Muster für Kubernetes-Cluster mit Hochverfügbarkeit
In diesem Artikel wird beschrieben, wie Sie eine hoch verfügbare Kubernetes-basierte Infrastruktur erstellen und betreiben, indem Sie eine AKS-Engine (Azure Kubernetes Service) unter Azure Stack Hub verwenden. Dieses Szenario trifft häufig für Organisationen mit kritischen Workloads in Umgebungen mit hohen Einschränkungen und starker Regulierung zu. Beispiele hierfür sind Organisationen in den Bereichen Finanzen, Verteidigung und Behörden.
Kontext und Problem
Viele Organisationen entwickeln cloudnative Lösungen, für die moderne Dienste und Technologien, z. B. Kubernetes, genutzt werden. Zwar sind in den meisten Regionen der Welt Azure-Rechenzentren vorhanden, aber es gibt auch spezielle Anwendungsfälle und Szenarien, bei denen unternehmenskritische Anwendungen an einem besonderen Ort ausgeführt werden müssen. Diese Aspekte spielen eine Rolle:
- Vertraulichkeitsgrad des Orts
- Latenz zwischen der Anwendung und lokalen Systemen
- Bandbreitenschutz
- Konnektivität
- Regulierungsbedingte oder gesetzliche Anforderungen
Die meisten dieser Anforderungen können durch die Verwendung von Azure mit Azure Stack Hub erfüllt werden. Im Folgenden sind viele Optionen, Entscheidungsmöglichkeiten und Aspekte beschrieben, die für eine erfolgreiche Implementierung von Kubernetes unter Azure Stack Hub berücksichtigt werden sollten.
Lösung
Bei diesem Muster wird davon ausgegangen, dass hohe Einschränkungen bestehen. Die Anwendung muss lokal ausgeführt werden, und alle personenbezogenen Daten dürfen nicht in die öffentliche Cloud gelangen. Überwachungsdaten und andere Daten, bei denen es sich nicht um personenbezogene Informationen handelt, können an die Azure-Umgebung gesendet und darin verarbeitet werden. Auf externe Dienste, z. B. eine öffentliche Container Registry-Instanz usw., kann zugegriffen werden, aber unter Umständen erfolgt eine Filterung durch eine Firewall oder einen Proxyserver.
Die hier dargestellte Beispielanwendung ist so konzipiert, dass nach Möglichkeit native Kubernetes-Lösungen genutzt werden. Bei diesem Ansatz wird die Abhängigkeit von Anbietern vermieden, und es werden keine plattformnativen Dienste genutzt. Beispielsweise wird für die Anwendung anstelle eines PaaS-Diensts oder eines externen Datenbankdiensts ein Back-End mit einer selbstgehosteten MongoDB-Datenbank verwendet. Weitere Informationen finden Sie im Lernpfad „Einführung in Kubernetes unter Azure“.

Im obigen Diagramm ist die Anwendungsarchitektur der Beispielanwendung dargestellt, die unter Kubernetes und Azure Stack Hub ausgeführt wird. Die App besteht aus mehreren Komponenten, z. B.:
- Einer AKS-Engine, die auf einem Kubernetes-Cluster unter Azure Stack Hub basiert.
- cert-manager mit einer Toolsuite für die Zertifikatverwaltung in Kubernetes, um automatisch Zertifikate von Let's Encrypt anzufordern.
- Einem Kubernetes-Namespace mit den Anwendungskomponenten für das Front-End (ratings-web), die API (ratings-api) und die Datenbank (ratings-mongodb).
- Einem Eingangsdatencontroller zum Weiterleiten von HTTP/HTTPS-Datenverkehr an Endpunkte im Kubernetes-Cluster.
Die Beispielanwendung wird verwendet, um die Anwendungsarchitektur zu veranschaulichen. Bei allen Komponenten handelt es sich um Beispiele. Die Architektur umfasst nicht mehr als eine Anwendungsbereitstellung. Zur Erzielung von Hochverfügbarkeit führen wir die Bereitstellung mindestens zweimal auf zwei verschiedenen Azure Stack Hub-Instanzen durch. Diese können entweder am selben Ort oder an zwei (oder mehr) unterschiedlichen Standorten ausgeführt werden:
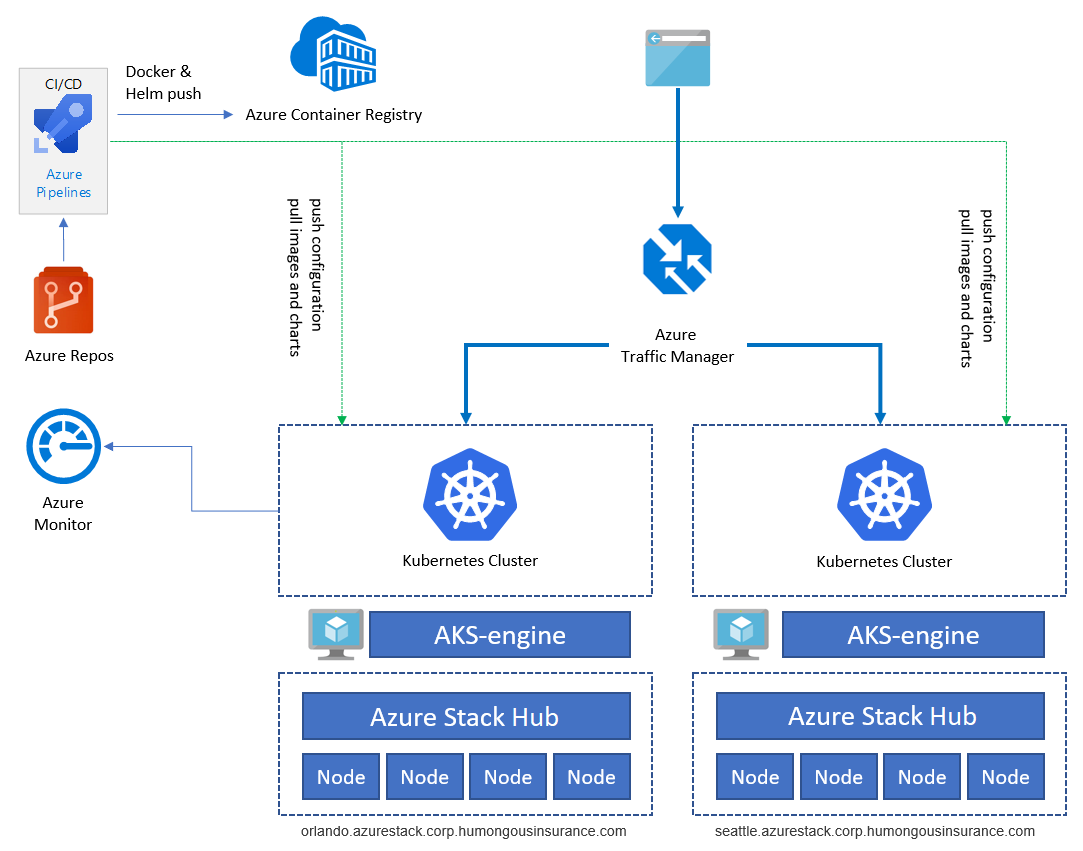
Dienste wie Azure Container Registry, Azure Monitor und andere werden außerhalb von Azure Stack Hub in Azure oder lokal gehostet. Mit diesem Hybridentwurf wird die Lösung vor einem Szenario geschützt, bei dem der Ausfall einer einzelnen Azure Stack Hub-Instanz ein großes Problem darstellt.
