Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Tipp
Diese Inhalte sind ein Auszug aus dem E-Book „Architecting Cloud Native .NET Applications for Azure“, verfügbar in der .NET-Dokumentation oder als kostenlos herunterladbare PDF-Datei, die offline gelesen werden kann.

Nach dem Front-End-Client befassen wir uns nun mit der Kommunikation zwischen Back-End-Microservices.
Beim Erstellen einer cloudnativen Anwendung sollten Sie darauf achten, wie Back-End-Dienste miteinander kommunizieren. Im Idealfall heißt das: je weniger Kommunikation zwischen Diensten, desto besser. Dies lässt sich jedoch nicht stets vermeiden, da Back-End-Dienste zum Abschluss eines Vorgangs häufig voneinander abhängig sind.
Es gibt mehrere weit verbreitete Ansätze zur Implementierung der Kommunikation zwischen Diensten. Die Art der Kommunikationsinteraktion bestimmt häufig den besten Ansatz.
Betrachten Sie die folgenden Interaktionstypen:
Abfrage: Wenn ein aufrufender Microservice eine Antwort von einem aufgerufenen Microservice anfordert, z. B. „Käuferinformationen für eine bestimmte Kunden-ID angeben“.
Befehl: Wenn der aufrufende Microservice einen anderen Microservice benötigt, um eine Aktion auszuführen, aber keine Antwort benötigt, z. B. „Bestellung senden“.
Ereignis: Wenn ein Microservice, der als Herausgeber bezeichnet wird, ein Ereignis auslöst, dessen Zustand sich geändert hat oder eine Aktion aufgetreten ist. Andere Microservices, sog. Abonnenten, die interessiert sind, können auf das Ereignis angemessen reagieren. Herausgeber und Abonnenten wissen nichts voneinander.
Microservicesysteme nutzen in der Regel eine Kombination dieser Interaktionstypen, wenn Vorgänge ausgeführt werden, die eine Interaktion zwischen Diensten erfordern. Sehen wir uns die einzelnen Elemente und ihre Implementieren genau an.
Abfragen
Oft muss ein Microservice möglicherweise einen anderen abfragen, was zum Abschließen eines Vorgangs eine sofortige Antwort erfordert. Ein Microservice des Typs „Warenkorb“ benötigt möglicherweise Produktinformationen und einen Preis, um einen Artikel zu seinem Warenkorb hinzuzufügen. Es gibt viele Ansätze zum Implementieren von Abfragevorgängen.
Messaging vom Typ 'Anforderungsantwort'
Eine Möglichkeit zur Implementierung dieses Szenarios besteht darin, dass der aufrufende Back-End-Microservice direkte HTTP-Anforderungen an die Microservices richtet, die er abfragen muss (siehe Abbildung 4-8).
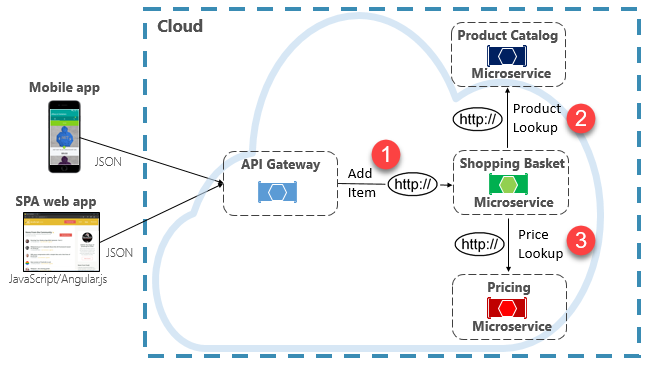
Abbildung 4-8. Direkte HTTP-Kommunikation
Während direkte HTTP-Aufrufe zwischen Microservices relativ einfach zu implementieren sind, sollte darauf geachtet werden, dass diese minimiert werden. Diese Aufrufe sind stets synchron und blockieren den Vorgang, bis ein Ergebnis zurückgegeben wird oder die Anforderung ein Timeout verursacht. Was einst eigenständige, unabhängige Dienste waren, die sich unabhängig voneinander entwickeln und häufig bereitgestellt werden konnten, ist heute miteinander gekoppelt. Mit zunehmender Kopplung zwischen Microservices nehmen die Vorteile ihrer Architektur ab.
Das Ausführen einer seltenen Anforderung, die einen einzelnen direkten HTTP-Aufruf an einen anderen Microservice richtet, kann für einige Systeme akzeptabel sein. Aufrufe mit hohem Volumen mit direkten HTTP-Aufrufe an mehrere Microservices sind jedoch nicht ratsam. Sie können Latenz erhöhen und sich negativ auf Leistung, Skalierbarkeit und Verfügbarkeit Ihres Systems auswirken. Schlimmer noch, eine lange Reihe direkter HTTP-Kommunikation kann zu tiefen und komplexen Ketten synchroner Aufrufe von Microservices führen, wie in Abbildung 4-9 dargestellt:
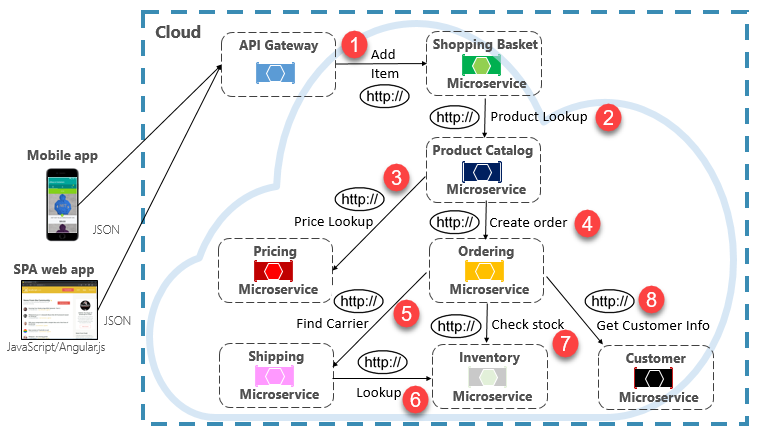
Abbildung 4-9. Verketten von HTTP-Abfragen
Sie können sich das Risiko bei dem in der vorherigen Abbildung gezeigten Entwurf sicherlich vorstellen. Was geschieht, wenn Schritt 3 fehlschlägt? Oder Schritt 8? Wie erfolgt die Wiederherstellung? Was geschieht, wenn Schritt 6 langsam ist, weil der zugrunde liegende Dienst ausgelastet ist? Wie fahren Sie fort? Selbst wenn alles ordnungsgemäß funktioniert, denken Sie an die Latenz, die bei diesem Aufruf auftreten würde, die die gesamte Latenz aller Schritte ist.
