Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In einer Pipeline können Sie die Kopieraktivität verwenden, um Daten zwischen Datenspeichern in der Cloud zu kopieren. Nachdem Sie die Daten kopiert haben, können Sie andere Aktivitäten in Ihrer Pipeline verwenden, um sie zu transformieren und zu analysieren.
Die Kopieraktivität verbindet sich mit Ihren Datenquellen und Zielen und verschiebt dann Daten effizient zwischen ihnen. So behandelt der Dienst den Kopiervorgang:
- Stellt eine Verbindung mit Ihrer Quelle her: Erstellt eine sichere Verbindung zum Lesen von Daten aus Ihrem Quelldatenspeicher.
- Verarbeitet die Daten: Verarbeitet Serialisierung/Deserialisierung, Komprimierung/Dekomprimierung, Spaltenzuordnung und Datentypkonvertierungen basierend auf Ihrer Konfiguration.
- Schreibt an das Ziel: Überträgt die verarbeiteten Daten an Ihren Zieldatenspeicher.
- Bietet Überwachung: Verfolgt den Kopiervorgang und bietet detaillierte Protokolle und Metriken zur Problembehandlung und Optimierung.
Tip
Wenn Sie Ihre Daten nur kopieren müssen und keine Transformationen benötigen, ist ein Kopierauftrag möglicherweise eine bessere Option für Sie. Kopieraufträge bieten eine vereinfachte Erfahrung für Szenarien der Datenverschiebung, für die keine vollständige Pipeline erstellt werden muss. Siehe: Die Übersicht über kopieraufträge oder verwenden Sie unsere Entscheidungstabelle zum Vergleichen der Kopieraktivität und des Kopierauftrags.
Prerequisites
Um zu beginnen, müssen Sie die folgenden Voraussetzungen erfüllen:
- Ein Microsoft Fabric-Mandantenkonto mit einem aktiven Abonnement. Sie können kostenlos ein Konto erstellen.
- Ein Microsoft Fabric-fähiger Arbeitsbereich.
Hinzufügen einer Copy-Aktivität mit dem Kopier-Assistenten
Führen Sie die folgenden Schritte aus, um Ihre Copy-Aktivität mithilfe des Kopier-Assistenten einzurichten.
Beginnen mit dem Kopier-Assistenten
Öffnen Sie eine vorhandene Pipeline, oder erstellen Sie eine neue Pipeline.
Wählen Sie Daten kopieren auf dem Canvas aus, um den Kopier-Assistenten zu öffnen, um loszulegen. Alternativ können Sie in der Dropdownliste Daten kopieren auf der Registerkarte Aktivitäten im Menüband die Option Kopier-Assistent verwenden auswählen.


Konfigurieren der Quelle
Wählen Sie einen Datenquellentyp aus der Kategorie aus. Sie verwenden Azure Blob Storage als Beispiel. Wählen Sie Azure Blob Storage aus.

Stellen Sie eine Verbindung mit Ihrer Datenquelle her, indem Sie Neue Verbindung erstellen auswählen.

Nachdem Sie neue Verbindung erstellen ausgewählt haben, geben Sie die erforderlichen Verbindungsinformationen ein, und wählen Sie dann Weiter aus. Ausführliche Informationen zur Verbindungserstellung für jeden Datenquellentyp finden Sie im Artikel zum jeweiligen Connector.
Wenn Sie bereits Über Verbindungen verfügen, können Sie "Vorhandene Verbindung" auswählen und ihre Verbindung aus der Dropdownliste auswählen.

Wählen Sie die Datei oder den Ordner aus, die bzw. der in diesem Quellkonfigurationsschritt kopiert werden soll, und wählen Sie dann Weiter aus.





