Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Dieses Lernprogramm zeigt ein End-to-End-Beispiel für einen Synapse Data Science-Workflow in Microsoft Fabric. Das Szenario erstellt ein Modell, um vorherzusagen, ob Bankkunden absteigen. Der Begriff "Kündigungsrate" oder "Abwanderungsrate" bezeichnet die Rate, mit der Bankkunden ihre Geschäftsbeziehungen mit der Bank beenden.
In diesem Lernprogramm werden die folgenden Schritte behandelt:
- Installieren von benutzerdefinierten Bibliotheken
- Laden der Daten
- Verstehen und Verarbeiten der Daten durch explorative Datenanalyse und Veranschaulichen der Verwendung des Fabric Data Wrangler-Features
- Verwenden Sie scikit-learn und LightGBM, um machine learning Modelle zu trainieren und Experimente mit den Features MLflow und Fabric Autologging nachzuverfolgen
- Auswerten und Speichern des endgültigen machine learning Modells
- Anzeigen der Modellleistung mit Power BI-Visualisierungen
Voraussetzungen
Rufen Sie ein Microsoft Fabric-Abonnement ab. Oder registrieren Sie sich für eine kostenlose Microsoft Fabric Testversion.
Melden Sie sich bei Microsoft Fabric an.
Wechseln Sie zu Fabric, indem Sie den Benutzeroberflächenschalter auf der unteren linken Seite Ihrer Startseite verwenden.

- Erstellen Sie bei Bedarf ein Microsoft Fabric Seehaus, wie in Create a lakehouse in Microsoft Fabric beschrieben.
Mithilfe eines Notizbuchs folgen
Wenn Sie in einem Notizbuch folgen möchten, wählen Sie eine der folgenden Optionen aus:
- Öffnen sie das integrierte Notizbuch, und führen Sie es aus.
- Laden Sie Ihr Notizbuch aus GitHub hoch.
Öffnen des integrierten Notizbuchs
Das Beispielnotizbuch "Kundenabwanderung" begleitet dieses Lernprogramm.
Um das Beispielnotizbuch für dieses Lernprogramm zu öffnen, befolgen Sie die Anweisungen unter "Vorbereiten Ihres Systems für Data Science-Lernprogramme".
Stellen Sie sicher, dass Sie ein Seehaus an das Notizbuch anfügen , bevor Sie mit dem Ausführen von Code beginnen.
Importieren des Notizbuchs aus GitHub
Das Notizbuch AIsample - Bank Customer Churn.ipynb begleitet dieses Lernprogramm.
Zum Öffnen des zugehörigen Notizbuchs für dieses Lernprogramm folgen Sie den Anweisungen unter "Vorbereiten Ihres Systems für Data Science-Lernprogramme ", um das Notizbuch in Ihren Arbeitsbereich zu importieren.
Wenn Sie den Code lieber von dieser Seite kopieren und einfügen möchten, können Sie ein neues Notizbucherstellen.
Fügen Sie ein Lakehouse an das Notebook an, bevor Sie mit der Ausführung von Code beginnen.
Schritt 1: Installieren von benutzerdefinierten Bibliotheken
Für machine learning Modellentwicklung oder Ad-hoc-Datenanalyse müssen Sie möglicherweise schnell eine benutzerdefinierte Bibliothek für Ihre Apache Spark-Sitzung installieren. Sie haben zwei Optionen zum Installieren von Bibliotheken.
- Verwenden Sie die Inlineinstallationsfunktionen (
%pipoder%conda) Ihres Notizbuchs, um eine Bibliothek nur in Ihrem aktuellen Notizbuch zu installieren. - Erstellen Sie alternativ eine Fabric-Umgebung. Installieren Sie Bibliotheken aus öffentlichen Quellen, oder laden Sie benutzerdefinierte Bibliotheken darauf hoch. Ihr Arbeitsbereichsadministrator kann die Umgebung als Standard für den Arbeitsbereich anfügen. Alle Bibliotheken in der Umgebung sind für die Verwendung in allen Notizbüchern und Spark-Auftragsdefinitionen im Arbeitsbereich verfügbar. Weitere Informationen zu Umgebungen finden Sie unter Create, configure and use an environment in Microsoft Fabric.
Verwenden Sie %pip install, um die imblearn-Bibliothek in Ihrem Notebook für dieses Tutorial zu installieren.
Hinweis
Der PySpark-Kernel wird nach Ausführung von %pip install neu gestartet. Installieren Sie die erforderlichen Bibliotheken, bevor Sie andere Zellen ausführen.
