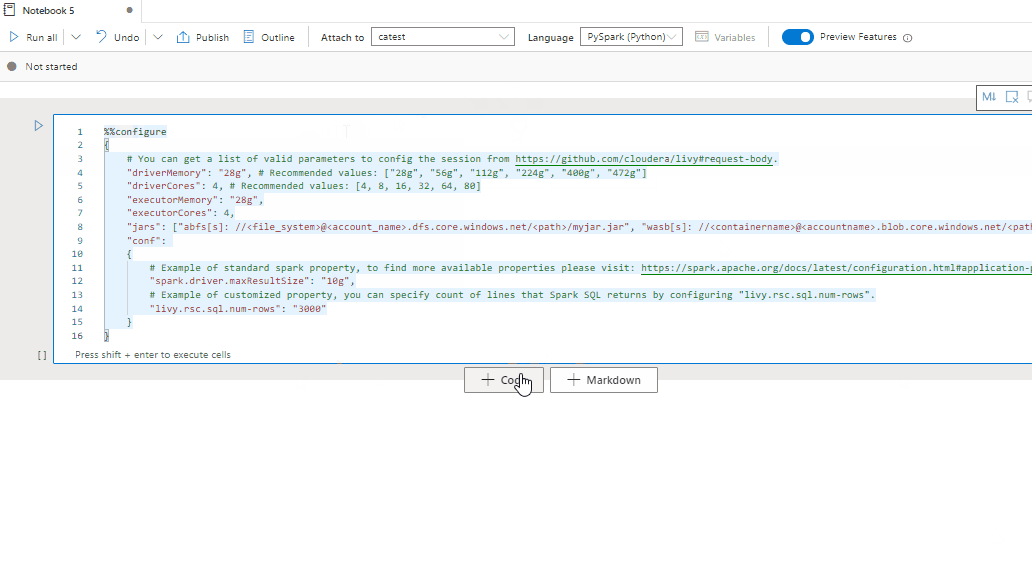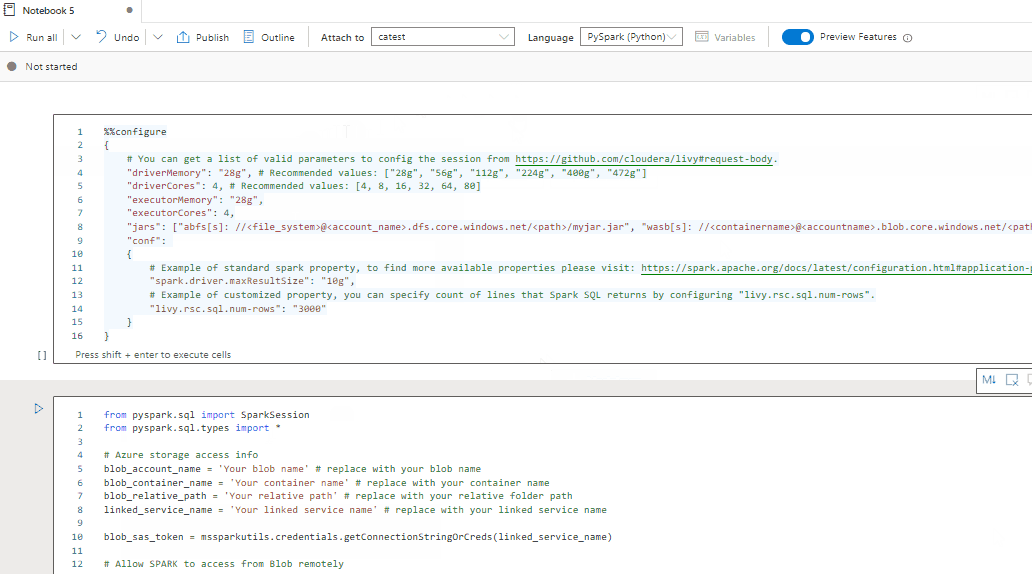
Synapse-Notebooks stellen Codeschnipsel bereit, welche die Eingabe häufig verwendeter Codemuster vereinfachen. Diese Muster umfassen das Konfigurieren Ihrer Spark-Sitzung, das Lesen von Daten als ein Spark DataFrame und das Zeichnen von Diagrammen mithilfe von Matplotlib.
Codeschnipsel werden in Tastaturkurzbefehlen in IntelliSense im IDE-Stil gemeinsam mit anderen Vorschlägen angezeigt. Der Inhalt der Codeschnipsel richtet sich nach der Codezellensprache. Sie können die verfügbaren Ausschnitte anzeigen, indem Sie Codeschnipsel oder ein beliebiges Schlüsselwort eingeben, die im Titel des Codeschnipsels im Codezellen-Editor angezeigt werden. Wenn Sie beispielsweise read eingeben, wird eine Liste der Codeschnipseln zum Lesen von Daten aus verschiedenen Datenquellen angezeigt.
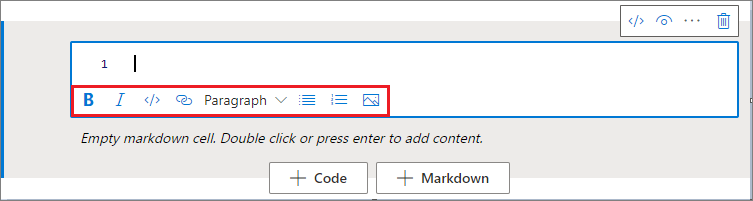
Formatieren von Textzellen mithilfe von Symbolleistenschaltflächen
Sie können die Formatierungsschaltflächen auf der Textzellensymbolleiste verwenden, um allgemeine Markdown-Aktionen durchzuführen. Diese Aktionen umfassen das Formatieren von Text als fett, das Formatieren von Text als kursiv, das Erstellen von Absätzen und Überschriften über ein Dropdownmenü, das Einfügen von Code, das Einfügen einer nicht sortierten Liste, das Einfügen einer sortierten Liste, das Einfügen eines Links und das Einfügen eines Bilds aus einer URL.
Rückgängigmachen oder Wiederholen eines Zellenvorgangs
Um die letzten Zellvorgänge zu widerrufen, wählen Sie die Schaltfläche Rückgängig machen oder Wiederholen aus, oder wählen Sie die Z-TASTE oder UMSCHALT+Z aus. Sie können jetzt bis zu 10 vergangene Zellenvorgänge rückgängig machen oder wiederholen.

Zu den unterstützten Zellvorgängen gehören:
- Einfügen oder Löschen einer Zeile. Sie können Löschvorgänge widerrufen, indem Sie Rückgängig machen auswählen. Diese Aktion behält den Textinhalt zusammen mit der Zelle bei.
- Zellen neu anordnen.
- Aktivieren oder Deaktivieren einer Parameterzelle.
- Konvertieren zwischen einer Codezelle und einer Markdown-Zelle.
Hinweis
Sie können Textvorgänge oder Kommentarvorgänge in einer Zelle nicht rückgängig machen.
Kommentieren auf einer Codezelle
Wählen Sie auf der Notebook-Symbolleiste die Schaltfläche Kommentare aus, um den Bereich Kommentare zu öffnen.
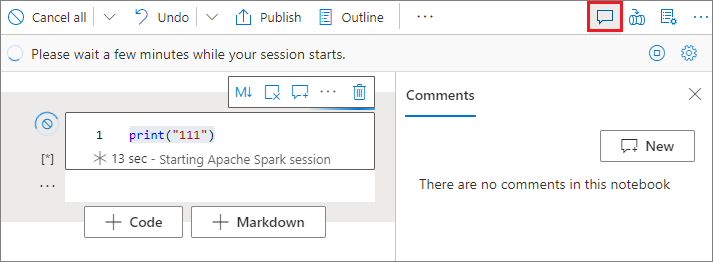
Wählen Sie Code in der Codezelle aus, wählen Sie im Bereich Kommentare die Option Neu aus, fügen Sie Kommentare hinzu, und wählen Sie dann die Schaltfläche Kommentar veröffentlichen aus.
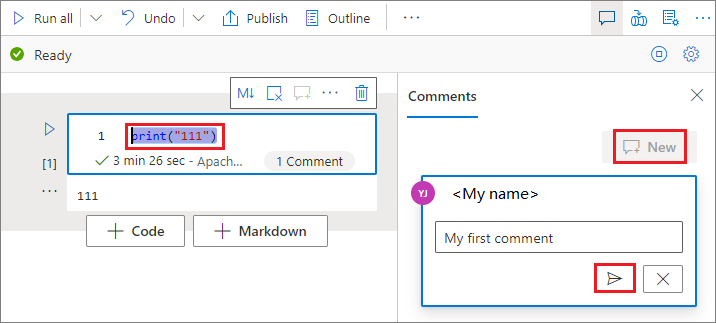
Bei Bedarf können Sie die Aktionen Kommentar bearbeiten, Thread auflösen und Thread löschen durchführen, indem Sie die Auslassungspunkte Weitere (...) neben Ihrem Kommentar auswählen.
