Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für:✅ Fabric Data Engineering and Data Science
Mit der Fabric Livy-API können Sie Spark-Batch- und Sitzungsaufträge von einem Remoteclient direkt an Fabric Spark Compute übermitteln, ohne das Fabric-Portal zu verwenden. In diesem Artikel erstellen Sie ein Lakehouse, authentifizieren sich mit einem Microsoft Entra-Token, entdecken den Livy-API-Endpunkt und übermitteln und überwachen einen Spark-Sitzungsauftrag.
Voraussetzungen
Fabric Premium- oder Testkapazität mit einem Lakehouse
Aktivieren der Mandantenadministratoreinstellung für die Livy-API
Ein Remoteclient wie Visual Studio Code mit Jupyter-Notizbuchunterstützung, PySpark und Microsoft Authentication Library (MSAL) (MSAL) für Python
Entweder ein Microsoft Entra App-Token. Registern Sie eine Anwendung mit dem Microsoft Identity Platform
Oder ein Microsoft Entra SPN (Dienstprinzipal)-Token. Addieren und Verwalten von Anwendungsanmeldeinformationen in Microsoft Entra ID
Auswählen eines REST-API-Clients
Sie können mit der Livy-API von jedem Client aus interagieren, der HTTP-Anforderungen unterstützt, einschließlich Tools wie Curl oder einer beliebigen Sprache mit einer HTTP-Bibliothek. Die Beispiele in diesem Artikel verwenden Visual Studio Code mit Jupyter Notebooks, PySpark und dem Microsoft Authentication Library (MSAL) (MSAL) für Python.
So autorisieren Sie die Livy-API-Anforderungen
Um die Livy-API zu verwenden, müssen Sie Ihre Anforderungen mithilfe von Microsoft Entra ID authentifizieren. Es stehen zwei Autorisierungsmethoden zur Verfügung:
Entra SPN-Token (Dienstprinzipal): Die Anwendung authentifiziert sich als solche mit den Anmeldeinformationen wie einem Clientgeheimnis oder Zertifikat. Diese Methode eignet sich für automatisierte Prozesse und Hintergrunddienste, bei denen keine Benutzerinteraktion erforderlich ist.
Entra-App-Token (Delegiertes): Die Anwendung fungiert im Namen eines angemeldeten Benutzers. Diese Methode eignet sich, wenn die Anwendung mit den Berechtigungen des authentifizierten Benutzers auf Ressourcen zugreifen soll.
Wählen Sie die Autorisierungsmethode aus, die am besten zu Ihrem Szenario passt, und folgen Sie dem entsprechenden Abschnitt unten.
So autorisieren Sie die Livy-API-Anforderungen mit einem Microsoft Entra SPN-Token
Um mit Fabric-APIs einschließlich der Livy-API zu arbeiten, müssen Sie zuerst eine Microsoft Entra Anwendung erstellen und einen geheimen Schlüssel erstellen und diesen geheimen Schlüssel in Ihrem Code verwenden. Ihre Anwendung muss registriert und konfiguriert werden, um API-Aufrufe für Fabric auszuführen. Weitere Informationen finden Sie unter Hinzufügen und Verwalten von Anmeldeinformationen von Anwendungen in Microsoft Entra ID
Erstellen Sie nach dem Erstellen der App-Registrierung einen geheimen Clientschlüssel.