Konfigurieren des Ziels
Wählen Sie einen Datenquellentyp aus der Kategorie aus. Sie verwenden Azure Blob Storage als Beispiel. Sie können entweder eine neue Verbindung erstellen, die mit einem neuen Azure Blob Storage-Konto verknüpft ist, indem Sie die Schritte im vorherigen Abschnitt ausführen, oder eine vorhandene Verbindung aus der Verbindungsdropdownliste verwenden. Die Funktionen "Verbindung testen " und " Bearbeiten" stehen für jede ausgewählte Verbindung zur Verfügung.
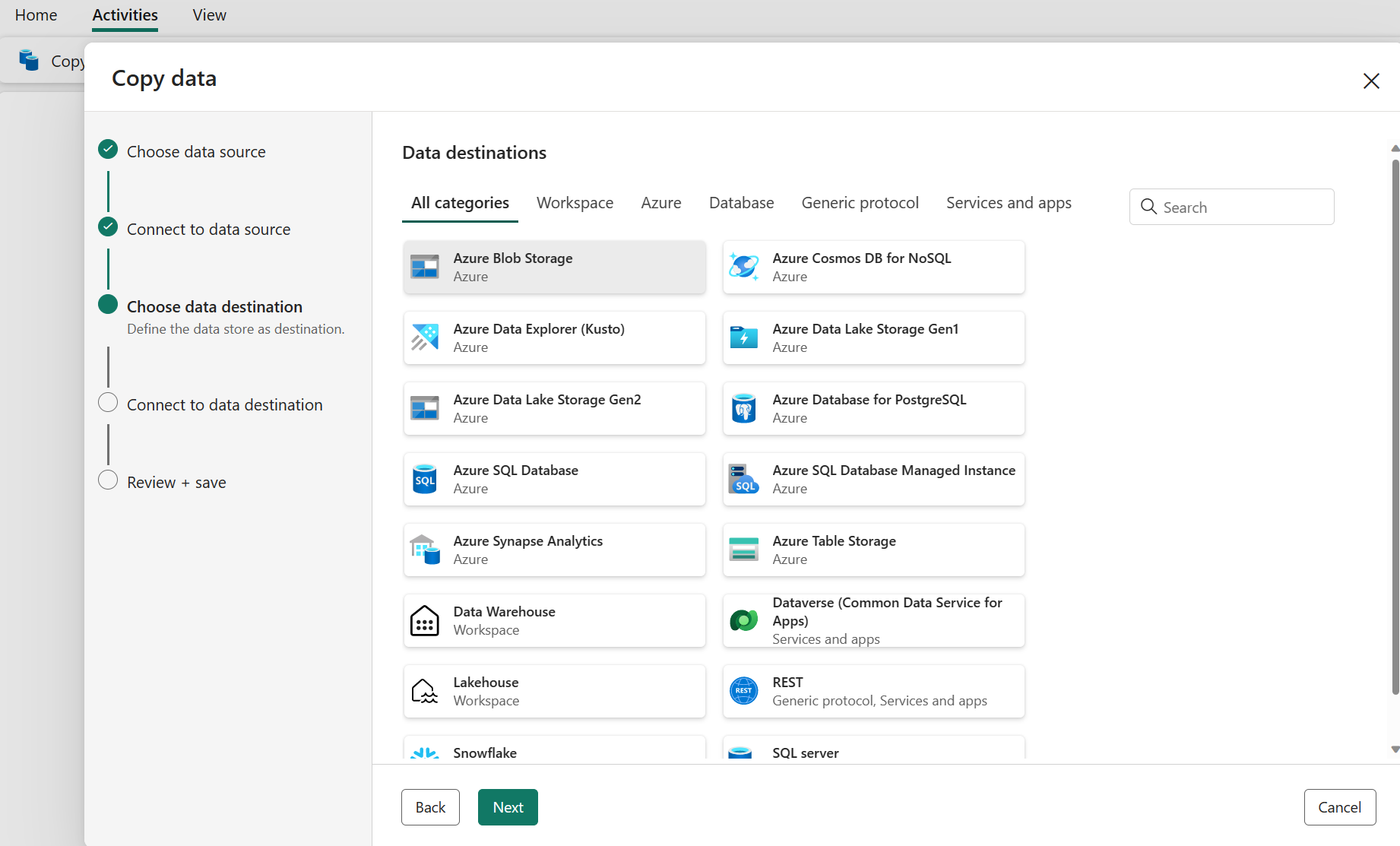
Konfigurieren Sie Ihre Quelldaten, und ordnen Sie sie Ihrem Ziel zu. Wählen Sie dann Weiter aus, um ihre Zielkonfigurationen abzuschließen.

