Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für:✅ Warehouse in Microsoft Fabric
Datenpipelines bieten eine Alternative zur Verwendung des COPY-Befehls über eine grafische Benutzeroberfläche. Eine Datenpipeline ist eine logische Gruppierung von Aktivitäten, die zusammen eine Datenerfassungsaufgabe bilden. Mit Pipelines können Sie ETL-Aktivitäten (Extrahieren, Transformieren und Laden) verwalten, anstatt sie einzeln zu koordinieren.
In diesem Tutorial erstellen Sie eine neue Pipeline, die Beispieldaten in ein Warehouse in Microsoft Fabric lädt.
Hinweis
Einige Features aus Azure Data Factory sind in Microsoft Fabric nicht verfügbar, aber die Konzepte sind austauschbar. Weitere Informationen zu Azure Data Factory und Pipelines finden Sie unter Pipelines und Aktivitäten in Azure Data Factory und Azure Synapse Analytics. Eine Schnellstartanleitung finden Sie unter Schnellstart: Erstellen Ihrer ersten Pipeline zum Kopieren von Daten.
Erstellen einer Datenpipeline
Um eine neue Pipeline zu erstellen, navigieren Sie zu Ihrem Arbeitsbereich, klicken Sie auf die Schaltfläche + Neu, und wählen Sie dann Datenpipeline aus.
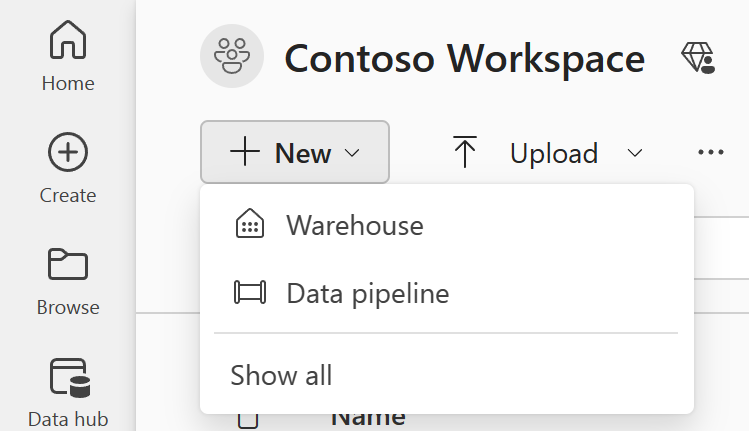
Geben Sie im Dialogfeld Neue Pipeline einen Namen für Ihre neue Pipeline ein, und klicken Sie auf Erstellen.
Sie landen im Pipelinecanvasbereich, in dem drei Optionen für die ersten Schritte angezeigt werden: Pipelineaktivität hinzufügen, Daten kopieren und Aufgabe für den Start auswählen.

Jede dieser Optionen bietet verschiedene Alternativen zum Erstellen einer Pipeline:
- Pipelineaktivität hinzufügen: Mit dieser Option wird der Pipeline-Editor gestartet, in dem Sie mithilfe von Pipelineaktivitäten neue Pipelines von Grund auf neu erstellen können.
- Daten kopieren: Mit dieser Option wird ein ausführlicher Assistent gestartet, der Ihnen dabei hilft, eine Datenquelle und ein Ziel auszuwählen und Datenladeoptionen wie die Spaltenzuordnungen zu konfigurieren. Nach Abschluss des Vorgangs wird eine neue Pipelineaktivität erstellt, wobei die Aufgabe Daten kopieren bereits für Sie konfiguriert ist.
- Aufgabe für den Start auswählen: Mit dieser Option werden basierend auf verschiedenen Szenarios mehrere vordefinierte Vorlagen gestartet, die Ihnen die ersten Schritte mit Pipelines erleichtern.
Wählen Sie die Option Daten kopieren aus, um den Kopier-Assistenten zu starten.
Auf der ersten Seite des Assistent Daten kopieren können Sie Ihre eigenen Daten aus verschiedenen Datenquellen oder aus einem der bereitgestellten Beispiele auswählen. In diesem Tutorial verwenden Sie das Beispiel COVID-19 Data Lake. Wählen Sie diese Option aus, und klicken Sie dann auf Weiter.
