Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Tip
Microsoft Fabric Data Warehouse ist ein relationales Enterprise-Warehouse auf einem Data Lake-Fundament mit zukunftsfähiger Architektur, integrierter KI und neuen Features. Wenn Sie mit Data Warehouse noch nicht vertraut sind, beginnen Sie mit Fabric Data Warehouse. Vorhandene dedizierte SQL-Pool-Workloads können auf Fabric aktualisieren, um neue Funktionen in den Bereichen Data Science, Echtzeitanalyse und Berichterstellung zu nutzen.
In diesem Artikel erfahren Sie, wie Sie eine Abfrage mithilfe eines serverlosen Synapse SQL-Pools schreiben, um Delta Lake-Dateien zu lesen. Delta Lake ist eine Open-Source-Speicherebene, die ACID-Transaktionen (Atomizität, Konsistenz, Isolation und Dauerhaftigkeit) in Apache Spark und Big Data-Workloads einführt. Weitere Informationen finden Sie im Video „Abfragen von Delta Lake-Tabellen“.
Wichtig
Die serverlosen SQL-Pools können Delta Lake Version 1.0 abfragen. Die Änderungen, die seit Delta Lake Version 1.2 eingeführt wurden (z. B. das Umbenennen von Spalten), werden in serverlosen Versionen nicht unterstützt. Wenn Sie die höheren Delta-Versionen mit Löschvektoren, v2-Prüfpunkten und anderen verwenden, sollten Sie die Verwendung einer anderen Abfrage-Engine wie Microsoft Fabric-SQL-Endpunkt für Lakehouses in Betracht ziehen.
Mit dem serverlosen SQL-Pool im Synapse-Arbeitsbereich können Sie die im Delta Lake-Format gespeicherten Daten lesen und für Berichterstellungstools bereitstellen. Ein serverloser SQL-Pool kann Delta Lake-Dateien lesen, die mit Apache Spark, Azure Databricks oder einem anderen Producer des Delta Lake-Formats erstellt werden.
Mit Apache Spark-Pools in Azure Synapse können technische Fachkräfte für Daten Delta Lake-Dateien mit Scala, PySpark und .NET ändern. Serverlose SQL-Pools unterstützen Datenanalysten beim Erstellen von Berichten zu Delta Lake-Dateien, die von technischen Fachkräften für Daten erstellt wurden.
Wichtig
Das Abfragen des Delta Lake-Formats mithilfe des serverlosen SQL-Pools ist eine allgemein verfügbare Funktion. Das Abfragen von Spark Delta-Tabellen befindet sich jedoch weiterhin in der öffentlichen Vorschauphase und ist noch nicht produktionsbereit. Es gibt bekannte Probleme, die auftreten können, wenn Sie Delta-Tabellen abfragen, die mit den Spark-Pools erstellt wurden. Sehen Sie sich die bekannten Probleme in der Selbsthilfe für serverlose SQL-Pools an.
Voraussetzungen
Wichtig
Datenquellen können nur in benutzerdefinierten Datenbanken erstellt werden (nicht in der Masterdatenbank oder in den Datenbanken, die aus Apache Spark-Pools repliziert werden).
Für die Beispiele in diesem Artikel müssen Sie die folgenden Schritte ausführen:
- Erstellen Sie eine Datenbank mit einer Datenquelle, die auf das Speicherkonto NYC Yellow Taxi verweist.
- Initialisieren Sie die Objekte, indem Sie das Setupskript für die Datenbank ausführen, die Sie in Schritt 1 erstellt haben. Mit diesem Setupskript werden die Datenquellen, die für die gesamte Datenbank gültigen Anmeldeinformationen und externe Dateiformate erstellt, die in diesen Beispielen verwendet werden.
Wenn Sie Ihre Datenbank erstellt und den Kontext auf Ihre Datenbank umgestellt haben (mithilfe einer USE database_name-Anweisung oder der Dropdownliste zum Auswählen der Datenbank in einem Abfrage-Editor), können Sie ihre externe Datenquelle, die den Stamm-URI zu Ihrem Dataset enthält, erstellen und zum Abfragen von Delta Lake-Dateien verwenden. Zum Beispiel:
CREATE EXTERNAL DATA SOURCE DeltaLakeStorage
WITH ( LOCATION = 'https://<yourstorageaccount>.blob.core.windows.net/delta-lake/' );
GO
SELECT TOP 10 *
FROM OPENROWSET(
BULK 'covid',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta'
) as rows;
Wenn eine Datenquelle mit einem SAS-Schlüssel oder einer benutzerdefinierten Identität geschützt ist, können Sie die Datenquelle mit datenbankweit gültigen Anmeldeinformationen konfigurieren.
