Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Clouddienste und IoT-Geräte generieren Telemetriedaten, die verwendet werden können, um Erkenntnisse wie Überwachung des Dienststatus, physische Produktionsprozesse und Nutzungstrends zu erhalten. Die Durchführung von Zeitreihenanalysen ist eine Möglichkeit, Abweichungen im Muster dieser Metriken im Vergleich zu ihrem typischen Basisplanmuster zu identifizieren.
Kusto Query Language (KQL) enthält native Unterstützung für erstellung, Manipulation und Analyse mehrerer Zeitreihen. In diesem Artikel erfahren Sie, wie KQL verwendet wird, um Tausende von Zeitreihen in Sekunden zu erstellen und zu analysieren, wodurch nahezu Echtzeitüberwachungslösungen und -workflows ermöglicht werden.
Erstellung von Zeitreihen
In diesem Abschnitt erstellen wir einen großen Satz normaler Zeitreihen einfach und intuitiv mithilfe des make-series Operators und füllen bei Bedarf fehlende Werte aus.
Der erste Schritt in der Zeitreihenanalyse besteht darin, die ursprüngliche Telemetrietabelle in eine Reihe von Zeitreihen zu partitionieren und zu transformieren. Die Tabelle enthält in der Regel eine Zeitstempelspalte, kontextbezogene Dimensionen und optionale Metriken. Die Dimensionen werden verwendet, um die Daten zu partitionieren. Ziel ist es, tausende Zeitreihen pro Partition in regelmäßigen Zeitintervallen zu erstellen.
Die Eingabetabelle demo_make_series1 enthält 600K-Datensätze mit beliebigem Webdienstdatenverkehr. Verwenden Sie den folgenden Befehl, um 10 Datensätze auszuwählen:
demo_make_series1 | take 10
Die resultierende Tabelle enthält eine Zeitstempelspalte, drei Kontextdimensionsspalten und keine Metriken:
| Zeitstempel | BrowserVer | OsVer | Land/Region |
|---|---|---|---|
| 2016-08-25 09:12:35.4020000 | Chrome 51.0 | Windows 7 | Vereinigtes Königreich |
| 2016-08-25 09:12:41.1120000 | Chrome 52.0 | Windows 10 | |
| 2016-08-25 09:12:46.2300000 | Chrome 52.0 | Windows 7 | Vereinigtes Königreich |
| 2016-08-25 09:12:46.5100000 | Chrome 52.0 | Windows 10 | Vereinigtes Königreich |
| 2016-08-25 09:12:46.5570000 | Chrome 52.0 | Windows 10 | Republik Litauen |
| 2016-08-25 09:12:47.0470000 | Chrome 52.0 | Windows 8.1 | Indien |
| 2016-08-25 09:12:51.3600000 | Chrome 52.0 | Windows 10 | Vereinigtes Königreich |
| 2016-08-25 09:12:51.6930000 | Chrome 52.0 | Windows 7 | Niederlande |
| 2016-08-25 09:12:56.4240000 | Chrome 52.0 | Windows 10 | Vereinigtes Königreich |
| 2016-08-25 09:13:08.7230000 | Chrome 52.0 | Windows 10 | Indien |
Da es keine Metriken gibt, können wir nur eine Reihe von Zeitreihen erstellen, die die Anzahl des Datenverkehrs selbst darstellt, partitioniert von Betriebssystemen mithilfe der folgenden Abfrage:
let min_t = toscalar(demo_make_series1 | summarize min(TimeStamp));
let max_t = toscalar(demo_make_series1 | summarize max(TimeStamp));
