Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Tipp
Dieser Inhalt ist ein Auszug aus dem eBook .NET Microservices Architecture for Containerized .NET Applications, verfügbar auf .NET Docs oder als kostenlose herunterladbare PDF, die offline gelesen werden kann.

Herausforderung Nr. 1: Definieren der Grenzen der einzelnen Microservice
Das Definieren von Microservice-Grenzen ist wahrscheinlich die erste Herausforderung, die jeder findet. Jeder Microservice muss ein Stück Ihrer Anwendung sein, und jeder Microservice sollte mit allen Vorteilen und Herausforderungen, die er vermittelt, autonom sein. Aber wie identifizieren Sie diese Grenzen?
Zunächst müssen Sie sich auf die logischen Domänenmodelle und verwandten Daten der Anwendung konzentrieren. Versuchen Sie, entkoppelte Dateninseln und unterschiedliche Kontexte innerhalb derselben Anwendung zu identifizieren. Jeder Kontext könnte eine andere Geschäftssprache haben (unterschiedliche Geschäftsbedingungen). Die Kontexte sollten unabhängig definiert und verwaltet werden. Die Begriffe und Entitäten, die in diesen verschiedenen Kontexten verwendet werden, klingen möglicherweise ähnlich, aber Sie können feststellen, dass in einem bestimmten Kontext ein Geschäftskonzept mit einem anderen Zweck in einem anderen Kontext verwendet wird und sogar einen anderen Namen hat. Beispielsweise kann ein Benutzer als Benutzer im Identitäts- oder Mitgliedschaftskontext, als Kunde in einem CRM-Kontext, als Käufer in einem Bestellkontext usw. bezeichnet werden.
Die Art und Weise, wie Sie Grenzen zwischen mehreren Anwendungskontexten mit einer anderen Domäne für jeden Kontext identifizieren können, ist genau, wie Sie die Grenzen für jeden Business Microservice und dessen zugehöriges Domänenmodell und -daten identifizieren können. Sie versuchen immer, die Kopplung zwischen diesen Microservices zu minimieren. Dieses Handbuch enthält ausführlichere Informationen zu diesem Identifizierungs- und Domänenmodelldesign im Abschnitt Identifizierung von Domänenmodellgrenzen für jeden Microservice später.
Herausforderung Nr. 2: Erstellen von Abfragen, die Daten aus mehreren Microservices abrufen
Eine zweite Herausforderung besteht darin, Abfragen zu implementieren, die Daten aus mehreren Microservices abrufen und gleichzeitig chatty-Kommunikation mit den Microservices von Remoteclient-Apps vermeiden. Ein Beispiel könnte ein einzelner Bildschirm aus einer mobilen App sein, der Benutzerinformationen anzeigen muss, die den Microservices für den Warenkorb, den Katalog und die Benutzeridentität gehören. Ein weiteres Beispiel wäre ein komplexer Bericht mit vielen Tabellen in mehreren Microservices. Die richtige Lösung hängt von der Komplexität der Abfragen ab. Aber in jedem Fall benötigen Sie eine Möglichkeit, Informationen zu aggregieren, wenn Sie die Effizienz in der Kommunikation Ihres Systems verbessern möchten. Die beliebtesten Lösungen sind die folgenden.
API-Gateway. Für die einfache Datenaggregation von mehreren Microservices, die unterschiedliche Datenbanken besitzen, ist der empfohlene Ansatz ein Aggregations-Microservice, der als API-Gateway bezeichnet wird. Sie müssen jedoch vorsichtig sein, um dieses Muster zu implementieren, da es sich um einen Drosselpunkt in Ihrem System handelt, und es kann gegen das Prinzip der Mikroserviceautonomie verstoßen. Um diese Möglichkeit zu minimieren, können Sie mehrere feinkörnige API-Gateways haben, die sich auf ein vertikales "Segment" oder einen Geschäftsbereich des Systems konzentrieren. Das API-Gatewaymuster wird weiter unten im Abschnitt "API-Gateway" ausführlicher erläutert.
GraphQL-Partnerverbund Eine Möglichkeit, zu berücksichtigen, ob Ihre Microservices bereits GraphQL verwenden, ist der GraphQL-Verbund. Mithilfe des Verbunds können Sie "Subgraphen" aus anderen Diensten definieren und zu einem umfassenden "Supergraphen" zusammensetzen, der als eigenständiges Schema fungiert.
