Übersicht über Hochverfügbarkeit und Notfallwiederherstellung für Azure Kubernetes Service (AKS)
Beim Erstellen und Verwalten von Anwendungen in der Cloud besteht immer das Risiko von Unterbrechungen durch Ausfälle und Katastrophen. Um Geschäftskontinuität (Business Continuity, BC) sicherzustellen, müssen Sie bei Ihrer Planung Hochverfügbarkeit (High Availability, HA) und Notfallwiederherstellung (Disaster Recovery, DR) berücksichtigen.
Hochverfügbarkeit bezieht sich auf den Entwurf und die Implementierung eines Systems oder Diensts, das bzw. der sehr zuverlässig und mit minimalen Ausfallzeiten arbeitet. Hochverfügbarkeit ist eine Kombination aus Tools, Technologien und Prozessen, die sicherstellen, dass ein System oder Dienst für die Durchführung der beabsichtigten Funktion verfügbar ist. Hochverfügbarkeit ist ein wichtiger Bestandteil der Planung für die Notfallwiederherstellung. Die Notfallwiederherstellung ist der Prozess der Wiederherstellung nach einem Notfall, um Geschäftsvorgänge wieder in einen normalen Zustand zu versetzen. Die Notfallwiederherstellung ist ein Aspekt der Geschäftskontinuität (Business Continuity, BC), also dem Prozess der Aufrechterhaltung von Geschäftsfunktionen, durch den diese im Fall einer großen Unterbrechung schnell fortgesetzt werden können.
In diesem Artikel werden einige empfohlene Methoden für Anwendungen behandelt, die für AKS bereitgestellt werden. Er stellt aber keine vollständige Liste möglicher Lösungen dar.
Technologieübersicht
Ein Kubernetes-Cluster ist in zwei Komponenten unterteilt:
- Die Steuerungsebene stellt die grundlegenden Kubernetes-Dienste und Orchestrierungsfunktionen für Anwendungsworkloads und
- Knoten bereit, die Ihre Anwendungsworkloads ausführen.
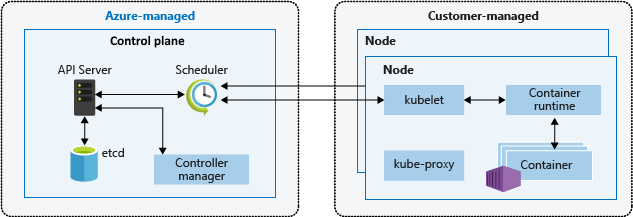
Wenn Sie einen AKS-Cluster erstellen, erstellt und konfiguriert die Azure-Plattform automatisch eine Steuerungsebene. AKS bietet zwei Tarife für die Clusterverwaltung: den Free-Tarif und den Standard-Tarif. Weitere Informationen finden Sie unter Tarife „Free“ und „Standard“ von für die AKS-Clusterverwaltung.
Die Steuerungsebene und ihre Ressourcen befinden sich ausschließlich in der Region, in der Sie den Cluster erstellt haben. AKS stellt eine Steuerungsebene mit Einzelmandant, einem dedizierten API-Server, einem Scheduler usw. bereit. Sie definieren die Anzahl und Größe der Knoten, und die Azure-Plattform konfiguriert die sichere Kommunikation zwischen Steuerungsebene und Knoten. Die Interaktion mit der Steuerungsebene erfolgt über Kubernetes-APIs, z.B. kubectl, oder das Kubernetes-Dashboard.
Zum Ausführen Ihrer Anwendungen und der unterstützenden Dienste benötigen Sie einen Kubernetes-Knoten. Ein AKS-Cluster besteht aus mindestens einem Knoten, bei dem es sich um einen virtuellen Azure-Computer (Azure-VM) handelt, der die Kubernetes-Knotenkomponenten und die Containerruntime ausführt. Die Größe der Azure-VMs für Ihre Knoten definiert die CPUs, den Arbeitsspeicher, die Größe und den Typ des verfügbaren Speichers (z. B. hochleistungsfähige SSDs oder reguläre HDDs). Planen Sie die VM- und Speichergröße danach, ob Ihre Anwendungen möglicherweise große Mengen an CPUs und Arbeitsspeicher oder Hochleistungsspeicher erfordern. In AKS basiert das VM-Image für die Knoten in Ihrem Cluster auf Ubuntu Linux, Azure Linux oder Windows Server 2022. Wenn Sie einen AKS-Cluster erstellen oder die Anzahl von Knoten aufskalieren, erstellt und konfiguriert die Azure-Plattform automatisch die angeforderte Anzahl von VMs.
