Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Data Wrangler beschleunigt Ihren Datenvorbereitungsworkflow, indem eine immersive, visuelle Schnittstelle für explorative Datenanalysen bereitgestellt wird. In diesem Artikel erfahren Sie, wie Sie:
- Starten von Data Wrangler aus Ihrem Fabric-Notizbuch
- Erkunden von Daten mit interaktiven Visualisierungen und Zusammenfassungsstatistiken
- Anwenden allgemeiner Datenreinigungsvorgänge mit automatischer Codegenerierung
- Exportieren Sie wiederverwendbare Pandas- oder PySpark-Funktionen in Ihr Notizbuch
Dieser Artikel konzentriert sich auf Pandas DataFrames. Informationen zu Spark DataFrames finden Sie in dieser Ressource.
Voraussetzungen
Erwerben Sie ein Microsoft Fabric-Abonnement. Registrieren Sie sich alternativ für eine kostenlose Microsoft Fabric-Testversion.
Melden Sie sich bei Microsoft Fabric an.
Wechseln Sie zu Fabric, indem Sie den Benutzeroberflächenschalter auf der unteren linken Seite Ihrer Startseite verwenden.

Begrenzungen
- Benutzerdefinierte Codevorgänge unterstützen derzeit nur Pandas DataFrames.
- Die Daten-Wrangler-Anzeige funktioniert am besten auf großen Monitoren. Sie können jedoch verschiedene Teile der Benutzeroberfläche minimieren oder ausblenden, um kleinere Bildschirme aufzunehmen.
Data Wrangler starten
Sie können Data Wrangler direkt aus einem Microsoft Fabric-Notizbuch starten, um alle Pandas oder Spark DataFrame zu erkunden und zu transformieren.
So beginnen Sie mit Beispieldaten:
Der folgende Codeschnipsel zeigt, wie Stichprobendaten in einen Pandas-DataFrame eingelesen werden können:
import pandas as pd
# Read a CSV into a Pandas DataFrame
df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/titanic.csv")
display(df)
Verwenden Sie auf der Registerkarte "Home" des Notizbuchs das Dropdownmenü "Data Wrangler", um die aktiven DataFrames, die zur Bearbeitung verfügbar sind, zu durchsuchen. Wählen Sie denjenigen aus, den Sie in Data Wrangler öffnen möchten.
Tipp
Sie können "Data Wrangler" nicht öffnen, während der Notebook-Kernel ausgelastet ist. Eine Zelle muss ihre Ausführung abschließen, bevor Data Wrangler gestartet werden kann, wie in diesem Screenshot gezeigt.

Daten-Wrangler aus einer Zelle starten
Sie können "Data Wrangler" auch direkt aus einer Notizbuchzelle öffnen, ohne zum Menüband zu navigieren. Dieser direkte Einstiegspunkt macht Data Wrangler genau dort verfügbar, wo Sie mit DataFrames arbeiten.
Wenn Sie eine Zelle ausführen, die einen DataFrame ausgibt, wird eine Daten-Wrangler-Eingabeaufforderung auf Zellenebene angezeigt. Wählen Sie die Eingabeaufforderung aus, um diesen DataFrame in Data Wrangler zu öffnen. Zu den unterstützten Befehlen gehören:
-
df.head()oderdf.head(n) -
df.tail()oderdf.tail(n) -
df.show()oderdf.show(n)
Ausführen einer Zelle, die einen DataFrame ausgibt:
import pandas as pd df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/titanic.csv") df.head()Nach Abschluss der Ausführung der Zelle wird an der Zelle eine Daten-Wrangler-Eingabeaufforderung angezeigt. Wählen Sie Open in Data Wrangler aus, um Data Wrangler mit dem
dfDataFrame zu öffnen.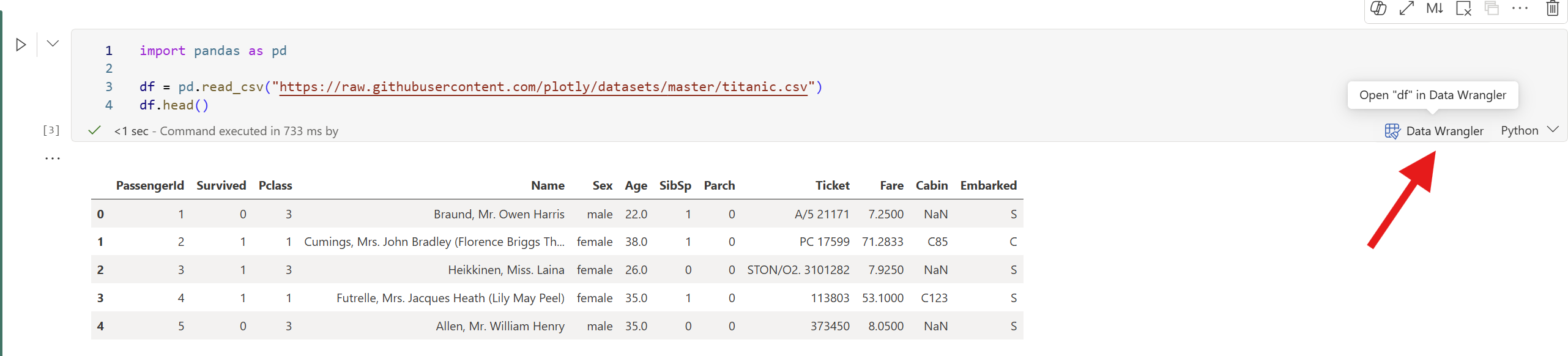

