Verwenden externer Tabellen mit Synapse SQL
Eine externe Tabelle verweist auf Daten in Hadoop, Azure Storage Blob oder Azure Data Lake Store. Sie können externe Tabellen verwenden, um Daten aus Dateien zu lesen oder Daten in Dateien in Azure Storage zu schreiben.
Mit Synapse SQL können Sie externe Tabellen verwenden, um externe Daten unter Verwendung eines dedizierten oder serverlosen SQL-Pools zu lesen.
Je nach Art der externen Datenquelle können zwei Arten von externen Tabellen verwendet werden:
- Externe Hadoop-Tabellen zum Lesen und Exportieren von Daten in verschiedenen Datenformaten wie CSV, Parquet und ORC. Die in dedizierten SQL-Pools verfügbaren externen Hadoop-Tabellen sind in serverlosen SQL-Pools nicht verfügbar.
- Native externe Tabellen zum Lesen und Exportieren von Daten in verschiedenen Datenformaten wie CSV und Parquet. Native externe Tabellen sind in serverlosen SQL-Pools verfügbar und befinden sich in dedizierten SQL-Pools in der öffentlichen Vorschauphase. Das Schreiben/Exportieren von Daten mithilfe von CETAS und den nativen externen Tabellen ist nur im serverlosen SQL-Pool verfügbar, nicht in den dedizierten SQL-Pools.
Die wichtigsten Unterschiede zwischen externen Hadoop-Tabellen und nativen externen Tabellen:
| Art der externen Tabelle | Hadoop | Systemeigenes Format |
|---|---|---|
| Dedizierter SQL-Pool | Verfügbar | Nur Parquet-Tabellen sind als öffentliche Vorschau verfügbar. |
| Serverloser SQL-Pool | Nicht verfügbar | Verfügbar |
| Unterstützte Formate | Trennzeichen/CSV, Parquet, ORC, Hive RC und RC | Serverloser SQL-Pool: Trennzeichen/CSV, Parquet und Delta Lake Dedizierte SQL-Pool: Parquet (Vorschau) |
| Ordnerpartitionsentfernung | Nein | Das Entfernen von Partitionen ist nur in partitionierten Tabellen verfügbar, die im Parquet- oder CSV-Format erstellt und von Apache Spark-Pools synchronisiert werden. Sie können zwar externe Tabellen für mit Parquet partitionierte Ordner erstellen, aber die Partitionierungsspalten sind dann nicht zugänglich und werden ignoriert, während die Partitionsentfernung nicht angewendet wird. Erstellen Sie keine externen Tabellen in Delta Lake-Ordnern, da sie nicht unterstützt werden. Verwenden Sie Delta-partitionierte Sichten, wenn Sie partitionierte Delta Lake-Daten abfragen müssen. |
| Dateibeendung (Prädikat-Pushdown) | No | Ja im serverlosen SQL-Pool. Für den Zeichenfolgen-Pushdown muss die Sortierung Latin1_General_100_BIN2_UTF8 für die VARCHAR-Spalten verwendet werden, um den Pushdown zu aktivieren. Weitere Informationen zu Sortierungen finden Sie unter Sortierungstypen, die für Synapse SQL unterstützt werden. |
| Benutzerdefiniertes Format für Speicherort | Nein | Ja, mithilfe von Platzhaltern wie /year=*/month=*/day=* für Parquet- oder CSV-Formate. Benutzerdefinierte Ordnerpfade sind in Delta Lake nicht verfügbar. Im serverlosen SQL-Pool können Sie auch rekursive /logs/**-Platzhalter verwenden, um auf Parquet- oder CSV-Dateien in einem beliebigen Unterordner unterhalb des referenzierten Ordners zu verweisen. |
| Rekursive Ordnerüberprüfung | Ja | Ja. In serverlosen SQL-Pools muss /** am Ende des Pfads zum Speicherort angegeben werden. Im dedizierten Pool werden die Ordner immer rekursiv überprüft. |
