Hochverfügbarkeit für SAP HANA auf Azure-VMs mit SUSE Linux Enterprise Server
Um Hochverfügbarkeit in einer lokalen SAP HANA-Bereitstellung zu erzielen, können Sie entweder die SAP HANA-Systemreplikation oder gemeinsam genutzten Speicher verwenden.
Die SAP HANA-Systemreplikation in Azure ist derzeit die einzige auf Azure-VMs (virtuelle Computer) unterstützte Hochverfügbarkeitsfunktion.
Die SAP HANA-Systemreplikation umfasst einen primären Knoten und mindestens einen sekundären Knoten. Änderungen an den Daten auf dem primären Knoten werden synchron oder asynchron an den sekundären Knoten repliziert.
In diesem Artikel wird das Bereitstellen und Konfigurieren der VMs, das Installieren des Clusterframeworks sowie das Installieren und Konfigurieren der SAP HANA-Systemreplikation beschrieben.
Bevor Sie beginnen, lesen Sie die folgenden SAP-Hinweise und -Dokumente:
- SAP-Hinweis 1928533. Der Hinweis enthält Folgendes:
- Liste der Azure-VM-Größen, die für die Bereitstellung von SAP-Software unterstützt werden
- Wichtige Kapazitätsinformationen für Azure-VM-Größen
- Unterstützte SAP-Software und Kombinationen aus Betriebssystem (OS) und Datenbank
- Die erforderlichen SAP-Kernelversionen für Windows und Linux in Microsoft Azure
- In SAP-Hinweis 2015553 sind die Voraussetzungen für Bereitstellungen von SAP-Software in Azure aufgeführt, die von SAP unterstützt werden.
- Der SAP-Hinweis 2205917 enthält empfohlene Betriebssystemeinstellungen für SUSE Linux Enterprise Server 12 (SLES 12) für SAP Applications.
- Der SAP-Hinweis 2684254 enthält empfohlene Betriebssystemeinstellungen für SUSE Linux Enterprise Server 15 (SLES 15) für SAP Applications.
- SAP-Hinweis 2235581 hat SAP HANA unterstützte Betriebssysteme
- SAP-Hinweis 2178632 enthält ausführliche Informationen zu allen Überwachungsmetriken, die für SAP in Azure gemeldet werden.
- SAP-Hinweis 2191498 enthält die erforderliche SAP-Host-Agent-Version für Linux in Azure.
- SAP-Hinweis 2243692 enthält Informationen zur SAP-Lizenzierung für Linux in Azure.
- SAP-Hinweis 1984787 enthält allgemeine Informationen zu SUSE Linux Enterprise Server 12.
- SAP-Hinweis 1999351 enthält Informationen zur Problembehandlung für die Azure Enhanced Monitoring-Erweiterung für SAP.
- SAP-Hinweis 401162 enthält Informationen dazu, wie Sie beim Einrichten der HANA-Systemreplikation Fehler vom Typ „Adresse bereits verwendet“ vermeiden.
- Das Support-Wiki der SAP-Community enthält alle erforderlichen SAP-Hinweise für Linux.
- Zertifizierte SAP HANA-IaaS-Plattformen.
- Leitfaden Azure Virtual Machines – Planung und Implementierung für SAP unter Linux
- Bereitstellung von Azure Virtual Machines für SAP unter Linux (Leitfaden).
- Leitfaden Azure Virtual Machines – DBMS-Bereitstellung für SAP unter Linux
- SUSE Linux Enterprise Server for SAP Applications 15 - Best Practices-Leitfäden und SUSE Linux Enterprise Server for SAP Applications 12 - Best Practices-Leitfäden:
- Einrichten einer leistungsoptimierten Infrastruktur für die SAP HANA-Systemreplikation (SLES for SAP Applications). Diese Anleitung enthält alle erforderlichen Informationen zum Einrichten der SAP HANA-Systemreplikation für die lokale Entwicklung. Verwenden Sie dieses Handbuch als Grundlage.
- Einrichten einer kostenoptimierten Infrastruktur für die SAP HANA-Systemreplikation (SLES for SAP Applications).
Planen von Hochverfügbarkeit für SAP HANA
Um Hochverfügbarkeit zu erreichen, installieren Sie SAP HANA auf zwei VMs. Die Daten werden mit der HANA-Systemreplikation repliziert.

Das Setup der SAP HANA-Systemreplikation verwendet einen dedizierten virtuellen Hostnamen und virtuelle IP-Adressen. In Azure benötigen Sie einen Lastenausgleich, um eine virtuelle IP-Adresse bereitzustellen.
Die obige Abbildung zeigt ein Beispiel für den Lastenausgleich mit den folgenden Konfigurationen:
- Front-End-IP-Adresse: 10.0.0.13 für HN1-db
- Testport: 62503
Vorbereiten der Infrastruktur
Der Ressourcen-Agent für SAP HANA ist im SUSE Linux Enterprise Server für SAP-Anwendungen enthalten. Ein Image für SUSE Linux Enterprise Server for SAP Applications 12 oder 15 ist in Azure Marketplace verfügbar. Sie können das Image verwenden, um neue virtuelle Computer bereitzustellen.
Manuelles Bereitstellen von Linux-VMs über das Azure-Portal
In diesem Dokument wird davon ausgegangen, dass Sie bereits eine Ressourcengruppe, ein virtuelles Azure-Netzwerk und ein Subnetz bereitgestellt haben.
Stellen Sie virtuelle Computer für SAP HANA bereit. Wählen Sie ein geeignetes SLES-Image aus, das für das HANA-System unterstützt wird. Sie können VMs über die verschiedenen Verfügbarkeitsoptionen (VM-Skalierungsgruppe, Verfügbarkeitszone oder Verfügbarkeitsgruppe) bereitstellen.
Wichtig
Vergewissern Sie sich, dass das von Ihnen gewählte Betriebssystem für SAP HANA auf den VM-Typen, die Sie verwenden möchten, SAP-zertifiziert ist. Sie können für SAP HANA zertifizierte VM-Typen und deren Betriebssystemversionen unter Für SAP HANA zertifizierte IaaS-Plattformen nachschlagen. Stellen Sie sicher, dass Sie sich die Details des jeweils aufgeführten VM-Typs ansehen, um die vollständige Liste der von SAP HANA unterstützten Betriebssystemversionen für den spezifischen VM-Typ zu erhalten.
Konfigurieren von Azure Load Balancer
Während der VM-Konfiguration können Sie im Abschnitt „Netzwerk“ einen Lastenausgleich erstellen oder einen vorhandenen Lastenausgleich auswählen. Führen Sie die folgenden Schritte aus, um den Standardlastenausgleich für das Hochverfügbarkeitssetup der HANA-Datenbank einzurichten.
Führen Sie die unter Erstellen eines Lastenausgleichs beschriebenen Schritte aus, um über das Azure-Portal einen Standardlastenausgleich für ein SAP-Hochverfügbarkeitssystem einzurichten. Berücksichtigen Sie beim Einrichten des Lastenausgleichs die folgenden Punkte:
- Front-End-IP-Konfiguration: Erstellen Sie eine IP-Adresse für das Front-End. Wählen Sie dasselbe virtuelle Netzwerk und Subnetz aus wie für Ihre Datenbank-VMs.
- Back-End-Pool: Erstellen Sie einen Back-End-Pool, und fügen Sie Datenbank-VMs hinzu.
- Regeln für eingehenden Datenverkehr: Erstellen Sie eine Lastenausgleichsregel. Führen Sie die gleichen Schritte für beide Lastenausgleichsregeln aus.
- Front-End-IP-Adresse: Wählen Sie eine Front-End-IP-Adresse aus.
- Back-End-Pool: Wählen Sie einen Back-End-Pool aus.
- Hochverfügbarkeitsports: Wählen Sie diese Option aus.
- Protokoll: Wählen Sie TCP.
