Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Tipp
Dieser Inhalt ist ein Auszug aus dem eBook .NET Microservices Architecture for Containerized .NET Applications, verfügbar auf .NET Docs oder als kostenlose herunterladbare PDF, die offline gelesen werden kann.

Die Behandlung unerwarteter Fehler ist eines der schwierigsten Probleme, die in einem verteilten System gelöst werden müssen. Ein Großteil des Codes, den Entwickler schreiben, umfasst die Behandlung von Ausnahmen, und dies ist auch der Ort, an dem die meiste Zeit beim Testen aufgewendet wird. Das Problem ist komplizierter als nur das Schreiben von Code zur Behandlung von Fehlern. Was geschieht, wenn der Computer, auf dem der Microservice ausgeführt wird, fehlschlägt? Sie müssen nicht nur diesen Microservice-Fehler (ein hartes Problem selbst) erkennen, sondern auch etwas, um Ihren Microservice neu zu starten.
Ein Microservice muss ausfallsicher gegenüber Fehlern sein und zur Verfügbarkeit häufig auf einem anderen Computer neu gestartet werden können. Diese Resilienz kommt auch auf den Zustand zurück, der im Namen des Microservice gespeichert wurde, von dem der Microservice diesen Zustand wiederherstellen kann und ob der Microservice erfolgreich neu gestartet werden kann. Anders ausgedrückt: Es muss resilienz in der Computefunktion bestehen (der Prozess kann jederzeit neu gestartet werden) sowie Resilienz im Zustand oder in den Daten (kein Datenverlust, und die Daten bleiben konsistent).
Die Probleme der Resilienz werden in anderen Szenarien, z. B. bei Fehlern während eines Anwendungsupgrades, verschärft. Der Microservice, der mit dem Bereitstellungssystem arbeitet, muss bestimmen, ob er weiterhin auf die neuere Version umsteigen kann oder stattdessen ein Rollback auf eine frühere Version durchführen kann, um einen konsistenten Zustand zu erhalten. Fragen, wie ob genügend Maschinen verfügbar sind, um weiter voranzukommen, und wie frühere Versionen des Microservice wiederhergestellt werden können, müssen berücksichtigt werden. Dieser Ansatz erfordert, dass der Microservice Gesundheitsinformationen ausgibt, damit die gesamte Anwendung und der Orchestrator diese Entscheidungen treffen können.
Darüber hinaus bezieht sich die Ausfallsicherheit auf das Verhalten von cloudbasierten Systemen. Wie bereits erwähnt, muss ein cloudbasiertes System Fehler annehmen und versuchen, sie automatisch wiederherzustellen. Bei Netzwerk- oder Containerfehlern müssen Client-Apps oder Clientdienste beispielsweise eine Strategie zum Wiederholen des Sendens von Nachrichten oder zum Wiederholen von Anforderungen haben, da in vielen Fällen Fehler in der Cloud teilweise auftreten. Im Abschnitt "Implementieren resilienter Anwendungen " in diesem Handbuch wird beschrieben, wie Teilfehler behandelt werden. Es beschreibt Techniken wie Wiederholungen mit exponentiellem Backoff oder das Circuit Breaker-Muster in .NET mithilfe von Bibliotheken wie Polly, die eine vielzahl von Richtlinien für die Behandlung dieses Themas bieten.