# Use pip to install libraries
%pip install imblearn
Schritt 2: Laden der Daten
Das Dataset in churn.csv enthält den Abwanderungsstatus von 10.000 Kunden sowie 14 Attribute, die Folgendes umfassen:
- Kreditwürdigkeit
- Geografischer Standort (Deutschland, Frankreich, Spanien)
- Geschlecht (männlich, weiblich)
- Alter
- Tenure (Anzahl der Jahre, in denen die Person ein Kunde bei dieser Bank war)
- Kontostand
- Geschätztes Gehalt
- Anzahl der Produkte, die ein Kunde über die Bank erworben hat
- Kreditkartenstatus (unabhängig davon, ob ein Kunde über eine Kreditkarte verfügt)
- Status eines aktiven Mitglieds (unabhängig davon, ob die Person ein aktiver Bankkunde ist)
Der Datensatz enthält auch die Spalten für Zeilennummer, Kunden-ID und Kundennachname. Werte in diesen Spalten sollten nicht die Entscheidung eines Kunden beeinflussen, die Bank zu verlassen.
Ein Kundenkonto-Abschlusserereignis definiert die Abwanderung dieses Kunden. Die Datensatzspalte Exited bezieht sich auf die Kundenabwanderung. Da Sie wenig Kontext zu diesen Attributen haben, benötigen Sie keine Hintergrundinformationen zum Dataset. Sie möchten verstehen, wie diese Attribute zum Exited Status beitragen.
Von diesen 10.000 Kunden verlassen nur 2.037 Kunden (etwa 20%) die Bank. Aufgrund des Klassenungleichgewichtsverhältnisses werden synthetische Daten generiert. Verwirrungsmatrixgenauigkeit hat möglicherweise keine Relevanz für die unausgeglichene Klassifizierung. Möglicherweise möchten Sie die Genauigkeit mithilfe der Fläche unter der Precision-Recall-Kurve (AUPRC) messen.
- Diese Tabelle zeigt eine Vorschau der
churn.csvDaten:
| Kunden-ID | Surname | CreditScore | Geografie | Geschlecht | Alter | Amtszeit | Bilanz | NumOfProducts | HasCrCard | IsActiveMember | Geschätztes Gehalt | Ausgetreten |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 15634602 | Hargrave | 619 | Frankreich | Female | 42 | 2 | 0.00 | 1 | 1 | 1 | 101348.88 | 1 |
| 15647311 | Hügel | 608 | Spanien | Female | 41 | 1 | 83807.86 | 1 | 0 | 1 | 112542.58 | 0 |
Laden Sie das Dataset herunter und laden Sie es in das Seehaus hoch.
Definieren Sie diese Parameter, damit Sie dieses Notizbuch mit verschiedenen Datasets verwenden können:
IS_CUSTOM_DATA = False # If TRUE, the dataset has to be uploaded manually
IS_SAMPLE = False # If TRUE, use only SAMPLE_ROWS of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_ROOT = "/lakehouse/default"
DATA_FOLDER = "Files/churn" # Folder with data files
DATA_FILE = "churn.csv" # Data file name
Dieser Code lädt eine öffentlich verfügbare Version des Datasets herunter und speichert dieses Dataset dann in einem Fabric Lakehouse:
Von Bedeutung
Fügen Sie vor dem Ausführen des Notizbuchs ein Seehaus hinzu. Wenn Sie kein Seehaus hinzufügen, tritt ein Fehler auf.
import os, requests
if not IS_CUSTOM_DATA:
# With an Azure Synapse Analytics blob, this can be done in one line
# Download demo data files into the lakehouse if they don't exist
remote_url = "https://synapseaisolutionsa.z13.web.core.windows.net/data/bankcustomerchurn"
file_list = ["churn.csv"]
download_path = "/lakehouse/default/Files/churn/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Beginnen Sie mit der Aufzeichnung der Zeit, die zum Ausführen des Notizbuchs erforderlich ist:
# Record the notebook running time
import time
ts = time.time()
Lesen von Rohdaten aus dem Lakehouse
Dieser Code liest Rohdaten aus dem Abschnitt "Dateien" des Lakehouse und fügt weitere Spalten für verschiedene Datumskomponenten hinzu. Die Erstellung der partitionierten Delta-Tabelle verwendet diese Informationen.
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv("Files/churn/raw/churn.csv")
.cache()
)
Erstellen Sie ein pandas DataFrame aus dem Dataset.
Dieser Code konvertiert den Spark DataFrame in einen Pandas DataFrame, um die Verarbeitung und Visualisierung zu vereinfachen:
df = df.toPandas()
Schritt 3: Durchführen einer explorativen Datenanalyse
Unformatierte Daten anzeigen
Erkunden Sie die Rohdaten mithilfe von display. Berechnen Sie einige grundlegende Statistiken, und zeigen Sie Diagrammansichten an. Importieren Sie zunächst die erforderlichen Bibliotheken für die Datenvisualisierung , z. B. seegeboren. Seaborn ist eine Python-Datenvisualisierungsbibliothek und bietet eine allgemeine Schnittstelle zum Erstellen visueller Elemente auf Datenframes und Arrays.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import pandas as pd
import itertools
display(df, summary=True)
Verwenden von Data Wrangler zum Durchführen der anfänglichen Datenreinigung
Starten Sie Data Wrangler direkt aus dem Notizbuch, um Pandas-Datenframes zu erkunden und zu transformieren. Wählen Sie in der horizontalen Symbolleiste das Dropdown "Data Wrangler" aus, um die aktivierten pandas DataFrames zu durchsuchen, die bearbeitet werden können. Wählen Sie den DataFrame aus, den Sie in Data Wrangler öffnen möchten.