Komponenten
Die Gesamtarchitektur umfasst die folgenden Komponenten:
Azure Stack Hub ist eine Erweiterung von Azure, mit der Workloads in einer lokalen Umgebung ausgeführt werden können, indem Azure-Dienste in Ihrem Rechenzentrum bereitgestellt werden. Weitere Informationen finden Sie unter Übersicht über Azure Stack Hub.
Die Azure Kubernetes Service-Engine (AKS-Engine) ist die Engine im Hintergrund des verwalteten Kubernetes-Dienstangebots (Azure Kubernetes Service, AKS), das derzeit in Azure verfügbar ist. Für Azure Stack Hub ermöglicht die AKS-Engine die Bereitstellung, Skalierung und Aktualisierung von selbst verwalteten Kubernetes-Clustern mit vollem Funktionsumfang, indem die IaaS-Funktionen von Azure Stack Hub genutzt werden. Weitere Informationen finden Sie in der Übersicht über die AKS-Engine.
Weitere Informationen zu den Unterschieden zwischen der AKS-Engine unter Azure und unter Azure Stack Hub finden Sie in diesem Abschnitt zu den bekannten Problemen und Einschränkungen.
Ein virtuelles Azure-Netzwerk (Azure Virtual Network, VNET) wird verwendet, um die Netzwerkinfrastruktur auf den einzelnen Azure Stack Hub-Instanzen für die virtuellen Computer (VMs) bereitzustellen, von denen die Infrastruktur für die Kubernetes-Cluster gehostet wird.
Azure Load Balancer wird für den Kubernetes-API-Endpunkt und den NGINX-Eingangsdatencontroller verwendet. Das Lastenausgleichsmodul leitet externen Datenverkehr (z. B. aus dem Internet) an Knoten und VMs weiter, von denen ein bestimmter Dienst angeboten wird.
Azure Container Registry (ACR) wird zum Speichern von privaten Docker-Images und Helm-Diagrammen genutzt, die für den Cluster bereitgestellt werden. Die AKS-Engine kann für die Authentifizierung bei Container Registry eine Azure AD-Identität verwenden. Für Kubernetes ist keine ACR-Instanz erforderlich. Sie können auch andere Containerregistrierungen nutzen, z.B. Docker-Hub.
Bei Azure Repos handelt es sich um einen Satz mit Tools für die Versionskontrolle, mit denen Sie Ihren Code verwalten können. Sie können auch GitHub oder andere Git-basierte Repositorys nutzen. Weitere Informationen finden Sie unter Was ist Azure Repos?.
Azure Pipelines ist Teil von Azure DevOps Services und dient zum Durchführen von automatisierten Build-, Test- und Bereitstellungsvorgängen. Sie können auch CI/CD-Lösungen von Drittanbietern, z.B. Jenkins, verwenden. Weitere Informationen finden Sie unter Was ist Azure Pipelines?.
Azure Monitor erfasst und speichert Metriken und Protokolle. Beispiele hierfür sind Plattformmetriken für die Azure-Dienste in der Lösung und Anwendungstelemetrie. Nutzen Sie diese Daten zum Überwachen der Anwendung, Einrichten von Warnungen und Dashboards und Durchführen von Analysen der Grundursache von Fehlern. Azure Monitor wird mit Kubernetes integriert, um Metriken von Controllern, Knoten und Containern sowie aus den Protokollen von Containern und Masterknoten zu erfassen. Weitere Informationen finden Sie unter Azure Monitor – Übersicht.
Azure Traffic Manager ist ein DNS-basiertes Lastenausgleichsmodul, mit dem Sie Datenverkehr optimal an Dienste in unterschiedlichen Azure-Regionen oder Azure Stack Hub-Bereitstellungen verteilen können. Zudem sorgt Traffic Manager für Hochverfügbarkeit und eine gute Reaktionsfähigkeit. Die Anwendungsendpunkte müssen extern zugänglich sein. Hierfür sind auch andere lokale Lösungen verfügbar.
Über den Kubernetes-Eingangsdatencontroller werden HTTP(S)-Routen für die Dienste in einem Kubernetes-Cluster verfügbar gemacht. Zu diesem Zweck können NGINX oder andere geeignete Eingangsdatencontroller verwendet werden.
Helm ist ein Paket-Manager für die Kubernetes-Bereitstellung, mit dem unterschiedliche Kubernetes-Objekte, z. B. Bereitstellungen, Dienste, Geheimnisse, in einem gemeinsamen „Diagramm“ zusammengestellt werden können. Sie können die Versionsverwaltung veröffentlichen, bereitstellen und steuern und ein Diagrammobjekt aktualisieren. Azure Container Registry kann als Repository zum Speichern von Paketen mit Helm-Diagrammen verwendet werden.
Überlegungen zum Entwurf
Dieses Muster basiert auf einigen allgemeinen Aspekten, die in den nächsten Abschnitten dieses Artikels ausführlicher beschrieben werden:
- Für die Anwendung werden native Kubernetes-Lösungen genutzt, um die Abhängigkeit von Anbietern zu vermeiden.
- Die Anwendung basiert auf einer Microservicearchitektur.
- Für Azure Stack Hub wird keine eingehende Konnektivität benötigt, aber die Internetkonnektivität in ausgehender Richtung ist zulässig.
Diese empfohlenen Vorgehensweisen gelten auch für reale Workloads und Szenarien.