| Speicherauthentifizierung | Speicherzugriffsschlüssel (Storage Access Key, SAK), Microsoft Entra-Passthrough, verwaltete Identität, benutzerdefinierte Microsoft Entra-Anwendungsidentität | Shared Access Signature(SAS), Microsoft Entra Passthrough, Verwaltete Identität, Benutzerdefinierte Anwendung Microsoft Entra Identity. |
| Spaltenzuordnung | Ordinal: Die Spalten in der Definition der externen Tabelle werden den Spalten in den zugrunde liegenden Parquet-Dateien nach Position zugeordnet. | Serverloser Pool: nach Name. Die Spalten in der Definition der externen Tabelle werden den Spalten in den zugrunde liegenden Parquet-Dateien nach Spaltennamenabgleich zugeordnet. Dedizierter Pool: Ordinalabgleich. Die Spalten in der Definition der externen Tabelle werden den Spalten in den zugrunde liegenden Parquet-Dateien nach Position zugeordnet. |
| CETAS (Export/Transformation) | Ja | CETAS mit den nativen Tabellen als Ziel funktioniert nur im serverlosen SQL-Pool. Sie können keine dedizierten SQL-Pools verwenden, um Daten mithilfe nativer Tabellen zu exportieren. |
Hinweis
Die nativen externen Tabellen sind die empfohlene Lösung in den Pools, in denen sie allgemein verfügbar sind. Wenn Sie auf externe Daten zugreifen müssen, verwenden Sie immer die nativen Tabellen in serverlosen Pools. In dedizierten Pools sollten Sie zu den nativen Tabellen wechseln, um Parquet-Dateien zu lesen, sobald sie allgemein verfügbar sind. Verwenden Sie die Hadoop-Tabellen nur, wenn Sie auf einige Typen zugreifen müssen, die in nativen externen Tabellen nicht unterstützt werden (z. B. ORC, RC), oder wenn die native Version nicht verfügbar ist.
Externe Tabellen im dedizierten SQL-Pool und serverlosen SQL-Pool
Externe Tabellen können für Folgendes verwendet werden:
- Abfragen von Azure Blob Storage und Azure Data Lake Gen2 mit Transact-SQL-Anweisungen
- Speichern von Abfrageergebnissen in Dateien in Azure Blob Storage oder Azure Data Lake Storage mithilfe von CETAS
- Importieren von Daten aus Azure Blob Storage und Azure Data Lake Storage und Speichern der Daten in einem dedizierten SQL-Pool (nur Hadoop-Tabellen in einem dedizierten Pool)
Hinweis
In Verbindung mit der Anweisung CREATE TABLE AS SELECT werden in einer externen Tabelle ausgewählte Daten in eine Tabelle innerhalb des dedizierten SQL-Pools importiert.
Wenn die Leistung externer Hadoop-Tabellen in den dedizierten Pools Ihre Leistungsziele nicht erfüllt, sollten Sie erwägen, externe Daten mithilfe der COPY-Anweisung in die Datawarehouse-Tabellen zu laden.
Ein Tutorial zum Laden finden Sie unter Verwenden von PolyBase zum Laden von Daten aus Azure Blob Storage.
Externe Tabellen können mithilfe der folgenden Schritte in Synapse SQL-Pools erstellt werden:
- Verwenden Sie CREATE EXTERNAL DATA SOURCE, um auf einen externen Azure-Speicher zu verweisen, und geben Sie die Anmeldeinformationen für den Zugriff auf den Speicher an.
- Beschreiben Sie das Format von CSV- oder Parquet-Dateien mithilfe von CREATE EXTERNAL FILE FORMAT.
- Verwenden Sie CREATE EXTERNAL TABLE für die Dateien in der Datenquelle mit demselben Dateiformat.
