Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Dokument werden verschiedene wichtige Themen für die Bereitstellung von SQL Server für SAP-Workloads in Azure IaaS behandelt. Lesen Sie im Vorfeld das Dokument Azure Virtual Machines: DBMS-Bereitstellung für SAP-Workloads und andere Artikel der Azure-Dokumentation für SAP-Workloads.
Wichtig
Dieser Artikel gilt für die Windows-Version von SQL Server. SAP unterstützt die Linux-Version von SQL Server mit keiner SAP-Software. Im Artikel wird nicht auf die Microsoft Azure SQL-Datenbank eingegangen. Dabei handelt es sich um ein PaaS-Angebot (Platform-as-a-Service) der Microsoft Azure-Plattform. In diesem Dokument geht es um das Ausführen des bekannten SQL Server-Produkts für lokale Bereitstellungen auf virtuellen Azure-Computern, wobei die IaaS-Funktion (Infrastructure as a Service) von Azure genutzt wird. Die Datenbankfunktionen und -features für diese beiden Angebote unterscheiden sich und dürfen nicht verwechselt werden. Weitere Informationen finden Sie unter Azure SQL-Datenbank.
Generell wird empfohlen, die neuesten SQL Server-Releases zu verwenden, um SAP-Workloads in Azure-IaaS auszuführen. Die neuesten SQL Server-Releases bieten eine bessere Integration mit einigen Azure-Diensten und -Funktionen. Außerdem umfassen sie Änderungen, die Abläufe in einer Azure-IaaS-Infrastruktur optimieren.
Eine allgemeine Dokumentation zu SQL Server-Instanzen, die auf Azure-VMs ausgeführt werden, finden Sie in den folgenden Artikeln:
- SQL Server in Azure Virtual Machines (Windows)
- Automatisieren der Verwaltung mit der Windows SQL Server IaaS-Agent-Erweiterung
- Konfigurieren der Azure Key Vault-Integration für SQL Server auf Azure-VMs (Resource Manager)
- Prüfliste: Bewährte Methoden für SQL Server auf Azure-VMs
- Speicher: Bewährte Methoden zur Leistung von SQL Server auf Azure-VMs
- Bewährte Methoden der HADR-Konfiguration (SQL Server auf Azure-VMs)
Nicht alle Inhalte und Anweisungen in der allgemeinen Dokumentation zu SQL Server auf Azure-VMs gelten für SAP-Workloads. Die Dokumentation vermittelt jedoch einen guten Eindruck von den Prinzipien. Ein Beispiel für Funktionen, die für SAP-Workloads nicht unterstützt werden, ist die Verwendung von FCI-Clustering.
Einige spezifische Informationen zu SQL Server in IaaS sollten Sie vor dem Fortfahren kennen:
- Unterstützung für SQL-Versionen: Auch wenn SAP-Hinweis 1928533 besagt, dass das mindestens unterstützte SQL Server-Release SQL Server 2008 R2 ist, wird das Fenster der unterstützten SQL Server-Versionen in Azure auch vom Lebenszyklus mit SQL Server vorgegeben. Die erweiterte Wartung von SQL Server 2012 wurde Mitte 2022 beendet. Daher sollte das aktuelle Mindestrelease für neu bereitgestellte Systeme SQL Server 2014 sein. Je aktueller, desto besser. Die neuesten SQL Server-Releases bieten eine bessere Integration mit einigen Azure-Diensten und -Funktionen. Außerdem umfassen sie Änderungen, die Abläufe in einer Azure-IaaS-Infrastruktur optimieren.
- Verwenden von Images aus dem Azure Marketplace: Die schnellste Möglichkeit zum Bereitstellen einer neuen Microsoft Azure-VM besteht darin, ein Image aus dem Azure Marketplace zu verwenden. Einige Images im Azure Marketplace enthalten die neuesten SQL Server-Releases. Die Images, bei denen SQL Server bereits installiert ist, können nicht sofort für SAP NetWeaver-Anwendungen verwendet werden. Dies liegt daran, dass innerhalb dieser Images die standardmäßige SQL Server-Sortierung und nicht die für SAP NetWeaver-Systeme erforderliche Sortierung installiert ist. Um solche Images zu verwenden, lesen Sie sich die Schritte im Kapitel Verwenden eines SQL Server-Images aus dem Microsoft Azure Marketplace durch.
- Unterstützung mehrerer SQL Server-Instanzen auf einer einzelnen Azure-VM: Diese Bereitstellungsmethode wird unterstützt. Beachten Sie jedoch die Ressourceneinschränkungen, insbesondere im Hinblick auf die Netzwerk- und Speicherbandbreite des verwendeten VM-Typs. Ausführliche Informationen finden Sie im Artikel Größen für VMs in Azure. Aufgrund dieser Kontingenteinschränkungen können Sie möglicherweise nicht die gleiche Architektur mit mehreren Instanzen implementieren, die Sie lokal implementieren können. Im Hinblick auf die Konfiguration und Einschränkungen der gemeinsamen Nutzung der auf einer einzelnen VM verfügbaren Ressourcen müssen die gleichen Aspekte wie bei der lokalen Bereitstellung berücksichtigt werden.
- Mehrere SAP-Datenbanken in einer einzelnen SQL Server-Instanz auf einer einzelnen VM: Konfigurationen wie diese werden unterstützt. Für mehrere SAP-Datenbanken, die die freigegebenen Ressourcen einer einzelnen SQL Server-Instanz gemeinsam nutzen, müssen die gleichen Aspekte wie bei lokalen Bereitstellungen berücksichtigt werden. Beachten Sie auch andere Grenzwerte, z. B. die Anzahl von Datenträgern, die an einen bestimmten VM-Typ angefügt werden können, sowie die Netzwerk- und Speicherkontingentgrenzen bestimmter VM-Typen, die unter Größen für VMs in Azure ausführlich beschrieben sind.