Das große Maß an Kopplung in der vorherigen Abbildung deutet darauf hin, dass die Dienste nicht optimal modelliert wurden. Es wäre gut, wenn das Team seinen Entwurf noch einmal überdenken würde.
Muster für materialisierte Sichten
Eine beliebte Option zum Aufheben der Kopplung von Microservices ist das Muster Materialisierte Sicht. Bei diesem Muster speichert ein Microservice seine eigene lokale, denormalisierte Kopie von Daten, die im Besitz anderer Diensten sind. Anstatt dass der Microservice „Warenkorb“ die Microservices „Produktkatalog“ und „Preise“ abfragt, verwaltet er eine eigene lokale Kopie dieser Daten. Dieses Muster beseitigt unnötige Kopplungen und verbessert Zuverlässigkeit und Reaktionszeit. Der gesamte Vorgang wird in einem einzelnen Prozess ausgeführt. Dieses Muster und andere Datenprobleme erkunden wir in Kapitel 5.
Dienstaggregatormuster
Eine weitere Option zum Beseitigen der Kopplung zwischen Microservices ist ein Microservice des Typs Aggregator, der in Abbildung 4-10 violett dargestellt ist.
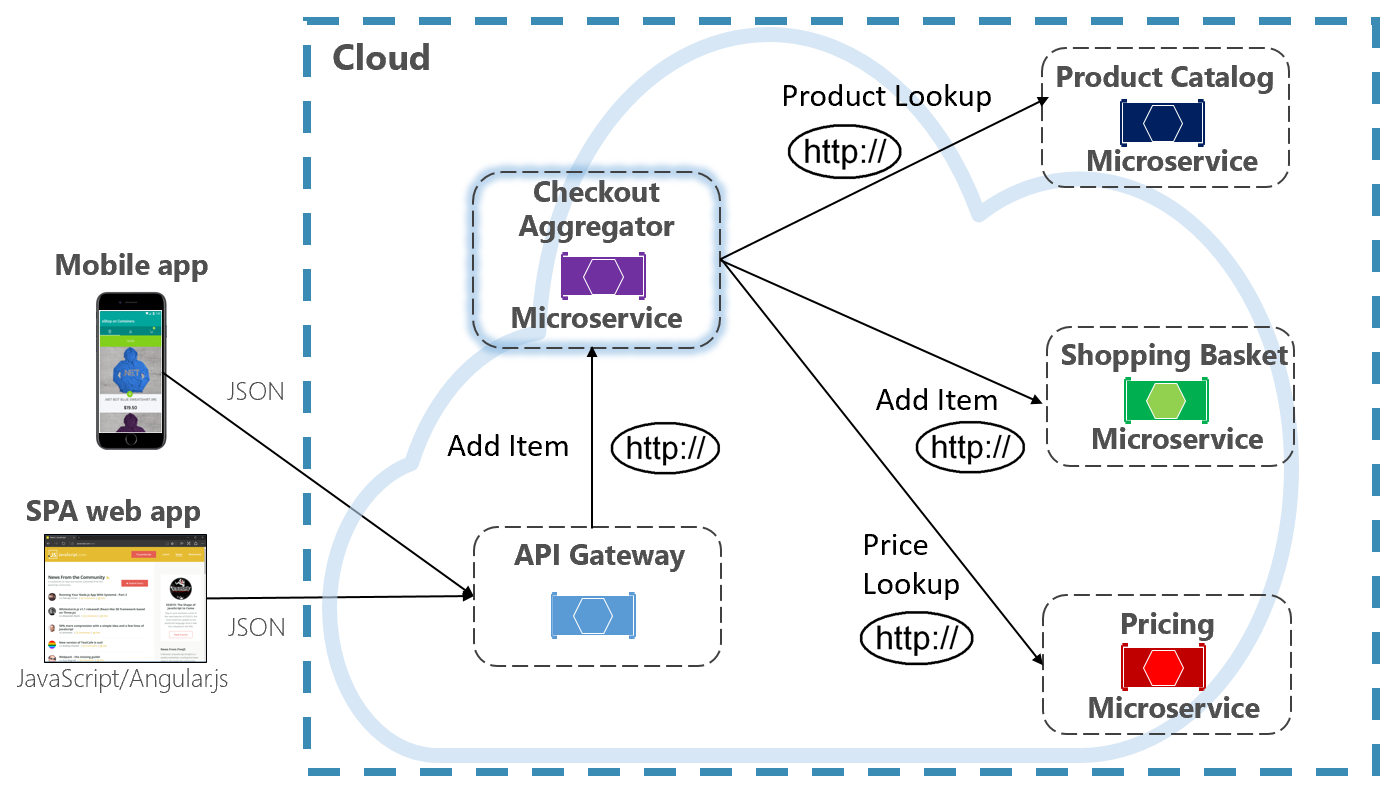
Abbildung 4-10. Microservice „Aggregator“
Das Muster isoliert einen Vorgang, der mehrere Back-End-Microservices aufruft, und zentralisiert seine Logik in einem spezialisierten Microservice. Der violette Microservice „Kassenaggregator“ in der vorherigen Abbildung orchestriert den Workflow für den Vorgang „Kasse“. Er enthält Aufrufe mehrerer Back-End-Microservices in einer festgelegten Reihenfolge. Daten aus dem Workflow werden aggregiert und an den Aufrufer zurückgegeben. Während er weiterhin direkte HTTP-Aufrufe implementiert, reduziert der Microservice „Aggregator“ direkte Abhängigkeiten zwischen Back-End-Microservices.
Anforderungs-/Antwortmuster
Ein weiterer Ansatz zum Entkoppeln synchroner HTTP-Nachrichten ist ein Anforderungs-Antwort-Muster mit Warteschlangenkommunikation. Die Kommunikation über eine Warteschlange erfolgt stets mithilfe eines unidirektionalen Kanals, wobei ein Produzent die Nachricht sendet, die vom Consumer empfangen wird. Bei diesem Muster werden sowohl eine Anforderungs- als auch eine Antwortwarteschlange implementiert, die in Abbildung 4-11 dargestellt ist.