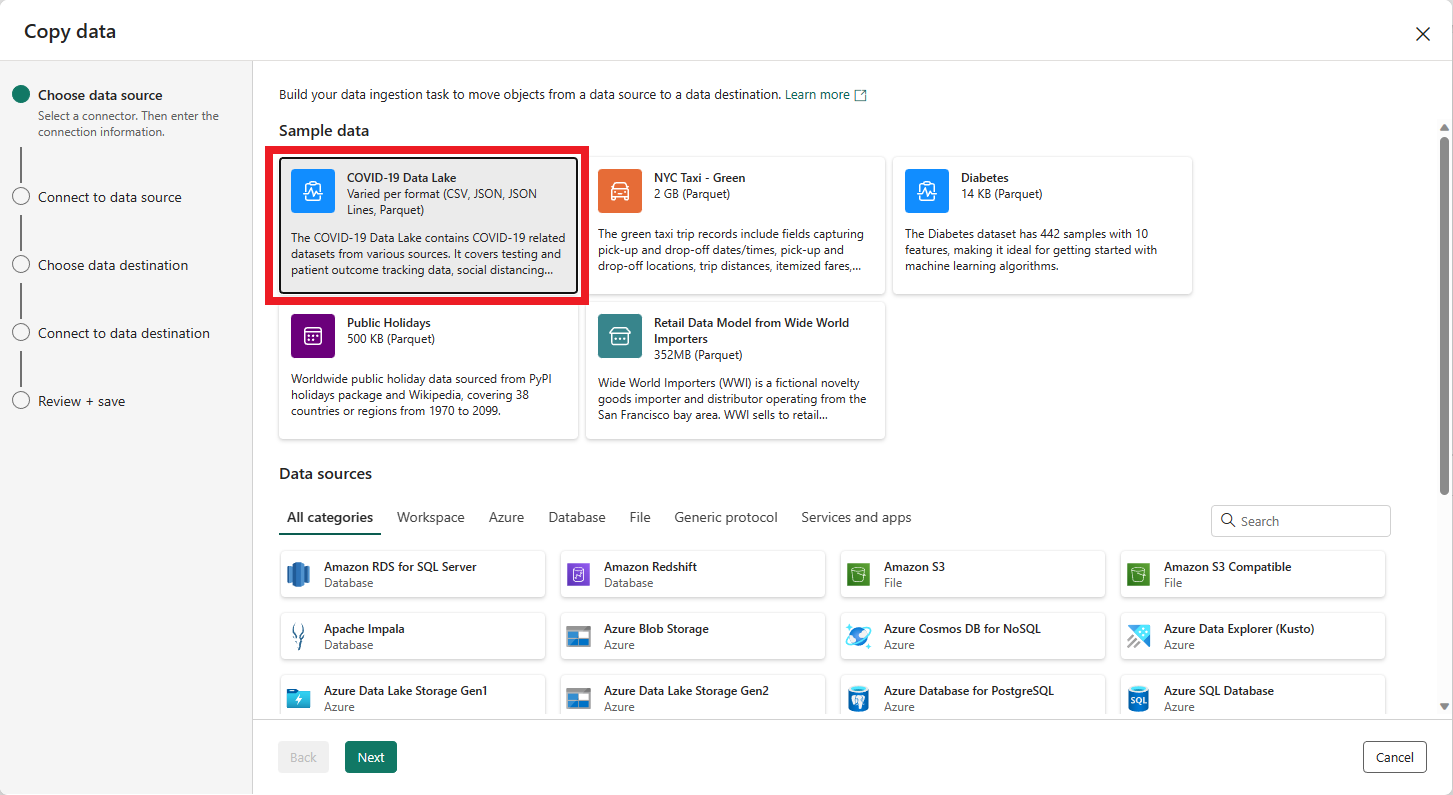
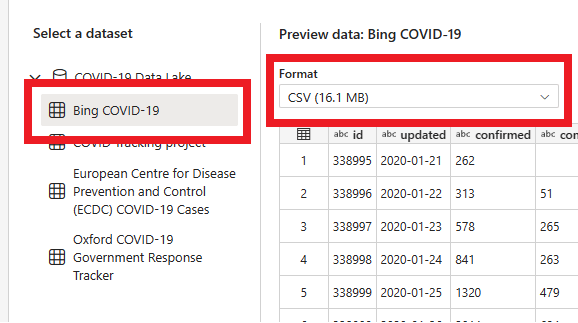
Auf der nächsten Seite können Sie ein Dataset, das Quelldateiformat und eine Vorschau des ausgewählten Datasets auswählen. Wählen Sie Bing COVID-19 und das CSV-Format aus, und klicken Sie auf Weiter.