Gesundheitsmanagement und Diagnostik in Microservices
Es mag offensichtlich erscheinen, und es wird oft übersehen, aber ein Microservice muss seinen Gesundheitszustand und seine Diagnosen melden. Andernfalls gibt es wenig Einblick in eine Betriebsperspektive. Das Korrelieren von Diagnoseereignissen über eine Reihe unabhängiger Dienste hinweg und der Umgang mit Abweichungen der Maschinentakte, um die Reihenfolge der Ereignisse zu verstehen, ist eine Herausforderung. Auf die gleiche Weise, wie Sie mit einem Microservice über vereinbarte Protokolle und Datenformate interagieren, ist es erforderlich, die Standardisierung zu implementieren, wie Integritäts- und Diagnoseereignisse protokolliert werden, die letztendlich in einem Ereignisspeicher für Abfragen und Anzeigen enden. Bei einem Microservices-Ansatz ist es wichtig, dass verschiedene Teams ein einzelnes Protokollierungsformat vereinbaren. Es muss ein einheitlicher Ansatz zum Anzeigen von Diagnoseereignissen in der Anwendung geben.
Gesundheitschecks
Die Integrität unterscheidet sich von der Diagnose. Bei der Integrität geht es darum, dass der Microservice seinen aktuellen Zustand meldet, damit entsprechende Maßnahmen ergriffen werden können. Ein gutes Beispiel ist die Verwendung der Upgrade- und Bereitstellungsmechanismen zum Wahren der Verfügbarkeit. Obwohl ein Dienst aufgrund eines Prozessabsturzes oder computerneustarts möglicherweise nicht einwandfrei ist, ist der Dienst möglicherweise weiterhin betriebsbereit. Das letzte, was Sie brauchen, ist, dies durch ein Upgrade zu verschlimmern. Der beste Ansatz besteht darin, zuerst eine Untersuchung zu durchführen oder Zeit für die Wiederherstellung des Microservice zu ermöglichen. Anhand von Integritätsereignissen eines Microservice können wir fundierte Entscheidungen treffen und selbstreparierende Dienste erstellen.
Im Abschnitt "Implementieren von Integritätsprüfungen in ASP.NET Core Services " dieses Leitfadens erläutern wir, wie Sie eine neue ASP.NET HealthChecks-Bibliothek in Ihren Microservices verwenden, damit sie ihren Status einem Überwachungsdienst melden können, um geeignete Maßnahmen zu ergreifen.
Sie haben auch die Möglichkeit, eine hervorragende Open-Source-Bibliothek namens AspNetCore.Diagnostics.HealthChecks zu verwenden, die auf GitHub und als NuGet-Paket verfügbar ist. Diese Bibliothek führt auch Integritätsprüfungen durch, wobei sie zwei Arten von Prüfungen behandelt:
- Liveness: Überprüft, ob der Microservice lebendig ist, d. h., wenn er Anfragen annehmen und antworten kann.
- Bereitschaft: Überprüft, ob die Abhängigkeiten des Microservice (Datenbank, Warteschlangendienste usw.) selbst bereit sind, damit der Microservice tun kann, was er tun soll.
Verwenden von Diagnose- und Protokollereignisdatenströmen
Protokolle enthalten Informationen dazu, wie eine Anwendung oder ein Dienst ausgeführt wird, einschließlich Ausnahmen, Warnungen und einfachen Informationsmeldungen. In der Regel befindet sich jedes Protokoll in einem Textformat mit einer Zeile pro Ereignis, obwohl ausnahmen häufig auch die Stapelablaufverfolgung über mehrere Zeilen hinweg anzeigen.
In monolithischen serverbasierten Anwendungen können Sie Protokolle in eine Datei auf einem Datenträger (einer Logfile) schreiben und dann mit jedem Tool analysieren. Da die Anwendungsausführung auf einen festen Server oder einen virtuellen Computer beschränkt ist, ist sie in der Regel nicht zu komplex, um den Ablauf von Ereignissen zu analysieren. In einer verteilten Anwendung, in der mehrere Dienste über viele Knoten in einem Orchestratorcluster ausgeführt werden, ist es jedoch eine Herausforderung, verteilte Ereignisse zu korrelieren.