- Integritätstest: Erstellen Sie einen Integritätstest mit folgenden Details:
- Protokoll: Wählen Sie TCP.
- Port: Beispielsweise 625<Instanznr.>
- Intervall: Geben Sie 5 ein.
- Testschwellenwert: Geben Sie 2 ein.
- Leerlauftimeout (Minuten): Geben Sie 30 ein.
- Floating IP aktivieren: Wählen Sie diese Option aus.
Hinweis
Die Konfigurationseigenschaft numberOfProbes für Integritätstests (im Portal als Fehlerschwellenwert bezeichnet) wird nicht berücksichtigt. Legen Sie die probeThreshold-Eigenschaft auf 2 fest, um die Anzahl erfolgreicher oder nicht erfolgreicher aufeinanderfolgender Integritätstests zu steuern. Diese Eigenschaft kann derzeit nicht über das Azure-Portal festgelegt werden. Verwenden Sie daher entweder die Azure-Befehlszeilenschnittstelle (Command Line Interface, CLI) oder den PowerShell-Befehl.
Weitere Informationen zu den erforderlichen Ports für SAP HANA finden Sie im Kapitel zu Verbindungen mit Mandantendatenbanken im Handbuch zu SAP HANA-Mandantendatenbanken oder im SAP-Hinweis 2388694.
Hinweis
Wenn VMs, die keine öffentlichen IP-Adressen besitzen, im Back-End-Pool einer internen Standardinstanz (keine öffentliche IP-Adresse) von Azure Load Balancer platziert werden, bietet die Standardkonfiguration keine ausgehende Internetverbindung. Sie können zusätzliche Schritte ausführen, um das Routing an öffentliche Endpunkte zuzulassen. Ausführliche Informationen zum Erreichen ausgehender Konnektivität finden Sie unter Konnektivität mit öffentlichen Endpunkten für VMs mithilfe von Azure Load Balancer Standard in SAP-Szenarien mit Hochverfügbarkeit.
Wichtig
- Aktivieren Sie keine TCP-Zeitstempel auf Azure-VMs, die sich hinter Azure Load Balancer befinden. Die Aktivierung von TCP-Zeitstempeln führt dazu, dass die Health Probes fehlschlagen. Legen Sie den Parameter
net.ipv4.tcp_timestampsauf0fest. Details finden Sie unter Load Balancer-Integritätstests sowie im SAP-Hinweis 2382421. - Um zu verhindern, dass saptune den manuell festgelegten
net.ipv4.tcp_timestamps-Wert von0wieder in1ändert, muss saptune mindestens auf die Version 3.1.1 aktualisiert werden. Weitere Informationen finden Sie unter saptune 3.1.1: Muss ich ein Update durchführen?.
Erstellen eines Pacemaker-Clusters
Führen Sie die Schritte in Einrichten von Pacemaker unter SUSE Linux Enterprise Server in Azure aus, um einen einfachen Pacemaker-Cluster für diesen HANA-Server zu erstellen. Sie können denselben Pacemaker-Cluster für SAP HANA und SAP NetWeaver (A)SCS verwenden.
Installieren von SAP HANA
Für die Schritte in diesem Abschnitt werden die folgenden Präfixe verwendet:
- [A] : Der Schritt gilt für alle Knoten.
- [1]: Der Schritt gilt nur für Knoten 1.
- [2]: Der Schritt gilt nur für den Knoten 2 des Pacemaker-Clusters.
Ersetzen Sie <placeholders> durch die Werte für Ihre SAP HANA-Installation.
[A]: Richten Sie das Datenträgerlayout mit LVM (Logical Volume Manager) ein.
Es wird empfohlen, LVM für Volumes zu verwenden, die Daten- und Protokolldateien speichern. Im folgenden Beispiel wird davon ausgegangen, dass die VMs über vier angefügte Datenträger verfügen, die zum Erstellen von zwei Volumes verwendet werden.
Führen Sie diesen Befehl aus, um alle verfügbaren Datenträger auflisten:
ls /dev/disk/azure/scsi1/lun*Beispielausgabe:
/dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 /dev/disk/azure/scsi1/lun2 /dev/disk/azure/scsi1/lun3Erstellen Sie physische Volumes für alle Datenträger, die Sie verwenden möchten:
sudo pvcreate /dev/disk/azure/scsi1/lun0 sudo pvcreate /dev/disk/azure/scsi1/lun1 sudo pvcreate /dev/disk/azure/scsi1/lun2 sudo pvcreate /dev/disk/azure/scsi1/lun3Erstellen Sie eine Volumegruppe für die Datendateien. Erstellen Sie eine Volumegruppe für Protokolldateien und eine für das freigegebene Verzeichnis von SAP HANA:
sudo vgcreate vg_hana_data_<HANA SID> /dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 sudo vgcreate vg_hana_log_<HANA SID> /dev/disk/azure/scsi1/lun2 sudo vgcreate vg_hana_shared_<HANA SID> /dev/disk/azure/scsi1/lun3Erstellen Sie die logischen Volumes.
Ein lineares Volume wird erstellt, wenn Sie
lvcreateohne den Schalter-iverwenden. Für eine bessere E/A-Leistung wird empfohlen, ein Striped-Volume zu erstellen. Passen Sie die Bereichsstreifengrößen an die in SAP HANA-VM-Speicherkonfigurationen beschriebenen Werte an. Das-i-Argument sollte die Anzahl der zugrunde liegenden physischen Volumes und das-I-Argument die Bereichsstreifengröße sein.Wenn beispielsweise zwei physische Volumes für das Datenvolume verwendet werden, wird das
-i-Argument auf 2 festgelegt, und die Bereichsstreifengröße für das Datenvolume beträgt 256 KiB. Für das Protokollvolume wird ein physisches Volume verwendet, sodass keine-i- oder-I-Schalter explizit für die Protokollvolumebefehle verwendet werden.Wichtig
Verwenden Sie den Schalter
-i, und ändern Sie die Zahl in die Anzahl der zugrunde liegenden physischen Volumes, wenn Sie für die einzelnen Daten-, Protokoll- oder freigegebenen Volumes mehrere physische Datenträger verwenden. Wenn Sie ein Stripesetvolume erstellen, verwenden Sie den Schalter-I, um die Bereichsstreifengröße anzugeben.Informationen zu empfohlenen Speicherkonfigurationen, einschließlich Bereichsstreifengrößen und Anzahl der Datenträger, finden Sie unter SAP HANA-VM-Speicherkonfigurationen.
sudo lvcreate <-i number of physical volumes> <-I stripe size for the data volume> -l 100%FREE -n hana_data vg_hana_data_<HANA SID> sudo lvcreate -l 100%FREE -n hana_log vg_hana_log_<HANA SID> sudo lvcreate -l 100%FREE -n hana_shared vg_hana_shared_<HANA SID> sudo mkfs.xfs /dev/vg_hana_data_<HANA SID>/hana_data sudo mkfs.xfs /dev/vg_hana_log_<HANA SID>/hana_log sudo mkfs.xfs /dev/vg_hana_shared_<HANA SID>/hana_sharedErstellen Sie die Bereitstellungsverzeichnisse, und kopieren Sie die universellen eindeutigen Bezeichner (UUID) aller logischen Volumes:
sudo mkdir -p /hana/data/<HANA SID> sudo mkdir -p /hana/log/<HANA SID> sudo mkdir -p /hana/shared/<HANA SID> # Write down the ID of /dev/vg_hana_data_<HANA SID>/hana_data, /dev/vg_hana_log_<HANA SID>/hana_log, and /dev/vg_hana_shared_<HANA SID>/hana_shared sudo blkidBearbeiten Sie die Datei /etc/fstab, um
fstab-Einträge für die drei logischen Volumes zu erstellen:sudo vi /etc/fstabFügen Sie in der Datei /etc/fstab die folgenden Zeilen hinzu:
/dev/disk/by-uuid/<UUID of /dev/mapper/vg_hana_data_<HANA SID>-hana_data> /hana/data/<HANA SID> xfs defaults,nofail 0 2 /dev/disk/by-uuid/<UUID of /dev/mapper/vg_hana_log_<HANA SID>-hana_log> /hana/log/<HANA SID> xfs defaults,nofail 0 2 /dev/disk/by-uuid/<UUID of /dev/mapper/vg_hana_shared_<HANA SID>-hana_shared> /hana/shared/<HANA SID> xfs defaults,nofail 0 2Stellen Sie die neuen Volumes bereit:
sudo mount -a
[A] Richten Sie das Datenträgerlayout mithilfe einfacher Datenträger ein.