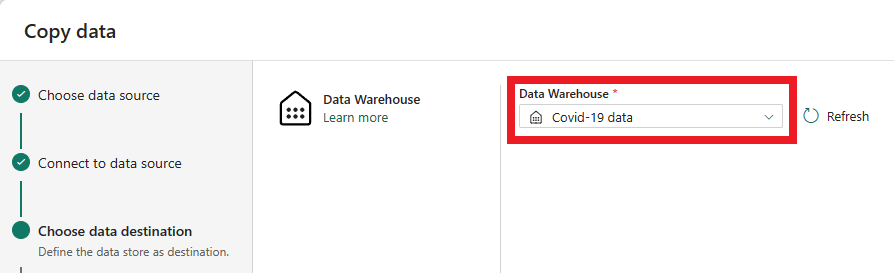
Auf der nächsten Seite mit der Bezeichnung Datenziele können Sie den Typ des Zielarbeitsbereichs konfigurieren. Sie laden Daten in ein Warehouse in Ihrem Arbeitsbereich. Wählen Sie daher die Registerkarte Warehouse und die Option Data Warehouse aus. Wählen Sie Weiter aus.

Jetzt ist es an der Zeit, das Warehouse auszuwählen, in das Daten geladen werden sollen. Wählen Sie in der Dropdownliste Ihr gewünschtes Warehouse aus und klicken Sie dann auf Weiter.
Der letzte Schritt zum Konfigurieren des Ziels besteht darin, einen Namen für die Zieltabelle anzugeben und die Spaltenzuordnungen zu konfigurieren. Hier können Sie die Daten in eine neue oder eine vorhandene Tabelle laden, ein Schema und Tabellennamen angeben, Spaltennamen ändern, Spalten entfernen oder deren Zuordnungen ändern. Sie können die Standardwerte übernehmen oder die Einstellungen nach Ihren Wünschen anpassen.
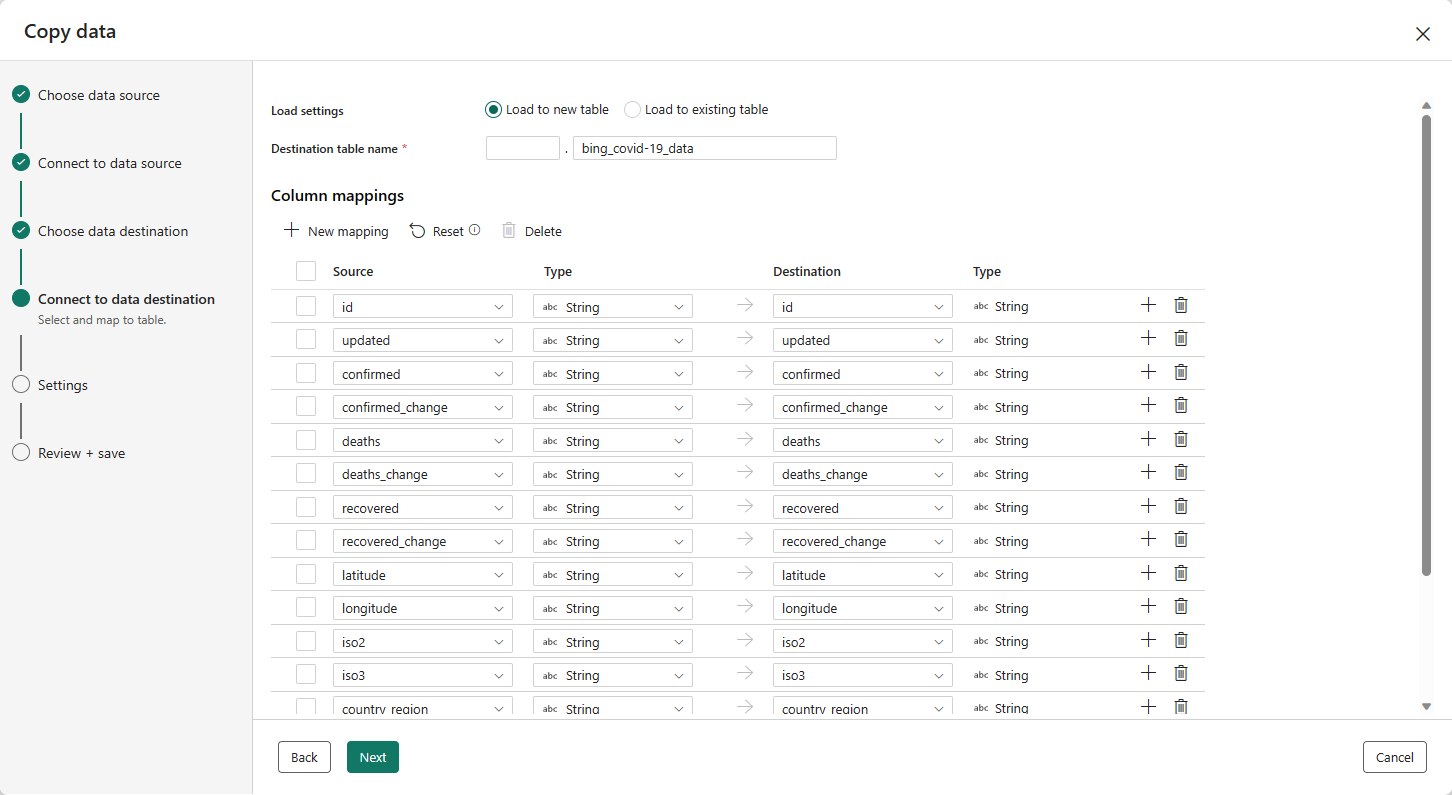
Wenn Sie die Optionen überprüft haben, klicken Sie auf Weiter.