Neue VMs der M-Serie und SQL Server
Azure veröffentlichte einige neue SKUs der M-Serie unter der Familie Mv3. Einige der VM-Typen in dieser Familie sollten nicht für SQL Server verwendet werden, einschließlich SQL Server 2022, ohne SMT (Hyperthreading) im Windows Server-Gastbetriebssystem zu deaktivieren. Grund ist die Anzahl der NUMA-Knoten, die im Windows Server-Gastbetriebssystem angezeigt werden, das mit mehr als 64 vCPUs zu groß für SQL Server ist. Durch Deaktivieren von SMT im Windows Server-Gastbetriebssystem wird die Anzahl der vCPUs reduziert. Damit wird die Anzahl der vCPUs auf jedem NUMA-Knoten kleiner als 64. Die Vorgehensweise zum Deaktivieren von SMT wird hier beschrieben. Die spezifischen VM-Typen sind:
- M176(d)s_3_v3: SMT deaktivieren oder M176bds_4_v3 oder M176bds_4_v3 als Alternativen verwenden
- M176(d)s_4_v3: SMT deaktivieren oder M176bds_4_v3 als Alternative verwenden
- M624(d)s_12_v3: SMT deaktivieren oder M416ms_v2 als Alternative verwenden
- M832(d)s_12_v3: SMT deaktivieren oder M416ms_v2 als Alternative verwenden
- M832i(d)s_16_v3: SMT deaktivieren oder M416ms_v2 als Alternative verwenden
Hinweis
Bei einigen der neuen M(b)v3-VM-Typen kann die Verwendung von im Cache zwischengespeichertem SSD Premium v1-Speicher zu niedrigeren IOPS-Raten bei Lese- und Schreibvorgängen und einem geringeren Durchsatz als ohne Lesecache führen.
Empfehlungen für die VM-/VHD-Struktur für SAP-bezogene SQL Server-Bereitstellungen
In Übereinstimmung mit der allgemeinen Beschreibung, sollten Betriebssystem, die ausführbaren SQL Server-Dateien und die ausführbaren SAP-Dateien auf getrennten Azure-Datenträgern gespeichert oder installiert werden. Üblicherweise werden die meisten SQL Server-Systemdatenbanken durch die SAP NetWeaver-Workload nicht stark genutzt. Dennoch sollten sich die Systemdatenbanken von SQL Server zusammen mit den anderen SQL Server-Verzeichnissen auf einem separaten Azure-Datenträger befinden. Die tempdb von SQL Server sollte sich entweder auf dem nicht persistenten Laufwerk „D:\“ oder auf einem separaten Datenträger befinden.
- Für alle SAP-zertifizierten VM-Typen (siehe SAP-Hinweis 1928533) können tempdb-Daten- und -Protokolldateien auf dem nicht persistenten Laufwerk „D:\“ platziert werden.
- Bei SQL Server-Releases, bei denen SQL Server die tempdb nur mit einer Datendatei installiert, sollten Sie mehrere tempdb-Datendateien verwenden. Beachten Sie, dass Datenträgervolumes „D:\“ je nach VM-Typ bezüglich Größe und Funktionen variieren können. Weitere Informationen zur genauen Größe des Laufwerks „D:\“ verschiedener VMs finden Sie im Artikel Größen für Windows-VMs in Azure.
Mithilfe dieser Konfigurationen kann die tempdb mehr Speicherplatz und – noch wichtiger – mehr IOPS (E/A-Vorgänge) und Speicherbandbreite nutzen, als auf dem Systemlaufwerk verfügbar ist. Das nicht persistente Laufwerk „D:\“ bietet außerdem bessere E/A-Latenz und einen höheren Durchsatz. Um die richtige tempdb-Größe zu bestimmen, können Sie die tempdb-Größen auf vorhandenen Systemen überprüfen.
Hinweis
Falls Sie tempdb-Datendateien und -Protokolldateien in einem Ordner auf dem Laufwerk „D:\“ platzieren, müssen Sie sicherstellen, dass der Ordner nach einem Neustart der VM vorhanden ist. Da das Laufwerk „D:\“ nach dem Neustart einer VM neu initialisiert werden kann, werden alle Datei- und Verzeichnisstrukturen ggf. gelöscht. Eine Möglichkeit, eventuelle Verzeichnisstrukturen auf Laufwerk „D:\“ vor dem Start des SQL Server-Diensts erneut zu erstellen, finden Sie in diesem Artikel.
Eine VM-Konfiguration, die SQL Server mit einer SAP-Datenbank ausführt und bei der die tempdb-Daten und die tempdb-Protokolldatei auf Laufwerk „D:\“ und Azure Storage Premium v1 oder v2 platziert sind, sieht wie folgt aus:
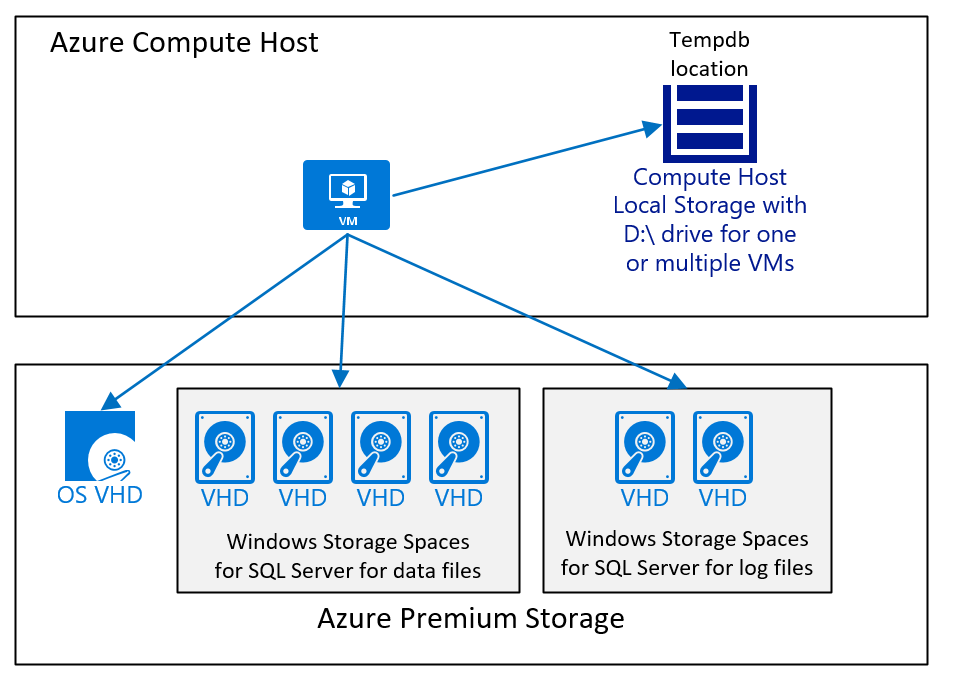
Die Abbildung zeigt ein einfaches Szenario. Wie in Artikel Azure Virtual Machines: DBMS-Bereitstellung für SAP-Workloads erläutert, sind der Azure Storage-Typ sowie die Anzahl und Größe von Datenträgern von verschiedenen Faktoren abhängig. Generell wird Folgendes empfohlen:
- Für kleinere und mittlere Bereitstellungen verwenden Sie ein großes Volume, das die SQL Server-Datendateien enthält. Der Grund für diese Konfiguration ist, dass es einfacher ist, mit verschiedenen E/A-Workloads zu arbeiten, wenn die SQL Server-Datendateien nicht den gleichen freien Speicherplatz nutzen. Während bei großen Bereitstellungen, insbesondere bereitstellungen, bei denen der Kunde mit einer heterogenen Datenbankmigration zu SQL Server in Azure verschoben wurde, haben wir separate Datenträger verwendet und dann die Datendateien auf diese Datenträger verteilt. Eine solche Architektur ist nur erfolgreich, wenn jeder Datenträger über die gleiche Anzahl von Datendateien verfügt, alle Datendateien die gleiche Größe besitzen und ungefähr den gleichen freien Speicherplatz aufweisen.