Ordnerpartitionsentfernung
Die nativen externen Tabellen in Synapse-Pools können die Dateien ignorieren, die in den Ordnern platziert werden und nicht für die Abfragen relevant sind. Wenn Ihre Dateien in einer Ordnerhierarchie gespeichert sind (z. B. /year=2020/month=03/day=16), und die Werte für year,month und day als Spalten zur Verfügung gestellt werden, lesen die Abfragen, die Filter wie year=2020 enthalten, die Dateien nur aus den Unterordnern, die im Ordner year=2020 platziert sind. Die Dateien und Ordner in anderen Ordnern (year=2021 oder year=2022) werden in dieser Abfrage ignoriert. Diese Entfernung wird als Partitionsentfernung bezeichnet.
Die Entfernung der Ordnerpartition ist in den nativen externen Tabellen verfügbar, die aus den Synapse Spark-Pools synchronisiert werden. Wenn Sie über ein partitioniertes Dataset verfügen und die Partitionsentfernung mit den erstellten externen Tabellen nutzen möchten, verwenden Sie die partitionierten Ansichten anstelle der externen Tabellen.
Entfernen von Dateien
Einige Datenformate wie Parquet und Delta enthalten Dateistatistiken für jede Spalte (z. B. Minimal-/Maximalwerte für jede Spalte). Bei Abfragen, bei denen Daten gefiltert werden, werden Dateien nicht gelesen, in denen die erforderlichen Spaltenwerte nicht vorhanden sind. Die Abfrage untersucht zunächst die Minimal-/Maximalwerte für die Spalten, die im Abfrageprädikat verwendet werden, um die Dateien zu finden, die die erforderlichen Daten nicht enthalten. Diese Dateien werden ignoriert und aus dem Abfrageplan entfernt.
Diese Vorgehensweise wird auch als Filterprädikat-Pushdown bezeichnet und kann die Leistung Ihrer Abfragen verbessern. Filter-Pushdown ist in den serverlosen SQL-Pools im Parquet- und Delta-Format verfügbar. Um den Filterpushdown für die Zeichenfolgentypen zu nutzen, verwenden Sie den VARCHAR-Typ mit Latin1_General_100_BIN2_UTF8-Sortierung. Weitere Informationen zu Sortierungen finden Sie unter Sortierungstypen, die für Synapse SQL unterstützt werden.
Sicherheit
Der Benutzer muss über die Berechtigung SELECT für eine externe Tabelle verfügen, um die Daten lesen zu können.
Externe Tabellen greifen auf den zugrunde liegenden Azure-Speicher mithilfe der datenbankweit gültigen Anmeldeinformationen zu, die in der Datenquelle mit den folgenden Regeln definiert wurden:
- Eine Datenquelle ohne Anmeldeinformationen ermöglicht externen Tabellen den Zugriff auf öffentlich verfügbare Dateien im Azure-Speicher.
- Eine Datenquelle kann über Anmeldeinformationen verfügen, die externen Tabellen den Zugriff nur auf die Dateien im Azure-Speicher mithilfe des SAS-Tokens oder der verwalteten Identität für den Arbeitsbereich ermöglichen. Entsprechende Beispiele finden Sie im Artikel Develop storage files storage access control (Entwickeln der Speicherzugriffssteuerung für Speicherdateien).