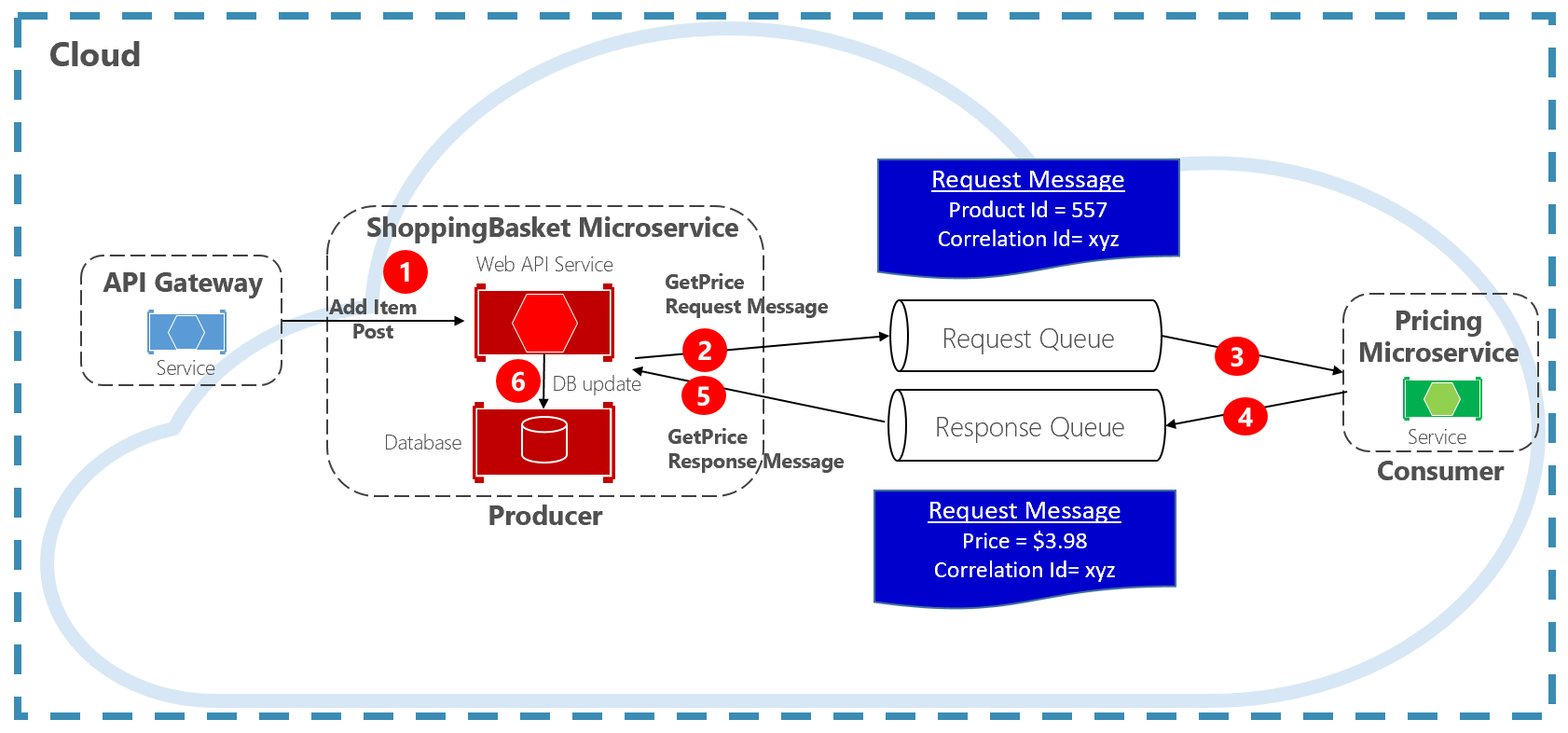
Abbildung 4-11. Anforderungs-/Antwortmuster
Hier erstellt der Nachrichtenproduzent eine abfragebasierte Nachricht, die eine eindeutige Korrelations-ID enthält, und platziert sie in einer Anforderungswarteschlange. Der nutzende Dienst entnimmt die Nachrichten der Warteschlange, verarbeitet sie und stellt die Antwort mit der gleichen Korrelations-ID in die Antwortwarteschlange. Der Producerdienst entnimmt die Nachricht der Warteschlange, gleicht sie mit der Korrelations-ID ab und verarbeitet sie weiter. Im nächsten Abschnitt werden Warteschlangen ausführlich behandelt.
Befehle
Eine andere Art der Kommunikationsinteraktion ist ein Befehl. Ein Microservice benötigt möglicherweise einen anderen Microservice, um eine Aktion auszuführen. Der Microservice „Bestellung“ benötigt möglicherweise den Microservice „Versand“, um für eine genehmigte Bestellung eine Sendung zu erstellen. In Abbildung 4-12 sendet ein Microservice, der als Producer bezeichnet wird, eine Nachricht an einen anderen Microservice, den Consumer, und fordert ihn auf, etwas zu tun.
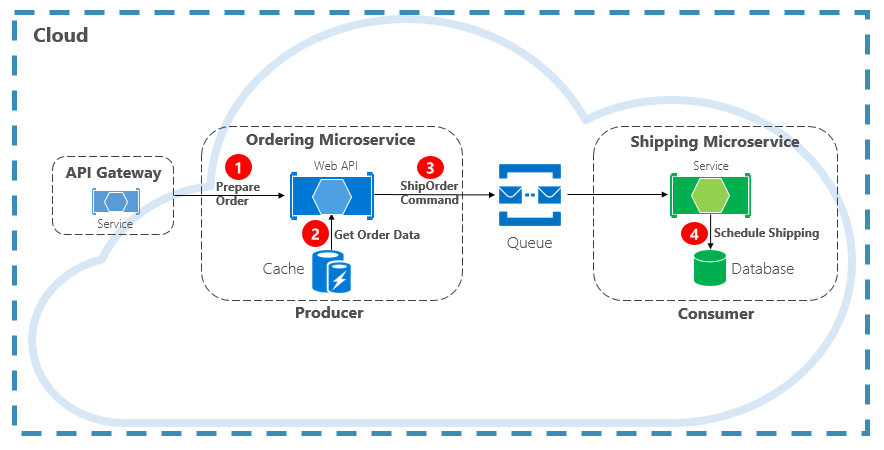
Abbildung 4-12. Befehlsinteraktion mit einer Warteschlange
In den meisten Fällen benötigt der Producer keine Antwort und kann die Nachricht auslösen und vergessen. Wenn eine Antwort benötigt wird, sendet der Consumer auf einem anderen Kanal eine separate Nachricht an den Producer zurück. Eine Befehlsnachricht wird am besten asynchron mithilfe einer Nachrichtenwarteschlange unterstützt von einem einfachen Nachrichtenbroker gesendet. Beachten Sie im vorherigen Diagramm, wie eine Warteschlange beide Dienste trennt und entkoppelt.