Für Demosysteme können Sie Ihre HANA-Daten- und Protokolldateien auf einem Datenträger platzieren.
Erstellen Sie auf /dev/disk/azure/scsi1/lun0 eine Partition, und formatieren Sie sie mit XFS:
sudo sh -c 'echo -e "n\n\n\n\n\nw\n" | fdisk /dev/disk/azure/scsi1/lun0' sudo mkfs.xfs /dev/disk/azure/scsi1/lun0-part1 # Write down the ID of /dev/disk/azure/scsi1/lun0-part1 sudo /sbin/blkid sudo vi /etc/fstabFügen Sie diese Zeile in die Datei /etc/fstab ein:
/dev/disk/by-uuid/<UUID> /hana xfs defaults,nofail 0 2Erstellen Sie das Zielverzeichnis, und stellen Sie den Datenträger bereit:
sudo mkdir /hana sudo mount -a
[A] Richten Sie die Hostnamensauflösung für alle Hosts ein.
Sie können entweder einen DNS-Server verwenden oder die Datei /etc/hosts auf allen Knoten ändern. In diesem Beispiel wird die Verwendung der Datei /etc/hosts veranschaulicht. Ersetzen Sie in den folgenden Befehlen die IP-Adressen und Hostnamen.
Bearbeiten Sie die Datei etc/hosts:
sudo vi /etc/hostsFügen Sie in der Datei /etc/hosts die folgenden Zeilen hinzu. Ändern Sie die IP-Adressen und Hostnamen entsprechend Ihrer Umgebung.
10.0.0.5 hn1-db-0 10.0.0.6 hn1-db-1
[A] Installieren Sie SAP HANA nach der Dokumentation von SAP.
Konfigurieren Sie die SAP HANA 2.0 Systemreplikation
Für die Schritte in diesem Abschnitt werden die folgenden Präfixe verwendet:
- [A] : Der Schritt gilt für alle Knoten.
- [1]: Der Schritt gilt nur für Knoten 1.
- [2]: Der Schritt gilt nur für den Knoten 2 des Pacemaker-Clusters.
Ersetzen Sie <placeholders> durch die Werte für Ihre SAP HANA-Installation.
[1] Erstellen Sie die Mandantendatenbank.
Wenn Sie SAP HANA 2.0 oder SAP HANA MDC verwenden, erstellen Sie eine Mandantendatenbank für Ihr SAP NetWeaver-System.
Führen Sie den folgenden Befehl als „<HANA-SID>adm“ aus:
hdbsql -u SYSTEM -p "<password>" -i <instance number> -d SYSTEMDB 'CREATE DATABASE <SAP SID> SYSTEM USER PASSWORD "<password>"'[1] Konfigurieren Sie die Systemreplikation auf dem ersten Knoten:
Sichern Sie zunächst die Datenbanken als „<HANA-SID>adm“:
hdbsql -d SYSTEMDB -u SYSTEM -p "<password>" -i <instance number> "BACKUP DATA USING FILE ('<name of initial backup file for SYS>')" hdbsql -d <HANA SID> -u SYSTEM -p "<password>" -i <instance number> "BACKUP DATA USING FILE ('<name of initial backup file for HANA SID>')" hdbsql -d <SAP SID> -u SYSTEM -p "<password>" -i <instance number> "BACKUP DATA USING FILE ('<name of initial backup file for SAP SID>')"Kopieren Sie dann die PKI-Dateien (Public Key--Infrastruktur) des Systems an den sekundären Standort:
scp /usr/sap/<HANA SID>/SYS/global/security/rsecssfs/data/SSFS_<HANA SID>.DAT hn1-db-1:/usr/sap/<HANA SID>/SYS/global/security/rsecssfs/data/ scp /usr/sap/<HANA SID>/SYS/global/security/rsecssfs/key/SSFS_<HANA SID>.KEY hn1-db-1:/usr/sap/<HANA SID>/SYS/global/security/rsecssfs/key/Erstellen Sie den primären Standort:
hdbnsutil -sr_enable --name=<site 1>[2] Konfigurieren Sie die Systemreplikation auf dem zweiten Knoten:
Registrieren Sie den zweiten Knoten zum Starten der Replikation.
Führen Sie den folgenden Befehl als „<HANA-SID>adm“ aus:
sapcontrol -nr <instance number> -function StopWait 600 10 hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2>
Implementieren von HANA-Ressourcenagents
SUSE bietet zwei verschiedene Softwarepakete für den Pacemaker-Ressourcenagenten zur Verwaltung von SAP HANA. Die Softwarepakete SAPHanaSR und SAPHanaSR-angi verwenden leicht unterschiedliche Syntax und Parameter und sind nicht kompatibel. Details und Unterschiede zwischen SAPHanaSR und SAPHanaSR-angi finden Sie in den SUSE-Versionshinweisen und der Benutzerdokumentation. Dieses Dokument behandelt beide Pakete in separaten Registerkarten in den jeweiligen Abschnitten.
Warnung
Ersetzen Sie das Paket SAPHanaSR in einem bereits konfigurierten Cluster nicht durch SAPHanaSR-angi. Für das Upgrade von SAPHanaSR auf SAPHanaSR-angi ist eine spezifische Vorgehensweise erforderlich.
- [A] Installieren Sie die Hochverfügbarkeitspakete für SAP HANA.
Führen Sie den folgenden Befehl aus, um die Hochverfügbarkeitspakete zu installieren:
sudo zypper install SAPHanaSR
Einrichten von SAP HANA-Anbietern für Hochverfügbarkeit/Notfallwiederherstellung
Die SAP HANA-Anbieter für Hochverfügbarkeit/Notfallwiederherstellung optimieren die Integration in den Cluster und verbessern die Erkennung, wann ein Clusterfailover erforderlich ist. Das Haupt-Hook-Skript ist SAPHanaSR (für SAPHanaSR-Paket) / susHanaSR (für SAPHanaSR-angi). Es wird dringend empfohlen, den Python-Hook für SAPHanaSR/susHanaSR zu konfigurieren. Für HANA 2.0 SPS 05 und höher empfehlen wir, sowohl SAPHanaSR/susHanaSR- als auch die susChkSrv-Hooks zu implementieren.
Der susChkSrv-Hook erweitert die Funktionalität des Hauptanbieters für SAPHanaSR/susHanaSR-Hochverfügbarkeit. Es wird ausgeführt, wenn der HANA-Prozess hdbindexserver abstürzt. Wenn ein einzelner Prozess abstürzt, versucht HANA in der Regel, diesen neu zu starten. Das Neustarten des Indexserverprozesses kann lange dauern. In dieser Zeit reagiert die HANA-Datenbank nicht.
Wenn susChkSrv implementiert ist, wird eine sofortige und konfigurierbare Aktion ausgeführt. Die Aktion löst ein Failover im konfigurierten Timeoutzeitraum aus, anstatt darauf zu warten, dass der Prozess hdbindexserver auf demselben Knoten neu gestartet wird.
- [A] Beenden Sie HANA auf beiden Knoten.
Führen Sie den folgenden Code als <sap-sid>-Administrator aus:
sapcontrol -nr <instance number> -function StopSystem
[A] Installieren Sie die HANA-Hooks für die Systemreplikation. Der Hook muss auf beiden HANA-Datenbankknoten installiert sein.
