Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Unternehmen müssen häufig große Datenmengen verarbeiten, bevor sie diese den wichtigsten Beteiligten im Unternehmen bereitstellen. In diesem Tutorial erfahren Sie, wie Sie die integrierten Schnittstellen in Azure Synapse Analytics nutzen können, um die Daten mit Apache Spark zu verarbeiten und die Daten dann Endbenutzern über Power BI und einen serverlosen SQL-Pool bereitzustellen.
Vorbereitung
- Als Standardspeicher konfigurierter Azure Synapse Analytics-Arbeitsbereich mit einem ADLS Gen2-Speicherkonto.
- Power BI-Arbeitsbereich und Power BI Desktop, um Daten zu visualisieren. Ausführliche Informationen finden Sie unter Erstellen der neuen Arbeitsbereiche in Power BI und Installieren von Power BI Desktop.
- Verknüpfter Dienst, um Verbindungen mit Ihrer Azure Synapse Analytics-Instanz und Ihren Power BI-Arbeitsbereichen herzustellen. Ausführliche Informationen finden Sie unter Schnellstart: Verknüpfen eines Power BI-Arbeitsbereichs mit einem Synapse-Arbeitsbereich.
- Serverloser Apache Spark-Pool in Ihrem Synapse Analytics-Arbeitsbereich. Ausführliche Informationen finden Sie unter Erstellen eines serverlosen Apache Spark-Pools.
Herunterladen und Vorbereiten der Daten
In diesem Beispiel verwenden Sie Apache Spark, um ein paar Analysen zu Trinkgelddaten von Taxifahrten in New York durchzuführen. Die Daten sind über Azure Open Datasets verfügbar. Diese Teilmenge des Datasets enthält Informationen über Taxifahrten von Yellow Cabs, einschließlich Informationen zu jeder einzelnen Fahrt, den Start- und Endzeiten/-orten, den Kosten und andere interessante Attribute.
Führen Sie die folgenden Zeilen aus, um einen Spark-Dataframe zu erstellen, indem Sie den Code in eine neue Zelle einfügen. Dadurch werden die Daten über die Open Datasets-API abgerufen. Das Abrufen aller dieser Daten generiert ungefähr 1,5 Milliarden Zeilen. Das folgende Codebeispiel verwendet „start_date“ und „end_date“, um einen Filter anzuwenden, der Daten für einen einzelnen Monat zurückgibt.
from azureml.opendatasets import NycTlcYellow from dateutil import parser from datetime import datetime end_date = parser.parse('2018-06-06') start_date = parser.parse('2018-05-01') nyc_tlc = NycTlcYellow(start_date=start_date, end_date=end_date) filtered_df = nyc_tlc.to_spark_dataframe()Mit Apache Spark SQL wird eine Datenbank namens „NycTlcTutorial“ erstellt. Diese Datenbank wird verwendet, um die Ergebnisse einer Datenverarbeitung zu speichern.
%%pyspark spark.sql("CREATE DATABASE IF NOT EXISTS NycTlcTutorial")Im nächsten Schritt werden Spark-Datenrahmenvorgänge verwendet, um die Daten zu verarbeiten. Im folgenden Code werden die folgenden Transformationen vorgenommen:
- Entfernen der Spalten, die nicht benötigt werden.
- Das Entfernen von Ausreißern/falschen Werten durch Filtern.
- Erstellen neuer Features wie
tripTimeSecsundtippedfür zusätzliche Analysen.
from pyspark.sql.functions import unix_timestamp, date_format, col, when taxi_df = filtered_df.select('totalAmount', 'fareAmount', 'tipAmount', 'paymentType', 'rateCodeId', 'passengerCount'\ , 'tripDistance', 'tpepPickupDateTime', 'tpepDropoffDateTime'\ , date_format('tpepPickupDateTime', 'hh').alias('pickupHour')\ , date_format('tpepPickupDateTime', 'EEEE').alias('weekdayString')\ , (unix_timestamp(col('tpepDropoffDateTime')) - unix_timestamp(col('tpepPickupDateTime'))).alias('tripTimeSecs')\ , (when(col('tipAmount') > 0, 1).otherwise(0)).alias('tipped') )\ .filter((filtered_df.passengerCount > 0) & (filtered_df.passengerCount < 8)\ & (filtered_df.tipAmount >= 0) & (filtered_df.tipAmount <= 25)\ & (filtered_df.fareAmount >= 1) & (filtered_df.fareAmount <= 250)\ & (filtered_df.tipAmount < filtered_df.fareAmount)\ & (filtered_df.tripDistance > 0) & (filtered_df.tripDistance <= 100)\ & (filtered_df.rateCodeId <= 5) & (filtered_df.paymentType.isin({"1", "2"})))Schließlich wird der Datenrahmen mit der Apache Spark-Methode
saveAsTablegespeichert. Dadurch wird es ermöglicht, dass Sie später über serverlose SQL-Pools Verbindungen mit derselben Tabelle herstellen und diese Tabelle abfragen können.