- Verwenden Sie das Laufwerk „D:\“ für tempdb, solange die Leistung ausreichend ist. Wenn die Leistung der Gesamtworkload von tempdb auf Laufwerk „D:\“ eingeschränkt wird, verschieben Sie tempdb auf einen Datenträger mit Azure Storage Premium v1 oder v2 oder mit Disk Ultra, wie in diesem Artikel empfohlen.
Der proportionale Füllmechanismus von SQL Server verteilt Lese- und Schreibvorgänge gleichmäßig auf alle Datendateien, sofern alle SQL Server-Datendateien die gleiche Größe aufweisen und denselben verfügbaren Platz haben. SAP unter SQL Server bieten die beste Leistung, wenn Lese- und Schreibvorgänge gleichmäßig auf alle verfügbaren Datendateien verteilt werden. Wenn eine Datenbank zu wenige Datendateien enthält oder die vorhandenen Datendateien sehr unausgeglichen sind, ist die beste Methode zur Korrektur ein R3load-Export und -Import. Ein R3load-Export und -Import ist mit Downtime verbunden und sollte nur durchgeführt werden, wenn ein offensichtliches Leistungsproblem vorliegt, das behoben werden muss. Wenn die Datendateien sich nur geringfügig unterscheiden, erhöhen Sie alle Datendateien auf dieselbe Größe. SQL Server gleicht die Daten dann im Lauf der Zeit aus. SQL Server vergrößert Datendateien automatisch gleichmäßig, wenn das Ablaufverfolgungsflag 1117 festgelegt wurde oder wenn SQL Server 2016 oder höher ohne Ablaufverfolgungsflag verwendet wird.
Besonderheiten von VMs der M-Serie
Bei Azure-VMs der M-Serie kann die Latenz beim Schreiben in das Transaktionsprotokoll im Vergleich zu Azure Storage Premium v1 reduziert sein, wenn die Azure-Schreibbeschleunigung verwendet wird. Wenn die von Storage Premium v1 bereitgestellte Latenz die Skalierbarkeit der SAP-Workload einschränkt, kann auf dem Datenträger, auf dem die SQL Server-Transaktionsprotokolldatei gespeichert ist, die Schreibbeschleunigung aktiviert werden. Details finden Sie im Dokument Schreibbeschleunigung. Die Azure-Schreibbeschleunigung funktioniert nicht mit Azure Storage Premium v2 und Disk Ultra. In beiden Fällen ist die Latenz besser als bei Azure Storage Premium v1. Die Schreibbeschleunigung unterstützt nicht SSD Premium v2.
Hinweis
Bei einigen der neuen M(b)v3-VM-Typen kann die Verwendung von im Cache zwischengespeichertem SSD Premium v1-Speicher zu niedrigeren IOPS-Raten bei Lese- und Schreibvorgängen und einem geringeren Durchsatz als ohne Lesecache führen.
Formatieren der Datenträger
Für SQL Server sollte die NTFS-Blockgröße für Datenträger, die SQL Server-Datendateien und -Protokolldateien enthalten, 64 KB betragen. Es ist nicht erforderlich, Laufwerk „D:\“ zu formatieren. Dieses Laufwerk ist bereits vorformatiert.
Um zu vermeiden, dass bei der Wiederherstellung oder Erstellung von Datenbanken die Datendateien initialisiert werden (wobei der Inhalt der Dateien gelöscht wird), stellen Sie sicher, dass der Benutzerkontext, in dem der SQL Server-Dienst ausgeführt wird, über die Berechtigung Datenträgerwartungsaufgaben durchführen verfügt. Weitere Informationen finden Sie im Artikel IFI für Datenbanken.
SQL Server 2014 und neuere SQL Server-Versionen: Direktes Speichern von Datenbankdateien in Azure Blob Storage
SQL Server 2014 und höher bieten die Möglichkeit, Datenbankdateien direkt in Azure Blob Storage ohne den umschließenden Wrapper einer VHD zu speichern. Diese Funktion sollte vor Jahren Mängel des Azure-Blockspeichers beheben. Heutzutage wird davon abgeraten, diese Bereitstellungsmethode zu verwenden und stattdessen entweder Azure Storage Premium v1, Storage Premium v2 oder Ultra-Datenträger auszuwählen. Abhängig von den Anforderungen.
Überlegungen zur Sicherung und Wiederherstellung für SQL Server
Wenn Sie SQL Server in Azure bereitstellen, müssen Sie Ihre Sicherungsarchitektur überprüfen. Auch wenn es sich um kein Produktionssystem handelt, muss die SQL-Server-SAP-Datenbank regelmäßig gesichert werden. Da Azure Storage drei Images vorhält, ist die Sicherung, um einen etwaigen Speicherabsturz kompensieren zu können, weniger dringlich. Der vorrangige Grund für die Pflege eines ordnungsgemäßen Sicherungs- und Wiederherstellungsplans ist wichtig für die Funktionalität der Zeitpunktwiederherstellung, um logische/manuelle Fehler zu kompensieren. Ziel ist es, die Datenbank mithilfe von Sicherungen zu einem bestimmten Zeitpunkt wiederherzustellen oder die Sicherungen in Azure zu verwenden, um das Seeding eines anderen Systems auszuführen, indem die vorhandene Datenbanksicherung kopiert wird.
