Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Spiegelung in Fabric bietet eine einfache Möglichkeit, komplexe ETL-Prozesse (Extract, Transform, Load) zu vermeiden und Ihre vorhandenen Google BigQuery Warehouse-Daten nahtlos in den Rest Ihrer Daten in Fabric zu integrieren. Sie können Ihre Google BigQuery-Daten kontinuierlich direkt in Fabric OneLake replizieren. Einmal in Fabric können Sie leistungsstarke Funktionen für Business Intelligence, KI, Datentechnik, Data Science und Datenfreigabe nutzen.
Für ein Tutorial zum Konfigurieren Ihrer Google BigQuery-Datenbank für die Spiegelung in Microsoft Fabric, siehe Tutorial: Konfigurieren von in Microsoft Fabric gespiegelten Datenbanken aus Google BigQuery.
Von Bedeutung
Die Spiegelung für Google BigQuery befindet sich jetzt in der Vorschau. Produktionsworkloads werden während der Vorschau nicht unterstützt.
Warum Spiegelung in Fabric verwenden?
Die Spiegelung in Microsoft Fabric entfernt die Komplexität des Zusammenfügens von Tools aus verschiedenen Anbietern. Ihre Daten müssen nicht migriert werden. Stellen Sie eine Verbindung mit Ihren Google BigQuery-Daten in nahezu Echtzeit her, um das Array der Analysetools von Fabric zu verwenden. Fabric arbeitet auch nahtlos mit Microsoft-Produkten, Google BigQuery und einer vielzahl von Technologien zusammen, die das Open-Source-Delta Lake-Tabellenformat unterstützen.
Welche Analyseerfahrungen sind integriert?
Die Spiegelung erstellt eine gespiegelte Datenbank und einen SQL-Analyseendpunkt in Ihrem Fabric Arbeitsbereich. Die gespiegelte Datenbank verwaltet die Replikation von Daten in OneLake sowie die Konvertierung in Parquet und ermöglicht nachgelagerte Anwendungsfälle wie Data Engineering, Data Science und mehr.
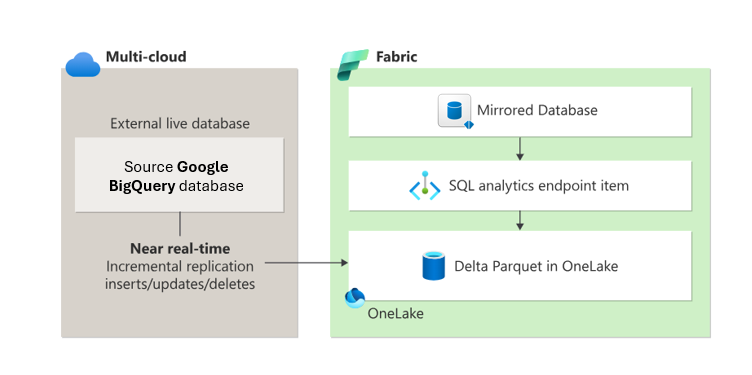
Der SQL-Analyseendpunkt bietet eine schreibgeschützte Analyseumgebung auf Grundlage der Delta-Tabellen, die während der Spiegelung erstellt wurden. Sie können gespiegelte Tabellen durchsuchen, codefreie Abfragen und Ansichten erstellen, SQL-Ansichten und gespeicherte Prozeduren erstellen und Daten über Lager und Seehäuser im selben Arbeitsbereich abfragen.
Weitere Informationen zu Analysefunktionen und kompatiblen Tools finden Sie unter Spiegelungsobjekte.
Sicherheitsüberlegungen
Es gibt bestimmte Benutzerberechtigungsanforderungen , um Fabric Mirroring zu aktivieren.
Fabric bietet außerdem Datenschutzfeatures zum Verwalten des Zugriffs innerhalb von Microsoft Fabric. Weitere Informationen finden Sie in unserer Dokumentation zu Datenschutzfeatures.
Gespiegelte Überlegungen zu BigQuery-Kosten
Die Fabric-Compute, die zum Replizieren Ihrer Daten in Fabric OneLake verwendet wird, ist kostenlos. Die Speicherkosten für Spiegelung sind bis zu einem nach Kapazität festgelegten Grenzwert kostenlos. Die Rechenressourcen zum Abfragen von Daten mit SQL, Power BI oder Spark werden zu den üblichen Preisen berechnet.
Fabric erhebt keine Eingangsgebühren für Netzwerkdaten in OneLake für die Spiegelung.
Es entstehen Google BigQuery-Rechen- und Cloud-Abfragekosten, wenn Daten gespiegelt werden: BigQuery Change Data Capture (CDC) nutzt BigQuery-Rechenleistung für Zeilenänderungen, die Speicher-Schreib-API für die Datenaufnahme und BigQuery-Speicher für die Datenspeicherung. All diese Schritte verursachen jeweils Kosten.
Weitere Informationen zu den Kosten für die Spiegelung von Google BigQuery finden Sie unter der Preisgestaltung erläutert.