Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Durch Tests wird sichergestellt, dass Code wie erwartet ausgeführt wird, aber die Zeit und der Aufwand zum Erstellen von Tests nimmt Zeit für andere Aufgaben wie die Featureentwicklung in Anspruch. Bei diesen Kosten ist es wichtig, den maximalen Wert aus tests zu extrahieren. In diesem Artikel werden DevOps-Testprinzipien erläutert, die sich auf den Wert von Komponententests und eine Shift-Left-Teststrategie konzentrieren.
Ehemals schrieben dedizierte Tester die meisten Tests, und viele Produktentwickler haben nicht gelernt, Unit-Tests zu schreiben. Das Schreiben von Tests kann zu schwierig erscheinen oder zu viel Arbeit sein. Es kann Skepsis darüber geben, ob eine Komponententeststrategie funktioniert, schlechte Erfahrungen mit schlecht geschriebenen Komponententests oder Angst, dass Komponententests Funktionstests ersetzen werden.

Um eine DevOps-Teststrategie zu implementieren, seien Sie pragmatisch und konzentrieren Sie sich auf die Entwicklung von Dynamik. Obwohl Sie auf Komponententests für neuen Code oder vorhandenen Code bestehen können, der sauber umgestaltet werden kann, kann es sinnvoll sein, dass eine Legacy-Codebasis eine Abhängigkeit zulässt. Wenn wichtige Teile des Produktcodes SQL verwenden, können Komponententests sich auf den SQL-Ressourcenanbieter verlassen, anstatt diese Ebene zu mocken, was ein kurzfristiger Fortschrittsansatz sein könnte.
Da DevOps-Organisationen reif sind, wird es einfacher, Prozesse zu verbessern. Obwohl es möglicherweise einen Widerstand gegen Veränderungen gibt, wertschätzen Agile Organisationen Veränderungen, die klare Vorteile bringen. Es sollte einfach sein, die Vision schnellerer Testläufe mit weniger Fehlern zu verkaufen, da es mehr Zeit bedeutet, in die Generierung neuer Werte durch die Featureentwicklung zu investieren.
DevOps-Testtaxonomie
Das Definieren einer Testtaxonomie ist ein wichtiger Aspekt des DevOps-Testprozesses. Eine DevOps-Testtaxonomie klassifiziert einzelne Tests anhand ihrer Abhängigkeiten und der Zeit, die sie ausführen müssen. Entwickler sollten verstehen, welche Arten von Tests in verschiedenen Szenarien verwendet werden sollen und welche Tests die verschiedenen Teile des Prozesses erfordern. Die meisten Organisationen kategorisieren Tests auf vier Ebenen:
- L0 - und L1-Tests sind Unittests oder Tests, die vom Code in der getesteten Assembly und von nichts anderem abhängen. L0 ist eine breite Klasse von schnellen, im Speicher durchgeführten Einheitstests.
- L2 sind funktionale Tests , die möglicherweise die Assembly sowie andere Abhängigkeiten erfordern, z. B. SQL oder das Dateisystem.
- L3-Funktionstests werden für testbare Dienstbereitstellungen ausgeführt. Diese Testkategorie erfordert das Bereitstellen von Diensten, kann jedoch Stubs für zentrale Dienstabhängigkeiten verwenden.
- L4-Tests sind eine eingeschränkte Klasse von Integrationstests , die für die Produktion ausgeführt werden. L4-Tests erfordern eine vollständige Bereitstellung des Produkts.
Obwohl es ideal wäre, dass alle Tests jederzeit ausgeführt werden können, ist es nicht machbar. Teams können auswählen, an welcher Stelle im DevOps-Prozess die einzelnen Tests ausgeführt werden sollen, und Shift-Left- oder Shift-Right-Strategien verwenden, um verschiedene Testtypen früher oder später im Prozess durchzuführen.
Die Erwartung könnte beispielsweise sein, dass Entwickler immer L2-Tests durchlaufen, bevor ein Commit ausgeführt wird, eine Pullanforderung schlägt automatisch fehl, wenn die L3-Testausführung fehlschlägt, und die Bereitstellung kann blockiert werden, wenn L4-Tests fehlschlagen. Die spezifischen Regeln können von Organisation zu Organisation variieren, aber die Durchsetzung der Erwartungen für alle Teams innerhalb einer Organisation führt alle in Richtung der gleichen Qualitätsziele.
