Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Lernprogramm lernen Sie, mehrere Machine Learning-Modelle zu trainieren, um das Beste auszuwählen, um vorherzusagen, welche Kunden wahrscheinlich die Bank verlassen werden.
In diesem Tutorial gehen Sie wie folgt vor:
- Trainieren von Random Forest- und LightGBM-Modellen.
- Verwenden Sie die native Integration von Microsoft Fabric in das MLflow-Framework, um die trainierten Machine Learning-Modelle, die verwendeten Hyperaparameter und die Auswertungsmetriken zu protokollieren.
- Registrieren Sie das trainierte Machine Learning-Modell.
- Bewerten Sie die Leistungen der trainierten Machine Learning-Modelle für den Validierungsdatensatz.
MLflow ist eine Open Source-Plattform zum Verwalten des Machine Learning-Lebenszyklus mit Features wie Tracking, Models und Model Registry. MLflow ist nativ in die Fabric Data Science-Erfahrung integriert.
Voraussetzungen
Erwerben Sie ein Microsoft Fabric-Abonnement. Registrieren Sie sich alternativ für eine kostenlose Microsoft Fabric-Testversion.
Melden Sie sich bei Microsoft Fabric an.
Wechseln Sie zu Fabric, indem Sie den Benutzeroberflächenschalter auf der unteren linken Seite Ihrer Startseite verwenden.

Dies ist Teil 3 von 5 in der Reihe von Tutorials. Um dieses Tutorial erfolgreich abzuschließen, führen Sie zunächst Folgendes durch:
- Teil 1: Aufnehmen von Daten in ein Microsoft Fabric Lakehouse mit Apache Spark.
- Teil 2: Erkunden und Visualisieren von Daten mithilfe von Microsoft Fabric-Notebooks, um mehr über die Daten zu erfahren.
Notebook für das Tutorial
3-train-evaluate.ipynb ist das Notebook, das dieses Lernprogramm begleitet.
Zum Öffnen des zugehörigen Notizbuchs für dieses Lernprogramm folgen Sie den Anweisungen in Vorbereiten Ihres Systems für Data Science-Lernprogramme, um das Notizbuch in Ihren Arbeitsbereich zu importieren.
Wenn Sie den Code lieber von dieser Seite kopieren und einfügen möchten, können Sie auch ein neues Notebook erstellen.
Fügen Sie unbedingt ein Lakehouse an das Notebook an, bevor Sie mit der Ausführung von Code beginnen.
Wichtig
Fügen Sie dasselbe Lakehouse an, das Sie in Teil 1 und Teil 2 verwendet haben.
Installieren von benutzerdefinierten Bibliotheken
Für dieses Notebook verwenden Sie imblearn, um imbalanced-learn zu installieren (importiert als %pip install). Unausgewogenes Lernen ist eine Bibliothek für synthetische Minderheitenübersamplingtechnik (SMOTE), die beim Umgang mit ungleichgewichtigen Datensätzen verwendet wird. Der PySpark-Kernel wird nach der Ausführung von %pip install neu gestartet. Daher muss die Bibliothek installiert werden, bevor andere Zellen ausgeführt werden.
Sie greifen mithilfe der imblearn Bibliothek auf SMOTE zu. Installieren Sie sie jetzt mithilfe der Inlineinstallationsfunktionen (z. B %pip, %conda).
# Install imblearn for SMOTE using pip
%pip install imblearn
%pip install scikit-learn==1.6.1
%pip install "mlflow==2.12.2"
Wichtig
Führe diese Installation jedes Mal aus, wenn du das Notizbuch neu startest.
Wenn Sie eine Bibliothek in einem Notebook installieren, ist sie nur für die Dauer der Notebooksitzung und nicht im Arbeitsbereich verfügbar. Wenn Sie das Notizbuch neu starten, müssen Sie die Bibliothek erneut installieren.
Wenn Sie häufig eine Bibliothek verwenden und sie für alle Notebooks in Ihrem Arbeitsbereich verfügbar machen möchten, können Sie hierfür eine Fabric-Umgebung verwenden. Sie können eine Umgebung erstellen, die Bibliothek darin installieren, und dann kann Ihr Arbeitsbereichsadministrator die Umgebung als Standardumgebung an den Arbeitsbereich anfügen. Weitere Informationen zum Festlegen einer Umgebung als Arbeitsbereichstandard finden Sie unter Durch Administrator*innen festgelegte Standardbibliotheken für den Arbeitsbereich.