Tipp
Der SAPHanaSR-Python-Hook kann nur für HANA 2.0 implementiert werden. Das SAPHanaSR-Paket muss mindestens Version 0.153 aufweisen.
Der Python-Hook für SAPHanaSR-angi kann nur für HANA 2.0 SPS 05 und höher implementiert werden.
Der Python-Hook für susChkSrv erfordert SAP HANA 2.0 SPS 05, und die SAPHanaSR-Version 0.161.1_BF oder höher muss installiert sein.[A] Passen Sie Datei global.ini auf jedem Clusterknoten an.
Wenn die Anforderungen für den susChkSrv-Hook nicht erfüllt sind, entfernen Sie den gesamten
[ha_dr_provider_suschksrv]-Block aus den folgenden Parametern. Sie können das Verhalten vonsusChkSrvmithilfe desaction_on_lost-Parameters anpassen. Gültige Werte sind: [ignore|stop|kill|fence].[ha_dr_provider_SAPHanaSR] provider = SAPHanaSR path = /usr/share/SAPHanaSR execution_order = 1 [ha_dr_provider_suschksrv] provider = susChkSrv path = /usr/share/SAPHanaSR execution_order = 3 action_on_lost = fence [trace] ha_dr_saphanasr = infoWenn Sie den Parameterpfad auf den Standardspeicherort
/usr/share/SAPHanaSRverweisen, wird der Code des Python-Hooks automatisch über Betriebssystemupdates oder Paketupdates aktualisiert. HANA verwendet beim nächsten Neustart die Codeupdates für den Hook. Bei einem optionalen eigenen Pfad wie/hana/shared/myHookskönnen Sie Betriebssystemupdates von der von Ihnen verwendeten Hook-Version entkoppeln.[A] Der Cluster erfordert die Konfiguration von sudoers auf jedem Clusterknoten für <sap-sid>-Administrator. In diesem Beispiel wird dies durch das Erstellen einer neuen Datei erreicht.
Führen Sie den folgenden Befehl als root aus. Ersetzen Sie <sid> durch die kleingeschriebene SAP-System-ID, <SID> durch die großgeschriebene SAP-System-ID und <siteA/B> durch ausgewählte HANA-Sitenamen.
cat << EOF > /etc/sudoers.d/20-saphana # Needed for SAPHanaSR and susChkSrv Python hooks Cmnd_Alias SOK_SITEA = /usr/sbin/crm_attribute -n hana_<sid>_site_srHook_<siteA> -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEA = /usr/sbin/crm_attribute -n hana_<sid>_site_srHook_<siteA> -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias SOK_SITEB = /usr/sbin/crm_attribute -n hana_<sid>_site_srHook_<siteB> -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEB = /usr/sbin/crm_attribute -n hana_<sid>_site_srHook_<siteB> -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias HELPER_TAKEOVER = /usr/sbin/SAPHanaSR-hookHelper --sid=<SID> --case=checkTakeover Cmnd_Alias HELPER_FENCE = /usr/sbin/SAPHanaSR-hookHelper --sid=<SID> --case=fenceMe <sid>adm ALL=(ALL) NOPASSWD: SOK_SITEA, SFAIL_SITEA, SOK_SITEB, SFAIL_SITEB, HELPER_TAKEOVER, HELPER_FENCE EOF
Ausführliche Informationen zur Implementierung des Hooks für die SAP HANA-Systemreplikation finden Sie unter Einrichten von HANA-Anbietern für Hochverfügbarkeit/Notfallwiederherstellung (HA/DR).
[A] Starten Sie SAP HANA auf beiden Knoten. Führen Sie den folgenden Befehl als <sap-sid>-Administrator aus:
sapcontrol -nr <instance number> -function StartSystem[1] Überprüfen Sie die Installation des Hooks. Führen Sie den folgenden Befehl als <sap-sid>-Administrator auf der aktiven HANA-Systemreplikationssite aus:
cdtrace awk '/ha_dr_SAPHanaSR.*crm_attribute/ \ { printf "%s %s %s %s\n",$2,$3,$5,$16 }' nameserver_* # Example output # 2021-04-08 22:18:15.877583 ha_dr_SAPHanaSR SFAIL # 2021-04-08 22:18:46.531564 ha_dr_SAPHanaSR SFAIL # 2021-04-08 22:21:26.816573 ha_dr_SAPHanaSR SOK
- [1] Überprüfen Sie die Installation des susChkSrv-Hooks.
Führen Sie den folgenden Befehl als <sap-sid>-Administrator auf allen HANA-VMs aus:
cdtrace egrep '(LOST:|STOP:|START:|DOWN:|init|load|fail)' nameserver_suschksrv.trc # Example output # 2022-11-03 18:06:21.116728 susChkSrv.init() version 0.7.7, parameter info: action_on_lost=fence stop_timeout=20 kill_signal=9 # 2022-11-03 18:06:27.613588 START: indexserver event looks like graceful tenant start # 2022-11-03 18:07:56.143766 START: indexserver event looks like graceful tenant start (indexserver started)
Erstellen von SAP HANA-Clusterressourcen
- [1] Erstellen Sie zuerst die HANA-Topologieressource.
Führen Sie die folgenden Befehle auf einem der Pacemaker-Clusterknoten aus:
sudo crm configure property maintenance-mode=true
# Replace <placeholders> with your instance number and HANA system ID
sudo crm configure primitive rsc_SAPHanaTopology_<HANA SID>_HDB<instance number> ocf:suse:SAPHanaTopology \
operations \$id="rsc_sap2_<HANA SID>_HDB<instance number>-operations" \
op monitor interval="10" timeout="600" \
op start interval="0" timeout="600" \
op stop interval="0" timeout="300" \
params SID="<HANA SID>" InstanceNumber="<instance number>"
sudo crm configure clone cln_SAPHanaTopology_<HANA SID>_HDB<instance number> rsc_SAPHanaTopology_<HANA SID>_HDB<instance number> \
meta clone-node-max="1" target-role="Started" interleave="true"
- [1] Erstellen Sie als nächstes die HANA-Ressourcen:
Hinweis
In diesem Artikel werden Begriffe verwendet, die von Microsoft nicht mehr genutzt werden. Sobald diese Begriffe aus der Software entfernt wurden, werden sie auch aus diesem Artikel gelöscht.
# Replace <placeholders> with your instance number and HANA system ID.
sudo crm configure primitive rsc_SAPHana_<HANA SID>_HDB<instance number> ocf:suse:SAPHana \
operations \$id="rsc_sap_<HANA SID>_HDB<instance number>-operations" \
op start interval="0" timeout="3600" \
op stop interval="0" timeout="3600" \
op promote interval="0" timeout="3600" \
op monitor interval="60" role="Master" timeout="700" \
op monitor interval="61" role="Slave" timeout="700" \
params SID="<HANA SID>" InstanceNumber="<instance number>" PREFER_SITE_TAKEOVER="true" \
DUPLICATE_PRIMARY_TIMEOUT="7200" AUTOMATED_REGISTER="false"
# Run the following command if the cluster nodes are running on SLES 12 SP05.
sudo crm configure ms msl_SAPHana_<HANA SID>_HDB<instance number> rsc_SAPHana_<HANA SID>_HDB<instance number> \
meta notify="true" clone-max="2" clone-node-max="1" \
target-role="Started" interleave="true"
# Run the following command if the cluster nodes are running on SLES 15 SP03 or later.
sudo crm configure clone msl_SAPHana_<HANA SID>_HDB<instance number> rsc_SAPHana_<HANA SID>_HDB<instance number> \
meta notify="true" clone-max="2" clone-node-max="1" \
target-role="Started" interleave="true" promotable="true"
sudo crm resource meta msl_SAPHana_<HANA SID>_HDB<instance number> set priority 100
- [1] Fahren Sie mit Clusterressourcen für virtuelle IP-Adressen, Standardwerte und Einschränkungen fort.
