Apache Spark-Pools mit GPU-Beschleunigung in Azure Synapse Analytics (veraltet)
Apache Spark ist ein Framework für die Parallelverarbeitung, das In-Memory-Verarbeitung unterstützt, um die Leistung von Big Data-Analyseanwendungen zu steigern. Apache Spark in Azure Synapse Analytics ist eine der cloudbasierten Apache Spark-Implementierungen von Microsoft.
Azure Synapse ermöglicht jetzt die Erstellung von Azure Synapse GPU-fähigen Pools für die Ausführung von Spark-Workloads mithilfe von zugrunde liegenden RAPIDS-Bibliotheken. Hierbei wird die hohe Leistungsstärke in Bezug auf die Parallelverarbeitung der GPUs genutzt, um die Verarbeitung zu beschleunigen. Mit dem RAPIDS Accelerator für Apache Spark können Sie Ihre vorhandenen Spark-Anwendungen ohne Codeänderung ausführen, indem Sie lediglich eine Konfigurationseinstellung aktivieren, die für einen GPU-fähigen Pool vorkonfiguriert ist. Sie können die RAPIDS-basierte GPU-Beschleunigung für Ihre Workload oder Teile davon aktivieren/deaktivieren, indem Sie diese Konfiguration festlegen:
spark.conf.set('spark.rapids.sql.enabled','true/false')
Hinweis
Die Vorschau für GPU-fähige Azure Synapse-Pools ist jetzt veraltet.
Achtung
Benachrichtigung zur Einstellung und Deaktivierung für GPUs unter der Azure Synapse-Runtime für Apache Spark 3.1 und 3.2
- Die Vorschau mit GPU-Beschleunigung ist jetzt für die Apache Spark 3.2-Runtime (veraltet) veraltet. Für veraltete Runtimes werden keine Fehler- und Featurebehebungen mehr bereitgestellt. Diese Runtime und die entsprechende Vorschau mit GPU-Beschleunigung in Spark 3.2 wurden am 8. Juli 2024 eingestellt und deaktiviert.
- Die Vorschau mit GPU-Beschleunigung ist jetzt für die Azure Synapse 3.1-Runtime (veraltet) veraltet. Azure Synapse Runtime für Apache Spark 3.1 hat am 26. Januar 2023 das Supportende erreicht. Der offizielle Support wurde am 26. Januar 2024 eingestellt, und Supporttickets, Fehlerbehebungen oder Sicherheitsupdates nach diesem Datum werden nicht mehr bearbeitet.
RAPIDS Accelerator für Apache Spark
Der Spark RAPIDS Accelerator ist ein Plug-In, bei dem der physische Plan eines Spark-Auftrags durch unterstützte GPU-Vorgänge überschrieben wird. Diese Vorgänge werden dann auf den GPUs ausgeführt, um die Verarbeitung zu beschleunigen. Diese Bibliothek befindet sich derzeit in der Vorschauphase, und es werden nicht alle Spark-Vorgänge unterstützt. (Sehen Sie sich die Liste mit den derzeit unterstützten Operatoren an. Weitere Unterstützung wird nach und nach in Form von Releases hinzugefügt.)
Konfigurationsoptionen für Cluster
Für das RAPIDS Accelerator-Plug-In wird nur eine 1:1-Zuordnung zwischen GPUs und Executors unterstützt. Dies bedeutet, dass ein Spark-Auftrag Executor- und Treiberressourcen anfordern muss, die durch die Poolressourcen abgedeckt werden können (basierend auf der Anzahl verfügbarer GPU- und CPU-Kerne). Um diese Bedingung zu erfüllen und eine optimale Auslastung aller Poolressourcen sicherzustellen, ist für eine Spark-Anwendung, die in GPU-fähigen Pools ausgeführt wird, die folgende Konfiguration der Treiber und Executors erforderlich:
| Poolgröße | Optionen für die Treibergröße | Treiberkerne | Treiberarbeitsspeicher (GB) | Executorkerne | Executorarbeitsspeicher (GB) | Anzahl von Executors |
|---|---|---|---|---|---|---|
| GPU: Groß | Kleiner Treiber | 4 | 30 | 12 | 60 | Anzahl von Knoten im Pool |
| GPU: Groß | Mittlerer Treiber | 7 | 30 | 9 | 60 | Anzahl von Knoten im Pool |
| GPU: Sehr groß | Mittlerer Treiber | 8 | 40 | 14 | 80 | 4 * Anzahl von Knoten im Pool |
| GPU: Sehr groß | Großer Treiber | 12 | 40 | 13 | 80 | 4 * Anzahl von Knoten im Pool |
Workloads, die nicht einer der obigen Konfigurationen entsprechen, werden nicht akzeptiert. Hiermit wird sichergestellt, dass Spark-Aufträge mit der effizientesten und leistungsfähigsten Konfiguration und allen verfügbaren Ressourcen im Pool ausgeführt werden.