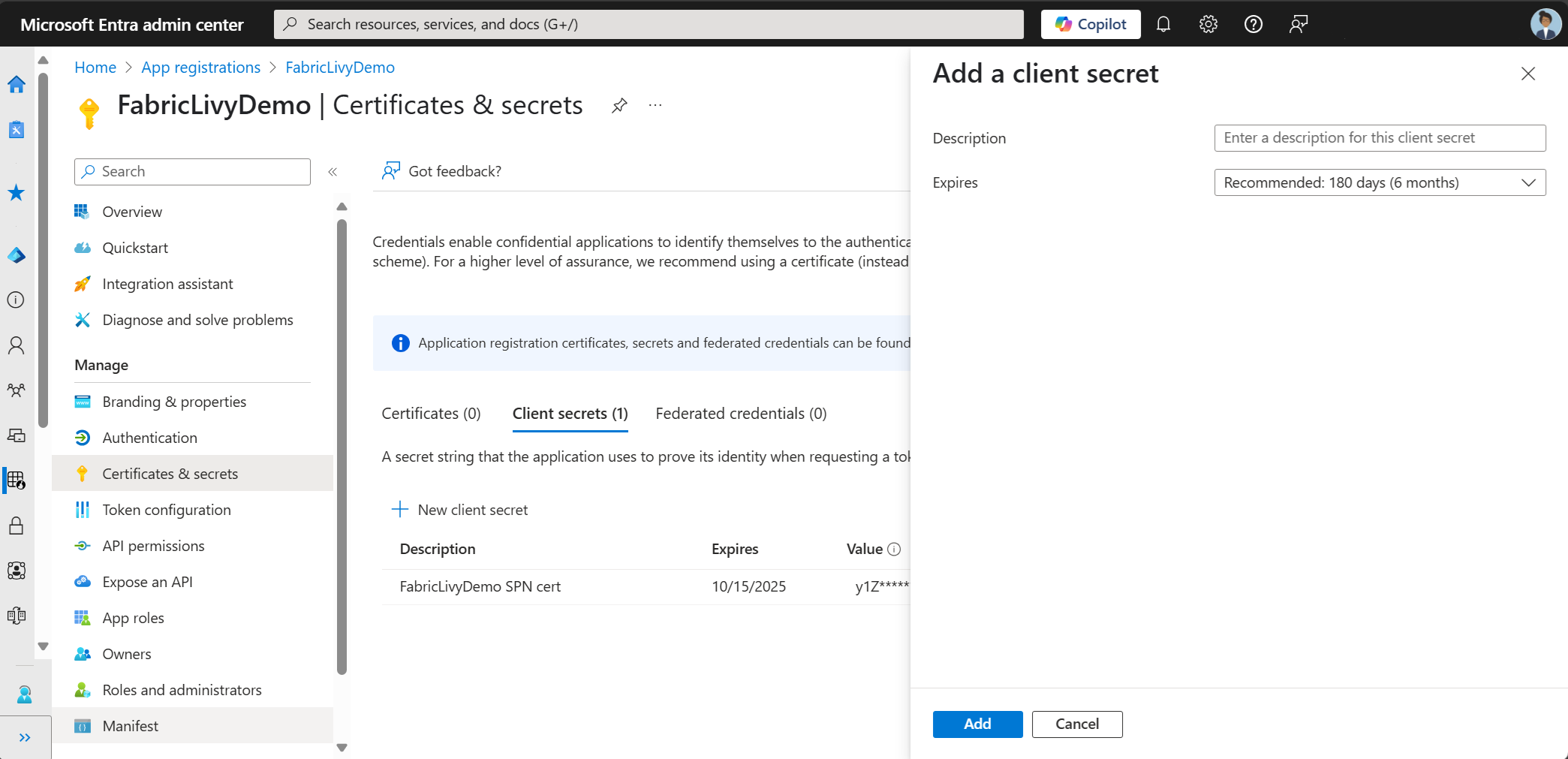
Achten Sie beim Erstellen des geheimen Clientschlüssels darauf, den Wert zu kopieren. Sie benötigen dies später im Code, und der geheime Schlüssel kann nicht mehr angezeigt werden. Sie benötigen außerdem die Anwendungs-ID (Client) und das Verzeichnis (Mandanten-ID) zusätzlich zum geheimen Schlüssel in Ihrem Code.