Eine microservicebasierte Anwendung sollte nicht versuchen, den Ausgabedatenstrom von Ereignissen oder Logfiles selbst zu speichern, und nicht einmal versuchen, das Routing der Ereignisse an einen zentralen Ort zu verwalten. Es sollte transparent sein, d. h., jeder Prozess sollte einfach seinen Ereignisdatenstrom in eine Standardausgabe schreiben, die von der Ausführungsumgebungsinfrastruktur erfasst wird, in der er ausgeführt wird. Ein Beispiel für diese Ereignisstreamrouter ist Microsoft.Diagnostic.EventFlow, der Ereignisstreams aus mehreren Quellen sammelt und in Ausgabesystemen veröffentlicht. Dazu können einfache Standardausgaben für eine Entwicklungsumgebung oder Cloudsysteme wie Azure Monitor und Azure Diagnostics gehören. Es gibt auch gute Analyseplattformen und Tools von Drittanbietern, die Protokolle durchsuchen, warnen, melden und überwachen können, auch in Echtzeit, z. B. Splunk oder Middleware.
Orchestratoren zur Verwaltung von Gesundheits- und Diagnosedaten
Wenn Sie eine mikroservicebasierte Anwendung erstellen, müssen Sie sich mit der Komplexität befassen. Natürlich ist ein einzelner Microservice einfach zu behandeln, aber Dutzende oder Hunderte von Typen und Tausende von Instanzen von Microservices ist ein komplexes Problem. Es geht nicht nur darum, Ihre Microservice-Architektur zu erstellen– Sie benötigen auch hohe Verfügbarkeit, Adressierbarkeit, Resilienz, Integrität und Diagnose, wenn Sie ein stabiles und zusammenhängendes System haben möchten.
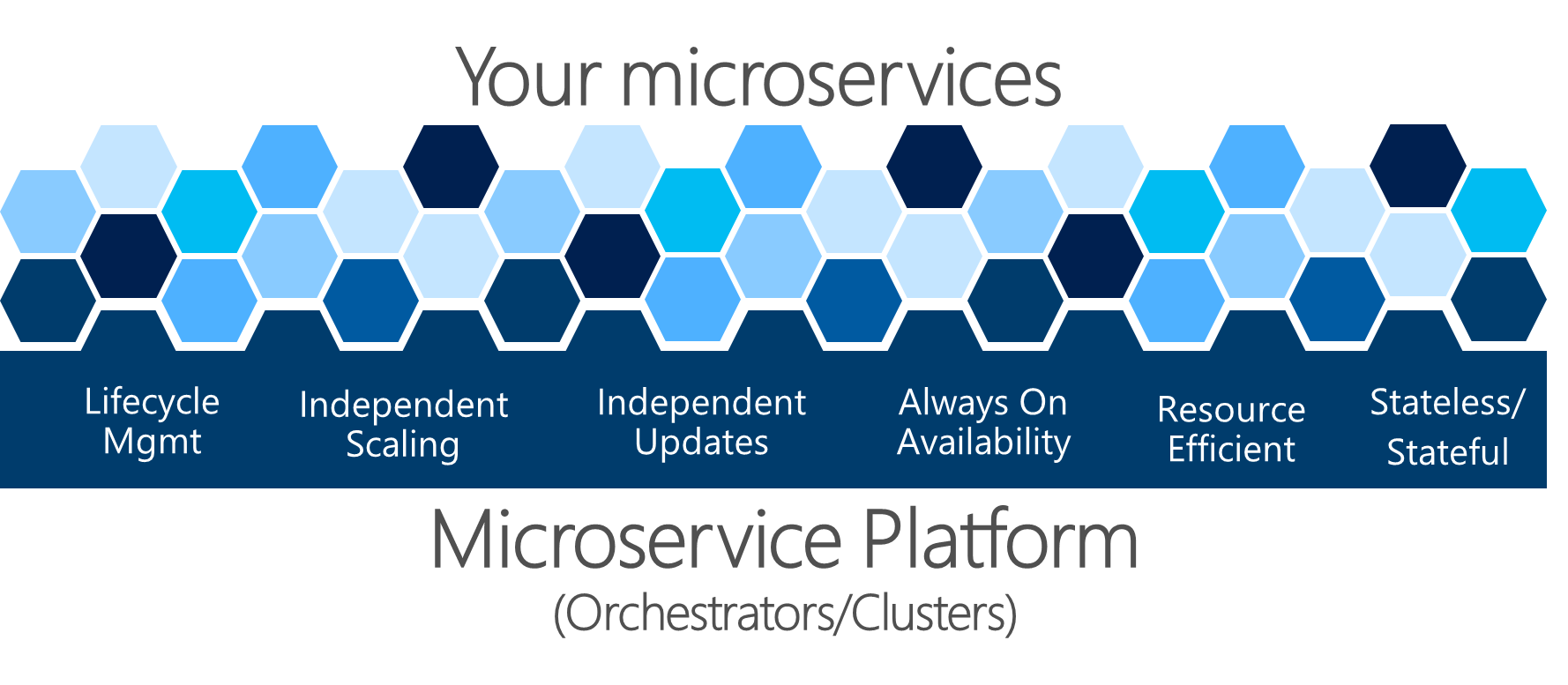
Abbildung 4-22. Eine Microservice-Plattform ist grundlegend für das Gesundheitsmanagement von Anwendungen.
