Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Shift right ist die Praxis, einige Tests später im DevOps-Prozess zu verschieben, um in der Produktion zu testen. Tests in der Produktion verwenden echte Bereitstellungen, um das Verhalten und die Leistung einer Anwendung in der Produktionsumgebung zu überprüfen und zu messen.
Eine Möglichkeit, mit der DevOps-Teams die Geschwindigkeit verbessern können, ist eine Umschalt-links-Teststrategie . Shift left pushs most testing earlier in the DevOps pipeline, to reduce the time for new code to reach production and operate zuverlässig.
Während viele Arten von Tests, z. B. Komponententests, leicht nach links verschoben werden können, können einige Testklassen nicht ausgeführt werden, ohne einen Teil oder alle Lösungen bereitzustellen. Die Bereitstellung in einem QA- oder Stagingdienst kann eine vergleichbare Umgebung simulieren, aber es gibt keinen vollständigen Ersatz für die Produktionsumgebung. Teams stellen fest, dass bestimmte Arten von Tests in der Produktion erfolgen müssen.
Tests in der Produktion bieten:
- Die volle Breite und Vielfalt der Produktionsumgebung.
- Die echte Arbeitsauslastung des Kundendatenverkehrs.
- Profile und Verhaltensweisen, wenn sich die Produktionsnachfrage im Laufe der Zeit weiterentwickelt.
Die Produktionsumgebung ändert sich ständig. Auch wenn sich eine App nicht ändert, hängt die Infrastruktur ständig von Änderungen ab. Tests in der Produktion validieren die Integrität und Qualität einer bestimmten Produktionsbereitstellung und der sich ständig ändernden Produktionsumgebung.
Das Verschieben von Recht auf Test in der Produktion ist für die folgenden Szenarien besonders wichtig:
Microservices-Bereitstellungen
Microservices-basierte Lösungen können über eine große Anzahl von Microservices verfügen, die unabhängig entwickelt, bereitgestellt und verwaltet werden. Das Verschieben von Tests ist für diese Projekte besonders wichtig, da unterschiedliche Versionen und Konfigurationen die Produktion auf vielfältige Weise erreichen können. Unabhängig von der Vorabproduktionstestabdeckung ist es erforderlich, die Kompatibilität in der Produktion zu testen.
Sicherstellen der Qualität nach der Bereitstellung
Die Veröffentlichung in die Produktion ist nur die Hälfte der Lieferung von Software. Die andere Hälfte stellt die Qualität im Maßstab mit einer echten Arbeitsauslastung in der Produktion sicher. Da sich die Umgebung ständig ändert, wird ein Team nie mit Tests in der Produktion durchgeführt.
Testdaten aus der Produktion sind buchstäblich die Testergebnisse aus der realen Kundenarbeitsauslastung. Tests in der Produktion umfassen Überwachung, Failovertests und Fehlereinfügung. Bei diesem Test werden Fehler, Ausnahmen, Leistungsmetriken und Sicherheitsereignisse nachverfolgt. Die Testtelemetrie hilft auch bei der Erkennung von Anomalien.
Bereitstellungsebenen
Um die Produktionsumgebung zu schützen, können Teams Änderungen schrittweise und kontrolliert bereitstellen, indem sie tierbasierte Bereitstellungen und Featurekennzeichnungen verwenden. Beispielsweise ist es besser, einen Fehler zu erfassen, der verhindert, dass ein Käufer seinen Kauf abschließt, wenn weniger als 1% von Kunden auf dieser Bereitstellungsebene sind, als nachdem alle Kunden gleichzeitig gewechselt wurden. Der Featurewert mit erkannten Fehlern muss die Nettoverluste dieser Fehler überschreiten, gemessen auf sinnvolle Weise für das jeweilige Unternehmen.
Die erste Ebene sollte die kleinste Größe sein, die zum Ausführen der Standardintegrationssuite erforderlich ist. Die Tests sind möglicherweise mit denen vergleichbar, die bereits früher in der Pipeline für andere Umgebungen ausgeführt wurden, aber Tests überprüfen, ob das Verhalten in der Produktionsumgebung identisch ist. Diese Stufe identifiziert offensichtliche Fehler, z. B. Fehlkonfigurationen, bevor sie sich auf Kunden auswirken.
Nachdem die erste Ebene überprüft wurde, kann die nächste Ebene erweitert werden, um eine Teilmenge von realen Benutzern für die Testausführung einzuschließen. Wenn alles gut aussieht, kann die Bereitstellung weitere Ebenen und Tests durchlaufen, bis jeder es verwendet. Die vollständige Bereitstellung bedeutet nicht, dass tests beendet sind. Das Nachverfolgen von Telemetrie ist für Tests in der Produktion von entscheidender Bedeutung.
