Verwenden Sie auf Azure Machine Learning basierende Modelle
Die vereinheitlichten Daten in Dynamics 365 Customer Insights - Data sind eine Quelle für den Aufbau von Machine-Learning-Modellen, die zusätzliche Geschäftseinblicke generieren können. Customer Insights - Data lässt sich in Azure Machine Learning integrieren, um Ihre eigenen benutzerdefinierten Modelle zu verwenden.
Anforderungen
- Zugriff auf Customer Insights - Data
- Ein aktives Azure-Enterprise-Abonnement
- Vereinheitlichte Kundenprofile
- Tabellenexport zu Azure Blob-Speicher konfiguriert
Azure Machine Learning Arbeitsbereich einrichten
Siehe Erstellen eines Azure Machine Learning Arbeitsbereichs für verschiedene Optionen zum Erstellen des Arbeitsbereichs. Um die beste Leistung zu erzielen, erstellen Sie den Arbeitsbereich in einer Azure-Region, die Ihrer Customer Insights Umgebung geografisch am nächsten ist.
Zugriff auf Ihren Arbeitsbereich über das Azure Machine Learning Studio. Es gibt mehrere Möglichkeiten, mit Ihrem Arbeitsbereich zu interagieren.
Arbeiten Sie mit dem Azure Machine Learning Designer
Der Azure Machine Learning-Designer stellt eine visuelle Canvas bereit, in die Sie Datasets und Module ziehen und ablegen können. Eine vom Designer erstellte Batch-Pipeline kann in Customer Insights - Data integriert werden, wenn sie entsprechend konfiguriert wird.
Arbeiten mit dem Azure Machine Learning SDK
Datenwissenschaftler und KI-Entwickler verwenden das Azure Machine Learning SDK, um Machine Learning Workflows zu erstellen. Zurzeit können Modelle, die mit dem SDK trainiert wurden, nicht direkt integriert werden. Für die Integration in Customer Insights - Data ist eine Batch-Inferenz-Pipeline erforderlich, die dieses Modell verwertet.
Anforderungen an die Batch-Pipeline zur Integration in Customer Insights - Data
Dataset-Konfiguration
Erstellen Sie Datasets, um Tabellendaten aus Customer Insights für Ihre Batch-Inferenz-Pipeline zu verwenden. Registrieren Sie diese Datasets im Arbeitsbereich. Zurzeit werden nur tabellarische Datasets im .csv-Format unterstützt. Parameterisieren Sie die Datasets, die den Daten der Tabelle entsprechen, als Pipeline-Parameter.
Dataset-Parameter im Designer
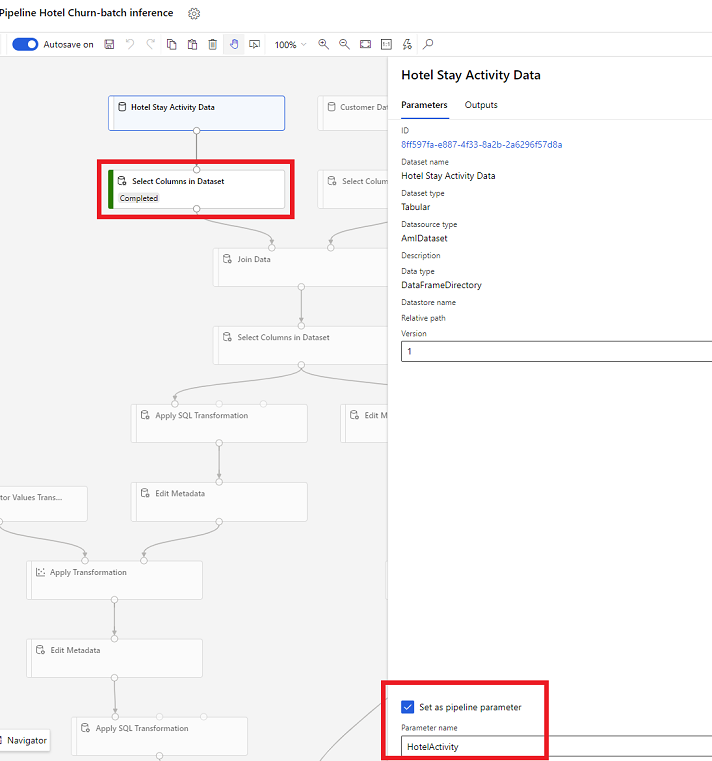
Öffnen Sie im Designer Spalten in Dataset auswählen und wählen Sie Als Pipeline-Parameter festlegen, wo Sie einen Namen für den Parameter angeben.