Es gibt mehrere Möglichkeiten, SQL Server-Datenbanken in Azure zu sichern und wiederherzustellen. Die beste Übersicht und viele Details finden Sie im Dokument Sicherung und Wiederherstellung für SQL Server auf Azure-VMs. Der Artikel behandelt mehrere Möglichkeiten.
Verwenden eines SQL Server-Image aus dem Microsoft Azure Marketplace
Microsoft bietet im Azure Marketplace VMs an, die bereits Versionen von SQL Server enthalten. Für SAP-Kunden, die Lizenzen für SQL Server und Windows benötigen, bieten diese Images die Möglichkeit, diese Lizenzen durch Einrichten von VMs abzudecken, auf denen SQL Server bereits installiert ist. Bei der Verwendung solcher Images für SAP müssen die folgenden Aspekte berücksichtigt werden:
- Die Nicht-Evaluierungsversionen von SQL Server verursachen höhere Kosten als eine VM mit einer „Nur-Windows-Bereitstellung“ aus Azure Marketplace. Weitere Informationen zum Vergleichen von Preisen finden Sie unter Windows-VM – Preise und unter SQL Server Enterprise-VMs – Preise.
- Sie können nur SQL Server-Releases verwenden, deren Software von SAP unterstützt wird.
- Die Sortierung der SQL Server-Instanz, die auf den im Azure Marketplace verfügbaren VMs installiert ist, ist nicht die Sortierung, die SAP NetWeaver zum Ausführen der SQL Server-Instanz benötigt. Sie können die Sortierung aber mithilfe des Leitfadens im folgenden Abschnitt ändern.
Ändern der SQL Server-Sortierung einer Microsoft Windows-/SQL Server-VM
Da die SQL Server-Images im Azure Marketplace nicht die Sortierung verwenden, die für SAP NetWeaver-Anwendungen erforderlich ist, muss diese sofort nach der Bereitstellung geändert werden. Für SQL Server können Sie die Sortierung mithilfe des folgenden Leitfadens ändern, sobald die VM bereitgestellt wurde und Admins sich an der bereitgestellten VM anmelden können:
- Öffnen Sie ein Windows-Befehlsfenster mit Administratorrechten.
- Wechseln Sie in das Verzeichnis „C:\Programme\Microsoft SQL Server\110\Setup Bootstrap\SQLServer2012“.
- Führen Sie den folgenden Befehl aus: Setup.exe /QUIET /ACTION=REBUILDDATABASE /INSTANCENAME=MSSQLSERVER /SQLSYSADMINACCOUNTS=
<local_admin_account_name> /SQLCOLLATION=SQL_Latin1_General_Cp850_BIN2<local_admin_account_name> ist das Konto, das als Administratorkonto definiert wurde, als die VM zum ersten Mal über den Katalog bereitgestellt wurde.
Dieser Vorgang sollte nur wenige Minuten dauern. Um sicherzustellen, dass dieser Schritt zum richtigen Ergebnis geführt hat, führen Sie die folgenden Schritte aus:
- Öffnen Sie SQL Server Management Studio.
- Öffnen Sie ein Abfragefenster.
- Führen Sie den Befehl „sp_helpsort“ in der SQL Server-Masterdatenbank aus.
Das Ergebnis sollte wie folgt aussehen:
Latin1-General, binary code point comparison sort for Unicode Data, SQL Server Sort Order 40 on Code Page 850 for non-Unicode Data
Wenn das nicht der Fall ist, BEENDEN Sie alle Bereitstellungen, und untersuchen Sie, warum der setup-Befehl nicht wie erwartet funktioniert hat. Die Bereitstellung von SAP NetWeaver-Anwendungen in SQL Server-Instanzen mit anderen SQL Server-Codepages als der genannten wird für NetWeaver-Bereitstellungen NICHT unterstützt.
SQL Server-Hochverfügbarkeit für SAP in Azure
Mit SQL Server in Azure-IaaS-Bereitstellungen für SAP haben Sie verschiedene Möglichkeiten, die Datenbankschicht mit Hochverfügbarkeit zu implementieren. Azure bietet unterschiedliche Verfügbarkeits-SLAs für einzelne VMs mit unterschiedlichen Azure-Blockspeichern, VM-Paare, die in einer Azure-Verfügbarkeitsgruppe bereitgestellt werden, oder VM-Paare, die in Azure-Verfügbarkeitszonen bereitgestellt werden. Für Produktionssysteme wird erwartet, dass Sie ein VM-Paar innerhalb einer VM-Skalierungsgruppe mit flexibler Orchestrierung über zwei Verfügbarkeitszonen hinweg bereitstellen. Weitere Informationen finden Sie unter Vergleich verschiedener Bereitstellungstypen für SAP-Workloads. Eine VM führt die aktive SQL Server-Instanz aus. Die andere VM führt die passive Instanz aus.
SQL Server-Clustering mit dem Windows-Dateiserver mit horizontaler Skalierung oder freigegebenen Azure-Datenträgern
Mit Windows Server 2016 führte Microsoft direkte Speicherplätze ein. Basierend auf der Bereitstellung direkter Speicherplätze wird das SQL Server-FCI-Clustering allgemeinen unterstützt. Azure bietet auch freigegebene Azure-Datenträger, die für das Windows-Clustering verwendet werden können. Für SAP-Workloads werden diese Hochverfügbarkeitsoptionen nicht unterstützt.
SQL Server-Protokollversand
Eine Hochverfügbarkeitsfunktion ist der SQL Server-Protokollversand. Wenn die VMs in der Hochverfügbarkeitskonfiguration eine funktionierende Namensauflösung aufweisen, treten keine Problem auf. Das Setup in Azure unterscheidet sich nicht von einem lokalen Setup im Hinblick auf die Einrichtung des Protokollversands und die Prinzipien für den Protokollversand. Weitere Informationen zum SQL Server-Protokollversand finden Sie im Artikel Grundlegendes zum Protokollversand (SQL Server).
Die Funktion „SQL Server-Protokollversand“ wurde in Azure kaum verwendet, um Hochverfügbarkeit in einer Azure-Region zu erzielen. Allerdings setzen SAP-Kunden den Protokollversand in den folgenden Fällen erfolgreich mit Azure ein:
- Notfallwiederherstellungsszenarien zwischen verschiedenen Azure-Regionen.