Wenn eine Zelle mehrere DataFrames definiert, stellt die Eingabeaufforderung ein Untermenü bereit, das alle DataFrames in der Zelle auflistet. Sie können eine beliebige Datei in Data Wrangler öffnen – auch solche, die Sie nicht explizit gedruckt haben.
Führen Sie eine Zelle aus, die mehrere DataFrames definiert:
import pandas as pd titanic_df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/titanic.csv") iris_df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/iris-data.csv") titanic_df.head() iris_df.head()Nachdem die Ausführung der Zelle abgeschlossen ist, wählen Sie an der Zelle die Data-Wrangler-Aufforderung aus. Ein Untermenü listet alle in der Zelle definierten DataFrames auf. Wählen Sie das aus, das Sie erkunden möchten.
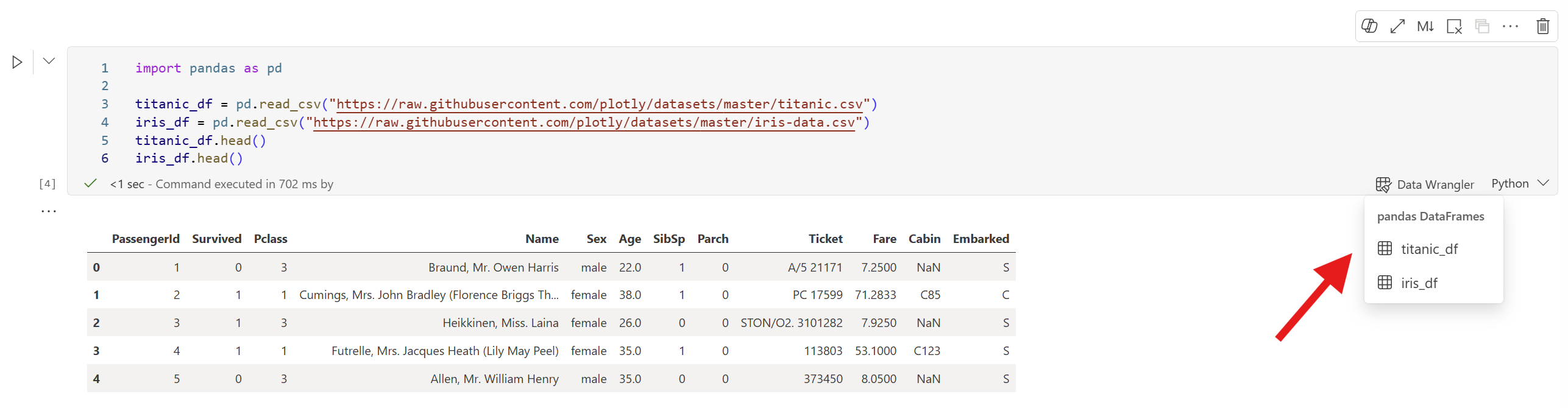