Eine Zelle verschieben
Um eine Zelle zu verschieben, wählen Sie die linke Seite der Zelle aus, und ziehen Sie die Zelle an die gewünschte Position.
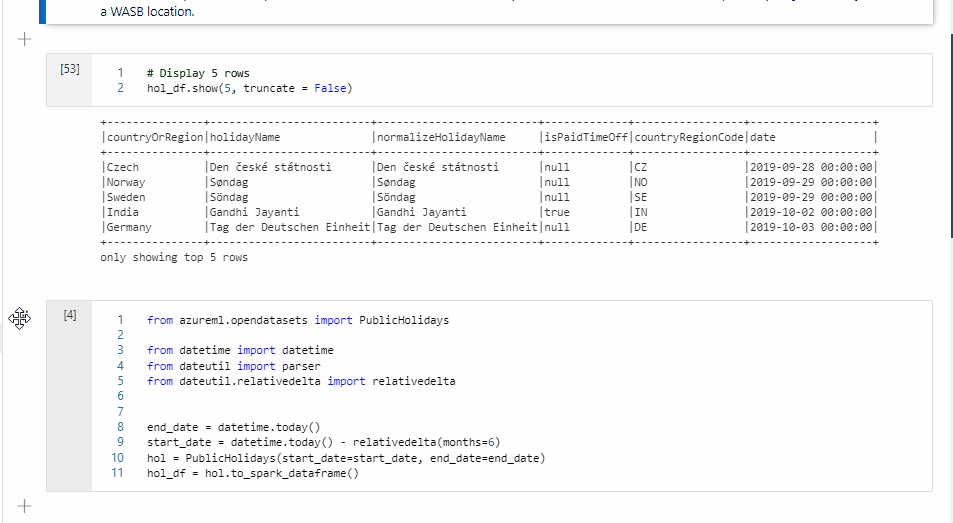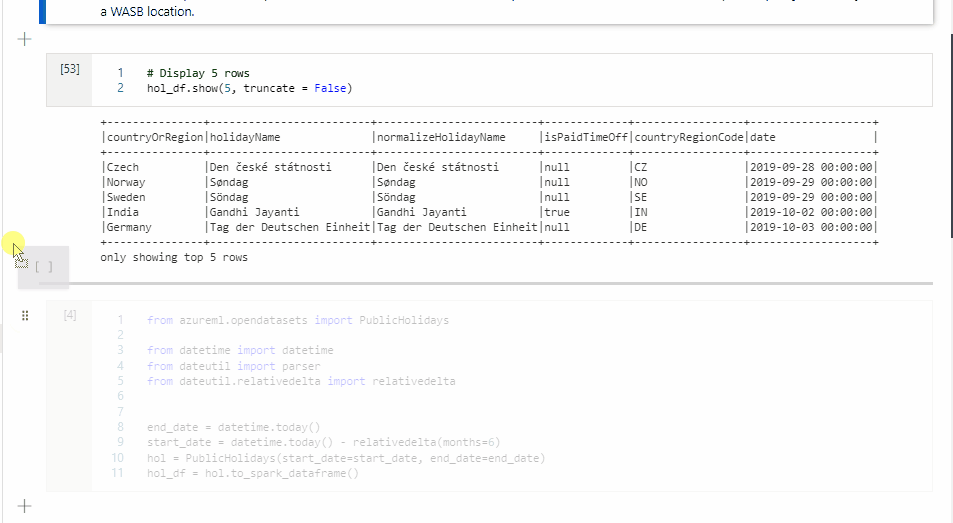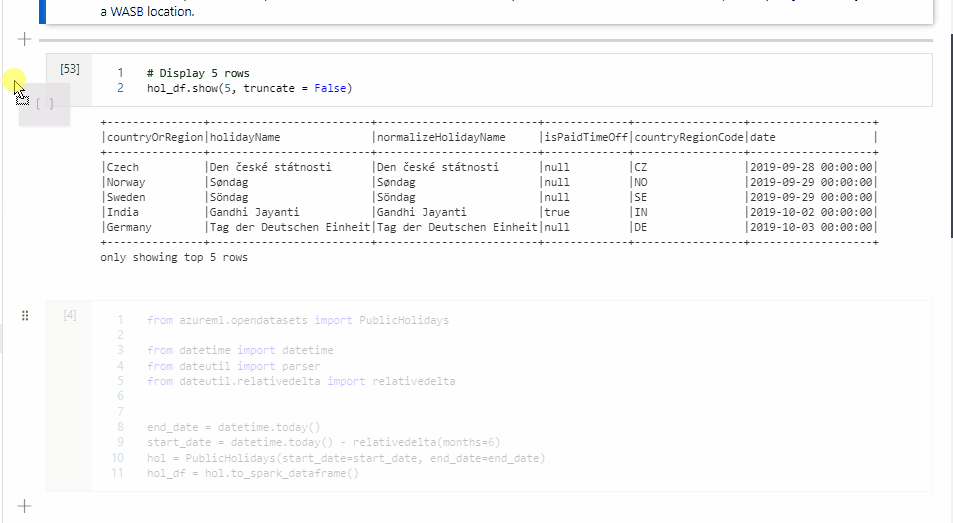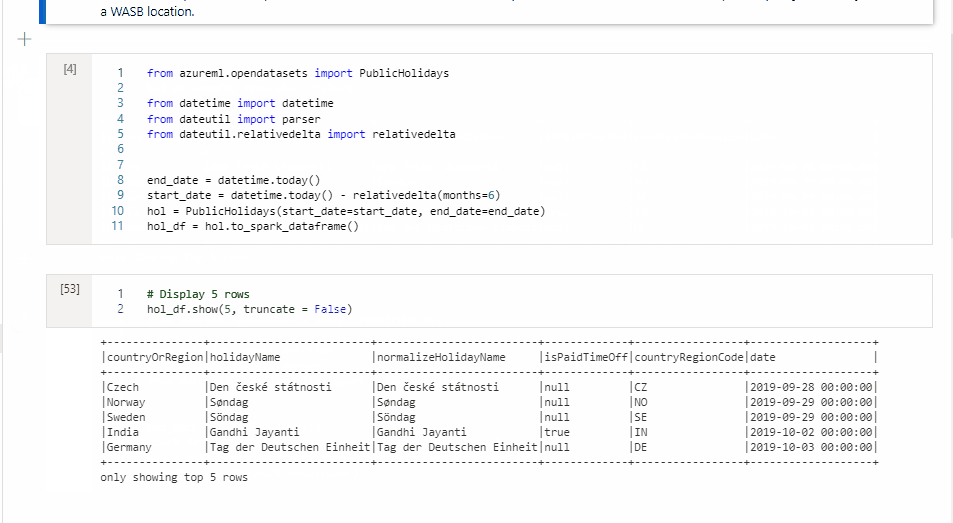
Kopieren einer Zelle
Wenn Sie eine Zelle kopieren möchten, erstellen Sie zuerst eine neue Zelle, markieren Sie dann den gesamten Text in der ursprünglichen Zelle, kopieren Sie den Text, und fügen Sie den Text in die neue Zelle ein. Wenn sich Ihre Zelle im Bearbeitungsmodus befindet, sind herkömmliche Tastenkombinationen zum Markieren des gesamten Texts auf die Zelle beschränkt.
Tipp
Synapse-Notebooks stellen auch Snippits häufig verwendeter Codemuster bereit.
Eine Zelle löschen
Wählen Sie zum Löschen einer Zelle die Schaltfläche Löschen rechts neben der Zelle aus.
Sie können auch Tastenkombinationen im Befehlsmodus verwenden. Wählen Sie UMSCHALT+D aus, um die aktive Zelle zu löschen.
Zelleneingabe reduzieren
Um die Eingabe der aktiven Zelle zu reduzieren, wählen Sie auf der Zellensymbolleiste die Auslassungspunkte für Weitere Befehle (...) und dann Eingabe ausblenden aus. Um die Eingabe zu erweitern, wählen Sie Eingabe anzeigen aus, während die Zelle reduziert ist.