- Konfiguration der Notfallwiederherstellung von einem lokalen System in eine Azure-Region
- Cut-Over-Szenarien von lokalen Systemen in Azure In diesen Fällen synchronisiert der Protokollversand die neue Datenbankbereitstellung in Azure mit dem laufenden Produktionssystem vor Ort. Zum Zeitpunkt des Cut-Over wird die Produktion gestoppt und sichergestellt, dass die letzten und aktuellsten Transaktionsprotokollsicherungen in die Azure-Datenbankbereitstellung übertragen wurden. Anschließend wird die Azure-Datenbankbereitstellung für die Produktion geöffnet.
SQL Server Always On
Da Always On für lokale SAP-Bereitstellungen unterstützt wird (siehe SAP-Hinweis 1772688), wird Always On auch in Kombination mit SAP in Azure unterstützt. Beim Bereitstellen des SQL Server-Verfügbarkeitsgruppenlisteners (nicht zu verwechseln mit der Azure-Verfügbarkeitsgruppe) gibt es einige besondere Überlegungen. Aus diesem Grund sind einige abweichende Installationsschritte erforderlich.
Im Folgenden finden Sie einige Überlegungen zur Verwendung eines Verfügbarkeitsgruppenlisteners:
- Die Verwendung eines Verfügbarkeitsgruppenlisteners ist nur mit Windows Server 2012 oder höheren Version als Gastbetriebssystem der VM möglich. Stellen Sie für Windows Server 2012 sicher, dass das Update zur Aktivierung von SQL Server-Verfügbarkeitsgruppenlistenern auf Windows Server 2008 R2- und Windows Server 2012-basierten Microsoft Azure-VMs angewendet wurde.
- Für Windows Server 2008 R2 ist dieser Patch nicht vorhanden. In diesem Fall müsste Always On auf die gleiche Weise wie Datenbankspiegelung verwendet werden. Durch Angeben eines Failoverpartners in der Verbindungszeichenfolge (über den SAP-default.pfl-Parameter dbs/mss/server, siehe SAP-Hinweis 965908).
- Bei Verwendung eines Verfügbarkeitsgruppenlisteners müssen Sie die Datenbank-VMs mit einem dedizierten Lastenausgleich verbinden. Sie sollten den Netzwerkschnittstellen dieser VMs in der Always On-Konfiguration statische IP-Adressen zuweisen (das Definieren einer statischen IP-Adresse wird in diesem Artikel beschrieben). Statische IP-Adressen verhindern im Gegensatz zu DHCP die Zuweisung neuer IP-Adressen in Fällen, in denen beide VMs beendet sein könnten.
- Beim Erstellen der WSFC-Clusterkonfiguration, in der dem Cluster eine spezielle IP-Adresse zugewiesen werden muss, sind spezielle Schritte notwendig, da Azure dem Clusternamen derzeit dieselbe IP-Adresse zuweisen würde wie dem Knoten, auf dem der Cluster erstellt wird. Das bedeutet, dass ein manueller Schritt ausgeführt werden muss, um dem Cluster eine andere IP-Adresse zuzuweisen.
- Der Verfügbarkeitsgruppenlistener wird in Azure mit TCP/IP-Endpunkten erstellt, die den VMs zugewiesen werden, auf denen die primären und sekundären Replikate der Verfügbarkeitsgruppe ausgeführt werden.
- Möglicherweise müssen diese Endpunkte mit Zugriffssteuerungslisten (ACLs) geschützt werden.
Eine ausführliche Dokumentation der Bereitstellung von Always On mit SQL Server auf Azure-VMs finden Sie in den folgenden Artikeln:
- Einführung in SQL Server Always On-Verfügbarkeitsgruppen auf Azure-VMs
- Konfigurieren einer Always On-Verfügbarkeitsgruppe auf Azure-VMs in verschiedenen Regionen
- Konfigurieren einer Load Balancer-Instanz für eine Always On-Verfügbarkeitsgruppe in Azure
- Bewährte Methoden der HADR-Konfiguration (SQL Server auf Azure-VMs)
Hinweis
Lesen Sie Einführung SQL Server Always On-Verfügbarkeitsgruppen für virtuelle Azure-Computer. Hier erfahren Sie mehr über den DNN-Listener (Direct Network Name) von SQL Server. Diese neue Funktionalität wurde mit SQL Server 2019 CU8 eingeführt. Diese neue Funktionalität kommt ohne die Verwendung eines Azure-Lastenausgleichs aus, der die virtuelle IP-Adresse des Verfügbarkeitsgruppenlisteners verwaltet.
SQL Server Always On ist die am häufigsten in Azure verwendete Funktionalität für Hochverfügbarkeit und Notfallwiederherstellung für SAP-Workloadbereitstellungen. Die meisten Kunden nutzen Always On für Hochverfügbarkeit innerhalb einer einzelnen Azure-Region. Wenn die Bereitstellung auf nur zwei Knoten beschränkt ist, haben Sie zwei Verbindungsmöglichkeiten:
- Verwenden des Verfügbarkeitsgruppenlisteners. Wenn Sie den Verfügbarkeitsgruppenlistener verwenden, müssen Sie eine Azure Load Balancer-Instanz bereitstellen.
- Mit SQL Server 2016 SP3, SQL Server 2017 CU 25 oder SQL Server 2019 CU8 sowie neueren SQL Server-Releases unter Windows Server 2016 oder höher können Sie den DNN-Listener (Direct Network Name) anstelle von Azure Load Balancer verwenden. DNN macht den Einsatz von Azure Load Balancer überflüssig.
Die Verwendung der Konnektivitätsparameter für die SQL Server-Datenbankspiegelung sollte nur für die Untersuchung von Problemen bei den anderen beiden Methoden in Betracht gezogen werden. In diesem Fall müssen Sie die Konnektivität der SAP-Anwendungen so konfigurieren, dass beide Knotennamen benannt sind. Ausführliche Informationen zu dieser SAP-Konfiguration finden Sie im SAP-Hinweis 965908. Wenn Sie diese Option verwenden, müssen Sie den Verfügbarkeitsgruppenlistener nicht konfigurieren. Als Ergebnis gibt es keine Azure Load Balancer-Instanz, und Probleme dieser Komponenten können untersucht werden. Beachten Sie jedoch, dass diese Option nur funktioniert, wenn Sie Ihre Verfügbarkeitsgruppe auf zwei Instanzen beschränken.
Die meisten Kunden verwenden die Always On-Funktion von SQL Server für Notfallwiederherstellungsfunktionen zwischen Azure-Regionen. Einige Kunden nutzen auch die Möglichkeit, Sicherungen von einem sekundären Replikat durchzuführen.