# Replace <placeholders> with your instance number, HANA system ID, and the front-end IP address of the Azure load balancer.
sudo crm configure primitive rsc_ip_<HANA SID>_HDB<instance number> ocf:heartbeat:IPaddr2 \
meta target-role="Started" \
operations \$id="rsc_ip_<HANA SID>_HDB<instance number>-operations" \
op monitor interval="10s" timeout="20s" \
params ip="<front-end IP address>"
sudo crm configure primitive rsc_nc_<HANA SID>_HDB<instance number> azure-lb port=625<instance number> \
op monitor timeout=20s interval=10 \
meta resource-stickiness=0
sudo crm configure group g_ip_<HANA SID>_HDB<instance number> rsc_ip_<HANA SID>_HDB<instance number> rsc_nc_<HANA SID>_HDB<instance number>
sudo crm configure colocation col_saphana_ip_<HANA SID>_HDB<instance number> 4000: g_ip_<HANA SID>_HDB<instance number>:Started \
msl_SAPHana_<HANA SID>_HDB<instance number>:Master
sudo crm configure order ord_SAPHana_<HANA SID>_HDB<instance number> Optional: cln_SAPHanaTopology_<HANA SID>_HDB<instance number> \
msl_SAPHana_<HANA SID>_HDB<instance number>
# Clean up the HANA resources. The HANA resources might have failed because of a known issue.
sudo crm resource cleanup rsc_SAPHana_<HANA SID>_HDB<instance number>
sudo crm configure property priority-fencing-delay=30
sudo crm configure property maintenance-mode=false
sudo crm configure rsc_defaults resource-stickiness=1000
sudo crm configure rsc_defaults migration-threshold=5000
Wichtig
Es wird empfohlen, AUTOMATED_REGISTER nur dann auf false festzulegen, während Sie gründliche Failovertests durchführen, wenn Sie verhindern möchten, dass eine fehlerhafte primäre Instanz automatisch als sekundär registriert wird. Wenn die Failovertests erfolgreich abgeschlossen wurden, legen Sie AUTOMATED_REGISTER auf true fest, damit die Systemreplikation nach der Übernahme automatisch fortgesetzt wird.
Vergewissern Sie sich, dass der Clusterstatus OK lautet und alle Ressourcen gestartet wurden. Es spielt keine Rolle, auf welchem Knoten die Ressourcen ausgeführt werden.
sudo crm_mon -r
# Online: [ hn1-db-0 hn1-db-1 ]
#
# Full list of resources:
#
# stonith-sbd (stonith:external/sbd): Started hn1-db-0
# Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
# Started: [ hn1-db-0 hn1-db-1 ]
# Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
# Masters: [ hn1-db-0 ]
# Slaves: [ hn1-db-1 ]
# Resource Group: g_ip_HN1_HDB03
# rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
# rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0
Konfigurieren der HANA-Systemreplikation im Modus „Aktiv/Lesezugriff“ in einem Pacemaker-Cluster
Ab SAP HANA 2.0 SPS 01 ermöglicht SAP ein Setup der SAP HANA-Systemreplikation im Modus „Aktiv/Lesezugriff“. In diesem Szenario können die sekundären Systeme der SAP HANA-Systemreplikation aktiv für leseintensive Workloads verwendet werden.
Zur Unterstützung eines solchen Setups in einem Cluster ist eine zweite virtuelle IP-Adresse erforderlich, damit Clients auf die sekundäre, lesefähige SAP HANA-Datenbank zugreifen können. Damit nach einer Übernahme weiterhin auf die sekundäre Replikationswebsite zugegriffen werden kann, muss der Cluster die virtuelle IP-Adresse zusammen mit der sekundären Instanz der SAP HANA-Ressource verschieben.
In diesem Abschnitt werden die zusätzlichen Schritte beschrieben, die zum Verwalten der HANA-Systemreplikation im Modus „Aktiv/Lesezugriff“ in einem SUSE-Hochverfügbarkeitscluster mit einer zweiten virtuellen IP-Adresse erforderlich sind.
Bevor Sie fortfahren, stellen Sie sicher, dass Sie den SUSE-Hochverfügbarkeitscluster, der die SAP HANA-Datenbank verwaltet, vollständig wie weiter oben in diesem Artikel beschrieben konfiguriert haben.
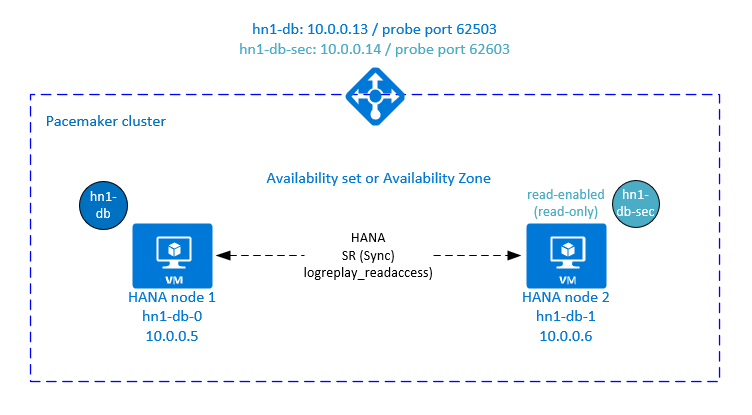
Einrichten des Lastenausgleichs für die Systemreplikation im Modus „Aktiv/Lesezugriff“
Um die zusätzlichen Schritte zum Bereitstellen der zweiten virtuellen IP-Adresse auszuführen, müssen Sie sicherstellen, dass Sie Azure Load Balancer wie unter Manuelles Bereitstellen von Linux-VMs über das Azure-Portal beschrieben konfiguriert haben.
Für den Standard-Loadbalancer führen Sie die zusätzlichen Schritte in der Load Balancer-Instanz aus, die Sie im vorherigen Abschnitt erstellt haben.
- Erstellen eines zweiten Front-End-IP-Pools:
- Öffnen Sie den Lastenausgleich, und wählen Sie den Front-End-IP-Pool und dann Hinzufügen aus.
- Geben Sie den Namen des zweiten Front-End-IP-Pools ein (z. B. hana-secondaryIP).
- Legen Sie die Zuweisung auf Statisch fest, und geben Sie die IP-Adresse ein (z. B. 10.0.0.14).
- Klicken Sie auf OK.
- Notieren Sie nach Erstellen des neuen Front-End-IP-Pools die Front-End-IP-Adresse.
- Erstellen eines Integritätstests:
- Wählen Sie im Lastenausgleich Integritätstests und dann Hinzufügen aus.
- Geben Sie den Namen des neuen Integritätstests ein (z. B. hana-secondaryhp).
- Wählen Sie TCP als Protokoll und Port 626<Instanznummer> aus. Behalten Sie für das Intervall den Wert 5 und als Fehlerschwellenwert 2 bei.
- Klicken Sie auf OK.
- Erstellen Sie die Lastenausgleichsregeln:
- Wählen Sie im Lastenausgleich Lastenausgleichsregeln und dann Hinzufügen aus.
- Geben Sie den Namen der neuen Lastenausgleichsregel ein (z. B. hana-secondarylb).
- Wählen Sie die Front-End-IP-Adresse, den Back-End-Pool und die zuvor erstellte Integritätsprüfung aus (zum Beispiel hana-secondaryIP, hana-backend und hana-secondaryhp).
- Wählen Sie HA-Ports aus.
- Erhöhen Sie das Leerlauftimeout auf 30 Minuten.
- Achten Sie darauf, dass Sie Floating IP aktivieren.
- Klickan Sie auf OK.