Überlegungen zur Skalierbarkeit
Skalierbarkeit ist wichtig, damit der Zugriff auf die Anwendung für Benutzer einheitlich, zuverlässig und leistungsstark ist.
Im Beispielszenario wird die Skalierbarkeit auf mehreren Ebenen des Anwendungsstapels beschrieben. Hier ist eine allgemeine Zusammenfassung der unterschiedlichen Ebenen angegeben:
| Architekturebene | Betrifft | Wie kann ich das erreichen? |
|---|---|---|
| Application | Application | Horizontale Skalierung basierend auf der Anzahl von Pods/Replikaten/Containerinstanzen* |
| Cluster | Kubernetes-Cluster | Anzahl von Knoten (zwischen 1 und 50), VM-SKU-Größen und Knotenpools (AKS-Engine unter Azure Stack Hub unterstützt derzeit nicht mehr als einen Knotenpool); Verwendung des Skalierungsbefehls der AKS-Engine (manuell) |
| Infrastruktur | Azure Stack Hub | Anzahl von Knoten, Kapazität und Skalierungseinheiten einer Azure Stack Hub-Bereitstellung |
* Verwendung der horizontalen automatischen Podskalierung (HPA) von Kubernetes; automatisierte metrikbasierte Skalierung oder vertikale Skalierung durch entsprechende Dimensionierung der Containerinstanzen (CPU/Arbeitsspeicher).
Azure Stack Hub (Infrastrukturebene)
Die Azure Stack Hub-Infrastruktur stellt die Grundlage dieser Implementierung dar, weil Azure Stack Hub auf physischer Hardware in einem Rechenzentrum ausgeführt wird. Bei der Auswahl der Hardware für Ihren Hub müssen Sie Entscheidungen in Bezug auf die CPU, Arbeitsspeicherdichte, Speicherkonfiguration und Anzahl von Servern treffen. Weitere Informationen zur Skalierbarkeit von Azure Stack Hub finden Sie in den folgenden Ressourcen:
- Übersicht über die Kapazitätsplanung für Azure Stack Hub
- Hinzufügen zusätzlicher Knoten einer Skalierungseinheit in Azure Stack Hub
Kubernetes-Cluster (Clusterebene)
Der Kubernetes-Cluster selbst besteht aus und basiert auf Azure-/Azure Stack-IaaS-Komponenten, z. B. Compute-, Speicher- und Netzwerkressourcen. Kubernetes-Lösungen verfügen über Master- und Workerknoten, die als VMs in Azure (und Azure Stack Hub) bereitgestellt werden.
- Über Knoten auf Steuerungsebene (Master) werden die grundlegenden Kubernetes-Dienste und Orchestrierungsfunktionen für Anwendungsworkloads bereitgestellt.
- Auf Workerknoten (Worker) werden Ihre Anwendungsworkloads ausgeführt.
Beim Auswählen von VM-Größen für die erste Bereitstellung sollten die folgenden Aspekte berücksichtigt werden:
Kosten: Achten Sie beim Planen Ihrer Workerknoten auf die anfallenden Gesamtkosten pro VM. Falls für Ihre Anwendungsworkloads beispielsweise eingeschränkte Ressourcen benötigt werden, sollten Sie die Bereitstellung von virtuellen Computern mit geringerer Größe planen. Die Abrechnung für Azure Stack Hub erfolgt – wie für Azure auch – normalerweise auf Nutzungsbasis. Die richtige Dimensionierung der VMs für Kubernetes-Rollen ist daher von entscheidender Bedeutung, um die Kosten für die Nutzung zu optimieren.
Skalierbarkeit: Der Cluster wird skaliert, indem die Anzahl von Master- und Workerknoten ab- und aufskaliert wird oder indem weitere Knotenpools hinzugefügt werden (derzeit in Azure Stack Hub nicht verfügbar). Die Skalierung des Clusters kann basierend auf Leistungsdaten erfolgen, die mit Container Insights (Azure Monitor und Log Analytics) gesammelt werden.
Falls für Ihre Anwendung mehr (oder weniger) Ressourcen benötigt werden, können Sie für Ihre aktuellen Knoten das Aufskalieren (oder Abskalieren) durchführen (im Bereich von 1 bis 50 Knoten). Falls Sie mehr als 50 Knoten benötigen, können Sie einen zusätzlichen Cluster unter einem separaten Abonnement erstellen. Das Hochskalieren der eigentlichen VMs auf eine andere VM-Größe ohne erneute Bereitstellung des Clusters ist nicht möglich.
Die Skalierung wird manuell mit dem virtuellen Hilfscomputer der AKS-Engine durchgeführt, der für die anfängliche Bereitstellung des Kubernetes-Clusters verwendet wurde. Weitere Informationen finden Sie im Artikel zum Skalieren von Kubernetes-Clustern.
Kontingente: Berücksichtigen Sie die von Ihnen konfigurierten Kontingente, wenn Sie eine AKS-Bereitstellung für Ihre Azure Stack Hub-Instanz planen. Stellen Sie sicher, dass für jedes Abonnement die richtigen Pläne und Kontingente konfiguriert wurden. Das Abonnement muss für den Umfang der Compute-, Speicher- und anderen Dienste ausgelegt sein, die für Ihre Cluster beim Aufskalieren benötigt werden.
Anwendungsworkloads: Informieren Sie sich im Artikel „Grundlegende Kubernetes-Konzepte für Azure Kubernetes Service (AKS)“ über die Cluster- und Workloadkonzepte. Dieser Artikel enthält hilfreiche Informationen zum Auswählen der richtigen VM-Größe basierend auf den Compute- und Arbeitsspeicheranforderungen Ihrer Anwendung.
Anwendung (Anwendungsebene)
Auf der Anwendungsebene verwenden wir die horizontale automatische Podskalierung (Horizontal Pod Autoscaler, HPA) von Kubernetes. Mit dieser Skalierung kann die Anzahl von Replikaten (Pod-/Containerinstanzen) in unserer Bereitstellung basierend auf unterschiedlichen Metriken (z. B. CPU-Auslastung) erhöht oder verringert werden.
Eine andere Möglichkeit ist die vertikale Skalierung von Containerinstanzen. Dies kann erreicht werden, indem Sie die CPU- und Arbeitsspeichermenge ändern, die für eine bestimmte Bereitstellung angefordert wurde und verfügbar ist. Weitere Informationen finden Sie unter „kubernetes.io“ im Artikel zum Verwalten von Ressourcen für Container.