Weitere Informationen zu Cluster- und Workloadkomponenten in AKS finden Sie unter Kernkonzepte von Kubernetes für AKS.
Wichtige Hinweise
Regionale und globale Ressourcen
Regionale Ressourcen werden als Teil eines Bereitstellungsstempels in einer einzelnen Azure-Region bereitgestellt. Diese Ressourcen teilen nichts mit Ressourcen in anderen Regionen, und sie können unabhängig entfernt oder in andere Regionen repliziert werden. Weitere Informationen finden Sie unter Regionale Ressourcen.
Globale Ressourcen teilen die Lebensdauer des Systems und können global im Kontext einer Bereitstellung mit mehreren Regionen verfügbar sein. Weitere Informationen finden Sie unter der Globale Ressourcen.
Ziele der Wiederherstellung
Ein vollständiger Notfallwiederherstellungsplan muss Geschäftsanforderungen für jeden Prozess angeben, den die Anwendung implementiert:
- Recovery Point Objective (RPO): die maximale Dauer des akzeptablen Datenverlusts. Das RPO (Recovery Point Objective) wird in Zeiteinheiten gemessen, z. B. Minuten, Stunden oder Tagen.
- Das RTO (Recovery Time Objective) ist die maximal akzeptable Dauer für Ausfälle, wobei diese Downtime durch Ihre Spezifikation definiert wird. Wenn beispielsweise die zulässige Downtime bei einer Katastrophe acht Stunden ist, beträgt die RTO acht Stunden.
Verfügbarkeitszonen
Sie können Verfügbarkeitszonen verwenden, um Ihre Daten über mehrere Zonen in derselben Region zu verteilen. Innerhalb einer Region sind Verfügbarkeitszonen nahe genug, um Verbindungen mit geringer Latenz mit anderen Verfügbarkeitszonen zu haben. Sie sind aber weit genug auseinander, um die Wahrscheinlichkeit zu verringern, dass mehrere von lokalen Ausfällen oder Wetterphänomenen betroffen ist. Weitere Informationen finden Sie unter Empfehlungen für die Verwendung von Verfügbarkeitszonen und Regionen.
Zonale Resilienz
AKS-Cluster sind resilient gegenüber zonalen Ausfällen. Wenn eine Zone ausfällt, wird der Cluster weiterhin in den verbleibenden Zonen ausgeführt. Die Steuerungsebene und die Knoten des Clusters werden über die Zonen verteilt, und die Azure-Plattform verarbeitet automatisch die Verteilung der Knoten. Weitere Informationen finden Sie unter Zonale Resilienz in AKS.
Lastenausgleich
Globaler Lastenausgleich
Globale Lastenausgleichsdienste verteilen den Datenverkehr auf regionale Back-Ends, Clouds oder hybride lokale Dienste. Diese Dienste leiten den Endbenutzer-Datenverkehr an das nächstgelegene verfügbare Back-End weiter. Außerdem reagieren sie auf Änderungen von Zuverlässigkeit oder Leistung des Diensts, um Verfügbarkeit und Leistung zu maximieren. Die folgenden Azure-Dienste bieten einen globalen Lastenausgleich:
- Azure Front Door
- Azure Traffic Manager
- Regionsübergreifender Azure Load Balancer
- Azure Kubernetes Fleet Manager
Regionaler Lastenausgleich
Regionale Lastenausgleichsdienste verteilen Datenverkehr in virtuellen Netzwerken auf VMs oder zonale und zonenredundante Dienstendpunkte innerhalb einer Region. Die folgenden Azure-Dienste bieten einen regionalen Lastenausgleich:
Einblick
Sie müssen Daten von Anwendungen und der Infrastruktur sammeln, um effektive Vorgänge zu ermöglichen und die Zuverlässigkeit zu maximieren. Azure bietet Tools, mit denen Sie Ihre AKS-Workloads überwachen und verwalten können. Weitere Informationen finden Sie unter Beobachtungsressourcen.