Da viele Nachrichtenwarteschlangen dieselbe Nachricht mehrmals senden können, die als mindestens einmal bezeichnet wird, muss der Verbraucher in der Lage sein, diese Szenarien mithilfe der relevanten idempotenten Nachrichtenverarbeitungsmuster korrekt zu identifizieren und zu verarbeiten.
Eine Nachrichtenwarteschlange ist ein zwischengeschaltetes Konstrukt, über das ein Producer und Consumer eine Nachricht übergeben. Warteschlangen implementieren ein asynchrones Punkt-zu-Punkt-Messagingmuster. Der Producer weiß, wo ein Befehl gesendet werden muss, und leitet ihn entsprechend weiter. Die Warteschlange garantiert, dass eine Nachricht von genau einer der Consumerinstanzen verarbeitet wird, die Daten aus dem Kanal lesen. In diesem Szenario kann entweder der Producer- oder Consumerdienst aufskaliert werden, ohne dass sich dies auf den anderen Dienst auswirkt. Außerdem können Technologien auf jeder Seite unterschiedlich sein, was bedeutet, dass wir möglicherweise einen Java-Microservice haben, der einen Golang-Microservice aufruft.
In Kapitel 1 haben wir über unterstützende Dienste gesprochen. Unterstützende Dienste sind zusätzliche Ressourcen, von denen cloudnative Systeme abhängen. Nachrichtenwarteschlangen sind unterstützende Dienste. Die Azure-Cloud unterstützt zwei Arten von Nachrichtenwarteschlangen, die Ihre cloudnativen Systeme nutzen können, um Befehlsmessaging zu implementieren: Azure Storage-Warteschlangen und Azure Service Bus-Warteschlangen.
Azure Storage-Warteschlangen
Azure Storage-Warteschlangen bieten eine einfache Warteschlangeninfrastruktur, die schnell, kostengünstig und von Azure-Speicherkonten unterstützt wird.
Azure Storage-Warteschlangen weisen einen REST-basierten Warteschlangenmechanismus mit zuverlässigem und persistentem Messaging auf. Sie bieten einen minimalen Featuresatz, sind aber kostengünstig und können Millionen von Nachrichten speichern. Ihre maximale Kapazität ist 500 TB. Eine einzelne Nachricht kann bis zu 64 KB groß sein.
Sie können überall auf der Welt über authentifizierte Aufrufe mithilfe von HTTP oder HTTPS auf Nachrichten zugreifen. Speicherwarteschlangen können auf eine große Anzahl gleichzeitiger Clients aufskaliert werden, um Datenverkehrsspitzen zu bewältigen.
Allerdings gelten Einschränkungen für den Dienst:
Die Nachrichtenreihenfolge ist nicht garantiert.
Eine Nachricht kann nur sieben Tage beibehalten werden, ehe sie automatisch entfernt wird.
Unterstützung für Zustandsverwaltung, Duplikaterkennung oder Transaktionen wird nicht geboten.
Abbildung 4-13 zeigt die Hierarchie einer Azure Storage-Warteschlange.
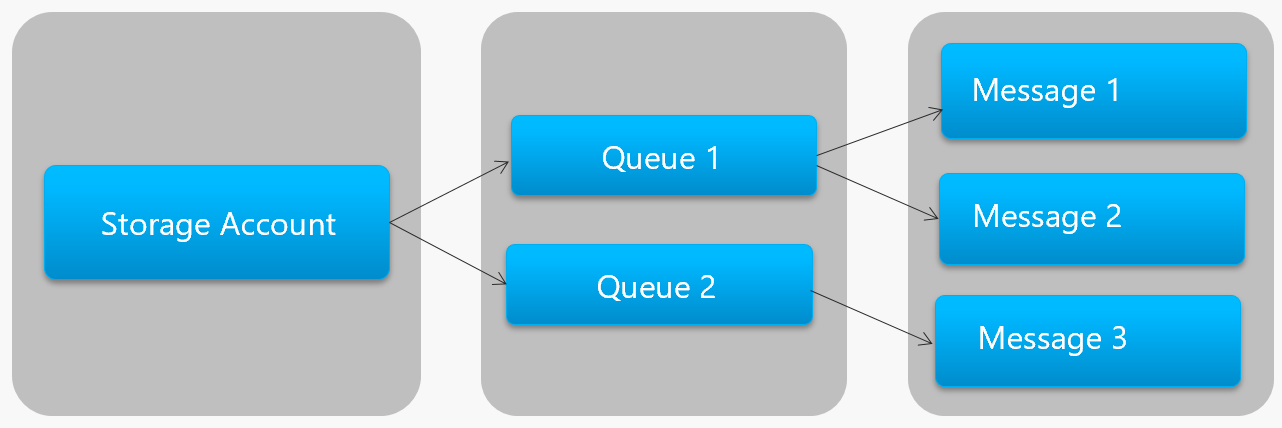
Abbildung 4-13. Hierarchie der Azure Storage-Warteschlange
Beachten Sie in der vorherigen Abbildung, wie Speicherwarteschlangen ihre Nachrichten im zugrunde liegenden Azure Storage-Konto speichern.
Für Entwickler stellt Microsoft mehrere client- und serverseitige Bibliotheken für die Verarbeitung von Azure Storage-Warteschlangen bereit. Die meisten wichtigen Plattformen werden unterstützt, einschließlich .NET, Java, JavaScript, Ruby, Python und Go. Entwickler sollten niemals direkt mit diesen Bibliotheken kommunizieren. Denn dadurch wird Ihr Microservicecode eng mit dem Azure Storage-Warteschlangendienst gekoppelt. Es empfiehlt sich, die Implementierungsdetails der API zu isolieren. Führen Sie eine Zwischenebene bzw. Zwischen-API ein, die generische Vorgänge verfügbar macht und die konkrete Bibliothek kapselt. Durch diese lose Kopplung können Sie einen Warteschlangendienst gegen einen anderen austauschen, ohne Änderungen am Hauptdienstcode vornehmen zu müssen.
Azure Storage-Warteschlangen sind eine wirtschaftliche Option zum Implementieren von Befehlsmessaging in Ihren cloudnativen Anwendungen. Insbesondere dann, wenn die Größe der Warteschlange 80 GB übersteigt oder ein einfacher Featuresatz akzeptabel ist. Sie zahlen nur für die Speicherung der Nachrichten. Es fallen keine festen Gebühren pro Stunde an.