Zellenausgabe reduzieren
Um die Ausgabe der aktiven Zelle zu reduzieren, wählen Sie auf der Zellensymbolleiste die Auslassungspunkte für Weitere Befehle (...) und dann Ausgabe ausblenden aus. Zum Erweitern der Ausgabe wählen Sie Ausgabe anzeigen aus, während die Zelle reduziert ist.
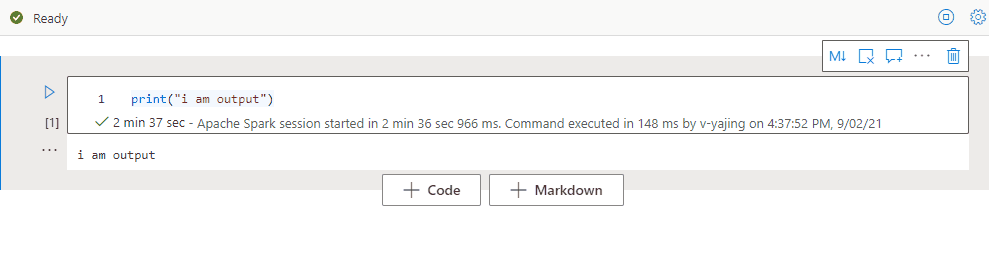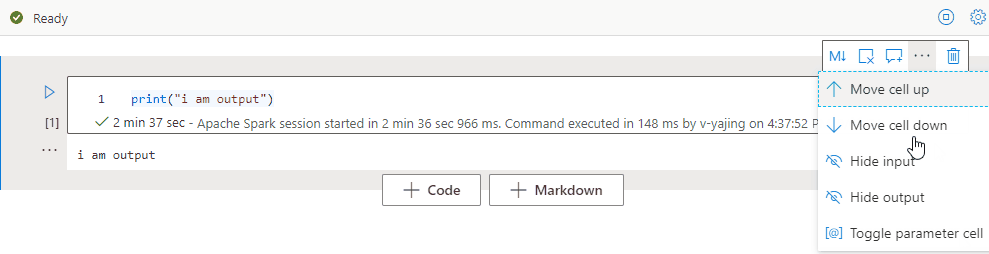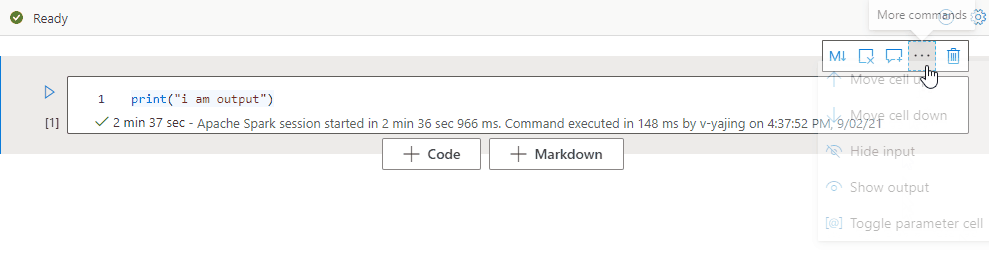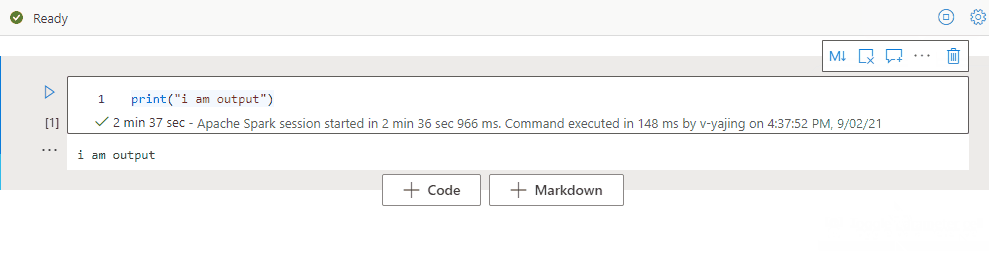
Verwenden einer Notebookgliederung
Die Gliederung (Inhaltsverzeichnis) stellt den ersten Markdown-Header einer beliebigen Markdown-Zelle in einem Randleistenfenster für die schnelle Navigation dar. Die Gliederungsrandleiste ist in der Größe veränderbar und reduzierbar, damit sie optimal an den Bildschirm angepasst werden kann. Um die Seitenleiste zu öffnen oder auszublenden, können Sie die Schaltfläche Gliederung auf der Notebook-Befehlsleiste auswählen.
Ausführen eines Notebooks
Sie können die Codezellen in Ihrem Notebook einzeln oder alle gleichzeitig ausführen. Der Zustand und Status jeder Zelle wird im Notebook angezeigt.
Hinweis
Das Löschen eines Notebooks führt nicht automatisch zum Abbruch von Aufträgen, die derzeit ausgeführt werden. Wenn Sie einen Auftrag abbrechen müssen, wechseln Sie zum Überwachen-Hub, und brechen Sie ihn manuell ab.
Ausführen einer Zelle
Es gibt mehrere Möglichkeiten zum Ausführen des Codes in einer Zelle:
Zeigen Sie mit der Maus auf die Zelle, die Sie ausführen möchten, und wählen Sie dann die Schaltfläche Zelle ausführen aus, oder wählen Sie STRG+EINGABETASTE aus.

Verwenden Sie Tastenkombinationen im Befehlsmodus. Drücken Sie UMSCHALT+EINGABE, um die aktive Zelle auszuführen und die Zelle darunter auszuwählen. Drücken Sie ALT+EINGABE, um die aktive Zelle auszuführen und darunter eine neue Zelle einzufügen.
Ausführen aller Zellen
Um alle Zellen im aktuellen Notebook nacheinander auszuführen, wählen Sie die Schaltfläche Alle ausführen aus.

Ausführen aller darüber- oder darunterliegenden Zellen
Um alle Zellen oberhalb der aktiven Zelle nacheinander auszuführen, erweitern Sie die Dropdownliste für die Schaltfläche Alle ausführen, und wählen Sie dann Zellen oberhalb ausführen aus. Wählen Sie Zellen unterhalb ausführen aus, um alle Zellen unterhalb der aktiven Zelle nacheinander auszuführen.
Abbrechen aller ausgeführten Zellen
Um die sich in Ausführung oder in der Warteschlange befindlichen Zellen abzubrechen, wählen Sie die Schaltfläche Alle abbrechen aus.

Verweis auf ein Notebook
Um im Kontext des aktuellen Notebooks auf ein anderes Notebook zu verweisen, verwenden Sie den Magic-Befehl %run <notebook path>. Alle im Referenznotebook definierten Variablen sind im aktuellen Notebook verfügbar.
Ein Beispiel:
%run /<path>/Notebook1 { "parameterInt": 1, "parameterFloat": 2.5, "parameterBool": true, "parameterString": "abc" }
Der Notebookverweis funktioniert sowohl im interaktiven Modus als auch in Pipelines.
Der Magic-Befehl %run hat folgende Einschränkungen:
- Der Befehl unterstützt geschachtelte Aufrufe, aber keine rekursiven.
- Der Befehl unterstützt das Übergeben eines absoluten Pfads oder Notebooknamens nur als Parameter. Er unterstützt keine relativen Pfade.
- Der Befehl unterstützt derzeit nur vier Parameterwerttypen:
int,float,boolundstring. Er unterstützt keine Vorgänge zur Ersetzung von Variablen. - Die referenzierten Notebooks müssen veröffentlicht sein. Sie müssen die Notebooks veröffentlichen, um auf sie zu verweisen, es sei denn, Sie wählen die Option zum Aktivieren eines unveröffentlichten Notebookverweises aus. Synapse Studio erkennt die nicht veröffentlichten Notebooks aus dem Git-Repository nicht.
- Referenzierte Notebooks unterstützen keine Anweisungstiefen größer als fünf.
