Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Dieses Lernprogramm zeigt ein End-to-End-Beispiel für einen Synapse Data Science-Workflow in Microsoft Fabric. Das Szenario erstellt ein Modell für Onlinebuchempfehlungen.
In diesem Lernprogramm werden die folgenden Schritte behandelt:
- Hochladen der Daten in ein Seehaus
- Durchführen einer explorativen Analyse der Daten
- Trainieren eines Modells und Protokollieren mit MLflow
- Laden des Modells und Erstellen von Vorhersagen
Viele Arten von Empfehlungsalgorithmen sind verfügbar. In diesem Tutorial wird der Matrixfaktorisierungsalgorithmus für alternierende kleinste Quadrate (Alternating Least Squares, ALS) verwendet. ALS ist ein modellbasierter Kollaborativer Filteralgorithmus.

ALS versucht, die Bewertungsmatrix R als Produkt von zwei Matrizen niedrigen Ranges, U und V, zu schätzen. Hier ist R = U * Vt. In der Regel werden diese Annäherungen als -Faktormatrizen bezeichnet.
Der ALS-Algorithmus ist iterativ. Jede Iteration enthält eine der Faktormatrizenkonstanten, während sie die andere mit der Methode der kleinsten Quadrate löst. Anschließend enthält sie die neu gelöste Faktormatrixkonstante, während sie die andere Faktormatrix löst.

Voraussetzungen
Rufen Sie ein Microsoft Fabric-Abonnement ab. Oder registrieren Sie sich für eine kostenlose Microsoft Fabric Testversion.
Melden Sie sich bei Microsoft Fabric an.
Wechseln Sie zu Fabric, indem Sie den Benutzeroberflächenschalter auf der unteren linken Seite Ihrer Startseite verwenden.

- Erstellen Sie bei Bedarf ein Microsoft Fabric Seehaus, wie in Create a lakehouse in Microsoft Fabric beschrieben.
Durchführung in einem Notebook
Wählen Sie eine der folgenden Optionen aus, um in einem Notizbuch zu folgen:
- Öffnen sie das integrierte Notizbuch, und führen Sie es aus.
- Laden Sie Ihr Notizbuch aus GitHub hoch.
Öffnen des integrierten Notizbuchs
Das Notebook Buchempfehlung ist diesem Tutorial als Beispiel beigefügt.
Um das Beispielnotizbuch für dieses Lernprogramm zu öffnen, befolgen Sie die Anweisungen in Vorbereiten Ihres Systems für Data Science-Lernprogramme.
Fügen Sie ein Lakehouse an das Notebook an, bevor Sie mit der Ausführung von Code beginnen.
Importieren des Notizbuchs aus GitHub
Das Notizbuch AIsample - Book Recommendation.ipynb begleitet dieses Lernprogramm.
Zum Öffnen des zugehörigen Notizbuchs für dieses Lernprogramm folgen Sie den Anweisungen in Vorbereiten Ihres Systems für Data Science-Lernprogramme, um das Notizbuch in Ihren Arbeitsbereich zu importieren.
Wenn Sie den Code lieber von dieser Seite kopieren und einfügen möchten, können Sie ein neues Notizbucherstellen.
Fügen Sie ein Lakehouse an das Notebook an, bevor Sie mit der Ausführung von Code beginnen.
Schritt 1: Laden der Daten
Das Buchempfehlungs-Dataset in diesem Szenario besteht aus drei separaten Datasets:
Books.csv: Eine INTERNATIONALE Standardbuchnummer (ISBN) identifiziert jedes Buch, wobei ungültige Datumsangaben bereits entfernt wurden. Das Dataset enthält auch den Titel, den Autor und publisher. Bei einem Buch mit mehreren Autoren listet die Books.csv-Datei nur den ersten Autor auf. URLs verweisen auf Ressourcen der Amazon-Website für die Coverbilder in drei Größen.
ISBN-NUMMER Book-Title Book-Author Year-Of-Publication Herausgeber Image-URL-S Image-URL-M Image-URL-l 0195153448 Klassische Mythologie Mark P. O. Morford 2002 Oxford University Press http://images.amazon.com/images/P/0195153448.01.THUMBZZZ.jpg http://images.amazon.com/images/P/0195153448.01.MZZZZZZZ.jpg http://images.amazon.com/images/P/0195153448.01.LZZZZZZZ.jpg 0002005018 Clara Callan Richard Bruce Wright 2001 HarperFlamingo Kanada http://images.amazon.com/images/P/0002005018.01.THUMBZZZ.jpg http://images.amazon.com/images/P/0002005018.01.MZZZZZZZ.jpg http://images.amazon.com/images/P/0002005018.01.LZZZZZZZ.jpg Ratings.csv: Bewertungen für jedes Buch sind entweder explizit (von Benutzern, auf einer Skala von 1 bis 10) oder implizit (ohne Benutzereingabe beobachtet und durch 0 angegeben).
User-ID ISBN-NUMMER Book-Rating 276725 034545104X 0 276726 0155061224 5 Users.csv: Benutzer-IDs werden anonymisiert und ganzzahligen Zahlen zugeordnet. Demografische Daten – z. B. Standort und Alter – werden bereitgestellt, sofern verfügbar. Wenn diese Daten nicht verfügbar sind, sind diese Werte
null.User-ID Ort Alter 1 nyc new york vereinigte staaten 2 "stockton california usa" 18.0
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Definieren Sie diese Parameter, damit Sie dieses Notizbuch mit verschiedenen Datasets verwenden können:
IS_CUSTOM_DATA = False # If True, the dataset has to be uploaded manually
USER_ID_COL = "User-ID" # Must not be '_user_id' for this notebook to run successfully
ITEM_ID_COL = "ISBN" # Must not be '_item_id' for this notebook to run successfully
ITEM_INFO_COL = (
"Book-Title" # Must not be '_item_info' for this notebook to run successfully
)
RATING_COL = (
"Book-Rating" # Must not be '_rating' for this notebook to run successfully
)
IS_SAMPLE = True # If True, use only <SAMPLE_ROWS> rows of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_FOLDER = "Files/book-recommendation/" # Folder that contains the datasets
ITEMS_FILE = "Books.csv" # File that contains the item information
USERS_FILE = "Users.csv" # File that contains the user information
RATINGS_FILE = "Ratings.csv" # File that contains the rating information
EXPERIMENT_NAME = "aisample-recommendation" # MLflow experiment name
Herunterladen und Speichern der Daten in einem Seehaus
Dieser Code lädt das Dataset herunter und speichert es dann im Seehaus.
Wichtig
Fügen Sie dem Notebook ein Lakehouse hinzu, bevor Sie es ausführen. Andernfalls wird eine Fehlermeldung angezeigt.
if not IS_CUSTOM_DATA:
# Download data files into a lakehouse if they don't exist
import os, requests
remote_url = "https://synapseaisolutionsa.z13.web.core.windows.net/data/Book-Recommendation-Dataset"
file_list = ["Books.csv", "Ratings.csv", "Users.csv"]
download_path = f"/lakehouse/default/{DATA_FOLDER}/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Einrichten der MLflow-Experimentverfolgung
Verwenden Sie diesen Code, um die MLflow-Experimentverfolgung einzurichten. In diesem Beispiel wird die automatische Protokollierung deaktiviert. Weitere Informationen finden Sie im Artikel Autologging in Microsoft Fabric.
# Set up MLflow for experiment tracking
import mlflow
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(disable=True) # Disable MLflow autologging
Daten aus dem Lakehouse lesen
Nachdem Sie die richtigen Daten im Lakehouse platziert haben, lesen Sie die drei Datasets in separate Spark DataFrames im Notebook. Die Dateipfade in diesem Code verwenden die zuvor definierten Parameter.
df_items = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{ITEMS_FILE}")
.cache()
)
df_ratings = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{RATINGS_FILE}")
.cache()
)
df_users = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{USERS_FILE}")
.cache()
)
Schritt 2: Durchführen einer explorativen Datenanalyse
Unformatierte Daten anzeigen
Erkunden Sie die DataFrames mithilfe des display Befehls. Mithilfe dieses Befehls können Sie allgemeine DataFrame-Statistiken anzeigen und verstehen, wie verschiedene Datasetspalten miteinander zusammenhängen. Bevor Sie die Datasets erkunden, verwenden Sie diesen Code, um die erforderlichen Bibliotheken zu importieren:
import pyspark.sql.functions as F
from pyspark.ml.feature import StringIndexer
import matplotlib.pyplot as plt
import seaborn as sns
color = sns.color_palette() # Adjusting plotting style
import pandas as pd # DataFrames
Verwenden Sie diesen Code, um den DataFrame anzuzeigen, der die Buchdaten enthält:
display(df_items, summary=True)
Fügen Sie eine _item_id Spalte für die spätere Verwendung hinzu. Der wert _item_id muss eine ganze Zahl für Empfehlungsmodelle sein. Dieser Code verwendet StringIndexer, um ITEM_ID_COL in Indizes zu transformieren:
df_items = (
StringIndexer(inputCol=ITEM_ID_COL, outputCol="_item_id")
.setHandleInvalid("skip")
.fit(df_items)
.transform(df_items)
.withColumn("_item_id", F.col("_item_id").cast("int"))
)
Zeigen Sie den DataFrame an, und überprüfen Sie, ob der _item_id Wert monoton und nacheinander wie erwartet erhöht wird:
display(df_items.sort(F.col("_item_id").desc()))
Verwenden Sie diesen Code, um die top 10 Autoren nach Anzahl der geschriebenen Bücher in absteigender Reihenfolge zu zeichnen. Agatha Christie ist der führende Autor mit mehr als 600 Büchern, gefolgt von William Shakespeare.
df_books = df_items.toPandas() # Create a pandas DataFrame from the Spark DataFrame for visualization
plt.figure(figsize=(8,5))
sns.countplot(y="Book-Author",palette = 'Paired', data=df_books,order=df_books['Book-Author'].value_counts().index[0:10])
plt.title("Top 10 authors with maximum number of books")

Zeigen Sie als Nächstes den DataFrame an, der die Benutzerdaten enthält:
display(df_users, summary=True)
Wenn eine Zeile einen fehlenden User-ID Wert aufweist, legen Sie diese Zeile ab. Fehlende Werte in einem benutzerdefinierten Dataset verursachen keine Probleme.
df_users = df_users.dropna(subset=(USER_ID_COL))
display(df_users, summary=True)
Fügen Sie eine _user_id Spalte für die spätere Verwendung hinzu. Bei Empfehlungsmodellen muss der _user_id Wert eine ganze Zahl sein. Im folgenden Codebeispiel werden StringIndexer verwendet, um USER_ID_COL in Indizes zu transformieren.
Das Dataset „Book“ verfügt bereits über eine ganzzahlige User-ID-Spalte. Das Hinzufügen einer _user_id Spalte zur Kompatibilität mit verschiedenen Datasets macht dieses Beispiel jedoch robuster. Verwenden Sie diesen Code, um die spalte _user_id hinzuzufügen:
df_users = (
StringIndexer(inputCol=USER_ID_COL, outputCol="_user_id")
.setHandleInvalid("skip")
.fit(df_users)
.transform(df_users)
.withColumn("_user_id", F.col("_user_id").cast("int"))
)
display(df_users.sort(F.col("_user_id").desc()))
Verwenden Sie diesen Code, um die Bewertungsdaten anzuzeigen:
display(df_ratings, summary=True)
Rufen Sie die unterschiedlichen Bewertungen ab, und speichern Sie sie für die spätere Verwendung in einer Liste mit dem Namen ratings:
ratings = [i[0] for i in df_ratings.select(RATING_COL).distinct().collect()]
print(ratings)
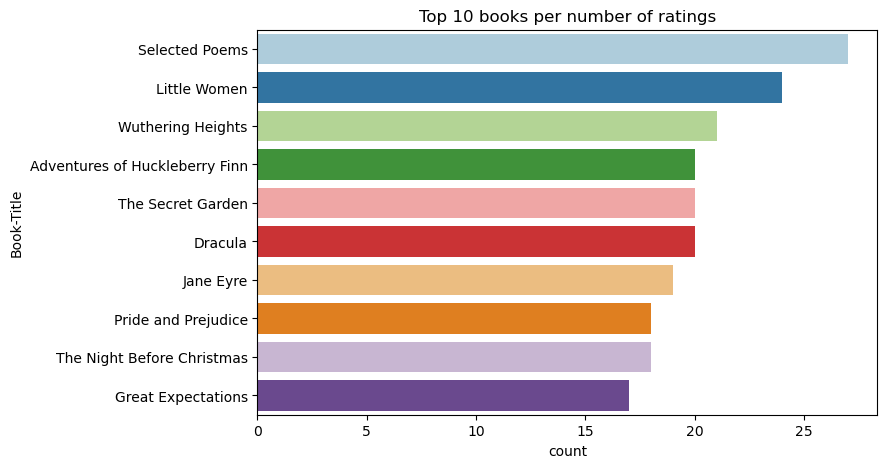
Verwenden Sie diesen Code, um die top 10 Bücher mit den höchsten Bewertungen anzuzeigen:
plt.figure(figsize=(8,5))
sns.countplot(y="Book-Title",palette = 'Paired',data= df_books, order=df_books['Book-Title'].value_counts().index[0:10])
plt.title("Top 10 books per number of ratings")
Nach den Bewertungen ist Selected Poems das beliebteste Buch. Abenteuer von Huckleberry Finn, The Secret Garden, und Dracula haben die gleiche Bewertung.
Zusammenführen von Daten
Führen Sie die drei DataFrames in einem DataFrame zusammen, um eine umfassendere Analyse zu erstellen:
df_all = df_ratings.join(df_users, USER_ID_COL, "inner").join(
df_items, ITEM_ID_COL, "inner"
)
df_all_columns = [
c for c in df_all.columns if c not in ["_user_id", "_item_id", RATING_COL]
]
# Reorder the columns to ensure that _user_id, _item_id, and Book-Rating are the first three columns
df_all = (
df_all.select(["_user_id", "_item_id", RATING_COL] + df_all_columns)
.withColumn("id", F.monotonically_increasing_id())
.cache()
)
display(df_all)
Verwenden Sie diesen Code, um die Anzahl der unterschiedlichen Benutzer, Bücher und Interaktionen anzuzeigen:
print(f"Total Users: {df_users.select('_user_id').distinct().count()}")
print(f"Total Items: {df_items.select('_item_id').distinct().count()}")
print(f"Total User-Item Interactions: {df_all.count()}")
Berechnen und Zeichnen der am häufigsten verwendeten Elemente
Verwenden Sie diesen Code, um die 10 beliebtesten Bücher zu berechnen und anzuzeigen:
# Compute top popular products
df_top_items = (
df_all.groupby(["_item_id"])
.count()
.join(df_items, "_item_id", "inner")
.sort(["count"], ascending=[0])
)
# Find top <topn> popular items
topn = 10
pd_top_items = df_top_items.limit(topn).toPandas()
pd_top_items.head(10)
Tipp
Verwenden Sie den Wert <topn> für die Empfehlungsabschnitte Beliebt oder Am häufigsten gekauft.
# Plot top <topn> items
f, ax = plt.subplots(figsize=(10, 5))
plt.xticks(rotation="vertical")
sns.barplot(y=ITEM_INFO_COL, x="count", data=pd_top_items)
ax.tick_params(axis='x', rotation=45)
plt.xlabel("Number of Ratings for the Item")
plt.show()

Vorbereiten von Schulungs- und Testdatensätzen
Die ALS-Matrix erfordert vor dem Training eine Datenvorbereitung. Verwenden Sie dieses Codebeispiel, um die Daten vorzubereiten. Der Code führt die folgenden Aktionen aus:
- Wandeln Sie die Bewertungsspalte in den richtigen Typ um.
- Die Trainingsdaten mit Benutzerbewertungen abtasten.
- Teilen Sie die Daten in Schulungs- und Testdatensätze auf.
if IS_SAMPLE:
# Must sort by '_user_id' before performing limit to ensure that ALS works normally
# If training and test datasets have no common _user_id, ALS will fail
df_all = df_all.sort("_user_id").limit(SAMPLE_ROWS)
# Cast the column into the correct type
df_all = df_all.withColumn(RATING_COL, F.col(RATING_COL).cast("float"))
# Using a fraction between 0 and 1 returns the approximate size of the dataset; for example, 0.8 means 80% of the dataset
# Rating = 0 means the user didn't rate the item, so it can't be used for training
# We use the 80% of the dataset with rating > 0 as the training dataset
fractions_train = {0: 0}
fractions_test = {0: 0}
for i in ratings:
if i == 0:
continue
fractions_train[i] = 0.8
fractions_test[i] = 1
# Training dataset
train = df_all.sampleBy(RATING_COL, fractions=fractions_train)
# Join with leftanti will select all rows from df_all with rating > 0 and not in the training dataset; for example, the remaining 20% of the dataset
# test dataset
test = df_all.join(train, on="id", how="leftanti").sampleBy(
RATING_COL, fractions=fractions_test
)
Sparsamkeit bezieht sich auf sparsame Feedbackdaten, die keine Ähnlichkeiten im Interesse der Benutzer identifizieren können. Um sowohl die Daten als auch das aktuelle Problem besser verstehen zu können, verwenden Sie diesen Code, um die Datenmenge sparsam zu berechnen:
# Compute the sparsity of the dataset
def get_mat_sparsity(ratings):
# Count the total number of ratings in the dataset - used as numerator
count_nonzero = ratings.select(RATING_COL).count()
print(f"Number of rows: {count_nonzero}")
# Count the total number of distinct user_id and distinct product_id - used as denominator
total_elements = (
ratings.select("_user_id").distinct().count()
* ratings.select("_item_id").distinct().count()
)
# Calculate the sparsity by dividing the numerator by the denominator
sparsity = (1.0 - (count_nonzero * 1.0) / total_elements) * 100
print("The ratings DataFrame is ", "%.4f" % sparsity + "% sparse.")
get_mat_sparsity(df_all)
# Check the ID range
# ALS supports only values in the integer range
print(f"max user_id: {df_all.agg({'_user_id': 'max'}).collect()[0][0]}")
print(f"max user_id: {df_all.agg({'_item_id': 'max'}).collect()[0][0]}")
Schritt 3: Entwickeln und Trainieren des Modells
Schulen Sie ein ALS-Modell, um Benutzern personalisierte Empfehlungen zu geben.
Definieren des Modells
Spark ML bietet eine bequeme API zum Erstellen des ALS-Modells. Das Modell behandelt jedoch nicht zuverlässig Probleme wie Datensparendheit und Kaltstart (Empfehlungen, wenn die Benutzer oder Elemente neu sind). Um die Modellleistung zu verbessern, kombinieren Sie die Kreuzüberprüfung und die automatische Hyperparameteroptimierung.
Verwenden Sie diesen Code, um die bibliotheken zu importieren, die für Modellschulungen und -auswertungen erforderlich sind:
# Import Spark required libraries
from pyspark.ml.evaluation import RegressionEvaluator
from pyspark.ml.recommendation import ALS
from pyspark.ml.tuning import ParamGridBuilder, CrossValidator, TrainValidationSplit
# Specify the training parameters
num_epochs = 1 # Number of epochs; here we use 1 to reduce the training time
rank_size_list = [64] # The values of rank in ALS for tuning
reg_param_list = [0.01, 0.1] # The values of regParam in ALS for tuning
model_tuning_method = "TrainValidationSplit" # TrainValidationSplit or CrossValidator
# Build the recommendation model by using ALS on the training data
# We set the cold start strategy to 'drop' to ensure that we don't get NaN evaluation metrics
als = ALS(
maxIter=num_epochs,
userCol="_user_id",
itemCol="_item_id",
ratingCol=RATING_COL,
coldStartStrategy="drop",
implicitPrefs=False,
nonnegative=True,
)
Optimieren von Modell-Hyperparametern
Im nächsten Codebeispiel wird ein Parameterraster erstellt, um die Hyperparameter zu durchsuchen. Der Code erstellt außerdem einen Regressions-Evaluator, der den RMSE-Fehler (Root-Mean-Square Error) als Bewertungsmetrik verwendet.
# Construct a grid search to select the best values for the training parameters
param_grid = (
ParamGridBuilder()
.addGrid(als.rank, rank_size_list)
.addGrid(als.regParam, reg_param_list)
.build()
)
print("Number of models to be tested: ", len(param_grid))
# Define the evaluator and set the loss function to the RMSE
evaluator = RegressionEvaluator(
metricName="rmse", labelCol=RATING_COL, predictionCol="prediction"
)
Im nächsten Codebeispiel werden verschiedene Modelloptimierungsmethoden basierend auf den vorkonfigurierten Parametern initiiert. Weitere Informationen zur Modelloptimierung finden Sie unter ML Tuning: Modellauswahl und Hyperparameteroptimierung auf der Apache Spark-Website.
# Build cross-validation by using CrossValidator and TrainValidationSplit
if model_tuning_method == "CrossValidator":
tuner = CrossValidator(
estimator=als,
estimatorParamMaps=param_grid,
evaluator=evaluator,
numFolds=5,
collectSubModels=True,
)
elif model_tuning_method == "TrainValidationSplit":
tuner = TrainValidationSplit(
estimator=als,
estimatorParamMaps=param_grid,
evaluator=evaluator,
# 80% of the training data will be used for training; 20% for validation
trainRatio=0.8,
collectSubModels=True,
)
else:
raise ValueError(f"Unknown model_tuning_method: {model_tuning_method}")
Auswerten des Modells
Wertet Modelle anhand der Testdaten aus. Ein gut geschultes Modell verfügt über hohe Metriken für das Dataset.
Ein überlastetes Modell benötigt möglicherweise mehr Schulungsdaten oder eine Reduzierung einiger redundanter Features. Möglicherweise müssen Sie die Modellarchitektur ändern oder die Parameter optimieren.
Anmerkung
Ein negativer R-Quadrat-Metrikwert gibt an, dass das trainierte Modell schlechter ist als eine horizontale gerade Linie. Diese Feststellung deutet darauf hin, dass das trainierte Modell die Daten nicht erklärt.
Verwenden Sie diesen Code, um eine Auswertungsfunktion zu definieren:
def evaluate(model, data, verbose=0):
"""
Evaluate the model by computing rmse, mae, r2, and variance over the data.
"""
predictions = model.transform(data).withColumn(
"prediction", F.col("prediction").cast("double")
)
if verbose > 1:
# Show 10 predictions
predictions.select("_user_id", "_item_id", RATING_COL, "prediction").limit(
10
).show()
# Initialize the regression evaluator
evaluator = RegressionEvaluator(predictionCol="prediction", labelCol=RATING_COL)
_evaluator = lambda metric: evaluator.setMetricName(metric).evaluate(predictions)
rmse = _evaluator("rmse")
mae = _evaluator("mae")
r2 = _evaluator("r2")
var = _evaluator("var")
if verbose > 0:
print(f"RMSE score = {rmse}")
print(f"MAE score = {mae}")
print(f"R2 score = {r2}")
print(f"Explained variance = {var}")
return predictions, (rmse, mae, r2, var)
Verfolgen des Experiments mithilfe von MLflow
Verwenden Sie MLflow, um alle Experimente nachzuverfolgen und Parameter, Metriken und Modelle zu protokollieren. Verwenden Sie diesen Code, um mit der Modellschulung und -auswertung zu beginnen:
from mlflow.models.signature import infer_signature
with mlflow.start_run(run_name="als"):
# Train models
models = tuner.fit(train)
best_metrics = {"RMSE": 10e6, "MAE": 10e6, "R2": 0, "Explained variance": 0}
best_index = 0
# Evaluate models
# Log models, metrics, and parameters
for idx, model in enumerate(models.subModels):
with mlflow.start_run(nested=True, run_name=f"als_{idx}") as run:
print("\nEvaluating on test data:")
print(f"subModel No. {idx + 1}")
predictions, (rmse, mae, r2, var) = evaluate(model, test, verbose=1)
signature = infer_signature(
train.select(["_user_id", "_item_id"]),
predictions.select(["_user_id", "_item_id", "prediction"]),
)
print("log model:")
mlflow.spark.log_model(
model,
f"{EXPERIMENT_NAME}-alsmodel",
signature=signature,
registered_model_name=f"{EXPERIMENT_NAME}-alsmodel",
dfs_tmpdir="Files/spark",
)
print("log metrics:")
current_metric = {
"RMSE": rmse,
"MAE": mae,
"R2": r2,
"Explained variance": var,
}
mlflow.log_metrics(current_metric)
if rmse < best_metrics["RMSE"]:
best_metrics = current_metric
best_index = idx
print("log parameters:")
mlflow.log_params(
{
"subModel_idx": idx,
"num_epochs": num_epochs,
"rank_size_list": rank_size_list,
"reg_param_list": reg_param_list,
"model_tuning_method": model_tuning_method,
"DATA_FOLDER": DATA_FOLDER,
}
)
# Log the best model and related metrics and parameters to the parent run
mlflow.spark.log_model(
models.subModels[best_index],
f"{EXPERIMENT_NAME}-alsmodel",
signature=signature,
registered_model_name=f"{EXPERIMENT_NAME}-alsmodel",
dfs_tmpdir="Files/spark",
)
mlflow.log_metrics(best_metrics)
mlflow.log_params(
{
"subModel_idx": idx,
"num_epochs": num_epochs,
"rank_size_list": rank_size_list,
"reg_param_list": reg_param_list,
"model_tuning_method": model_tuning_method,
"DATA_FOLDER": DATA_FOLDER,
}
)
Wählen Sie das Experiment mit dem Namen aisample-recommendation aus Ihrem Arbeitsbereich aus, um die protokollierten Informationen für den Schulungslauf anzuzeigen. Wenn Sie den Namen des Experiments ändern, wählen Sie das Experiment mit dem neuen Namen aus. Die protokollierten Informationen ähneln dieser Abbildung:

Schritt 4: Laden des endgültigen Modells für die Bewertung und Erstellen von Vorhersagen
Nachdem Sie das Training des Modells abgeschlossen und das beste Modell ausgewählt haben, laden Sie das Modell zum Bewerten (manchmal auch als Inferencing bezeichnet). Dieser Code lädt das Modell und verwendet Vorhersagen, um die 10 besten Bücher für jeden Benutzer zu empfehlen:
# Load the best model
# MLflow uses PipelineModel to wrap the original model, so we extract the original ALSModel from the stages
model_uri = f"models:/{EXPERIMENT_NAME}-alsmodel/1"
loaded_model = mlflow.spark.load_model(model_uri, dfs_tmpdir="Files/spark").stages[-1]
# Generate top 10 book recommendations for each user
userRecs = loaded_model.recommendForAllUsers(10)
# Represent the recommendations in an interpretable format
userRecs = (
userRecs.withColumn("rec_exp", F.explode("recommendations"))
.select("_user_id", F.col("rec_exp._item_id"), F.col("rec_exp.rating"))
.join(df_items.select(["_item_id", "Book-Title"]), on="_item_id")
)
userRecs.limit(10).show()
Die Ausgabe ähnelt dieser Tabelle:
| _item_id | _user_id | rating | Book-Title |
|---|---|---|---|
| 44865 | 7 | 7.9996786 | Lasher: Leben von ... |
| 786 | 7 | 6.2255826 | Der Piano Man's D... |
| 45330 | 7 | 4.980466 | Geisteszustand |
| 38960 | 7 | 4.980466 | Alles, was er jemals wollte |
| 125415 | 7 | 4.505084 | Harry Potter und ... |
| 44939 | 7 | 4.3579073 | Taltos: Leben von ... |
| 175247 | 7 | 4.3579073 | Der Bonesetter ... |
| 170183 | 7 | 4.228735 | Das Einfache leben... |
| 88503 | 7 | 4.221206 | Insel der Blu... |
| 32894 | 7 | 3.9031885 | Wintersonnenwende |
Speichern Sie die Vorhersagen im Seehaus
Verwenden Sie diesen Code, um die Empfehlungen erneut in das Lakehouse zu schreiben:
# Code to save userRecs into the lakehouse
userRecs.write.format("delta").mode("overwrite").save(
f"{DATA_FOLDER}/predictions/userRecs"
)