Azure Service Bus-Warteschlangen
Bei komplexeren Messaginganforderungen sollten Sie Azure Service Bus-Warteschlangen in Betracht ziehen.
Aufsetzend auf einer zuverlässigen Nachrichteninfrastruktur unterstützt Azure Service Bus ein Messagingmodell mit Broker. Nachrichten werden zuverlässig in einem Broker (der Warteschlange) gespeichert, bis sie vom Consumer empfangen werden. Die Warteschlange garantiert die FIFO-Übermittlung (First-In/First-Out) von Nachrichten, wobei die Reihenfolge berücksichtigt wird, in der Nachrichten der Warteschlange hinzugefügt wurden.
Die Größe einer Nachricht kann viel größer sein, nämlich bis zu 256 KB. Nachrichten werden für einen unbegrenzten Zeitraum in der Warteschlange beibehalten. Azure Service Bus unterstützt nicht nur HTTP-basierte Aufrufe, sondern bietet auch vollständige Unterstützung für das Protokoll AMQP. AMQP ist ein anbieterübergreifender offener Standard, der ein binäres Protokoll und höhere Zuverlässigkeitsgrade unterstützt.
Azure Service Bus bietet eine Vielzahl von Features, einschließlich Transaktionsunterstützung und einer Erkennungsfunktion für Duplikate. Die Warteschlange garantiert pro Nachricht höchstens eine Zustellung. Eine bereits gesendete Nachricht wird automatisch verworfen. Wenn ein Producer Zweifel hat, kann er dieselbe Nachricht erneut senden, und Service Bus garantiert, dass nur eine Kopie verarbeitet wird. Die Duplikaterkennung befreit Sie von der Notwendigkeit, zusätzliche Infrastruktur aufzubauen.
Zwei weitere Unternehmensfeatures sind Partitionierung und Sitzungen. Eine herkömmliche Service Bus-Warteschlange wird von einem einzelnen Nachrichtenbroker verarbeitet und in einem einzelnen Nachrichtenspeicher gespeichert. Die Service Bus-Partitionierung verteilt die Warteschlange jedoch auf mehrere Nachrichtenbroker und -speicher. Der Gesamtdurchsatz wird nicht mehr durch die Leistung eines einzelnen Nachrichtenbrokers oder -speichers eingeschränkt. Ein vorübergehender Ausfall eines Nachrichtenspeichers führt nicht dazu, dass eine partitionierte Warteschlange nicht mehr verfügbar ist.
Service Bus-Sitzungen bieten eine Möglichkeit zum Gruppieren von Nachrichten. Stellen Sie sich ein Workflowszenario vor, in dem Nachrichten zusammen verarbeitet müssen und der Vorgang am Ende abgeschlossen werden muss. Um den Vorteil nutzen zu können, müssen Sitzungen explizit für die Warteschlange aktiviert sein, und jede zugehörige Nachricht muss dieselbe Sitzungs-ID enthalten.
Es gibt jedoch einige wichtige Vorbehalte: Die Größe von Service Bus-Warteschlangen ist auf 80 GB begrenzt, was viel weniger ist als das, was von Speicherwarteschlangen geboten wird. Darüber hinaus fallen für Service Bus-Warteschlangen Basiskosten und -gebühren pro Vorgang an.
Abbildung 4-14 zeigt die allgemeine Architektur einer Service Bus-Warteschlange.
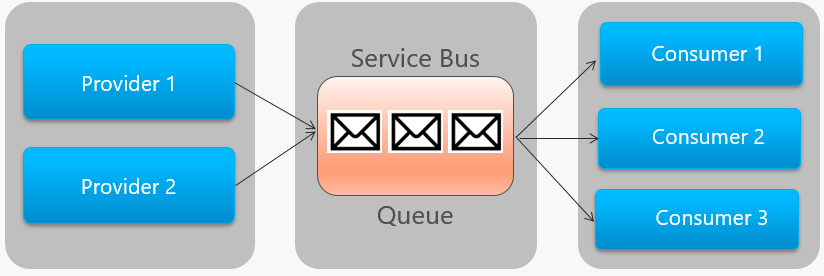
Abbildung 4-14. Service Bus-Warteschlange
Beachten Sie in der vorherigen Abbildung die Punkt-zu-Punkt-Beziehung. Zwei Instanzen desselben Anbieters stellen Nachrichten in eine einzelne Service Bus-Warteschlange. Jede Nachricht wird nur von einer von drei Consumerinstanzen auf der rechten Seite genutzt. Als Nächstes besprechen wir die Implementierung von Messaging, bei dem verschiedene Consumer an derselben Nachricht interessiert sein können.
Ereignisse
Das Stellen von Nachrichten in eine Warteschlange ist eine effektive Methode zur Implementierung der Kommunikation, bei der ein Producer einem Consumer asynchron eine Nachricht senden kann. Was geschieht jedoch, wenn viele verschiedene Consumer an derselben Nachricht interessiert sind? Eine dedizierte Nachrichtenwarteschlange für jeden Consumer ließe sich nicht gut skalieren und wäre schwierig zu verwalten.
Für dieses Szenario greifen wir auf den dritten Typ der Nachrichteninteraktion zurück, das Ereignis. Ein Microservice meldet, dass eine Aktion stattgefunden hat. Andere Microservices reagieren bei Interesse auf die Aktion bzw. das Ereignis. Dies wird auch als ereignisgesteuerter Architekturstil bezeichnet.
Die Ereignisverwaltung umfasst zwei Schritte. Für eine bestimmte Zustandsänderung veröffentlicht ein Microservice ein Ereignis für einen Nachrichtenbroker und stellt es jedem anderen interessierten Microservice zur Verfügung. Der interessierte Microservice wird benachrichtigt, indem er das Ereignis im Nachrichtenbroker abonniert. Sie verwenden das Veröffentlichen/Abonnieren-Muster, um die ereignisbasierte Kommunikation zu implementieren.
Abbildung 4-15 zeigt einen Microservice des Typs „Warenkorb“, der ein Ereignis mit zwei anderen Microservices veröffentlicht, die es abonniert haben.