SQL Server: Transparent Data Encryption
Viele Kunden verwenden SQL Server Transparent Data Encryption (TDE) beim Bereitstellen ihrer SAP-SQL Server-Datenbanken in Azure. Die TDE-Funktion von SQL Server wird vollständig von SAP unterstützt (siehe SAP-Hinweis 1380493).
Anwenden von TDE (SQL Server)
Wenn Sie eine heterogene Migration aus einer anderen lokalen Datenbank zu Windows/SQL Server in Azure ausführen, erstellen Sie vorab eine leere Zieldatenbank in SQL Server. Im nächsten Schritt würden Sie die TDE-Funktionalität von SQL Server auf diese leere Datenbank anwenden. Sie sollten in dieser Reihenfolge vorgehen, da die Verschlüsselung der leeren Datenbank einige Zeit dauern kann. Die SAP-Importvorgänge importieren die Daten dann während der Downtime in die verschlüsselte Datenbank. Der Import in eine verschlüsselte Datenbank dauert wesentlich kürzer als das Verschlüsseln der Datenbank nach dem Export während der Downtime. Beim Versuch, TDE auf SAP-Workloads anzuwenden, die in der Datenbank ausgeführt werden, sind Probleme aufgetreten. Daher wird empfohlen, die TDE-Bereitstellung als eine Aktivität zu behandeln, die ohne oder mit einer geringen SAP-Workload für die jeweilige Datenbank ausgeführt werden muss. Ab SQL Server 2016 können Sie die TDE-Überprüfung beenden und fortsetzen, der die anfängliche Verschlüsselung ausführt. Im Dokument Transparent Data Encryption (TDE) werden der Befehl und weitere Details beschrieben.
In Fällen, in denen Sie SAP-SQL Server-Datenbanken aus einem lokalen System nach Azure verschieben, wird empfohlen zu testen, in welcher Infrastruktur Sie die Verschlüsselung am schnellsten anwenden können. Beachten Sie für diesem Fall Folgendes:
- Sie können nicht festlegen, wie viele Threads verwendet werden, um Datenverschlüsselung auf die Datenbank anzuwenden. Die Anzahl von Threads hängt vor allem von der Anzahl von Datenträgervolumes ab, über die die Daten- und Protokolldateien von SQL Server verteilt sind. Das heißt, je mehr unterschiedliche Volumes (Laufwerkbuchstaben), desto mehr Threads werden parallel aktiviert, um die Verschlüsselung durchzuführen. Eine solche Konfiguration widerspricht früheren Datenträgerkonfigurationsvorschlägen, maximal einen Speicherplatz für die SQL Server-Datenbankdateien auf Azure-VMs zu erstellen. Eine Konfiguration mit einigen wenigen Volumes würde dazu führen, dass einige wenige Threads die Verschlüsselung ausführen. Eine einzelne Threadverschlüsselung liest 64-KB-Erweiterungen, verschlüsselt sie und schreibt dann einen Datensatz in die Transaktionsprotokolldatei, der angibt, dass die Erweiterung verschlüsselt wurde. Daher ist die Last des Transaktionsprotokolls moderat.
- In älteren SQL Server-Releases war die Sicherungskomprimierung nicht mehr effizient, wenn die SQL Server-Datenbank verschlüsselt wurde. Dieses Verhalten war in Fällen problematisch, in denen Sie Ihre SQL Server-Datenbank lokal verschlüsseln und dann eine Sicherung nach Azure kopieren wollten, um die Datenbank in Azure wiederherzustellen. Die SQL Server-Sicherungskomprimierung kann ein Komprimierungsverhältnis mit dem Faktor 4 erzielen.
- Mit SQL Server 2016 hat SQL Server eine neue Funktionalität eingeführt, die es ermöglicht, die Sicherung verschlüsselter Datenbanken effizient zu komprimieren. In diesem Blogbeitrag finden Sie weitere Informationen.
Verwenden von Azure Key Vault
Azure bietet den Dienst Key Vault zum Speichern von Verschlüsselungsschlüsseln an. SQL Server auf der anderen Seite bietet einen Connector, um Azure Key Vault als Speicher für die TDE-Zertifikate zu nutzen.
Weitere Informationen zum Verwenden von Azure Key Vault für SQL Server TDE finden Sie in den folgenden Artikeln:
- Konfigurieren der Azure Key Vault-Integration für SQL Server auf Azure-VMs (Resource Manager)
- Weitere Fragen von Kunden zu SQL Server Transparent Data Encryption – TDE und Azure Key Vault
Wichtig
Bei SQL Server TDE, insbesondere mit Azure Key Vault, wird empfohlen, die neuesten Patches von SQL Server 2014, SQL Server 2016 und SQL Server 2017 zu verwenden. Grund dafür ist, dass der Code auf Basis von Kundenfeedback optimiert und Fehler behoben wurden. Ein Beispiel finden Sie im Wissensdatenbankartikel 4058175.
Mindestkonfigurationen für die Bereitstellung
In diesem Abschnitt wird eine Reihe von Mindestkonfigurationen für verschiedene Datenbankgrößen unter der SAP-Workload vorgeschlagen. Es ist zu schwierig zu beurteilen, ob diese Größen zu Ihrer spezifischen Workload passen. In einigen Fällen sind wir im Vergleich zur Datenbankgröße ggf. großzügig hinsichtlich des Arbeitsspeichers. Auf der anderen Seite kann die Datenträgerdimensionierung für einige Workloads zu klein sein. Daher sollten diese Konfigurationen als das behandelt werden, was sie sind. Dabei handelt es sich um Konfigurationen, die Ihnen einen Ausgangspunkt bereitstellen sollten. Konfigurationen zur Optimierung für Ihre spezifischen Workload- und Kosteneffizienzanforderungen.