CQRS mit Abfrage-/schreibgeschützten Tabellen: Eine weitere Lösung zum Aggregieren von Daten aus mehreren Microservices ist das Materialisierte Ansichtsmuster. Bei diesem Ansatz generieren Sie vorab eine schreibgeschützte Tabelle mit den Daten, die mehreren Microservices gehören (d.h. Sie bereiten vor den eigentlichen Abfragen denormalisierte Daten vor). Die Tabelle verfügt über ein Format, das für die Anforderungen der Client-App geeignet ist.
Betrachten Sie etwas wie den Bildschirm für eine mobile App. Wenn Sie über eine einzelne Datenbank verfügen, können Sie die Daten für diesen Bildschirm mithilfe einer SQL-Abfrage zusammenziehen, die eine komplexe Verknüpfung mit mehreren Tabellen ausführt. Wenn Sie jedoch über mehrere Datenbanken verfügen und jede Datenbank einem anderen Microservice gehört, können Sie diese Datenbanken nicht abfragen und eine SQL-Verknüpfung erstellen. Ihre komplexe Abfrage wird zu einer Herausforderung. Sie können die Anforderung mithilfe eines CQRS-Ansatzes beheben– Sie erstellen eine denormalisierte Tabelle in einer anderen Datenbank, die nur für Abfragen verwendet wird. Die Tabelle kann speziell für die Daten entworfen werden, die Sie für die komplexe Abfrage benötigen, mit einer 1:1-Beziehung zwischen Feldern, die vom Bildschirm Ihrer Anwendung und den Spalten in der Abfragetabelle benötigt werden. Sie könnte auch zu Berichterstellungszwecken dienen.
Dieser Ansatz löst nicht nur das ursprüngliche Problem (wie man Mikroservices abfragen und verknüpfen kann), sondern verbessert auch die Leistung erheblich im Vergleich mit einer komplexen Verknüpfung, da Sie bereits über die Daten verfügen, die die Anwendung in der Abfragetabelle benötigt. Natürlich bedeutet die Verwendung von Command and Query Responsibility Segregation (CQRS) mit Abfrage-/Lesetabellen zusätzliche Entwicklungsarbeit, und Sie müssen die letztendliche Konsistenz akzeptieren. Dennoch sollten Sie CQRS mit mehreren Datenbanken verwenden, um Anforderungen an Leistung und hohe Skalierbarkeit in kollaborativen Szenarien (oder wettbewerbsfähigen Szenarien, je nach Sichtweise) zu erfüllen.
"Kalte Daten" in zentralen Datenbanken. Bei komplexen Berichten und Abfragen, die möglicherweise keine Echtzeitdaten erfordern, besteht ein allgemeiner Ansatz darin, Ihre "heißen Daten" (Transaktionsdaten aus den Microservices) als "kalte Daten" in große Datenbanken zu exportieren, die nur für die Berichterstellung verwendet werden. Dieses zentrale Datenbanksystem kann ein Big Data-basiertes System sein, wie Hadoop; ein Data Warehouse wie ein auf Azure SQL Data Warehouse basierendes Data Warehouse; oder sogar eine einzelne SQL-Datenbank, die nur für Berichte verwendet wird (wenn die Größe kein Problem ist).
Beachten Sie, dass diese zentralisierte Datenbank nur für Abfragen und Berichte verwendet wird, die keine Echtzeitdaten benötigen. Die ursprünglichen Aktualisierungen und Transaktionen müssen als Quelle der Wahrheit in Ihren Microservices-Daten enthalten sein. Die Art und Weise, wie Sie Daten synchronisieren würden, wäre entweder mithilfe der ereignisgesteuerten Kommunikation (in den nächsten Abschnitten behandelt) oder mithilfe anderer Import-/Exporttools der Datenbankinfrastruktur. Wenn Sie ereignisgesteuerte Kommunikation verwenden, würde dieser Integrationsprozess der Art und Weise ähneln, wie Sie Daten weitergeben, wie zuvor für CQRS-Abfragetabellen beschrieben.