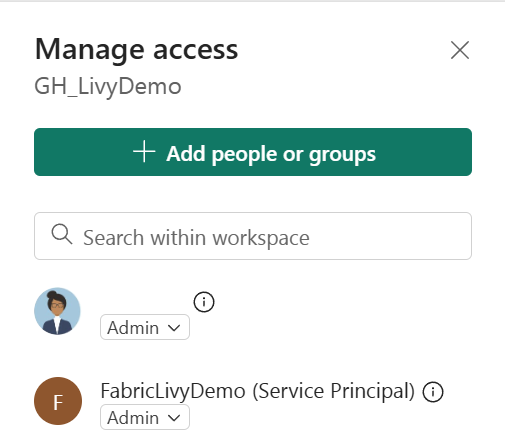
Fügen Sie als Nächstes den Dienstprinzipal zu Ihrem Arbeitsbereich hinzu.
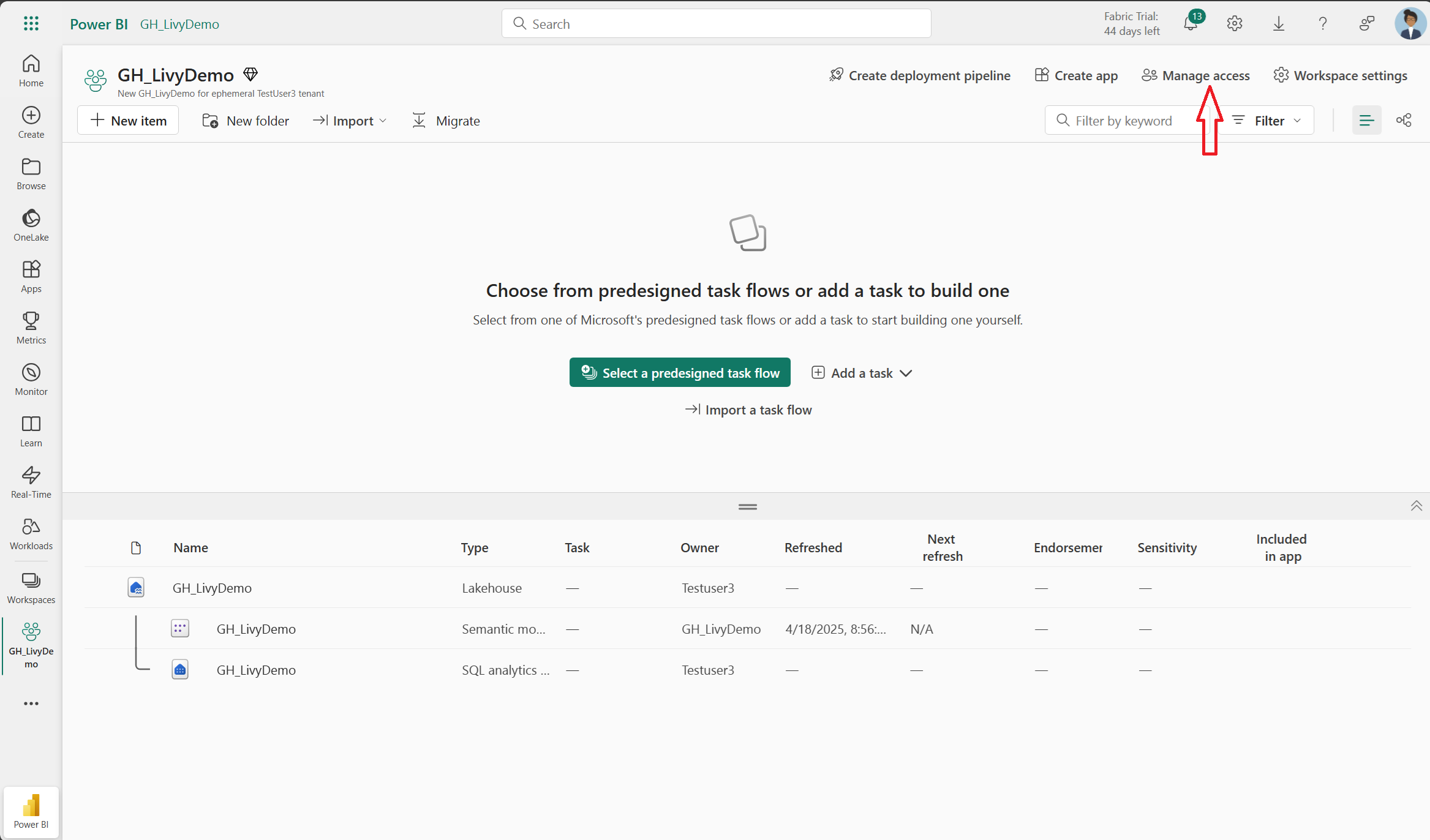
Suchen Sie mithilfe der Anwendungs-ID (Client-ID) oder des Namens nach der Microsoft Entra-Anwendung, fügen Sie sie dem Arbeitsbereich hinzu und stellen Sie sicher, dass der Dienstprinzipal über Mitwirkenderberechtigungen verfügt.



So autorisieren Sie die Livy-API-Anforderungen mit einem Entra-App-Token
Um mit Fabric APIs einschließlich der Livy-API zu arbeiten, müssen Sie zuerst eine Microsoft Entra-Anwendung erstellen und ein Token abrufen. Ihre Anwendung muss registriert und konfiguriert werden, um API-Aufrufe für Fabric auszuführen. Weitere Informationen finden Sie unter Registern einer Anwendung mit dem Microsoft Identity Platform.
Die folgenden Microsoft Entra Bereichsberechtigungen sind erforderlich, um Livy-API-Aufträge auszuführen:

Erforderliche Bereiche
| Geltungsbereich | Beschreibung |
|---|---|
Lakehouse.Execute.All |
Führen Sie Vorgänge in Fabric Seehäusern aus. |
Lakehouse.Read.All |
Lesen Sie Lakehouse-Metadaten. |
Code.AccessFabric.All |
Ermöglicht das Abrufen von Zugriffstoken für Microsoft Fabric. Erforderlich für alle Livy-API-Vorgänge. |