Einrichten der HANA-Systemreplikation im Modus „Aktiv/Lesezugriff“
Die Schritte zum Konfigurieren der HANA-Systemreplikation werden unter Konfigurieren der SAP HANA 2.0-Systemreplikation beschrieben. Wenn Sie ein Szenario mit lesefähigem sekundären Standort bereitstellen, führen Sie beim Einrichten der Systemreplikation auf dem zweiten Knoten den folgenden Befehl als „<HANA-SID>adm“ aus:
sapcontrol -nr <instance number> -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> --operationMode=logreplay_readaccess
Hinzufügen einer sekundären virtuellen IP-Adressressource
Sie können die zweite virtuelle IP und die entsprechende Colocation-Einschränkung einrichten, indem Sie die folgenden Befehle ausführen:
crm configure property maintenance-mode=true
crm configure primitive rsc_secip_<HANA SID>_HDB<instance number> ocf:heartbeat:IPaddr2 \
meta target-role="Started" \
operations \$id="rsc_secip_<HANA SID>_HDB<instance number>-operations" \
op monitor interval="10s" timeout="20s" \
params ip="<secondary IP address>"
crm configure primitive rsc_secnc_<HANA SID>_HDB<instance number> azure-lb port=626<instance number> \
op monitor timeout=20s interval=10 \
meta resource-stickiness=0
crm configure group g_secip_<HANA SID>_HDB<instance number> rsc_secip_<HANA SID>_HDB<instance number> rsc_secnc_<HANA SID>_HDB<instance number>
crm configure colocation col_saphana_secip_<HANA SID>_HDB<instance number> 4000: g_secip_<HANA SID>_HDB<instance number>:Started \
msl_SAPHana_<HANA SID>_HDB<instance number>:Slave
crm configure property maintenance-mode=false
Vergewissern Sie sich, dass der Clusterstatus OK lautet und alle Ressourcen gestartet wurden. Die zweite virtuelle IP wird zusammen mit der sekundären SAPHana-Ressource am sekundären Standort ausgeführt.
sudo crm_mon -r
# Online: [ hn1-db-0 hn1-db-1 ]
#
# Full list of resources:
#
# stonith-sbd (stonith:external/sbd): Started hn1-db-0
# Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
# Started: [ hn1-db-0 hn1-db-1 ]
# Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
# Masters: [ hn1-db-0 ]
# Slaves: [ hn1-db-1 ]
# Resource Group: g_ip_HN1_HDB03
# rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
# rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0
# Resource Group: g_secip_HN1_HDB03:
# rsc_secip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
# rsc_secnc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
Im nächsten Abschnitt werden die typischen Failovertests beschrieben, die ausgeführt werden sollten.
Überlegungen beim Testen eines HANA-Clusters, der mit einem lesefähigen sekundären Standort konfiguriert ist:
Wenn Sie die
SAPHana_<HANA SID>_HDB<instance number>-Clusterressource zuhn1-db-1migrieren, wird die zweite virtuelle IP inhn1-db-0geändert. Wenn SieAUTOMATED_REGISTER="false"konfiguriert haben und die HANA-Systemreplikation nicht automatisch registriert wurde, wird die zweite virtuelle IP inhn1-db-0ausgeführt, da der Server verfügbar ist und die Clusterdienste online sind.Wenn Sie einen Serverabsturz testen, werden die zweite virtuelle IP-Ressource (
rsc_secip_<HANA SID>_HDB<instance number>) und die Azure Load Balancer-Portressource (rsc_secnc_<HANA SID>_HDB<instance number>) zusammen mit den primären virtuellen IP-Adressressourcen auf dem primären Server ausgeführt. Während der sekundäre Server ausgefallen ist, stellen die Anwendungen, die mit einer HANA-Datenbank mit Lesezugriff verbunden sind, eine Verbindung mit der primären HANA-Datenbank her. Dieses Verhalten wird erwartet, da Sie nicht möchten, dass auf Anwendungen, die mit einer HANA-Datenbank mit Lesezugriff verbunden sind, nicht zugegriffen werden kann, während der sekundäre Server nicht verfügbar ist.Wenn der sekundäre Server verfügbar ist und die Clusterdienste online sind, werden die zweiten virtuellen IP-Adressressourcen und die Portressourcen automatisch auf den sekundären Server verschoben, auch wenn die HANA-Systemreplikation möglicherweise nicht als sekundär registriert ist. Sie müssen sicherstellen, dass Sie die sekundäre HANA-Datenbank als lesefähig registrieren, bevor Sie Clusterdienste auf diesem Server starten. Sie können die Clusterressource der HANA-Instanz mit der Parameterfestlegung
AUTOMATED_REGISTER="true"so konfigurieren, dass die sekundäre Instanz automatisch registriert wird.Während Failover und Fallback können die bestehenden Verbindungen für Anwendungen, die zu diesem Zeitpunkt die zweite virtuelle IP zur Verbindung mit der HANA-Datenbank verwenden, unterbrochen werden.
Testen der Clustereinrichtung
In diesem Abschnitt wird beschrieben, wie Sie Ihre Einrichtung testen können. Bei jedem Test wird davon ausgegangen, dass Sie als root angemeldet sind und dass der SAP HANA-Master auf der VM hn1-db-0 ausgeführt wird.
Testen der Migration
Bevor Sie den Test starten, stellen Sie sicher, dass Pacemaker keine fehlerhaften Aktionen enthält (indem Sie crm_mon -r ausführen), dass keine unerwarteten Speicherorteinschränkungen bestehen (z. B. durch zurückgebliebene Elemente vom Migrationstest) und dass HANA synchron ist (z. B. indem Sie SAPHanaSR-showAttr ausführen).
hn1-db-0:~ # SAPHanaSR-showAttr
Sites srHook
----------------
SITE2 SOK
Global cib-time
--------------------------------
global Mon Aug 13 11:26:04 2018
Hosts clone_state lpa_hn1_lpt node_state op_mode remoteHost roles score site srmode sync_state version vhost
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
hn1-db-0 PROMOTED 1534159564 online logreplay nws-hana-vm-1 4:P:master1:master:worker:master 150 SITE1 sync PRIM 2.00.030.00.1522209842 nws-hana-vm-0
hn1-db-1 DEMOTED 30 online logreplay nws-hana-vm-0 4:S:master1:master:worker:master 100 SITE2 sync SOK 2.00.030.00.1522209842 nws-hana-vm-1
Sie können den SAP HANA-Masterknoten migrieren, indem Sie den folgenden Befehl ausführen:
crm resource move msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1 force
Dieses Cluster würde den SAP HANA-Masterknoten und die Gruppe, die die virtuelle IP-Adresse hn1-db-1 enthält, migrieren.
Nach Abschluss der Migration sieht die Ausgabe von crm_mon -r wie im folgenden Beispiel aus:
Online: [ hn1-db-0 hn1-db-1 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started hn1-db-1
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
Masters: [ hn1-db-1 ]
Stopped: [ hn1-db-0 ]
Resource Group: g_ip_HN1_HDB03
rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
Failed Actions:
* rsc_SAPHana_HN1_HDB03_start_0 on hn1-db-0 'not running' (7): call=84, status=complete, exitreason='none',
last-rc-change='Mon Aug 13 11:31:37 2018', queued=0ms, exec=2095ms
Mit AUTOMATED_REGISTER="false" würde der Cluster die fehlerhafte HANA-Datenbank nicht neu starten oder sie gegen die neue primäre Datenbank auf hn1-db-0 registrieren. In diesem Fall konfigurieren Sie die HANA-Instanz als sekundär, indem Sie diesen Befehl ausführen:
su - <hana sid>adm
# Stop the HANA instance, just in case it is running
hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> sapcontrol -nr <instance number> -function StopWait 600 10
hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1>
Die Migration erstellt Speicherorteinschränkungen, die erneut gelöscht werden müssen:
# Switch back to root and clean up the failed state
exit
hn1-db-0:~ # crm resource clear msl_SAPHana_<HANA SID>_HDB<instance number>
Darüber hinaus müssen Sie auch den Status der sekundären Knotenressource bereinigen:
hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0
Überwachen Sie den Zustand der HANA-Ressource mithilfe von crm_mon -r. Wenn HANA auf hn1-db-0 gestartet wird, sieht die Ausgabe wie im folgenden Beispiel aus:
Online: [ hn1-db-0 hn1-db-1 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started hn1-db-1
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_HDB03
rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
Blockieren der Netzwerkkommunikation
Zustand der Ressource vor dem Starten des Tests:
Online: [ hn1-db-0 hn1-db-1 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started hn1-db-1
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_HDB03
rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
Führen Sie die Firewallregel aus, um die Kommunikation auf einem der Knoten zu blockieren.