Informationen zum Migrieren vorhandener Arbeitsbereichbibliotheken und Spark-Eigenschaften zu einer Umgebung finden Sie unter Migrieren der Arbeitsbereichsbibliotheken und Spark-Eigenschaften zu einer Standardumgebung.
Laden der Daten
Bevor Sie ein Machine Learning-Modell trainieren, müssen Sie die Delta-Tabelle aus dem Lakehouse laden, um die bereinigten Daten zu lesen, die Sie im vorherigen Notebook erstellt haben.
import pandas as pd
SEED = 12345
df_clean = spark.read.format("delta").load("Tables/df_clean").toPandas()
Generieren eines Experiments zum Nachverfolgen und Protokollieren der Modelle mithilfe von MLflow
In diesem Abschnitt wird veranschaulicht, wie Sie ein Experiment generieren, das Machine Learning-Modell- und die Schulungsparameter angeben sowie Bewertungsmetriken festlegen, die Machine Learning-Modelle trainieren, protokollieren und die trainierten Modelle zur späteren Verwendung speichern.
import mlflow
# Setup experiment name
EXPERIMENT_NAME = "bank-churn-experiment-SBM" # MLflow experiment name
Mit der Erweiterung der automatischen MLflow-Protokollierung erfasst die automatische Protokollierung automatisch die Werte von Eingabeparametern und Ausgabemetriken eines Machine Learning-Modells, während es trainiert wird. Diese Informationen werden dann in Ihrem Arbeitsbereich protokolliert, wo sie mithilfe der MLflow-APIs oder der entsprechenden Experimente in Ihrem Arbeitsbereich angezeigt und visualisiert werden können.
Alle Experimente mit ihren jeweiligen Namen werden protokolliert, und Sie können deren Parameter und Leistungsmetriken nachverfolgen. Weitere Informationen zur automatischen Protokollierung finden Sie unter Automatische Protokollierung in Microsoft Fabric.
Festlegen von Experiment- und Autoprotokollierungsspezifikationen
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(exclusive=False)
Importieren von scikit-learn und LightGBM
Mit Ihren Daten können Sie jetzt die Machine Learning-Modelle definieren. In diesem Notebook wenden Sie Random Forest- und LightGBM-Modelle an. Verwenden Sie scikit-learn und lightgbm, um die Modelle in wenigen Codezeilen zu implementieren.
# Import the required libraries for model training
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, f1_score, precision_score, confusion_matrix, recall_score, roc_auc_score, classification_report
Vorbereiten von Schulungs-, Validierungs- und Testdatensätzen
Verwenden Sie die train_test_split-Funktion aus scikit-learn, um die Daten in Schulungs-, Validierungs- und Testsätze aufzuteilen.
y = df_clean["Exited"]
X = df_clean.drop("Exited",axis=1)
# Split the dataset to 60%, 20%, 20% for training, validation, and test datasets
# Train-Test Separation
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=SEED)
# Train-Validation Separation
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.25, random_state=SEED)
Speichern von Testdaten in einer Delta-Tabelle
Speichern Sie die Testdaten zur Verwendung im nächsten Notebook in der Delta-Tabelle.
table_name = "df_test"
# Create PySpark DataFrame from Pandas
df_test=spark.createDataFrame(X_test)
df_test.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark test DataFrame saved to delta table: {table_name}")
Anwenden von SMOTE auf die Trainingsdaten zum Synthetisieren neuer Stichproben für die Minderheitenklasse
Die Datensuche in Teil 2 zeigte, dass von den 10.000 Datenpunkten, die 10.000 Kunden entsprechen, nur 2.037 Kunden (rund 20%) die Bank verlassen haben. Dies weist darauf hin, dass der Datensatz sehr unausgeglichen ist. Das Problem der unausgewogenen Klassifizierung besteht darin, dass es zu wenige Beispiele für die Minderheitenklasse für ein Modell gibt, um die Entscheidungsgrenze effektiv zu erlernen. SMOTE ist der am häufigsten verwendete Ansatz, um neue Stichproben für die Minderheitenklasse zu synthetisieren. Erfahren Sie mehr über SMOTE hier und hier.
