Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
von Ruslan Yakushev
IIS-Websiteanalyse ist ein Tool im IIS Search Engine Optimization Toolkit, das verwendet werden kann, um Websites für den Zweck zu analysieren, die Inhalte, Struktur und URLs der Website für Suchmaschinencrawler zu optimieren. Darüber hinaus können Sie das Tool verwenden, um übliche Probleme in Websiteinhalten zu ermitteln und zu beheben, die sich negativ auf die Benutzererfahrung der Website auswirken. Das IIS-Websiteanalysetool enthält einen Webcrawler, der alle öffentlich verfügbaren Websitelinks und Ressourcen durchforstet und die Inhalte herunterlädt, die für die Websiteanalyse verwendet werden.
Durchforsten einer Website
Der erste Schritt bei der Analyse einer Website besteht darin, alle Ressourcen und URLs zu durchforsten, die öffentlich von der Website verfügbar gemacht werden. Das ist, was beim Erstellen einer neuen Websiteanalyse durch das IIS-Websiteanalysetool geschieht. Führen Sie die folgenden Schritte aus, um das IIS-Websiteanalysetool eine Website durchforsten und Daten für die Analyse sammeln zu lassen:
Starten Sie das SEO-Tool, indem Sie zu Start > Programme > IIS 7.0 Extensions navigieren und das Search Engine Optimization (SEO) Toolkit-Symbol anklicken.
Wählen Sie im Bereich Verbindungen den Serverknoten aus. Die SEO-Hauptseite wird automatisch geöffnet.
Klicken Sie im Abschnitt Websiteanalyse auf den Aufgabenlink Neue Analyse erstellen.
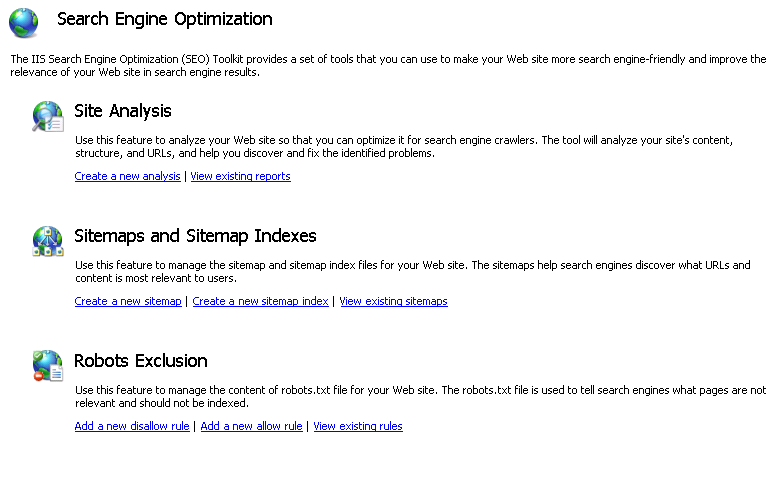
Geben Sie im Dialogfeld Neue Analyse einen Namen ein, der den Analysebericht eindeutig bezeichnet. Geben Sie auch die URL ein, bei welcher der Crawler anfangen soll.
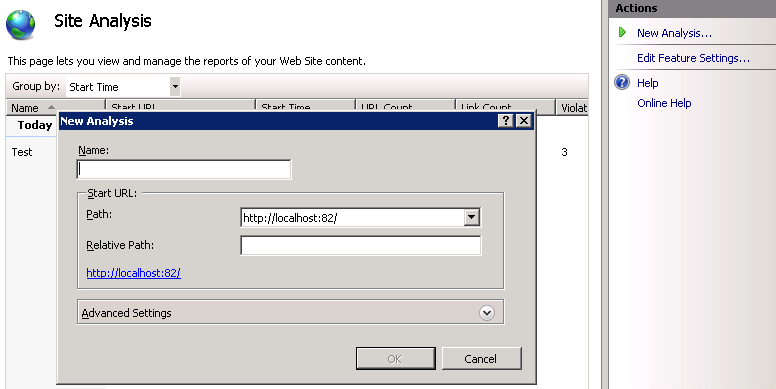
Beachten Sie, dass der Serverknoten im Bereich Verbindungen ausgewählt ist (wir haben keine bestimmte Website auf dem Server ausgewählt). Es ist möglich, jede Website zu durchforsten, auf die öffentlich im Internet zugegriffen werden kann. Weitere Informationen zum Dialogfeld „Neue Analyse“ finden Sie im Abschnitt Webcrawlereinstellungen.Nachdem alle Parameter angegeben wurden, klicken Sie auf OK, um die Analyse zu starten:
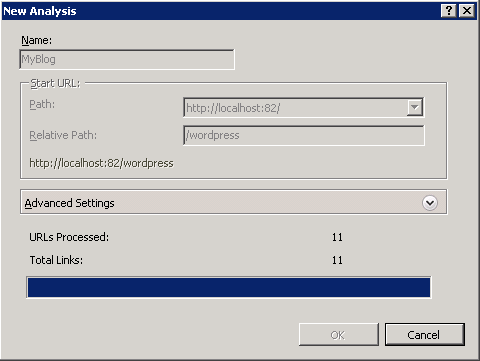
Die beiden während der Analyse gemeldeten Zahlen sind:- Verarbeitete Links – das ist die Gesamtanzahl der Links, die vom Webcrawler durchforstet und heruntergeladen wurden.
- Links insgesamt – das ist die Gesamtanzahl der Links, die beim Durchforsten der Website gefunden wurden.