# Execute iptable rule on hn1-db-1 (10.0.0.6) to block the incoming and outgoing traffic to hn1-db-0 (10.0.0.5)
iptables -A INPUT -s 10.0.0.5 -j DROP; iptables -A OUTPUT -d 10.0.0.5 -j DROP
Wenn Clusterknoten nicht miteinander kommunizieren können, besteht das Risiko eines Split-Brain-Szenarios. In solchen Situationen versuchen Clusterknoten, sich gleichzeitig zu umgrenzen, was zu einem Fence Race führt.
Beim Konfigurieren eines Fencinggeräts wird empfohlen, die pcmk_delay_max-Eigenschaft zu konfigurieren. Im Fall eines Split-Brain-Szenarios fügt der Cluster der Fencing-Aktion auf jedem Knoten also eine zufällige Verzögerung bis zum pcmk_delay_max-Wert hinzu. Der Knoten mit der kürzesten Verzögerung wird für das Fencing ausgewählt.
Um sicherzustellen, dass der Knoten, auf dem der HANA-Master ausgeführt wird, Vorrang hat und das Fence Race in einem Split-Brain-Szenario gewinnt, empfiehlt es sich, die priority-fencing-delay-Eigenschaft in der Clusterkonfiguration festzulegen. Durch Aktivieren der priority-fencing-delay-Eigenschaft kann der Cluster eine zusätzliche Verzögerung in der Fencing-Aktion speziell für den Knoten einführen, der die HANA-Masterressource hostet, sodass der Knoten das Fence Race gewinnen kann.
Führen Sie den folgenden Befehl aus, um die Firewallregel zu löschen.
# If the iptables rule set on the server gets reset after a reboot, the rules will be cleared out. In case they have not been reset, please proceed to remove the iptables rule using the following command.
iptables -D INPUT -s 10.0.0.5 -j DROP; iptables -D OUTPUT -d 10.0.0.5 -j DROP
Testen der SBD-Umgrenzung
Sie können das Setup von SBD testen, indem Sie den inquisitor-Prozess beenden:
hn1-db-0:~ # ps aux | grep sbd
root 1912 0.0 0.0 85420 11740 ? SL 12:25 0:00 sbd: inquisitor
root 1929 0.0 0.0 85456 11776 ? SL 12:25 0:00 sbd: watcher: /dev/disk/by-id/scsi-360014056f268462316e4681b704a9f73 - slot: 0 - uuid: 7b862dba-e7f7-4800-92ed-f76a4e3978c8
root 1930 0.0 0.0 85456 11776 ? SL 12:25 0:00 sbd: watcher: /dev/disk/by-id/scsi-360014059bc9ea4e4bac4b18808299aaf - slot: 0 - uuid: 5813ee04-b75c-482e-805e-3b1e22ba16cd
root 1931 0.0 0.0 85456 11776 ? SL 12:25 0:00 sbd: watcher: /dev/disk/by-id/scsi-36001405b8dddd44eb3647908def6621c - slot: 0 - uuid: 986ed8f8-947d-4396-8aec-b933b75e904c
root 1932 0.0 0.0 90524 16656 ? SL 12:25 0:00 sbd: watcher: Pacemaker
root 1933 0.0 0.0 102708 28260 ? SL 12:25 0:00 sbd: watcher: Cluster
root 13877 0.0 0.0 9292 1572 pts/0 S+ 12:27 0:00 grep sbd
hn1-db-0:~ # kill -9 1912
Der <HANA SID>-db-<database 1>-Clusterknoten wird neu gestartet. Der Pacemaker-Dienst wird möglicherweise nicht neu gestartet. Stellen Sie sicher, dass Sie ihn neu starten.
Testen eines manuellen Failovers
Sie können ein manuelles Failover durch Beenden des Pacemaker-Diensts auf Knoten hn1-db-0 testen:
service pacemaker stop
Nach dem Failover können Sie den Dienst erneut starten. Wenn Sie AUTOMATED_REGISTER="false" festlegen, wird die SAP HANA-Ressource auf dem Knoten hn1-db-0 nicht als sekundär gestartet.
In diesem Fall konfigurieren Sie die HANA-Instanz als sekundär, indem Sie diesen Befehl ausführen:
service pacemaker start
su - <hana sid>adm
# Stop the HANA instance, just in case it is running
sapcontrol -nr <instance number> -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1>
# Switch back to root and clean up the failed state
exit
crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0
SUSE-Tests
Wichtig
Stellen Sie sicher, dass das von Ihnen ausgewählte Betriebssystem auf den spezifischen VM-Typen, die Sie verwenden, von SAP für SAP HANA zertifiziert wurde. Sie können für SAP HANA zertifizierte VM-Typen und deren Betriebssystemversionen unter Für SAP HANA zertifizierte IaaS-Plattformen nachschlagen. Überprüfen Sie die Details der VM-Typen, die Sie verwenden möchten, um die vollständige Liste der von SAP HANA unterstützten Betriebssystemreleases für den spezifischen VM-Typ zu erhalten.
Führen Sie abhängig von Ihrem Szenario alle Testfälle aus, die im Szenarioleitfaden zur leistungsoptimierten SAP HANA-Systemreplikation oder zur kostenoptimierten SAP HANA-Systemreplikation aufgeführt werden. Sie finden diese Leitfäden unter SLES for SAP – Best Practices.
Die folgenden Tests sind eine Kopie der Testbeschreibungen aus der Anleitung zum Szenario für die leistungsoptimierte SAP HANA-Systemreplikation unter SUSE Linux Enterprise Server for SAP Applications 12 SP1. Eine aktuelle Version finden Sie im Leitfaden selbst. Stellen Sie vor dem Starten von Tests stets sicher, dass HANA synchron und die Pacemaker-Konfiguration korrekt ist.
In den folgenden Testbeschreibungen wird von PREFER_SITE_TAKEOVER="true" und AUTOMATED_REGISTER="false" ausgegangen.
Hinweis
Die folgenden Tests sind so konzipiert, dass sie nacheinander ausgeführt werden. Jeder Test hängt vom Beendigungszustand des vorherigen Tests ab.