Beispiel für „CREATE EXTERNAL DATA SOURCE“
Im folgenden Beispiel wird eine externe Hadoop-Datenquelle im dedizierten SQL-Pool für Azure Data Lake Gen2 erstellt, die auf das Dataset für New York verweist:
CREATE DATABASE SCOPED CREDENTIAL [ADLS_credential]
WITH IDENTITY='SHARED ACCESS SIGNATURE',
SECRET = 'sv=2018-03-28&ss=bf&srt=sco&sp=rl&st=2019-10-14T12%3A10%3A25Z&se=2061-12-31T12%3A10%3A00Z&sig=KlSU2ullCscyTS0An0nozEpo4tO5JAgGBvw%2FJX2lguw%3D'
GO
CREATE EXTERNAL DATA SOURCE AzureDataLakeStore
WITH
-- Please note the abfss endpoint when your account has secure transfer enabled
( LOCATION = 'abfss://data@newyorktaxidataset.dfs.core.windows.net' ,
CREDENTIAL = ADLS_credential ,
TYPE = HADOOP
) ;
Im folgenden Beispiel wird eine externe Datenquelle für Azure Data Lake Gen2 erstellt, die auf das öffentlich verfügbare Dataset für New York verweist:
CREATE EXTERNAL DATA SOURCE YellowTaxi