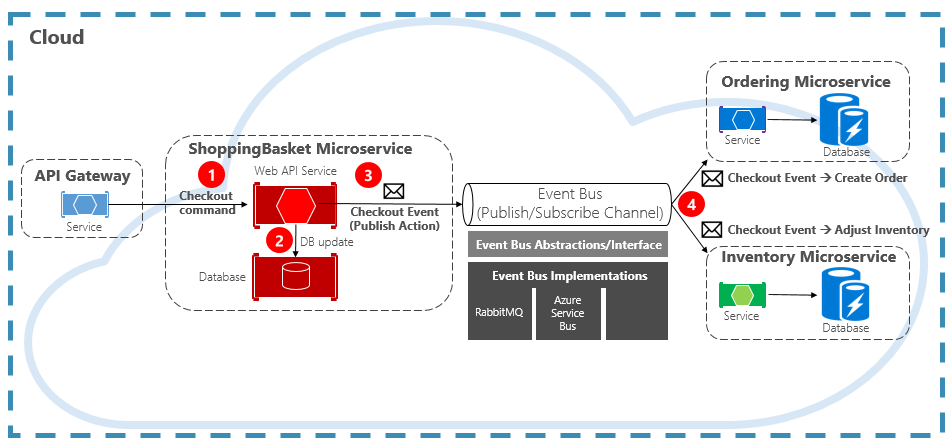
Abbildung 4-15. Ereignisgesteuertes Messaging
Beachten Sie die Komponente Ereignisbus, die sich in der Mitte des Kommunikationskanals befindet. Es handelt sich um eine benutzerdefinierte Klasse, die den Nachrichtenbroker kapselt und von der zugrunde liegenden Anwendung entkoppelt. Die Microservices „Bestellung“ und „Bestand“ führen das Ereignis unabhängig voneinander durch, ohne dass sie voneinander oder vom Microservice „Warenkorb“ Kenntnis haben. Wenn das registrierte Ereignis im Ereignisbus veröffentlicht wird, reagieren sie entsprechend.
Mit der Ereignisverwaltung wechseln wir von der Warteschlangentechnologie zu Themen. Ein Thema ähnelt einer Warteschlange, unterstützt aber ein 1:n-Messagingmuster. Ein Microservice veröffentlicht eine Nachricht. Mehrere abonnierende Microservices können diese Nachricht empfangen und darauf reagieren. Abbildung 4-16 zeigt eine Themenarchitektur.
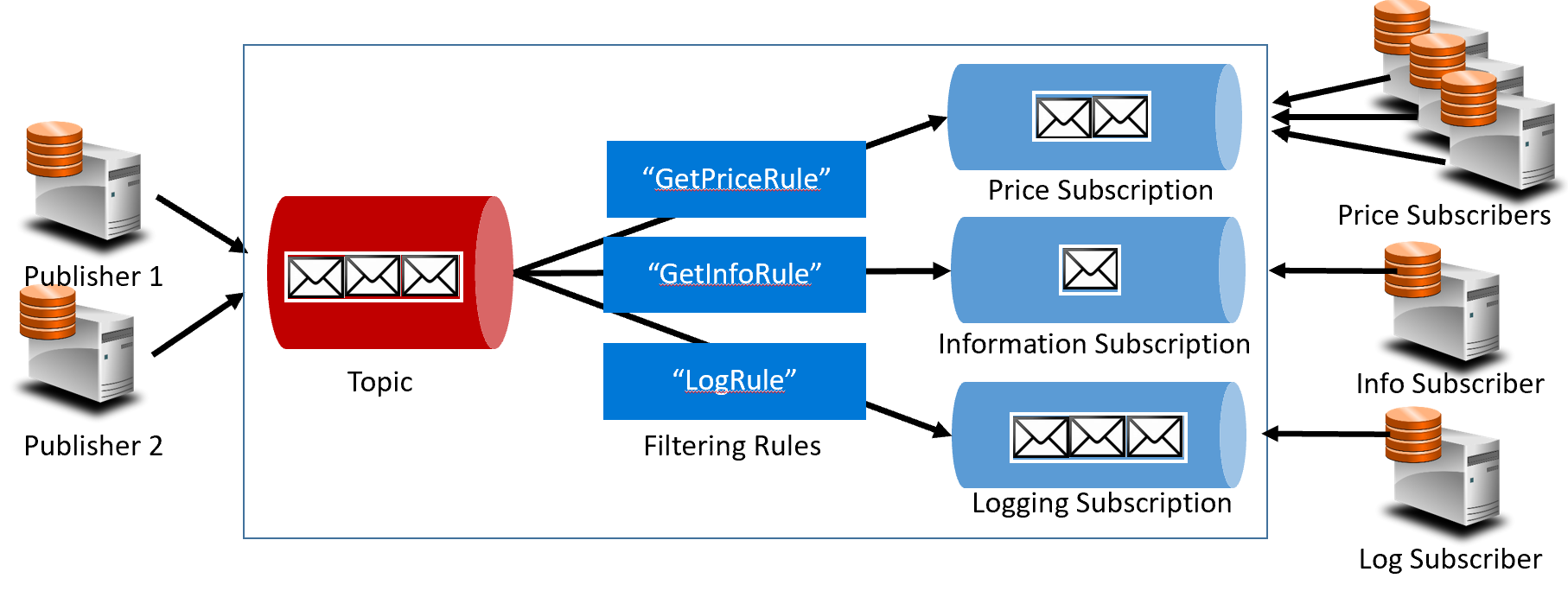
Abbildung 4-16. Themenarchitektur
In der vorherigen Abbildung senden Herausgeber Nachrichten an das Thema. Am Ende erhalten Abonnenten Nachrichten von Abonnements. In der Mitte leitet das Thema Nachrichten auf Grundlage einer Reihe von Regeln an Abonnements weiter, die in dunkelblauen Kästchen dargestellt sind. Regeln fungieren als Filter, die bestimmte Nachrichten an ein Abonnement weiterleiten. Hier wird das Ereignis GetPrice an die Abonnements „Preis“ und „Protokollierung“ gesendet, da das protokollierte Abonnement sich für den Empfang aller Nachrichten entschieden hat. Das Ereignis GetInformation wird an die Informations- und Protokollierungsabonnements gesendet.
Die Azure-Cloud unterstützt zwei Themendienste: Azure Service Bus-Themen und Azure Event Grid.
Azure Service Bus-Themen
Azure Service Bus-Themen setzen auf dem gleichen zuverlässigen Nachrichtenmodell mit Brokern von Azure Service Bus-Warteschlangen auf. Ein Thema kann Nachrichten von mehreren unabhängigen Herausgebern empfangen und Nachrichten an bis zu 2.000 Abonnenten senden. Abonnements können zur Laufzeit dynamisch hinzugefügt oder entfernt werden, ohne das System beenden oder das Thema neu erstellen zu müssen.