Code.AccessStorage.All |
Ermöglicht das Erhalten von Zugriffstoken für OneLake und Azure-Speicher. Erforderlich für das Lesen und Schreiben von Daten in Seehäusern. |
Optionaler Code.* Gültigkeitsbereiche
Fügen Sie diese Bereiche nur hinzu, wenn Ihre Spark-Aufträge zur Laufzeit auf die entsprechenden Azure-Dienste zugreifen müssen.
| Geltungsbereich | Beschreibung | Wann verwenden? |
|---|---|---|
Code.AccessAzureKeyvault.All |
Ermöglicht das Abrufen von Zugriffstoken zum Azure Key Vault. | Ihr Spark-Code ruft geheime Schlüssel, Schlüssel oder Zertifikate aus Azure Key Vault ab. |
Code.AccessAzureDataLake.All |
Ermöglicht das Abrufen von Zugriffstoken zum Azure Data Lake Storage Gen1. | Ihr Spark-Code liest aus oder schreibt in Azure Data Lake Storage Gen1 Konten. |
Code.AccessAzureDataExplorer.All |
Ermöglicht das Abrufen von Zugriffstoken für den Azure Data Explorer (Kusto). | Ihr Spark-Code ruft Daten aus oder überträgt sie an Azure Data Explorer-Cluster. |
Code.AccessSQL.All |
Ermöglicht das Abrufen von Zugriffstoken zum Azure SQL. | Ihr Spark-Code muss eine Verbindung mit Azure SQL Datenbanken herstellen. |
Wenn Sie Ihre Anwendung registrieren, benötigen Sie sowohl die Anwendungs-ID (Client-ID) als auch die Verzeichnis-ID (Mandant).

