Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel wird erläutert, wie Pipelines für die Git-Integration und -Bereitstellung für User Data Functions in Microsoft Fabric funktionieren. Mit der Git-Integration können Sie Ihren Fabric-Arbeitsbereich mit einem Repository-Branch synchronisieren, sodass Sie Ihre Nutzerfunktionen versionieren, mithilfe von Branches und Pull-Requests zusammenarbeiten und mit Ihrem Code in Ihren bevorzugten Git-Tools wie Azure DevOps arbeiten zu können.
Weitere Informationen über den Prozess der Integration von Git mit Ihrem Microsoft Fabric-Arbeitsbereich finden Sie unter Grundlegende Konzepten der Git-Integration.
Herstellen einer Verbindung
Über Ihre Arbeitsbereichseinstellungen können Sie ganz einfach eine Verbindung mit Ihrem Repository einrichten, um Änderungen zu committen und zu synchronisieren. Informationen zum Einrichten der Verbindung finden Sie unter Erste Schritte mit der Git-Integration. Nach der Verbindung werden Ihre Elemente im Bereich Quellcodeverwaltung angezeigt, einschließlich der User Data Functions-Elemente.

Nachdem Sie die User Data Functions-Elemente erfolgreich in das Git-Repository committet haben, werden die User Data Functions-Ordner im Repository angezeigt. Sie können nun zukünftige Vorgänge wie das Erstellen eines Pull Requests ausführen.
Darstellung von User Data Functions in Git
Die folgende Abbildung zeigt ein Beispiel für die Dateistruktur der einzelnen Benutzerdatenfunktionen im Repository.

In der Ordnerstruktur sind die folgenden Elemente enthalten:
.platform: Die Datei
.platformenthält die folgenden Attribute: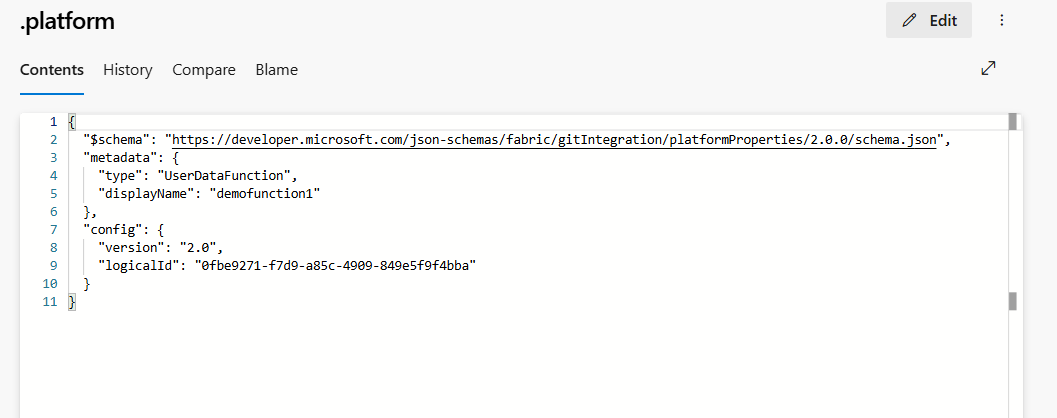
- version: Dabei handelt es sich um die Versionsnummer der Systemdateien. Diese Nummer wird verwendet, um Abwärtskompatibilität zu ermöglichen. Die Versionsnummer des Elements kann unter Umständen anders lauten.
- logicalId: Dabei handelt es sich um einen automatisch generierten arbeitsbereichsübergreifenden Bezeichner, der ein Element und seine Darstellung der Quellcodeverwaltung darstellt.
-
type:
UserDataFunctionist der Typ zum Definieren eines User Data Functions-Elements. - displayName: Hiermit wird der Namen des Elements dargestellt. Wenn das User Data Functions-Element umbenannt wird, wird dieses displayName-Element aktualisiert.