Hinweis
Der Daten-Assistent kann nicht geöffnet werden, während der Notebook-Kernel ausgelastet ist. Die Ausführung der Zelle muss abgeschlossen sein, bevor Sie Data Wrangler starten. Erfahren Sie mehr über Data Wrangler.

Nachdem Data Wrangler gestartet wurde, wird eine beschreibende Übersicht über das Datenpanel generiert, wie in den folgenden Abbildungen dargestellt. Die Übersicht enthält Informationen über die Dimension des DataFrame, fehlende Werte und vieles mehr. Sie können Data Wrangler verwenden, um ein Skript zu erzeugen, das die Zeilen mit fehlenden Werten, die doppelten Zeilen und die Spalten mit bestimmten Namen entfernt. Anschließend können Sie das Skript in eine Zelle kopieren. Die nächste Zelle zeigt das kopierte Skript an.


def clean_data(df):
# Drop rows with missing data across all columns
df.dropna(inplace=True)
# Drop duplicate rows in columns: 'RowNumber', 'CustomerId'
df.drop_duplicates(subset=['RowNumber', 'CustomerId'], inplace=True)
# Drop columns: 'RowNumber', 'CustomerId', 'Surname'
df.drop(columns=['RowNumber', 'CustomerId', 'Surname'], inplace=True)
return df
df_clean = clean_data(df.copy())
Bestimmen von Attributen
Dieser Code bestimmt die kategorisierten, numerischen und Zielattribute:
# Determine the dependent (target) attribute
dependent_variable_name = "Exited"
print(dependent_variable_name)
# Determine the categorical attributes
categorical_variables = [col for col in df_clean.columns if col in "O"
or df_clean[col].nunique() <=5
and col not in "Exited"]
print(categorical_variables)
# Determine the numerical attributes
numeric_variables = [col for col in df_clean.columns if df_clean[col].dtype != "object"
and df_clean[col].nunique() >5]
print(numeric_variables)
Zeigen Sie die fünfteilige Zusammenfassung an
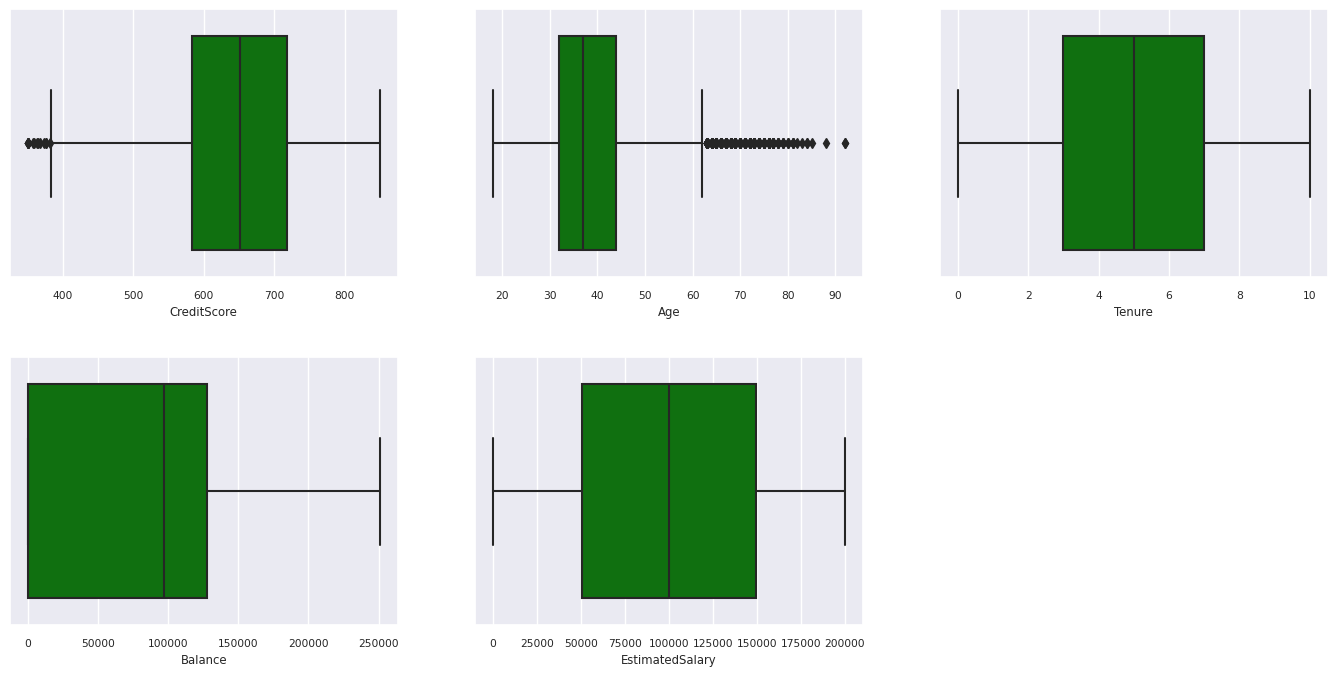
Verwenden von Boxplots zum Anzeigen der Fünf-Zahlen-Zusammenfassung
- Die Mindestbewertung
- erstes Quartil
- Median
- drittes Quartil
- Maximale Punktzahl
für die numerischen Attribute.