taxi_df.write.mode("overwrite").saveAsTable("NycTlcTutorial.nyctaxi")
Abfragen von Daten mit serverlosen SQL-Pools
Azure Synapse Analytics ermöglicht den verschiedenen Berechnungsengines von Arbeitsbereichen die gemeinsame Nutzung von Datenbanken und Tabellen zwischen serverlosen Apache Spark-Pools und dem serverlosen SQL-Pool. Dies wird durch die Synapse-Funktionalität Verwaltung von gemeinsam genutzten Metadaten ermöglicht. Im Ergebnis werden die von Spark erstellten Datenbanken und ihre Parquet-basierten Tabellen im serverlosen SQL-Pool des Arbeitsbereichs sichtbar.
So fragen Sie Ihre Apache Spark-Tabelle über Ihren serverlosen SQL-Pool ab:
Nachdem Sie Ihre Apache Spark-Tabelle gespeichert haben, wechseln Sie zur Registerkarte Data.
Suchen Sie unter Workspaces nach der Apache Spark-Tabelle, die Sie soeben erstellt haben, und wählen Sie New SQL script und dann Select TOP 100 rows aus.
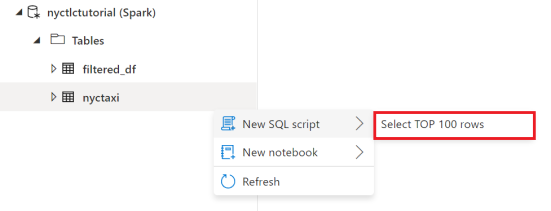
Sie können Ihre Abfrage weiter verfeinern, oder Sie können Ihre Ergebnisse mit den SQL-Optionen für Diagrammerstellung visualisieren.
Verbinden mit Power BI
Im nächsten Schritt verbinden Sie Ihren serverlosen SQL-Pool mit Ihrem Power BI-Arbeitsbereich. Sobald Sie eine Verbindung mit Ihrem Arbeitsbereich hergestellt haben, können Sie Power BI-Berichte sowohl direkt aus Azure Synapse Analytics als auch aus Power BI Desktop erstellen.
Hinweis
Bevor Sie beginnen, müssen Sie einen verknüpften Dienst für Ihren Power BI-Arbeitsbereich einrichten und Power BI Desktop herunterladen.
So verbinden Sie Ihren serverlosen SQL-Pool mit Ihrem Power BI-Arbeitsbereich:
Navigieren Sie zur Registerkarte Power BI-Datasets, und wählen Sie die Option für + Neues Dataset aus. Laden Sie über die Eingabeaufforderung die PBIDS-Datei aus der SQL Analytics-Datenbank herunter, die Sie als Datenquelle verwenden möchten.
Öffnen Sie die Datei mit Power BI Desktop, um ein Dataset zu erstellen. Nachdem Sie die Datei geöffnet haben, stellen Sie eine Verbindung mit der SQL Server-Datenbank her. Verwenden Sie dazu das Microsoft-Konto und die Option Importieren.
Erstellen eines Power BI-Berichts
Aus Power BI Desktop können Sie Ihrem Bericht nun ein Wichtigste Einflussfaktoren-Diagramm hinzufügen.
Ziehen Sie die Mittelwertspalte tipAmount auf die Analysieren-Achse.
Ziehen Sie die Spalte weekdayString und die Mittelwertspalten tripDistanceund tripTimeSecs auf die Erläuterung nach-Achse.