Bereichsdefinition
Die Anwendungsverfügbarkeit ist beim Verwalten von AKS-Clustern wichtig. Standardmäßig bietet AKS Hochverfügbarkeit, indem mehrere Knoten in einer VM-Skalierungsgruppe verwendet werden, aber diese Knoten schützen Ihr System nicht vor einem Regionsausfall. Um die Uptime zu maximieren, müssen Sie im Voraus planen, um die Geschäftskontinuität aufrechtzuerhalten und eine Notfallwiederherstellung vorzubereiten. Wenden Sie dazu die folgenden bewährten Methoden an:
- Planen für AKS-Cluster in mehreren Regionen.
- Weiterleiten des Datenverkehrs über mehrere Cluster mithilfe von Azure Traffic Manager.
- Verwenden der Georeplikation für Ihre Containerimageregistrierungen.
- Mehrere Cluster übergreifendes Planen für den Anwendungszustand.
- Mehrere Regionen übergreifendes Replizieren des Speichers.
Implementierungen des Bereitstellungsmodells
| Bereitstellungsmodell | Vorteile | Nachteile |
|---|---|---|
| Aktiv/Aktiv | • Keine Datenverluste oder Inkonsistenzen während eines Failovers • Hohe Resilienz • Bessere Nutzung von Ressourcen mit höherer Leistung |
• Komplexe Implementierung und Verwaltung • Höhere Kosten • Erfordert einen Lastenausgleich und eine Form des Datenverkehrsroutings |
| Aktiv/Passiv | • Einfachere Implementierung und Verwaltung • Geringere Kosten • Erfordert keinen Lastenausgleich oder Datenverkehrs-Manager |
• Potenzial für Datenverluste oder Inkonsistenzen während eines Failovers • Längere Wiederherstellungszeit und Downtime • Keine vollständige Nutzung von Ressourcen |
| Passiv-Kalt | • Niedrigste Kosten • Erfordert weder Synchronisierung noch Replikation, Lastenausgleich oder Datenverkehrs-Manager • Geeignet für nicht kritische Workloads mit niedriger Priorität |
• Hohes Risiko von Datenverlust oder Inkonsistenz während eines Failovers • Längste Wiederherstellungszeit und Downtime • Erfordert manuelle Eingriffe zum Aktivieren des Clusters und Auslösen der Sicherung |
Aktiv-Aktiv-Bereitstellungsmodell für Hochverfügbarkeit
Im Aktiv-Aktiv-Bereitstellungsmodell für Hochverfügbarkeit (HA) verwenden Sie zwei unabhängige AKS-Cluster, die in zwei verschiedenen Azure-Regionen (in der Regel gekoppelte Regionen wie „Kanada, Mitte“ und „Kanada, Osten“ oder „USA, Osten 2“ und „USA, Mitte“) bereitgestellt werden und aktiv den Datenverkehr verarbeiten.
Mit dieser Beispielarchitektur:
- Sie stellen zwei AKS-Cluster in separaten Azure-Regionen bereit.
- Im normalen Betrieb wird der Netzwerkdatenverkehr zwischen beiden Regionen weitergeleitet. Wenn eine Region nicht mehr verfügbar ist, wird der Datenverkehr automatisch an die nächstgelegene Region der Benutzer*innen weitergeleitet, die die Anforderung gesendet haben.
- Für jede regionale AKS-Instanz wird ein Hub-Spoke-Paar bereitgestellt. Azure Firewall Manager-Richtlinien verwalten die Firewallregeln in den Regionen.
- Azure Key Vault wird in jeder Region bereitgestellt, um Geheimnisse und Schlüssel zu speichern.
- Azure Front Door verwaltet den Lastenausgleich und leitet den Datenverkehr an eine regionale Instanz von Azure Application Gateway weiter, die sich vor jedem AKS-Cluster befindet.
- Regionale Log Analytics-Instanzen speichern regionale Netzwerkmetriken und Diagnoseprotokolle.