df_num_cols = df_clean[numeric_variables]
sns.set(font_scale = 0.7)
fig, axes = plt.subplots(nrows = 2, ncols = 3, gridspec_kw = dict(hspace=0.3), figsize = (17,8))
fig.tight_layout()
for ax,col in zip(axes.flatten(), df_num_cols.columns):
sns.boxplot(x = df_num_cols[col], color='green', ax = ax)
# fig.suptitle('visualize and compare the distribution and central tendency of numerical attributes', color = 'k', fontsize = 12)
fig.delaxes(axes[1,2])
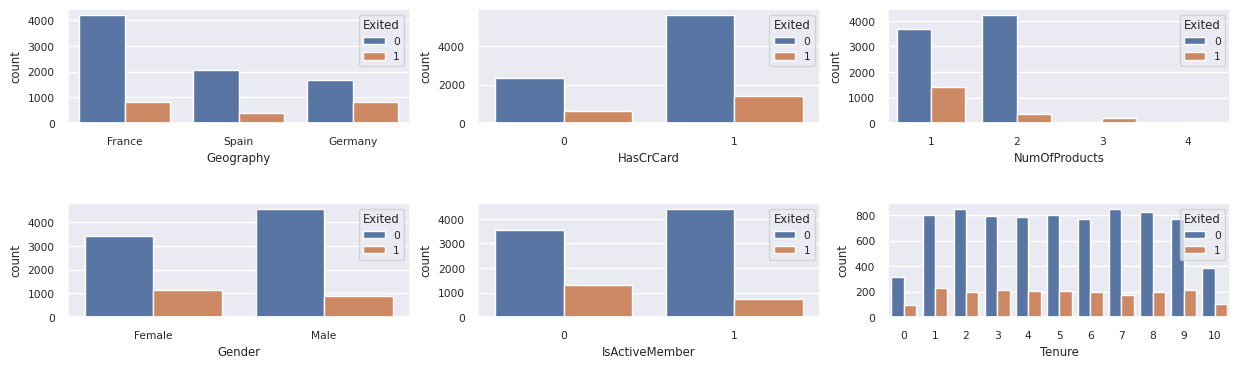
Anzeigen der Verteilung von verlassenen und verbliebenen Kunden
Zeigen Sie die Verteilung von ausgestiegenen und nicht ausgestiegenen Kunden über die kategorischen Attribute an.
attr_list = ['Geography', 'Gender', 'HasCrCard', 'IsActiveMember', 'NumOfProducts', 'Tenure']
fig, axarr = plt.subplots(2, 3, figsize=(15, 4))
for ind, item in enumerate (attr_list):
sns.countplot(x = item, hue = 'Exited', data = df_clean, ax = axarr[ind%2][ind//2])
fig.subplots_adjust(hspace=0.7)
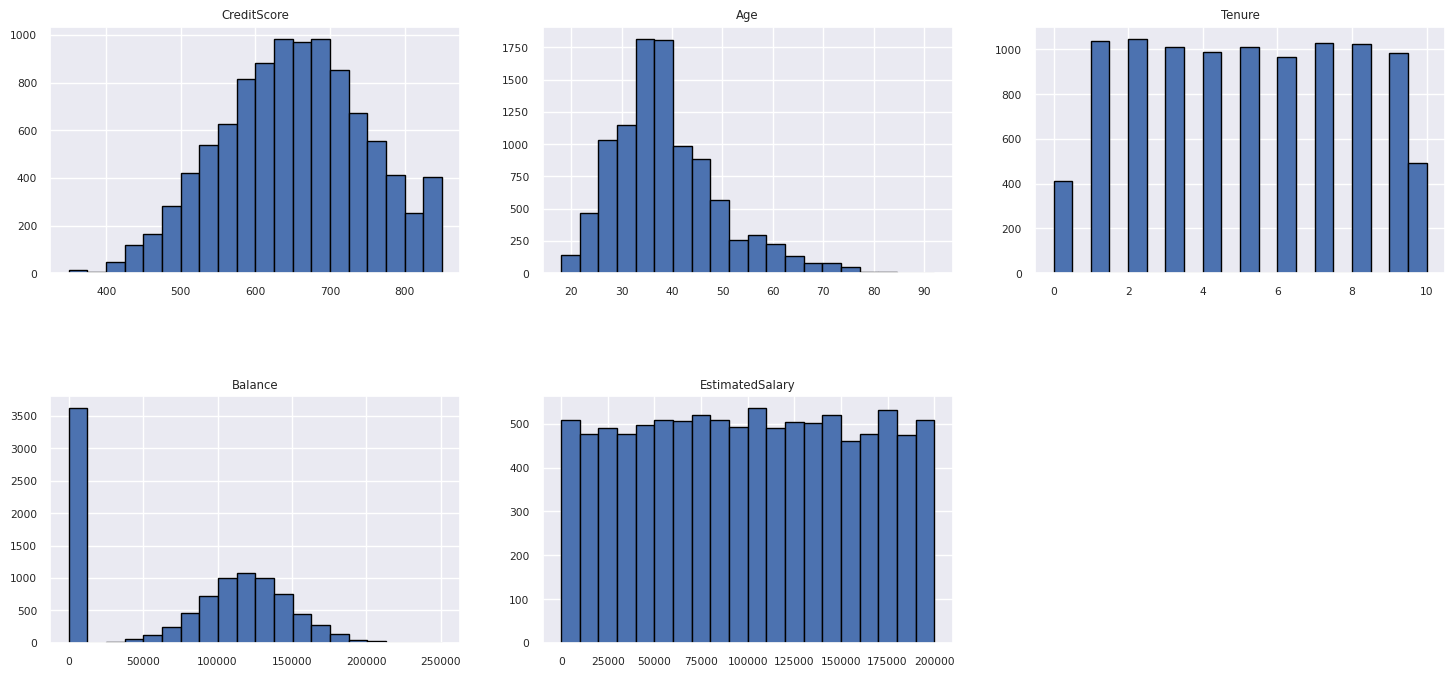
Anzeigen der Verteilung numerischer Attribute
Verwenden Sie ein Histogramm, um die Häufigkeitsverteilung numerischer Attribute anzuzeigen:
columns = df_num_cols.columns[: len(df_num_cols.columns)]
fig = plt.figure()
fig.set_size_inches(18, 8)
length = len(columns)
for i,j in itertools.zip_longest(columns, range(length)):
plt.subplot((length // 2), 3, j+1)
plt.subplots_adjust(wspace = 0.2, hspace = 0.5)
df_num_cols[i].hist(bins = 20, edgecolor = 'black')
plt.title(i)
# fig = fig.suptitle('distribution of numerical attributes', color = 'r' ,fontsize = 14)
plt.show()
Durchführung von Feature Engineering
Dieses Feature engineering generiert neue Attribute basierend auf den aktuellen Attributen:
df_clean["NewTenure"] = df_clean["Tenure"]/df_clean["Age"]
df_clean["NewCreditsScore"] = pd.qcut(df_clean['CreditScore'], 6, labels = [1, 2, 3, 4, 5, 6])
df_clean["NewAgeScore"] = pd.qcut(df_clean['Age'], 8, labels = [1, 2, 3, 4, 5, 6, 7, 8])
df_clean["NewBalanceScore"] = pd.qcut(df_clean['Balance'].rank(method="first"), 5, labels = [1, 2, 3, 4, 5])
df_clean["NewEstSalaryScore"] = pd.qcut(df_clean['EstimatedSalary'], 10, labels = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
Verwenden Sie Data Wrangler, um ein One-Hot-Encoding auszuführen
Führen Sie die gleichen Schritte aus, um Data Wrangler wie zuvor beschrieben zu starten. Verwenden Sie Data Wrangler, um ein One-Hot-Encoding durchzuführen. In dieser Zelle wird das kopierte und generierte Skript für One-Hot-Encoding angezeigt:


df_clean = pd.get_dummies(df_clean, columns=['Geography', 'Gender'])
Erstellen einer Delta-Tabelle zum Generieren des Power BI-Berichts
table_name = "df_clean"
# Create a PySpark DataFrame from pandas
sparkDF=spark.createDataFrame(df_clean)
sparkDF.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Zusammenfassung der Beobachtungen aus der explorativen Datenanalyse
- Die meisten Kunden stammen aus Frankreich. Spanien hat die niedrigste Abwanderungsrate im Vergleich zu Frankreich und Deutschland.
- Die meisten Kunden haben Kreditkarten.
- Einige Kunden sind beide älter als 60 Jahre und verfügen über Kreditbewertungen unter 400. Sie werden jedoch nicht als Ausreißer betrachtet.
- Sehr wenige Kunden haben mehr als zwei Bankprodukte.
- Inaktive Kunden haben eine höhere Abwanderungsrate.
- Gender und Tenure Years haben wenig Auswirkungen auf die Entscheidung eines Kunden, ein Bankkonto zu schließen.