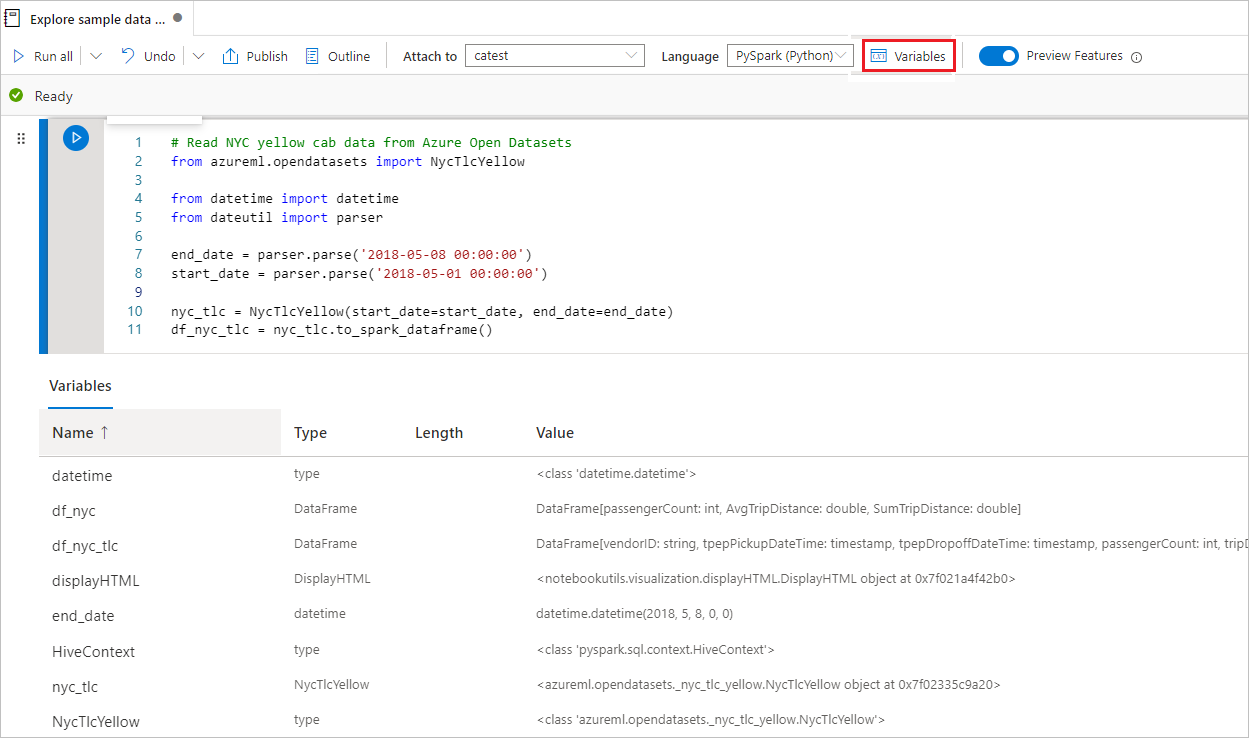
Verwenden des Variablen-Explorers
Ein Synapse-Notebook stellt einen integrierten Variablen-Explorer in Form einer Tabelle bereit, in der Variablen in der aktuellen Spark-Sitzung für PySpark (Python)-Zellen aufgelistet sind. Die Tabelle enthält Spalten für Variablennamen, Typ, Länge und Wert. Weitere Variablen erscheinen automatisch, wenn sie in den Codezellen definiert werden. Das Auswählen einzelner Spaltenüberschriften sortiert die Variablen in der Tabelle.
Um den Variablen-Explorer zu öffnen oder auszublenden, können Sie die Schaltfläche Variablen in der Notebook-Befehlsleiste auswählen.
Hinweis
Der Variablen-Explorer unterstützt nur Python.
Verwenden des Zellenstatusindikators
Ein Schritt-für-Schritt-Status einer Zellenausführung wird unterhalb der Zelle angezeigt, um den aktuellen Status anzuzeigen. Nach Abschluss der Zellausführung wird eine Zusammenfassung mit der Gesamtdauer und Endzeit angezeigt und bleibt für zukünftige Verweise dort.

Verwenden der Spark-Statusanzeige
Ein Synapse-Notebook basiert ausschließlich auf Spark. Codezellen werden remote auf dem serverlosen Apache Spark-Pool ausgeführt. Eine Spark-Auftragsstatusanzeige mit einer Echtzeit-Statusanzeige hilft Ihnen, den Auftragsausführungsstatus zu verstehen.
Die Anzahl der Aufgaben für jeden Auftrag oder jede Phase helfen Ihnen die Parallelebene Ihres Spark-Auftrags zu identifizieren. Darüber hinaus können Sie für einen bestimmten Auftrag (oder eine Phase) einen Drilldown zur Spark-Benutzeroberfläche ausführen, indem Sie auf den für den Auftrags- oder Phasennamen auf den Link klicken.
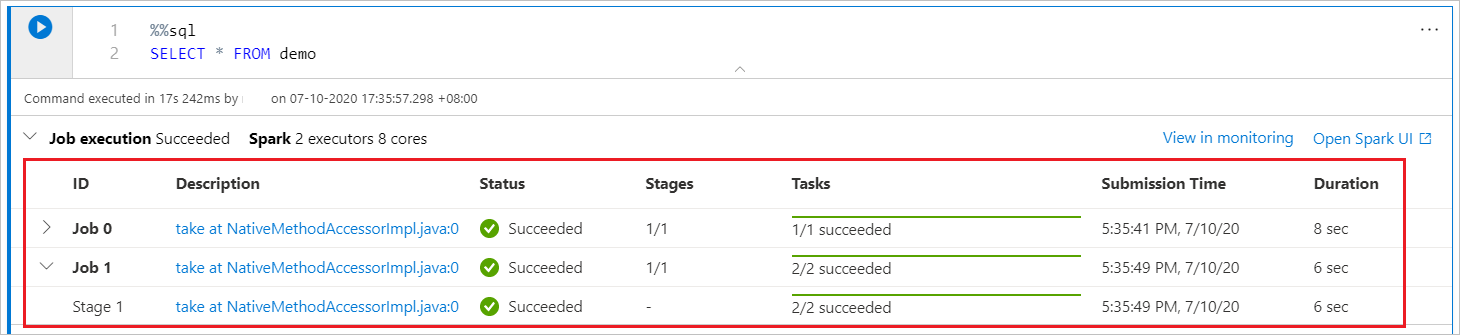
Konfigurieren einer Spark-Sitzung
Im Bereich Sitzung konfigurieren, den Sie durch Klicken auf das Zahnradsymbol in der rechten oberen Ecke des Notebooks finden, können Sie die Timeoutdauer sowie die Anzahl und Größe der Executors angeben, die für die aktuelle Spark-Sitzung gelten sollen. Starten Sie die Spark-Sitzung neu, damit die Konfigurationsänderungen wirksam werden. Alle zwischengespeicherten Notebook-Variablen werden gelöscht.
Sie können auch eine Konfiguration aus der Apache Spark-Konfiguration erstellen oder eine vorhandene Konfiguration auswählen. Ausführliche Informationen finden Sie unter Apache Spark-Konfiguration verwalten.
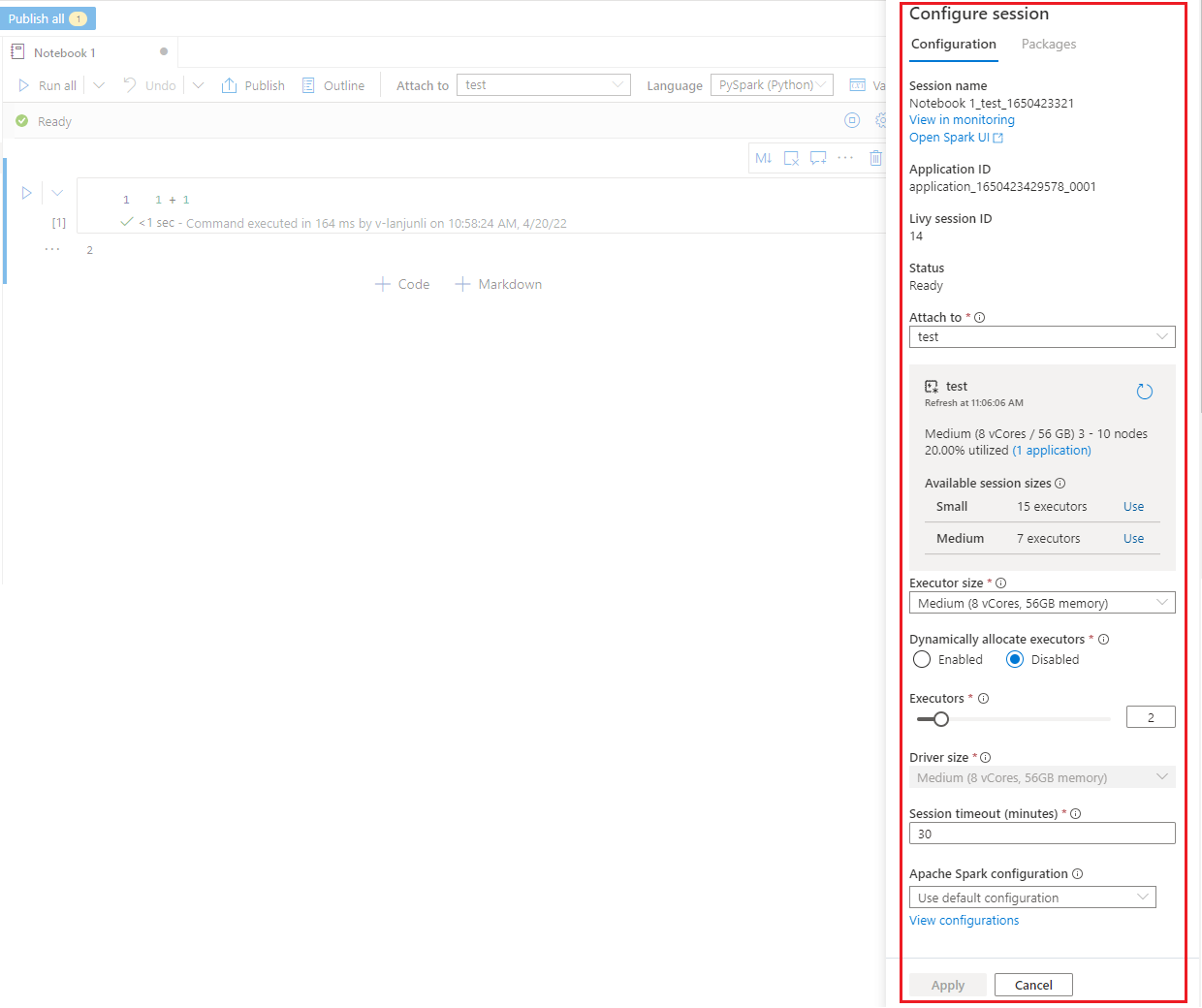
Magic-Befehl zum Konfigurieren einer Spark-Sitzung
Sie können Spark-Sitzungseinstellungen auch über den Magic-Befehl %%configure angeben. Damit die Einstellungen wirksam werden, starten Sie die Spark-Sitzung neu.