- Die Containerimages für die Workload werden in einer verwalteten Containerregistrierung gespeichert. Für alle Kubernetes-Instanzen im Cluster wird eine einzelne Azure Container Registry-Instanz verwendet. Durch eine Aktivierung der Georeplikation für Azure Container Registry werden Images automatisch in die ausgewählten Azure-Regionen repliziert. So kann auch dann noch auf die Images zugegriffen werden, wenn es in einer Region zu einem Ausfall kommt.
Führen Sie die folgenden Schritte aus, um ein Aktiv-Aktiv-Bereitstellungsmodell in AKS zu erstellen:
Erstellen Sie zwei identische Bereitstellungen in zwei unterschiedlichen Azure-Regionen.
Erstellen Sie zwei Instanzen Ihrer Web-App.
Erstellen Sie ein Azure Front Door-Profil mit den folgenden Ressourcen:
- Ein Endpunkt.
- Zwei Ursprungsgruppen mit jeweils einer Priorität von 1.
- Einer Route.
Beschränken Sie den Netzwerkdatenverkehr aus der Azure Front Door-Instanz nur auf die Web-Apps. 5. Konfigurieren Sie alle anderen Azure-Back-End-Dienste, z. B. Datenbanken, Speicherkonten und Authentifizierungsanbieter.
Stellen Sie Code für beide Web-Apps mit Continuous Deployment bereit.
Weitere Informationen finden Sie in der Übersicht über die empfohlene Aktiv-Aktiv-Lösung mit Hochverfügbarkeit für AKS.
Aktiv-Passiv-Bereitstellungsmodell für die Notfallwiederherstellung
Im Aktiv-Passiv-Bereitstellungsmodell für die Notfallwiederherstellung (DR) verwenden Sie zwei unabhängige AKS-Cluster, die in zwei verschiedenen Azure-Regionen (in der Regel gekoppelte Regionen wie „Kanada, Mitte“ und „Kanada, Osten“ oder „USA, Osten 2“ und „USA, Mitte“) bereitgestellt werden und aktiv den Datenverkehr verarbeiten. Zu jedem Zeitpunkt verarbeitet immer nur einer der Cluster aktiv den Datenverkehr. Der andere Cluster enthält die gleichen Konfigurations- und Anwendungsdaten wie der aktive Cluster, akzeptiert jedoch keinen Datenverkehr, es sei denn, dieser wird von einem Datenverkehrs-Manager weitergeleitet.
Mit dieser Beispielarchitektur:
- Sie stellen zwei AKS-Cluster in separaten Azure-Regionen bereit.
- Im normalen Betrieb wird der Netzwerkdatenverkehr an den primären AKS-Cluster weitergeleitet, den Sie in der Azure Front Door-Konfiguration festlegen.
- Die Priorität muss auf einen Wert zwischen 1 und 5 festgelegt werden, wobei 1 die höchste und 5 die niedrigste Priorität ist.
- Sie können mehrere Cluster auf dieselbe Prioritätsebene festlegen und eine Gewichtung für die einzelnen Cluster angeben.
- Wenn der primäre Cluster nicht verfügbar ist (bei einem Notfall), wird der Datenverkehr automatisch an die nächste Region weitergeleitet, die in Azure Front Door ausgewählt ist.
- Der gesamte Datenverkehr muss den Azure Front Door-Datenverkehrs-Manager durchlaufen, damit dieses System funktioniert.
- Azure Front Door leitet Datenverkehr an die Azure Application Gateway-Instanz in der primären Region weiter (der Cluster muss mit Priorität 1 gekennzeichnet sein). Wenn diese Region ausfällt, leitet der Dienst den Datenverkehr an den nächsten Cluster in der Prioritätsliste um.
- Die Regeln stammen aus Azure Front Door.
- Für jede regionale AKS-Instanz wird ein Hub-Spoke-Paar bereitgestellt. Azure Firewall Manager-Richtlinien verwalten die Firewallregeln in den Regionen.
- Azure Key Vault wird in jeder Region bereitgestellt, um Geheimnisse und Schlüssel zu speichern.
- Regionale Log Analytics-Instanzen speichern regionale Netzwerkmetriken und Diagnoseprotokolle.