Der authentifizierte Benutzende, der die Livy-API aufruft, muss Mitglied des Arbeitsbereichs sein, in dem sich sowohl die API- als auch die Datenquellenelemente befinden, und über die Rolle „Mitwirkender“ verfügen. Weitere Informationen finden Sie unter Gewähren des Zugriffs auf Arbeitsbereiche für Benutzer.
Grundlegendes zu Code.* Bereichen für die Livy-API
Wenn Ihre Spark-Aufträge über die Livy-API ausgeführt werden, steuern die Code.* Bereiche, auf welche externen Dienste die Spark Runtime im Namen des authentifizierten Benutzers zugreifen kann. Zwei sind erforderlich; der Rest ist je nach Workload optional.
Erforderliche Code.* Bereiche
| Geltungsbereich | Beschreibung |
|---|---|
Code.AccessFabric.All |
Ermöglicht das Abrufen von Zugriffstoken für Microsoft Fabric. Erforderlich für alle Livy-API-Vorgänge. |
Code.AccessStorage.All |
Ermöglicht das Erhalten von Zugriffstoken für OneLake und Azure-Speicher. Erforderlich für das Lesen und Schreiben von Daten in Seehäusern. |
Optionaler Code.* Gültigkeitsbereiche
Fügen Sie diese Bereiche nur hinzu, wenn Ihre Spark-Aufträge zur Laufzeit auf die entsprechenden Azure-Dienste zugreifen müssen.
| Geltungsbereich | Beschreibung | Wann verwenden? |
|---|---|---|
Code.AccessAzureKeyvault.All |
Ermöglicht das Abrufen von Zugriffstoken zum Azure Key Vault. | Ihr Spark-Code ruft geheime Schlüssel, Schlüssel oder Zertifikate aus Azure Key Vault ab. |
Code.AccessAzureDataLake.All |
Ermöglicht das Abrufen von Zugriffstoken zum Azure Data Lake Storage Gen1. | Ihr Spark-Code liest aus oder schreibt in Azure Data Lake Storage Gen1 Konten. |
Code.AccessAzureDataExplorer.All |
Ermöglicht das Abrufen von Zugriffstoken für den Azure Data Explorer (Kusto). | Ihr Spark-Code ruft Daten aus oder überträgt sie an Azure Data Explorer-Cluster. |
Code.AccessSQL.All |
Ermöglicht das Abrufen von Zugriffstoken zum Azure SQL. | Ihr Spark-Code muss eine Verbindung mit Azure SQL Datenbanken herstellen. |
Hinweis
Die Lakehouse.Execute.All- und Lakehouse.Read.All-Bereiche sind ebenfalls erforderlich, jedoch nicht Teil der Code.*-Familie. Sie erteilen die Berechtigung zum Ausführen von Vorgängen in und lesen Metadaten aus Fabric Seehäusern.
So entdecken Sie den Fabric Livy-API-Endpunkt
Für den Zugriff auf den Livy-Endpunkt ist ein Lakehouse-Artefakt erforderlich. Nachdem das Lakehouse erstellt wurde, finden Sie den Livy-API-Endpunkt im Einstellungsbereich.

Der Endpunkt der Livy-API weist folgendes Muster auf:
https://api.fabric.microsoft.com/v1/workspaces/><ws_id>/lakehouses/<lakehouse_id>/livyapi/versions/2023-12-01/
An die URL wird je nach Ihrer Auswahl entweder <sessions> oder <batches> angefügt.
Laden Sie die Dateien der Livy-API Swagger herunter.
Die vollständigen Swagger-Dateien für die Livy-API sind hier verfügbar.
Hohe Parallelitätssitzungen
Hohe Parallelitätsunterstützung (HC) ermöglicht die gleichzeitige Spark-Ausführung, indem Clients mehrere unabhängige Ausführungskontexte abrufen können, die als "Hohe Parallelitätssitzungen" bezeichnet werden.