Wir empfehlen Ihnen, am Anfang Ihres Notebooks %%configure auszuführen. Hier ist ein Beispiel. Die vollständige Liste der gültigen Parameter finden Sie in den Livy-Informationen auf GitHub.
%%configure
{
//You can get a list of valid parameters to configure the session from https://github.com/cloudera/livy#request-body.
"driverMemory":"28g", // Recommended values: ["28g", "56g", "112g", "224g", "400g", "472g"]
"driverCores":4, // Recommended values: [4, 8, 16, 32, 64, 80]
"executorMemory":"28g",
"executorCores":4,
"jars":["abfs[s]://<file_system>@<account_name>.dfs.core.windows.net/<path>/myjar.jar","wasb[s]://<containername>@<accountname>.blob.core.windows.net/<path>/myjar1.jar"],
"conf":{
//Example of a standard Spark property. To find more available properties, go to https://spark.apache.org/docs/latest/configuration.html#application-properties.
"spark.driver.maxResultSize":"10g",
//Example of a customized property. You can specify the count of lines that Spark SQL returns by configuring "livy.rsc.sql.num-rows".
"livy.rsc.sql.num-rows":"3000"
}
}
Hier sind einige Überlegungen für den Magic-Befehl %%configure:
- Wir empfehlen Ihnen, denselben Wert für
driverMemoryundexecutorMemoryin%%configurezu verwenden. Wir empfehlen Ihnen auch, dassdriverCoresundexecutorCoresdenselben Wert haben. - Sie können in Synapse-Pipelines
%%configureverwenden, aber wenn Sie dies nicht in der ersten Codezelle festlegen, schlägt die Pipelineausführung fehl, da sie die Sitzung nicht neu starten kann. - Der in
mssparkutils.notebook.runverwendete Befehl%%configurewird ignoriert, aber der in%run <notebook>verwendete Befehl wird weiterhin ausgeführt. - Sie müssen die standardmäßigen Spark-Konfigurationseigenschaften im Textkörper
"conf"verwenden. Wir unterstützen keine Verweise auf oberster Ebene für die Spark-Konfigurationseigenschaften. - Einige spezielle Spark-Eigenschaften werden im Textkörper
"conf"nicht wirksam werden, einschließlich"spark.driver.cores","spark.executor.cores","spark.driver.memory","spark.executor.memory"und"spark.executor.instances".
Parametrisierte Sitzungskonfiguration aus einer Pipeline
Sie können die parametrisierte Sitzungskonfiguration verwenden, um Werte im Magic-Befehl %%configure durch Parameter der Pipelineausführung (Notebookaktivität) zu ersetzen. Wenn Sie eine %%configure-Codezelle vorbereiten, können Sie Standardwerte überschreiben, indem Sie ein Objekt wie folgt verwenden:
{
"activityParameterName": "parameterNameInPipelineNotebookActivity",
"defaultValue": "defaultValueIfNoParameterFromPipelineNotebookActivity"
}
Das folgende Beispiel zeigt Standardwerte von 4 und "2000", die ebenfalls konfigurierbar sind:
%%configure
{
"driverCores":
{
"activityParameterName": "driverCoresFromNotebookActivity",
"defaultValue": 4
},
"conf":
{
"livy.rsc.sql.num-rows":
{
"activityParameterName": "rows",
"defaultValue": "2000"
}
}
}
Das Notebook verwendet den Standardwert, wenn Sie das Notebook direkt im interaktiven Modus ausführen, oder wenn die Notebookaktivität der Pipeline keinen Parameter bereitstellt, der "activityParameterName" entspricht.
Während dem Modus der Pipelineausführung können Sie die Registerkarte Einstellungen verwenden, um Einstellungen für eine Pipelinenotebookaktivität zu konfigurieren.
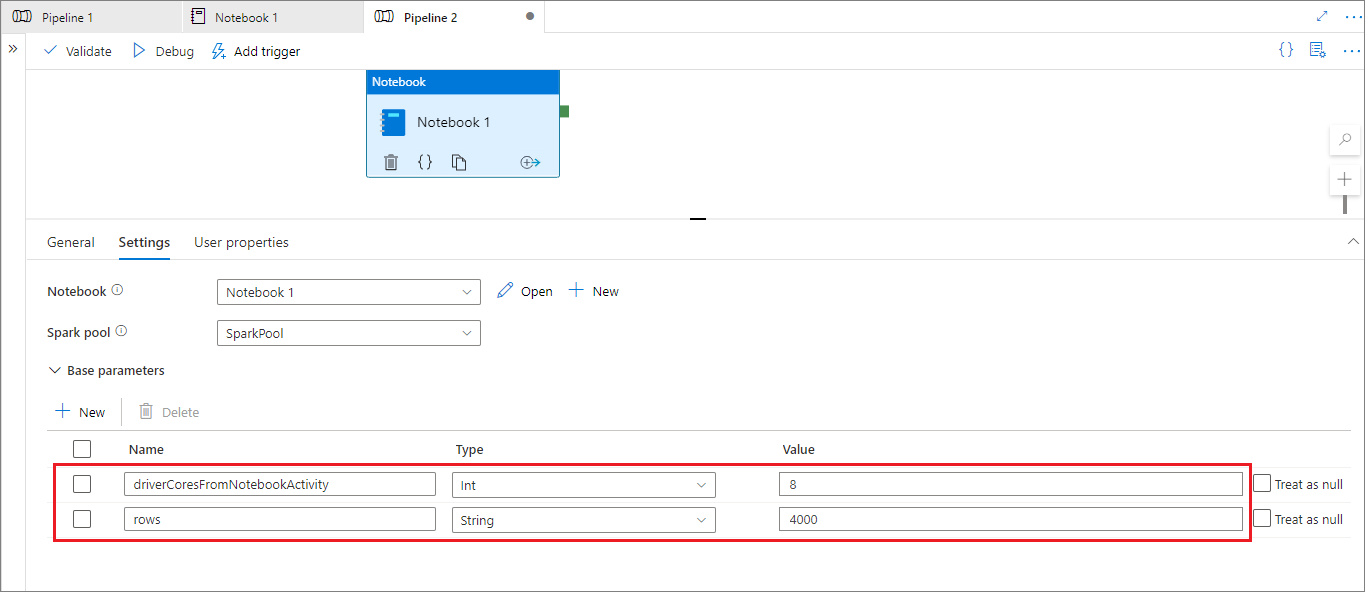
Wenn Sie die Sitzungskonfiguration ändern möchten, sollte der Name des Parameters der Pipelinenotebookaktivität mit dem Namen von activityParameterName im Notebook übereinstimmen. In diesem Beispiel ersetzt 8 während einer Pipelineausführung driverCores in %%configure, und 4000 ersetzt livy.rsc.sql.num-rows.