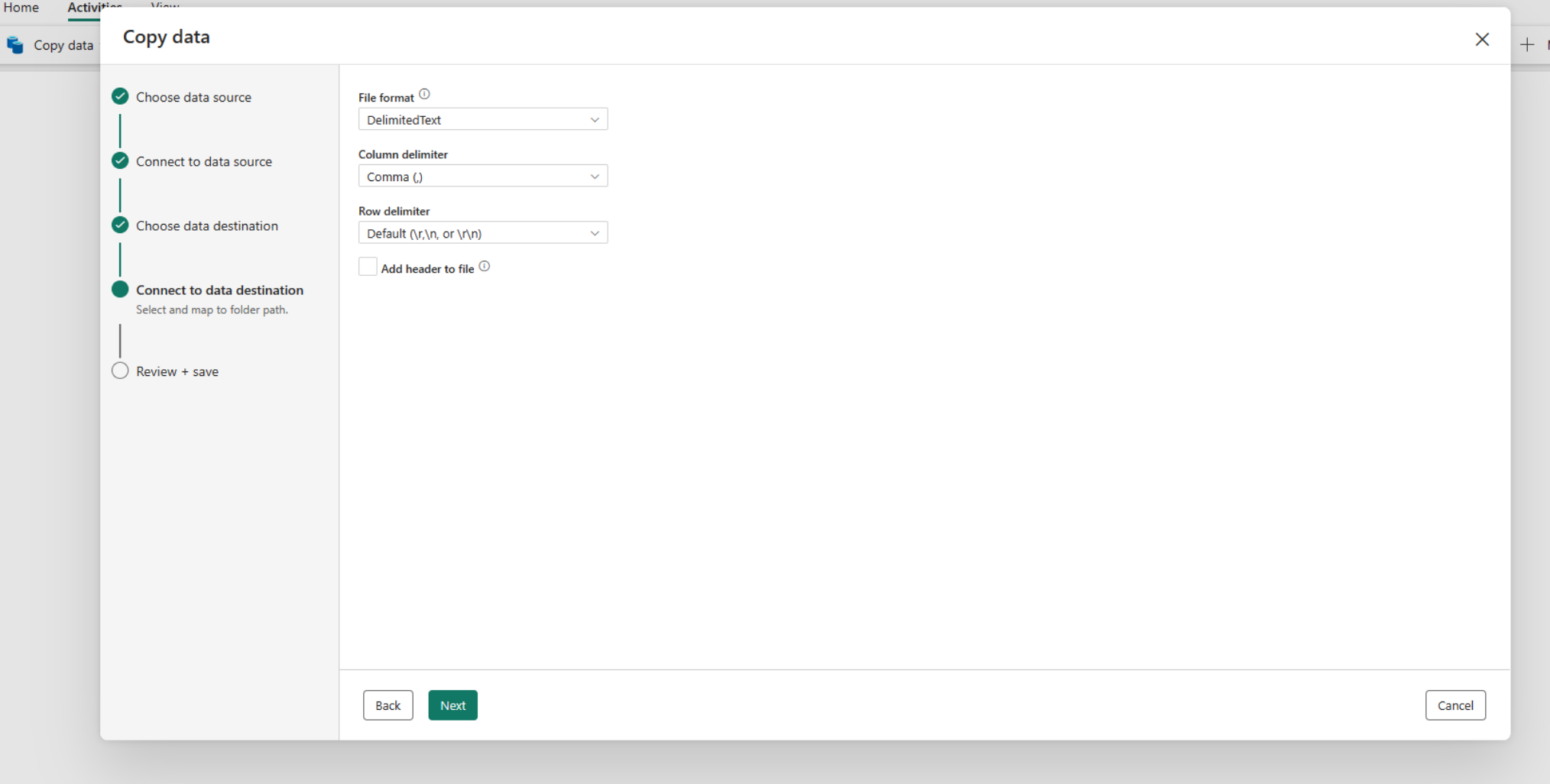
Note
Sie können nur ein einziges lokales Daten-Gateway innerhalb desselben Kopiervorgangs verwenden. Wenn sowohl Quell- als auch Senken lokale Datenquellen sind, müssen sie dasselbe Gateway verwenden. Um Daten zwischen lokalen Datenquellen mit verschiedenen Gateways zu verschieben, müssen Sie die Daten mithilfe des ersten Gateways in eine Zwischen-Cloudquelle innerhalb einer einzigen Kopieraktivität kopieren. Dann können Sie einen weiteren Kopiervorgang verwenden, um es von der intermediären Cloud-Quelle über das zweite Gateway zu kopieren.



Überprüfen und Erstellen Ihrer Kopieraktivität
Überprüfen Sie die Einstellungen Ihrer Copy-Aktivität in den vorherigen Schritten, und wählen Sie OK aus, um den Vorgang abzuschließen. Sie können auch zu den vorherigen Schritten zurückkehren, um Ihre Einstellungen bei Bedarf im Tool zu bearbeiten.


Nach Abschluss wird die Kopieraktivität zu Ihrem Pipeline-Canvas hinzugefügt. Alle Einstellungen, einschließlich erweiterter Einstellungen für diese Copy-Aktivität, sind unter den Registerkarten verfügbar, wenn diese ausgewählt sind.

Jetzt können Sie Ihre Pipeline entweder mit dieser einzelnen Kopieraktivität speichern oder ihre Pipeline weiter entwerfen.
Direktes Hinzufügen einer Copy-Aktivität
Führen Sie die folgenden Schritte aus, um eine Copy-Aktivität direkt hinzuzufügen.
Hinzufügen einer Kopier-Aktivität
Öffnen Sie eine vorhandene Pipeline, oder erstellen Sie eine neue Pipeline.
Fügen Sie eine Copy-Aktivität hinzu, indem Sie entweder Pipelineaktivität hinzufügen>Copy-Aktivität oder Daten kopieren>Zu Canvas hinzufügen unter der Registerkarte Aktivitäten auswählen.