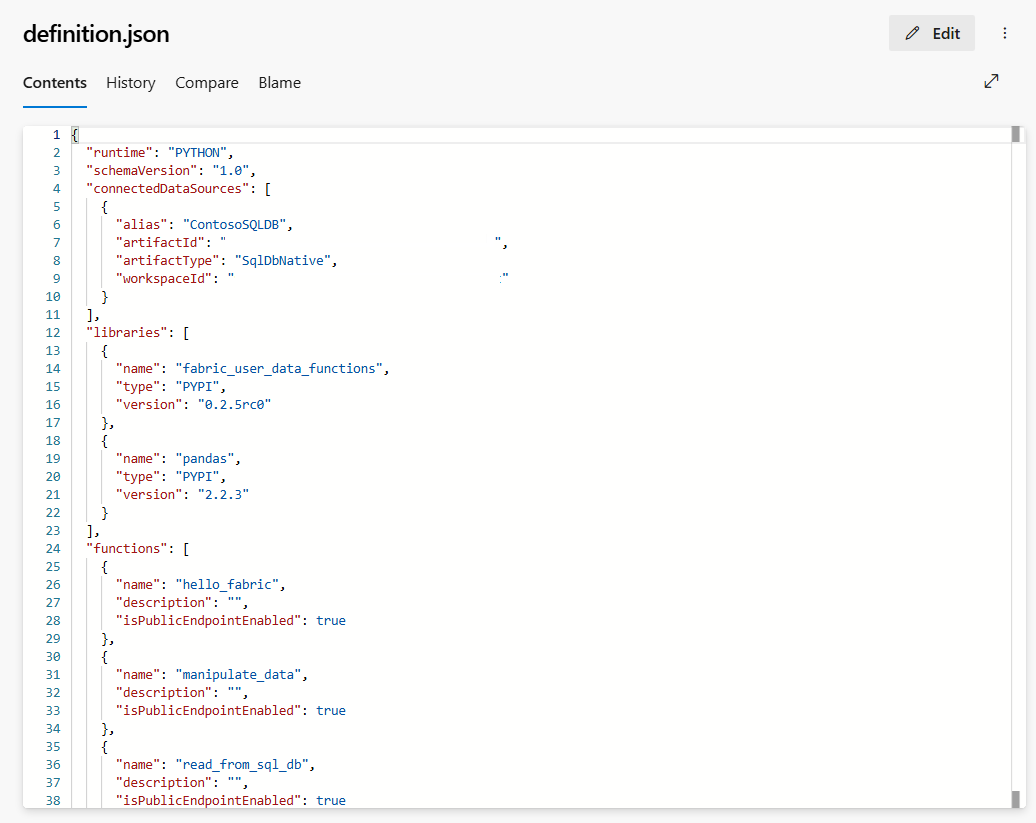
definitions.json: Diese Datei gibt alle Definitionen des User Data Functions-Elements wie Verbindungen oder Bibliotheken als Darstellung der Eigenschaften des User Data Functions-Elements an.
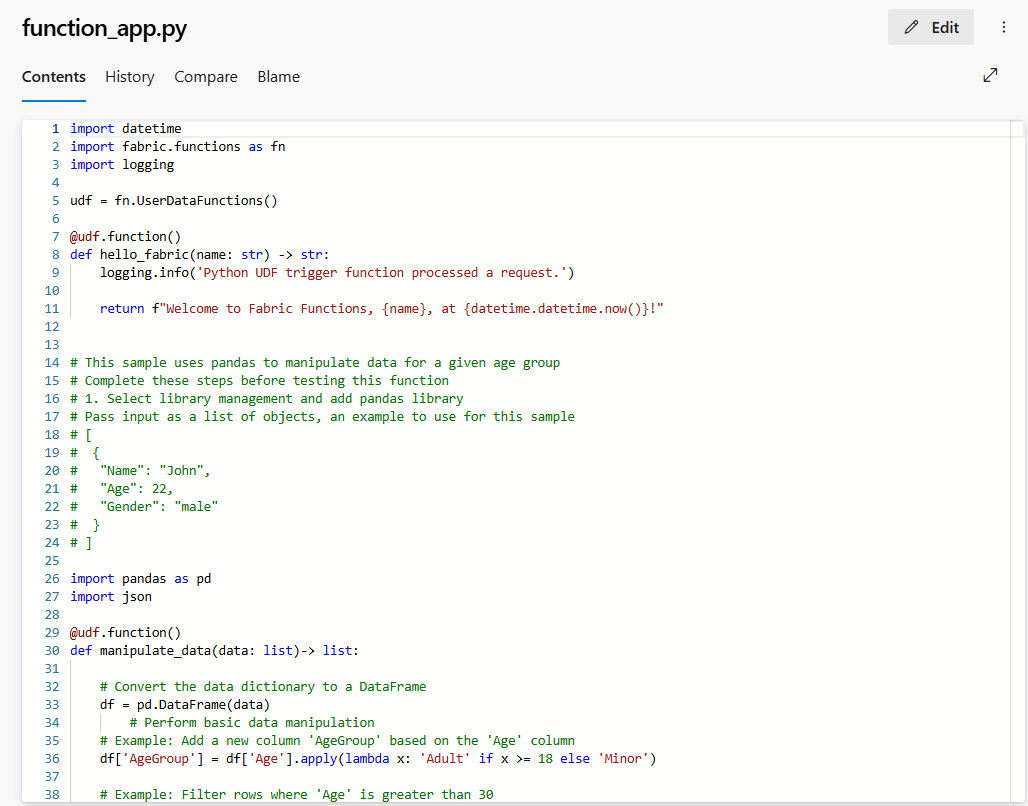
function-app.py: Bei dieser Datei handelt es sich um Ihren Funktionscode. Alle Codeänderungen, die Sie am User Data Functions-Element vornehmen, werden mit diesem Repository synchronisiert. Sie können verschiedene Git-Vorgänge ausführen, um den Codeentwicklungszyklus zu verwalten.