Wenn eine Pipelineausführung fehlschlägt, nachdem Sie den Magic-Befehl %%configure verwendet haben, können Sie weitere Fehlerinformationen erhalten, indem Sie die Magic-Zelle %%configure im interaktiven Modus des Notebooks ausführen.
Einfügen von Daten in ein Notebook
Sie können Daten aus Azure Data Lake Storage Gen 2, Azure Blob Storage und SQL-Pools laden, wie in den folgenden Codebeispielen gezeigt.
Lesen einer CSV-Datei aus Azure Data Lake Storage Gen2 als Spark-DataFrame
from pyspark.sql import SparkSession
from pyspark.sql.types import *
account_name = "Your account name"
container_name = "Your container name"
relative_path = "Your path"
adls_path = 'abfss://%s@%s.dfs.core.windows.net/%s' % (container_name, account_name, relative_path)
df1 = spark.read.option('header', 'true') \
.option('delimiter', ',') \
.csv(adls_path + '/Testfile.csv')
Lesen einer CSV-Datei aus Azure Blob Storage als Spark-DataFrame
from pyspark.sql import SparkSession
# Azure storage access info
blob_account_name = 'Your account name' # replace with your blob name
blob_container_name = 'Your container name' # replace with your container name
blob_relative_path = 'Your path' # replace with your relative folder path
linked_service_name = 'Your linked service name' # replace with your linked service name
blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
# Allow Spark to access from Azure Blob Storage remotely
wasb_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path)
spark.conf.set('fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token)
print('Remote blob path: ' + wasb_path)
df = spark.read.option("header", "true") \
.option("delimiter","|") \
.schema(schema) \
.csv(wasbs_path)
Lesen von Daten aus einem primären Speicherkonto
Sie können auf Daten im primären Speicherkonto direkt zugreifen. Es besteht keine Notwendigkeit, die geheimen Schlüssel bereitzustellen. Klicken Sie im Daten-Explorer mit der rechten Maustaste auf eine Datei, und wählen Sie Neues Notebook aus, um ein neues Notebook mit einem automatisch generierten Datenextraktor anzuzeigen.
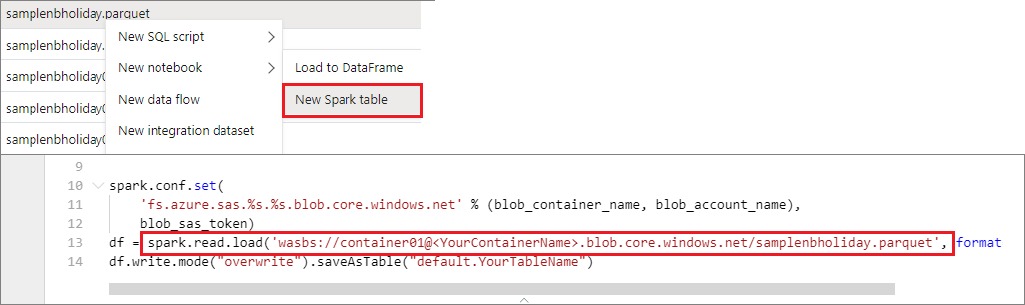
Verwenden von IPython-Widgets
Widgets sind ereignisreiche Python-Objekte, die eine Darstellung im Browser aufweisen, häufig als Steuerelement wie ein Schieberegler oder ein Textfeld. IPython-Widgets funktionieren nur in Python-Umgebungen. Sie werden derzeit nicht in anderen Sprachen unterstützt (z. B. Scala, SQL oder C#).
Schritte zur Verwendung von IPython-Widgets
Importieren Sie das Modul
ipywidgets, um das Jupyter Widgets-Framework zu verwenden:import ipywidgets as widgetsVerwenden Sie die Funktion auf oberster Ebene
display, um ein Widget zu rendern, oder hinterlassen Sie einen Ausdruck vom Typwidgetin der letzten Zeile der Codezelle:slider = widgets.IntSlider() display(slider)slider = widgets.IntSlider() sliderFühren Sie die Zelle aus. Das Widget wird im Ausgabebereich angezeigt.
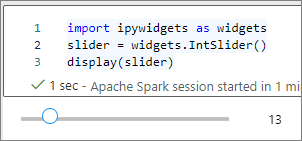
Sie können mehrere display()-Aufrufe verwenden, um dieselbe Instanz des Widgets mehrfach zu rendern, diese bleiben aber miteinander synchronisiert:
slider = widgets.IntSlider()
display(slider)
display(slider)
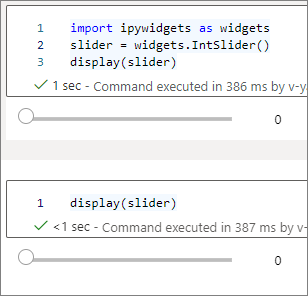
Um zwei Widgets zu rendern, die unabhängig voneinander sind, erstellen Sie zwei Instanzen des Widgets:
slider1 = widgets.IntSlider()
slider2 = widgets.IntSlider()
display(slider1)
display(slider2)
Unterstützte Widgets
| Widgettyp | Widgets |
|---|---|
| Numeric |
IntSlider, FloatSlider, FloatLogSlider, IntRangeSlider, FloatRangeSlider, IntProgress, FloatProgress, BoundedIntText, BoundedFloatText, IntText, FloatText |
| Boolean |
ToggleButton, Checkbox, Valid |
| Auswahl |
Dropdown, RadioButtons, Select, SelectionSlider, SelectionRangeSlider, ToggleButtons, SelectMultiple |
| String |
Text, Text area, Combobox, Password, Label, HTML, HTML Math, Image, Button |
| Wiedergeben (Animation) |
Date picker, Color picker, Controller |
| Container/Layout |
Box, HBox, VBox, GridBox, Accordion, Tabs, Stacked |
Bekannte Einschränkungen
In der folgenden Tabelle sind Widgets aufgeführt, die derzeit nicht unterstützt werden, zusammen mit Workarounds:
Funktionalität Problemumgehung Output-WidgetSie können stattdessen die print()-Funktion verwenden, um Text instdoutzu schreiben.widgets.jslink()Sie können die widgets.link()-Funktion verwenden, um zwei ähnliche Widgets zu verknüpfen.FileUpload-WidgetNicht verfügbar. Die globale Funktion
display, die Azure Synapse Analytics bereitstellt, unterstützt nicht das Anzeigen mehrerer Widgets in einem Aufruf (d. h.display(a, b)). Dieses Verhalten unterscheidet sich von der IPython-Funktiondisplay.Wenn Sie ein Notebook schließen, das ein IPython-Widget enthält, können Sie das Widget erst dann anzeigen oder damit interagieren, wenn Sie die entsprechende Zelle erneut ausführen.
Speichern von Notebooks
Sie können ein einzelnes Notebook oder alle Notebooks in Ihrem Arbeitsbereich speichern:
Um die von Ihnen an einem einzelnen Notebook vorgenommene Änderungen zu speichern, wählen Sie auf der Notebook-Befehlsleiste die Schaltfläche Veröffentlichen aus.

Um alle Notebooks in Ihrem Arbeitsbereich zu speichern, wählen Sie die Schaltfläche Alle veröffentlichen auf der Befehlsleiste des Arbeitsbereichs aus.

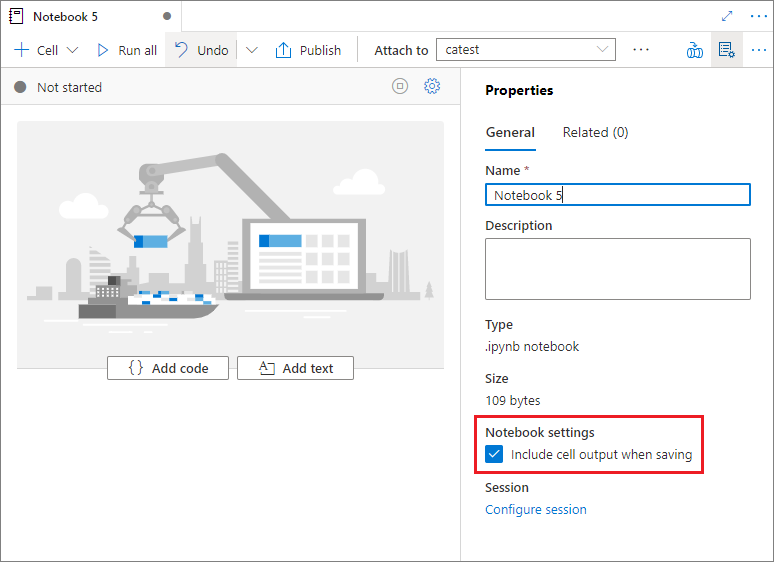
Im Bereich Eigenschaften des Notebooks können Sie konfigurieren, ob die Zellenausgabe beim Speichern eingeschlossen werden soll.