Konfigurieren Ihrer allgemeinen Einstellungen auf der Registerkarte „Allgemein“
Informationen zum Konfigurieren Ihrer allgemeinen Einstellungen finden Sie unter Allgemein.
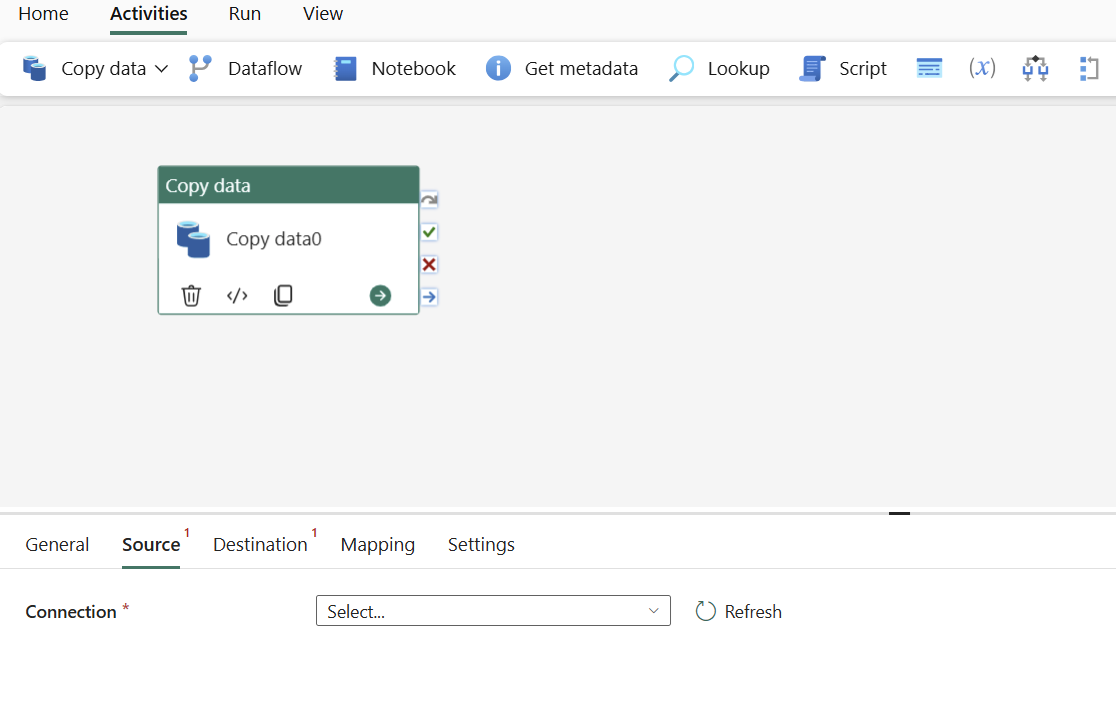
Konfigurieren der Quelle auf der Registerkarte „Quelle“
Wählen Sie in "Verbindung" eine vorhandene Verbindung aus, oder wählen Sie "Mehr " aus, um eine neue Verbindung zu erstellen.
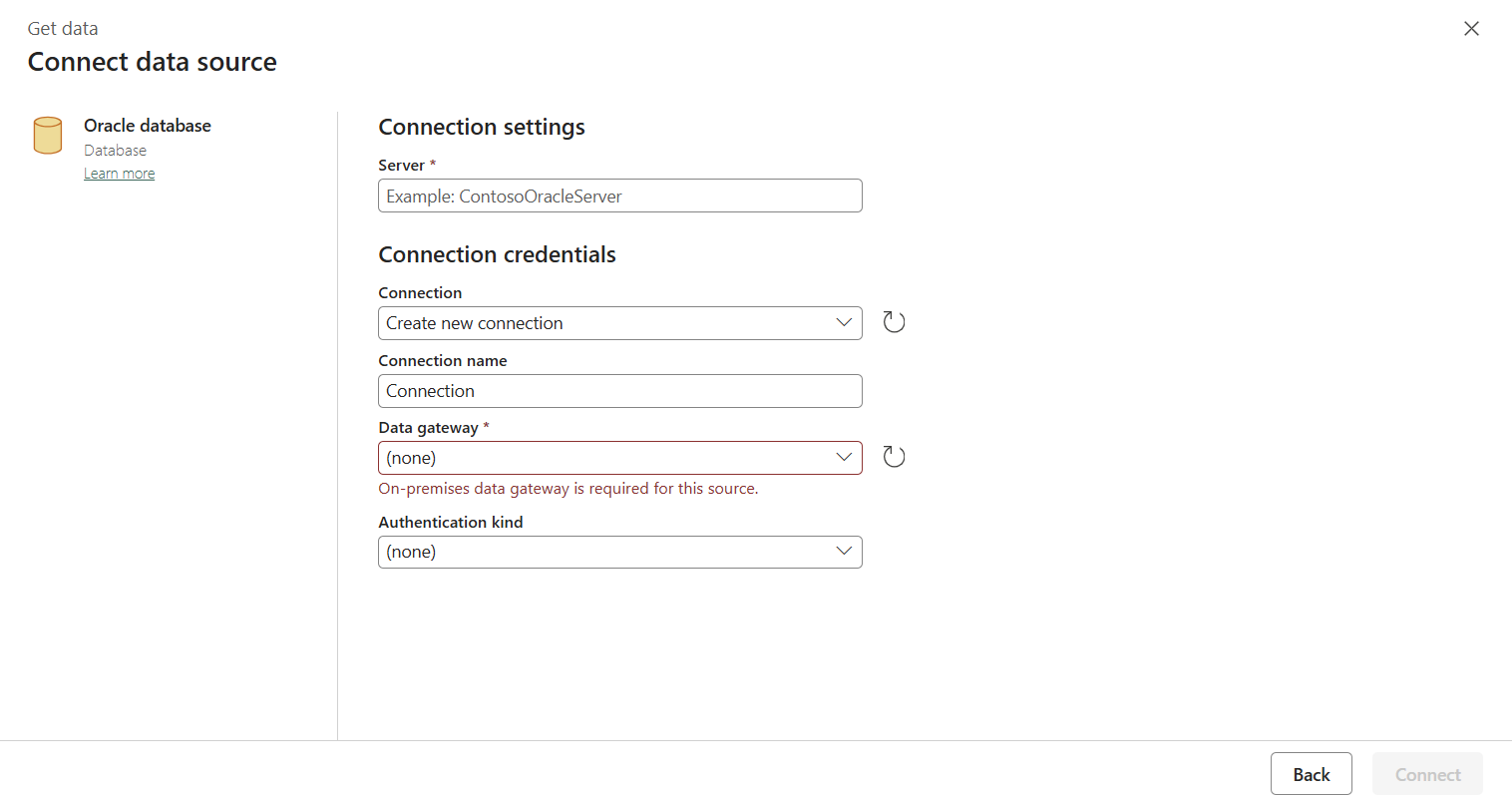
Wählen Sie im Popupfenster den Datenquellentyp aus. Sie verwenden Azure SQL-Datenbank als Beispiel. Wählen Sie Azure SQL-Datenbank und dann Weiter aus.

