Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
.NET für Apache Spark bietet kostenlose , Open-Source- und plattformübergreifende .NET-Unterstützung für Spark.
Sie stellt .NET-Bindungen für Spark bereit, sodass Sie über C# und F# auf Spark-APIs zugreifen können. Mit .NET für Apache Spark können Sie auch benutzerdefinierte Funktionen für Spark schreiben und ausführen, die in .NET geschrieben wurden. Mit den .NET-APIs für Spark können Sie auf alle Aspekte von Spark DataFrames zugreifen, die Ihnen dabei helfen, Ihre Daten zu analysieren, einschließlich Spark SQL, Delta Lake und Strukturiertes Streaming.
Sie können Daten mit .NET für Apache Spark über Spark Batchauftragsdefinitionen oder mit interaktiven Azure Synapse Analytics-Notizbüchern analysieren. In diesem Artikel erfahren Sie, wie Sie .NET für Apache Spark mit Azure Synapse mit beiden Techniken verwenden.
Von Bedeutung
.NET für Apache Spark ist ein Open-Source-Projekt unter .NET Foundation, das derzeit die .NET 3.1-Bibliothek erfordert, die den Status "Out-of-Support" erreicht hat. Wir möchten Benutzer von Azure Synapse Spark über das Entfernen der .NET für Apache Spark-Bibliothek in der Azure Synapse Runtime für Apache Spark, Version 3.3, informieren. Benutzer können sich auf die .NET-Supportrichtlinie beziehen, um weitere Details zu diesem Thema zu erhalten.
Daher ist es benutzern nicht mehr möglich, Apache Spark-APIs über C# und F# zu verwenden oder C#-Code in Notizbüchern in Synapse oder über Apache Spark Job-Definitionen in Synapse auszuführen. Es ist wichtig zu beachten, dass diese Änderung nur Azure Synapse Runtime für Apache Spark 3.3 und höher betrifft.
Wir werden .NET für Apache Spark weiterhin in allen früheren Versionen der Azure Synapse Runtime gemäß ihren Lebenszyklusphasen unterstützen. Wir haben jedoch keine Pläne, .NET für Apache Spark in Azure Synapse Runtime für Apache Spark 3.3 und zukünftige Versionen zu unterstützen. Es wird empfohlen, dass Benutzer mit vorhandenen Workloads, die in C# oder F# geschrieben wurden, zu Python oder Scala migrieren. Die Nutzer werden empfohlen, diese Informationen zu notieren und entsprechend zu planen.
Senden von Batchaufträgen mithilfe der Spark-Auftragsdefinition
Besuchen Sie das Lernprogramm, um zu erfahren, wie Sie Azure Synapse Analytics zum Erstellen von Apache Spark-Auftragsdefinitionen für Synapse Spark-Pools verwenden. Wenn Sie Ihre App nicht gepackt haben, um sie an Azure Synapse zu übermitteln, führen Sie die folgenden Schritte aus.
Konfigurieren Sie Ihre
dotnetAnwendungsabhängigkeiten für die Kompatibilität mit Synapse Spark. Die erforderliche .NET Spark-Version wird in der Synapse Studio-Schnittstelle unter Ihrer Apache Spark Pool-Konfiguration unter der Toolbox "Verwalten" aufgeführt.
Erstellen Sie Ihr Projekt als .NET-Konsolenanwendung, die eine ausführbare Ubuntu x86-Datei ausgibt.
<Project Sdk="Microsoft.NET.Sdk"> <PropertyGroup> <OutputType>Exe</OutputType> <TargetFramework>netcoreapp3.1</TargetFramework> </PropertyGroup> <ItemGroup> <PackageReference Include="Microsoft.Spark" Version="2.1.0" /> </ItemGroup> </Project>Führen Sie die folgenden Befehle aus, um Ihre App zu veröffentlichen. Ersetzen Sie "mySparkApp" unbedingt durch den Pfad zu Ihrer App.
cd mySparkApp dotnet publish -c Release -f netcoreapp3.1 -r ubuntu.18.04-x64Komprimieren Sie den Inhalt des Veröffentlichungsordners,
publish.zip, z. B., der als Ergebnis von Schritt 1 erstellt wurde. Alle Assemblys sollten sich im Stammverzeichnis der ZIP-Datei befinden, und es sollte keine Zwischenordnerebene vorhanden sein. Das bedeutet, dass beim Entpacken vonpublish.zipalle Assemblys in Ihr aktuelles Arbeitsverzeichnis extrahiert werden.Unter Windows:
Erstellen Sie mit Windows PowerShell oder PowerShell 7 eine .zip aus dem Inhalt Ihres Veröffentlichungsverzeichnisses.