Viele erweiterte Features von Azure Service Bus-Warteschlangen sind auch für Themen verfügbar, einschließlich Duplikaterkennung und Transaktionsunterstützung. Standardmäßig wird ein Service Bus-Thema von einem einzelnen Nachrichtenbroker verarbeitet und in einem einzelnen Nachrichtenspeicher gespeichert. Doch die Service Bus-Partitionierung skaliert ein Thema so, dass es auf viele Nachrichtenbroker und -speicher verteilt wird.
Bei der geplanten Nachrichtenzustellung wird eine Nachricht mit einem bestimmten Verarbeitungszeitpunkt markiert. Die Nachricht wird vor diesem Zeitpunkt nicht im Thema angezeigt. Mit der Nachrichtenverzögerung können Sie den Abruf einer Nachricht auf einen späteren Zeitpunkt zurückstellen. Beide werden üblicherweise in Szenarien zur Verarbeitung von Workflows verwendet, in denen Vorgänge in einer bestimmten Reihenfolge verarbeitet werden. Sie können die Verarbeitung empfangener Nachrichten solange zurückstellen, bis die vorherigen Aufgaben abgeschlossen sind.
Service Bus-Themen sind eine zuverlässige und bewährte Technologie zum Ermöglichen der Veröffentlichen-/Abonnieren-Kommunikation in Ihren cloudnativen Systemen.
Azure-Ereignisraster
Während Azure Service Bus ein erprobter Messagingbroker mit einer vollständigen Palette von Unternehmensfeatures ist, ist Azure Event Grid noch relativ neu.
Auf den ersten Blick erinnert Event Grid an ein weiteres themenbasiertes Messagingsystem. Es ist jedoch in vielerlei Hinsicht anders. Die Lösung ist auf ereignisgesteuerte Workloads ausgerichtet und ermöglicht die Verarbeitung von Ereignissen in Echtzeit, eine tiefgreifende Integration in Azure und eine offene Plattform – alles in einer serverlosen Infrastruktur. Sie ist für moderne cloudnative und serverlose Anwendungen konzipiert.
Als zentrale Backplane für Ereignisse bzw. Pipe reagiert Event Grid auf Ereignisse innerhalb von Azure-Ressourcen und Ihren eigenen Diensten.
Ereignisbenachrichtigungen werden in einem Event Grid-Thema veröffentlicht, das wiederum jedes Ereignis an ein Abonnement weiterleitet. Abonnenten ordnen Abonnements zu und nutzen die Ereignisse. Genau wie Service Bus unterstützt Event Grid ein gefiltertes Abonnentenmodell, bei dem ein Abonnement eine Regel für die Ereignisse festlegt, die empfangen werden sollen. Event Grid bietet schnellen Durchsatz mit einer Garantie von 10 Mio. Ereignissen pro Sekunde, ermöglicht die Zustellung nahezu in Echtzeit und ist somit weitaus leistungsstärker als Azure Service Bus.
Ein Pluspunkt für Event Grid ist die tiefgreifende Integration in das Fabric der Azure-Infrastruktur. Eine Azure-Ressource, z. B. Cosmos DB, kann integrierte Ereignisse direkt in anderen interessierten Azure-Ressourcen veröffentlichen, ohne dass benutzerdefinierter Code erforderlich ist. Event Grid kann Ereignisse in einem Azure-Abonnement, einer Ressourcengruppe oder einem Dienst veröffentlichen, sodass Entwickler den Lebenszyklus von Cloudressourcen präzise steuern können. Event Grid ist jedoch nicht auf Azure beschränkt. Es handelt sich um eine offene Plattform, die benutzerdefinierte HTTP-Ereignisse nutzen kann, die von Anwendungen oder Diensten von Drittanbietern veröffentlicht werden, und Ereignisse an externe Abonnenten weiterleitet.
Zum Veröffentlichen und Abonnieren nativer Ereignisse aus Azure-Ressourcen ist keine Programmierung erforderlich. Mit einer einfachen Konfiguration können Sie Ereignisse von einer Azure-Ressource in eine andere integrieren, indem Sie die Integration von Themen und Abonnements nutzen. Abbildung 4-17 zeigt den Aufbau von Event Grid.
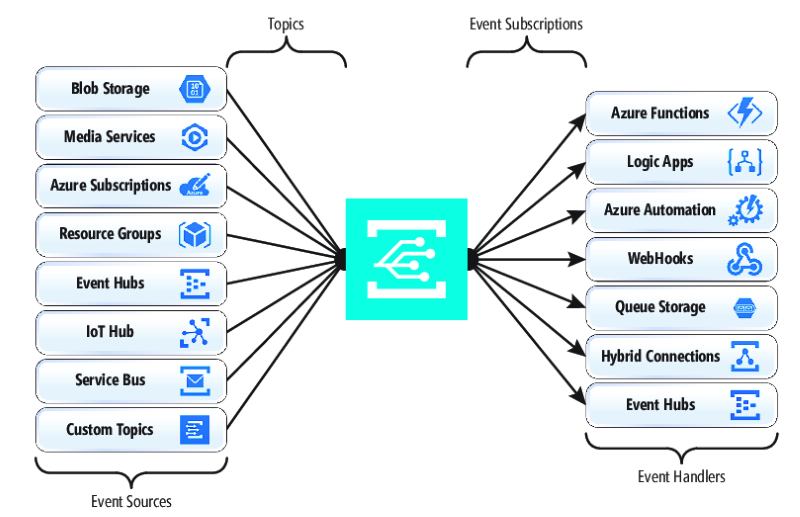
Abbildung 4-17. Aufbau von Event Grid
Ein wichtiger Unterschied zwischen Event Grid und Service Bus ist das zugrunde liegende Nachrichtenaustauschmuster.
Service Bus implementiert ein Pullmodell im älteren Stil, bei dem der nachgeschaltete Abonnent das Themenabonnement aktiv auf neue Nachrichten abruft. Auf der anderen Seite gibt dieser Ansatz dem Abonnenten die volle Kontrolle über das Tempo, mit dem Nachrichten verarbeitet werden. Er steuert, wann und wie viele Nachrichten zu einem bestimmten Zeitpunkt verarbeitet werden sollen. Ungelesene Nachrichten verbleiben im Abonnement, bis sie verarbeitet werden. Ein erhebliches Manko ist die Latenz zwischen dem Zeitpunkt, an dem das Ereignis generiert wird, und dem Abfragevorgang, der diese Nachricht zur Verarbeitung per Pull an den Abonnenten weiterleitet. Außerdem werden durch den Aufwand des ständigen Abfragens des nächsten Ereignisses Ressourcen und Finanzmittel in Anspruch genommen.
