Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Das 📦 Microsoft.Extensions.DataIngestion-Paket stellt grundlegende .NET-Bausteine für die Datenaufnahme bereit. Es ermöglicht Entwicklern das Lesen, Verarbeiten und Vorbereiten von Dokumenten für KI- und Machine Learning-Workflows, insbesondere Retrieval-Augmented Generation (RAG)-Szenarien.
Mit diesen Bausteinen können Sie robuste, flexible und intelligente Datenaufnahmepipelines erstellen, die auf Ihre Anwendungsanforderungen zugeschnitten sind:
- Einheitliche Dokumentdarstellung: Stellen Sie einen beliebigen Dateityp (z. B. PDF, Bild oder Microsoft Word) in einem konsistenten Format dar, das gut mit großen Sprachmodellen funktioniert.
- Flexible Datenintegration: Lesen Sie Dokumente sowohl aus Clouddiensten als auch aus lokalen Quellen mit mehreren integrierten Lesern, sodass Sie Daten problemlos von überall beziehen können.
- Integrierte KI-Verbesserungen: Inhalte automatisch mit Zusammenfassungen, Stimmungsanalyse, Stichwortextraktion und Klassifizierung anreichern, Ihre Daten für intelligente Workflows vorbereiten.
- Anpassbare Chunking-Strategien: Teilen Sie Dokumente mithilfe von tokenbasierten, abschnittsbasierten oder semantisch-basierten Ansätzen in Chunks auf, sodass Sie Ihre Abruf- und Analyseanforderungen optimieren können.
- Produktionsfertiger Speicher: Speichern Sie verarbeitete Blöcke in beliebten Vektordatenbanken und Dokumentspeichern, mit Unterstützung für die Generierung von Einbettungen, wodurch Ihre Pipelines für reale Szenarien bereit sind.
- End-to-End-Pipelinekomposition: Verkettung von Lesern, Prozessoren, Chunkern und Writern mit der IngestionPipeline<T> API, was Gerüstcode reduziert und es einfach macht, vollständige Workflows zu erstellen, anzupassen und zu erweitern.
- Leistung und Skalierbarkeit: Diese Komponenten sind für die skalierbare Datenverarbeitung konzipiert und können große Datenmengen effizient verarbeiten, sodass sie für Anwendungen auf Unternehmensniveau geeignet sind.
Alle diese Komponenten sind offen und erweiterbar. Sie können benutzerdefinierte Logik und neue Connectors hinzufügen und das System erweitern, um neue KI-Szenarien zu unterstützen. Durch die Standardisierung, wie Dokumente dargestellt, verarbeitet und gespeichert werden, können .NET-Entwickler zuverlässige, skalierbare und wartungsfähige Datenpipelinen erstellen, ohne das Rad für jedes Projekt neu zu erfinden.
Gebaut auf stabilen Fundamenten
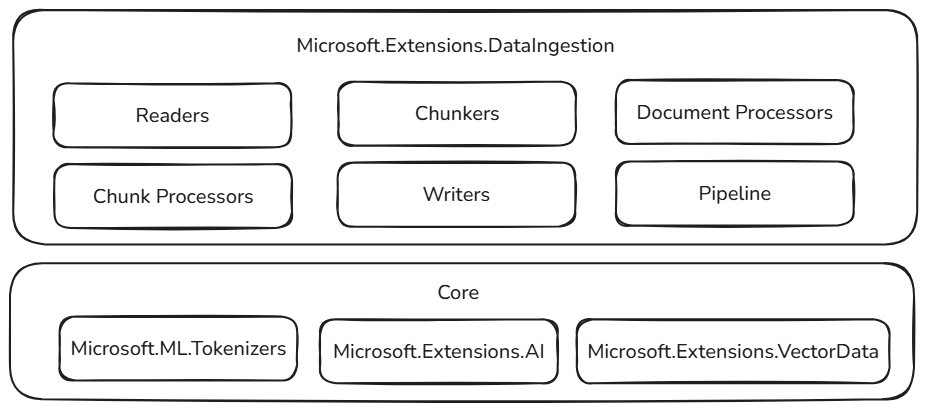
Diese Datenaufnahmebausteine basieren auf bewährten und erweiterbaren Komponenten im .NET-Ökosystem, sorgen für Zuverlässigkeit, Interoperabilität und nahtlose Integration mit vorhandenen KI-Workflows:
- Microsoft.ML.Tokenizers: Tokenizer stellen die Grundlage für die Segmentierung von Dokumenten basierend auf Tokens bereit. Dies ermöglicht eine präzise Aufteilung von Inhalten, die für die Vorbereitung von Daten für große Sprachmodelle und die Optimierung von Abrufstrategien unerlässlich sind.
- Microsoft.Extensions.AI: Dieser Satz von Bibliotheken treibt Anreicherungstransformationen mithilfe großer Sprachmodelle in Kraft. Es ermöglicht Features wie Zusammenfassung, Stimmungsanalyse, Stichwortextraktion und Einbettungsgenerierung, wodurch Ihre Daten mit intelligenten Erkenntnissen leicht verbessert werden können.
- Microsoft.Extensions.VectorData: Dieser Satz von Bibliotheken bietet eine konsistente Schnittstelle zum Speichern verarbeiteter Blöcke in einer Vielzahl von Vektorspeichern, einschließlich Qdrant, Azure SQL, CosmosDB, MongoDB, ElasticSearch und vielem mehr. Dadurch wird sichergestellt, dass Ihre Datenpipelines für die Produktion bereit sind und über verschiedene Speicher-Back-Ends skaliert werden können.
Zusätzlich zu vertrauten Mustern und Tools bauen diese Abstraktionen auf bereits erweiterbaren Komponenten auf. Plug-In-Fähigkeiten und Interoperabilität sind von größter Bedeutung. Während das restliche .NET KI-Ökosystem wächst, nehmen auch die Fähigkeiten der Datenaufnahmekomponenten zu. Mit diesem Ansatz können Entwickler neue Anbieter, Anreicherungen und Speicheroptionen problemlos integrieren, ihre Pipelines zukunftsfähig halten und an sich entwickelnde KI-Szenarien anpassen.
Siehe auch
Zusammenarbeit auf GitHub
Die Quelle für diesen Inhalt finden Sie auf GitHub, wo Sie auch Issues und Pull Requests erstellen und überprüfen können. Weitere Informationen finden Sie in unserem Leitfaden für Mitwirkende.