Komponententestrichtlinien
Legen Sie strenge Richtlinien für L0- und L1-Komponententests fest. Diese Tests müssen sehr schnell und zuverlässig sein. Beispielsweise sollte die durchschnittliche Ausführungszeit pro L0-Test in einer Assembly kleiner als 60 Millisekunden sein. Die durchschnittliche Ausführungszeit pro L1-Test in einer Assembly sollte kleiner als 400 Millisekunden sein. Kein Test auf dieser Stufe sollte 2 Sekunden überschreiten.
Ein Microsoft-Team führt in weniger als sechs Minuten über 60.000 Komponententests parallel aus. Ihr Ziel ist es, diese Zeit auf weniger als eine Minute zu reduzieren. Das Team verfolgt die Ausführungszeit für Komponententests mit Tools wie das folgende Diagramm und meldet Fehler bei Tests, die die zulässige Zeit überschreiten.
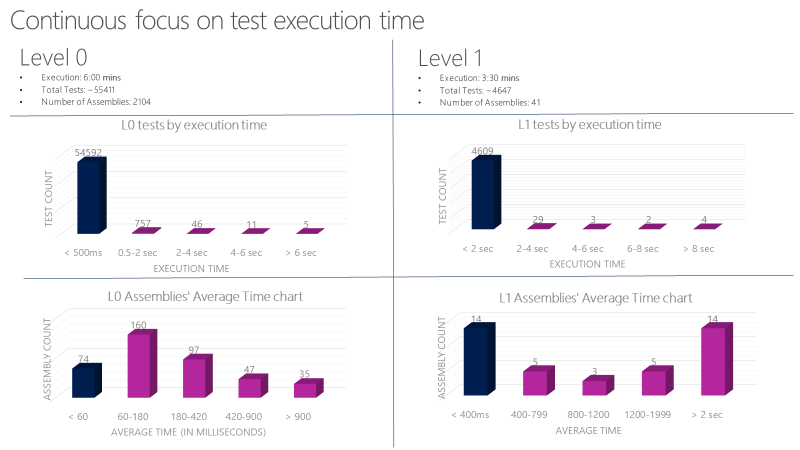
Richtlinien für funktionale Tests
Funktionale Tests müssen unabhängig sein. Das Schlüsselkonzept für L2-Tests ist Isolation. Ordnungsgemäß isolierte Tests können zuverlässig in jeder Sequenz ausgeführt werden, da sie die vollständige Kontrolle über die Umgebung haben, in der sie ausgeführt werden. Der Zustand muss am Anfang des Tests bekannt sein. Wenn ein Test Daten erstellt und in der Datenbank zurückgelassen hat, könnte die Ausführung eines anderen Tests, der von einem anderen Datenbankzustand abhängt, beeinträchtigt werden.
Legacytests, die eine Benutzeridentität benötigen, haben möglicherweise externe Authentifizierungsanbieter aufgerufen, um die Identität abzurufen. Diese Praxis führt zu mehreren Herausforderungen. Die externe Abhängigkeit könnte vorübergehend unzuverlässig oder nicht verfügbar sein und den Test unterbrechen. Diese Praxis verstößt auch gegen das Testisolationsprinzip, da ein Test den Status einer Identität ändern könnte, z. B. die Berechtigung, was zu einem unerwarteten Standardzustand für andere Tests führt. Erwägen Sie, diese Probleme zu verhindern, indem Sie in die Identitätsunterstützung im Testframework investieren.
DevOps-Testprinzipien
Um ein Testportfolio auf moderne DevOps-Prozesse umzustellen, formulieren Sie eine Qualitätsvision. Teams sollte bei der Definition und Implementierung einer DevOps-Teststrategie die folgenden Testprinzipien einhalten.
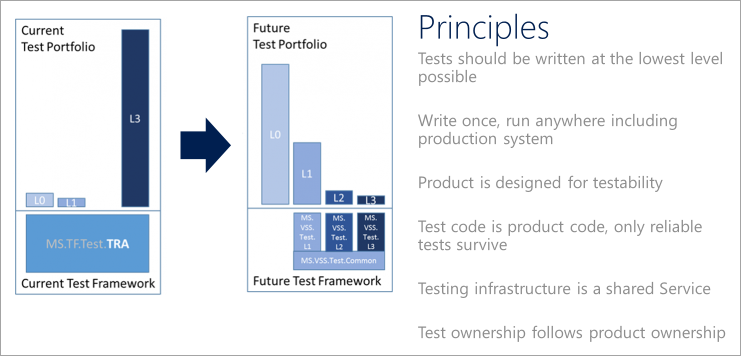
Wechseln nach links zum Testen früher
Tests können lange dauern. Da Projekte skaliert werden, wachsen Die Testzahlen und Typen erheblich. Wenn Test-Suiten Stunden oder Tage in Anspruch nehmen, bis sie abgeschlossen sind, können sie weiter nach hinten verschoben werden, bis sie im letzten Moment ausgeführt werden. Die Vorteile der Codequalität durch Testing werden erst lange nach der Codeeinreichung wahrgenommen.