Compress-Archive publish/* publish.zip -UpdateIn Linux:
Öffnen Sie eine Bash-Shell, wechseln Sie in das bin-Verzeichnis mit allen veröffentlichten Binärdateien und führen Sie den folgenden Befehl aus.
zip -r publish.zip
.NET für Apache Spark in Azure Synapse Analytics-Notizbüchern
Notizbücher eignen sich hervorragend für das Prototyping Ihrer .NET für Apache Spark-Pipelines und -Szenarien. Sie können mit dem Arbeiten, Verstehen, Filtern, Anzeigen und Visualisieren Ihrer Daten schnell und effizient beginnen.
Data Engineers, Data Scientists, Business Analysts und Machine Learning Engineers sind alle in der Lage, über ein freigegebenes, interaktives Dokument zusammenzuarbeiten. Sie sehen sofortige Ergebnisse aus der Datensuche und können Ihre Daten im selben Notizbuch visualisieren.
Verwenden von .NET für Apache Spark-Notizbücher
Wenn Sie ein neues Notizbuch erstellen, wählen Sie einen Sprachkernkern aus, den Sie ihre Geschäftslogik ausdrücken möchten. Kernelunterstützung ist für mehrere Sprachen verfügbar, einschließlich C#.
Wenn Sie .NET für Apache Spark in Ihrem Azure Synapse Analytics-Notizbuch verwenden möchten, wählen Sie .NET Spark (C#) als Kernel aus, und fügen Sie das Notizbuch an einen vorhandenen serverlosen Apache Spark-Pool an.
Das .NET Spark-Notizbuch basiert auf den interaktiven .NET-Oberflächen und bietet interaktive C#-Erfahrungen mit der Möglichkeit, .NET für Spark aus dem Feld heraus mit der Spark-Sitzungsvariable spark zu verwenden, die bereits vordefinierte ist.
Installieren von NuGet-Paketen in Notizbüchern
Sie können NuGet-Pakete Ihrer Wahl in Ihrem Notizbuch installieren, indem Sie den #r nuget magischen Befehl vor dem Namen des NuGet-Pakets verwenden. Das folgende Diagramm zeigt ein Beispiel:
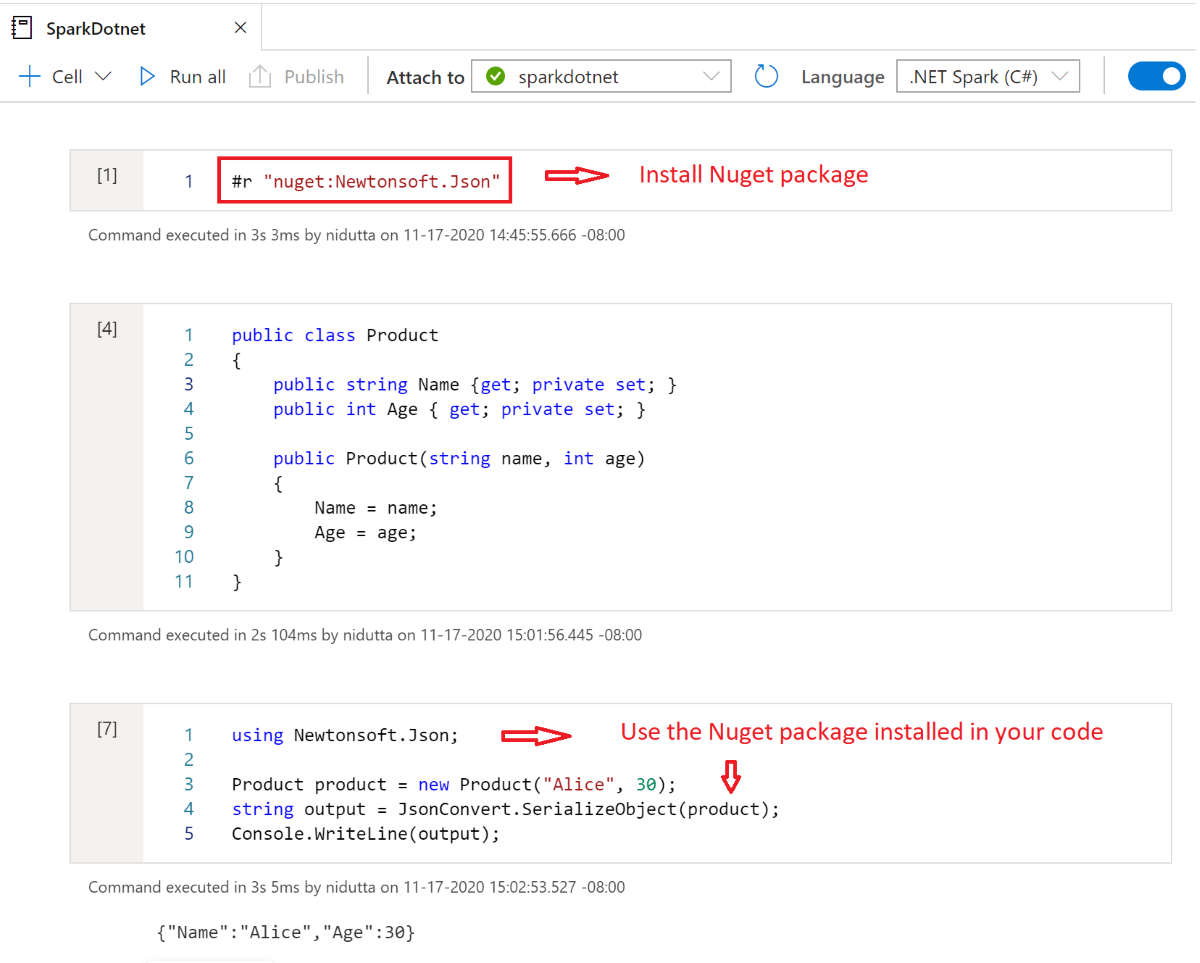
Weitere Informationen zum Arbeiten mit NuGet-Paketen in Notizbüchern finden Sie in der interaktiven .NET-Dokumentation.
.NET für Apache Spark C#-Kernel-Funktionen
Die folgenden Features sind verfügbar, wenn Sie .NET für Apache Spark im Azure Synapse Analytics-Notizbuch verwenden:
- Deklaratives HTML: Generieren Sie die Ausgabe aus Ihren Zellen mithilfe von HTML-Syntax, z. B. Kopfzeilen, Aufzählungen und sogar Anzeigen von Bildern.
- Einfache C#-Anweisungen (z. B. Zuweisungen, Drucken in Konsole, Auslösen von Ausnahmen usw.).
- Mehrzeilige C#-Codeblöcke (zum Beispiel if-Anweisungen, foreach-Schleifen, Klassendefinitionen usw.).
- Zugriff auf die C#-Standardbibliothek (z. B. System, LINQ, Enumerables usw.).
- Unterstützung für C# 8.0-Sprachfeatures.
-
sparkals vordefinierte Variable, um Ihnen Zugriff auf Ihre Apache Spark-Sitzung zu gewähren. - Unterstützung für das Definieren von benutzerdefinierten .NET-Funktionen, die in Apache Spark ausgeführt werden können. Es wird empfohlen , UDFs in .NET für Apache Spark Interactive-Umgebungen zu schreiben und aufzurufen , um zu erfahren, wie UDFs in .NET für Apache Spark Interactive-Erfahrungen verwendet werden.
- Unterstützung für die Visualisierung der Ausgabe von Spark-Aufträgen mithilfe verschiedener Diagramme (z. B. Linie, Balken oder Histogramm) und Layouts (z. B. einzeln, überlagert usw.) mithilfe der
XPlot.Plotly-Bibliothek. - Möglichkeit zum Einschließen von NuGet-Paketen in Ihr C#-Notizbuch.
Problembehandlung
OutOfMemoryError: java heap space at org.apache.spark
Dotnet Spark 1.0.0 verwendet eine andere Debugarchitektur als 1.1.1+. Sie müssen 1.0.0 für Ihre veröffentlichte Version und 1.1.1+ für das lokale Debuggen verwenden.