Verwenden der Magic-Befehle
Sie können bekannte Jupyter-Magic-Befehle in Synapse-Notebooks verwenden. Überprüfen Sie die folgenden Listen der derzeit verfügbaren Magic-Befehle. Teilen Sie uns Ihre Anwendungsfälle auf GitHub mit, damit wir weitere Magic-Befehle erstellen können, um Ihre Anforderungen zu erfüllen.
Hinweis
Nur die folgenden Magic-Befehle werden in Synapse-Pipelines unterstützt: %%pyspark, %%spark, %%csharp, %%sql.
Verfügbare Magic-Befehle für Zeilen:
%lsmagic, %time, %timeit, %history, %run, %load
Verfügbare Magic-Befehle für Zellen:
%%time, %%timeit, %%capture, %%writefile, %%sql, %%pyspark, %%spark, %%csharp, %%html, %%configure
Verweisen auf ein unveröffentlichtes Notebook
Das Verweisen auf ein nicht veröffentlichtes Notebook ist hilfreich, wenn Sie lokal debuggen möchten. Wenn Sie dieses Feature aktivieren, ruft ein Notebook den aktuellen Inhalt im Webcache ab. Wenn Sie eine Zelle ausführen, die eine Notebookverweis-Anweisung enthält, verweisen Sie im aktuellen Notebookbrowser auf die präsentierenden Notebooks anstelle einer gespeicherten Version in einem Cluster. Andere Notebooks können in Ihrem Notebook-Editor auf die Änderungen verweisen, ohne dass Sie die Änderungen veröffentlichen (Livemodus) oder committen (Git-Modus) müssen. Mithilfe dieses Ansatzes können Sie die Verunreinigung allgemeiner Bibliotheken während des Entwicklungs- oder Debuggingprozesses verhindern.
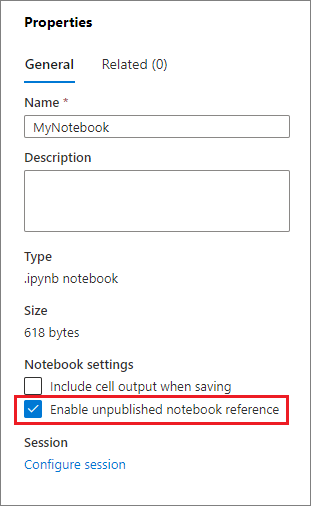
Sie können das Verweisen auf ein nicht veröffentlichtes Notebook aktivieren, indem Sie im Bereich Eigenschaften das entsprechende Kontrollkästchen aktivieren.
Die folgende Tabelle vergleicht die Fälle. Obwohl %run und mssparkutils.notebook.run hier das gleiche Verhalten aufweisen, verwendet die Tabelle %run als Beispiel.
| Case | Disable | Aktivieren |
|---|---|---|
| Livemodus | ||
Nb1 (veröffentlicht) %run Nb1 |
Ausführen der veröffentlichten Version von Nb1 | Ausführen der veröffentlichten Version von Nb1 |
Nb1 (Neu) %run Nb1 |
Fehler | Ausführen der neuen Nb1 |
Nb1 (zuvor veröffentlicht, bearbeitet) %run Nb1 |
Ausführen der veröffentlichten Version von Nb1 | Ausführen der bearbeiteten Version von Nb1 |
| Git-Modus | ||
Nb1 (veröffentlicht) %run Nb1 |
Ausführen der veröffentlichten Version von Nb1 | Ausführen der veröffentlichten Version von Nb1 |
Nb1 (Neu) %run Nb1 |
Fehler | Ausführen der neuen Nb1 |
Nb1 (Nicht veröffentlicht, committet) %run Nb1 |
Fehler | Ausführen der committeten Nb1 |
Nb1 (zuvor veröffentlicht, committet) %run Nb1 |
Ausführen der veröffentlichten Version von Nb1 | Ausführen der committeten Version von Nb1 |
Nb1 (zuvor veröffentlicht, neu im aktuellen Kanal) %run Nb1 |
Ausführen der veröffentlichten Version von Nb1 | Ausführen der neuen Nb1 |
Nb1 (nicht veröffentlicht, zuvor committet, bearbeitet) %run Nb1 |
Fehler | Ausführen der bearbeiteten Version von Nb1 |
Nb1 (zuvor veröffentlicht und committet, bearbeitet) %run Nb1 |
Ausführen der veröffentlichten Version von Nb1 | Ausführen der bearbeiteten Version von Nb1 |
Zusammenfassung:
- Wenn Sie das Verweisen auf ein nicht veröffentlichtes Notebook deaktivieren, führen Sie immer die veröffentlichte Version aus.
- Wenn Sie das Verweisen auf ein nicht veröffentlichtes Notebook aktivieren, übernimmt die Referenzausführung immer die aktuelle Version des Notebooks, die in der Benutzeroberfläche des Notebooks angezeigt wird.
Verwalten aktiver Sitzungen
Sie können Ihre Notebooksitzungen wiederverwenden, ohne neue Sitzungen starten zu müssen. In Synapse-Notebooks können Sie Ihre aktiven Sitzungen in einer einzigen Liste verwalten. Um die Liste zu öffnen, wählen Sie die Auslassungspunkte (...) und dann Sitzungen verwalten aus.
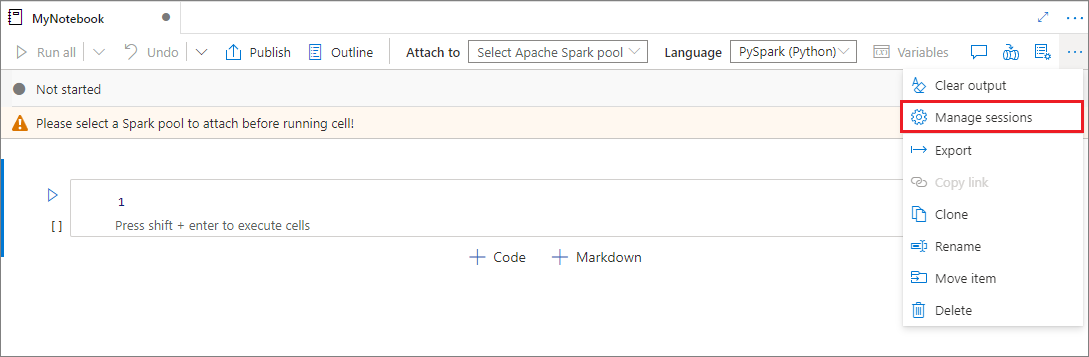
Im Bereich Aktive Sitzungen werden alle Sitzungen im aktuellen Arbeitsbereich aufgelistet, die Sie aus einem Notebook gestartet haben. Die Liste zeigt die Sitzungsinformationen und die dazugehörigen Notebooks. Die Aktionen Trennen mit Notebook, Beenden der Sitzungund Anzeigen in der Überwachung sind hier verfügbar. Außerdem können Sie Ihr ausgewähltes Notebook mit einer aktiven Sitzung verbinden, die von einem anderen Notebook aus gestartet wurde. Die Sitzung wird dann vom vorherigen Notebook getrennt (wenn es sich nicht im Leerlauf befindet) und dem aktuellen angefügt.
Verwenden von Python-Protokollen in einem Notebook
Mit dem folgenden Beispielcode können Sie Python-Protokolle finden und verschiedene Protokollebenen und -formate einstellen:
import logging
# Customize the logging format for all loggers
FORMAT = "%(asctime)s - %(name)s - %(levelname)s - %(message)s"
formatter = logging.Formatter(fmt=FORMAT)
for handler in logging.getLogger().handlers:
handler.setFormatter(formatter)
# Customize the log level for all loggers
logging.getLogger().setLevel(logging.INFO)
# Customize the log level for a specific logger
customizedLogger = logging.getLogger('customized')
customizedLogger.setLevel(logging.WARNING)
# Logger that uses the default global log level
defaultLogger = logging.getLogger('default')
defaultLogger.debug("default debug message")
defaultLogger.info("default info message")
defaultLogger.warning("default warning message")
defaultLogger.error("default error message")
defaultLogger.critical("default critical message")
# Logger that uses the customized log level
customizedLogger.debug("customized debug message")
customizedLogger.info("customized info message")
customizedLogger.warning("customized warning message")
customizedLogger.error("customized error message")
customizedLogger.critical("customized critical message")
Anzeigen des Verlaufs von Eingabebefehlen
Synapse-Notebooks unterstützen den Magic-Befehl %history zum Drucken des Eingabebefehlsverlaufs für die aktuelle Sitzung. Der Magic-Befehl %history ähnelt dem standardmäßigen Jupyter IPython-Befehl und funktioniert für mehrere Sprachkontexte in einem Notebook.