Lange dauernde Tests können auch Fehler erzeugen, die zeitaufwändig sind, um zu untersuchen. Teams können eine Toleranz für Fehler entwickeln, insbesondere zu Beginn der Sprints. Diese Toleranz untergräbt den Wert von Tests als Einblick in die Codebasisqualität. Lange laufende, Last-Minute-Tests fügen auch Unvorstellbarkeit zu End-of-Sprint-Erwartungen hinzu, da eine unbekannte Menge an technischen Schulden bezahlt werden muss, um den Code versandbar zu erhalten.
Das Ziel des Linksschiebens der Tests besteht darin, die Qualität bereits in einem früheren Stadium sicherzustellen, indem Testaufgaben früher im Ablauf durchgeführt werden. Durch eine Kombination aus Test- und Prozessverbesserungen verringert sich die Verschiebung nach links sowohl die Zeit, die für die Ausführung von Tests benötigt wird, als auch die Auswirkungen von Fehlern später im Zyklus. Durch Linksverschiebung wird sichergestellt, dass die meisten Tests abgeschlossen sind, bevor eine Änderung in den Hauptzweig zusammengeführt wird.
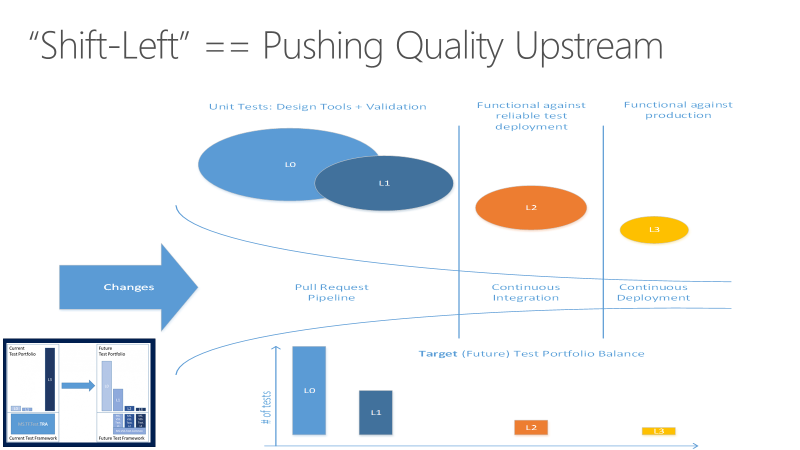
Neben der Verschiebung bestimmter Testaufgaben, die zur Verbesserung der Codequalität übrig bleiben, können Teams andere Testaspekte nach rechts oder später im DevOps-Zyklus verschieben, um das Endprodukt zu verbessern. Weitere Informationen finden Sie unter Shift right to test in production.
Schreiben Sie Tests auf der niedrigstmöglichen Ebene
Schreiben Sie weitere Unit-Tests. Bevorzugen Sie Tests mit den wenigsten externen Abhängigkeiten, und konzentrieren Sie sich auf die Ausführung der meisten Tests im Rahmen des Builds. Stellen Sie sich ein paralleles Buildsystem vor, das Komponententests für eine Assembly ausführen kann, sobald die Assembly und die zugehörigen Tests verfügbar sind. Es ist nicht machbar, jeden Aspekt eines Dienstes auf dieser Ebene zu testen, aber das Prinzip besteht darin, leichtere Komponententests zu verwenden, wenn sie dieselben Ergebnisse wie schwerere funktionale Tests erzeugen können.
Ziel der Testsicherheit
Ein unzuverlässiger Test ist organisatorisch teuer zu verwalten. Ein solcher Test steht im direkten Widerspruch zum Ziel der technischen Effizienz, weil er es schwierig macht, Änderungen mit Vertrauen vorzunehmen. Entwickler sollten in der Lage sein, überall Änderungen vorzunehmen und schnell Zuversicht zu gewinnen, dass nichts beschädigt wurde. Halten Sie einen hohen Standard an Zuverlässigkeit. Verhindern Sie die Verwendung von UI-Tests, da sie tendenziell unzuverlässig sind.