Ein Beispiel für eine Konfiguration für eine kleine SQL Server-Instanz mit einer Datenbankgröße zwischen 50 GB und 250 GB könnte wie folgt aussehen:
| Konfiguration | Datenbank-VM | Kommentare |
|---|---|---|
| VM-Typ | E4s_v3/v4/v5 (4 vCPUs/32 GiB RAM) | |
| Beschleunigter Netzwerkbetrieb | Aktivieren | |
| SQL Server-Version | SQL Server 2019 oder neuer | |
| Anzahl der Datendateien | 4 | |
| Anzahl der Protokolldateien | 1 | |
| Anzahl der temporären Datendateien | 4 oder Standard seit SQL Server 2016 | |
| Betriebssystem | Windows Server 2019 oder neuer | |
| Datenträgeraggregation | Speicherplätze nach Bedarf | |
| Dateisystem | NTFS | |
| Blockgröße formatieren | 64 KB | |
| Anzahl und Typ der Datenträger | Storage Premium v1: 2 × P10 (RAID0) Storage Premium v2: 2 × 150 GiB (RAID0) – Standard-IOPS und -Durchsatz oder gleichwertig mit SSD Premium v2 |
Cache = Read Only (Schreibgeschützt) für Storage Premium v1 |
| Anzahl und Typ von Protokolldatenträgern | Storage Premium v1: 1 × P20 Storage Premium v2: 1 × 128 GiB – Standard IOPS und -Durchsatz oder gleichwertig mit SSD Premium v2 |
Cache = NONE (KEINER) |
| Parameter für maximalen Arbeitsspeicher von SQL Server | 90 % vom physischen RAM | Ausgehend von einer einzelnen Instanz |
Ein Konfigurationsbeispiel für eine kleine SQL Server-Instanz mit einer Datenbankgröße zwischen 250 GB und 750 GB (z. B. ein kleineres SAP Business Suite-System) könnte wie folgt aussehen:
| Konfiguration | Datenbank-VM | Kommentare |
|---|---|---|
| VM-Typ | E16s_v3/v4/v5 (16 vCPUs/128 GiB RAM) | |
| Beschleunigter Netzwerkbetrieb | Aktivieren | |
| SQL Server-Version | SQL Server 2019 oder neuer | |
| Anzahl der Datendateien | 8 | |
| Anzahl der Protokolldateien | 1 | |
| Anzahl der temporären Datendateien | 8 oder Standard seit SQL Server 2016 | |
| Betriebssystem | Windows Server 2019 oder neuer | |
| Datenträgeraggregation | Speicherplätze nach Bedarf | |
| Dateisystem | NTFS | |
| Blockgröße formatieren | 64 KB | |
| Anzahl und Typ der Datenträger | Storage Premium v1: 4 × P20 (RAID0) Storage Premium v2: 4 × 100 GiB – 200 GiB (RAID0) – Standard-IOPS und 25 MB/s zusätzlicher Durchsatz pro Datenträger oder gleichwertig mit SSD Premium v2 |
Cache = Read Only (Schreibgeschützt) für Storage Premium v1 |
| Anzahl und Typ von Protokolldatenträgern | Storage Premium v1: 1 × P20 Storage Premium v2: 1 × 200 GiB – Standard IOPS und -Durchsatz oder gleichwertig mit SSD Premium v2 |
Cache = NONE (KEINER) |
| Parameter für maximalen Arbeitsspeicher von SQL Server | 90 % vom physischen RAM | Ausgehend von einer einzelnen Instanz |
Ein Konfigurationsbeispiel für eine mittleren SQL Server-Instanz mit einer Datenbankgröße zwischen 750 GB und 2.000 GB (z. B. ein mittelgroßes SAP Business Suite-System) könnte wie folgt aussehen:
| Konfiguration | Datenbank-VM | Kommentare |
|---|---|---|
| VM-Typ | E64s_v3/v4/v5 (64 vCPUs/432 GiB RAM) | |
| Beschleunigter Netzwerkbetrieb | Aktivieren | |
| SQL Server-Version | SQL Server 2019 oder neuer | |
| Anzahl von Datengeräten | 16 | |
| Anzahl von Protokollgeräten | 1 | |
| Anzahl der temporären Datendateien | 8 oder Standard seit SQL Server 2016 | |
| Betriebssystem | Windows Server 2019 oder neuer | |
| Datenträgeraggregation | Speicherplätze nach Bedarf | |
| Dateisystem | NTFS | |
| Blockgröße formatieren | 64 KB | |
| Anzahl und Typ der Datenträger | Storage Premium v1: 4 × P30 (RAID0) Storage Premium v2: 4 × 250 GiB – 500 GiB – plus 2.000 IOPS und 75 MB/s Durchsatz pro Datenträger oder gleichwertig mit SSD Premium v2 |
Cache = Read Only (Schreibgeschützt) für Storage Premium v1 |
| Anzahl und Typ von Protokolldatenträgern | Storage Premium v1: 1 × P20 Storage Premium v2: 1 × 400 GiB – Standard-IOPS und zusätzlicher Durchsatz von 75 MB/s oder gleichwertig mit SSD Premium v2 |
Cache = NONE (KEINER) |
| Parameter für maximalen Arbeitsspeicher von SQL Server | 90 % vom physischen RAM | Ausgehend von einer einzelnen Instanz |
Ein Konfigurationsbeispiel für eine größere SQL Server-Instanz mit einer Datenbankgröße zwischen 2.000 GB und 4.000 GB (z. B. ein größeres SAP Business Suite-System) könnte wie folgt aussehen:
| Konfiguration | Datenbank-VM | Kommentare |
|---|---|---|
| VM-Typ | E96(d)s_v5 (96 vCPUs/672 GiB RAM) | |
| Beschleunigter Netzwerkbetrieb | Aktivieren | |
| SQL Server-Version | SQL Server 2019 oder neuer | |
| Anzahl von Datengeräten | 24 | |
| Anzahl von Protokollgeräten | 1 | |
| Anzahl der temporären Datendateien | 8 oder Standard seit SQL Server 2016 | |
| Betriebssystem | Windows Server 2019 oder neuer | |
| Datenträgeraggregation | Speicherplätze nach Bedarf | |
| Dateisystem | NTFS | |
| Blockgröße formatieren | 64 KB | |
| Anzahl und Typ der Datenträger | Storage Premium v1: 4 × P30 (RAID0) Storage Premium v2: 4 × 500 GiB – 800 GiB – plus 2.500 IOPS und 100 MB/s Durchsatz pro Datenträger oder gleichwertig mit SSD Premium v2 |
Cache = Read Only (Schreibgeschützt) für Storage Premium v1 |
| Anzahl und Typ von Protokolldatenträgern | Storage Premium v1: 1 × P20 Storage Premium v2: 1 × 400 GiB – plus 1.000 IOPS und zusätzlicher Durchsatz von 75 MB/s oder gleichwertig mit SSD Premium v2 |
Cache = NONE (KEINER) |