demo_make_series1
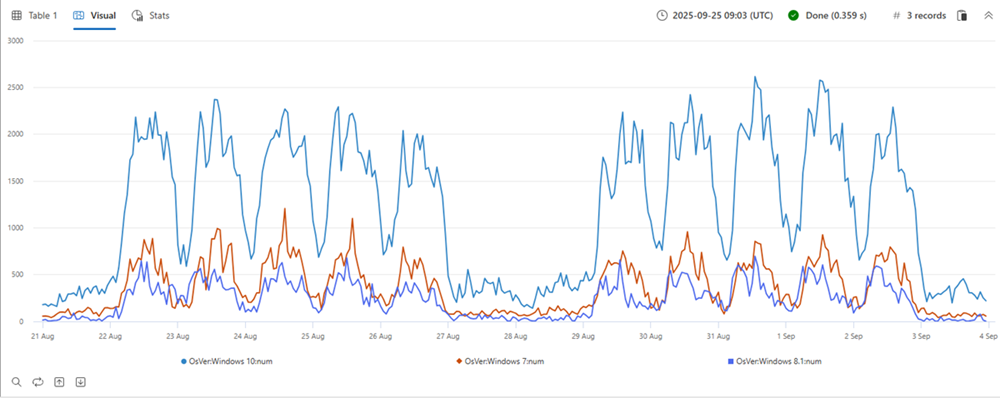
| make-series num=count() default=0 on TimeStamp from min_t to max_t step 1h by OsVer
| render timechart
- Verwenden Sie den
make-seriesOperator, um eine Reihe von drei Zeitreihen zu erstellen, wobei:-
num=count(): Zeitreihe des Datenverkehrs -
from min_t to max_t step 1h: Die Zeitreihe wird im Zeitbereich in Abschnitten von jeweils einer Stunde erstellt (ältester und neuester Zeitstempel der Tabellendatensätze). -
default=0: Geben Sie die Füllmethode für fehlende Container an, um normale Zeitreihen zu erstellen. Alternativ können Sieseries_fill_const(),series_fill_forward(),series_fill_backward()undseries_fill_linear()für Änderungen verwenden. -
by OsVer: Partition nach Betriebssystem
-
- Die tatsächliche Datenstruktur der Zeitreihen ist ein numerisches Array des aggregierten Werts pro Zeitabschnitt. Wir verwenden
render timechartzur Visualisierung.
In der oben stehenden Tabelle sind drei Partitionen enthalten. Wir können eine separate Zeitreihe erstellen: Windows 10 (rot), 7 (blau) und 8.1 (grün) für jede Betriebssystemversion, wie im Diagramm dargestellt:
Analysefunktionen für Zeitreihen
In diesem Abschnitt führen wir typische Datenreihenverarbeitungsfunktionen aus. Sobald eine Reihe von Zeitreihen erstellt wurde, unterstützt KQL eine wachsende Liste von Funktionen, die verarbeitet und analysiert werden sollen. Wir beschreiben einige repräsentative Funktionen für die Verarbeitung und Analyse von Zeitreihen.
Filterung
Das Filtern ist eine gängige Methode bei der Signalverarbeitung und nützlich für Zeitreihenverarbeitungsaufgaben (z. B. glätten Sie ein lautes Signal, Änderungserkennung).
- Es gibt zwei generische Filterfunktionen:
-
series_fir(): Anwenden des FIR-Filters. Wird zur einfachen Berechnung des gleitenden Mittelwerts und der Differenzierung der Zeitreihen zur Änderungserkennung verwendet. -
series_iir(): Anwendung des IIR-Filters. Wird für exponentielle Glättung und kumulative Summenberechnung verwendet.
-
-
Extenddie Zeitreihen, die durch Hinzufügen einer neuen gleitenden Mittelwertreihe von Größe 5 Bins (namens ma_num) zur Abfrage festgelegt werden:
let min_t = toscalar(demo_make_series1 | summarize min(TimeStamp));
let max_t = toscalar(demo_make_series1 | summarize max(TimeStamp));
demo_make_series1
| make-series num=count() default=0 on TimeStamp from min_t to max_t step 1h by OsVer
| extend ma_num=series_fir(num, repeat(1, 5), true, true)
| render timechart

Regressionsanalyse
Eine segmentierte lineare Regressionsanalyse kann verwendet werden, um den Trend der Zeitreihe zu schätzen.
- Verwenden Sie series_fit_line(), um die beste Linie an eine Zeitreihe für die allgemeine Trenderkennung anzupassen.
- Verwenden Sie series_fit_2lines(), um Trendänderungen relativ zum Basisplan zu erkennen, die in Überwachungsszenarien nützlich sind.