Überlegungen zu Netzwerk und Konnektivität
Das Netzwerk und die Konnektivität wirken sich ebenfalls auf die oben erwähnten drei Ebenen für Kubernetes unter Azure Stack Hub aus. In der folgenden Tabelle sind die Ebenen und die darin enthaltenen Dienste aufgeführt:
| Ebene | Betrifft | Was? |
|---|---|---|
| Application | Application | Wie kann auf die Anwendung zugegriffen werden? Wird sie für den Zugriff über das Internet verfügbar gemacht? |
| Cluster | Kubernetes-Cluster | Kubernetes-API, AKS-Engine-VM, Pullen von Containerimages (ausgehend), Senden von Überwachungs- und Telemetriedaten (ausgehend) |
| Infrastruktur | Azure Stack Hub | Zugänglichkeit der Azure Stack Hub-Verwaltungsendpunkte, z. B. Portal und Azure Resource Manager-Endpunkte |
Anwendung
Der wichtigste Aspekt für die Anwendungsebene ist, ob die Anwendung über das Internet verfügbar gemacht wird bzw. zugänglich ist. Aus Sicht von Kubernetes bedeutet die Zugänglichkeit über das Internet, dass eine Bereitstellung oder ein Pod über einen Kubernetes-Dienst oder einen Eingangsdatencontroller verfügbar gemacht wird.
Das Verfügbarmachen einer Anwendung mit einer öffentlichen IP-Adresse über einen Load Balancer oder einen Eingangsdatencontroller bedeutet nicht zwangsläufig, dass die Anwendung sofort über das Internet zugänglich ist. In Azure Stack Hub kann eine öffentliche IP-Adresse auch nur im lokalen Intranet sichtbar sein. Nicht alle öffentlichen IP-Adressen sind auch wirklich über das Internet erreichbar.
Im obigen Abschnitt wurde der eingehende Datenverkehr für die Anwendung beschrieben. Ein weiteres Thema, das bei der Sicherstellung einer erfolgreichen Kubernetes-Bereitstellung berücksichtigt werden muss, ist ausgehender Datenverkehr. Hier sind einige Anwendungsfälle angegeben, für die ausgehender Datenverkehr erforderlich ist:
- Pullen von Containerimages, die in Docker Hub oder Azure Container Registry gespeichert sind
- Abrufen von Helm-Diagrammen
- Ausgeben von Application Insights-Daten (oder anderer Überwachungsdaten)
Für einige Unternehmensumgebungen werden unter Umständen transparente oder nicht transparente Proxyserver benötigt. Für diese Server ist eine bestimmte Konfiguration auf verschiedenen Komponenten unseres Clusters erforderlich. Die Dokumentation zur AKS-Engine enthält verschiedene Details zu Netzwerkproxys. Ausführliche Informationen hierzu finden Sie im Artikel zur AKS-Engine und zu Proxyservern.
Schließlich gibt es noch die Anforderung, dass der Fluss von clusterübergreifendem Datenverkehr zwischen Azure Stack Hub-Instanzen möglich sein muss. Die Beispielbereitstellung enthält individuelle Kubernetes-Cluster, die auf einzelnen Azure Stack Hub-Instanzen ausgeführt werden. Der Datenverkehr, der zwischen diesen Komponenten fließt, z. B. Replikationsdatenverkehr zwischen zwei Datenbanken, ist „extern“. Externer Datenverkehr muss entweder über eine Site-to-Site-VPN-Verbindung oder öffentliche Azure Stack Hub-IP-Adressen weitergeleitet werden, um für Kubernetes auf zwei Azure Stack Hub-Instanzen eine Verbindung herzustellen:

Cluster
Der Kubernetes-Cluster muss nicht unbedingt über das Internet zugänglich sein. Der relevante Teil ist die Kubernetes-API, die zum Betreiben eines Clusters verwendet wird, z. B. mit kubectl. Der Kubernetes-API-Endpunkt muss für alle Benutzer zugänglich sein, von denen der Cluster betrieben wird oder die Anwendungen und die zugehörigen Dienste bereitstellen. Dieses Thema wird unten im Abschnitt Bereitstellungsaspekte (CI/CD) aus DevOps-Sicht ausführlicher beschrieben.
Auf der Clusterebene sollten auch einige Aspekte in Bezug auf ausgehenden Datenverkehr berücksichtigt werden:
- Updates für Knoten (für Ubuntu)
- Überwachungsdaten (an Azure Log Analytics gesendet)
- Andere Agents, für die ausgehender Datenverkehr erforderlich ist (je nach Umgebung der einzelnen Bereitsteller)
Bevor Sie Ihren Kubernetes-Cluster mit einer AKS-Engine bereitstellen, sollten Sie den endgültigen Netzwerkentwurf planen. Anstatt ein dediziertes virtuelles Netzwerk zu erstellen, kann es effizienter sein, einen Cluster in einem vorhandenen Netzwerk bereitzustellen. Beispielsweise können Sie ggf. eine vorhandene Site-to-Site-VPN-Verbindung nutzen, die in Ihrer Azure Stack Hub-Umgebung bereits konfiguriert ist.
Infrastruktur
Bei der Infrastruktur geht es um den Zugriff auf die Azure Stack Hub-Verwaltungsendpunkte. Zu den Endpunkten gehören die Mandanten- und Administratorportale sowie die Azure Resource Manager-Endpunkte für Administratoren und Mandanten. Diese Endpunkte werden zum Betreiben von Azure Stack Hub und der zugehörigen Kerndienste benötigt.
Überlegungen zu Daten und Speicher
Zwei Instanzen unserer Anwendung werden in zwei einzelnen Kubernetes-Clustern auf zwei Azure Stack Hub-Instanzen bereitgestellt. Bei diesem Entwurf müssen wir berücksichtigen, wie Daten zwischen den einzelnen Komponenten repliziert und synchronisiert werden sollen.
Mit Azure verfügen wir über eine integrierte Funktion zum übergreifenden Replizieren von Speicher in mehreren Regionen und Zonen in der Cloud. Für Azure Stack Hub gibt es derzeit keine native Möglichkeit zum Replizieren von Speicher auf zwei unterschiedlichen Azure Stack Hub-Instanzen. Diese Instanzen stellen zwei unabhängige Clouds ohne allgemeine Option für die gemeinsame Verwaltung dar. Bei der Auslegung von Anwendungen unter Azure Stack Hub auf Resilienz sollten Sie diese Unabhängigkeit in Ihrem Anwendungsentwurf und für die Bereitstellungen beachten.