WITH ( LOCATION = 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/',
TYPE = HADOOP)
Beispiel für „CREATE EXTERNAL FILE FORMAT“
Im folgenden Beispiel wird ein externes Dateiformat für Zensusdateien erstellt:
CREATE EXTERNAL FILE FORMAT census_file_format
WITH
(
FORMAT_TYPE = PARQUET,
DATA_COMPRESSION = 'org.apache.hadoop.io.compress.SnappyCodec'
)
Beispiel für „CREATE EXTERNAL TABLE“
Im folgenden Beispiel wird eine externe Tabelle erstellt und die erste Zeile zurückgegeben:
CREATE EXTERNAL TABLE census_external_table
(
decennialTime varchar(20),
stateName varchar(100),
countyName varchar(100),
population int,
race varchar(50),
sex varchar(10),
minAge int,
maxAge int
)
WITH (
LOCATION = '/parquet/',
DATA_SOURCE = population_ds,
FILE_FORMAT = census_file_format
)
GO
SELECT TOP 1 * FROM census_external_table
Erstellen und Abfragen externer Tabellen auf der Grundlage einer Datei in Azure Data Lake
Mithilfe der Data Lake-Erkundungsfunktionen von Synapse Studio können Sie nun mit einem einfachen Rechtsklick auf die Datei eine externe Tabelle unter Verwendung eines Synapse SQL-Pools erstellen und abfragen. Die 1-Klick-Geste zum Erstellen externer Tabellen aus dem ADLS Gen2-Speicherkonto wird nur für Parquet-Dateien unterstützt.
Voraussetzungen
Für den Zugriff auf den Arbeitsbereich müssen Sie mindestens über die Zugriffsrolle
Storage Blob Data Contributorfür das ADLS Gen2-Konto verfügen. Alternativ werden Zugriffssteuerungslisten benötigt, mit denen Sie die Dateien abfragen können.Sie müssen mindestens über Berechtigungen zum Erstellen einer externen Tabelle und Abfragen externer Tabellen im Synapse SQL-Pool (dediziert oder serverlos) verfügen.
Wählen Sie im Datenbereich die Datei aus, auf deren Grundlage Sie die externe Tabelle erstellen möchten:
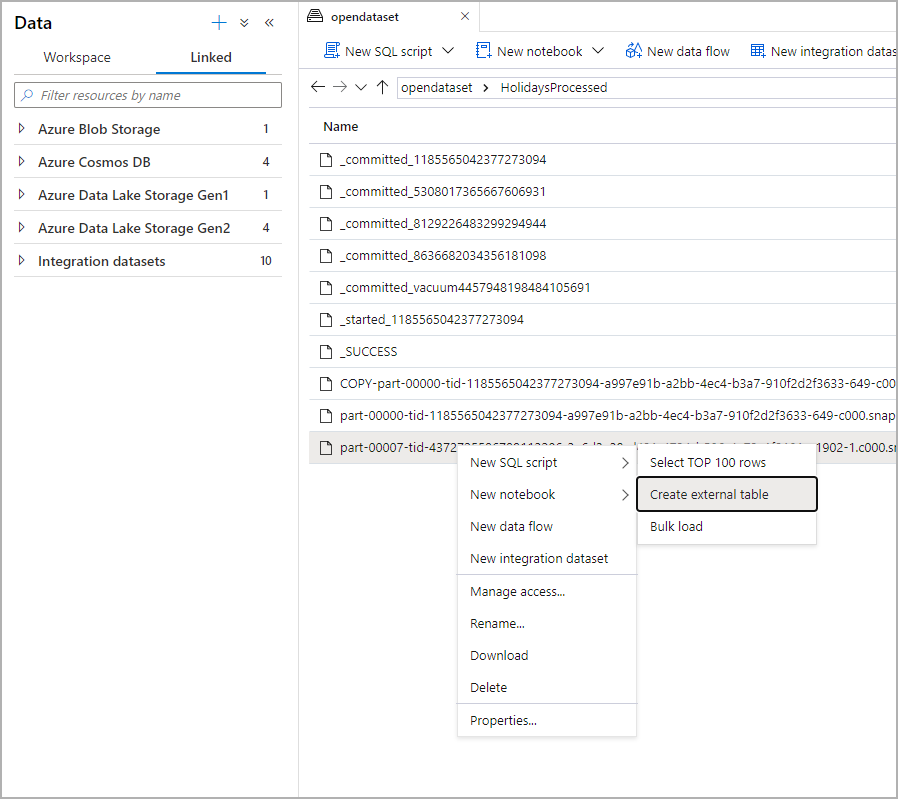