Auf der nächsten Seite haben Sie die Möglichkeit, den Stagingansatz zu verwenden oder erweiterte Optionen für den Datenkopiervorgang bereitzustellen (der den T-SQL-Befehl „COPY“ verwendet). Überprüfen Sie die Optionen, ohne sie zu ändern, und klicken Sie auf Weiter.
Die letzte Seite im Assistenten bietet eine Zusammenfassung der Kopieraktivität. Wählen Sie die Option Datenübertragung sofort starten aus, und klicken Sie dann auf Speichern + ausführen.
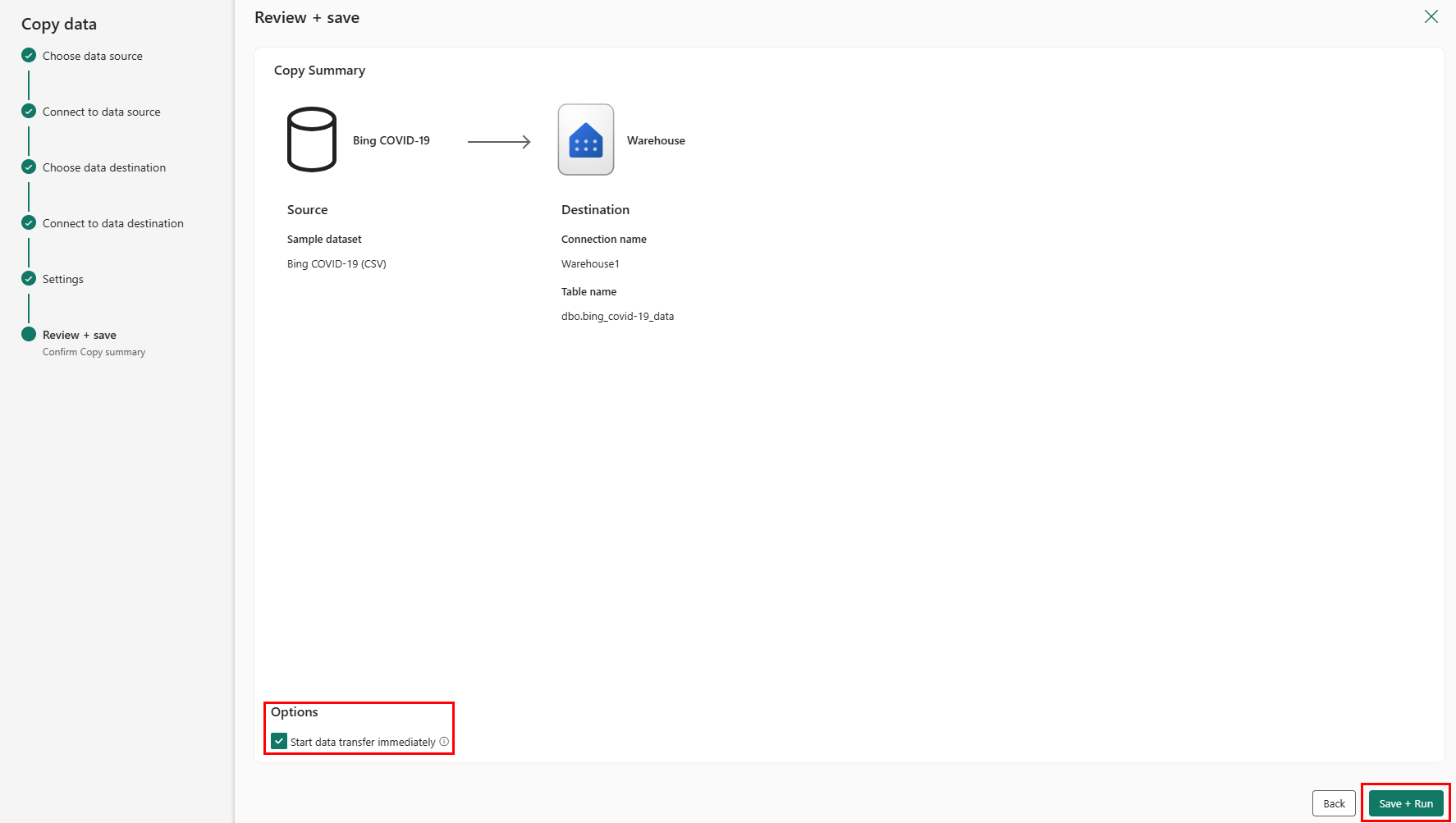
Sie werden zum Pipelinecanvasbereich weitergeleitet, in dem bereits eine neue Aktivität zum Kopieren von Daten für Sie konfiguriert ist. Die Pipeline wird automatisch ausgeführt. Sie können den Status Ihrer Pipeline im Bereich Ausgabe überwachen:
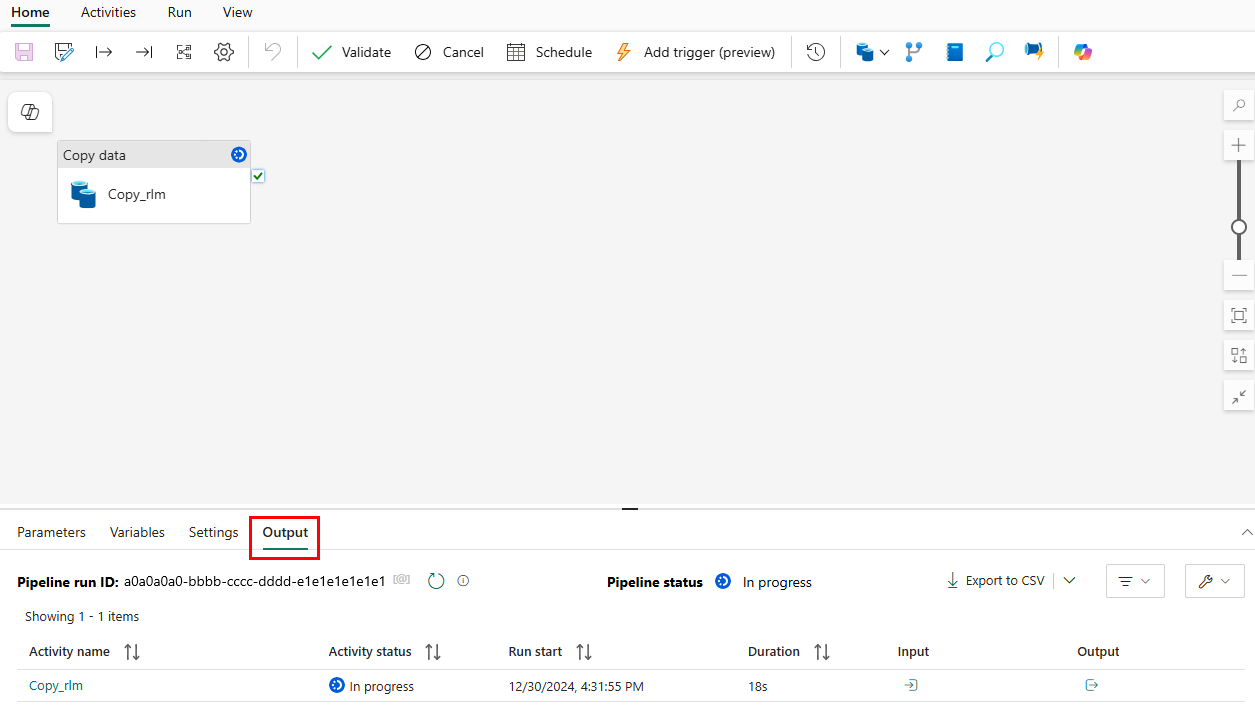
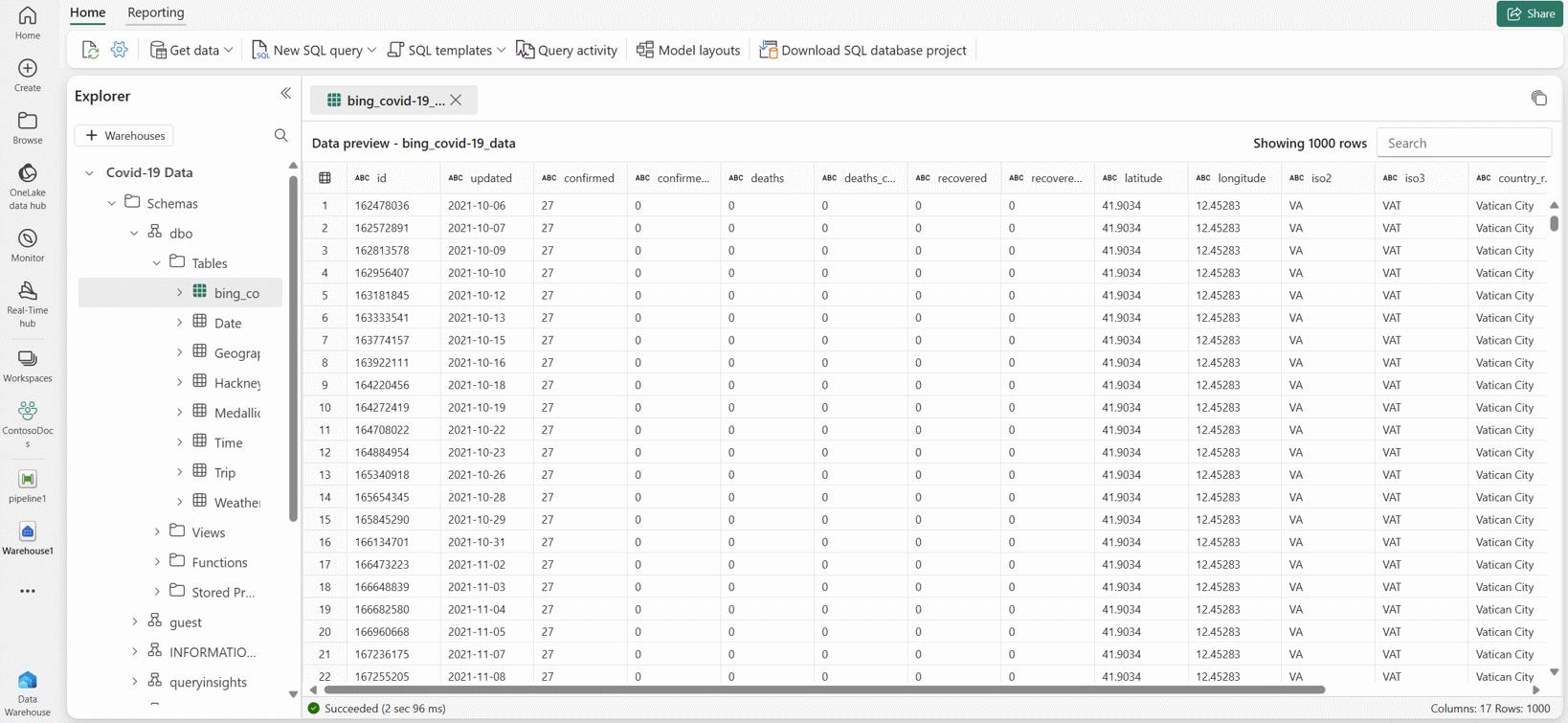
Nach einigen Sekunden wird die Pipeline erfolgreich beendet. Wenn Sie zurück zu Ihrem Warehouse navigieren, können Sie Ihre Tabelle auswählen, um eine Vorschau der Daten anzuzeigen und zu bestätigen, dass der Kopiervorgang abgeschlossen wurde.







Weitere Informationen zur Datenerfassung in Ihrem Warehouse in Microsoft Fabric finden Sie in den folgenden Artikeln:
- Erfassen von Daten im Warehouse
- Erfassen von Daten in Ihr Warehouse mithilfe der COPY-Anweisung
- Erfassen von Daten in Ihrem Warehouse mithilfe von Transact-SQL