Fehlereinfügung
Teams verwenden häufig Fehlerinjektions- und Chaostechnik, um zu sehen, wie sich ein System unter Fehlerbedingungen verhält. Diese Methoden helfen bei:
- Überprüfen Sie, ob implementierte Resilienzmechanismen tatsächlich funktionieren.
- Überprüfen Sie, ob ein Fehler in einem Subsystem innerhalb dieses Subsystems enthalten ist und nicht überlappend ist, um einen großen Ausfall zu erzeugen.
- Beweisen Sie, dass Reparaturarbeiten für einen vorherigen Vorfall die gewünschte Wirkung haben, ohne auf einen anderen Vorfall warten zu müssen.
- Erstellen Sie realistischere Schulungsbohrungen für Live-Site-Techniker, damit sie sich besser auf die Behandlung von Vorfällen vorbereiten können.
Es empfiehlt sich, Fehlereinfügungsversuche zu automatisieren, da sie teure Tests sind, die auf sich ständig ändernden Systemen ausgeführt werden müssen.
Chaos Engineering kann ein effektives Tool sein, sollte aber auf Canaryumgebungen beschränkt sein, die wenig oder keine Kundenwirkung haben.
Failovertests
Eine Form der Fehlereinfügung ist Failovertests zur Unterstützung von Geschäftskontinuität und Notfallwiederherstellung (BCDR). Teams sollten Failoverpläne für alle Dienste und Subsysteme haben. Die Pläne sollten Folgendes umfassen:
- Eine klare Erklärung über die geschäftlichen Auswirkungen des Diensts, die nach unten gehen.
- Eine Karte aller Abhängigkeiten in Bezug auf Plattform, Technologie und Personen, die die BCDR-Pläne erstellen.
- Formale Dokumentation der Notfallwiederherstellungsverfahren.
- Eine Häufigkeit zum regelmäßigen Ausführen von Notfallwiederherstellungs drills.
Fehlertests für Schaltkreisbrecher
Ein Schaltkreistrennmechanismus schneidet eine bestimmte Komponente von einem größeren System ab, in der Regel, um Fehler in dieser Komponente daran zu hindern, sich außerhalb seiner Grenzen zu verbreiten. Sie können Schaltkreisbrecher absichtlich auslösen, um die folgenden Szenarien zu testen:
Gibt an, ob ein Fallback funktioniert, wenn der Schaltkreisschalter geöffnet wird. Der Fallback funktioniert möglicherweise mit Komponententests, aber die einzige Möglichkeit, zu wissen, ob es sich in der Produktion wie erwartet verhält, besteht darin, einen Fehler einzusetzen, um ihn auszulösen.
Gibt an, ob der Schaltkreisschalter den richtigen Empfindlichkeitsschwellenwert aufweist, der bei Bedarf geöffnet werden soll. Fehlereinfügung kann Latenz erzwingen oder Abhängigkeiten trennen, um die Reaktionsfähigkeit der Unterbrechung zu beobachten. Es ist wichtig, nicht nur zu überprüfen, ob das richtige Verhalten auftritt, sondern dass es schnell genug geschieht.
Beispiel: Testen eines Redis-Cache-Schaltkreistrennzeichens
Der Redis-Cache verbessert die Produktleistung, indem der Zugriff auf häufig verwendete Daten beschleunigt wird. Betrachten Sie ein Szenario, das eine nicht kritische Abhängigkeit von Redis akzeptiert. Wenn Redis abläuft, sollte das System weiterhin funktionieren, da es auf die Verwendung der ursprünglichen Datenquelle für Anforderungen zurückgreifen kann. Um zu bestätigen, dass ein Redis-Fehler einen Schaltkreisschalter auslöst und dass der Fallback in der Produktion funktioniert, führen Sie regelmäßig Tests mit diesen Verhaltensweisen aus.
Das folgende Diagramm zeigt Tests für das Fallbackverhalten des Redis-Schaltkreises. Das Ziel besteht darin, sicherzustellen, dass Aufrufe, wenn der Breaker geöffnet wird, letztendlich zu SQL wechseln.