Tipp
Beachten Sie, dass SMOTE nur auf den Trainingsdatensatz angewendet werden sollte. Sie müssen den Testdatensatz in seiner ursprünglichen ungleichgewichtigen Verteilung belassen, um eine gültige Annäherung darüber zu erhalten, wie das Modell für die ursprünglichen Daten ausgeführt wird, was die Situation in der Produktion darstellt.
from collections import Counter
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=SEED)
X_res, y_res = sm.fit_resample(X_train, y_train)
new_train = pd.concat([X_res, y_res], axis=1)
Tipp
Du kannst die MLflow-Warnmeldung sicher ignorieren, die angezeigt wird, wenn du diese Zelle ausführst.
Wenn eine ModuleNotFoundError-Meldung angezeigt wird, hast du die erste Zelle in diesem Notebook nicht ausgeführt, wodurch die imblearn-Bibliothek installiert wird. Du musst diese Bibliothek jedes Mal installieren, wenn du das Notebook neu startest. Kehre zurück, und führe alle Zellen in diesem Notebook erneut aus, wobei du mit der ersten Zelle beginnst.
Modelltraining
- Trainieren Sie das Modell mit Random Forest mit einer maximalen Tiefe von 4 mit 4 Merkmalen
mlflow.sklearn.autolog(registered_model_name='rfc1_sm') # Register the trained model with autologging
rfc1_sm = RandomForestClassifier(max_depth=4, max_features=4, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc1_sm") as run:
rfc1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc1_sm_run_id, run.info.status))
# rfc1.fit(X_train,y_train) # Imbalanaced training data
rfc1_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc1_sm.score(X_val, y_val)
y_pred = rfc1_sm.predict(X_val)
cr_rfc1_sm = classification_report(y_val, y_pred)
cm_rfc1_sm = confusion_matrix(y_val, y_pred)
roc_auc_rfc1_sm = roc_auc_score(y_res, rfc1_sm.predict_proba(X_res)[:, 1])
- Trainieren Sie das Modell mit Random Forest mit einer maximalen Tiefe von 8 mit 6 Merkmalen
mlflow.sklearn.autolog(registered_model_name='rfc2_sm') # Register the trained model with autologging
rfc2_sm = RandomForestClassifier(max_depth=8, max_features=6, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc2_sm") as run:
rfc2_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc2_sm_run_id, run.info.status))
# rfc2.fit(X_train,y_train) # Imbalanced training data
rfc2_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc2_sm.score(X_val, y_val)