Der Benutzer kann die obige Konfiguration über seine Workload festlegen. Für Notebooks kann der Benutzer den Magic-Befehl %%configure verwenden, um eine der obigen Konfigurationen festzulegen (unten dargestellt).
Ein Beispiel hierfür ist die Verwendung eines großen Pools mit drei Knoten:
%%configure -f
{
"driverMemory": "30g",
"driverCores": 4,
"executorMemory": "60g",
"executorCores": 12,
"numExecutors": 3
}
Ausführen eines Spark-Beispielauftrags über ein Notebook in einem Azure Synapse-Pool mit GPU-Beschleunigung
Es ist hilfreich, wenn Sie sich vor dem Fortfahren mit diesem Abschnitt mit den grundlegenden Konzepten der Nutzung eines Notebooks in Azure Synapse Analytics vertraut machen. Hier sind die Schritte zum Ausführen einer Spark-Anwendung mit GPU-Beschleunigung beschrieben. Sie können eine Spark-Anwendung in allen vier Sprachen schreiben, die in Synapse unterstützt werden: PySpark (Python), Spark (Scala), SparkSQL und .NET für Spark (C#).
Erstellen eines GPU-fähigen Pools
Erstellen Sie ein Notebook, und fügen Sie es an den GPU-fähigen Pool an, den Sie im ersten Schritt erstellt haben.
Legen Sie die Konfigurationen wie im vorherigen Abschnitt beschrieben fest.
Erstellen Sie einen Beispieldatenrahmen, indem Sie den folgenden Code in die erste Zelle Ihres Notebooks kopieren:
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.Row
