Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In Microsoft OneLake können Sie nahtlos mit Tabellen in Delta Lake- und Apache Iceberg-Formaten arbeiten.
Diese Flexibilität wird durch die Metadatenvirtualisierung ermöglicht, ein Feature, mit dem Iceberg-Tabellen als Delta Lake-Tabellen interpretiert werden können und umgekehrt. Sie können Iceberg-Tabellen direkt schreiben oder Verknüpfungen zu ihnen erstellen, sodass diese Tabellen für verschiedene Fabric-Workloads zugänglich sind. Ebenso können Fabric-Tabellen, die im Delta Lake-Format geschrieben wurden, mit Iceberg-Lesern gelesen werden.
Wenn Sie eine Verknüpfung zu einem Iceberg-Tabellenordner schreiben oder erstellen, generiert OneLake automatisch virtuelle Delta Lake-Metadaten (Delta-Protokoll) für die Tabelle, wodurch die Verwendung mit Fabric-Workloads ermöglicht wird. Umgekehrt enthalten Delta Lake-Tabellen jetzt virtuelle Iceberg-Metadaten und ermöglichen die Kompatibilität mit Iceberg-Lesern.
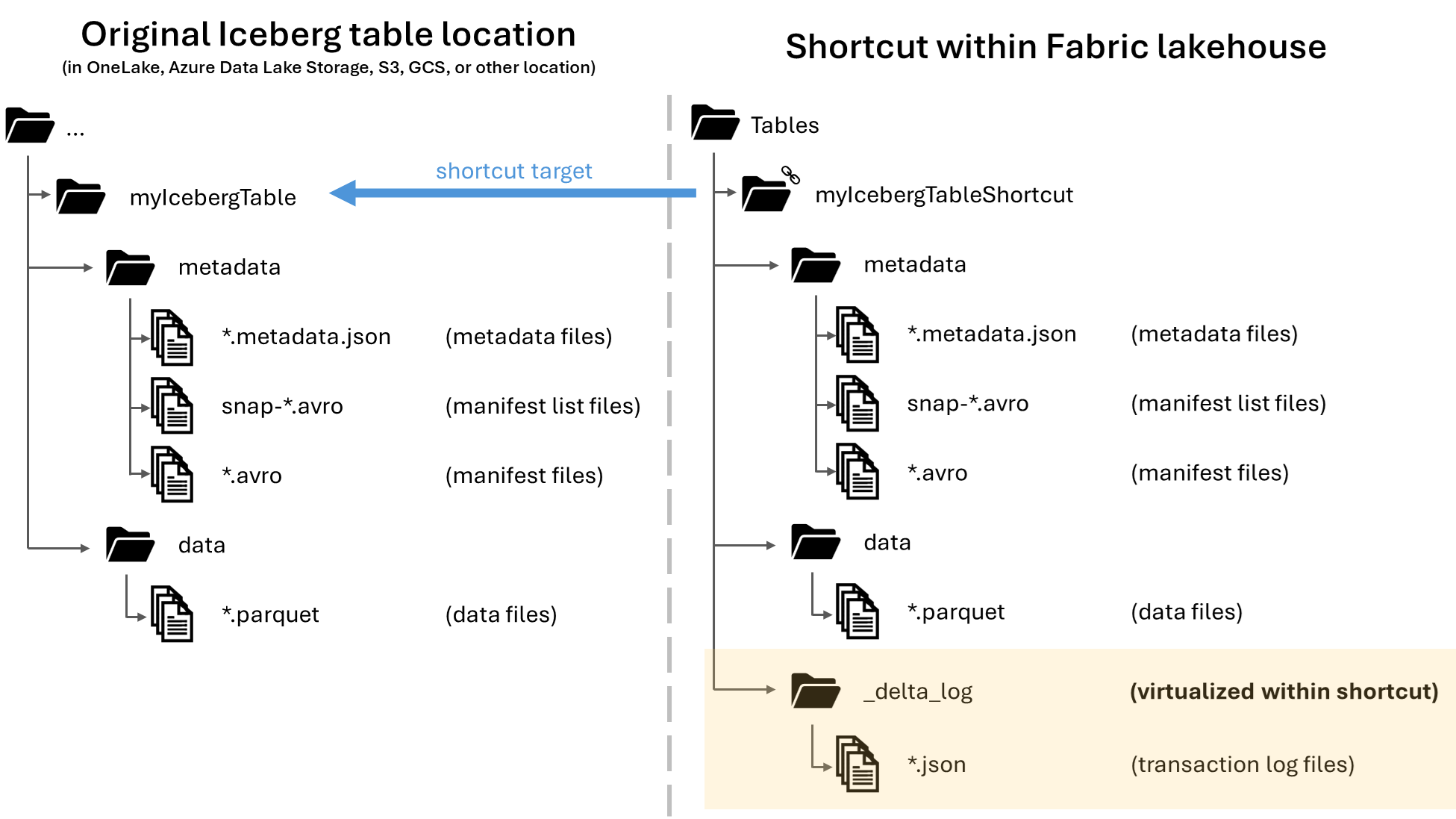
Während dieser Artikel Anleitungen für die Verwendung von Iceberg-Tabellen mit Snowflake enthält, ist dieses Feature für die Verwendung mit Iceberg-Tabellen und im Speicher befindlichen Datendateien im Parquet-Format vorgesehen.
Delta-Lake-Tabellen als Iceberg virtualisieren
Führen Sie die folgenden Schritte aus, um die automatische Konvertierung und Virtualisierung von Tabellen aus dem Delta Lake-Format in das Iceberg-Format einzurichten.
Stellen Sie sicher, dass sich ihre Delta Lake-Tabelle oder eine Verknüpfung zu ihr im
TablesAbschnitt Ihres Datenelements befindet. Das Datenelement kann ein Seehaus oder ein anderes Fabric-Datenelement sein.Tipp
Wenn Ihr Lakehouse schema-aktiviert ist, befindet sich Ihr Tabellenverzeichnis direkt in einem Schema, wie z. B.
dbo. Wenn Ihr Lakehouse nicht schemafähig ist, befindet sich Ihr Tabellenverzeichnis direkt imTablesVerzeichnis.Vergewissern Sie sich, dass Ihre Delta Lake-Tabelle erfolgreich in das virtuelle Iceberg-Format konvertiert wurde. Sie können dies tun, indem Sie das Verzeichnis hinter der Tabelle untersuchen.
Um das Verzeichnis anzuzeigen, wenn sich Ihre Tabelle in einem Seehaus befindet, können Sie mit der rechten Maustaste auf die Tabelle in der Fabric-Benutzeroberfläche klicken und "Dateien anzeigen" auswählen.
Wenn sich Ihre Tabelle in einem anderen Datenelementtyp befindet, z. B. einem Lagerhaus, einer Datenbank oder einer gespiegelten Datenbank, müssen Sie einen Client wie Azure Storage-Explorer oder OneLake-Datei-Explorer anstelle der Fabric-Benutzeroberfläche verwenden, um die Dateien hinter der Tabelle anzuzeigen.
Sie sollten ein Verzeichnis mit dem Namen
metadatainnerhalb des Tabellenordners sehen, und es sollte mehrere Dateien enthalten, einschließlich der Konvertierungsprotokolldatei. Öffnen Sie die Konvertierungsprotokolldatei, um weitere Informationen zum Delta Lake zu Iceberg-Konvertierung anzuzeigen, einschließlich des Zeitstempels der letzten Konvertierung und aller Fehlerdetails.Wenn die Konvertierungsprotokolldatei anzeigt, dass die Tabelle erfolgreich konvertiert wurde, lesen Sie die Iceberg-Tabelle mit Ihrem Dienst, Ihrer App oder Bibliothek.
Je nachdem, welchen Iceberg-Reader Sie verwenden, müssen Sie entweder den Pfad zum Tabellenverzeichnis oder zur zuletzt im
.metadata.jsonVerzeichnis angezeigtenmetadataDatei kennen.Sie können den HTTP-Pfad zur neuesten Metadatendatei Ihrer Tabelle anzeigen, indem Sie die Eigenschaftenansicht für die
*.metadata.jsonDatei mit der höchsten Versionsnummer öffnen. Notieren Sie sich diesen Pfad.Der Pfad zum Ordner Des Datenelements
Tablessieht möglicherweise wie folgt aus:https://onelake.dfs.fabric.microsoft.com/83896315-c5ba-4777-8d1c-e4ab3a7016bc/a95f62fa-2826-49f8-b561-a163ba537828/Tables/Innerhalb dieses Ordners kann der relative Pfad zur neuesten Metadatendatei so aussehen:
dbo/MyTable/metadata/321.metadata.json.Um Ihre virtuelle Iceberg-Tabelle mit Snowflake zu lesen, befolgen Sie die Schritte in diesem Leitfaden.
Erstellen einer Schnellzugriffsverknüpfung zu einer Iceberg-Tabelle
Wenn Sie bereits über eine Iceberg-Tabelle an einem Speicherort verfügen, der von OneLake-Verknüpfungen unterstützt wird, führen Sie die folgenden Schritte aus, um eine Verknüpfung zu erstellen und die Iceberg-Tabelle im Delta Lake-Format anzuzeigen.
Suchen Sie die Iceberg-Tabelle. Suchen Sie den Speicherort der Iceberg-Tabelle. Das kann Azure Data Lake Storage, OneLake, Amazon S3, Google Cloud Storage oder ein S3-kompatibler Speicherdienst sein.
Hinweis
Wenn Sie Snowflake verwenden und nicht sicher sind, wo die Iceberg-Tabelle gespeichert ist, können Sie die folgende Anweisung ausführen, um den Speicherort der Iceberg-Tabelle anzuzeigen.
SELECT SYSTEM$GET_ICEBERG_TABLE_INFORMATION('<table_name>');Wenn Sie diese Anweisung ausführen, wird ein Pfad zur Metadatendatei für die Iceberg-Tabelle zurückgegeben. Dieser Pfad gibt an, in welchem Speicherkonto die Iceberg-Tabelle enthalten ist. Nachfolgend sehen Sie ein Beispiel mit den relevanten Informationen, um den Pfad einer in Azure Data Lake Storage gespeicherten Iceberg-Tabelle zu finden:
{"metadataLocation":"azure://<storage_account_path>/<path_within_storage>/<table_name>/metadata/00001-389700a2-977f-47a2-9f5f-7fd80a0d41b2.metadata.json","status":"success"}Der Iceberg-Tabellenordner muss einen Ordner
metadataenthalten, der selbst mindestens eine Datei enthält, die auf.metadata.jsonendet.Erstellen Sie in Ihrem Fabric Lakehouse eine neue Tabellenverknüpfung im Tabellenbereich eines Seehauses.
Tipp
Wenn Schemas wie dbo unter dem Ordner "Tabellen" Ihres Lakehouse angezeigt werden, ist das Lakehouse schemafähig. Klicken Sie in diesem Fall mit der rechten Maustaste auf das Schema, und erstellen Sie eine Tabellenverknüpfung unter dem Schema.
Wählen Sie für den Zielpfad der Verknüpfung den Iceberg-Tabellenordner aus. Der Iceberg-Tabellenordner enthält die Ordner
metadataunddata.Sobald Ihre Verknüpfung erstellt wurde, sollte diese Tabelle automatisch als Delta Lake-Tabelle in Ihrem Lakehouse angezeigt werden und steht dann zur Verwendung in Fabric bereit.
Wenn die neue Verknüpfung zur Iceberg-Tabelle nicht als verwendbare Tabelle angezeigt wird, überprüfen Sie den Abschnitt Problembehandlung.
Problembehandlung
Anhand der folgenden Tipps können Sie sicherstellen, dass die Iceberg-Tabellen mit diesem Feature kompatibel sind:
Überprüfen der Ordnerstruktur der Iceberg-Tabelle
Öffnen Sie den Iceberg-Ordner in Ihrem bevorzugten Speicher-Explorertool, und überprüfen Sie die Verzeichnisauflistung des Iceberg-Ordners am ursprünglichen Speicherort. Sie sollten eine Ordnerstruktur wie im folgenden Beispiel sehen:
../
|-- MyIcebergTable123/
|-- data/
|-- A5WYPKGO_2o_APgwTeNOAxg_0_1_002.parquet
|-- A5WYPKGO_2o_AAIBON_h9Rc_0_1_003.parquet
|-- metadata/
|-- 00000-1bdf7d4c-dc90-488e-9dd9-2e44de30a465.metadata.json
|-- 00001-08bf3227-b5d2-40e2-a8c7-2934ea97e6da.metadata.json
|-- 00002-0f6303de-382e-4ebc-b9ed-6195bd0fb0e7.metadata.json
|-- 1730313479898000000-Kws8nlgCX2QxoDHYHm4uMQ.avro
|-- 1730313479898000000-OdsKRrRogW_PVK9njHIqAA.avro
|-- snap-1730313479898000000-9029d7a2-b3cc-46af-96c1-ac92356e93e9.avro
|-- snap-1730313479898000000-913546ba-bb04-4c8e-81be-342b0cbc5b50.avro
Wenn der Metadatenordner oder die Dateien mit den in diesem Beispiel gezeigten Erweiterungen nicht angezeigt werden, verfügen Sie möglicherweise nicht über eine ordnungsgemäß generierte Iceberg-Tabelle.
Überprüfen des Konvertierungsprotokolls
Wenn eine Iceberg-Tabelle als Delta Lake-Tabelle virtualisiert wird, wird im Verknüpfungsordner der Ordner _delta_log/ angezeigt. Dieser Ordner enthält nach erfolgreicher Konvertierung die Metadaten des Delta Lake-Formats (das Delta-Protokoll).
Dieser Ordner enthält auch die Datei latest_conversion_log.txt, die Informationen darüber enthält, ob die letzte Konvertierung erfolgreich war oder fehlgeschlagen ist.
Wenn Sie den Inhalt dieser Datei nach dem Erstellen der Verknüpfung anzeigen möchten, öffnen Sie im Bereich „Tabellen“ Ihres Lakehouses das Menü für die Iceberg-Tabellenverknüpfung und wählen Sie Dateien anzeigen aus.
Sie sollten eine Struktur wie im folgenden Beispiel sehen:
Tables/
|-- MyIcebergTable123/
|-- data/
|-- <data files>
|-- metadata/
|-- <metadata files>
|-- _delta_log/ <-- Virtual folder. This folder doesn't exist in the original location.
|-- 00000000000000000000.json
|-- latest_conversion_log.txt <-- Conversion log with latest success/failure details.
Öffnen Sie die Protokolldatei für die Konvertierung, um Details zur letzten Konvertierungszeit oder zu Fehlern anzuzeigen. Wenn keine Protokolldatei für die Konvertierung angezeigt wird, wurde kein Konvertierungsversuch unternommen.
Wenn kein Konvertierungsversuch unternommen wurde
Wenn keine Protokolldatei für die Konvertierung angezeigt wird, wurde kein Konvertierungsversuch unternommen. Nachfolgend sind zwei häufige Gründe aufgeführt, warum kein Konvertierungsversuch unternommen wird:
Die Verknüpfung wurde nicht an der richtigen Stelle erstellt.
Damit eine Verknüpfung zu einer Iceberg-Tabelle in das Delta Lake-Format konvertiert werden kann, muss die Verknüpfung direkt unter dem Ordner „Tabellen“ eines Lakehouse platziert werden, das nicht für Schemas aktiviert ist. Sie dürfen die Verknüpfung nicht im Bereich „Dateien“ oder unter einem anderen Ordner platzieren, wenn die Tabelle automatisch als Delta Lake-Tabelle virtualisiert werden soll.
Der Zielpfad der Verknüpfung ist nicht der Pfad des Iceberg-Ordners.
Wenn Sie die Verknüpfung erstellen, muss der Ordnerpfad, den Sie als Zielspeicherort auswählen, ausschließlich der Ordner der Iceberg-Tabelle sein. Dieser Ordner enthält die Dateien
metadataunddata.
Fehlermeldung "Fabric-Kapazitätsregion kann nicht überprüft werden" in Snowflake
Wenn Sie Snowflake verwenden, um eine neue Iceberg-Tabelle in OneLake zu schreiben, wird möglicherweise die folgende Fehlermeldung angezeigt:
Der Fabric-Kapazitätsbereich kann nicht überprüft werden. Grund: 'Ungültiges Zugriffstoken. Dies kann auf Authentifizierung und Bereichsdefinition zurückzuführen sein. Überprüfen Sie delegierte Zugriffsbereiche.
Wenn dieser Fehler angezeigt wird, lassen Sie Ihren Fabric-Mandantenadministrator überprüfen, ob beide in dem Abschnitt Schreiben einer Iceberg-Tabelle in OneLake mit Snowflake genannten Mandanteneinstellungen aktiviert sind.
- Öffnen Sie in der oberen rechten Ecke der Fabric-Benutzeroberfläche Einstellungen, und wählen Sie das Verwaltungsportal aus.
- Aktivieren Sie unter "Mandanteneinstellungen" im Abschnitt " Entwicklereinstellungen " die Einstellung " Dienstprinzipale", die Fabric-APIs verwenden können.
- Aktivieren Sie im selben Bereich im Abschnitt OneLake-Einstellungen die Einstellung mit der Bezeichnung Benutzer können auf Daten, die in OneLake gespeichert sind, mit Apps außerhalb von Fabric darauf zugreifen.
Einschränkungen und Aspekte
Beachten Sie die folgenden temporären Einschränkungen, wenn Sie dieses Feature verwenden:
Unterstützte Apache Iceberg-Version
Das Tabellenformatvirtualisierungsfeature unterstützt derzeit Apache Iceberg V2 . Dies bedeutet, dass Iceberg V2-Metadaten generiert werden, wenn dieses Feature eine Delta Lake-Tabelle liest. Ursprüngliche Iceberg-Tabellen, die für dieses Feature bereitgestellt werden, müssen Iceberg V2 sein, um in das Delta Lake-Format konvertiert zu werden.
Wir arbeiten an der Unterstützung für das Lesen von Iceberg V3-Tabellen. Bleiben Sie auf dem Laufenden!
Neueste Metadatenversion konvertiert
Das Feature zur Virtualisierung des Tabellenformats konvertiert momentan die neueste Version der Tabellenmetadaten im ursprünglichen Tabellenformat. Wenn mehrere Versionen in das ursprüngliche Tabellenformat geschrieben werden, wird nur die neueste Tabellenmetadatenversion in das virtuelle Tabellenformat konvertiert.
Unterstützte Datentypen
Die folgenden Iceberg-Spaltendatentypen werden mithilfe dieses Features ihren entsprechenden Delta-Lake-Typen zugeordnet.
Iceberg-Spaltentyp Delta Lake-Spaltentyp Kommentare intintegerlonglongSiehe Problem mit Schriftartbreite. floatfloatdoubledoubleSiehe Problem mit Zeichenbreite. decimal(P, S)decimal(P, S)Siehe Problem mit Typbreite. booleanbooleandatedatetimestamptimestamp_ntzDer Iceberg-Datentyp timestampenthält keine Zeitzoneninformationen. Der Delta Lake-Typtimestamp_ntzwird in Fabric-Workloads nicht vollständig unterstützt. Wir empfehlen die Verwendung von Zeitstempeln, die Zeitzonen enthalten.timestamptztimestampUm diesen Typ zu verwenden, geben Sie in Snowflake bei der Erstellung von Iceberg-Tabellen timestamp_ltzals Spaltentyp an. Hier finden Sie weitere Informationen zu den Iceberg-Datentypen, die in Snowflake unterstützt werden.stringstringbinarybinarytimeNicht verfügbar Nicht unterstützt Problem mit Zeichenbreite
Wenn Sie Snowflake verwenden, um die Iceberg-Tabelle zu schreiben, und die Tabelle den Spaltentyp
INT64,doubleoderDecimalmit Genauigkeit >= 10 enthält, kann die resultierende virtuelle Delta Lake-Tabelle möglicherweise nicht von allen Fabric-Engines verwendet werden. Ihnen wird möglicherweise der folgende Fehler angezeigt:Parquet column cannot be converted in file ... Column: [ColumnA], Expected: decimal(18,4), Found: INT32.Wir arbeiten an der Behebung dieses Problems.
Problemumgehung: Wenn Sie die Benutzeroberfläche für die Lakehouse-Tabellenvorschau verwenden und dieses Problem sehen, können Sie den Fehler beheben, indem Sie zur Ansicht des SQL-Endpunkts wechseln (obere rechte Ecke, Lakehouse-Ansicht auswählen, zu SQL-Endpunkt wechseln) und von dort aus eine Vorschau der Tabelle anzeigen. Wenn Sie dann wieder zur Lakehouse-Ansicht wechseln, sollte die Tabellenvorschau ordnungsgemäß angezeigt werden.
Wenn Sie ein Spark-Notebook oder einen Spark-Auftrag ausführen und dieses Problem auftritt, können Sie den Fehler beheben, indem Sie die Spark-Konfiguration
spark.sql.parquet.enableVectorizedReaderauffalsefestlegen. Hier ist ein Beispiel für einen PySpark-Befehl, der in einem Spark-Notebook ausgeführt werden kann:spark.conf.set("spark.sql.parquet.enableVectorizedReader","false")Metadatenspeicher der Iceberg-Tabelle ist nicht portierbar
Die Metadatendateien einer Iceberg-Tabelle verweisen unter Verwendung absoluter Pfadverweise aufeinander. Wenn Sie den Ordnerinhalt einer Iceberg-Tabelle an einen anderen Speicherort kopieren oder verschieben, ohne die Iceberg-Metadatendateien neu zu schreiben, wird die Tabelle für Iceberg-Reader unlesbar, einschließlich dieses OneLake-Features.
Problemumgehung:
Wenn Sie die Iceberg-Tabelle an einen anderen Ort verschieben müssen, um dieses Feature zu verwenden, verwenden Sie das Tool, mit dem die Iceberg-Tabelle ursprünglich geschrieben wurde, um eine neue Iceberg-Tabelle am gewünschten Ort zu schreiben.
Iceberg-Tabellenordner dürfen nur eine Gruppe von Metadatendateien enthalten
Wenn Sie eine Iceberg-Tabelle in Snowflake ablegen und neu erstellen, werden die Metadatendateien nicht bereinigt. Dieses Verhalten ist designiert, um das
UNDROPFeature in Snowflake zu unterstützen. Da die Verknüpfung jedoch direkt auf einen Ordner verweist und dieser Ordner jetzt mehrere Metadatendateien enthält, kann die Tabelle erst konvertiert werden, wenn Sie die Metadatendateien der alten Tabelle entfernen.Die Konvertierung schlägt fehl, wenn mehrere Metadatendateien im Metadatenordner der Iceberg-Tabelle gefunden werden.
Problemumgehung:
So stellen Sie sicher, dass die konvertierte Tabelle die richtige Version der Tabelle widerspiegelt:
- Stellen Sie sicher, dass Sie nicht mehr als eine Iceberg-Tabelle im selben Ordner speichern.
- Bereinigen Sie nach dem Ablegen der Tabelle alle Inhalte eines Iceberg-Tabellenordners, bevor Sie die Tabelle neu erstellen.
Metadatenänderungen werden nicht sofort widergespiegelt
Wenn Sie Metadatenänderungen an der Iceberg-Tabelle vornehmen, z. B. eine Spalte hinzufügen, eine Spalte löschen, eine Spalte umbenennen oder einen Spaltentyp ändern, wird die Tabelle möglicherweise erst dann erneut konvertiert, wenn eine Datenänderung vorgenommen wird, z. B. das Hinzufügen einer Datenzeile.
Wir arbeiten daran, das Problem zu beheben, damit die richtige Metadatendatei ausgewählt wird, die die neueste Metadatenänderung enthält.
Problemumgehung:
Nachdem Sie die Schemaänderung an der Iceberg-Tabelle vorgenommen haben, fügen Sie eine Datenzeile hinzu, oder nehmen Sie eine andere Änderung an den Daten vor. Nach dieser Änderung sollten Sie die Tabelle aktualisieren können, um die neueste Ansicht in Fabric zu sehen.
Einschränkungen der Regionsverfügbarkeit
Dieses Feature ist in den folgenden Regionen noch nicht verfügbar:
- Katar, Mitte
- Norwegen, Westen
Problemumgehung:
Arbeitsbereiche, die mit Fabric-Kapazitäten in anderen Regionen verbunden sind, können dieses Feature verwenden. Hier finden Sie die vollständige Liste der Regionen, in denen Microsoft Fabric verfügbar ist.
Private Links werden nicht unterstützt
Derzeit wird dieses Feature nicht für Mandanten oder Arbeitsbereiche unterstützt, die private Links aktiviert haben.
Wir arbeiten an einer Verbesserung, um diese Einschränkung zu entfernen.
OneLake-Verknüpfungen müssen dieselbe Region haben
Es gibt eine temporäre Einschränkung für die Verwendung dieses Features mit Verknüpfungen, die auf OneLake-Speicherorte verweisen: Der Zielspeicherort der Verknüpfung muss sich in derselben Region wie die Verknüpfung selbst befinden.
Wir arbeiten an einer Verbesserung, um diese Anforderung zu entfernen.
Problemumgehung:
Wenn Sie einen OneLake-Shortcut zu einer Iceberg-Tabelle in einem anderen Lakehouse haben, stellen Sie sicher, dass dieses Lakehouse einer Kapazität in derselben Region zugeordnet ist.
Bestimmte Iceberg-Partitionstransformationstypen werden nicht unterstützt.
Derzeit werden die Iceberg-Partitionstypen
bucket[N]undtruncate[W]voidnicht unterstützt.Wenn die konvertierte Iceberg-Tabelle diese Partitionstransformationstypen enthält, ist die Virtualisierung im Delta Lake-Format nicht erfolgreich.
Wir arbeiten an einer Verbesserung, um diese Einschränkung zu entfernen.
Zugehöriger Inhalt
- Verwenden Sie Snowflake, um Iceberg-Tabellen in OneLake zu schreiben oder zu lesen.
- Weitere Informationen zu OneLake-Verknüpfungen