y_pred = rfc2_sm.predict(X_val)
cr_rfc2_sm = classification_report(y_val, y_pred)
cm_rfc2_sm = confusion_matrix(y_val, y_pred)
roc_auc_rfc2_sm = roc_auc_score(y_res, rfc2_sm.predict_proba(X_res)[:, 1])
- Trainieren des Modells mithilfe von LightGBM
# lgbm_model
mlflow.lightgbm.autolog(registered_model_name='lgbm_sm') # Register the trained model with autologging
lgbm_sm_model = LGBMClassifier(learning_rate = 0.07,
max_delta_step = 2,
n_estimators = 100,
max_depth = 10,
eval_metric = "logloss",
objective='binary',
random_state=42)
with mlflow.start_run(run_name="lgbm_sm") as run:
lgbm1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
# lgbm_sm_model.fit(X_train,y_train) # Imbalanced training data
lgbm_sm_model.fit(X_res, y_res.ravel()) # Balanced training data
y_pred = lgbm_sm_model.predict(X_val)
accuracy = accuracy_score(y_val, y_pred)
cr_lgbm_sm = classification_report(y_val, y_pred)
cm_lgbm_sm = confusion_matrix(y_val, y_pred)
roc_auc_lgbm_sm = roc_auc_score(y_res, lgbm_sm_model.predict_proba(X_res)[:, 1])
Experimentartefakt zur Nachverfolgung der Modellleistung
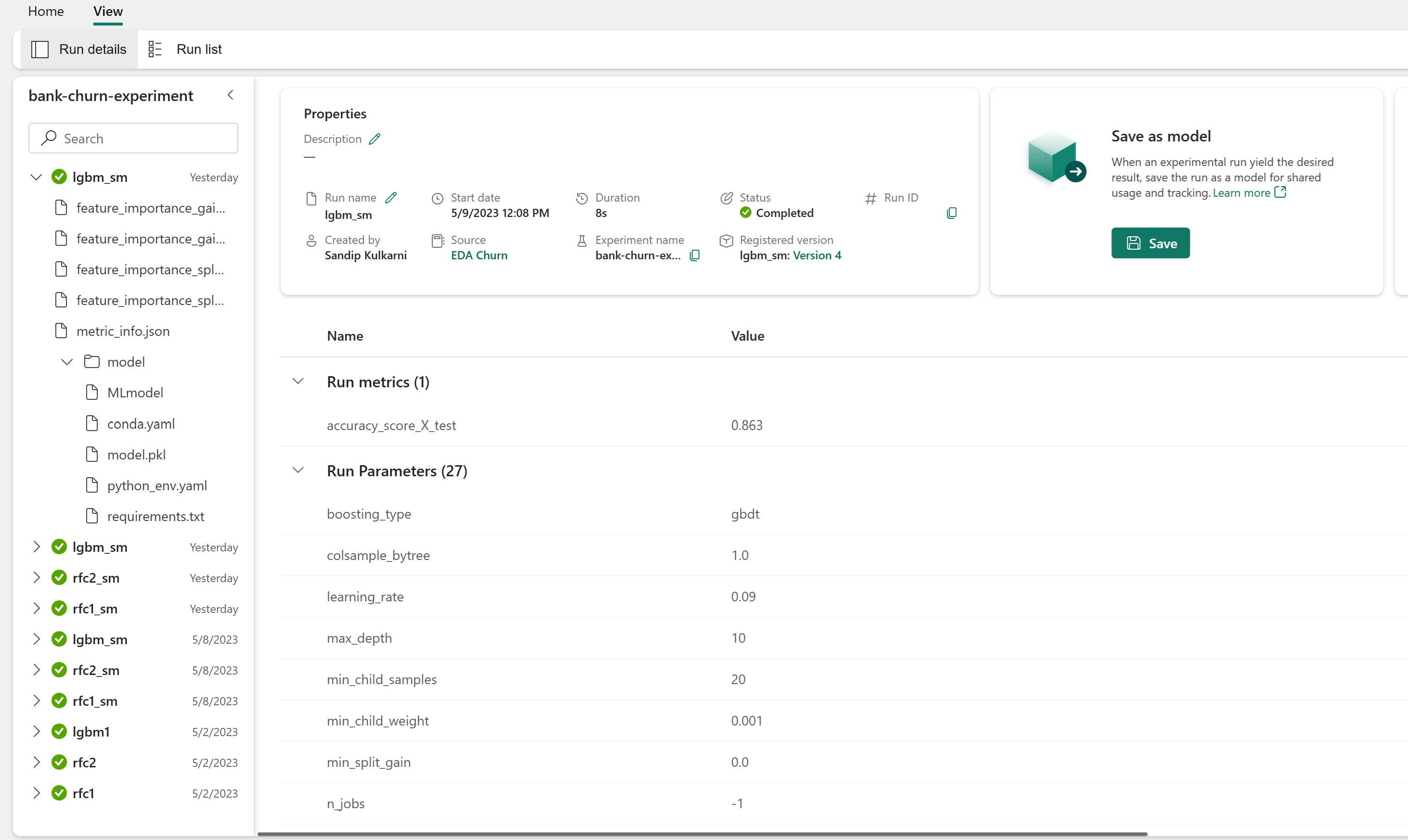
Das Experiment wird automatisch im Experimentartefakt gespeichert, das im Arbeitsbereich gefunden werden kann. Sie werden basierend auf dem Namen benannt, der zum Festlegen des Experiments verwendet wird. Alle trainierten Machine Learning-Modelle, deren Ausführung, Leistungsmetriken und Modellparameter werden protokolliert.
So zeigen Sie Ihre Experimente an:
Wählen Sie im linken Fensterbereich Ihren Arbeitsbereich aus.
Filtere oben rechts, um nur Experimente anzuzeigen, um das gesuchte Experiment leichter zu finden.
Suchen und wählen Sie den Namen des Experiments aus, in diesem Fall Sample-bank-churn-experiment. Wenn das Experiment nicht in Ihrem Arbeitsbereich angezeigt wird, aktualisieren Sie Ihren Browser.


Bewerten der Leistung der trainierten Modelle für den Validierungsdatensatz
Nach Abschluss des Trainings des Machine Learning-Modells können Sie die Leistung von trainierten Modellen auf zwei Arten bewerten.
Öffnen Sie das gespeicherte Experiment aus dem Arbeitsbereich, laden Sie die Machine Learning-Modelle, und bewerten Sie dann die Leistung der geladenen Modelle im Validierungsdatensatz.