Wenn Ihr Anwendungsdesign jedoch ständig Informationen aus mehreren Mikroservices für komplexe Abfragen aggregiert, kann das ein Symptom für ein schlechtes Design sein; der -a-Mikroservice sollte so weit wie möglich von anderen Mikroservices isoliert sein. (Dadurch werden Berichte/Analysen ausgeschlossen, die immer zentrale Kaltdatendatenbanken verwenden sollten.) Dieses Problem kann häufig ein Grund für die Zusammenführung von Microservices sein. Sie müssen die Autonomie der Entwicklung und Bereitstellung jedes Mikroservice mit starken Abhängigkeiten, Kohäsion und Datenaggregation in Einklang bringen.
Herausforderung Nr. 3: So erzielen Sie Konsistenz über mehrere Microservices hinweg
Wie bereits erwähnt, sind die Daten, die sich im Besitz jedes Microservice befinden, privat für diesen Microservice und kann nur über seine Microservice-API aufgerufen werden. Daher stellt eine Herausforderung dar, wie End-to-End-Geschäftsprozesse implementiert und gleichzeitig Konsistenz über mehrere Microservices hinweg beibehalten werden.
Um dieses Problem zu analysieren, sehen wir uns ein Beispiel aus der eShopOnContainers-Referenzanwendung an. Der Katalog microservice unterhält Informationen zu allen Produkten, einschließlich des Produktpreises. Der Basket Microservice verwaltet zeitliche Daten zu Produktartikeln, die Benutzer zu ihren Einkaufskörben hinzufügen, einschließlich des Preises der Artikel zum Zeitpunkt, zu dem sie dem Korb hinzugefügt wurden. Wenn der Preis eines Produkts im Katalog aktualisiert wird, sollte dieser Preis auch in den aktiven Körben aktualisiert werden, die dasselbe Produkt enthalten, und das System sollte den Benutzer wahrscheinlich warnen, dass sich der Preis eines bestimmten Artikels geändert hat, da er es ihrem Warenkorb hinzugefügt hat.
Wenn sich der Preis in der Produkttabelle ändert, könnte das Katalogsubsystem in einer hypothetischen version dieser Anwendung einfach eine ACID-Transaktion verwenden, um den aktuellen Preis in der Tabelle "Basket" zu aktualisieren.
In einer mikroservicesbasierten Anwendung befinden sich die Tabellen "Produkt" und "Basket" jedoch im Besitz ihrer jeweiligen Microservices. Kein Microservice sollte jemals Tabellen/Speicher im Besitz eines anderen Microservice in seinen eigenen Transaktionen enthalten, nicht einmal in direkten Abfragen, wie in Abbildung 4-9 dargestellt.
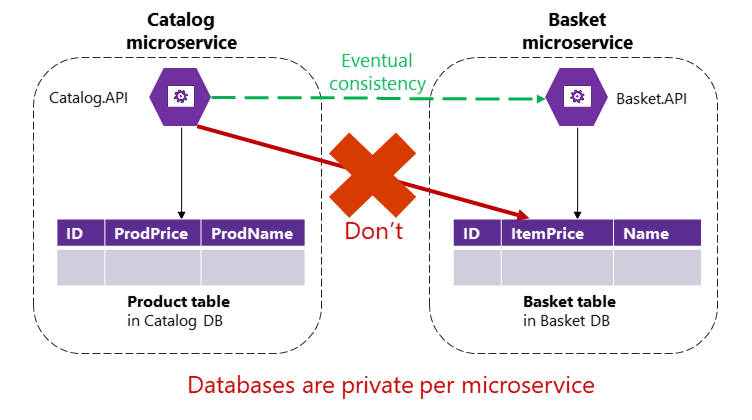
Abbildung 4-9. Ein Microservice kann nicht direkt auf eine Tabelle in einem anderen Microservice zugreifen.
** Der Katalog-Mikroservice sollte die Tabelle "Korb" nicht direkt aktualisieren, da die Tabelle "Korb" dem Mikroservice "Korb" gehört. Um ein Update für den Basket Microservice vorzunehmen, sollte der Katalog-Microservice die letztendliche Konsistenz verwenden, die wahrscheinlich auf asynchroner Kommunikation wie Integrationsereignissen (Nachrichten- und ereignisbasierte Kommunikation) basiert. So führt die eShopOnContainers-Referenzanwendung diese Art von Konsistenz über Microservices hinweg aus.