Hinweis
dass der Webcrawler immer auf einem Clientcomputer ausgeführt wird. Wenn Sie eine Verbindung mit einem Remote-IIS-Server herstellen und eine neue Analyse starten, wird der Webcrawler im IIS-Manager-Prozess (InetMgr.exe) auf dem lokalen Computer gehostet, der mit dem Remote-IIS-Server verbunden ist. Alle gesammelten Daten und zwischengespeicherten Webinhalte werden im lokalen Clientdateisystem gespeichert.
Nachdem die Website durchforstet und analysiert wurde, wird die Zusammenfassungsansicht des Websiteanalyseberichts angezeigt. Weitere Informationen zum Analysieren der Website für SEO und inhaltsspezifische Probleme finden Sie im Artikel „Verwenden der Websiteanalyseberichte“.
Webcrawlereinstellungen
Andere Parameter, die beim Starten einer neuen Analyse angegeben werden können, sind:
- Maximale Linkanzahl – diese Einstellung steuert, wie viele eindeutige Links während einer Durchforstung von einer Website verarbeitet und von einer Website heruntergeladen werden. Ein Link ist eine beliebige URL, die im Markup einer Seite verwendet wird, einschließlich Hyperlinks, Verweise auf Bilddateien, CSS-Dateien und Javascript-Dateien. Wenn Sie diese Zahl erhöhen, wird die Größe der Berichtsdatei erhöht und der Durchforstungsprozess wird länger ausgeführt.
- Maximale Downloadgröße pro Link – Diese Einstellung steuert, wie viele Kilobyte Inhalt pro Link heruntergeladen werden. Wenn Sie diese Zahl erhöhen, wird die Größe des zwischengespeicherten Inhalts erhöht, der von der Websiteanalyse im lokalen Dateisystem gespeichert ist.
- ‚nofollow‘-Attribut ignorieren – Das Attribut ‚nofollow‘ und das Metatag ‚nofollow‘ werden verwendet, um Suchmaschinen-Crawler anzuweisen, bestimmten oder sämtlichen Links auf einer Seite nicht zu folgen. Das dient zum Schutz vor Spam in Blogkommentaren. Wenn Seiten auf Ihrer Website dieses Attribut verwenden, werden die Hyperlinks auf diesen Seiten während der Websiteanalyse nicht verarbeitet oder analysiert. Beachten Sie, dass Links zu Ressourcen wie Bildern, CSS- und Javascript-Dateien weiterhin verarbeitet werden. Wenn es erforderlich ist, sogar die Hyperlinks zu analysieren, die dieses Attribut verwenden, verwenden Sie diese Einstellung, um die Attribute und Metatags ‚nofollow‘ zu ignorieren.
- Metatag ‚noindex' ignorieren – Das Tag ‚noindex‘ wird verwendet, um Suchmaschinencrawlern zu sagen, dass der Inhalt der Seite nicht indiziert werden soll. Wenn Seiten auf Ihrer Website dieses Metatag verwenden, werden die Inhalte dieser Seiten nicht nach Verstößen durchsucht. Wenn es erforderlich ist, auch die Seiten zu analysieren, die dieses Attribut verwenden, verwenden Sie diese Einstellung, um das Metatag ‚noindex‘ zu ignorieren.
- Externe Links – Sie können diese Dropdownliste verwenden, wenn Ihre Website Unterdomänen hat oder wenn Sie eine Analyse für ein bestimmtes Verzeichnis innerhalb einer Website ausführen möchten. Diese Einstellung steuert, ob Unterdomänen und/oder Unterverzeichnisse als externe oder interne Verknüpfungen behandelt werden sollen.
Darüber hinaus können die folgenden generischen Einstellungen für den Webcrawler konfiguriert werden, indem Sie FeatureSettings bearbeiten im Aktionsbereich auswählen:
- Maximale Anzahl gleichzeitiger Anfragen – diese Einstellung steuert, wie viele gleichzeitige Anfragen der Webcrawler vornehmen wird.
- Berichtsverzeichnis – gibt das Verzeichnis im lokalen Dateisystem an, in dem alle durchforsteten Daten und zwischengespeicherten Websiteinhalte gespeichert werden.
Blockieren des IIS-Websiteanalyse-Webcrawlers
Alle HTTP-Anfragen, die vom IIS-Websiteanalyse-Webcrawler vorgenommen werden, haben einen „user-agent“ HTTP-Header, der auf Folgendes eingestellt ist:
"iisbot/1.0 (+http://www.iis.net/iisbot.html)"
Der IIS-Websiteanalyse-Webcrawler ist vollständig mit dem Robots Exclusion Protocol konform. Das bedeutet, dass Sie die Datei „Robots.txt“ verwenden können, um zu verhindern, dass der IIS-Websiteanalyse-Webcrawler Ihre Website durchforsten kann. Möglicherweise möchten Sie es verwenden, um zu verhindern, dass andere Personen IIS-Websiteanalysen für Ihre Websites ausführen.
Um zu verhindern, dass der IIS-Websiteanalyse-Webcrawler eine Website durchforsten kann, fügen Sie am Ende der Datei „Robots.txt“, die sich im Stammverzeichnis der Website befindet, die folgenden Zeilen hinzu:
User-Agent: iisbot
Disallow: /
Zusammenfassung
Sie haben nun erfolgreich das IIS-Websiteanalysetool so konfiguriert, dass eine Website durchforstet und die Daten über den Inhalt und die Struktur der Website gesammelt werden. Informationen zum Analysieren der gesammelten Daten mithilfe von Websiteanalyseberichten finden Sie unter „Verwenden von Websiteanalyseberichten“.