Tipp
Das Untermenü listet DataFrames auf, die in der aktuellen Zelle definiert sind. Um einen DataFrame aus einer vorherigen Zelle zu öffnen, führen Sie eine neue Zelle aus, die darauf verweist, oder verwenden Sie die Dropdownliste "Daten-Wrangler" auf der Registerkarte "Start", um alle aktiven DataFrames zu durchsuchen.
Auswählen von benutzerdefinierten Beispielen
Wählen Sie zum Öffnen eines benutzerdefinierten Beispiels eines beliebigen aktiven DataFrames mit Data Wrangler die Option "Benutzerdefiniertes Beispiel aus der Dropdownliste auswählen" aus, wie in diesem Screenshot gezeigt:

Diese Aktion öffnet ein Dialogfeld mit Optionen, um die Größe des gewünschten Beispiels (Anzahl der Zeilen) und die Samplingmethode (erste Datensätze, letzte Datensätze oder einen Zufallssatz) anzugeben. Die ersten 5.000 Zeilen des DataFrame dienen als Standard-Stichprobengröße, wie im folgenden Screenshot gezeigt:

Anzeigen von Zusammenfassungsstatistiken
Wenn Data Wrangler geladen wird, wird eine beschreibende Übersicht über das ausgewählte DataFrame im Zusammenfassungsbereich angezeigt. Diese Übersicht enthält Informationen zu den DataFrame-Dimensionen, fehlenden Werten und mehr. Wenn Sie eine Spalte im Raster "Daten-Wrangler" auswählen, aktualisiert sich der Zusammenfassungsbereich und zeigt beschreibende Statistiken zu dieser speziellen Spalte an. Schnelle Einblicke in jede Spalte sind auch über die Kopfzeile möglich.
Tipp
Spaltenspezifische Statistiken und visuelle Elemente (sowohl im Zusammenfassungsbereich als auch in den Spaltenüberschriften) hängen vom Spaltendatentyp ab. Ein per Binning verarbeitetes Histogramm einer numerischen Spalte wird beispielsweise nur dann in der Spaltenüberschrift angezeigt, wenn die Spalte in einen numerischen Typen umgewandelt wird, wie im folgenden Screenshot dargestellt:

Durchsuchen von Datenbereinigungsvorgängen
Der Bereich "Vorgänge " enthält eine durchsuchbare Liste von Datenreinigungsvorgängen. Wenn Sie einen Datenreinigungsvorgang im Bereich "Vorgänge " auswählen, müssen Sie eine Zielspalte oder -spalten zusammen mit allen erforderlichen Parametern angeben, um den Vorgang abzuschließen. Bei der Aufforderung zur numerischen Skalierung ist beispielsweise ein neuer Wertebereich erforderlich, wie im folgenden Screenshot gezeigt:

Tipp
Sie können eine kleinere Auswahl von Vorgängen aus dem Menü der einzelnen Spaltenüberschriften anwenden, wie im folgenden Screenshot dargestellt:

Vorschau anzeigen und Operationen anwenden
Die Ergebnisse eines ausgewählten Vorgangs werden im Data Wrangler-Anzeigeraster automatisch in der Vorschau angezeigt, und der entsprechende Code erscheint automatisch in dem Bereich unter dem Raster. Um den vorab angezeigten Code zu übernehmen, wählen Sie "Übernehmen" in einem der beiden Bereiche aus. Um den vorschauierten Code zu löschen und einen neuen Vorgang zu versuchen, wählen Sie "Verwerfen" aus, wie in diesem Screenshot gezeigt:

Nachdem Sie einen Vorgang angewendet haben, werden das Daten-Wrangler-Anzeigeraster und die Zusammenfassungsstatistiken aktualisiert, um die Ergebnisse widerzuspiegeln. Der Code erscheint in der laufenden Liste der übergebenen Operationen im Reinigungsschritte-Bereich, wie in diesem Screenshot gezeigt.