Die Navigation erfolgt zur Verbindungserstellungsseite. Geben Sie die erforderlichen Verbindungsinformationen in den Bereich ein, und wählen Sie dann Erstellen aus. Ausführliche Informationen zur Verbindungserstellung für jeden Datenquellentyp finden Sie im Artikel zum jeweiligen Connector.
Nachdem Die Verbindung erstellt wurde, gelangen Sie zurück zur Pipelineseite. Wählen Sie dann "Aktualisieren" aus, um die Verbindung abzurufen, die Sie aus der Dropdownliste erstellt haben. Sie können auch eine vorhandene Azure SQL-Datenbankverbindung direkt aus der Dropdownliste auswählen, wenn Sie sie bereits zuvor erstellt haben. Die Funktionen "Verbindung testen " und " Bearbeiten" stehen für jede ausgewählte Verbindung zur Verfügung. Wählen Sie dann unter Verbindungstyp die Option Azure SQL-Datenbank aus.
Geben Sie eine zu kopierende Tabelle an. Wählen Sie Vorschau der Daten aus, um eine Vorschau Ihrer Quelltabelle anzuzeigen. Sie können auch Abfrage und Gespeicherte Prozedur verwenden, um Daten aus Ihrer Quelle zu lesen.
Erweitern Sie "Erweitert ", um erweiterte Einstellungen wie Abfragetimeout oder Partitionierung zu verwenden. (Erweiterte Einstellungen variieren je nach Connector.)



Konfigurieren Ihres Ziels auf der Registerkarte „Ziel“
Wählen Sie in "Verbindung " eine vorhandene Verbindung aus, oder wählen Sie "Mehr " aus, um eine neue Verbindung zu erstellen. Dabei kann es sich entweder um Ihren internen Erstklassigen Datenspeicher aus Ihrem Arbeitsbereich, z. B. Lakehouse, oder um Ihre externen Datenspeicher handeln. In diesem Beispiel verwenden wir Lakehouse.
Nachdem Die Verbindung erstellt wurde, gelangen Sie zurück zur Pipelineseite. Wählen Sie dann "Aktualisieren" aus, um die Verbindung abzurufen, die Sie aus der Dropdownliste erstellt haben. Sie können auch eine vorhandene Lakehouse-Verbindung direkt aus der Dropdownliste auswählen, wenn Sie sie bereits zuvor erstellt haben.
Geben Sie eine Tabelle an, oder richten Sie den Dateipfad ein, um die Datei oder den Ordner als Ziel zu definieren. Wählen Sie hier Tabellen aus, und geben Sie eine Tabelle zum Schreiben von Daten an.
Erweitern Sie Erweitert, um weitere erweiterte Einstellungen anzuzeigen, wie maximale Zeilen pro Datei oder Aktionen mit Tabellen. (Erweiterte Einstellungen variieren je nach Connector.)
Jetzt können Sie Ihre Pipeline entweder mit dieser Kopieraktivität speichern oder ihre Pipeline weiter entwerfen.
Konfigurieren Sie Ihre Zuordnungen im Register „Zuordnungen“
Wenn der von Ihnen verwendete Connector die Zuordnung unterstützt, können Sie zur Registerkarte "Zuordnung " wechseln, um Ihre Zuordnung zu konfigurieren.
Wählen Sie Schemas importieren aus, um Ihr Datenschema zu importieren.