Sie können eine externe Datenquelle mit einem Speicherort erstellen, der auf den Stammordner des Speichers verweist. Nachdem Sie die externe Datenquelle erstellt haben, verwenden Sie die Datenquelle und den relativen Pfad zu der Datei in der OPENROWSET-Funktion. Auf diese Weise müssen Sie nicht den vollständigen absoluten URI zu Ihren Dateien verwenden. Sie können dann auch benutzerdefinierte Anmeldeinformationen für den Zugriff auf den Speicherort definieren.
Delta Lake-Ordner lesen
Wichtig
Verwenden Sie das Setupskript in den Voraussetzungen, um die Beispieldatenquellen und -tabellen einzurichten.
Mit der Funktion OPENROWSET können Sie die Inhalte von Delta Lake-Dateien lesen, indem Sie die URL zu Ihrem Stammordner angeben.
Die einfachste Möglichkeit zum Anzeigen des Inhalts Ihrer DELTA-Datei besteht darin, die Datei-URL zu der OPENROWSET-Funktion bereitzustellen und das DELTA-Format anzugeben. Wenn die Datei öffentlich verfügbar ist oder Ihre Microsoft Entra-Identität auf diese Datei zugreifen kann, sollten Sie den Inhalt der Datei mithilfe einer Abfrage wie im folgenden Beispiel anzeigen können:
SELECT TOP 10 *
FROM OPENROWSET(
BULK '/covid/',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta') as rows;
Spaltennamen und Datentypen werden automatisch aus Data Lake-Dateien gelesen. Die OPENROWSET-Funktion verwendet Typen nach bester Schätzung wie VARCHAR(1000) für die Zeichenfolgenspalten.
Der URI in der OPENROWSET-Funktion muss auf den Delta Lake-Stammordner verweisen, der einen Unterordner namens _delta_log enthält.
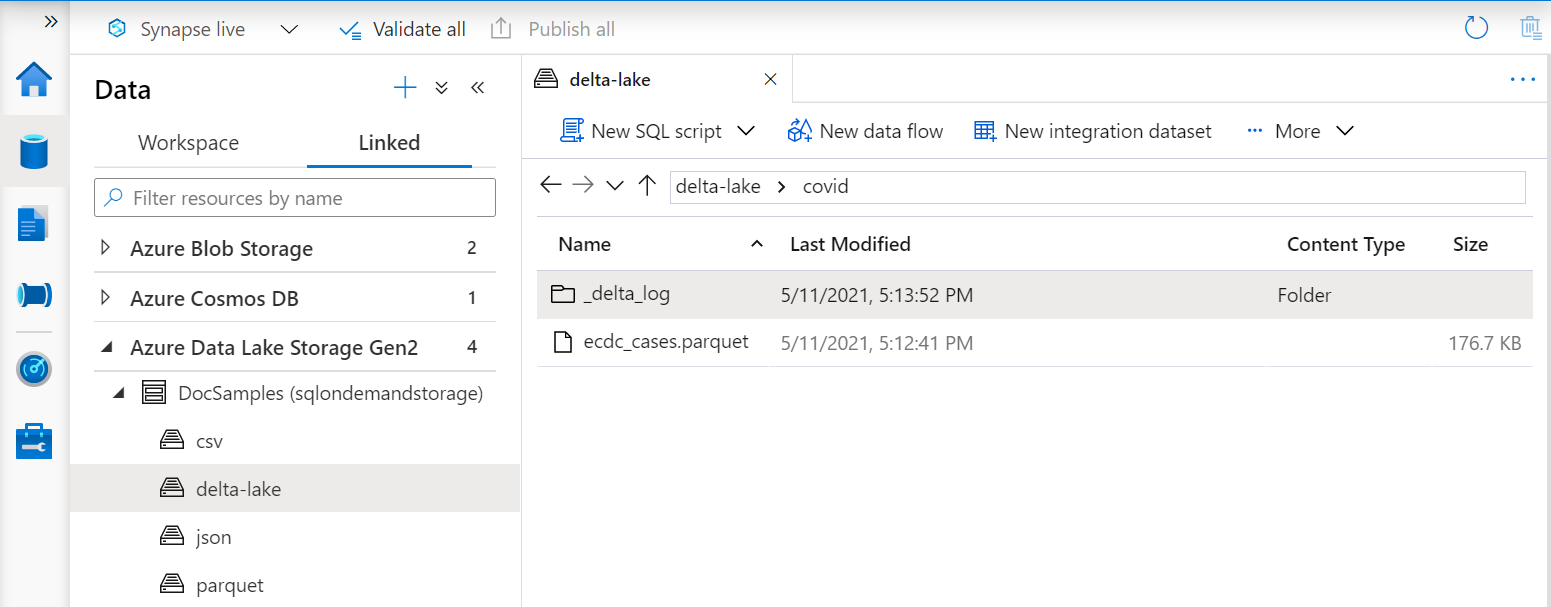
Wenn Sie nicht über diesen Unterordner verfügen, verwenden Sie nicht das Delta Lake-Format. Sie können Ihre einfachen Parquet-Dateien im Ordner mithilfe eines Skripts wie dem folgenden Apache Spark-Python-Beispielskript in das Delta Lake-Format konvertieren:
%%pyspark
from delta.tables import DeltaTable
deltaTable = DeltaTable.convertToDelta(spark, "parquet.`abfss://delta-lake@sqlondemandstorage.dfs.core.windows.net/covid`")
Um die Leistung Ihrer Abfragen zu verbessern, sollten Sie explizite Typen in der WITH-Klausel angeben.
