Azure Kubernetes-Netzwerkrichtlinien
Netzwerkrichtlinien bieten Mikrosegmentierung für Pods – genau wie Netzwerksicherheitsgruppen (NSGs) Mikrosegmentierung für virtuelle Computer bieten. Die Implementierung des Azure-Netzwerkrichtlinien-Managers unterstützt die standardmäßige Kubernetes-Netzwerkrichtlinienspezifikation. Sie können Bezeichnungen verwenden, um eine Gruppe von Pods auszuwählen und eine Liste von Ein- und Ausgangsregeln zu definieren, damit Sie den eingehenden und ausgehenden Datenverkehr für diese Pods filtern können. Weitere Informationen zu Kubernetes-Netzwerkrichtlinien finden Sie in der Kubernetes-Dokumentation.
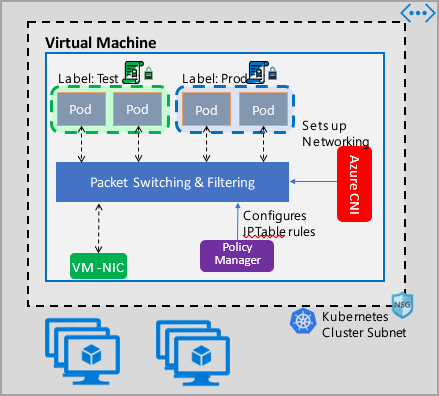
Die Implementierung der Azure-Netzwerkrichtlinienverwaltung arbeitet mit dem Azure CNI zusammen, das die Integration virtueller Netzwerke für Container bereitstellt. Der Netzwerkrichtlinien-Manager wird unter Linux sowie unter Windows Server unterstützt. Die Implementierung erzwingt die Filterung des Datenverkehrs durch Konfiguration von Positiv- und Negativregeln für IP-Adressen auf der Grundlage der in Linux IPTables oder ACLPolicies von Host Network Service (HNS) für Windows Server definierten Richtlinien.
Planen der Sicherheit Ihres Kubernetes-Clusters
Wenn Sie die Sicherheit Ihres Clusters implementieren, verwenden Sie Netzwerksicherheitsgruppen, um den eingehenden und ausgehenden Datenverkehr des Clustersubnetzes zu filtern (Nord-Süd-Datenverkehr). Verwenden Sie den Azure-Netzwerkrichtlinien-Manager für Datenverkehr zwischen Pods im Cluster (Ost-West-Datenverkehr).
Verwenden des Azure-Netzwerkrichtlinien-Managers
Der Azure-Netzwerkrichtlinien-Manager kann auf folgende Weise verwendet werden, um eine Mikrosegmentierung für Pods zu ermöglichen.
Azure Kubernetes Service (AKS)
Der Netzwerkrichtlinien-Manager ist nativ in AKS verfügbar und kann im Rahmen der Clustererstellung aktiviert werden.
Weitere Informationen finden Sie unter Sicherer Datenverkehr zwischen Pods durch Netzwerkrichtlinien in Azure Kubernetes Service (AKS).
Eigenständiges Erstellen von Kubernetes-Clustern in Azure
Installieren Sie bei eigenständig erstellten Clustern zunächst das CNI-Plug-In, und aktivieren Sie es auf jeder VM in einem Cluster. Ausführliche Anweisungen finden Sie unter Bereitstellen des Plug-Ins für einen eigenen Kubernetes-Cluster.
Führen Sie nach Bereitstellung des Clusters den folgenden kubectl-Befehl aus, um den Daemon-Satz des Azure-Netzwerkrichtlinien-Managers herunterzuladen und auf den Cluster anzuwenden.
Linux:
kubectl apply -f https://raw.githubusercontent.com/Azure/azure-container-networking/master/npm/azure-npm.yaml
Windows:
kubectl apply -f https://raw.githubusercontent.com/Azure/azure-container-networking/master/npm/examples/windows/azure-npm.yaml
Die Lösung ist ebenfalls Open Source, und der Code ist im Azure-Containernetzwerkrepository verfügbar.