Die komplexen Probleme, die in Abbildung 4-22 dargestellt sind, sind schwer selbst zu lösen. Entwicklungsteams sollten sich auf die Lösung von Geschäftsproblemen konzentrieren und benutzerdefinierte Anwendungen mit mikroservicebasierten Ansätzen erstellen. Sie sollten sich nicht auf die Lösung komplexer Infrastrukturprobleme konzentrieren; Wenn dies der Fall wäre, wären die Kosten für jede mikroservicebasierte Anwendung enorm. Daher gibt es mikroserviceorientierte Plattformen, die als Orchestratoren oder Microservice-Cluster bezeichnet werden, die versuchen, die schwierigen Probleme beim Erstellen und Ausführen eines Dienstes zu lösen und Infrastrukturressourcen effizient zu nutzen. Dieser Ansatz reduziert die Komplexität der Erstellung von Anwendungen, die einen Microservices-Ansatz verwenden.
Verschiedene Orchestratoren klingen möglicherweise ähnlich, aber die Diagnose- und Integritätsprüfungen, die von jedem von ihnen angeboten werden, unterscheiden sich in den Features und dem Reifezustand, manchmal abhängig von der Betriebssystemplattform, wie im nächsten Abschnitt erläutert.
Weitere Ressourcen
Die Twelve-Factor-App. XI. Protokolle: Behandeln von Protokollen als Ereignisdatenströme
https://12factor.net/logsMicrosoft Diagnostic EventFlow-Bibliothek GitHub-Repository.
https://github.com/Azure/diagnostics-eventflowWas ist Azure Diagnostics?
https://learn.microsoft.com/azure/azure-diagnosticsVerbinden von Windows-Computern mit dem Azure Monitor-Dienst
https://learn.microsoft.com/azure/azure-monitor/platform/agent-windowsSinnvolles Protokollieren: Verwenden des Semantischen Protokollierungsanwendungsblocks
https://learn.microsoft.com/previous-versions/msp-n-p/dn440729(v=pandp.60)Splunk Offizielle Website.
https://www.splunk.com/Middleware Offizielle Website.
https://middleware.io/EventSource-Klasse API für die Ereignisablaufverfolgung für Windows (ETW)
https://learn.microsoft.com/dotnet/api/system.diagnostics.tracing.eventsource
Zusammenarbeit auf GitHub
Die Quelle für diesen Inhalt finden Sie auf GitHub, wo Sie auch Issues und Pull Requests erstellen und überprüfen können. Weitere Informationen finden Sie in unserem Leitfaden für Mitwirkende.