Hinweis
Der serverlose Synapse SQL-Pool verwendet Schemarückschlüsse, um Spalten und deren Typen automatisch zu bestimmen. Die Regeln für die Schema-Inferenz sind dieselben wie für Parquet-Dateien. Informationen zur Delta Lake-Typzuordnung zum nativen SQL-Typ finden Sie unter Typzuordnung für Parquet.
Stellen Sie sicher, dass Sie auf Ihre Datei zugreifen können. Wenn Ihre Datei mit einem SAS-Schlüssel oder einer benutzerdefinierten Azure-Identität geschützt ist, müssen Sie Anmeldeinformationen auf Serverebene für die SQL-Anmeldung einrichten.
Wichtig
Achten Sie darauf, eine UTF-8-Datenbanksortierung (z. B. Latin1_General_100_BIN2_UTF8) zu verwenden, da Zeichenfolgenwerte in Delta Lake-Dateien mit UTF-8 codiert sind.
Ein Konflikt zwischen der Textcodierung in der Delta Lake-Datei und der Sortierung kann zu unerwarteten Konvertierungsfehlern führen.
Die Standardsortierung der aktuellen Datenbank kann mit der folgenden T-SQL-Anweisung problemlos geändert werden: .
ALTER DATABASE CURRENT COLLATE Latin1_General_100_BIN2_UTF8; Weitere Informationen zu Sortierungen finden Sie unter Sortierungstypen, die für Synapse SQL unterstützt werden.
Explizites Angeben des Schemas
Bei OPENROWSET können Sie mit der WITH-Klausel explizit angeben, welche Spalten aus der Datei gelesen werden sollen:
SELECT TOP 10 *
FROM OPENROWSET(
BULK 'covid',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta'
)
WITH ( date_rep date,
cases int,
geo_id varchar(6)
) as rows;
Mit der expliziten Angabe des Resultsetschemas können Sie die Typgrößen minimieren und die präziseren Typen VARCHAR(6) für Zeichenfolgenspalten anstelle von pessimistischem VARCHAR(1000) verwenden. Die Minimierung von Typen kann die Leistung Ihrer Abfragen erheblich verbessern.
Wichtig
Stellen Sie sicher, dass Sie explizit eine UTF-8-Sortierung (z. B. Latin1_General_100_BIN2_UTF8) für alle Zeichenfolgenspalten in der WITH-Klausel angeben, oder legen Sie eine UTF-8-Sortierung auf Datenbankebene fest.
Ein Konflikt zwischen der Textcodierung in der Datei und der Sortierung der Zeichenfolgenspalte kann zu unerwarteten Konvertierungsfehlern führen.
Die Standardsortierung der aktuellen Datenbank kann mithilfe der folgenden T-SQL-Anweisung problemlos geändert werden:
alter database current collate Latin1_General_100_BIN2_UTF8Sie können die Sortierung der Spaltentypen problemlos mit der folgenden Definition festlegen: geo_id varchar(6) collate Latin1_General_100_BIN2_UTF8
Datensatz
In diesem Beispiel wird das Dataset NYC Yellow Taxi verwendet. Der ursprüngliche PARQUET-Datensatz wird in das DELTA-Format konvertiert, und die DELTA-Version wird in den Beispielen verwendet.
Abfragen von partitionierten Daten
Der in diesem Beispiel bereitgestellte Datensatz ist in separate Unterordner aufgeteilt (partitioniert).
Im Gegensatz zu Parquet müssen Sie keine bestimmten Partitionen mithilfe der FILEPATH-Funktion als Ziel verwenden.