Schreiben von Funktionstests, die überall ausgeführt werden können
Tests können spezielle Integrationspunkte verwenden, die speziell zum Aktivieren von Tests entwickelt wurden. Ein Grund für diese Praxis ist ein Mangel an Testbarkeit im Produkt selbst. Leider sind Tests wie diese oft von internen Kenntnissen abhängig und verwenden Implementierungsdetails, die aus funktionaler Testperspektive nicht wichtig sind. Diese Tests sind auf Umgebungen beschränkt, die über die geheimen Schlüssel und die Konfiguration verfügen, die zum Ausführen der Tests erforderlich sind, was in der Regel Produktionsbereitstellungen ausschließt. Funktionale Tests sollten nur die öffentliche API des Produkts verwenden.
Entwerfen von Produkten zur Testbarkeit
Organisationen in einem reifenden DevOps-Prozess haben eine umfassende Sicht darauf, was es bedeutet, ein Qualitätsprodukt im Rhythmus der Cloud zu liefern. Eine starke Verschiebung des Gleichgewichts zugunsten von Komponententests über Funktionstests erfordert Teams, Design- und Implementierungsoptionen zu treffen, die Die Testbarkeit unterstützen. Es gibt verschiedene Ideen darüber, was gut entworfenen und gut implementierten Code für die Testbarkeit darstellt, ebenso wie es unterschiedliche Codierungsstile gibt. Das Prinzip besteht darin, dass das Entwerfen für Die Testbarkeit zu einem Hauptteil der Diskussion über Design- und Codequalität werden muss.
Behandeln von Testcode als Produktcode
Explizit zu erklären, dass Testcode Produktcode ist, verdeutlicht, dass die Qualität des Testcodes ebenso wichtig für die Bereitstellung ist wie die des Produktcodes. Teams sollten Testcode auf die gleiche Weise behandeln, wie sie den Produktcode behandeln und dieselbe Sorgfalt auf das Design und die Implementierung von Tests und Testframeworks anwenden. Dieser Aufwand ähnelt der Verwaltung von Konfiguration und Infrastruktur als Code. Um vollständig zu sein, sollte eine Codeüberprüfung den Testcode einbeziehen und denselben Qualitätsmaßstäben wie dem Produktcode unterziehen.
Gemeinsame Testinfrastruktur verwenden
Senken Sie den Balken für die Verwendung der Testinfrastruktur, um vertrauenswürdige Qualitätssignale zu generieren. Anzeigen von Tests als gemeinsamer Dienst für das gesamte Team. Speichern Sie Komponententestcode zusammen mit dem Produktcode, und erstellen Sie ihn mit dem Produkt. Tests, die als Teil des Buildprozesses ausgeführt werden, müssen auch unter Entwicklungstools wie Azure DevOps ausgeführt werden. Wenn Tests in jeder Umgebung von der lokalen Entwicklung über die Produktion ausgeführt werden können, haben sie die gleiche Zuverlässigkeit wie der Produktcode.
Mach Codebesitzer für Tests verantwortlich
Testcode sollte sich neben dem Produktcode in einem Repository befinden. Damit Code an einer Komponentengrenze getestet werden kann, pushen Sie die Verantwortlichkeit für Tests an die Person, die den Komponentencode schreibt. Verlassen Sie sich nicht auf andere, um die Komponente zu testen.
Fallstudie: Schicht nach links mit Einheitentests
Ein Microsoft-Team hat beschlossen, ihre veralteten Testsuiten durch moderne DevOps-Unit-Tests und einen Shift-left-Ansatz zu ersetzen. Das Team verfolgte den Fortschritt in dreiwochenigen Sprints, wie in der folgenden Abbildung dargestellt. Das Diagramm umfasst Sprints 78-120, die 42 Sprints über 126 Wochen oder etwa zweieinhalb Jahre Aufwand darstellen.
Das Team startete bei 27.000 Alttests im Sprint 78 und erreichte null Alttests bei Sprint 120. Eine Reihe von L0- und L1-Komponententests ersetzten die meisten der alten Funktionstests. Neue L2-Tests ersetzten einige der Tests, und viele der alten Tests wurden gelöscht.