Jede HC-Sitzung stellt einen logischen Ausführungskontext dar, der einer Spark REPL (Read-Eval-Print Loop) zugeordnet ist. Spark-Anweisungen, die unter verschiedenen HC-Sitzungen übermittelt werden, können gleichzeitig ausgeführt werden.
Dadurch können:
- Parallele Ausführung über HC-Sitzungen hinweg
- Vorhersehbare Ressourcennutzung
- Isolation zwischen gleichzeitigen Anforderungen
- Geringerer Aufwand im Vergleich zum Erstellen einer neuen Sitzung pro Anforderung
Wenn Sie eine einzelne Sitzung für alle Anforderungen verwenden, werden Anweisungen sequenziell ausgeführt. Das Erstellen einer neuen Sitzung für jede Anforderung führt zu unnötigem Aufwand und Ressourcenunternutzung.
Hinweis
Die Erfassung der HC-Sitzung ist nicht idempotent. Mehrere Anforderungsabrufe mit derselben sessionTag führen zu unterschiedlichenn HC-Sitzungs-IDs, auch wenn sie von derselben zugrunde liegenden Livy-Sitzung unterstützt werden.
Eine schrittweise exemplarische Vorgehensweise mit Beispielcode finden Sie unter Get started with the Livy API for Fabric High Concurrency Sessions. Eine konzeptionelle Übersicht finden Sie unter High concurrency support in the Fabric Livy API.
Übermitteln von Livy-API-Aufträgen
Nachdem die Einrichtung der Livy-API abgeschlossen ist, können Sie entweder Batch- oder Sitzungsaufträge übermitteln.
Integration in Fabric Umgebungen
Diese Livy-API-Sitzung wird standardmäßig für den Standardstartpool für den Arbeitsbereich ausgeführt. Alternativ können Sie Fabric Umgebungen Erstellen, Konfigurieren und Verwenden einer Umgebung in Microsoft Fabric zum Anpassen des Spark-Pools, den die Livy-API-Sitzung für diese Spark-Aufträge verwendet.
Um eine Fabric Umgebung in einer Livy Spark-Sitzung zu verwenden, aktualisieren Sie die JSON so, dass sie diese Nutzlast enthält.
create_livy_session = requests.post(livy_base_url, headers = headers, json={
"conf" : {
"spark.fabric.environmentDetails" : "{\"id\" : \""EnvironmentID""}"}
}
)
Um eine Fabric Umgebung in einer Livy Spark Batchsitzung zu verwenden, aktualisieren Sie die JSON-Nutzlast wie hier gezeigt:
payload_data = {
"name":"livybatchdemo_with"+ newlakehouseName,
"file":"abfss://YourABFSPathToYourPayload.py",
"conf": {
"spark.targetLakehouse": "Fabric_LakehouseID",
"spark.fabric.environmentDetails" : "{\"id\" : \""EnvironmentID"\"}" # Replace "EnvironmentID" with your environment ID, or remove this line to use starter pools instead of an environment
}
}
Überwachen des Anforderungsverlaufs
Sie können den Überwachungshub verwenden, um frühere Livy-API-Übermittlungen anzuzeigen und mögliche Übermittlungsfehler zu debuggen.

Zugehöriger Inhalt
- Apache Livy-REST-API-Dokumentation
- Erste Schritte mit den Administratoreneinstellungen für Ihre Fabric-Kapazität
- Apache Spark Workspace Administrationseinstellungen in Microsoft Fabric
- Registern Sie eine Anwendung mit dem Microsoft Identity Platform
- Microsoft Entra Übersicht über Berechtigung und Zustimmung
- Fabric REST-API-Bereiche
- Übersicht zur Apache Spark-Überwachung
- Apache Spark-Anwendungsdetails