OPENROWSET identifiziert Partitionierungsspalten in Ihrer Delta Lake-Ordnerstruktur und ermöglicht ihnen das direkte Abfragen von Daten mithilfe dieser Spalten. Dieses Beispiel zeigt die Fahrpreisbeträge nach Jahr, Monat und Zahlungsart für die ersten drei Monate des Jahres 2017.
SELECT
YEAR(pickup_datetime) AS year,
passenger_count,
COUNT(*) AS cnt
FROM
OPENROWSET(
BULK 'yellow',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT='DELTA'
) nyc
WHERE
nyc.year = 2017
AND nyc.month IN (1, 2, 3)
AND pickup_datetime BETWEEN CAST('1/1/2017' AS datetime) AND CAST('3/31/2017' AS datetime)
GROUP BY
passenger_count,
YEAR(pickup_datetime)
ORDER BY
YEAR(pickup_datetime),
passenger_count;
Die OPENROWSET-Funktion entfernt Partitionen, die nicht mit year und month in der where-Klausel übereinstimmen. Diese Datei-/Partitionsbereinigungsmethode verringert Ihr Dataset erheblich, verbessert die Leistung und reduziert die Kosten der Abfrage.
Der Ordnername in der OPENROWSET-Funktion (yellow in diesem Beispiel), wird mithilfe von LOCATION in der DeltaLakeStorage-Datenquelle verkettet und muss auf den Delta Lake-Stammordner verweisen, der einen Unterordner namens _delta_log enthält.
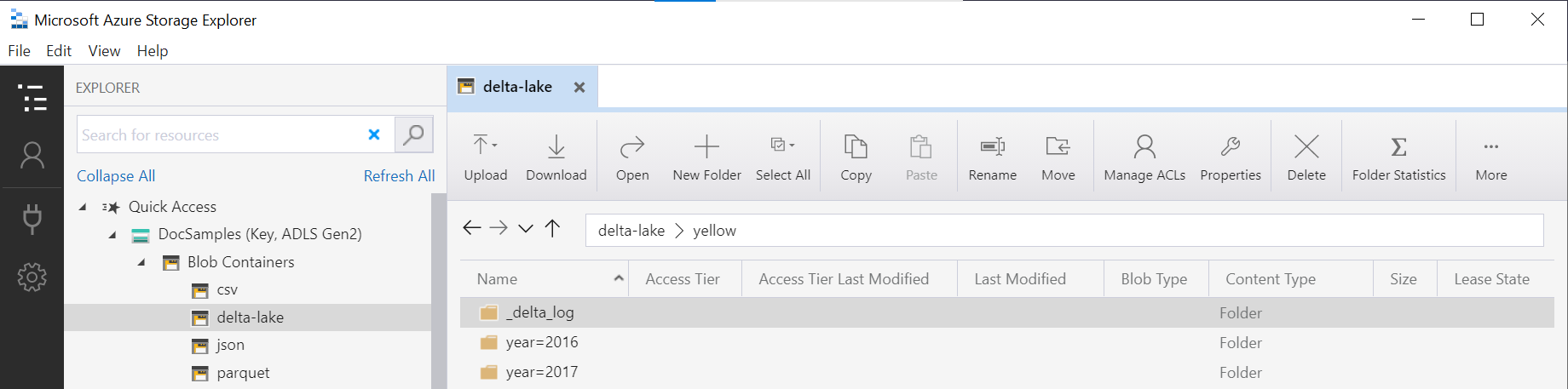
Wenn Sie nicht über diesen Unterordner verfügen, verwenden Sie nicht das Delta Lake-Format. Sie können Ihre einfachen Parquet-Dateien im Ordner mithilfe des folgenden Apache Spark Python-Skripts in das Delta Lake-Format konvertieren:
%%pyspark
from delta.tables import DeltaTable
deltaTable = DeltaTable.convertToDelta(spark, "parquet.`abfss://delta-lake@sqlondemandstorage.dfs.core.windows.net/yellow`", "year INT, month INT")
Das zweite Argument der DeltaTable.convertToDeltaLake Funktion stellt die Partitionierungsspalten (Jahr und Monat) dar, die Teil des Ordnermusters sind (year=*/month=* in diesem Beispiel), und deren Typen.
Einschränkungen
- Überprüfen Sie die Einschränkungen und bekannten Probleme auf der Selbsthilfeseite bei Problemen mit serverlosen Synapse-SQL-Pools.
Zugehöriger Inhalt
Lesen Sie den nächsten Artikel, um zu lernen, wie man geschachtelte Parquet-Typen abfragt. Wenn Sie die Erstellung der Delta Lake-Lösung fortsetzen möchten, lesen Sie nach, wie Sie Sichten oder externe Tabellen im Delta Lake-Ordner erstellen.