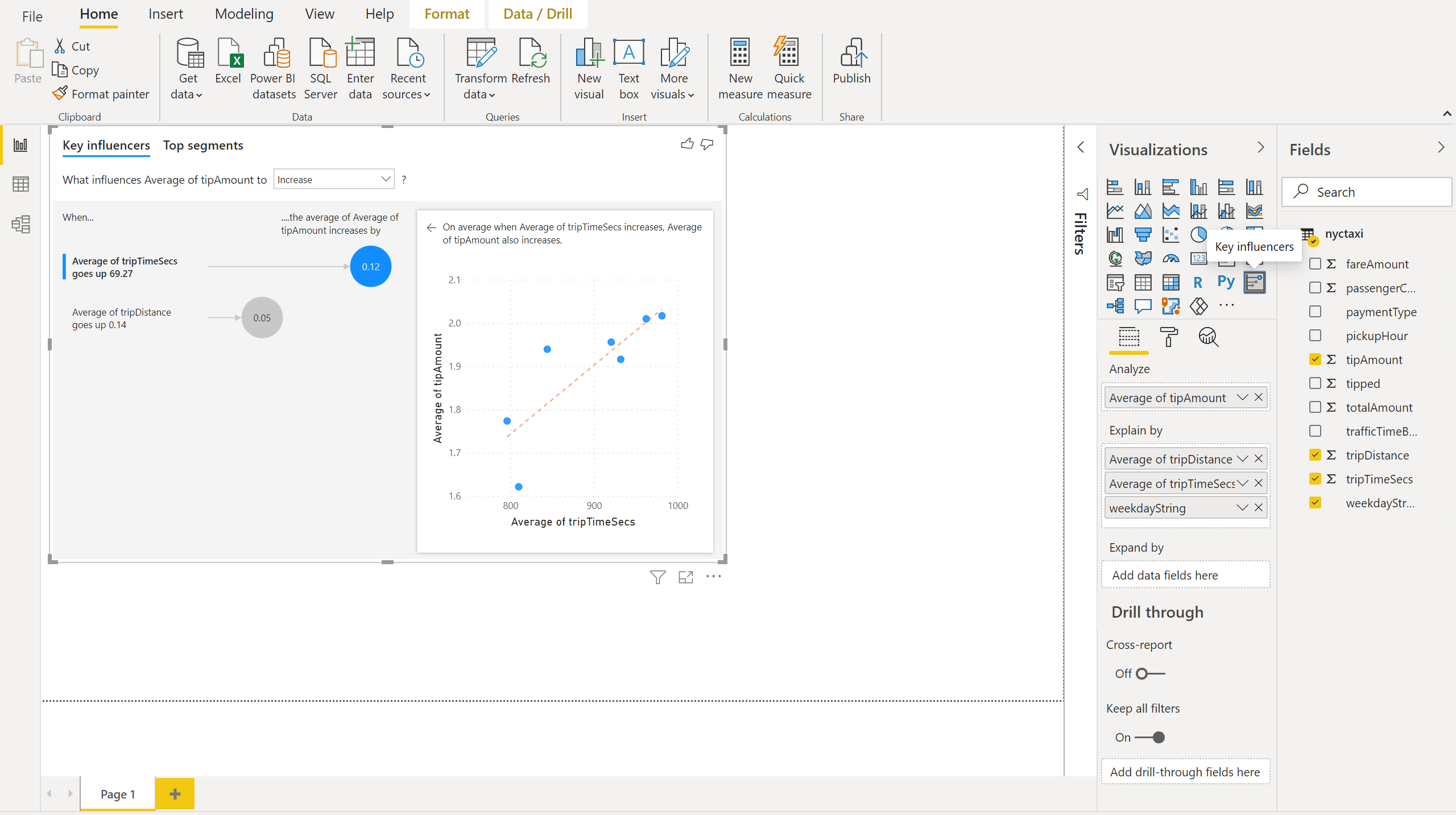
Wählen Sie auf der Power BI Desktop-Registerkarte „Startseite“ die Optionen Veröffentlichen und Speichern aus. Geben Sie einen Dateinamen ein, und speichern Sie diesen Bericht im Arbeitsbereich „NycTaxiTutorial“.
Darüber hinaus können Sie Power BI-Visualisierungen aus Ihrem Azure Synapse Analytics-Arbeitsbereich erstellen. Navigieren Sie dazu in Ihrem Azure Synapse-Arbeitsbereich zur Registerkarte Entwickeln, und öffnen Sie die Registerkarte „Power BI“. Von hier aus können Sie Ihren Bericht auswählen und weitere Visualisierungen erstellen.