Tipp
Den zuletzt angewendeten Schritt können Sie jederzeit rückgängigmachen. Im Bereich "Reinigungsschritte " wird ein Papierkorbsymbol angezeigt, wenn Sie mit dem Mauszeiger auf den zuletzt angewendeten Schritt zeigen, wie in diesem Screenshot gezeigt:

In der folgenden Tabelle sind die Vorgänge zusammengefasst, die Data Wrangler derzeit unterstützt:
| Vorgang | Beschreibung |
|---|---|
| Sortieren | Eine Spalte in auf- oder absteigender Reihenfolge sortieren |
| Filter | Filtern von Zeilen basierend auf einer oder mehreren Bedingungen |
| One-Hot-Codieren | Erstellen neuer Spalten für jeden eindeutigen Wert in einer vorhandenen Spalte, die das Vorhandensein oder Fehlen dieser Werte pro Zeile angeben |
| Binarizer mit mehreren Bezeichnungen | Daten mithilfe eines Trennzeichens teilen und neue Spalten für jede Kategorie erstellen, wobei 1 markiert wird, wenn eine Zeile diese Kategorie aufweist, und 0, wenn nicht. |
| Spaltentyp ändern | Ändern des Datentyps einer Spalte |
| Spalte löschen | Löschen einer oder mehrerer Spalten |
| Spalte auswählen | Auswählen einer oder mehrerer Spalten, die beibehalten werden sollen, und Löschen der restlichen Spalten |
| Spalte umbenennen | Umbenennen einer Spalte |
| Fehlende Werte löschen | Entfernen von Zeilen mit fehlenden Werten |
| Doppelte Zeilen löschen | Löschen aller Zeilen mit doppelten Werten in einer oder mehreren Spalten |
| Fehlende Werte auffüllen | Ersetzen von Zellen mit fehlenden Werten durch einen neuen Wert |
| Suchen und Ersetzen | Ersetzen von Zellen durch ein genau übereinstimmendes Muster |
| Nach Spalte und Aggregat gruppieren | Gruppieren nach Spaltenwerten und Aggregatergebnissen |
| Leerzeichen entfernen | Entfernen von Leerzeichen am Anfang und Ende des Texts |
| Text aufteilen | Aufteilen einer Spalte in mehrere Spalten basierend auf einem benutzerdefinierten Trennzeichen |
| Text in Kleinbuchstaben konvertieren | Konvertieren des Texts in Kleinbuchstaben |
| Text in Großbuchstaben konvertieren | Text in Großbuchstaben umwandeln |
| Mindest- und Maximalwerte skalieren | Skalieren einer numerischen Spalte zwischen einem minimalen und einem maximalen Wert |
| Schnell ausfüllen | Automatisches Erstellen einer neuen Spalte basierend auf Beispielen, die aus einer vorhandenen Spalte abgeleitet sind |
Anpassen der Anzeige
Sie können die Benutzeroberfläche jederzeit mithilfe der Registerkarte "Ansichten" in der Symbolleiste oberhalb des Anzeigebereichs "Daten-Wrangler" anpassen. Diese Option kann verschiedene Bereiche basierend auf Ihren Einstellungen und der Bildschirmgröße ausblenden oder anzeigen, wie in diesem Screenshot gezeigt:

Speichern und Exportieren von Code
Die Symbolleiste oberhalb des Data Wrangler-Anzeigerasters bietet Optionen zum Speichern des generierten Codes. Sie können den Code in die Zwischenablage kopieren oder in das Notizbuch als Funktion exportieren. Beim Exportieren des Codes wird Data Wrangler geschlossen und die neue Funktion einer Codezelle im Notebook hinzugefügt. Sie können den bereinigten DataFrame auch als CSV-Datei herunterladen.
Tipp
Data Wrangler generiert Code, der nur ausgeführt wird, wenn Sie die neue Zelle manuell ausführen, und ihr ursprünglicher DataFrame wird nicht überschrieben, wie in diesem Screenshot gezeigt:

Anschließend können Sie diesen exportierten Code ausführen, wie im folgenden Screenshot dargestellt:

Nächste Schritte
Nachdem Sie nun wissen, wie Sie Data Wrangler mit Pandas DataFrames verwenden, erkunden Sie diese Ressourcen:
- Verwenden von Data Wrangler mit Spark DataFrames – Anwenden der gleichen Techniken auf Spark DataFrames
- Sehen Sie sich eine Live-Demo an - Sehen Sie sich Data Wrangler in Aktion mit Guy in einem Cube an
- Testen von Data Wrangler in VS Code – Verwenden von Data Wrangler in Visual Studio Code
Haben Sie Feedback? Teilen Sie Ihre Ideen im Fabric Ideas-Forum.