In den meisten Fällen ist die Speicherreplikation zur Erzielung einer resilienten und hoch verfügbaren Anwendung, die unter AKS bereitgestellt wird, nicht erforderlich. In Ihrem Anwendungsentwurf sollten Sie die unabhängige Speicherung für jede Azure Stack Hub-Instanz aber berücksichtigen. Falls diese Art von Entwurf für Sie problematisch ist oder die Bereitstellung der Lösung unter Azure Stack Hub verhindert, können Sie Lösungen von Microsoft-Partnern in Anspruch nehmen, mit denen Speicher angefügt werden kann. Das Anfügen von Speicher stellt eine Lösung für die übergreifende Speicherreplikation auf mehreren Azure Stack Hub-Instanzen und in Azure dar. Weitere Informationen finden Sie im Abschnitt zu den Partnerlösungen.
Für unsere Architektur wurden die folgenden Ebenen berücksichtigt:
Configuration
Umfasst die Konfiguration von Azure Stack Hub, der AKS-Engine und des eigentlichen Kubernetes-Clusters. Die Konfiguration sollte so weit wie möglich automatisiert und im Infrastructure-as-Code-Format in einem Git-basierten Versionskontrollsystem wie Azure DevOps oder GitHub gespeichert werden. Diese Einstellungen können nicht ohne größeren Aufwand für mehrere Bereitstellungen synchronisiert werden. Daher empfehlen wir Ihnen, die Konfiguration extern zu speichern und anzuwenden und eine DevOps-Pipeline zu nutzen.
Anwendung
Die Anwendung sollte in einem Git-basierten Repository gespeichert werden. Bei einer neuen Bereitstellung, bei Änderungen der Anwendung oder bei einer Notfallwiederherstellung kann die Bereitstellung mit Azure Pipelines dann leicht durchgeführt werden.
Daten
Daten sind bei den meisten Anwendungsentwürfen der wichtigste Aspekt. Anwendungsdaten müssen zwischen den verschiedenen Instanzen der Anwendung immer synchron gehalten werden. Darüber hinaus ist für Daten auch eine Strategie für die Sicherung und die Notfallwiederherstellung erforderlich, falls es zu einem Ausfall kommt.
Die Umsetzung dieses Entwurfs hängt stark von der gewählten Technologie ab. Hier sind einige Lösungsbeispiele für die Implementierung einer Datenbank mit Hochverfügbarkeit unter Azure Stack Hub angegeben:
- Bereitstellen einer SQL Server 2016-Verfügbarkeitsgruppe in Azure und Azure Stack Hub
- Bereitstellen einer MongoDB-Hochverfügbarkeitslösung in Azure und Azure Stack Hub
Die Überlegungen bei der übergreifenden Nutzung von Daten an mehreren Standorten sind noch umfangreicher, wenn eine hoch verfügbare und resiliente Lösung erzielt werden soll. Zu berücksichtigen:
- Latenz und Netzwerkkonnektivität zwischen Azure Stack Hub-Instanzen.
- Verfügbarkeit von Identitäten für Dienste und Berechtigungen. Jede Azure Stack Hub-Instanz wird in ein externes Verzeichnis integriert. Während der Bereitstellung entscheiden Sie sich entweder für die Verwendung von Azure Active Directory (Azure AD) oder Active Directory-Verbunddienste (AD FS). Daher besteht die Möglichkeit, nur eine Identität zu verwenden, die mit mehreren unabhängigen Azure Stack Hub-Instanzen interagieren kann.
Business Continuity & Disaster Recovery
Der Bereich „Business Continuity & Disaster Recovery“ (BCDR), also Geschäftskontinuität und Notfallwiederherstellung, ist sowohl für Azure Stack Hub als auch für Azure ein wichtiges Thema. Der Hauptunterschied besteht darin, dass bei Azure Stack Hub der gesamte BCDR-Prozess vom Operator verwaltet werden muss. In Azure werden Teile von BCDR automatisch von Microsoft verwaltet.
BCDR wirkt sich auf dieselben Bereiche aus, die im vorherigen Abschnitt Überlegungen zu Daten und Speicher beschrieben wurden:
- Infrastruktur/Konfiguration
- Anwendungsverfügbarkeit
- Anwendungsdaten
Wie bereits im vorherigen Abschnitt erwähnt, ist der Azure Stack Hub-Operator für diese Bereiche verantwortlich, und die Einzelheiten können von Organisation zu Organisation variieren. Führen Sie die Planung für BCDR gemäß Ihren verfügbaren Tools und Prozessen durch.
Infrastruktur und Konfiguration
In diesem Abschnitt werden die physische und logische Infrastruktur und die Konfiguration von Azure Stack Hub beschrieben. Es geht um Aktionen für Administratoren und Mandanten.
Der Operator (oder Administrator) von Azure Stack Hub ist für die Wartung der Azure Stack Hub-Instanzen verantwortlich. Beispiele hierfür sind Komponenten wie Netzwerk, Speicher, Identität und andere Bereiche, deren Erläuterung den Umfang dieses Artikels sprengen würde. Weitere Informationen zu den Besonderheiten von Azure Stack Hub-Vorgängen finden Sie in den folgenden Ressourcen:
- Datenwiederherstellung in Azure Stack Hub mit dem Infrastructure Backup-Dienst
- Aktivieren der Sicherung für Azure Stack Hub über das Administratorportal
- Wiederherstellen nach schwerwiegendem Datenverlust
- Bewährte Methoden für den Infrastructure Backup-Dienst
Azure Stack Hub ist die Plattform und das Fabric für die Bereitstellung von Kubernetes-Anwendungen. Der Anwendungsbesitzer für die Kubernetes-Anwendung ist ein Benutzer von Azure Stack Hub mit der Zugriffsberechtigung, die zum Bereitstellen der erforderlichen Anwendungsinfrastruktur für die Lösung erforderlich ist. Die Anwendungsinfrastruktur umfasst in diesem Fall den Kubernetes-Cluster, der per AKS-Engine bereitgestellt wurde, und die zugehörigen Dienste. Diese Komponenten werden in Azure Stack Hub bereitgestellt und unterliegen den Beschränkungen des jeweiligen Azure Stack Hub-Angebots. Stellen Sie sicher, dass das vom Besitzer der Kubernetes-Anwendung akzeptierte Angebot mit ausreichend Kapazität (in Form von Azure Stack Hub-Kontingenten) für die Bereitstellung der gesamten Lösung verbunden ist. Wie im vorherigen Abschnitt empfohlen, sollte die Anwendungsbereitstellung automatisiert werden, indem Infrastructure-as-Code und Bereitstellungspipelines wie Azure DevOps mit Azure Pipelines genutzt werden.