resources: Der Ordner enthält die Datei „functions.json“ mit allen Metadaten wie Verbindungen, Bibliotheken und Funktionen in diesem Element. Aktualisieren Sie diese Datei NICHT manuell.
functions.jsonermöglicht es Fabric, in einem Arbeitsbereich das User Data Functions-Element zu erstellen oder es neu zu erstellen.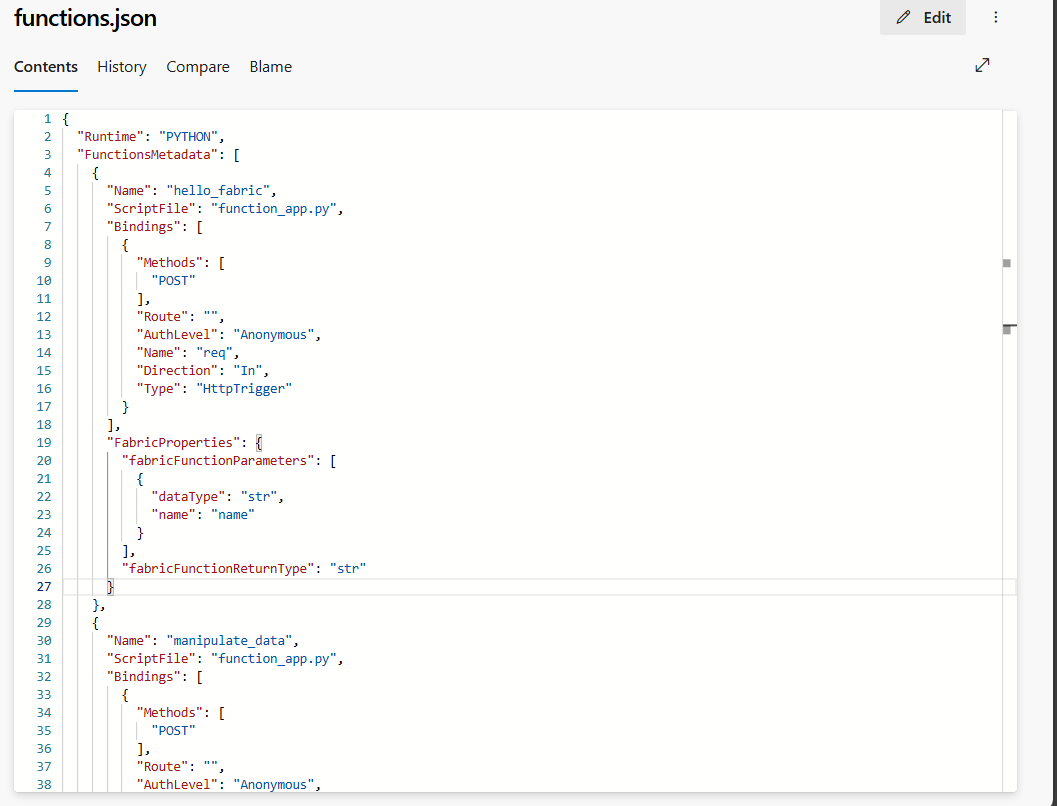




Weitere Informationen zur Git-Integration, einschließlich Details zur Ordnerstruktur und Systemdateien, finden Sie im Quellcodeformat der Git-Integration.
User Data Functions in Bereitstellungspipelines
Sie können Bereitstellungspipelines verwenden, um Ihre Benutzerdatenfunktionen in verschiedenen Umgebungen bereitzustellen, z. B. Entwicklung, Test und Produktion. Bereitstellungspipelines helfen Ihnen, Ihren Entwicklungsprozess zu optimieren, Qualität und Konsistenz sicherzustellen und manuelle Fehler mit einfachen, low-code-Vorgängen zu reduzieren.
Hinweis
Alle Verbindungen und Bibliotheken werden neuen User Data Functions-Elementen hinzugefügt, die in anderen Umgebungen erstellt wurden.
So stellen Sie Ihre Benutzerdatenfunktionen mithilfe einer Bereitstellungspipeline bereit:
Erstellen Sie eine neue Bereitstellungspipeline, oder öffnen Sie eine vorhandene Bereitstellungspipeline. Weitere Informationen finden Sie unter Erste Schritte mit Bereitstellungspipelines.
Weisen Sie Arbeitsbereiche entsprechend Ihren Bereitstellungszielen verschiedenen Phasen zu.
Wählen Sie Elemente einschließlich User Data Functions-Elementen zwischen verschiedenen Phasen aus, zeigen Sie diese an und vergleichen Sie sie.
Wählen Sie Bereitstellen aus, um das User Data Functions-Element in Ihrer Testumgebung bereitzustellen. Sie können einen Hinweis hinzufügen, um Details zu den Änderungen an dieser Bereitstellung anzugeben. Ebenso können Sie Änderungen an die Phasen Entwicklung, Test und Produktion pushen.
Überwachen Sie den Bereitstellungsstatus unter Bereitstellungsverlauf.