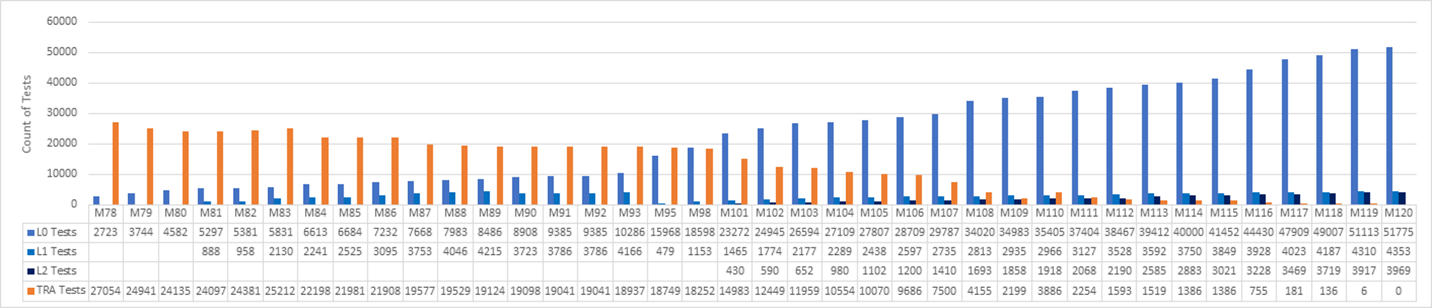
In einer Software-Reise, die über zwei Jahre dauert, gibt es viel zu lernen aus dem Prozess selbst. Insgesamt war der Aufwand, das Testsystem über zwei Jahre vollständig zu wiederholen, eine massive Investition. Nicht jedes Featureteam hat gleichzeitig gearbeitet. Viele Teams in der gesamten Organisation investierten Zeit in jeden Sprint, und in einigen Sprints war es am meisten von dem, was das Team getan hat. Obwohl es schwierig ist, die Kosten der Schicht zu messen, war es eine nicht verhandelbare Anforderung für die Qualität und die Leistungsziele des Teams.
Erste Schritte
Zu Beginn ließ das Team die alten Funktionstests, die als TRA-Tests bezeichnet werden, unverändert. Das Team wollte, dass Entwickler sich auf die Idee der Unit-Tests einlassen, insbesondere bei neuen Features. Der Fokus lag darauf, die Erstellung von L0- und L1-Tests so einfach wie möglich zu machen. Das Team musste zuerst diese Fähigkeit entwickeln und Schwung aufbauen.
Das vorangehende Diagramm zeigt, dass die Anzahl der Unit-Tests früh ansteigt, da das Team den Nutzen des Erstellens von Unit-Tests erkannte. Komponententests waren einfacher zu warten, schneller auszuführen und hatten weniger Fehler. Es war einfach, Unterstützung für die Ausführung aller Komponententests im Pull-Anforderungsfluss zu erhalten.
Das Team konzentrierte sich nicht auf das Schreiben neuer L2-Tests bis sprint 101. In der Zwischenzeit ging die TRA-Testanzahl von 27.000 auf 14.000 von Sprint 78 auf Sprint 101 zurück. Neue Komponententests ersetzten einige der TRA-Tests, aber viele wurden einfach gelöscht, basierend auf der Teamanalyse ihrer Nützlichkeit.
Die TRA-Tests sind von 2100 auf 3800 im Sprint 110 gestiegen, da weitere Tests im Quellbaum entdeckt und dem Graphen hinzugefügt wurden. Es stellte sich heraus, dass die Tests immer ausgeführt wurden, aber nicht ordnungsgemäß nachverfolgt wurden. Dies war keine Krise, aber es war wichtig, ehrlich zu sein und bei Bedarf neu zu bewerten.
Schneller werden
Nachdem das Team ein signal für kontinuierliche Integration (CI) hatte, das extrem schnell und zuverlässig war, wurde es zu einem vertrauenswürdigen Indikator für die Produktqualität. Der folgende Screenshot zeigt die Pullanforderung und die CI-Pipeline in Aktion und die Zeit, die es dauert, um verschiedene Phasen zu durchlaufen.
