Verwenden eines Notebooks zum Laden von Daten in Ihr Lakehouse
In diesem Tutorial erfahren Sie, wie Sie die Daten in Ihrem Fabric-Lakehouse mit einem Notebook lesen/schreiben. Fabric unterstützt Spark-APIs und Pandas-APIs, um dieses Ziel zu erreichen.
Laden von Daten mit einer Apache Spark-API
Verwenden Sie in der Codezelle des Notebooks das folgende Codebeispiel, um Daten aus der Quelle zu lesen und in Dateien, Tabellen oder beide Abschnitte Ihres Lakehouse zu laden.
Um den Ort anzugeben, aus dem gelesen werden soll, können Sie den relativen Pfad verwenden, wenn die Daten aus dem Standard-Lakehouse des aktuellen Notebooks stammen. Wenn die Daten aus einem anderen Lakehouse stammen, können Sie den absoluten ABFS-Pfad (Azure Blob File System) verwenden. Kopieren Sie diesen Pfad aus dem Kontextmenü der Daten.
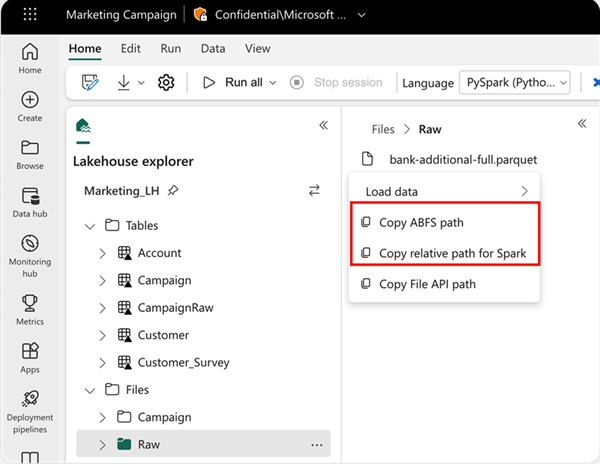
ABFS-Pfad kopieren: Damit wird der absolute Pfad der Datei zurückgegeben.
Relativen Pfad für Spark kopieren: Damit wird der relative Pfad der Datei im Standard-Lakehouse zurückgegeben.
df = spark.read.parquet("location to read from")
# Keep it if you want to save dataframe as CSV files to Files section of the default lakehouse
df.write.mode("overwrite").format("csv").save("Files/ " + csv_table_name)
# Keep it if you want to save dataframe as Parquet files to Files section of the default lakehouse
df.write.mode("overwrite").format("parquet").save("Files/" + parquet_table_name)
# Keep it if you want to save dataframe as a delta lake, parquet table to Tables section of the default lakehouse
df.write.mode("overwrite").format("delta").saveAsTable(delta_table_name)
# Keep it if you want to save the dataframe as a delta lake, appending the data to an existing table
df.write.mode("append").format("delta").saveAsTable(delta_table_name)
Laden von Daten mit einer Pandas-API
Zur Unterstützung der Pandas-API wird das Standard-Lakehouse automatisch in das Notebook eingebunden. Der Bereitstellungspunkt ist „/lakehouse/default/”. Sie können diesen Bereitstellungspunkt verwenden, um Daten aus dem Standard-Lakehouse zu lesen/schreiben. Die Option „Datei-API-Pfad kopieren” im Kontextmenü gibt den Datei-API-Pfad von diesem Bereitstellungspunkt zurück. Der von der Option ABFS-Pfad kopieren zurückgegebene Pfad funktioniert auch für die Pandas-API.
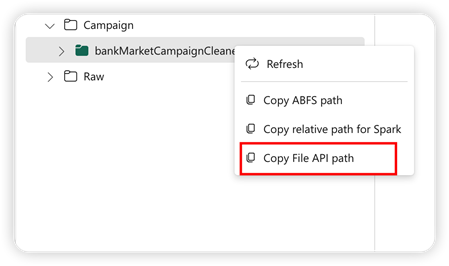
Datei-API-Pfad kopieren: Damit wird der Pfad unter dem Bereitstellungspunkt des Standard-Lakehouse zurückgegeben.
# Keep it if you want to read parquet file with Pandas from the default lakehouse mount point
import pandas as pd
df = pd.read_parquet("/lakehouse/default/Files/sample.parquet")
# Keep it if you want to read parquet file with Pandas from the absolute abfss path
import pandas as pd
df = pd.read_parquet("abfss://DevExpBuildDemo@msit-onelake.dfs.fabric.microsoft.com/Marketing_LH.Lakehouse/Files/sample.parquet")
Tipp
Verwenden Sie für die Spark-API die Option ABFS-Pfad kopieren oder Relativen Pfad für Spark kopieren, um den Pfad der Datei abzurufen. Verwenden Sie für die Pandas-API die Option ABFS-Pfad kopieren oder Datei-API-Pfad kopieren, um den Pfad der Datei abzurufen.
Die schnellste Möglichkeit, den Code für die Spark-API oder Pandas-API zu verwenden, besteht darin, die Option Daten laden zu verwenden und die API auszuwählen, die Sie verwenden möchten. Der Code wird automatisch in einer neuen Codezelle des Notebooks generiert.