Die automatische Zuordnung wird angezeigt. Geben Sie die Quellspalte und Zielspalte an. Wenn Sie eine neue Tabelle im Ziel erstellen, können Sie den Namen der Zielspalte hier anpassen. Wenn Sie Daten in die vorhandene Zieltabelle schreiben möchten, können Sie den Namen der vorhandenen Zielspalte nicht ändern. Sie können auch den Typ der Quell- und Zielspalten anzeigen.
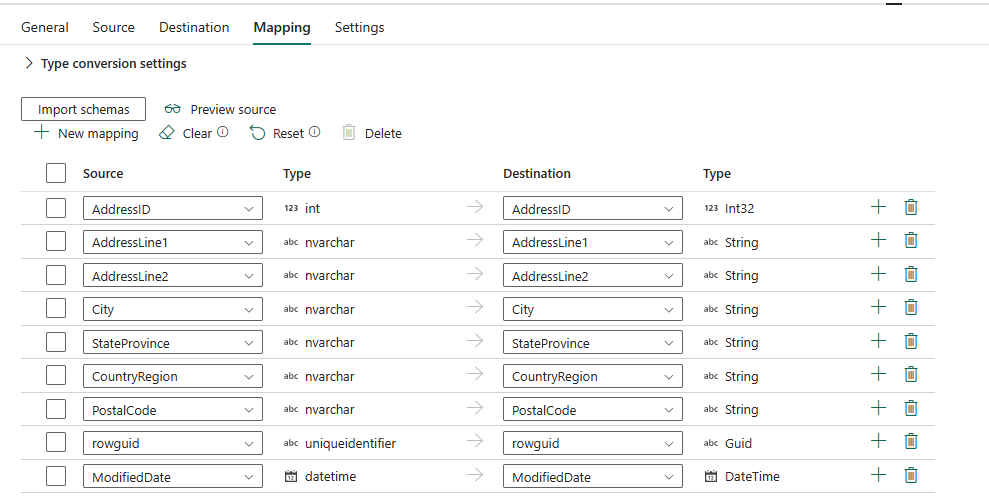


Sie können auch +Neue Zuordnung auswählen, um neue Zuordnung hinzuzufügen, wählen Sie "Löschen " aus, um alle Zuordnungseinstellungen zu löschen, und wählen Sie "Zurücksetzen " aus, um alle Zuordnungsquellspalte zurückzusetzen.
Datentypzuordnung
Kopieraktivitäten innerhalb von Pipelines und Kopierjobs führen die Zuordnung von Quelltypen zu Zieltypen gemäß dem folgenden Ablauf durch:
- Konvertieren Sie von systemeigenen Quelldatentypen in Zwischendatentypen, die von Fabric Data Factory verwendet werden.
- Wandeln Sie den Zwischendatentyp bei Bedarf automatisch um, um den entsprechenden Zieltypen zu entsprechen.
- Konvertieren Sie zwischen Zwischendatentypen in systemeigene Zieldatentypen.
Kopieraktivitäten in Pipelines und Kopieraufträge unterstützen derzeit die folgenden Zwischen-Datentypen: Boolean, Byte, Byte array, Datetime, DatetimeOffset, Decimal, Double, GUID, Int16, Int32, Int64, SByte, Single, String, Timespan, UInt16, UInt32 und UInt64.
Die folgenden Datentypkonvertierungen werden zwischen den Zwischentypen von Quelle zu Ziel unterstützt.
| Quelle\Ziel | Boolean | Byte-Array | Datum/Uhrzeit | Decimal | Gleitkommapunkt | GUID | Integer | String | TimeSpan |
|---|---|---|---|---|---|---|---|---|---|
| Boolean | ✓ | ✓ | ✓ | ✓ | |||||
| Byte-Array | ✓ | ✓ | |||||||
| Datum/Uhrzeit | ✓ | ✓ | |||||||
| Decimal | ✓ | ✓ | ✓ | ✓ | |||||
| Gleitkommapunkt | ✓ | ✓ | ✓ | ✓ | |||||
| GUID | ✓ | ✓ | |||||||
| Integer | ✓ | ✓ | ✓ | ✓ | |||||
| String | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| TimeSpan | ✓ | ✓ |
(1) Datum/Uhrzeit umfasst DateTime, DateTimeOffset, Datum und Uhrzeit.
(2) „Float-point“ beinhaltet „Single“ und „Double“.
(3) „Integer“ beinhaltet „SByte“, „Byte“, „Int16“, „UInt16“, „Int32“, „UInt32“, „Int64“ und „UInt64“.
Weitere Informationen zu den detaillierten Datentypkonvertierungen für einen bestimmten Connector finden Sie im Artikel zur Konfiguration der Kopieraktivität für diesen Connector hier.
Note
Derzeit wird diese Datentypkonvertierung beim Kopieren zwischen tabellarischen Daten unterstützt. Hierarchische Quellen/Ziele werden nicht unterstützt, was bedeutet, dass keine systemdefinierte Datentypkonvertierung zwischen Quell- und Zielzwischentypen vorhanden ist.
Konfigurieren der anderen Einstellungen auf der Registerkarte „Einstellungen“
Die Registerkarte Einstellungen enthält die Einstellungen für Leistung, Staging usw.