- Die Containerimages für die Workload werden in einer verwalteten Containerregistrierung gespeichert. Für alle Kubernetes-Instanzen im Cluster wird eine einzelne Azure Container Registry-Instanz verwendet. Durch eine Aktivierung der Georeplikation für Azure Container Registry werden Images automatisch in die ausgewählten Azure-Regionen repliziert. So kann auch dann noch auf die Images zugegriffen werden, wenn es in einer Region zu einem Ausfall kommt.
Führen Sie die folgenden Schritte aus, um ein Aktiv-Passiv-Bereitstellungsmodell in AKS zu erstellen:
Erstellen Sie zwei identische Bereitstellungen in zwei unterschiedlichen Azure-Regionen.
Konfigurieren Sie Regeln für die automatische Skalierung für die sekundäre Anwendung, damit sie auf die gleiche Instanzanzahl wie die primäre Anwendung skaliert wird, wenn die primäre Region inaktiv wird. Im inaktiven Zustand ist keine Skalierung erforderlich. Dies trägt dazu bei, die Kosten zu senken.
Erstellen Sie zwei Instanzen Ihrer Webanwendung mit einer Instanz in jedem Cluster.
Erstellen Sie ein Azure Front Door-Profil mit den folgenden Ressourcen:
- Ein Endpunkt.
- Einer Ursprungsgruppe mit der Priorität 1 für die primäre Region.
- Einer zweiten Ursprungsgruppe mit einer Priorität von 2 für die sekundäre Region.
- Einer Route.
Beschränken Sie den Netzwerkdatenverkehr an die Webanwendungen auf ausschließlich die Azure Front Door-Instanz.
Konfigurieren Sie alle anderen Azure-Back-End-Dienste, z. B. Datenbanken, Speicherkonten und Authentifizierungsanbieter.
Stellen Sie Code für beide Webanwendungen mit Continuous Deployment bereit.
Weitere Informationen finden Sie in der Übersicht über die empfohlene Aktiv-Passiv-Lösung für die Notfallwiederherstellung für AKS.
Passiv-Kalt-Bereitstellungsmodell mit Failover
Das Passiv-Kalt-Bereitstellungsmodell mit Failover wird auf die gleiche Weise wie das Aktiv-Passiv-Bereitstellungsmodell für die Notfallwiederherstellung konfiguriert, nur dass die Cluster inaktiv bleiben, bis Benutzer*innen sie im Fall eines Notfalls aktivieren. Dieser Ansatz wird hier nicht behandelt, da er eine ähnliche Konfiguration wie der Aktiv-Passiv-Ansatz erfordert, aber mit dem Zusatzaufwand des manuellen Eingriffs, um den Cluster zu aktivieren und eine Sicherung auszulösen.
Mit dieser Beispielarchitektur:
- Sie erstellen zwei AKS-Cluster, vorzugsweise in verschiedenen Regionen oder Zonen, um die Resilienz zu verbessern.
- Wenn Sie ein Failover ausführen müssen, aktivieren Sie die Bereitstellung, um den Datenverkehrsflow zu übernehmen.
- Wenn der primäre passive Cluster ausfällt, müssen Sie den „kalten“ Cluster manuell aktivieren, damit er den Datenverkehrsflow übernimmt.
- Dies muss entweder jedes Mal manuell oder durch ein bestimmtes Ereignisses ausgelöst werden, das von Ihnen angegeben wird.
- Azure Key Vault wird in jeder Region bereitgestellt, um Geheimnisse und Schlüssel zu speichern.
- Regionale Log Analytics-Instanzen speichern regionale Netzwerkmetriken und Diagnoseprotokolle für jeden Cluster.
Führen Sie die folgenden Schritte aus, um ein Passiv-Kalt-Bereitstellungsmodell mit Failover in AKS zu erstellen:
- Erstellen Sie zwei identische Bereitstellungen in unterschiedlichen Zonen/Regionen.
- Konfigurieren Sie Regeln für die automatische Skalierung für die sekundäre Anwendung, damit sie auf die gleiche Instanzanzahl wie die primäre Anwendung skaliert wird, wenn die primäre Region inaktiv wird. Im inaktiven Zustand ist keine Skalierung erforderlich, wodurch die Kosten reduziert werden.