Schritt 4: Durchführen von Modelltraining und -verfolgung
Nachdem die Daten vorhanden sind, können Sie das Modell jetzt definieren. Wenden Sie Random-Forest- und LightGBM-Modelle in diesem Notebook an.
Verwenden Sie die Scikit-Learn- und LightGBM-Bibliotheken, um die Modelle mit einigen Codezeilen zu implementieren. Verwenden Sie außerdem MLfLow und Fabric Autologging, um die Experimente nachzuverfolgen.
In diesem Codebeispiel wird die Delta-Tabelle aus dem Lakehouse geladen. Sie können andere Delta-Tabellen verwenden, die selbst das Seehaus als Quelle verwenden.
SEED = 12345
df_clean = spark.read.format("delta").load("Tables/df_clean").toPandas()
Generieren eines Experiments zum Nachverfolgen und Protokollieren der Modelle mithilfe von MLflow
In diesem Abschnitt wird gezeigt, wie Sie ein Experiment generieren und die Modell- und Schulungsparameter sowie die Bewertungsmetriken angeben. Darüber hinaus wird gezeigt, wie Sie die Modelle trainieren, protokollieren und die trainierten Modelle zur späteren Verwendung speichern.
import mlflow
# Set up the experiment name
EXPERIMENT_NAME = "sample-bank-churn-experiment" # MLflow experiment name
Bei der automatischen Erfassung werden sowohl die Eingabeparameterwerte als auch die Ausgabemetriken eines machine learning Modells erfasst, da dieses Modell trainiert wird. Diese Informationen werden dann in Ihrem Arbeitsbereich protokolliert, in dem die MLflow-APIs oder das jeweilige Experiment in Ihrem Arbeitsbereich darauf zugreifen und es visualisieren können.
Wenn das Experiment abgeschlossen ist, ähnelt Ihr Experiment diesem Bild:

Alle Experimente mit ihren jeweiligen Namen werden protokolliert, und Sie können deren Parameter und Leistungsmetriken nachverfolgen. Weitere Informationen zum automatischen Logging finden Sie unter Autologging in Microsoft Fabric.
Festlegen von Experiment- und Autoprotokollierungsspezifikationen
mlflow.set_experiment(EXPERIMENT_NAME) # Use a date stamp to append to the experiment
mlflow.autolog(exclusive=False)
Importieren von scikit-learn und LightGBM
# Import the required libraries for model training
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, f1_score, precision_score, confusion_matrix, recall_score, roc_auc_score, classification_report
Vorbereiten von Schulungs- und Testdatensätzen
y = df_clean["Exited"]
X = df_clean.drop("Exited",axis=1)
# Train/test separation
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=SEED)
Anwenden von SMOTE auf die Schulungsdaten
Die ungleichgewichtige Klassifikation hat ein Problem: Es gibt zu wenige Beispiele für die Minderheitsklasse für ein Modell, um die Entscheidungsgrenze effektiv zu erlernen. Um dieses Problem zu bewältigen, ist die am häufigsten verwendete Technik die Synthesische Minderheiten-Oversampling-Technik (SMOTE), die neue Beispiele für die Minderheitenklasse synthetisiert. Greifen Sie mithilfe der imblearn-Bibliothek, die Sie in Schritt 1 installiert haben, auf SMOTE zu.
Wenden Sie SMOTE nur auf das Schulungsdatenset an. Lassen Sie das Testdatenset in seiner ursprünglichen Ungleichgewichtverteilung zurück, sodass Sie eine gültige Annäherung der Modellleistung für die ursprünglichen Daten erhalten. Dieses Experiment stellt die Situation in der Produktion dar.
from collections import Counter
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=SEED)
X_res, y_res = sm.fit_resample(X_train, y_train)
new_train = pd.concat([X_res, y_res], axis=1)
Weitere Informationen finden Sie unter SMOTE und von zufälligen Übersamplings zu SMOTE und ADASYN. Die imbalanced-learn-Website hostet diese Ressourcen.
Trainieren des Modells
Verwenden Sie Random Forest, um das Modell zu trainieren, mit einer maximalen Tiefe von vier und vier Features.