In der folgenden Tabelle werden die einzelnen Einstellungen beschrieben.
| Setting | Description | JSON-Skripteigenschaft |
|---|---|---|
| Intelligente Durchsatzoptimierung | Geben Sie Folgendes an, um den Durchsatz zu optimieren. Es gibt folgende Auswahlmöglichkeiten: • Auto • Standard • Ausgeglichen • Maximum Wenn Sie Automatisch auswählen, wird die optimale Einstellung basierend auf Ihrem Quell-Ziel-Paar und Datenmuster dynamisch angewendet. Sie können ihren Durchsatz auch anpassen, und der benutzerdefinierte Wert kann 4-256 sein, während höherer Wert mehr Gewinne bedeutet. |
dataIntegrationUnits |
| Parallelitätsgrad für Kopiervorgänge | Geben Sie den Parallelitätsgrad an, der beim Laden von Daten verwendet werden soll. | parallelCopies |
| Adaptive Leistungsoptimierung (Vorschau) | Geben Sie an, ob der Dienst Leistungsoptimierungen und Optimierungen gemäß der benutzerdefinierten Konfiguration anwenden kann. | adaptive Leistungsoptimierung |
| Überprüfung der Datenkonsistenz | Wenn Sie diese Eigenschaft festlegen true , überprüft die Kopieraktivität beim Kopieren von Binärdateien die Dateigröße, lastModifiedDate und die Prüfsumme für jede binärdatei, die aus der Quelle in den Zielspeicher kopiert wurde, um die Datenkonsistenz zwischen Quell- und Zielspeicher sicherzustellen. Beim Kopieren von Tabellendaten überprüft die Kopieraktivität nach Abschluss des Auftrags die Gesamtzeilenzahl, um sicherzustellen, dass die Gesamtanzahl der aus der Quelle gelesenen Zeilen mit der Anzahl der in das Ziel kopierten Zeilen plus der Anzahl der inkompatiblen und übersprungenen Zeilen übereinstimmt. Beachten Sie, dass die Kopierleistung durch Aktivieren dieser Option beeinträchtigt wird. |
validateDataConsistency |
| Fehlertoleranz | Wenn Sie diese Option auswählen, können Sie einige Fehler ignorieren, die in der Mitte des Kopiervorgangs auftreten. Beispiel: Inkompatible Zeilen zwischen Quell- und Zielspeicher, Datei, die während der Datenverschiebung gelöscht wird usw. | • enableSkipIncompatibleRow (Aktivieren von 'Überspringen inkompatibler Zeilen') • skipErrorFile: fileMissing fileForbidden invalidFileName |
| Aktivieren der Protokollierung | Wenn Sie diese Option auswählen, können Sie protokollieren: kopierte Dateien, übersprungene Dateien und Zeilen. | / |
| Staging aktivieren | Legen Sie fest, ob Daten über einen Zwischenspeicher kopiert werden sollen. Aktivieren Sie Staging nur für hilfreiche Szenarien. | enableStaging |
| Für Arbeitsbereich | ||
| Workspace | Geben Sie an, dass der integrierte Stagingspeicher verwendet werden soll. Stellen Sie sicher, dass der/die letzte Benutzer*in, der/die die Pipeline geändert hat, mindestens die Rolle "Mitwirkender" im Arbeitsbereich zugewiesen ist. | / |
| Für Extern | ||
| Stagingkonto-Verknüpfung | Geben Sie die Verbindung eines Azure Blob Storage oder Azure Data Lake Storage Gen2 an, das sich auf die Instanz von Storage bezieht, die Sie als Staging-Zwischenspeicher verwenden. Erstellen Sie eine Stagingverbindung, wenn sie nicht vorhanden ist. | Verbindung (unter externalReferences) |
| Speicherpfad | Geben Sie den gewünschten Pfad für die vorbereiteten Daten an. Wenn Sie keinen Pfad angeben, erstellt der Dienst einen Container zum Speichern der temporären Daten. Geben Sie nur dann einen Pfad an, wenn Sie Storage mit einer Shared Access Signature verwenden oder sich die temporären Daten an einem bestimmten Speicherort befinden müssen. | path |
| Komprimierung aktivieren | Gibt an, ob die Daten komprimiert werden sollen, bevor sie an das Ziel kopiert werden. Durch diese Einstellung wird die Menge der übertragenen Daten reduziert. | enableCompression |
| Preserve | Legen Sie fest, ob Metadaten/ACLs beim Kopieren von Daten beibehalten werden sollen. | preserve |
Note
Wenn Sie das phasenweise Kopieren mit aktivierter Komprimierung verwenden, wird die Dienstprinzipalauthentifizierung für das Staging von Blob-Verbindungen nicht unterstützt.
Note
Das Staging im Arbeitsbereich läuft nach 60 Minuten ab. Für lang andauernde Aufträge empfiehlt es sich, externen Speicher für die Zwischenspeicherung zu verwenden.
Konfigurieren von Parametern in einer Kopieraktivität
Parameter können verwendet werden, um das Verhalten einer Pipeline und deren Aktivitäten zu steuern. Sie können Dynamischen Inhalt hinzufügen verwenden, um Parameter für Ihre Kopieraktivitätseigenschaften anzugeben. Nehmen wir die Spezifikation von Lakehouse/Data Warehouse als Beispiel, um zu sehen, wie diese genutzt werden kann.
Wählen Sie in Ihrer Quelle oder Ihrem Ziel "Dynamische Inhalte verwenden " in der Dropdownliste der Verbindung aus.
Klicken Sie im Popup-Bereich Dynamischen Inhalt hinzufügen auf der Registerkarte Parameter auf +.
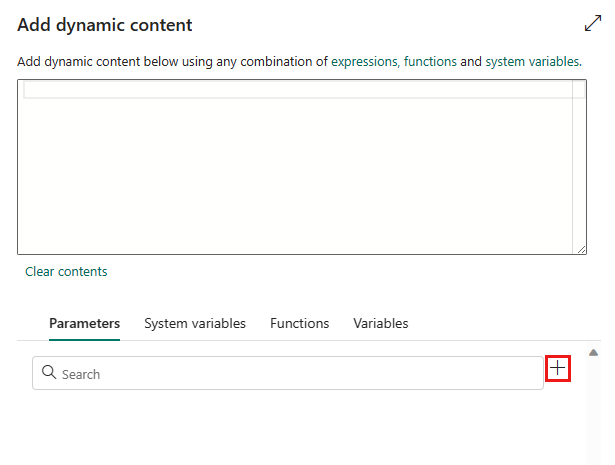
Geben Sie den Namen für den Parameter an, und geben Sie ihm bei Bedarf einen Standardwert an, oder Sie können den Wert für den Parameter angeben, wenn er in der Pipeline ausgelöst wird.