Beispiel für series_fit_line() und series_fit_2lines() Funktionen in einer Zeitreihenabfrage:
demo_series2
| extend series_fit_2lines(y), series_fit_line(y)
| render linechart with(xcolumn=x)
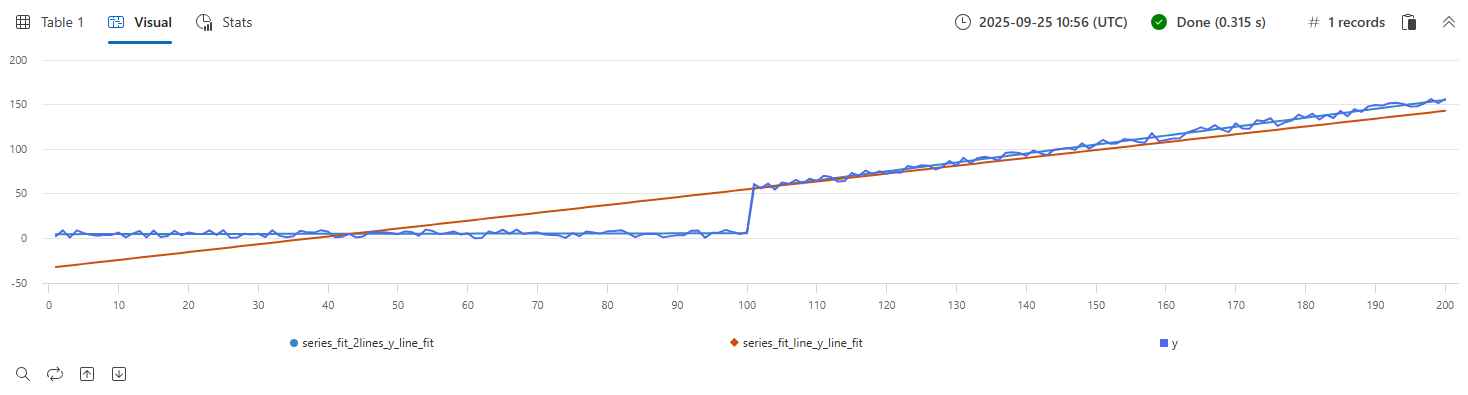
- Blau: Originalzeitreihe
- Grün: angepasste Linie
- Rot: zwei angepasste Linien
Hinweis
Die Funktion hat den Sprungpunkt (Pegelwechsel) genau erkannt.
Saisonalitätserkennung
Viele Metriken folgen saisonalen (periodischen) Mustern. Der Benutzerverkehr von Clouddiensten enthält in der Regel tägliche und wöchentliche Muster, die um die Mitte des Geschäftstags am höchsten und in der Nacht sowie am Wochenende am niedrigsten sind. IoT-Sensoren messen in regelmäßigen Intervallen. Physische Messungen wie Temperatur, Druck oder Feuchtigkeit können auch saisonales Verhalten zeigen.
Im folgenden Beispiel wird die Saisonalitätserkennung auf einen monatigen Datenverkehr eines Webdiensts angewendet (2-Stunden-Bins):
demo_series3
| render timechart

- Verwenden Sie series_periods_detect(), um die Zeiträume in der Zeitreihe automatisch zu erkennen, wobei:
-
num: die zu analysierende Zeitreihe -
0.: die Mindestdauer in Tagen (0 bedeutet kein Minimum) -
14d/2h: die maximale Länge des Zeitraums in Tagen, wobei 14 Tage in 2-Stunden-Intervalle unterteilt werden. -
2: Die Anzahl der zu erkennenden Zeiträume
-
- Verwenden Sie series_periods_validate(), wenn wir wissen, dass eine Metrik bestimmte unterschiedliche Perioden aufweisen soll und wir überprüfen möchten, ob sie vorhanden sind.
Hinweis
Es handelt sich um eine Anomalie, wenn bestimmte unterschiedliche Zeiträume nicht vorhanden sind.
demo_series3
| project (periods, scores) = series_periods_detect(num, 0., 14d/2h, 2) //to detect the periods in the time series
| mv-expand periods, scores
| extend days=2h*todouble(periods)/1d
| Zeiträume | Spielergebnisse | Tage |
|---|---|---|
| 84 | 0.820622786055595 | 7 |
| 12 | 0.764601405803502 | 1 |
Die Funktion erkennt tägliche und wöchentliche Saisonalität. Die täglichen Ergebnisse sind niedriger als die wöchentlichen, da sich Wochenendtage von Wochentagen unterscheiden.