Weitere Informationen zu Azure Stack Hub-Angeboten und -Kontingenten finden Sie unter Übersicht: Azure Stack Hub-Dienste, -Pläne, -Angebote und Abonnements.
Es ist wichtig, die Konfiguration der AKS-Engine, einschließlich der Ausgaben, sicher zu speichern und aufzubewahren. Da diese Dateien vertrauliche Informationen für den Zugriff auf den Kubernetes-Cluster enthalten, müssen sie vor der Offenlegung für unbefugte Benutzer geschützt werden.
Anwendungsverfügbarkeit
Die Anwendung sollte nicht auf Sicherungen einer bereitgestellten Instanz basieren. Gehen Sie standardmäßig so vor, dass Sie die Anwendung anhand von Infrastructure-as-Code-Mustern vollständig neu bereitstellen. Verwenden Sie für die erneute Bereitstellung beispielsweise Azure DevOps mit Azure Pipelines. Das BCDR-Verfahren sollte die erneute Bereitstellung der Anwendung in demselben oder einem anderen Kubernetes-Cluster beinhalten.
Anwendungsdaten
Anwendungsdaten sind von entscheidender Bedeutung, wenn es um die Eindämmung von Datenverlusten geht. Im vorherigen Abschnitt wurden Verfahren zum Replizieren und Synchronisieren von Daten zwischen zwei (oder mehr) Instanzen der Anwendung beschrieben. Je nach Datenbankinfrastruktur (MySQL, MongoDB, MSSQL oder andere), die zum Speichern der Daten verwendet wird, können Sie zwischen verschiedenen Verfahren zur Sicherstellung der Verfügbarkeit und Sicherung von Datenbanken wählen.
Zur Erzielung von Integrität wird eine der beiden folgenden Vorgehensweisen empfohlen:
- Eine native Sicherungslösung für die jeweilige Datenbank
- Eine Sicherungslösung, von der die Sicherung und Wiederherstellung der Datenbanken, die von Ihrer Anwendung genutzt werden, offiziell unterstützt wird
Wichtig
Speichern Sie Ihre Sicherungsdaten nicht auf derselben Azure Stack Hub-Instanz, auf der sich Ihre Anwendungsdaten befinden. Bei einem vollständigen Ausfall der Azure Stack Hub-Instanz würde dies nämlich auch zu einer Kompromittierung Ihrer Sicherungen führen.
Überlegungen zur Verfügbarkeit
Bei Kubernetes unter Azure Stack Hub mit Bereitstellung über die AKS-Engine handelt es sich nicht um einen verwalteten Dienst. Es handelt sich um eine automatisierte Bereitstellung und Konfiguration eines Kubernetes-Clusters per Azure IaaS (Infrastructure-as-a-Service). Daher wird die gleiche Verfügbarkeit wie für die zugrunde liegende Infrastruktur erzielt.
Die Azure Stack Hub-Infrastruktur ist bereits fehlerresistent und verfügt über Funktionen wie Verfügbarkeitsgruppen, um Komponenten auf mehrere Fehler- und Updatedomänen verteilen zu können. Für die zugrunde liegende Technologie (Failoverclustering) kommt es für die VMs auf einem betroffenen physischen Server aber trotzdem noch zu Downtime, falls ein Hardwarefehler auftritt.
Eine bewährte Methode besteht darin, Ihren Kubernetes-Produktionscluster und die Workload in zwei (oder mehr) Clustern bereitzustellen. Diese Cluster sollten an verschiedenen Orten oder in verschiedenen Rechenzentren gehostet werden, und es sollten Lösungen wie Azure Traffic Manager eingesetzt werden, um Benutzer basierend auf der Antwortzeit des Clusters oder auf dem Standort weiterzuleiten.

Kunden, die nur einen Kubernetes-Cluster besitzen, stellen in der Regel eine Verbindung mit der Dienst-IP-Adresse oder dem DNS-Namen einer bestimmten Anwendung her. In einer Bereitstellung mit mehreren Clustern sollten Kunden eine Verbindung mit dem DNS-Namen der Traffic Manager-Instanz herstellen, die auf die Dienste bzw. den eingehenden Datenverkehr in den einzelnen Kubernetes-Clustern verweist.

Hinweis
Dieses Muster ist auch eine bewährte Methode für (verwaltete) AKS-Cluster in Azure.
Der Kubernetes-Cluster selbst, der über die AKS-Engine bereitgestellt wird, sollte mindestens aus drei Masterknoten und zwei Workerknoten bestehen.
Überlegungen zu Identität und Sicherheit
Die Identität und die Sicherheit sind wichtige Themen. Dies gilt vor allem, wenn die Lösung unabhängige Azure Stack Hub-Instanzen umfasst. Sowohl Kubernetes als auch Azure (einschließlich Azure Stack Hub) verfügt über eigene Mechanismen für die rollenbasierte Zugriffssteuerung (RBAC):
- Mit der rollenbasierten Zugriffssteuerung von Azure wird der Zugriff auf Ressourcen in Azure (und Azure Stack Hub) gesteuert, z. B. auch die Möglichkeit zum Erstellen neuer Azure-Ressourcen. Berechtigungen können Benutzern, Gruppen oder Dienstprinzipalen zugewiesen werden. (Ein Dienstprinzipal ist eine Sicherheitsidentität, die von Anwendungen verwendet wird.)
- Mit der rollenbasierten Zugriffssteuerung von Kubernetes werden die Berechtigungen für die Kubernetes-API gesteuert. Beispielsweise sind das Erstellen und Auflisten von Pods Aktionen, die per RBAC für einen Benutzer autorisiert (oder abgelehnt) werden können. Zum Zuweisen von Kubernetes-Berechtigungen zu Benutzern erstellen Sie Rollen und Rollenbindungen.
Azure Stack Hub-Identität und RBAC
Für Azure Stack Hub können zwei Identitätsanbieter ausgewählt werden. Die Auswahl des Anbieters hängt davon ab, welche Umgebung Sie verwenden und ob die Ausführung in einer verbundenen oder nicht verbundenen Umgebung erfolgt:
- Azure AD: Kann nur in einer verbundenen Umgebung verwendet werden.
- ADFS für herkömmliche Active Directory-Gesamtstruktur: Kann sowohl in einer verbundenen als auch in einer nicht verbundenen Umgebung genutzt werden.