%history [-n] [range [range ...]]
Im vorherigen Code ist -n die Druckausführungsnummer. Der Wert range kann wie folgt lauten:
-
N: Drucken von Code derNth. ausgeführten Zelle. -
M-N: Drucken von Code aus derMth. bis zurNth. ausgeführten Zelle.
Um beispielsweise den Eingabeverlauf von der ersten bis zur zweiten ausgeführten Zelle zu drucken, verwenden Sie %history -n 1-2.
Integrieren eines Notebooks
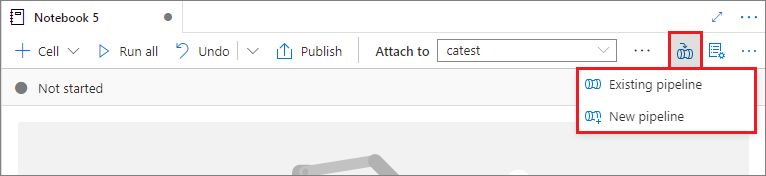
Hinzufügen eines Notebooks zu einer Pipeline
Um ein Notebook zu einer vorhandenen Pipeline hinzuzufügen oder eine neue Pipeline zu erstellen, wählen Sie in der oberen rechten Ecke die Schaltfläche Zur Pipeline hinzufügen aus.
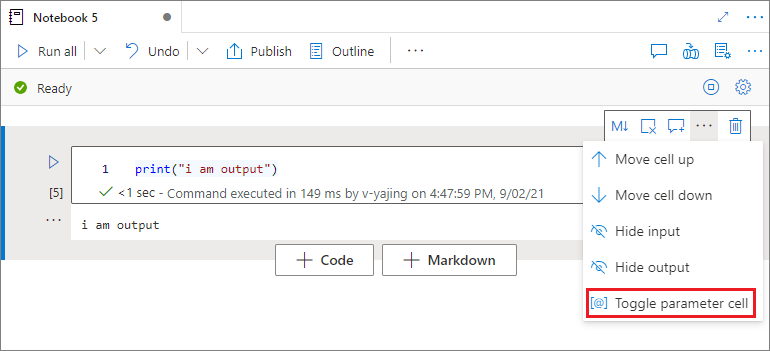
Festlegen einer Parameterzelle
Um Ihr Notebook zu parametrisieren, wählen Sie die Auslassungspunkte (...) aus, um auf der Zellensymbolleiste auf weitere Befehle zuzugreifen. Wählen Sie dann Parameterzelle umschalten aus, um die Zelle als Parameterzelle festzulegen.
Azure Data Factory sucht nach der Parameterzelle und behandelt diese Zelle als den Standard für die Parameter, die zur Ausführungszeit übermittelt werden. Das Ausführungsmodul fügt eine neue Zelle unter der Parameterzelle mit Eingabeparametern hinzu, um die Standardwerte zu überschreiben.
Zuweisen von Parameterwerten über eine Pipeline
Nachdem Sie ein Notebook mit Parametern erstellt haben, können Sie es über eine Pipeline ausführen, indem Sie eine Synapse-Notebookaktivität verwenden. Nachdem Sie die Aktivität zu Ihrem Pipelinecanvas hinzugefügt haben, können Sie die Parameterwerte auf der Registerkarte Einstellungen im Abschnitt Basisparameter festlegen.
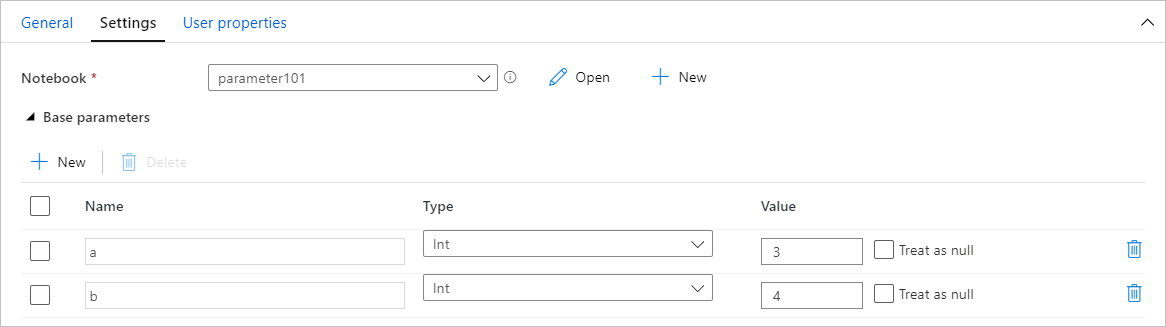
Wenn Sie Parameterwerte zuweisen, können Sie die Pipelineausdruckssprache oder Systemvariablen verwenden.
Verwenden von Tastenkombinationen
Ähnlich wie Jupyter Notebooks verfügen Synapse-Notebooks über eine modale Benutzeroberfläche. Mit der Tastatur werden unterschiedliche Aktionen ausgeführt, je nachdem, in welchem Modus sich die Notebook-Zelle befindet. Synapse-Notebooks unterstützen die folgenden beiden Modi für eine Codezelle:
Befehlsmodus: Eine Zelle befindet sich im Befehlsmodus, wenn kein Textcursor Sie zum Eingeben auffordert. Wenn sich eine Zelle im Befehlsmodus befindet, können Sie das Notebook als Ganzes bearbeiten, aber keine Eingaben in einzelnen Zellen vornehmen. Wechseln Sie in den Befehlsmodus, indem Sie die ESC-TASTE auswählen oder die Maus verwenden, um den Bereich außerhalb des Editorbereichs einer Zelle auszuwählen.

Bearbeitungsmodus: Wenn sich eine Zelle im Bearbeitungsmodus befindet, werden Sie von einem Textcursor aufgefordert, in die Zelle einzugeben. Wechseln Sie in den Bearbeitungsmodus, indem Sie die EINGABETASTE auswählen oder die Maus verwenden, um den Editorbereich einer Zelle auszuwählen.

Tastenkombinationen im Befehlsmodus
| Aktion | Tastenkombinationen für Synapse-Notebooks |
|---|---|
| Aktuelle Zelle ausführen und die darunter auswählen | UMSCHALT+EINGABE |
| Aktuelle Zelle ausführen und darunter einfügen | ALT+EINGABE |
| Aktuelle Zelle ausführen | STRG+EINGABE |
| Zelle darüber auswählen | Nach oben |
| Zelle darunter auswählen | Nach unten |
| Vorherige Zelle auswählen | K |
| Nächste Zelle auswählen | J |
| Zelle oberhalb einfügen | Ein |
| Zelle unterhalb einfügen | B |
| Ausgewählte Zellen löschen | UMSCHALT+D |
| In den Bearbeitungsmodus wechseln | EINGABETASTE |
Tastenkombinationen im Bearbeitungsmodus
| Aktion | Tastenkombinationen für Synapse-Notebooks |
|---|---|
| Cursor nach oben verschieben | Nach oben |
| Cursor nach unten verschieben | Nach unten |
| Rückgängig machen | STRG+Z |
| Wiederholen | STRG+Y |
| Auskommentieren/Auskommentierung aufheben | STRG+/ |
| Wort davor löschen | STRG+RÜCKTASTE |
| Wort danach löschen | STRG+ENTF |
| Zum Anfang der Zelle wechseln | STRG+POS1 |
| Zum Ende der Zelle wechseln | STRG+ENDE |
| Ein Wort nach links wechseln | Strg+Nach-Links |
| Ein Wort nach rechts wechseln | Strg+Nach-Rechts |
| Alle auswählen | STRG+A |
| Einziehen | STRG+] |
| Einzug entfernen | STRG+[ |
| In den Befehlsmodus wechseln | Esc |
Zugehöriger Inhalt
- Synapse-Beispielnotebooks
- Schnellstart: Erstellen eines Apache Spark-Pools in Azure Synapse Analytics mithilfe von Webtools
- Was ist Apache Spark in Azure Synapse Analytics?
- Verwenden von .NET für Apache Spark mit Azure Synapse Analytics
- Dokumentation zu .NET für Apache Spark
- Dokumentation zu Azure Synapse Analytics