Event Grid ist dagegen anders. Es implementiert ein Pushmodell, bei dem Ereignisse wie empfangen an die Ereignishandler gesendet werden, wodurch die Ereigniszustellung nahezu in Echtzeit erfolgt. Außerdem werden Kosten gesenkt, da der Dienst nur dann ausgelöst wird, wenn er zum Nutzen eines Ereignisses benötigt wird – und nicht ständig wie beim Abfragen. Das heißt, ein Ereignishandler muss die eingehende Last verarbeiten und Drosselungsmechanismen bereitstellen, um sich vor Überlastung zu schützen. Viele Azure-Dienste, die diese Ereignisse nutzen, z. B. Azure Functions und Logic Apps, bieten automatische Skalierungsfunktionen, um erhöhte Lasten zu bewältigen.
Event Grid ist ein vollständig verwalteter serverloser Clouddienst. Der Dienst wird dynamisch basierend auf Ihrem Datenverkehr skaliert und stellt Ihnen nur Ihre tatsächliche Nutzung und keine vorab erworbene Kapazität in Rechnung. Die ersten 100.000 Vorgänge pro Monat sind kostenlos. Zu diesen Vorgängen zählen der Eingang von Ereignissen (eingehende Ereignisbenachrichtigungen), Zustellversuche für Abonnements, Verwaltungsaufrufe und die Filterung nach Themen. Bei einer Verfügbarkeit von 99,99 % garantiert Event Grid die Zustellung eines Ereignisses innerhalb von 24 Stunden mit integrierter Wiederholungsfunktion bei nicht erfolgreicher Zustellung. Nicht zugestellte Nachrichten können zur Auflösung in eine Warteschlange für unzustellbare Nachrichten verschoben werden. Im Gegensatz zu Azure Service Bus ist Event Grid für schnelle Leistung optimiert und unterstützt keine Features wie geordnetes Messaging, Transaktionen und Sitzungen.
Streamen von Nachrichten in die Azure-Cloud
Azure Service Bus und Event Grid unterstützen besonders Anwendungen, die einzelne, diskrete Ereignisse verfügbar machen, z. B. wenn ein neues Dokument in eine Cosmos DB-Datenbank eingefügt wurde. Was aber, wenn Ihr cloudnatives System einen Stream zusammengehöriger Ereignisse verarbeiten muss? Ereignisstreams sind komplexer. Sie sind in der Regel zeitlich geordnet, stehen miteinander in Beziehung und müssen als Gruppe verarbeitet werden.
Azure Event Hub ist eine Datenstreamingplattform und ein Ereigniserfassungsdienst, der Ereignisse sammelt, transformiert und speichert. Er ist optimiert für die Erfassung von Streamingdaten, wie z. B. kontinuierliche Ereignisbenachrichtigungen, die in einem Telemetriekontext ausgegeben werden. Der Dienst ist überaus skalierbar und kann Millionen von Ereignissen pro Sekunde speichern und verarbeiten. Wie in Abbildung 4-18 zu sehen, dient er oft als Zugang zu einer Ereignispipeline, die den Erfassungsstream von der Nutzung der Ereignisse entkoppelt.
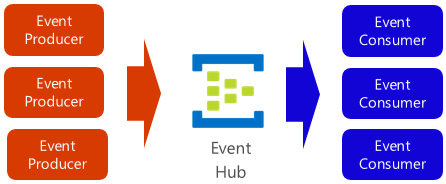
Abbildung 4-18. Azure Event Hub
Event Hub bietet niedrige Latenz und eine konfigurierbare zeitliche Aufbewahrung. Im Gegensatz zu Warteschlangen und Themen behalten Event Hubs-Instanzen Ereignisdaten bei, nachdem sie von einem Consumer gelesen wurden. Dieses Feature ermöglicht es anderen internen und externen Datenanalysediensten, die Daten zur weiteren Analyse wiederzuverwenden. In der Event Hub-Instanz gespeicherte Ereignisse werden nur nach Ablauf des Aufbewahrungszeitraums gelöscht, der standardmäßig ein Tag ist, sich aber konfigurieren lässt.
Event Hub unterstützt gängige Ereignisveröffentlichungsprotokolle, einschließlich HTTPS, AMQP und auch Kafka 1.0. Vorhandene Kafka-Anwendungen können mithilfe des Protokolls Kafka mit Event Hub kommunizieren, was eine Alternative zur Verwaltung großer Kafka-Cluster darstellt. Viele cloudnative Open-Source-Systeme nutzen Kafka.
Azure Event Hubs ermöglicht Nachrichtenstreaming über ein partitioniertes Consumermuster, bei dem jeder Consumer nur eine bestimmte Teilmenge bzw. Partition des Nachrichtendatenstroms liest. Dieses Muster ermöglicht enorme horizontale Skalierung für die Ereignisverarbeitung und stellt weitere datenstromorientierte Features zur Verfügung, die in Warteschlangen und Themen nicht verfügbar sind. Eine Partition ist eine geordnete Sequenz von Ereignissen, die in einem Event Hub besteht. Neu eingehende Ereignisse werden am Ende dieser Sequenz hinzugefügt. Abbildung 4-19 zeigt die Partitionierung in einer Event Hub-Instanz.
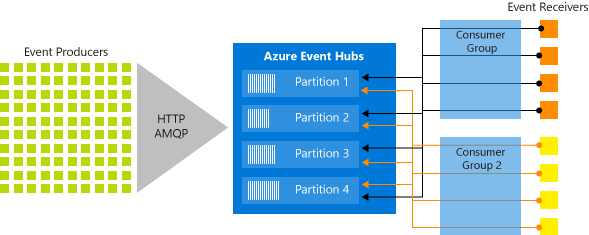
Abbildung 4-19. Event Hub-Partitionierung
Statt Daten aus derselben Ressource zu lesen, liest jede Consumergruppe Daten aus einer Teilmenge oder Partition des Nachrichtendatenstroms.
Für cloudnative Anwendungen, die eine große Anzahl von Ereignissen streamen müssen, kann Azure Event Hub eine zuverlässige und kostengünstige Lösung sein.
Zusammenarbeit auf GitHub
Die Quelle für diesen Inhalt finden Sie auf GitHub, wo Sie auch Issues und Pull Requests erstellen und überprüfen können. Weitere Informationen finden Sie in unserem Leitfaden für Mitwirkende.