Wie vom CAP-Theorem angegeben, müssen Sie zwischen Verfügbarkeit und ACID starker Konsistenz wählen. Die meisten mikroservicebasierten Szenarien erfordern Verfügbarkeit und hohe Skalierbarkeit im Gegensatz zu starker Konsistenz. Unternehmenskritische Anwendungen müssen ununterbrochen verfügbar sein, und Entwickler können eine starke Konsistenz umgehen, indem sie Techniken für das Arbeiten mit schwachen oder letztlichen Konsistenzen verwenden. Dies ist der Ansatz der meisten mikroservicebasierten Architekturen.
Darüber hinaus sind ACID-Stil- oder Zwei-Phasen-Commit-Transaktionen nicht nur gegen Mikroservices-Prinzipien; Die meisten NoSQL-Datenbanken (wie Azure Cosmos DB, MongoDB usw.) unterstützen keine zweistufigen Commit-Transaktionen, die typisch für verteilte Datenbanken sind. Die Aufrechterhaltung der Datenkonsistenz über Dienste und Datenbanken hinweg ist jedoch unerlässlich. Diese Herausforderung bezieht sich auch auf die Frage, wie Änderungen über mehrere Mikroservices verteilt werden, wenn bestimmte Daten redundant sein müssen, z. B. wenn Sie den Namen oder die Beschreibung des Produkts im Katalog-Mikroservice und im Basket Microservice haben müssen.
Eine gute Lösung für dieses Problem besteht darin, die letztendliche Konsistenz zwischen Mikroservices zu verwenden, die durch ereignisgesteuerte Kommunikation und ein Veröffentlichungs- und Abonnierungssystem formuliert wurden. Diese Themen werden im Abschnitt "Asynchrone ereignisgesteuerte Kommunikation " weiter unten in diesem Handbuch behandelt.
Herausforderung Nr. 4: Entwerfen der Kommunikation über Mikroservicegrenzen hinweg
Die Kommunikation über Mikroservicegrenzen hinweg ist eine echte Herausforderung. In diesem Zusammenhang bezieht sich die Kommunikation nicht auf das Protokoll, das Sie verwenden sollten (HTTP und REST, AMQP, Messaging usw.). Stattdessen geht es darum, welchen Kommunikationsstil Sie verwenden sollten, und insbesondere, wie gekoppelt Ihre Microservices sein sollten. Je nach Kopplungsgrad variieren die Auswirkungen dieses Ausfalls auf Ihr System erheblich, wenn ein Fehler auftritt.
In einem verteilten System wie einer Mikroservices-basierten Anwendung, in dem viele Artefakte dynamisch im Umlauf sind und Dienste über zahlreiche Server oder Hosts verteilt sind, werden Komponenten schließlich ausfallen. Teilweiser Ausfall und sogar größere Ausfälle treten auf, daher müssen Sie Ihre Microservices und die Kommunikation über sie hinweg entwerfen, wobei die allgemeinen Risiken in dieser Art von verteilten Systemen berücksichtigt werden.
Ein beliebter Ansatz ist die Implementierung von HTTP (REST)-basierten Microservices aufgrund ihrer Einfachheit.A popular approach is implement HTTP (REST)-based microservices, due to their simplicity. Ein HTTP-basierter Ansatz ist vollkommen akzeptabel; Das Problem ist hier im Zusammenhang mit der Verwendung. Wenn Sie HTTP-Anforderungen und -Antworten nur für die Interaktion mit Ihren Microservices von Clientanwendungen oder von API-Gateways verwenden, ist dies in Ordnung. Wenn Sie jedoch lange Ketten synchroner HTTP-Aufrufe über Microservices hinweg erstellen und die Kommunikation über ihre Grenzen hinweg funktioniert, als wären die Microservices Objekte in einer monolithischen Anwendung, werden schließlich Probleme in Ihrer Anwendung auftreten.