| Parameter für maximalen Arbeitsspeicher von SQL Server | 90 % vom physischen RAM | Ausgehend von einer einzelnen Instanz |
Ein Konfigurationsbeispiel für eine große SQL Server-Instanz mit einer Datenbankgröße von 4 TB oder mehr (z. B. ein großes global genutztes SAP Business Suite-System) könnte wie folgt aussehen:
| Konfiguration | Datenbank-VM | Kommentare |
|---|---|---|
| VM-Typ | M-Series (1,0 bis 4,0 TB RAM) | |
| Beschleunigter Netzwerkbetrieb | Aktivieren | |
| SQL Server-Version | SQL Server 2019 oder neuer | |
| Anzahl von Datengeräten | 32 | |
| Anzahl von Protokollgeräten | 1 | |
| Anzahl der temporären Datendateien | 8 oder Standard seit SQL Server 2016 | |
| Betriebssystem | Windows Server 2019 oder neuer | |
| Datenträgeraggregation | Speicherplätze nach Bedarf | |
| Dateisystem | NTFS | |
| Blockgröße formatieren | 64 KB | |
| Anzahl und Typ der Datenträger | Storage Premium v1: 4 × P40 oder mehr (RAID0) Storage Premium v2: 4+ × 1.000 GiB – 4.000 GiB – plus 4.500 IOPS und 125 MB/s Durchsatz pro Datenträger oder gleichwertig mit SSD Premium v2 |
Cache = Read Only (Schreibgeschützt) für Storage Premium v1 |
| Anzahl und Typ von Protokolldatenträgern | Storage Premium v1: 1 × P30 Storage Premium v2: 1 × 500 GiB – plus 2.000 IOPS und 125 MB/s Durchsatz oder gleichwertig mit SSD Premium v2 |
Cache = NONE (KEINER) |
| Parameter für maximalen Arbeitsspeicher von SQL Server | 95 % vom physischen RAM | Ausgehend von einer einzelnen Instanz |
Bei dieser Konfiguration handelt es sich beispielsweise um die Datenbank-VM-Konfiguration einer SAP Business Suite-Instanz in SQL Server. Diese VM hostet die 30-TB-Datenbank der einzelnen globalen SAP Business Suite-Instanz eines globalen Unternehmens mit einem Jahresumsatz von über 200 Milliarden USD und mehr als 200.000 Vollzeitmitarbeitenden. Das System führt die gesamte Finanzverarbeitung, Vertriebs- und Verteilungsverarbeitung und viele weitere Geschäftsprozesse aus verschiedenen geografischen Regionen aus, einschließlich der Gehaltsabrechnung in Nordamerika. Das System wird seit Anfang 2018 in Azure ausgeführt und verwendet VMs der Azure-M-Serie als Datenbank-VMs. Als Hochverfügbarkeit verwendet das System Always On mit einem synchronen Replikat in einer anderen Verfügbarkeitszone derselben Azure-Region. Und eine weitere asynchrone Replik in einer anderen Azure-Region. Die NetWeaver-Anwendungsschicht wird auf den neuesten VMs der Serien D(a) und E(a) eingesetzt.
| Konfiguration | Datenbank-VM | Kommentare |
|---|---|---|
| VM-Typ | M192dms_v2 (192 vCPUs/4.196 GiB RAM) | |
| Beschleunigter Netzwerkbetrieb | Aktiviert | |
| SQL Server-Version | SQL Server 2019 | |
| Anzahl der Datendateien | 32 | |
| Anzahl der Protokolldateien | 1 | |
| Anzahl der temporären Datendateien | 8 | |
| Betriebssystem | Windows Server 2019 | |
| Datenträgeraggregation | Speicherplätze | |
| Dateisystem | NTFS | |
| Blockgröße formatieren | 64 KB | |
| Anzahl und Typ der Datenträger | Storage Premium v1: 16 × P40 oder gleichwertig mit SSD Premium v2 | Cache = Read Only (Schreibgeschützt) |
| Anzahl und Typ von Protokolldatenträgern | Storage Premium v1: 1 × P60 oder gleichwertig mit SSD Premium v2 | Verwenden der Schreibbeschleunigung |
| Anzahl und Typ von tempdb-Datenträgern | Storage Premium v1: 1 × P30 oder gleichwertig mit SSD Premium v2 | Keine Zwischenspeicherung |
| Parameter für maximalen Arbeitsspeicher von SQL Server | 95 % vom physischen RAM |
SQL Server für SAP in Azure – Allgemeine Zusammenfassung
In diesem Leitfaden finden Sie verschiedene Empfehlungen. Es ist ratsam, den Leitfaden mehrmals zu lesen, bevor Sie Ihre Azure-Bereitstellung planen. Im Allgemeinen sollten Sie jedoch den wichtigsten Empfehlungen speziell für SQL Server auf Azure folgen:
- Verwenden Sie das neueste SQL Server-Release wie SQL Server 2022, das die meisten Vorteile in Azure bietet.
- Planen Sie Ihre SAP-Systemlandschaft in Azure sorgfältig, um das Layout von Datendateien und die Einschränkungen von Azure gegeneinander abzuwägen:
- Verwenden Sie nicht zu viele Datenträger, aber ausreichend viele, um sicherzustellen, dass die erforderlichen IOPS erzielt werden können.
- Erstellen Sie nur Stripesets für Datenträger, wenn Sie einen höheren Durchsatz erzielen müssen.
- Verwenden Sie nicht zu viele Datenträger, aber ausreichend viele, um sicherzustellen, dass die erforderlichen IOPS erzielt werden können.
- Auf dem Laufwerk „D:\“ sollten Sie nie Software installieren oder Dateien speichern, die Persistenz erfordern, da dieses Laufwerk nicht persistent ist. Alles auf diesem Laufwerk kann bei einem Windows-Neustart oder vm-Neustart verlorengehen.
- Verwenden Sie Ihre SQL Server Always On-Lösung, um Datenbankdaten zu replizieren.
- Verwenden Sie immer die Namensauflösung, und verlassen Sie sich nicht auf IP-Adressen.
- Wenden Sie die neuesten SQL Server-Patches an, wenn Sie SQL Server TDE verwenden.
- Verwenden Sie SQL Server-Images aus dem Azure Marketplace mit großer Sorgfalt. Wenn Sie SQL Server verwenden, müssen Sie die Sortierung in der Instanz vor der Installation eines SAP NetWeaver-Systems ändern.
- Installieren und konfigurieren Sie die SAP-Hostüberwachung für Azure wie im Bereitstellungsleitfaden beschrieben.
Nächste Schritte
Lesen Sie diesen Artikel: