Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Verwenden Sie Verknüpfungstransformationen, um strukturierte Dateien in abfragbare Delta-Tabellen zu konvertieren. Wenn sich Ihre Quelldaten bereits in einem tabellarischen Format wie CSV, Parkett oder JSON befinden, kopieren und konvertieren Dateitransformationen diese Daten automatisch in das Delta Lake-Format, sodass Sie sie mithilfe von SQL, Spark oder Power BI abfragen können, ohne ETL-pipelines zu erstellen.
Informationen zu unstrukturierten Textdateien, die KI-Verarbeitung benötigen, z. B. Zusammenfassungs-, Übersetzungs- oder Stimmungsanalyse, finden Sie unter Shortcut Transformations (AI-powered).
Verknüpfungstransformationen bleiben immer mit den Quelldaten synchronisiert. Fabric Spark compute führt die Transformation durch und kopiert die von einer OneLake-Verknüpfung referenzierten Daten in eine verwaltete Delta-Tabelle. Mit der automatischen Schemabehandlung, tiefgehenden Entflachungskapazitäten und Unterstützung für mehrere Komprimierungsformate reduzieren Abkürzungstransformationen die Komplexität des Erstellens und Verwaltens von ETL-Pipelines.
Hinweis
Abkürzungstransformationen befinden sich derzeit in der öffentlichen Vorschau und unterliegen möglichen Änderungen.
Gründe für die Verwendung von Kurzweg-Transformationen
- Automatische Konvertierung – Fabric kopiert und konvertiert Quelldateien ohne manuelle Pipeline-Orchestrierung in das Delta-Format.
- Häufige Synchronisierung – Fabric fragt die Verknüpfung alle zwei Minuten einmal ab und synchronisiert Änderungen.
- Delta Lake-Ausgabe – Die resultierende Tabelle ist mit jedem Apache Spark-Modul kompatibel.
- Geerbte Governance – Die Verknüpfung erbt OneLake-Abstammung, Berechtigungen und Microsoft-Purview-Richtlinien.
Voraussetzungen
| Anforderung | Einzelheiten |
|---|---|
| Microsoft Fabric-SKU | Kapazität oder Testversion, die Lakehouse-Workloads unterstützt. |
| Ursprungsdaten | Ein Ordner, der homogene CSV-, Parkett- oder JSON-Dateien enthält. |
| Rolle im Arbeitsbereich | Mitwirkender oder höher. |
Unterstützte Quellen, Formate und Ziele
Alle in OneLake unterstützten Datenquellen werden unterstützt.
| Quelldateiformat | Bestimmungsort | Unterstützte Erweiterungen | Unterstützte Komprimierungstypen | Hinweise |
|---|---|---|---|---|
| CSV (UTF-8, UTF-16) | Tabelle "Delta Lake" im Ordner "Lakehouse / Tables " | .csv, .txt (Trennzeichen), TSV (tabtrennt), PSV (pipetrennt) | .csv.gz, .csv.bz2 | .csv.zip und .csv.snappy werden nicht unterstützt. |
| Parquet | Tabelle "Delta Lake" im Ordner "Lakehouse / Tables " | .parquet | .parquet.snappy, .parquet.gzip, .parquet.lz4, .parquet.brotli, .parquet.zstd | |
| JSON | Tabelle "Delta Lake" im Ordner "Lakehouse / Tables " | .json, JSONL, ndjson | .json.gz, .json.bz2, .jsonl.gz, .ndjson.gz, .jsonl.bz2, .ndjson.bz2 | .json.zip und .json.snappy werden nicht unterstützt. |
Einrichten einer Transformation von Shortcuts
Wählen Sie im Bereich Tabellen Ihres Lakehouse die Neue Tabellenverknüpfung aus, was die Verknüpfungstransformation (Vorschau) ist. Wählen Sie Ihre Quelle aus (z. B. Azure Data Lake, Azure Blob Storage, Dataverse, Amazon S3, GCP, SharePoint, OneDrive und mehr).
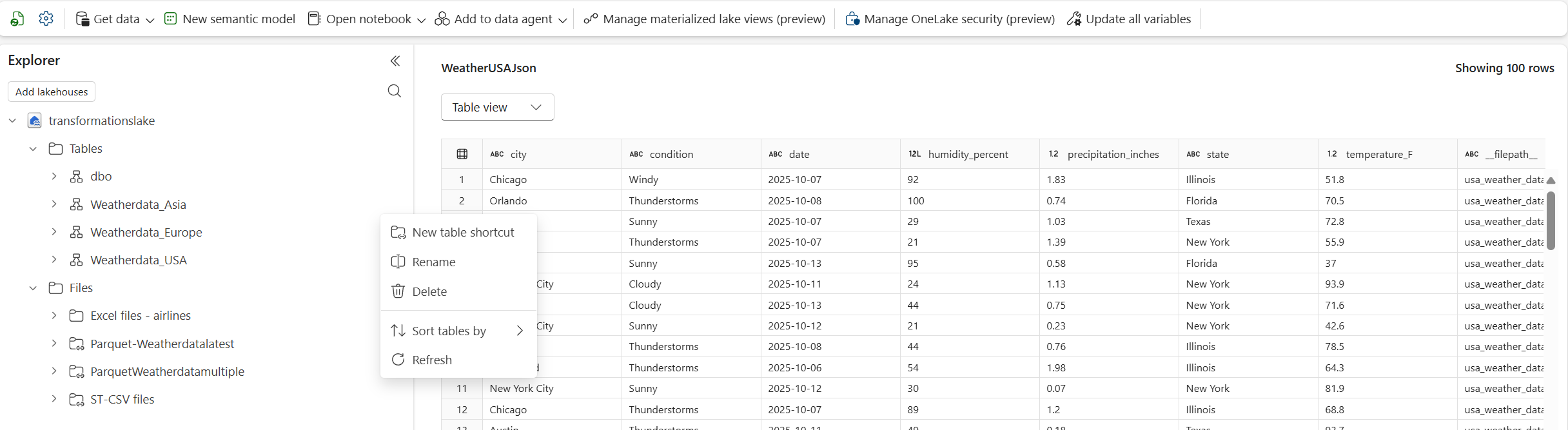
Wählen Sie Datei, Transformation konfigurieren und Verknüpfung erstellen – Navigieren Sie zu einer vorhandenen OneLake-Verknüpfung, die auf den Ordner mit Ihren CSV-Dateien verweist, konfigurieren Sie die Parameter und initiieren Sie die Erstellung.
- Trennzeichen in CSV-Dateien – Wählen Sie das Zeichen aus, das zum Trennen von Spalten verwendet wird (Komma, Semikolon, senkrechter Strich, Tabulator, kaufmännisches Und-Zeichen, Leerzeichen).
- Erste Zeile als Kopfzeile – Gibt an, ob die erste Zeile Spaltennamen enthält.
- Tabellenverknüpfungsname – Geben Sie einen freundlichen Namen an; Fabric erstellt ihn unter /Tables.
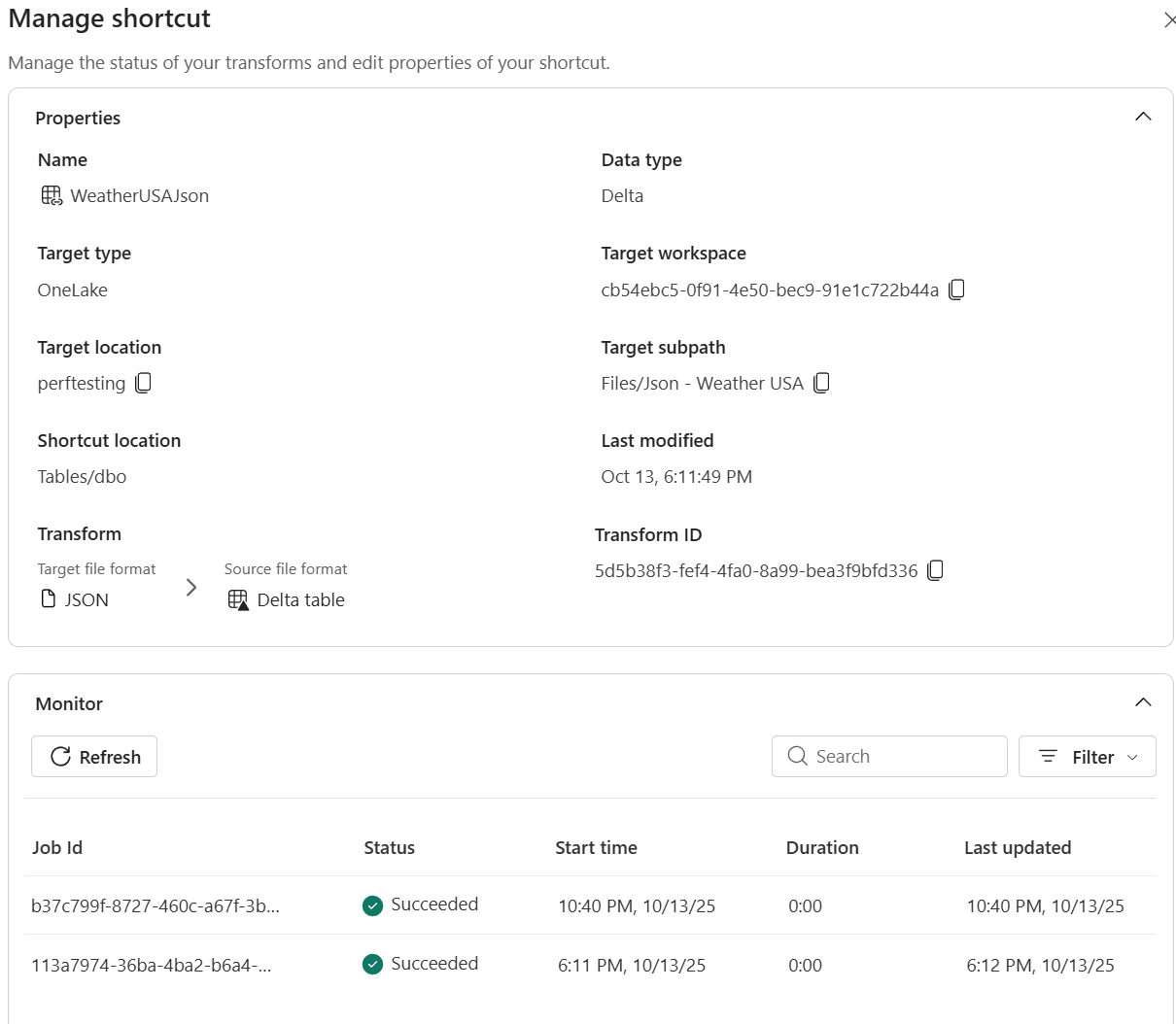
Nachverfolgen von Aktualisierungen und Anzeigen von Protokollen zur Transparenz im Hub "Verknüpfungsüberwachung verwalten".

Fabric Spark compute kopiert die Daten in eine Delta-Tabelle und zeigt den Fortschritt im Manage shortcut-Bereich an. Kurzbefehls-Transformationen sind in Lakehouse-Elementen verfügbar. Sie erstellen Delta Lake-Tabellen im Ordner Lakehouse /Tables .
Funktionsweise der Synchronisierung
Nach dem anfänglichen Laden berechnet Fabric Spark:
- Fragt das Verknüpfungsziel alle zwei Minuten ab.
- Erkennt neue oder geänderte Dateien und fügt Zeilen entsprechend an oder überschreibt sie.
- Erkennt gelöschte Dateien und entfernt entsprechende Zeilen.
Überwachen und Probleme beheben
Abkürzungstransformationen umfassen Überwachung und Fehlerbehandlung, um den Aufnahmestatus nachzuverfolgen und Probleme zu diagnostizieren.
Öffnen Sie das Seehaus, und klicken Sie mit der rechten Maustaste auf die Verknüpfung, die Ihre Transformation einfüttert.
Wählen Sie "Verknüpfung verwalten" aus.
Im Detailbereich können Sie Folgendes anzeigen:
- Status – Letztes Scanergebnis und aktueller Synchronisierungsstatus.
- Aktualisierungsverlauf – Chronologische Liste der Synchronisierungsvorgänge mit Zeilenanzahl und allen Fehlerdetails.