import scala.collection.JavaConversions._
val schema = StructType( Array(
StructField("emp_id", IntegerType),
StructField("name", StringType),
StructField("emp_dept_id", IntegerType),
StructField("salary", IntegerType)
))
val emp = Seq(Row(1, "Smith", 10, 100000),
Row(2, "Rose", 20, 97600),
Row(3, "Williams", 20, 110000),
Row(4, "Jones", 10, 80000),
Row(5, "Brown", 40, 60000),
Row(6, "Brown", 30, 78000)
)
val empDF = spark.createDataFrame(emp, schema)
- Sie führen nun eine Aggregierung durch, indem Sie das höchste Gehalt nach Abteilungs-ID abrufen und das Ergebnis anzeigen:
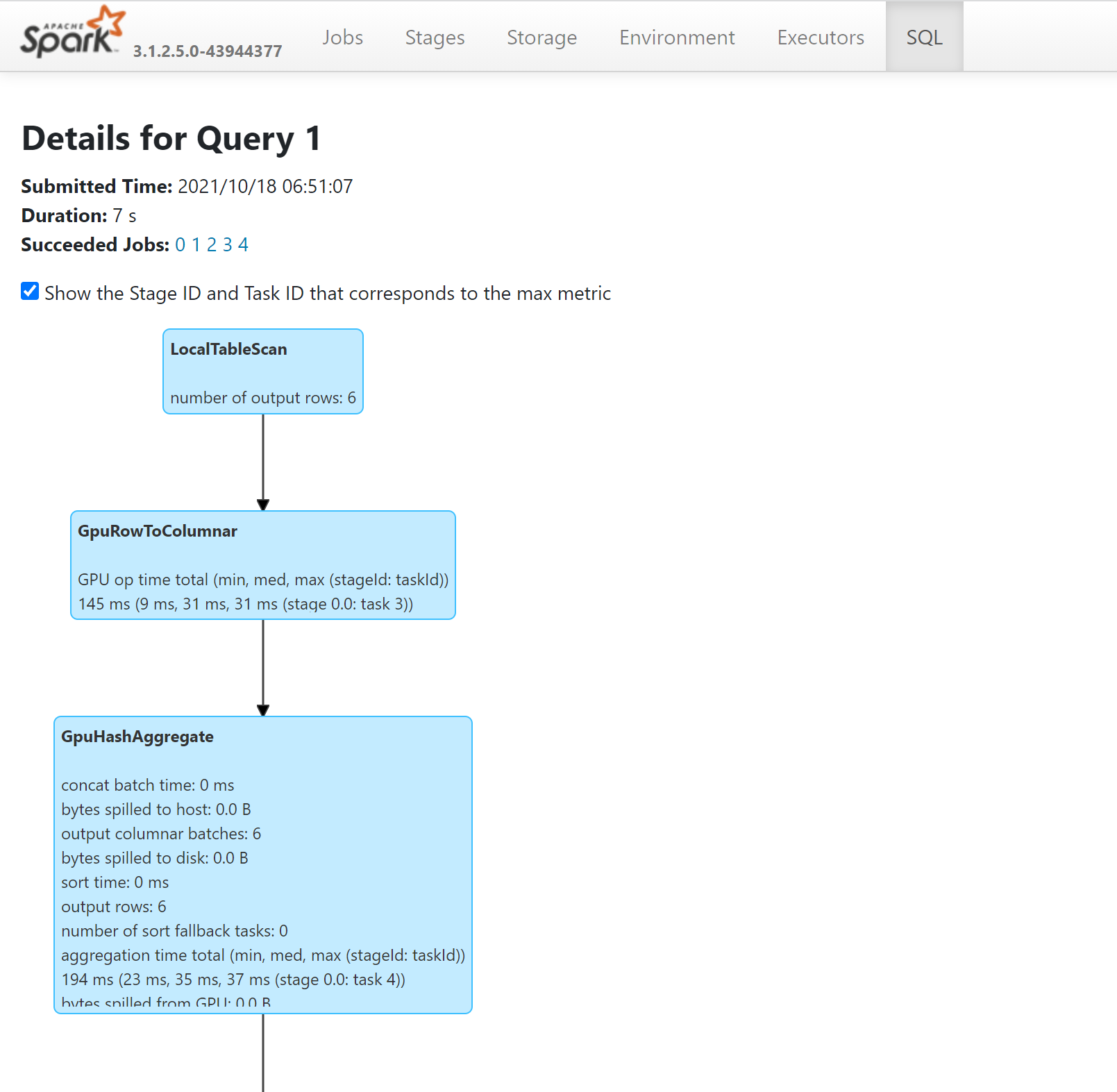
- Sie können die Vorgänge in Ihrer Abfrage verfolgen, die auf GPUs ausgeführt wurde, indem Sie sich den SQL-Plan auf dem Spark-Verlaufsserver ansehen:
Optimieren Ihrer Anwendung für GPUs
Für die meisten Spark-Aufträge kann die Leistung verbessert werden, indem die Standardwerte der Konfigurationseinstellungen optimiert werden. Dies gilt auch für Aufträge, für die das RAPIDS Accelerator-Plug-In für Apache Spark genutzt wird.
Kontingente und Ressourceneinschränkungen in Azure Synapse GPU-fähigen Pools
Arbeitsbereichsebene
Jeder Azure Synapse-Arbeitsbereich verfügt über ein Standardkontingent von 50 virtuellen GPU-Kernen. Um Ihr Kontingent an GPU-Kernen zu erhöhen, übermitteln Sie eine Supportanfrage über das Azure-Portal.