- Erstellen Sie zwei Instanzen Ihrer Webanwendung mit einer Instanz in jedem Cluster.
- Konfigurieren Sie alle anderen Azure-Back-End-Dienste, z. B. Datenbanken, Speicherkonten und Authentifizierungsanbieter.
- Legen Sie eine Bedingung fest, bei der der „kalte“ Cluster ausgelöst werden soll. Sie können bei Bedarf einen Lastenausgleich verwenden.
Weitere Informationen finden Sie in der Übersicht über die empfohlenen Passiv-Kalt-Lösung mit Failover für AKS.
Dienstkontingente und Limits
AKS legt Standardgrenzwerte und -kontingente für Ressourcen und Features fest, einschließlich Nutzungseinschränkungen für bestimmte VM-SKUs.
| Ressource | Begrenzung |
|---|---|
| Maximale Anzahl Cluster pro Abonnement – global | 5,000 |
| Maximale Anzahl Cluster pro Abonnement und Region 1 | 100 |
| Maximale Knoten pro Cluster mit VM-Skalierungsgruppen und der Load Balancer Standard-SKU | 5.000 für alle Knotenpools Hinweis: Wenn Sie nicht bis auf 5.000 Knoten pro Cluster skalieren können, lesen Sie Bewährte Methoden für große Cluster. |
| Maximale Anzahl von Knoten pro Knotenpool (Virtual Machine Scale Sets-Knotenpools) | 1000 |
| Maximale Knotenpools pro Cluster | 100 |
| Maximale Anzahl von Pods pro Knoten: mit dem Netzwerk-Plug-In1 für Kubenet | Maximal: 250 Azure CLI-Standardwert: 110 Standardwert der Azure Resource Manager-Vorlage: 110 Standardwert für Bereitstellung im Azure-Portal: 30 |
| Maximale Anzahl Pods pro Knoten: mit Azure Container Networking Interface (Azure CNI)2 | Maximal: 250 Maximal empfohlene Anzahl für Windows Server-Container: 110 Standardwert: 30 |
| OSM-AKS-Add-On (Open Service Mesh) | Kubernetes-Clusterversion: Von AKS unterstützte Versionen OSM-Controller pro Cluster: 1 Pods pro OSM-Controller: 1.600 Von OSM verwaltete Kubernetes-Dienstkonten: 160 |
| Maximale Anzahl von Kubernetes-Diensten mit Lastenausgleich pro Cluster mit Load Balancer Standard-SKU | 300 |
| Maximale Knoten pro Cluster mit VM-Verfügbarkeitsgruppen und der Load Balancer Basic-SKU | 100 |
1 Mehr sind auf Anfrage möglich.
2 Windows Server-Container müssen das Netzwerk-Plug-In für Azure CNI verwenden. Kubenet wird für Windows Server-Container nicht unterstützt.
| Kubernetes-Steuerungsebene | Begrenzung |
|---|---|
| Standard-Tarif | Skaliert den Kubernetes-API-Server automatisch, basierend auf der Last. Höhere Grenzwerte für Komponenten der Steuerungsebene und API-Server/etcd-Instanzen. |
| Free-Tarif | Begrenzte Ressourcen mit einem Grenzwert von 50 Änderungsaufrufen und 100 schreibgeschützten Aufrufen von In-Flight-Anforderungen. Empfohlener Knotengrenzwert von 10 Knoten pro Cluster. Optimal für das Experimentieren, Lernen und einfache Testen. Nicht für Produktions-/kritische Workloads empfohlen. |
Weitere Informationen finden Sie unter AKS: Dienstkontingente und -grenzwerte.
Backup
Azure Backup unterstützt das Sichern von AKS-Clusterressourcen und persistenten Volumes, die an den Cluster angefügt sind, über eine Sicherungserweiterung. Der Backup-Tresor kommuniziert über diese Erweiterung mit dem AKS-Cluster, um Sicherungs- und Wiederherstellungsvorgänge auszuführen.
Weitere Informationen finden Sie in den folgenden Artikeln:

Azure Kubernetes Service
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für