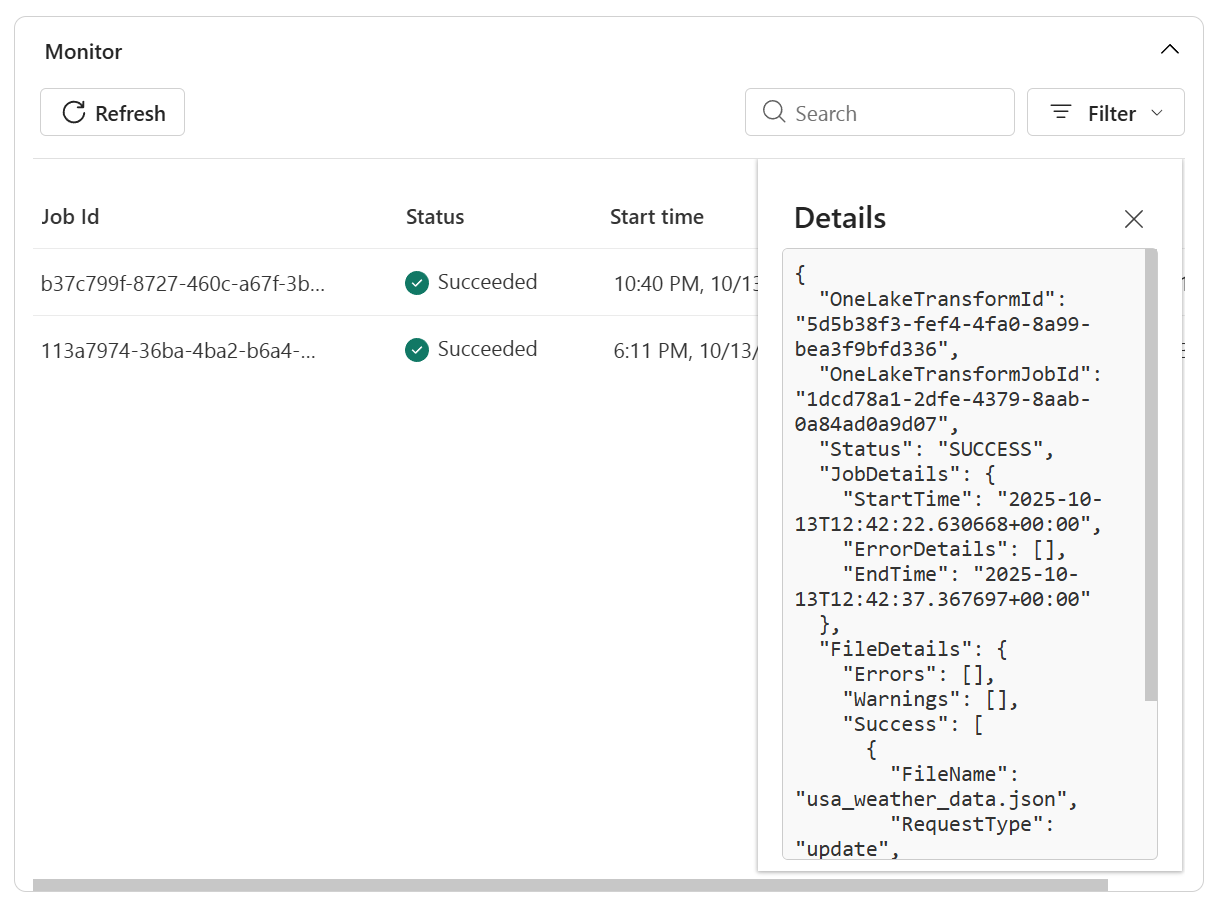
Weitere Details in Protokollen zur Problembehandlung anzeigen
Einschränkungen
Aktuelle Einschränkungen von Kurzbefehlsumwandlungen:
-
Quellformat: Es werden nur CSV-, JSON- und Parkettdateien unterstützt.
- Nicht unterstützte Datentypen für CSV: Gemischte Datentypspalten, Timestamp_Nanos, komplexe logische Typen - MAP/LIST/STRUCT, Raw-Binärdatei
- Nicht unterstützte Datentypen für Parkett: Timestamp_nanos, Dezimalzahl mit INT32/INT64, INT96, Nicht zugewiesene ganzzahlige Typen - UINT_8/UINT_16/UINT_64, Komplexe logische Typen - MAP/LIST/STRUCT
- Nicht unterstützte Datentypen für JSON: Gemischte Datentypen in einem Array, unformatierte binäre Blobs innerhalb von JSON, Timestamp_Nanos
- Dateischemakonsistenz: Dateien müssen ein identisches Schema gemeinsam nutzen.
- Verfügbarkeit des Arbeitsbereichs: Verfügbar nur in Lakehouse-Objekten (nicht in Data Warehouses oder KQL-Datenbanken).
- Schreibvorgänge: Transformationen sind leseoptimiert; direkte MERGE INTO- oder DELETE-Anweisungen auf der Transformationszieltabelle werden nicht unterstützt.
- Flachung des Array-Datentyps in JSON: Der Arraydatentyp wird in Delta-Tabellen und Daten aufbewahrt, auf die mit Spark SQL und Pyspark zugegriffen werden kann. Für weitere Transformationen könnte Fabric Materialized Lake Views für Silberschicht verwendet werden.
- Abflachungstiefe in JSON: Geschachtelte Strukturen werden bis zu fünf Ebenen tief abgeflacht. Für eine tiefere Schachtelung ist eine Vorverarbeitung erforderlich.
Verwenden Sie den Fabric-Roadmap - und Fabric-Updates-Blog , um mehr über neue Features und Versionen zu erfahren.
Aufräumen
Um die Synchronisierung zu beenden, löschen Sie die Verknüpfungstransformation aus Lakehouse Explorer.
Durch das Löschen der Transformation werden die zugrunde liegenden Dateien nicht entfernt.