mlflow.sklearn.autolog(registered_model_name='rfc1_sm') # Register the trained model with autologging
rfc1_sm = RandomForestClassifier(max_depth=4, max_features=4, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc1_sm") as run:
rfc1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc1_sm_run_id, run.info.status))
# rfc1.fit(X_train,y_train) # Imbalanced training data
rfc1_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc1_sm.score(X_test, y_test)
y_pred = rfc1_sm.predict(X_test)
cr_rfc1_sm = classification_report(y_test, y_pred)
cm_rfc1_sm = confusion_matrix(y_test, y_pred)
roc_auc_rfc1_sm = roc_auc_score(y_res, rfc1_sm.predict_proba(X_res)[:, 1])
Verwenden Sie random Forest, um das Modell mit einer maximalen Tiefe von acht zu trainieren, und mit sechs Features:
mlflow.sklearn.autolog(registered_model_name='rfc2_sm') # Register the trained model with autologging
rfc2_sm = RandomForestClassifier(max_depth=8, max_features=6, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc2_sm") as run:
rfc2_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc2_sm_run_id, run.info.status))
# rfc2.fit(X_train,y_train) # Imbalanced training data
rfc2_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc2_sm.score(X_test, y_test)
y_pred = rfc2_sm.predict(X_test)
cr_rfc2_sm = classification_report(y_test, y_pred)
cm_rfc2_sm = confusion_matrix(y_test, y_pred)
roc_auc_rfc2_sm = roc_auc_score(y_res, rfc2_sm.predict_proba(X_res)[:, 1])
Trainieren Sie das Modell mit LightGBM:
# lgbm_model
mlflow.lightgbm.autolog(registered_model_name='lgbm_sm') # Register the trained model with autologging
lgbm_sm_model = LGBMClassifier(learning_rate = 0.07,
max_delta_step = 2,
n_estimators = 100,
max_depth = 10,
eval_metric = "logloss",
objective='binary',
random_state=42)
with mlflow.start_run(run_name="lgbm_sm") as run:
lgbm1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
# lgbm_sm_model.fit(X_train,y_train) # Imbalanced training data
lgbm_sm_model.fit(X_res, y_res.ravel()) # Balanced training data
y_pred = lgbm_sm_model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
cr_lgbm_sm = classification_report(y_test, y_pred)
cm_lgbm_sm = confusion_matrix(y_test, y_pred)
roc_auc_lgbm_sm = roc_auc_score(y_res, lgbm_sm_model.predict_proba(X_res)[:, 1])
Anzeigen des Experimentartefakts zum Nachverfolgen der Modellleistung
Die Experimentläufe werden automatisch im Artefakt des Experiments gespeichert. Sie finden das Artefakt im Arbeitsbereich. Der Artefaktname basiert auf dem Experimentnamen. Auf der Experimentseite werden alle trainierten Modelle, deren Ausführung, Leistungsmetriken und Modellparameter protokolliert.
Um Ihre Experimente anzusehen:
- Wählen Sie im linken Bereich Ihren Arbeitsbereich aus.
- Suchen und wählen Sie den Namen des Experiments aus, hier sample-bank-churn-experiment.
Schritt 5: Auswerten und Speichern des endgültigen machine learning Modells
Öffnen Sie das gespeicherte Experiment aus dem Arbeitsbereich, um das beste Modell auszuwählen und zu speichern:
# Define run_uri to fetch the model
# MLflow client: mlflow.model.url, list model
load_model_rfc1_sm = mlflow.sklearn.load_model(f"runs:/{rfc1_sm_run_id}/model")
load_model_rfc2_sm = mlflow.sklearn.load_model(f"runs:/{rfc2_sm_run_id}/model")
load_model_lgbm1_sm = mlflow.lightgbm.load_model(f"runs:/{lgbm1_sm_run_id}/model")
Bewerten der Leistung der gespeicherten Modelle im Testdatensatz
ypred_rfc1_sm = load_model_rfc1_sm.predict(X_test) # Random forest with maximum depth of 4 and 4 features
ypred_rfc2_sm = load_model_rfc2_sm.predict(X_test) # Random forest with maximum depth of 8 and 6 features
ypred_lgbm1_sm = load_model_lgbm1_sm.predict(X_test) # LightGBM
Anzeigen von richtigen/falschen Positiven/Negativen mithilfe einer Konfusionsmatrix.
Um die Genauigkeit der Klassifizierung zu bewerten, erstellen Sie ein Skript, das die Konfusionsmatrix zeichnet. Sie können auch eine Verwirrungsmatrix mit SynapseML-Tools darstellen, wie in der Betrugserkennungsbeispiel gezeigt.
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
print(cm)
plt.figure(figsize=(4,4))
plt.rcParams.update({'font.size': 10})
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45, color="blue")
plt.yticks(tick_marks, classes, color="blue")
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="red" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
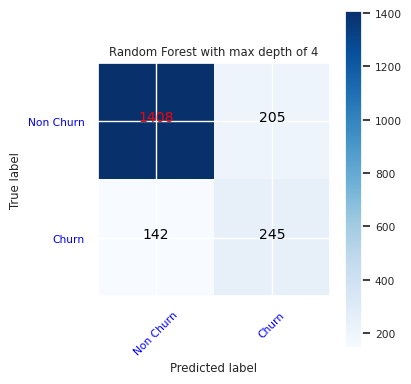
Erstellen Sie eine Konfusionsmatrix für den Random Forest Klassifizierer mit einer maximalen Tiefe von vier und vier Features.
cfm = confusion_matrix(y_test, y_pred=ypred_rfc1_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 4')
tn, fp, fn, tp = cfm.ravel()
Erstellen Sie eine Verwirrungsmatrix für den Random-Forest-Klassifikator mit einer maximalen Tiefe von acht, bei sechs Merkmalen.