# Define run_uri to fetch the model # mlflow client: mlflow.model.url, list model load_model_rfc1_sm = mlflow.sklearn.load_model(f"runs:/{rfc1_sm_run_id}/model") load_model_rfc2_sm = mlflow.sklearn.load_model(f"runs:/{rfc2_sm_run_id}/model") load_model_lgbm1_sm = mlflow.lightgbm.load_model(f"runs:/{lgbm1_sm_run_id}/model") # Assess the performance of the loaded model on validation dataset ypred_rfc1_sm_v1 = load_model_rfc1_sm.predict(X_val) # Random Forest with max depth of 4 and 4 features ypred_rfc2_sm_v1 = load_model_rfc2_sm.predict(X_val) # Random Forest with max depth of 8 and 6 features ypred_lgbm1_sm_v1 = load_model_lgbm1_sm.predict(X_val) # LightGBMBewerten Sie die Leistung der trainierten Machine Learning-Modelle direkt im Validierungsdatensatz.
ypred_rfc1_sm_v2 = rfc1_sm.predict(X_val) # Random Forest with max depth of 4 and 4 features ypred_rfc2_sm_v2 = rfc2_sm.predict(X_val) # Random Forest with max depth of 8 and 6 features ypred_lgbm1_sm_v2 = lgbm_sm_model.predict(X_val) # LightGBM
Je nach Ihren Vorlieben ist jeder Ansatz in Ordnung und sollte identische Leistungen bieten. In diesem Notebook wählen Sie den ersten Ansatz aus, um die Autoprotokollierungsfunktionen von MLflow in Microsoft Fabric besser zu veranschaulichen.
Anzeigen von True/False Positiven/Negativen mit der Wahrheitsmatrix
Als Nächstes entwickeln Sie ein Skript, um die Wahrheitsmatrix zu zeichnen, um die Genauigkeit der Klassifizierung mithilfe des Validierungsdatensatzes zu bewerten. Die Wahrheitsmatrix kann auch mithilfe von SynapseML-Tools gezeichnet werden, die in dem hier verfügbaren Betrugserkennungsbeispiel gezeigt wird.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import itertools
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
print(cm)
plt.figure(figsize=(4,4))
plt.rcParams.update({'font.size': 10})
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45, color="blue")
plt.yticks(tick_marks, classes, color="blue")
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="red" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
- Wahrheitsmatrix für Zufallsgesamtstrukturklassifizierung mit maximaler Tiefe von 4 und 4 Features
cfm = confusion_matrix(y_val, y_pred=ypred_rfc1_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 4')
tn, fp, fn, tp = cfm.ravel()
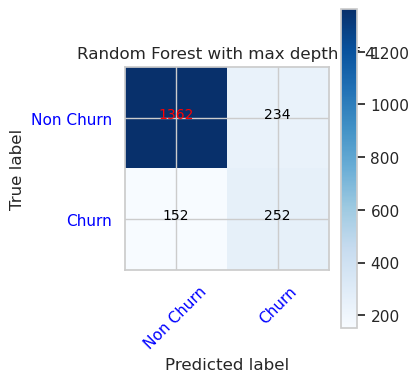
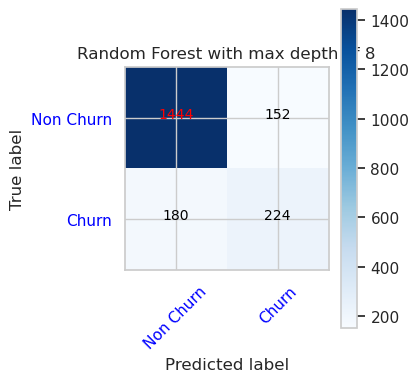
- Wahrheitsmatrix für Zufällige Gesamtstrukturklassifizierung mit maximaler Tiefe von 8 und 6 Features
cfm = confusion_matrix(y_val, y_pred=ypred_rfc2_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 8')
tn, fp, fn, tp = cfm.ravel()
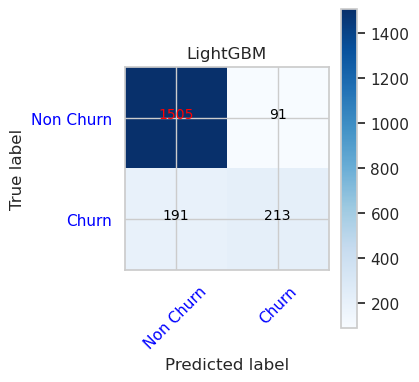
- Wahrheitsmatrix für LightGBM
cfm = confusion_matrix(y_val, y_pred=ypred_lgbm1_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='LightGBM')
tn, fp, fn, tp = cfm.ravel()