Daraufhin wird ein Dialogfenster geöffnet. Wählen Sie die Option für den dedizierten oder den serverlosen SQL-Pool aus, geben Sie einen Namen für die Tabelle ein, und wählen Sie „Skript öffnen“ aus:
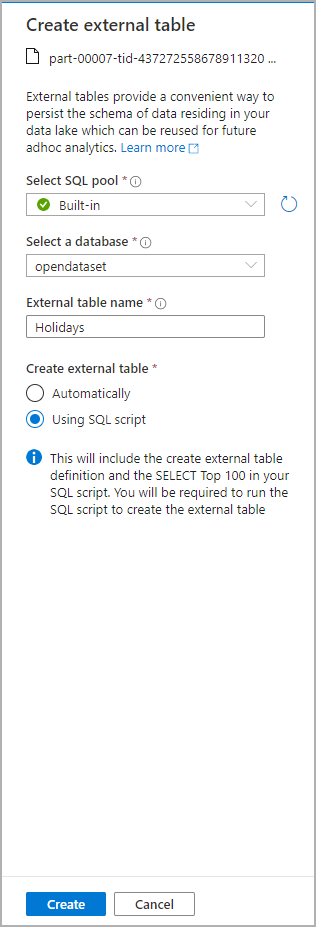
Das SQL-Skript wird automatisch generiert, und das Schema wird aus der Datei abgeleitet:
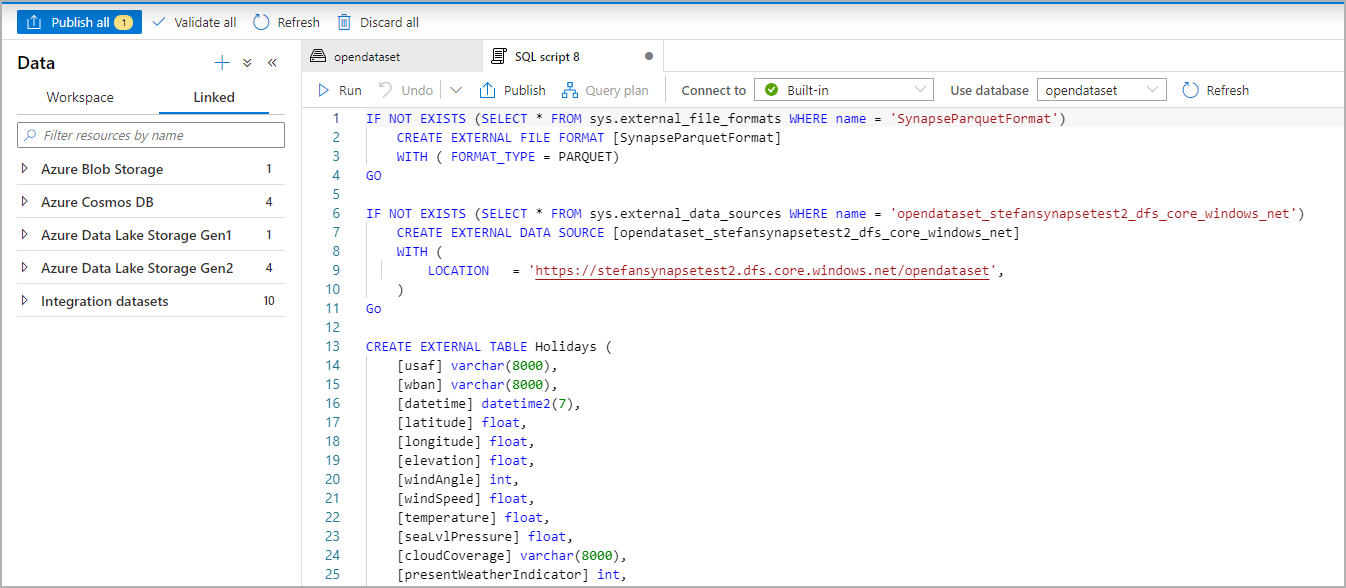
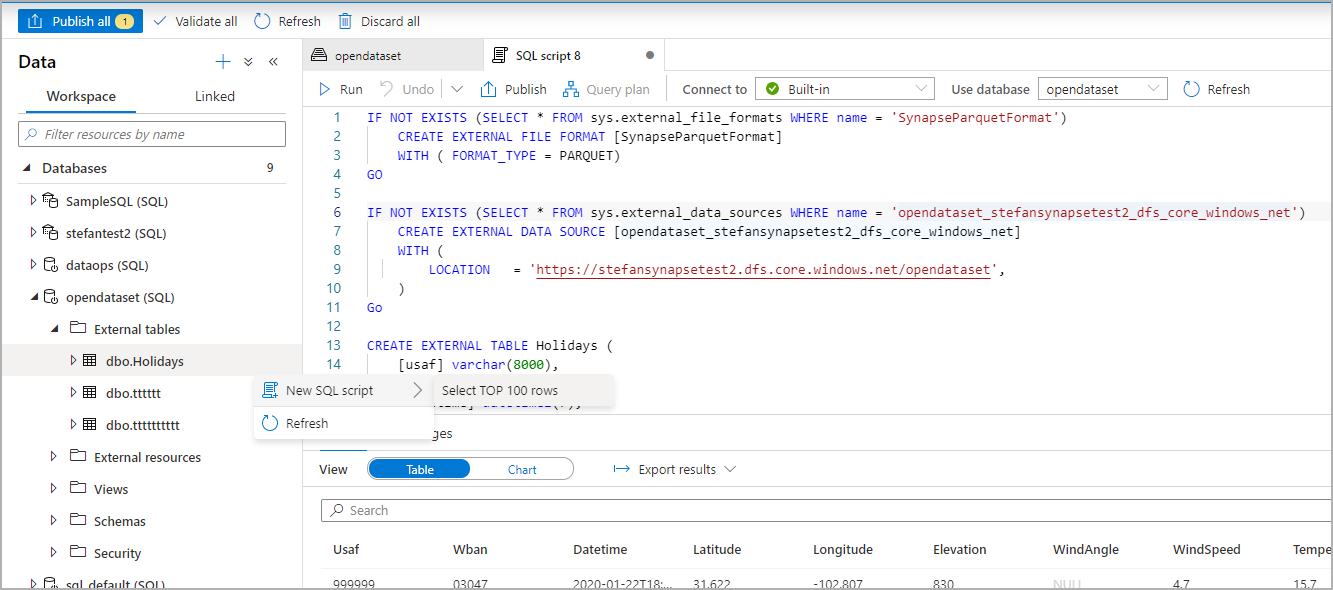
Führen Sie das Skript aus. Durch das Skript wird automatisch eine Abfrage vom Typ „Top 100 auswählen“ ausgeführt:
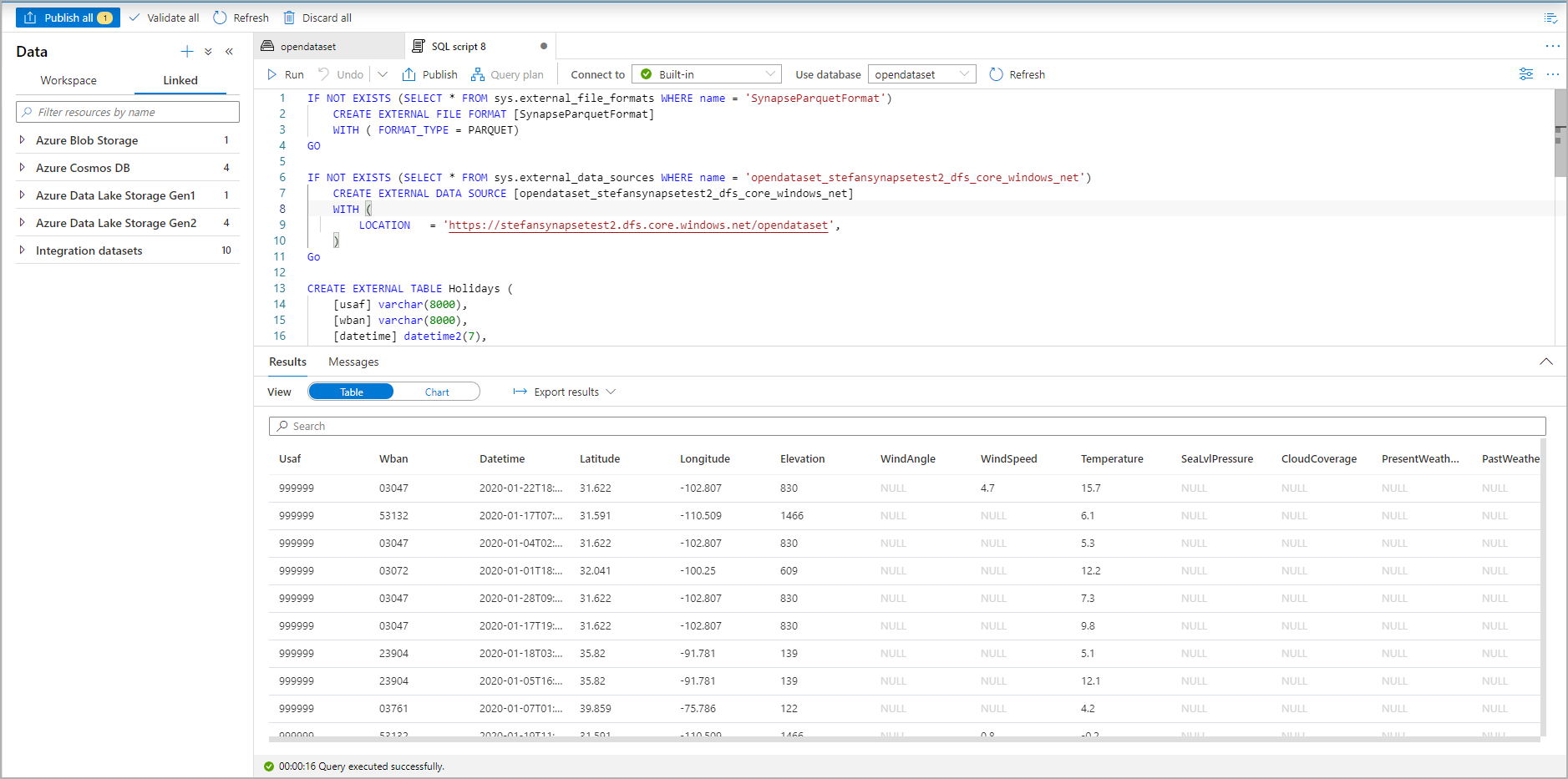
Die externe Tabelle ist nun erstellt. Zur späteren Erkundung ihres Inhalts kann der Benutzer sie direkt über den Datenbereich abfragen:
Nächste Schritte
Im Artikel zu CETAS erfahren Sie, wie Sie die Abfrageergebnisse in einer externen Tabelle in Azure Storage speichern. Oder Sie können damit beginnen, Apache Spark für externe Azure Synapse-Tabellen abzufragen.