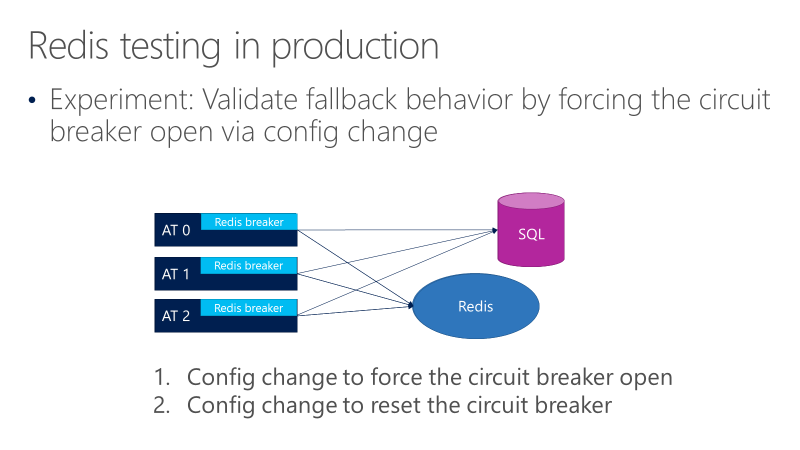
Das vorangehende Diagramm zeigt drei ATs mit den Brechern vor den Aufrufen von Redis. Ein Test erzwingt das Öffnen des Schaltkreisschalters durch eine Konfigurationsänderung und beobachtet dann, ob die Aufrufe an SQL gehen. Ein weiterer Test überprüft dann die entgegengesetzte Konfigurationsänderung, indem der Schaltkreisschalter geschlossen wird, um zu bestätigen, dass Anrufe wieder zu Redis zurückkehren.
Dieser Test überprüft, ob das Fallbackverhalten funktioniert, wenn der Breaker geöffnet wird. Es wird jedoch nicht überprüft, ob die Konfiguration des Schaltkreistrennschalters bei Bedarf den Halteschalter öffnet. Das Testen dieses Verhaltens erfordert die Simulation tatsächlicher Fehler.
Ein Fehler-Agent kann Fehler in Anrufen führen, die an Redis gehen. Das folgende Diagramm zeigt Tests mit Fehlereinfügung.
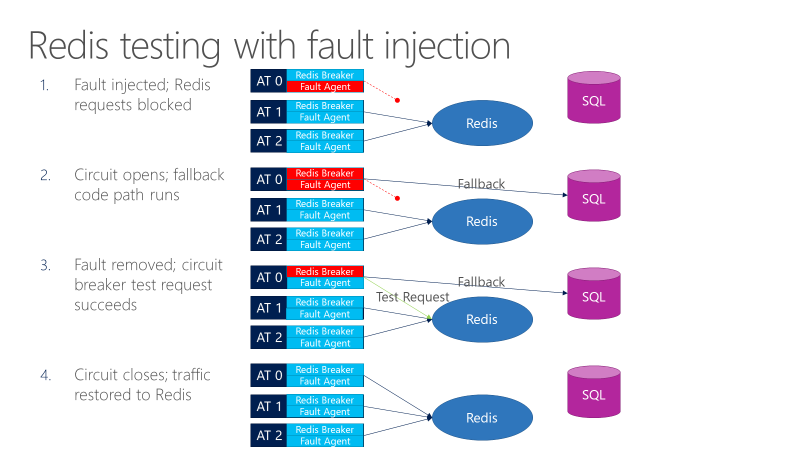
- Der Fehlerinjektor blockiert Redis-Anforderungen.
- Der Schaltkreisschalter wird geöffnet, und der Test kann beobachten, ob Fallback funktioniert.
- Der Fehler wird entfernt, und der Schaltkreisschalter sendet eine Testanforderung an Redis.
- Wenn die Anforderung erfolgreich ist, werden Aufrufe wieder auf Redis zurückgesetzt.
Weitere Schritte können die Empfindlichkeit des Unterbrechungsschalters testen, ob der Schwellenwert zu hoch oder zu niedrig ist und ob andere Systemtimeouts das Verhalten des Schaltkreistrenners beeinträchtigen.
Wenn der Breaker in diesem Beispiel nicht wie erwartet geöffnet oder geschlossen wird, kann dies zu einem Live site Incident (LSI) führen. Ohne den Fehlereinfügungstest wird das Problem möglicherweise nicht erkannt, da es schwierig ist, diese Art von Tests in einer Laborumgebung durchzuführen.
Nächste Schritte
- [Schichttests nach links mit Komponententests]umschalt-links
- Was sind Microservices?
- Ausführen eines Testfailovers (Notfallwiederherstellungs-Drilldown) zu Azure
- Sichere Bereitstellungsmethoden
- Was ist Überwachung?
- Was ist Plattform-Engineering?