cfm = confusion_matrix(y_test, y_pred=ypred_rfc2_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 8')
tn, fp, fn, tp = cfm.ravel()

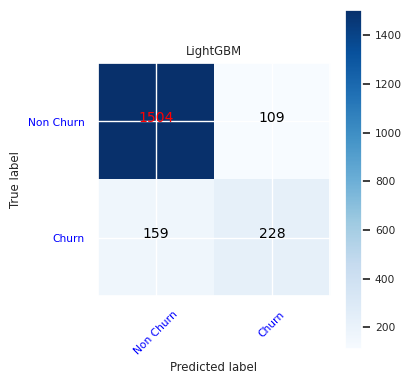
Erstellen Sie eine Verwirrungsmatrix für LightGBM:
cfm = confusion_matrix(y_test, y_pred=ypred_lgbm1_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='LightGBM')
tn, fp, fn, tp = cfm.ravel()
Speichern von Ergebnissen für Power BI
Speichern Sie den Delta-Frame im Lakehouse, um die Modellvorhersageergebnisse in eine Power BI-Visualisierung zu übertragen.
df_pred = X_test.copy()
df_pred['y_test'] = y_test
df_pred['ypred_rfc1_sm'] = ypred_rfc1_sm
df_pred['ypred_rfc2_sm'] =ypred_rfc2_sm
df_pred['ypred_lgbm1_sm'] = ypred_lgbm1_sm
table_name = "df_pred_results"
sparkDF=spark.createDataFrame(df_pred)
sparkDF.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Schritt 6: Zugriff auf Visualisierungen in Power BI
Access Ihrer gespeicherten Tabelle in Power BI:
- Wählen Sie auf der linken Seite OneLake aus.
- Wählen Sie das Seehaus aus, das Sie diesem Notizbuch hinzugefügt haben.
- Im Abschnitt "Dieses Lakehouse öffnen" wählen Sie die Option "Öffnen" aus.
- Wählen Sie im Menüband " Neues semantisches Modell" aus. Wählen Sie
df_pred_resultsund dann Bestätigen aus, um ein neues Power BI-Semantikmodell zu erstellen, welches mit den Vorhersagen verknüpft ist. - Öffnen Sie ein neues Semantikmodell. Sie finden es in OneLake.
- Wählen Sie oben auf der Seite "Semantikmodelle" unter "Datei" die Option "Neuen Bericht erstellen" aus, um die Power BI-Berichterstellungsseite zu öffnen.
Der folgende Screenshot zeigt einige Beispielvisualisierungen. Im Datenbereich werden die Delta-Tabellen und -Spalten angezeigt, die aus einer Tabelle ausgewählt werden sollen. Nach Auswahl der entsprechenden Rubrikachse (x) und Wertachse (y) können Sie die Filter und Funktionen, z. B. Summe oder Mittelwert der Tabellenspalte, auswählen.
Hinweis
In diesem Screenshot beschreibt das veranschaulichte Beispiel die Analyse der gespeicherten Vorhersageergebnisse in Power BI:

Für einen echten Kundenabwanderungsfall benötigt der Benutzer jedoch möglicherweise eine umfassendere Spezifikation der Anforderungen für die zu erstellenden Visualisierungen, die basierend auf Fachkompetenz erstellt werden müssen, und was das Unternehmen sowie das Business-Analytics-Team als Metriken standardisiert haben.
Der Power BI-Bericht zeigt, dass Kunden, die mehr als zwei der Bankprodukte verwenden, eine höhere Abwanderungsrate aufweisen. Allerdings hatten nur wenige Kunden mehr als zwei Produkte. (Sehen Sie sich die Zeichnung im unteren linken Bereich an.) Die Bank sollte weitere Daten sammeln, aber auch andere Features untersuchen, die mit weiteren Produkten korrelieren.
Bankkunden in Deutschland haben im Vergleich zu Kunden in Frankreich und Spanien eine höhere Abwanderungsrate. (Siehe Zeichnung im unteren rechten Bereich). Basierend auf den Berichtsergebnissen könnte eine Untersuchung der Faktoren, die Kunden dazu veranlassten, das Unternehmen zu verlassen, unterstützend sein.
Es gibt mehr Kunden im mittleren Alter (zwischen 25 und 45). Kunden im Alter von 45 bis 60 Jahren neigen dazu, häufiger auszusteigen.
Schließlich würden Kunden mit niedrigeren Kreditbewertungen die Bank für andere Finanzinstitute höchstwahrscheinlich verlassen. Die Bank sollte Möglichkeiten untersuchen, um Kunden mit niedrigeren Kreditergebnissen und Kontoguthaben zu ermutigen, mit der Bank zu bleiben.
# Determine the entire runtime
print(f"Full run cost {int(time.time() - ts)} seconds.")