Überwachen und Visualisieren von Netzwerkkonfigurationen mit dem Azure-NPM
Der Azure-Netzwerkrichtlinien-Manager enthält informative Prometheus-Metriken, mit denen Sie Ihre Konfigurationen überwachen und besser verstehen können. Er bietet integrierte Visualisierungen im Azure-Portal oder in Grafana Labs. Sie können diese Metriken entweder mithilfe von Azure Monitor oder mithilfe eines Prometheus-Servers sammeln.
Vorteile von Metriken des Azure-Netzwerkrichtlinien-Managers
Benutzer*innen konnten bislang nur mit den in einem Clusterknoten ausgeführten Befehlen iptables und ipset mehr über die Netzwerkkonfiguration erfahren. Die Ausgabe dieser Befehle ist jedoch ausführlich und schwer verständlich.
Insgesamt stellen die Metriken Folgendes bereit:
Anzahl von Richtlinien, ACL-Regeln, IPSets, IPSet-Einträge und Einträge in einem bestimmten IPSet
Ausführungszeiten für einzelne Betriebssystemaufrufe und für die Behandlung von Kubernetes-Ressourcenereignissen (Median, 90. Perzentil und 99. Perzentil)
Fehlerinformationen für die Behandlung von Kubernetes-Ressourcenereignissen. (Bei diesen Ressourcenereignisse tritt ein Fehler auf, wenn ein Betriebssystemaufruf nicht erfolgreich ist.)
Beispielanwendungsfälle für Metriken
Warnungen über Prometheus AlertManager
Eine Konfiguration für diese Warnungen finden Sie weiter unten.
Warnung, wenn für den Netzwerkrichtlinien-Manager ein Fehler bei einem Betriebssystemaufruf oder beim Übersetzen einer Netzwerkrichtlinie auftritt.
Warnung, wenn die Medianzeit zum Anwenden von Änderungen für ein Erstellungsereignis mehr als 100 Millisekunden betrug.
Visualisierungen und Debuggen über unser Grafana-Dashboard oder über unsere Azure Monitor-Arbeitsmappe
Sehen Sie sich an, wie viele IPTables-Regeln Ihre Richtlinien erstellen. (Eine hohe Anzahl von IPTables-Regeln kann die Wartezeit geringfügig erhöhen.)
Korrelieren Sie die Clusteranzahl (z. B. ACLs) mit Ausführungszeiten.
Rufen Sie den benutzerfreundlichen Namen eines IPSet-Elements in einer bestimmten IPTables-Regel ab (
azure-npm-487392steht beispielsweise fürpodlabel-role:database).
Alle unterstützten Metriken
Die folgende Liste enthält unterstützte Metriken. Jede quantile-Bezeichnung hat die möglichen Werte 0.5, 0.9 und 0.99. Jede had_error-Bezeichnung hat die möglichen Werte false und true, die angeben, ob der Vorgang erfolgreich war oder nicht.
| Metrikname | BESCHREIBUNG | Prometheus-Metriktyp | Bezeichnungen |
|---|---|---|---|
npm_num_policies |
Anzahl der Netzwerkrichtlinien | Maßstab | - |
npm_num_iptables_rules |
Anzahl der IPTables-Regeln | Maßstab | - |
npm_num_ipsets |
Anzahl von IPSets | Maßstab | - |
npm_num_ipset_entries |
Anzahl der IP-Adresseinträge in allen IPSets | Maßstab | - |
npm_add_iptables_rule_exec_time |
Laufzeit zum Hinzufügen einer IPTables-Regel | Zusammenfassung | quantile |
npm_add_ipset_exec_time |
Laufzeit zum Hinzufügen von IPSet | Zusammenfassung | quantile |
npm_ipset_counts (erweitert) |
Anzahl von Einträgen in jedem einzelnen IPSet | GaugeVec | set_name & set_hash |
npm_add_policy_exec_time |
Laufzeit zum Hinzufügen einer Netzwerkrichtlinie | Zusammenfassung | quantile & had_error |
npm_controller_policy_exec_time |
Laufzeit zum Aktualisieren/Löschen einer Netzwerkrichtlinie | Zusammenfassung | quantile & had_error & operation (mit dem Wert update oder delete) |
npm_controller_namespace_exec_time |
Laufzeit zum Erstellen/Aktualisieren/Löschen eines Namespace | Zusammenfassung | quantile & had_error & operation (mit dem Wert create, update oder delete) |
npm_controller_pod_exec_time |
Laufzeit zum Erstellen/Aktualisieren/Löschen eines Pods | Zusammenfassung | quantile & had_error & operation (mit dem Wert create, update oder delete) |
Es gibt auch die Metriken „exec_time_count“ und „exec_time_sum“ für die einzelnen Übersichtsmetriken „exec_time“.
Die Metriken können mit Azure Monitor für Container oder Prometheus ausgelesen werden.
Einrichten für Azure Monitor
Als Erstes müssen Sie Azure Monitor für Container für die Kubernetes-Cluster aktivieren. Die Schritte werden unter Azure Monitor für Container – Übersicht beschrieben. Konfigurieren Sie nach der Aktivierung von Azure Monitor für Container die ConfigMap von Azure Monitor für Container, um die Integration des Netzwerkrichtlinien-Managers und die Sammlung von Prometheus-Metriken für den Netzwerkrichtlinien-Manager zu aktivieren.
Die ConfigMap von Azure Monitor für Container verfügt über einen Abschnitt namens integrations mit Einstellungen zum Sammeln von Metriken für den Netzwerkrichtlinien-Manager.
Diese Einstellungen sind in ConfigMap standardmäßig deaktiviert. Durch Aktivieren der Grundeinstellung collect_basic_metrics = true werden grundlegende Metriken für den Netzwerkrichtlinien-Manager gesammelt. Durch Aktivieren der erweiterten Einstellung collect_advanced_metrics = true werden neben den grundlegenden Metriken auch erweiterte Metriken gesammelt.
Nachdem Sie ConfigMap bearbeitet haben, speichern Sie die Datei lokal, und wenden Sie ConfigMap wie folgt auf den Cluster an.
kubectl apply -f container-azm-ms-agentconfig.yaml
Der folgende Codeschnipsel stammt aus der ConfigMap von Azure Monitor für Container und zeigt die aktivierte Integration des Netzwerkrichtlinien-Managers mit Sammlung erweiterter Metriken:
integrations: |-
[integrations.azure_network_policy_manager]
collect_basic_metrics = false
collect_advanced_metrics = true
Erweiterte Metriken sind optional. Wenn Sie sie aktivieren, wird die Sammlung grundlegender Metriken automatisch aktiviert. Erweiterte Metriken enthalten derzeit nur Network Policy Manager_ipset_counts.
Weitere Informationen finden Sie unter Konfigurieren der Datensammlung des Container Insights-Agents.
Visualisierungsoptionen für Azure Monitor
Nach der Aktivierung der Sammlung der Metriken für den Netzwerkrichtlinien-Manager können Sie sich die Metriken im Azure-Portal mithilfe von Container Insights oder in Grafana ansehen.
Anzeigen im Azure-Portal unter Erkenntnissen für den Cluster
Öffnen Sie das Azure-Portal. Navigieren Sie in den Erkenntnissen Ihres Clusters zu Arbeitsmappen, und öffnen Sie die Konfiguration des Netzwerkrichtlinien-Managers.
Sie können nicht nur die Arbeitsmappe anzeigen, sondern unter dem Abschnitt mit den Erkenntnissen unter „Protokolle“ auch direkt die Prometheus-Metriken abfragen. Dies folgende Abfrage gibt beispielsweise alle gesammelten Metriken zurück:
| where TimeGenerated > ago(5h)
| where Name contains "npm_"
Sie können die Metriken auch direkt in Log Analytics abfragen. Weitere Informationen finden Sie unter Abfrageprotokolle aus Container Insights.
Anzeigen auf dem Grafana-Dashboard
Richten Sie einen Grafana-Server ein, und konfigurieren Sie wie unter diesem Link beschrieben eine Log Analytics-Datenquelle. Importieren Sie dann das Grafana-Dashboard mit einem Log Analytics-Back-End in Grafana Labs.
Das Dashboard verfügt über visuelles Elemente ähnlich der Azure-Arbeitsmappe. Sie können dem Diagramm Bereiche hinzufügen und Metriken für den Netzwerkrichtlinien-Manager aus der Tabelle „InsightsMetrics“ visualisieren.
Einrichten für Prometheus-Server
Einige Benutzer*innen sammeln ggf. Metriken mit einem Prometheus-Server anstatt mit Azure Monitor für Container. Sie müssen Ihrer Auslesekonfiguration lediglich zwei Aufträge hinzufügen, um Metriken für den Netzwerkrichtlinien-Manager zu sammeln.
Fügen Sie dem Cluster das folgende Helm-Repository hinzu, um einen Prometheus-Server zu installieren:
helm repo add stable https://kubernetes-charts.storage.googleapis.com
helm repo update
Fügen Sie anschließend einen Server hinzu,
helm install prometheus stable/prometheus -n monitoring \
--set pushgateway.enabled=false,alertmanager.enabled=false, \
--set-file extraScrapeConfigs=prometheus-server-scrape-config.yaml
prometheus-server-scrape-config.yaml setzt sich aus Folgendem zusammen:
- job_name: "azure-npm-node-metrics"
metrics_path: /node-metrics
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
action: replace
regex: ([^:]+)(?::\d+)?
replacement: "$1:10091"
target_label: __address__
- job_name: "azure-npm-cluster-metrics"
metrics_path: /cluster-metrics
kubernetes_sd_configs:
- role: service
relabel_configs:
- source_labels: [__meta_kubernetes_namespace]
regex: kube-system
action: keep
- source_labels: [__meta_kubernetes_service_name]
regex: npm-metrics-cluster-service
action: keep
# Comment from here to the end to collect advanced metrics: number of entries for each IPSet
metric_relabel_configs:
- source_labels: [__name__]
regex: npm_ipset_counts
action: drop
Sie können den Auftrag azure-npm-node-metrics auch durch den folgenden Inhalt ersetzen oder ihn in einen bereits vorhandenen Auftrag für Kubernetes-Pods einschließen:
- job_name: "azure-npm-node-metrics-from-pod-config"
metrics_path: /node-metrics
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_namespace]
regex: kube-system
action: keep
- source_labels: [__meta_kubernetes_pod_annotationpresent_azure_Network Policy Manager_scrapeable]
action: keep
- source_labels: [__address__]
action: replace
regex: ([^:]+)(?::\d+)?
replacement: "$1:10091"
target_label: __address__
Einrichten von Warnungen für AlertManager
Wenn Sie einen Prometheus-Server verwenden, können Sie AlertManager wie hier beschrieben einrichten. Nachfolgend sehen Sie eine Beispielkonfiguration für die beiden zuvor beschriebenen Warnungsregeln:
groups:
- name: npm.rules
rules:
# fire when Network Policy Manager has a new failure with an OS call or when translating a Network Policy (suppose there's a scraping interval of 5m)
- alert: AzureNetwork Policy ManagerFailureCreatePolicy
# this expression says to grab the current count minus the count 5 minutes ago, or grab the current count if there was no data 5 minutes ago
expr: (npm_add_policy_exec_time_count{had_error='true'} - (npm_add_policy_exec_time_count{had_error='true'} offset 5m)) or npm_add_policy_exec_time_count{had_error='true'}
labels:
severity: warning
addon: azure-npm
annotations:
summary: "Azure Network Policy Manager failed to handle a policy create event"
description: "Current failure count since Network Policy Manager started: {{ $value }}"
# fire when the median time to apply changes for a pod create event is more than 100 milliseconds.
- alert: AzurenpmHighControllerPodCreateTimeMedian
expr: topk(1, npm_controller_pod_exec_time{operation="create",quantile="0.5",had_error="false"}) > 100.0
labels:
severity: warning
addon: azure-Network Policy Manager
annotations:
summary: "Azure Network Policy Manager controller pod create time median > 100.0 ms"
# could have a simpler description like the one for the alert above,
# but this description includes the number of pod creates that were handled in the past 10 minutes,
# which is the retention period for observations when calculating quantiles for a Prometheus Summary metric
description: "value: [{{ $value }}] and observation count: [{{ printf `(npm_controller_pod_exec_time_count{operation='create',pod='%s',had_error='false'} - (npm_controller_pod_exec_time_count{operation='create',pod='%s',had_error='false'} offset 10m)) or npm_controller_pod_exec_time_count{operation='create',pod='%s',had_error='false'}` $labels.pod $labels.pod $labels.pod | query | first | value }}] for pod: [{{ $labels.pod }}]"
Visualisierungsoptionen für Prometheus
Bei Verwendung eines Prometheus-Servers wird nur das Grafana-Dashboard unterstützt.
Richten Sie bei Bedarf den Grafana-Server ein, und konfigurieren Sie eine Prometheus-Datenquelle. Importieren Sie dann das Grafana-Dashboard mit einem Prometheus-Back-End in Grafana Labs.
Die visuellen Elemente für dieses Dashboard sind identisch mit dem Dashboard mit einem Container Insights- bzw. Log Analytics-Back-End.
Beispieldashboards
Nachfolgend finden Sie einige Beispieldashboards für Metriken für den Netzwerkrichtlinien-Manager in Container Insights (CI) und Grafana.
Zusammengefasste Anzahlwerte in CI
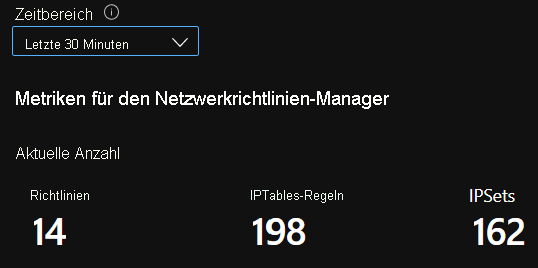
Anzahlwerte in CI im Zeitverlauf

IPSet-Einträge in CI

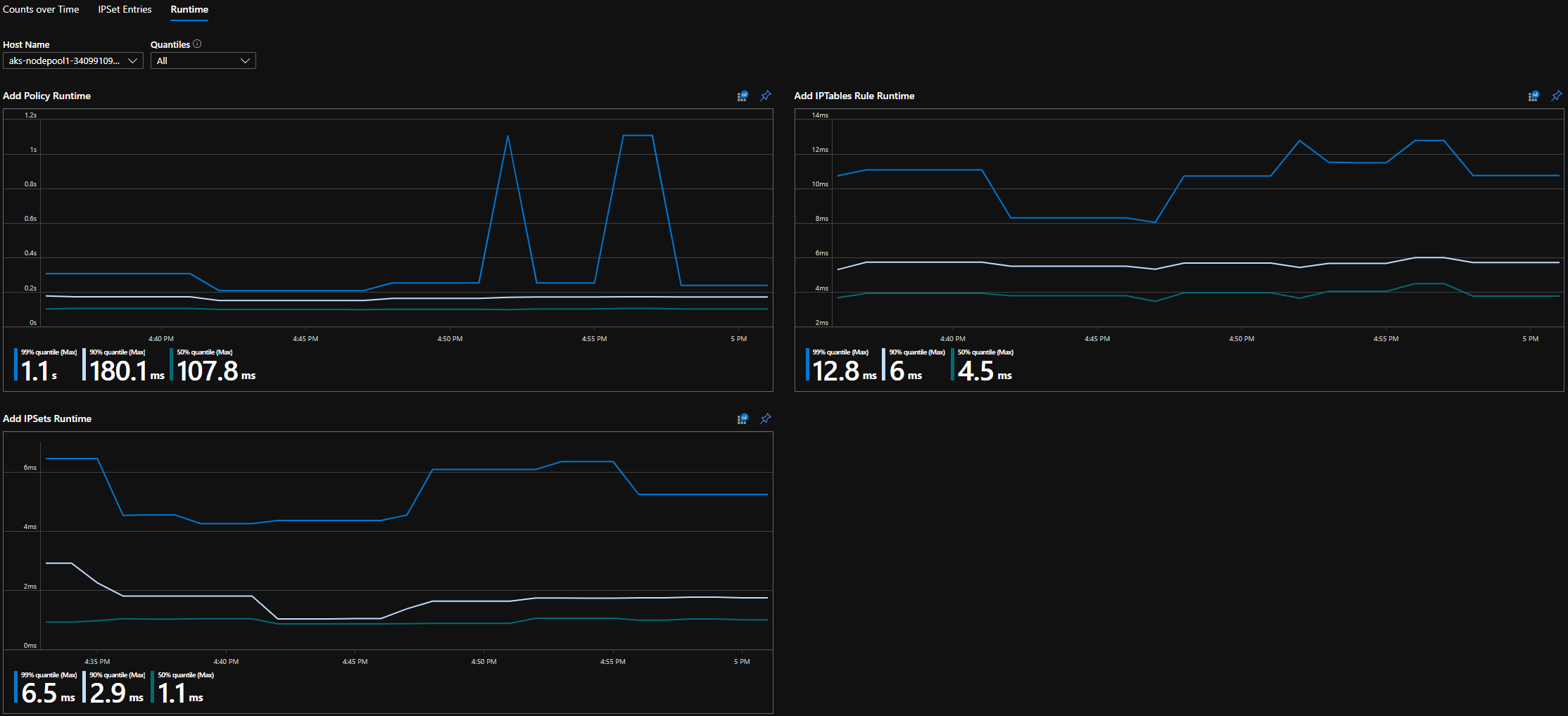
Laufzeitquantile in CI
Zusammengefasste Anzahlwerte auf dem Grafana-Dashboard
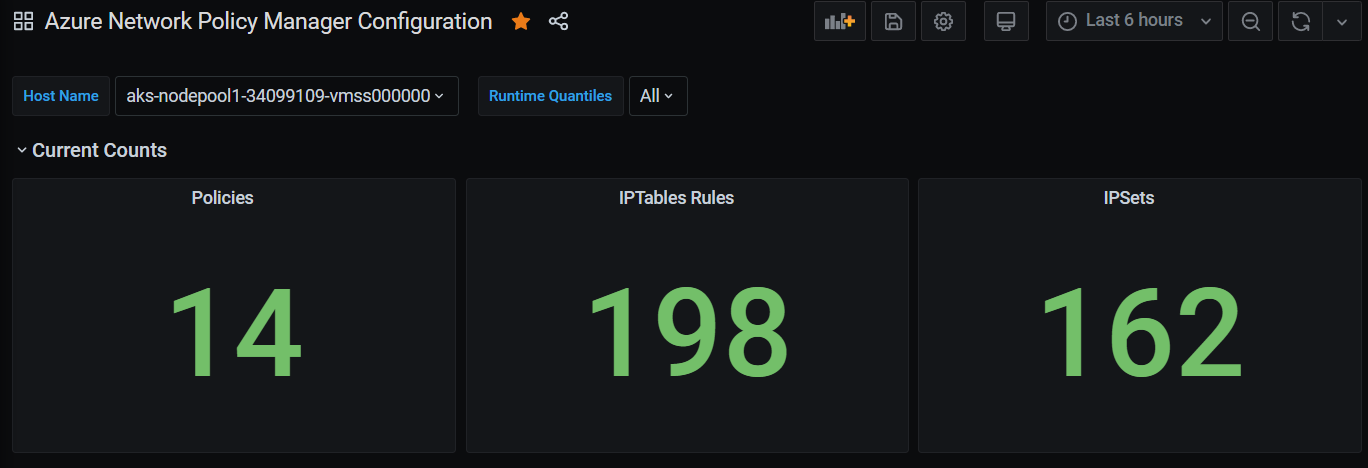
Anzahlwerte im Zeitverlauf auf dem Grafana-Dashboard

IPSet-Einträge auf dem Grafana-Dashboard

Laufzeitquantile auf dem Grafana-Dashboard

Nächste Schritte
Weitere Informationen zu Azure Kubernetes Service
Weitere Informationen zu Containernetzwerken
Bereitstellen des Plug-Ins für Kubernetes-Cluster oder Docker-Container