Elementbezogene Funktionen
Arithmetische und logische Vorgänge können in einer Zeitreihe ausgeführt werden. Mit series_subtract() können wir eine Restzeitreihe berechnen, d. a. die Differenz zwischen der ursprünglichen Rohmetrik und einer geglätteten Metrik und suchen nach Anomalien im Restsignal:
let min_t = toscalar(demo_make_series1 | summarize min(TimeStamp));
let max_t = toscalar(demo_make_series1 | summarize max(TimeStamp));
demo_make_series1
| make-series num=count() default=0 on TimeStamp from min_t to max_t step 1h by OsVer
| extend ma_num=series_fir(num, repeat(1, 5), true, true)
| extend residual_num=series_subtract(num, ma_num) //to calculate residual time series
| where OsVer == "Windows 10" // filter on Win 10 to visualize a cleaner chart
| render timechart
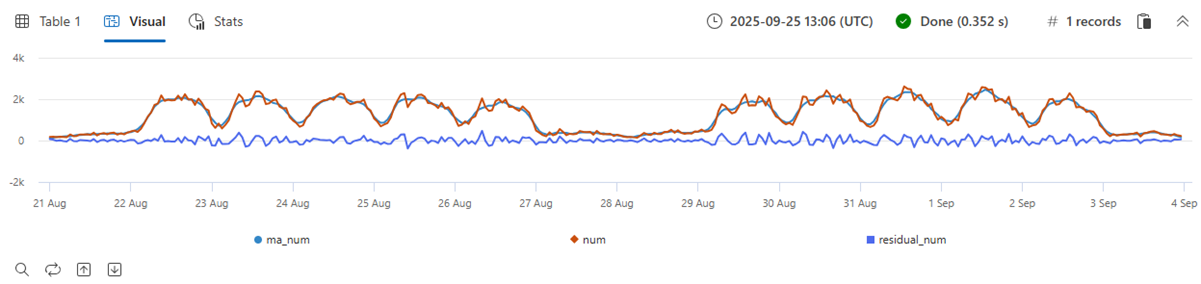
- Blau: Originalzeitreihe
- Rot: Geglättete Zeitreihen
- Grün: Restzeitreihe
Zeitreihenworkflow für eine große Anzahl von Vorgängen
Im folgenden Beispiel wird gezeigt, wie diese Funktionen für die Anomalieerkennung in Sekunden in mehreren Tausend Zeitreihen ausgeführt werden können. Um einige beispielhafte Telemetriedatensätze aus der Metrik für die Anzahl von Lesevorgängen eines Datenbankdiensts im Lauf von vier Tagen anzuzeigen, führen Sie die folgende Abfrage aus:
demo_many_series1
| take 4
| ZEITSTEMPEL | Loc | Op | Deutsche Bahn | DataRead |
|---|---|---|---|---|
| 2016-09-11 21:00:00.0000000 | Loc 9 | 5117853934049630089 | 262 | 0 |
| 2016-09-11 21:00:00.0000000 | Loc 9 | 5117853934049630089 | 241 | 0 |
| 2016-09-11 21:00:00.0000000 | Loc 9 | -865998331941149874 | 262 | 279862 |
| 2016-09-11 21:00:00.0000000 | Loc 9 | 371921734563783410 | 255 | 0 |
Und einfache Statistiken:
demo_many_series1
| summarize num=count(), min_t=min(TIMESTAMP), max_t=max(TIMESTAMP)
| Zahl | min_t | max_t |
|---|---|---|
| 2177472 | 2016-09-08 00:00:00.0000000 | 2016-09-11 23:00:00.0000000 |
Das Erstellen einer Zeitreihe in 1-Stunden-Bins der Lesemetrik (insgesamt vier Tage * 24 Stunden = 96 Punkte) führt zu normalen Musterschwankungen.
let min_t = toscalar(demo_many_series1 | summarize min(TIMESTAMP));
let max_t = toscalar(demo_many_series1 | summarize max(TIMESTAMP));
demo_many_series1
| make-series reads=avg(DataRead) on TIMESTAMP from min_t to max_t step 1h
| render timechart with(ymin=0)
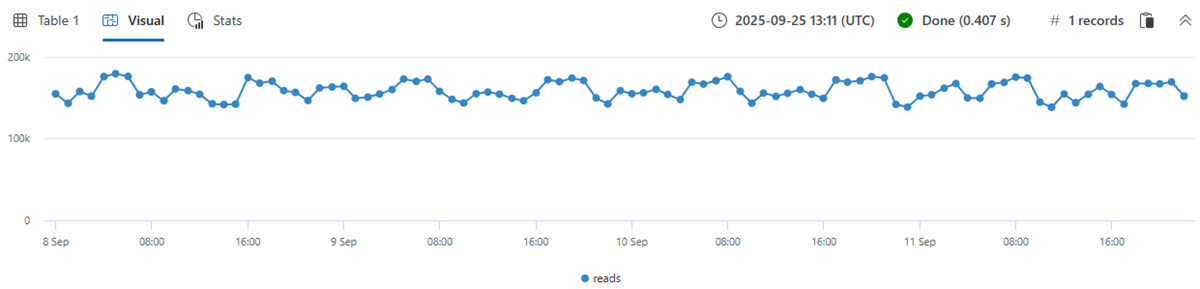
Das oben genannte Verhalten ist irreführend, da die einzelne normale Zeitreihe aus Tausenden verschiedener Instanzen aggregiert wird, die ungewöhnliche Muster aufweisen können. Daher erstellen wir eine Zeitreihe pro Instanz. Eine Instanz wird durch Loc (Location), Op (Operation) und DB (spezifischer Computer) definiert.