Der Identitätsanbieter verwaltet Benutzer und Gruppen, einschließlich der Authentifizierung und Autorisierung für den Zugriff auf Ressourcen. Es kann der Zugriff auf Azure Stack Hub-Ressourcen, z. B. Abonnements, Ressourcengruppen und einzelne Ressourcen wie VMs oder Lastenausgleichsmodule gewährt werden. Um ein einheitliches Zugriffsmodell zu erhalten, sollten Sie erwägen, die gleichen Gruppen (entweder direkt oder geschachtelt) für alle Azure Stack Hub-Instanzen zu nutzen. Hier ist ein Konfigurationsbeispiel angegeben:

Das Beispiel enthält eine dedizierte Gruppe (mit AAD oder ADFS) für einen bestimmten Zweck. Ein Beispiel hierfür ist das Bereitstellen von Berechtigungen vom Typ „Mitwirkender“ für die Ressourcengruppe, die unsere Infrastruktur für Kubernetes-Cluster auf einer bestimmten Azure Stack Hub-Instanz (hier „Seattle K8s Cluster Contributor“) enthält. Diese Gruppen werden dann in einer übergeordneten Gruppe geschachtelt, in der die „Untergruppen“ für die einzelnen Azure Stack Hub-Instanzen enthalten sind.
Unser Beispielbenutzer verfügt jetzt über Berechtigungen vom Typ „Mitwirkender“ für beide Ressourcengruppen mit allen Ressourcen der Kubernetes-Infrastruktur. Der Benutzer hat Zugriff auf Ressourcen auf beiden Azure Stack Hub-Instanzen, da für die Instanzen derselbe Identitätsanbieter verwendet wird.
Wichtig
Diese Berechtigungen betreffen nur Azure Stack Hub und einige der zugehörigen bereitgestellten Ressourcen. Ein Benutzer mit diesen Zugriffsberechtigungen kann viel Schaden anrichten, aber er hat keinen Zugriff auf die Kubernetes-IaaS-VMs oder die Kubernetes-API, ohne dass ihm zusätzliche Zugriffsberechtigungen für die Kubernetes-Bereitstellung gewährt werden.
Kubernetes-Identität und RBAC
Für einen Kubernetes-Cluster wird standardmäßig nicht derselbe Identitätsanbieter wie für die zugrunde liegende Azure Stack Hub-Instanz verwendet. Für die VMs, auf denen der Kubernetes-Cluster und die Master- und Workerknoten gehostet werden, wird der SSH-Schlüssel genutzt, der während der Bereitstellung des Clusters angegeben wird. Dieser SSH-Schlüssel wird benötigt, um per SSH eine Verbindung mit diesen Knoten herzustellen.
Die Kubernetes-API (z. B. beim Zugriff mit kubectl) ist auch durch Dienstkonten geschützt, z. B. ein Standarddienstkonto vom Typ „Clusteradministrator“. Die Anmeldeinformationen für dieses Dienstkonto werden anfänglich in der .kube/config-Datei auf Ihren Kubernetes-Masterknoten gespeichert.
Geheimnisverwaltung und Anwendungsanmeldeinformationen
Beim Speichern von Geheimnissen, z. B. Verbindungszeichenfolgen oder Datenbankanmeldeinformationen, haben Sie mehrere Optionen:
- Azure-Schlüsseltresor
- Kubernetes-Geheimnisse
- Drittanbieterlösungen, z. B. HashiCorp Vault (unter Kubernetes)
Achten Sie darauf, dass Sie Geheimnisse oder Anmeldeinformationen nicht als Klartext in Ihren Konfigurationsdateien, im Anwendungscode oder in Skripts speichern. Speichern Sie diese Daten auch nicht in einem Versionskontrollsystem. Stattdessen sollten die Geheimnisse bei Bedarf über die Bereitstellungsautomatisierung abgerufen werden.
Patch und Update
Der Prozess Patch und Update (PNU) in Azure Kubernetes Service ist teilweise automatisiert. Upgrades der Kubernetes-Version werden manuell ausgelöst, während Sicherheitsupdates automatisch angewendet werden. Diese Updates können Sicherheitsfixes oder Kernelupdates für das Betriebssystem enthalten. AKS startet diese Linux-Knoten nicht automatisch neu, um das Update abzuschließen.
Der PNU-Prozess für einen Kubernetes-Cluster, der per AKS-Engine unter Azure Stack Hub bereitgestellt wird, wird nicht verwaltet, sodass die Verantwortung dafür beim Operator des Clusters liegt.
Die AKS-Engine dient als Unterstützung bei den beiden wichtigsten Aufgaben:
- Upgrade auf eine neuere Version von Kubernetes und des Betriebssystem-Basisimages
- Alleiniges Upgrade des Betriebssystem-Basisimages
Neuere Betriebssystem-Basisimages enthalten die aktuellen Sicherheitsfixes und Kernelupdates für das Betriebssystem.
Mit dem Mechanismus Unattended Upgrade (Unbeaufsichtigtes Upgrade) werden automatisch Sicherheitsupdates installiert, die veröffentlicht werden, bevor auf dem Azure Stack Hub Marketplace eine neue Version des Betriebssystem-Basisimages verfügbar ist. Das unbeaufsichtigte Upgrade ist standardmäßig aktiviert, und die Sicherheitsupdates werden automatisch installiert, aber die Kubernetes-Clusterknoten werden nicht neu gestartet. Das Neustarten der Knoten kann automatisiert werden, indem der Open-Source-Daemon KUbernetes REboot Daemon (kured)) verwendet wird. Bei kured wird auf Linux-Knoten geachtet, für die ein Neustart erforderlich ist, und anschließend werden automatisch die erneute Planung der Podausführung und der Prozess für den Knotenneustart durchgeführt.
Bereitstellungsaspekte (CI/CD)
Für Azure und Azure Stack Hub werden die gleichen Azure Resource Manager-REST-APIs verfügbar gemacht. Diese APIs werden genauso wie andere Azure-Clouds (Azure, Azure China 21Vianet, Azure Government) kontaktiert. Zwischen Clouds können Unterschiede bei den API-Versionen bestehen, und von Azure Stack Hub wird nur ein Teil der Dienste bereitgestellt. Auch der URI der Verwaltungsendpunkte variiert von Cloud zu Cloud und für die einzelnen Azure Stack Hub-Instanzen.