Dataset-Parameter im SDK (Python)
HotelStayActivity_dataset = Dataset.get_by_name(ws, name='Hotel Stay Activity Data') HotelStayActivity_pipeline_param = PipelineParameter(name="HotelStayActivity_pipeline_param", default_value=HotelStayActivity_dataset) HotelStayActivity_ds_consumption = DatasetConsumptionConfig("HotelStayActivity_dataset", HotelStayActivity_pipeline_param)
Batch-Inferenz-Pipeline
Verwenden Sie im Designer eine Trainings-Pipeline, um eine Inferenz-Pipeline zu erstellen oder zu aktualisieren. Zurzeit werden nur Batch-Inferenz-Pipelines unterstützt.
Veröffentlichen Sie mit dem SDK die Pipeline an einen Endpunkt. Derzeit lässt sich Customer Insights - Data mit der Standard-Pipeline in einem Batch-Pipeline-Endpunkt im Arbeitsbereich für maschinelles Lernen integrieren.
published_pipeline = pipeline.publish(name="ChurnInferencePipeline", description="Published Churn Inference pipeline") pipeline_endpoint = PipelineEndpoint.get(workspace=ws, name="ChurnPipelineEndpoint") pipeline_endpoint.add_default(pipeline=published_pipeline)
Pipeline-Daten importieren
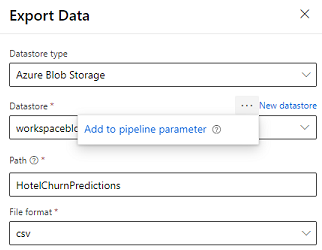
Der Designer bietet das Modul Daten exportieren, mit dem die Ausgabe einer Pipeline in den Azure-Speicher exportiert werden kann. Derzeit muss das Modul den Datenspeichertyp Azure Blob Storage verwenden und den Datastore und den relativen Pfad parametrisieren. Das System überschreibt diese beiden Parameter während der Pipeline-Ausführung mit einem Datenspeicher und Pfad, auf den die Anwendung Zugriff hat.
Wenn Sie die Inferenzausgabe mit Code schreiben, laden Sie die Ausgabe in den Pfad innerhalb eines registrierten Datenspeichers im Arbeitsbereich hoch. Wenn der Pfad und der Datenspeicher in der Pipeline parametrisiert sind, kann Customer Insights die Inferenzausgabe lesen und importieren. Derzeit wird eine einfache tabellarische Ausgabe im csv-Format unterstützt. Der Pfad muss das Verzeichnis und den Dateinamen enthalten.
# In Pipeline setup script OutputPathParameter = PipelineParameter(name="output_path", default_value="HotelChurnOutput/HotelChurnOutput.csv") OutputDatastoreParameter = PipelineParameter(name="output_datastore", default_value="workspaceblobstore") ... # In pipeline execution script run = Run.get_context() ws = run.experiment.workspace datastore = Datastore.get(ws, output_datastore) # output_datastore is parameterized directory_name = os.path.dirname(output_path) # output_path is parameterized. # Datastore.upload() or Dataset.File.upload_directory() are supported methods to uplaod the data # datastore.upload(src_dir=<<working directory>>, target_path=directory_name, overwrite=False, show_progress=True) output_dataset = Dataset.File.upload_directory(src_dir=<<working directory>>, target = (datastore, directory_name)) # Remove trailing "/" from directory_name