Wie viele Zeitreihen können wir erstellen?
demo_many_series1
| summarize by Loc, Op, DB
| count
| Anzahl |
|---|
| 18339 |
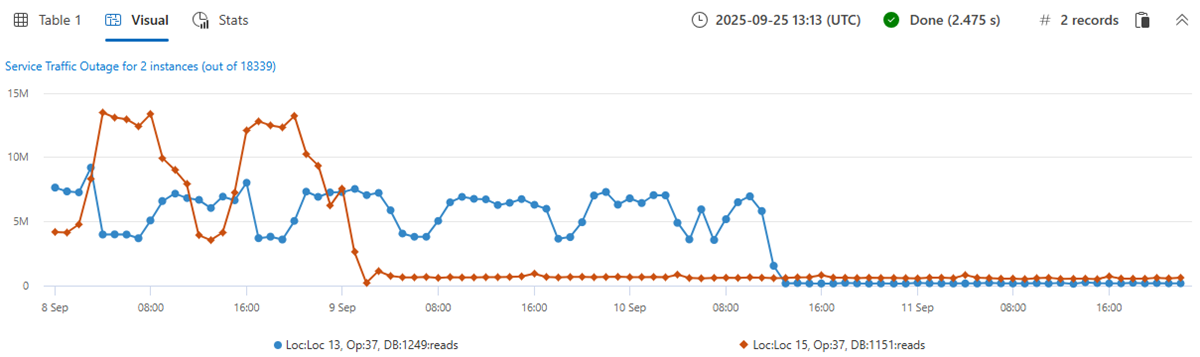
Nun erstellen Sie einen Satz aus 18.339 Zeitreihen der Metrik für die Anzahl von Lesevorgängen. Wir fügen die by Klausel zur make-series-Anweisung hinzu, wenden eine lineare Regression an und wählen die zwei Zeitreihen mit dem signifikantesten abnehmenden Trend aus.
let min_t = toscalar(demo_many_series1 | summarize min(TIMESTAMP));
let max_t = toscalar(demo_many_series1 | summarize max(TIMESTAMP));
demo_many_series1
| make-series reads=avg(DataRead) on TIMESTAMP from min_t to max_t step 1h by Loc, Op, DB
| extend (rsquare, slope) = series_fit_line(reads)
| top 2 by slope asc
| render timechart with(title='Service Traffic Outage for 2 instances (out of 18339)')
Zeigen Sie die Instanzen an:
let min_t = toscalar(demo_many_series1 | summarize min(TIMESTAMP));
let max_t = toscalar(demo_many_series1 | summarize max(TIMESTAMP));
demo_many_series1
| make-series reads=avg(DataRead) on TIMESTAMP from min_t to max_t step 1h by Loc, Op, DB
| extend (rsquare, slope) = series_fit_line(reads)
| top 2 by slope asc
| project Loc, Op, DB, slope
| Loc | Op | Deutsche Bahn | Steigung |
|---|---|---|---|
| Loc 15 | 37 | 1151 | -102743.910227889 |
| Loc 13 | 37 | 1249 | -86303.2334644601 |
In weniger als zwei Minuten wurden fast 20.000 Zeitreihen analysiert, und dabei wurden zwei anormale Zeitreihen entdeckt, bei denen die Leseanzahl plötzlich abfiel.
Diese erweiterten Funktionen in Kombination mit schneller Leistung liefern eine einzigartige und leistungsstarke Lösung für die Zeitreihenanalyse.
Verwandte Inhalte
- Erfahren Sie mehr über Anomalieerkennung und Prognose mit KQL.
- Erfahren Sie mehr über maschinelle Lernfunktionen mit KQL.