Abgesehen von diesen geringfügigen Unterschieden stellen Azure Resource Manager-REST-APIs eine einheitliche Möglichkeit zur Interaktion mit Azure und Azure Stack Hub dar. Hierfür können die gleichen Tools wie für andere Azure-Clouds genutzt werden. Sie können Azure DevOps, ein Tool wie Jenkins oder PowerShell verwenden, um Dienste für Azure Stack Hub bereitzustellen und zu orchestrieren.
Überlegungen
Eines der wichtigsten Merkmale von Azure Stack Hub-Bereitstellungen ist die Zugänglichkeit über das Internet. Die Zugänglichkeit über das Internet bestimmt, ob für Ihre CI/CD-Aufträge ein von Microsoft gehosteter oder ein selbstgehosteter Build-Agent gewählt werden muss.
Ein selbstgehosteter Agent kann zusätzlich zu Azure Stack Hub (als IaaS-VM) oder in einem Subnetz des Netzwerks mit Zugriff auf Azure Stack Hub ausgeführt werden. Weitere Informationen zu den Unterschieden finden Sie unter Azure Pipelines-Agents.
Die folgende Abbildung dient als Hilfe beim Treffen der Entscheidung, ob Sie einen selbstgehosteten oder einen von Microsoft gehosteten Build-Agent benötigen:

- Sind die Azure Stack Hub-Verwaltungsendpunkte über das Internet zugänglich?
- Ja: Wir können Azure Pipelines mit von Microsoft gehosteten Agents verwenden, um eine Verbindung mit Azure Stack Hub herzustellen.
- Nein: Wir benötigen selbstgehostete Agents, die eine Verbindung mit den Verwaltungsendpunkten von Azure Stack Hub herstellen können.
- Ist unser Kubernetes-Cluster über das Internet zugänglich?
- Ja: Wir können Azure Pipelines mit von Microsoft gehosteten Agents verwenden, um direkt mit dem Kubernetes-API-Endpunkt zu interagieren.
- Nein: Wir benötigen selbstgehostete Agents, die eine Verbindung mit dem API-Endpunkt des Kubernetes-Clusters herstellen können.
In Szenarien, in denen die Azure Stack Hub-Verwaltungsendpunkte und die Kubernetes-API über das Internet zugänglich sind, kann für die Bereitstellung ein von Microsoft gehosteter Agent genutzt werden. Diese Bereitstellung führt zur folgenden Anwendungsarchitektur:

Falls die Azure Resource Manager-Endpunkte, die Kubernetes-API oder beide Komponenten nicht direkt über das Internet zugänglich sind, können wir einen selbstgehosteten Build-Agent nutzen, um die Pipelineschritte auszuführen. Bei diesem Entwurf sind die Konnektivitätsanforderungen geringer, und es ist eine Bereitstellung nur mit einer lokalen Netzwerkverbindung mit Azure Resource Manager-Endpunkten und der Kubernetes-API möglich:

Hinweis
Wie sieht es bei Szenarien ohne Verbindung aus? In Szenarien, in denen Azure Stack Hub, Kubernetes oder beide Systeme nicht über per Internet zugängliche Verwaltungsendpunkte verfügen, können Sie trotzdem Azure DevOps für Ihre Bereitstellungen verwenden. Sie können entweder einen selbstgehosteten Agent-Pool (lokal oder unter Azure Stack Hub ausgeführter DevOps-Agent) oder eine vollständig selbstgehostete Azure DevOps Server-Instanz lokal verwenden. Der selbstgehostete Agent benötigt nur eine HTTPS-Internetverbindung (TCP/443) in ausgehender Richtung.
Bei diesem Muster kann ein Kubernetes-Cluster (Bereitstellung und Orchestrierung per AKS-Engine) auf jeder Azure Stack Hub-Instanz verwendet werden. Dies umfasst eine Anwendung mit einem Front-End, einer Mid-Tier-Komponente, Back-End-Diensten (z. B. MongoDB) und einem NGINX-basierten Eingangsdatencontroller. Anstatt eine Datenbank zu verwenden, die im K8s-Cluster gehostet wird, können Sie „externe Datenspeicher“ nutzen. Beispiele für Datenbankoptionen sind MySQL, SQL Server und alle Arten von Datenbanken, die außerhalb von Azure Stack Hub oder per IaaS gehostet werden. Diese Konfigurationen können hier aber nicht ausführlicher beschrieben werden.
Partnerlösungen
Es sind Lösungen von Microsoft-Partnern erhältlich, mit denen die Funktionen von Azure Stack Hub erweitert werden können. Diese Lösungen haben sich in Bereitstellungen von Anwendungen, die in Kubernetes-Clustern ausgeführt werden, als nützlich erwiesen.
Speicher- und Datenlösungen
Wie unter Überlegungen zu Daten und Speicher beschrieben, ist für Azure Stack Hub derzeit keine native Lösung zum übergreifenden Replizieren von Speicher für mehrere Instanzen verfügbar. Im Gegensatz zu Azure ist die Funktion zum Replizieren von Speicher in mehreren Regionen nicht vorhanden. In Azure Stack Hub stellt jede Instanz eine eigene Cloud dar. Es gibt aber Lösungen von Microsoft-Partnern, mit denen die übergreifende Speicherreplikation für Azure Stack Hub-Instanzen und Azure ermöglicht wird.
SCALITY
Scality stellt schon seit 2009 Webspeicher für die digitalen Anforderungen von Unternehmen zur Verfügung. Mit dem softwaredefinierten Speicher „Scality RING“ werden handelsübliche x86-Server zu einem unbegrenzten Petabyte-Speicherpool für alle Arten von Daten (Dateien oder Objekte).
CLOUDIAN
Cloudian erleichtert Unternehmen die Erfüllung von Speicheranforderungen durch die Bereitstellung von unbegrenztem skalierbarem Speicher, mit dem sehr große Datasets zur Vereinfachung der Verwaltung in einer zentralen Umgebung zusammengefasst werden können.
Nächste Schritte
Weitere Informationen zu den in diesem Artikel behandelten Konzepten:
- Cloudübergreifende Skalierung und Muster für geografisch verteilte Apps in Azure Stack Hub
- Microservicearchitektur in Azure Kubernetes Service (AKS)
Wenn Sie zum Testen des Lösungsbeispiels bereit sind, können Sie mit dem Artikel Bereitstellen eines Kubernetes-Hochverfügbarkeitsclusters in Azure Stack Hub fortfahren. In diesem Bereitstellungsleitfaden finden Sie detaillierte Anweisungen zum Bereitstellen und Testen der zugehörigen Komponenten.