Stellen Sie sich beispielsweise vor, dass Ihre Clientanwendung einen HTTP-API-Aufruf an einen einzelnen Microservice wie den Sortier-Microservice sendet. Wenn der Sortier microservice wiederum zusätzliche Microservices mithilfe von HTTP innerhalb desselben Anforderungs-/Antwortzyklus aufruft, erstellen Sie eine Kette von HTTP-Aufrufen. Es könnte zunächst vernünftig klingen. Es gibt jedoch wichtige Punkte, die Sie berücksichtigen sollten, wenn Sie diesen Pfad hinuntergehen:
Blockieren und geringe Leistung. Aufgrund der synchronen Art von HTTP erhält die ursprüngliche Anforderung erst dann eine Antwort, wenn alle internen HTTP-Aufrufe abgeschlossen sind. Stellen Sie sich vor, ob die Anzahl dieser Aufrufe erheblich zunimmt und gleichzeitig einer der zwischengeschalteten HTTP-Aufrufe eines Microservice blockiert wird. Das Ergebnis ist, dass die Leistung beeinträchtigt wird, und die Gesamtskalierbarkeit wird exponentiell beeinflusst, da zusätzliche HTTP-Anforderungen steigen.
Koppeln von Microservices mit HTTP. Business Microservices sollten nicht mit anderen Business Microservices gekoppelt werden. Im Idealfall sollten sie nicht über die Existenz anderer Microservices "wissen". Wenn Ihre Anwendung microservices wie im Beispiel koppelt, ist das Erreichen der Autonomie pro Mikroservice fast unmöglich.
Fehler in einem beliebigen Microservice. Wenn Sie eine Kette von Microservices implementiert haben, die durch HTTP-Aufrufe verknüpft ist, und einer der Microservices ausfällt (was früher oder später passieren wird), schlägt die gesamte Kette von Microservices fehl. Ein mikroservicebasiertes System sollte so konzipiert werden, dass es auch bei Teilausfällen so gut wie möglich funktioniert. Auch wenn Sie Clientlogik implementieren, die Wiederholungen mit exponentiellen Backoff- oder Schaltkreistrennmechanismen verwendet, desto komplexer sind die HTTP-Aufrufketten, desto komplexer ist es, eine Fehlerstrategie basierend auf HTTP zu implementieren.
Tatsächlich könnte argumentiert werden, dass Sie über eine monolithische Anwendung verfügen, wenn Ihre internen Microservices kommunizieren, indem sie Ketten von HTTP-Anfragen erstellen, wie es beschrieben wurde. Diese Anwendung basiert allerdings auf der Kommunikation zwischen Prozessen via HTTP anstelle von Kommunikationsmechanismen innerhalb eines Prozesses.
Um die Mikroserviceautonomie zu erzwingen und eine bessere Resilienz zu haben, sollten Sie daher die Verwendung von Ketten der Anforderungs-/Antwortkommunikation über Mikroservices hinweg minimieren. Es wird empfohlen, nur asynchrone Interaktion für die Kommunikation zwischen Mikroservices zu verwenden, entweder durch asynchrone Nachrichten- und ereignisbasierte Kommunikation oder durch (asynchrones) HTTP-Polling, das unabhängig vom originären HTTP-Anforderung-/Antwort-Zyklus erfolgt.
Die Verwendung asynchroner Kommunikation wird weiter unten in diesem Leitfaden in den Abschnitten Asynchrone Microservice-Integration zur Unterstützung der Autonomie und Asynchrone nachrichtenbasierte Kommunikation erklärt.
Weitere Ressourcen
CAP-Theorem
https://en.wikipedia.org/wiki/CAP_theoremMögliche Konsistenz
https://en.wikipedia.org/wiki/Eventual_consistencyDatenkonsistenz-Leitfaden
https://learn.microsoft.com/previous-versions/msp-n-p/dn589800(v=pandp.10)Martin Fowler. CQRS Command and Query Responsibility Segregation (CQRS: Zuständigkeitstrennung für Befehle und Abfragen)
https://martinfowler.com/bliki/CQRS.htmlMaterialisierte Sicht
https://learn.microsoft.com/azure/architecture/patterns/materialized-viewCharles Row. ACID vs. BASE: Die Verschiebung des pH der Datenbanktransaktionsverarbeitung
https://www.dataversity.net/acid-vs-base-the-shifting-ph-of-database-transaction-processing/Ausgleichende Transaktion
https://learn.microsoft.com/azure/architecture/patterns/compensating-transactionUdi Dahan. Dienstorientierte Komposition
https://udidahan.com/2014/07/30/service-oriented-composition-with-video/
Zusammenarbeit auf GitHub
Die Quelle für diesen Inhalt finden Sie auf GitHub, wo Sie auch Issues und Pull Requests erstellen und überprüfen können. Weitere Informationen finden Sie in unserem Leitfaden für Mitwirkende.