Test 1: Beenden der primären Datenbank auf Knoten 1
Ressourcenzustand vor dem Test:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Führen Sie die folgenden Befehle als „<HANA-SID>adm“ auf dem Knoten
hn1-db-0aus:hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> HDB stopPacemaker erkennt die angehaltene HANA-Instanz und führt ein Failover zum anderen Knoten aus. Nach Abschluss des Failovers wird die HANA-Instanz auf dem Knoten
hn1-db-0angehalten, da Pacemaker den Knoten nicht automatisch als sekundären HANA-Knoten registriert.Führen Sie die folgenden Befehle aus, um den Knoten
hn1-db-0als sekundär zu registrieren und die fehlerhafte Ressource zu bereinigen:hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0Ressourcenzustand nach dem Test:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Test 2: Beenden der primären Datenbank auf Knoten 2
Ressourcenzustand vor dem Test:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Führen Sie die folgenden Befehle als „<HANA-SID>adm“ auf dem Knoten
hn1-db-1aus:hn1adm@hn1-db-1:/usr/sap/HN1/HDB01> HDB stopPacemaker erkennt die angehaltene HANA-Instanz und führt ein Failover zum anderen Knoten aus. Nach Abschluss des Failovers wird die HANA-Instanz auf dem Knoten
hn1-db-1angehalten, da Pacemaker den Knoten nicht automatisch als sekundären HANA-Knoten registriert.Führen Sie die folgenden Befehle aus, um den Knoten
hn1-db-1als sekundär zu registrieren und die fehlerhafte Ressource zu bereinigen:hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> # run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1Ressourcenzustand nach dem Test:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Test 3: Absturz der primären Datenbank auf Knoten 1
Ressourcenzustand vor dem Test:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Führen Sie die folgenden Befehle als „<HANA-SID>adm“ auf dem Knoten
hn1-db-0aus:hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> HDB kill-9Pacemaker erkennt die beendete HANA-Instanz und führt ein Failover zum anderen Knoten aus. Nach Abschluss des Failovers wird die HANA-Instanz auf dem Knoten
hn1-db-0angehalten, da Pacemaker den Knoten nicht automatisch als sekundären HANA-Knoten registriert.Führen Sie die folgenden Befehle aus, um den Knoten
hn1-db-0als sekundär zu registrieren und die fehlerhafte Ressource zu bereinigen:hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0Ressourcenzustand nach dem Test:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Test 4: Absturz der primären Datenbank auf Knoten 2
Ressourcenzustand vor dem Test:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Führen Sie die folgenden Befehle als „<HANA-SID>adm“ auf dem Knoten
hn1-db-1aus:hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> HDB kill-9Pacemaker erkennt die beendete HANA-Instanz und führt ein Failover zum anderen Knoten aus. Nach Abschluss des Failovers wird die HANA-Instanz auf dem Knoten
hn1-db-1angehalten, da Pacemaker den Knoten nicht automatisch als sekundären HANA-Knoten registriert.Führen Sie die folgenden Befehle aus, um den Knoten
hn1-db-1als sekundär zu registrieren und die fehlerhafte Ressource zu bereinigen.hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> # run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1Ressourcenzustand nach dem Test:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Test 5: Absturz des Knotens am primären Standort (Knoten 1)
Ressourcenzustand vor dem Test:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Führen Sie die folgenden Befehle als root auf dem Knoten
hn1-db-0aus:hn1-db-0:~ # echo 'b' > /proc/sysrq-triggerPacemaker erkennt den beendeten Clusterknoten und umgrenzt den Knoten. Nachdem der Knoten umgrenzt wurde, löst Pacemaker eine Übernahme der HANA-Instanz aus. Bei einem Neustart des umgrenzten Knotens wird Pacemaker nicht automatisch gestartet.
Führen Sie die folgenden Befehle aus, um Pacemaker zu starten, die SBD-Nachrichten für den Knoten
hn1-db-0zu bereinigen, den Knotenhn1-db-0als sekundär zu registrieren und die fehlerhafte Ressource zu bereinigen:# run as root # list the SBD device(s) hn1-db-0:~ # cat /etc/sysconfig/sbd | grep SBD_DEVICE= # SBD_DEVICE="/dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116;/dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1;/dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3" hn1-db-0:~ # sbd -d /dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116 -d /dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1 -d /dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3 message hn1-db-0 clear hn1-db-0:~ # systemctl start pacemaker # run as <hana sid>adm hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0Ressourcenzustand nach dem Test:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Test 6: Absturz des Knotens am sekundären Standort (Knoten 2)
Ressourcenzustand vor dem Test:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Führen Sie die folgenden Befehle als root auf dem Knoten
hn1-db-1aus:hn1-db-1:~ # echo 'b' > /proc/sysrq-triggerPacemaker erkennt den beendeten Clusterknoten und umgrenzt den Knoten. Nachdem der Knoten umgrenzt wurde, löst Pacemaker eine Übernahme der HANA-Instanz aus. Bei einem Neustart des umgrenzten Knotens wird Pacemaker nicht automatisch gestartet.
Führen Sie die folgenden Befehle aus, um Pacemaker zu starten, die SBD-Nachrichten für den Knoten
hn1-db-1zu bereinigen, den Knotenhn1-db-1als sekundär zu registrieren und die fehlerhafte Ressource zu bereinigen:# run as root # list the SBD device(s) hn1-db-1:~ # cat /etc/sysconfig/sbd | grep SBD_DEVICE= # SBD_DEVICE="/dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116;/dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1;/dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3" hn1-db-1:~ # sbd -d /dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116 -d /dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1 -d /dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3 message hn1-db-1 clear hn1-db-1:~ # systemctl start pacemaker # run as <hana sid>adm hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> # run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1Ressourcenzustand nach dem Test:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0 </code></pre>Test 7: Beenden der sekundären Datenbank auf Knoten 2
Ressourcenzustand vor dem Test:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Führen Sie die folgenden Befehle als „<HANA-SID>adm“ auf dem Knoten
hn1-db-1aus:hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> HDB stopPacemaker erkennt die angehaltene HANA-Instanz und kennzeichnet die Ressource auf dem Knoten
hn1-db-1als fehlerhaft. Pacemaker startet die HANA-Instanz automatisch neu.Führen Sie zum Bereinigen des fehlerhaften Zustands den folgenden Befehl aus:
# run as root hn1-db-1>:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1Ressourcenzustand nach dem Test:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Test 8: Absturz der sekundären Datenbank auf Knoten 2
Ressourcenzustand vor dem Test:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Führen Sie die folgenden Befehle als „<HANA-SID>adm“ auf dem Knoten
hn1-db-1aus:hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> HDB kill-9Pacemaker erkennt die beendete HANA-Instanz und kennzeichnet die Ressource auf dem Knoten
hn1-db-1als fehlerhaft. Führen Sie zum Bereinigen des fehlerhaften Zustands den folgenden Befehl aus: Pacemaker startet die HANA-Instanz anschließend automatisch neu.# run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> HN1-db-1Ressourcenzustand nach dem Test:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Test 9: Absturz des Knotens am sekundären Standort (Knoten 2), auf dem die sekundäre HANA-Datenbank ausgeführt wird
Ressourcenzustand vor dem Test:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Führen Sie die folgenden Befehle als root auf dem Knoten
hn1-db-1aus:hn1-db-1:~ # echo b > /proc/sysrq-triggerPacemaker erkennt den beendeten Clusterknoten und umgrenzt den Knoten. Bei einem Neustart des umgrenzten Knotens wird Pacemaker nicht automatisch gestartet.
Führen Sie die folgenden Befehle aus, um Pacemaker zu starten und die SBD-Nachrichten für den Knoten
hn1-db-1sowie die fehlerhafte Ressource zu bereinigen:# run as root # list the SBD device(s) hn1-db-1:~ # cat /etc/sysconfig/sbd | grep SBD_DEVICE= # SBD_DEVICE="/dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116;/dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1;/dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3" hn1-db-1:~ # sbd -d /dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116 -d /dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1 -d /dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3 message hn1-db-1 clear hn1-db-1:~ # systemctl start pacemaker hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1Ressourcenzustand nach dem Test:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Test 10: Absturz des Indexservers für die primäre Datenbank
Dieser Test ist nur dann relevant, wenn Sie den susChkSrv-Hook wie in Implementieren der HANA-Ressourcenagenten beschrieben eingerichtet haben.
Ressourcenzustand vor dem Test:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Führen Sie die folgenden Befehle als root auf dem Knoten
hn1-db-0aus:hn1-db-0:~ # killall -9 hdbindexserverWenn der Indexserver beendet wird, erkennt der susChkSrv-Hook dieses Ereignis und löst eine Aktion zum Umgrenzen des Knotens „hn1-db-0“ aus und initiiert einen Übernahmevorgang.
Führen Sie die folgenden Befehle aus, um den Knoten
hn1-db-0als sekundär zu registrieren und die fehlerhafte Ressource zu bereinigen:# run as <hana sid>adm hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0Ressourcenzustand nach dem Test:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Sie können einen vergleichbaren Testfall ausführen, indem Sie den Indexserver auf dem sekundären Knoten zum Absturz bringen. Bei einem Absturz des Indexservers erkennt der susChkSrv-Hook dieses Auftreten und initiiert eine Aktion, um den sekundären Knoten zu umgrenzen.