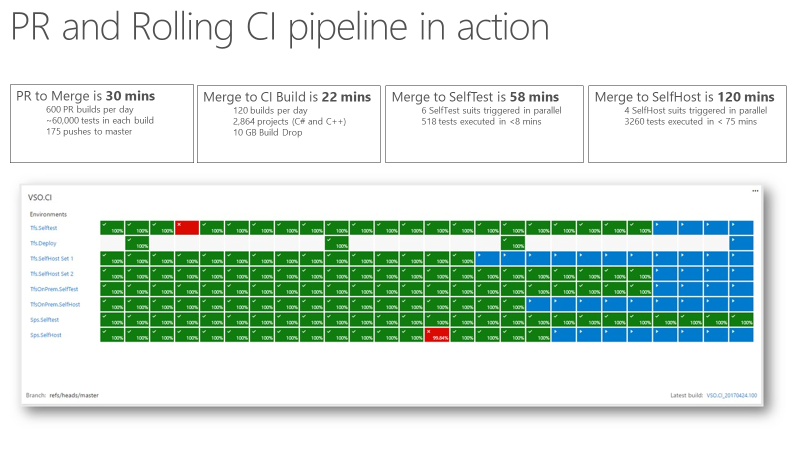
Es dauert etwa 30 Minuten, um von der Pullanforderung zum Zusammenführen zu wechseln, einschließlich der Ausführung von 60.000 Komponententests. Vom Code-Merge bis zum CI-Build dauert es etwa 22 Minuten. Das erste Qualitätssignal von CI, SelfTest, kommt nach etwa einer Stunde. Anschließend wird der Großteil des Produkts mit der vorgeschlagenen Änderung getestet. Innerhalb von zwei Stunden von Merge nach SelfHost wird das gesamte Produkt getestet und die Änderung ist bereit, in die Produktion zu gehen.
Verwenden von Metriken
Das Team nutzt eine Scorecard, wie im folgenden Beispiel gezeigt. Auf einer übergeordneten Ebene verfolgt die Scorecard zwei Arten von Metriken: Gesundheit oder Schulden und Leistung.
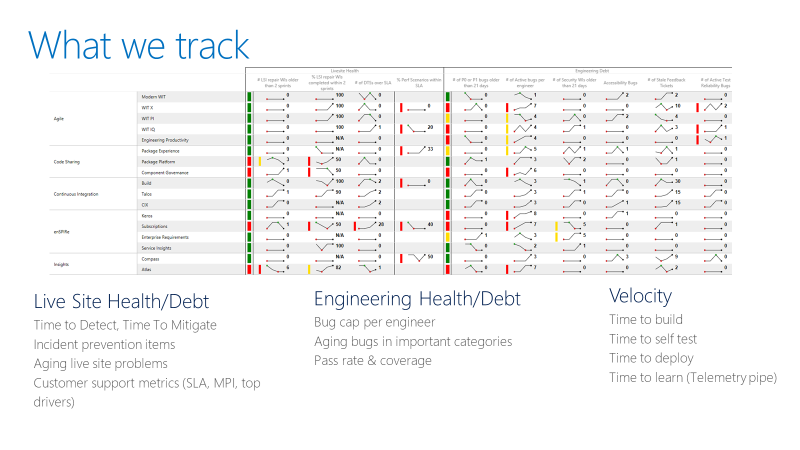
Bei Den Metriken für die Integrität von Livewebsites verfolgt das Team die Zeit für die Erkennung, die Zeit zur Entschärfung und die Anzahl der Reparaturelemente, die ein Team trägt. Ein Reparaturelement ist die Arbeit, die das Team in einer Live-Site-Retrospektive identifiziert, um ähnliche Vorfälle daran zu hindern, sich wiederholen zu können. Die Scorecard verfolgt auch, ob die Reparaturelemente von den Teams innerhalb eines angemessenen Zeitrahmens abgeschlossen werden.
Für Technische Integritätsmetriken verfolgt das Team aktive Fehler pro Entwickler. Wenn ein Team über mehr als fünf Fehler pro Entwickler verfügt, muss das Team das Beheben dieser Fehler priorisieren, bevor eine neue Featureentwicklung erfolgt. Das Team verfolgt auch veraltete Fehler in speziellen Kategorien wie Sicherheit.
Technische Geschwindigkeitsmetriken messen die Geschwindigkeit in verschiedenen Teilen der kontinuierlichen Integration und kontinuierlichen Lieferung (CI/CD)-Pipeline. Das Gesamtziel besteht darin, die Geschwindigkeit der DevOps-Pipeline zu erhöhen: Angefangen bei einer Idee, das Abrufen des Codes in die Produktion und das Empfangen von Daten von Kunden.