Der Parameterwert sollte Lakehouse/Data Warehouse-Verbindungs-ID sein. Um dies zu erhalten, öffnen Sie Ihre Manage Connections and Gateways, wählen Sie die Lakehouse/Data Warehouse-Verbindung aus, die Sie verwenden möchten, und öffnen Sie "Einstellungen ", um Ihre Verbindungs-ID abzurufen. Wenn Sie eine neue Verbindung erstellen möchten, können Sie auf dieser Seite +Neu auswählen oder zur Datenseite über die Dropdownliste "Verbindung " wechseln.
Wählen Sie Speichern aus, um zum Bereich Dynamischen Inhalt hinzufügen zurückzukehren. Wählen Sie dann Ihren Parameter aus, damit er im Ausdrucksfeld angezeigt wird. Klicken Sie anschließend auf OK. Sie kehren zur Pipelineseite zurück und können sehen, dass der Parameterausdruck nach der Verbindung angegeben wurde.
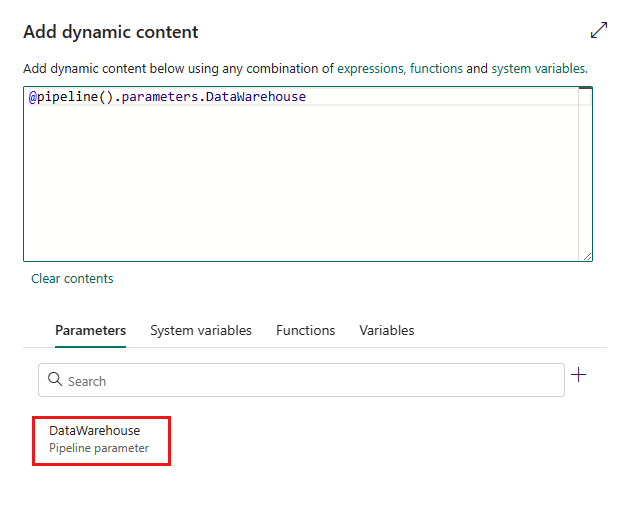
Geben Sie die ID Ihres Lakehouse oder Ihres Data Warehouse an. Um die ID zu finden, gehen Sie in Ihrem Arbeitsbereich zu Ihrem Lakehouse oder Data Warehouse. Die ID erscheint in der URL nach
/lakehouses/oder/datawarehouses/.Lakehouse ID:

Lager-ID:

Geben Sie die SQL-Verbindungszeichenfolge für Ihr Data Warehouse an.