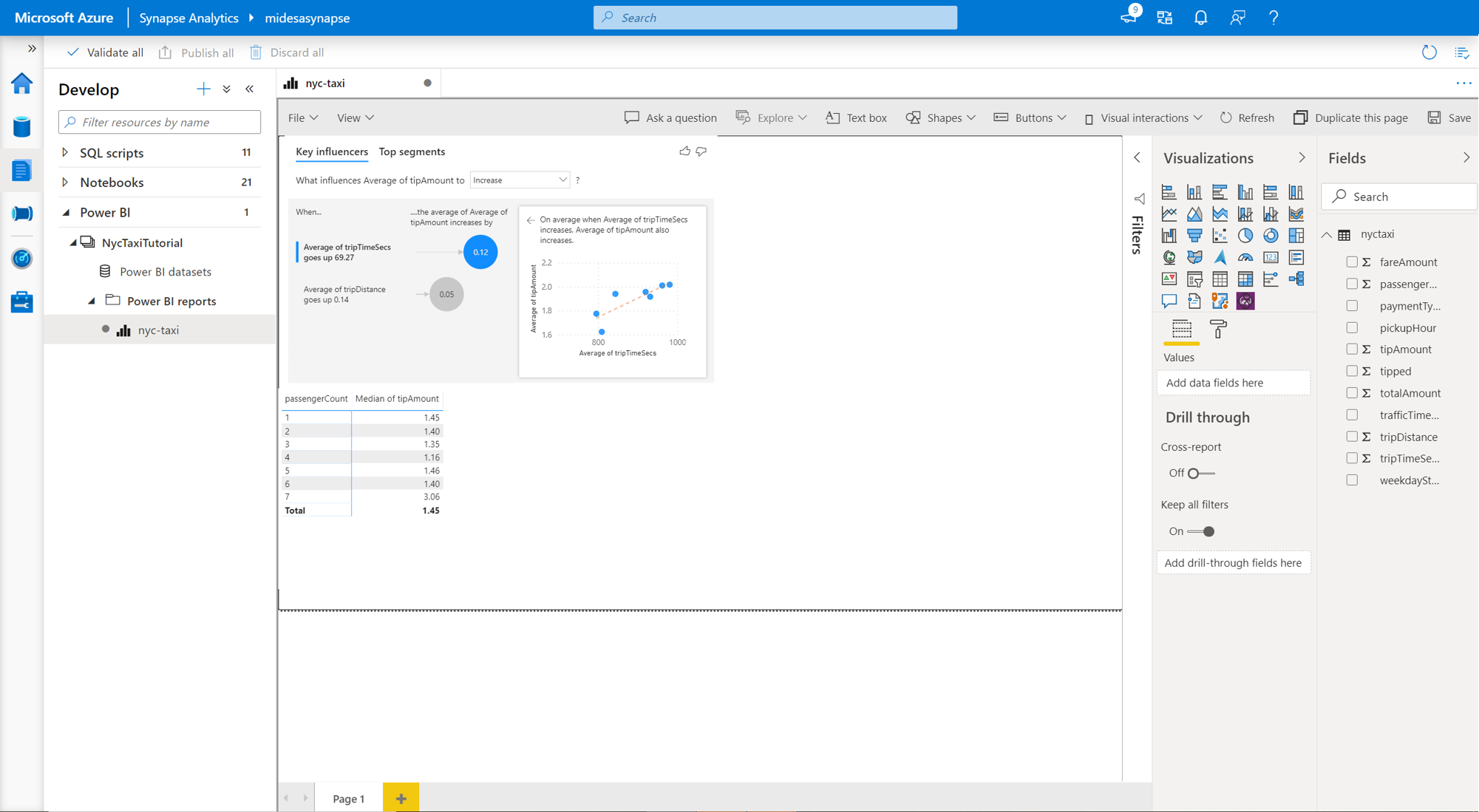
Wenn Sie weitere Informationen dazu wünschen, wie ein Dataset über einen serverlosen SQL-Pool erstellt und wie eine Verbindung mit Power BI hergestellt wird, wechseln Sie zum Tutorial: Verwenden eines serverlosen SQL-Pools mit Power BI Desktop und Erstellen eines Berichts.
Nächste Schritte
Weitere Informationen zu den Datenvisualisierungsfunktionen in Azure Synapse Analytics finden Sie in den folgenden Dokumenten und Tutorials: