Erklärungstypen in Microsoft Syntex
Gilt für: ✓ Unstrukturierte Dokumentverarbeitung
Erklärungen werden verwendet, um die Informationen zu definieren, die Sie in Ihren unstrukturierten Dokumentverarbeitungsmodellen in Microsoft Syntex bezeichnen und extrahieren möchten. Wenn Sie eine Erklärung erstellen, müssen Sie einen Erklärungstyp auswählen. Dieser Artikel hilft Ihnen dabei, die verschiedenen Erklärungstypen zu verstehen, und wie sie verwendet werden.

Diese Erklärungstypen stehen zur Verfügung:
Begriffsliste: Liste von Wörtern, Phrasen, Zahlen oder anderen Zeichen, die Sie im Dokument oder in der Information, die Sie extrahieren, verwenden können. Zum Beispiel ist die Textzeichenfolge Überweisender Arzt in allen Dokumenten „Ärztliche Überweisung“ enthalten, die Sie identifizieren. Oder die Telefonnummer des überweisenden Arztes aus allen von Ihnen identifizierten Dokumenten „Ärztliche Überweisung“.
Regulärer Ausdruck: Verwendet eine Notation für den Mustervergleich, um bestimmte Zeichenmuster zu finden. Beispielsweise können Sie einen regulären Ausdruck verwenden, um alle Instanzen eines E-Mail-Adressen-Musters in einer Gruppe von Dokumenten zu suchen.
Näherung: Beschreibt, wie nahe die Erklärungen beieinander liegen. Beispielsweise wird eine Begriffsliste für Straßennummern direkt vor der Begriffsliste der Straßennamen ohne Token dazwischen angezeigt (Sie erfahren mehr über Token weiter unten in diesem Artikel). Die Verwendung des Näherungstyps erfordert, dass Sie mindestens zwei Erklärungen in Ihrem Modell haben, ansonsten die Option deaktiviert wird.
Begriffsliste
Der Erklärungstyp "Begriffsliste" wird normalerweise verwendet, um ein Dokument durch Ihr Modell zu identifizieren und zu klassifizieren. Wie im Beispiel der Bezeichnung Überweisender Arzt beschrieben, handelt es sich dabei um eine Kette von Wörtern, Phrasen, Zahlen oder Zeichen, die in den Dokumenten, die Sie identifizieren, konsistent ist.
Auch wenn dies keine Voraussetzung ist, können Sie mit Ihrer Erklärung einen besseren Erfolg erzielen, wenn die Phrase, die Sie erfassen, sich an einer konsistenten Stelle in Ihrem Dokument befindet. Beispielsweise könnte sich die Bezeichnung Überweisender Arzt durchgängig im ersten Absatz des Dokuments befinden. Sie können auch die Option Konfigurieren, wo Begriffe im Dokument vorkommen in den erweiterten Einstellung verwenden, um bestimmte Bereiche auszuwählen, in denen sich der Begriff befindet, insbesondere wenn die Möglichkeit besteht, dass der Begriff an mehreren Stellen in Ihrem Dokument vorkommt.
Wenn die Groß-/Kleinschreibung bei der Identifizierung Ihrer Bezeichnung beachtet werden muss, können Sie dies in Ihrer Erklärung mit dem Typ "Begriffsliste" angeben, indem Sie das Kontrollkästchen Nur exakte Groß-/Kleinschreibung aktivieren.

Ein Begriffstyp ist besonders nützlich, wenn Sie eine Erklärung erstellen, die Informationen in verschiedenen Formaten wie Datum, Telefonnummer und Kreditkartennummer identifiziert und extrahiert. Ein Datum kann beispielsweise in vielen verschiedenen Formaten angezeigt werden (1/1/2020, 1-1-2020, 01/01/20, 01.01.2020 oder 1. Jan. 2020). Durch das Definieren einer Begriffsliste wird Ihre Erklärung effizienter, indem mögliche Abweichungen in den Daten, die Sie identifizieren und extrahieren möchten, erfasst werden.
Für das Beispiel Telefonnummer extrahieren Sie die Telefonnummer für jeden überweisenden Arzt aus allen Dokumenten „Ärztliche Überweisung“, die das Modell identifiziert. Geben Sie beim Erstellen der Erklärung die verschiedenen Formate ein, in denen eine Telefonnummer möglicherweise in Ihrem Dokument angezeigt wird, damit Sie mögliche Abweichungen erfassen können.

In diesem Beispiel aktivieren Sie unter Erweiterte Einstellungen das Kontrollkästchen Beliebige Ziffer von 0-9, um zu erkennen, dass jeder in Ihrer Begriffsliste verwendete "0" -Wert eine beliebige Ziffer von 0 bis 9 ist.

Wenn Sie eine Begriffsliste erstellen, die Textzeichen enthält, aktivieren Sie das Kontrollkästchen Beliebiger Buchstabe von a-z, um zu erkennen, dass jedes in der Begriffsliste verwendete "a" -Zeichen ein beliebiges Zeichen von "a" bis "z" ist.
Wenn Sie beispielsweise eine Datum-Begriffsliste erstellen und sicherstellen möchten, dass ein Datumsformat wie der 1. Januar 2020 erkannt wird, müssen Sie:
- Fügen Sie Ihrer Begriffsliste aaa 0, 0000 und aaa 00, 0000 hinzu.
- Stellen Sie sicher, dass auch Beliebiger Buchstabe von a-z ausgewählt ist.

Wenn Ihre Begriffsliste Anforderungen an die Groß-/Kleinschreibung hat, können Sie das Kontrollkästchen Nur genaue Groß-/Kleinschreibung aktivieren. Wenn für das Beispiel „Datum“ der erste Buchstabe des Monats groß geschrieben werden muss, müssen Sie Folgendes tun:
- Fügen Sie Ihrer Begriffsliste Aaa 0, 0000 und Aaa 00, 0000 hinzu.
- Stellen Sie sicher, dass auch Nur genaue Groß-/Kleinschreibung ausgewählt ist.

Hinweis
Anstatt manuell eine Erklärung für die Begriffsliste zu erstellen, verwenden Sie die Erklärungsbibliothek, um Begriffslistenvorlagen für eine allgemeine Begriffsliste wie Datum, Telefonnummer oder Kreditkartennummer zu verwenden.
Regulärer Ausdruck
Ein Erklärungstyp für einen regulären Ausdruck erlaubt Ihnen das Erstellen von Mustern, die Ihnen beim Suchen und Identifizieren bestimmter Textzeichenfolgen in Dokumenten helfen. Sie können reguläre Ausdrücke verwenden, um große Textmengen schnell zu analysieren zum:
- Suchen bestimmter Zeichenmuster.
- Validieren von Text, um sicherzustellen, dass er mit einem vordefinierten Muster übereinstimmt (beispielsweise eine E-Mail-Adresse).
- Extrahieren, bearbeiten, ersetzen oder löschen von Teilen der Textzeichenfolgen.
Ein regulärer Ausdruckstyp ist besonders nützlich, wenn Sie eine Erklärung erstellen, die Informationen mit ähnlichen Formaten wie E-Mail-Adressen, Bankkontonummern oder URLs identifiziert und extrahiert. Beispielsweise wird eine E-Mail-Adresse wie megan@contoso.comin einem bestimmten Muster angezeigt ("megan" ist der erste Teil und "com" der letzte Teil).
Der reguläre Ausdruck für eine E-Mail-Adresse ist: [A-Za-z0-9._%-]+@[A-Za-z0-9.-]+.[A-Za-z]{2,6}.
Der Ausdruck besteht aus fünf Teilen in dieser Reihenfolge:
Eine beliebige Anzahl der folgenden Sonderzeichen:
a. Buchstaben von a bis z
b. Zahlen von 0–9
c. Punkt, Unterstrich, Prozent oder Gedankenstrich
Das Symbol „@“
Eine beliebige Anzahl der gleichen Zeichen wie im ersten Teil der E-Mail-Adresse
Ein Punkt
Zwei bis sechs Buchstaben
So fügen Sie einen Erklärungstyp für einen regulären Ausdruck hinzu:
Wählen Sie aus dem Bereich Erstellen einer Erklärung unter Erklärungstyp die Option Regulärer Ausdruck aus.

Sie können entweder einen Ausdruck im Textfeld Regulärer Ausdruck eingeben, oder Hinzufügen eines regulären Ausdrucks aus einer Vorlage auswählen.
Wenn Sie einen regulären Ausdruck mittels einer Vorlage hinzufügen, wird der Name und der reguläre Ausdruck automatisch dem Textfeld hinzugefügt. Wenn Sie z. B. die Vorlage Email Adresse auswählen, wird der Bereich Erklärung erstellen aufgefüllt.

Begrenzungen
Die folgende Tabelle enthält Inlinezeichenoptionen, die derzeit nicht für die Verwendung in Mustern regulärer Ausdrücke verfügbar sind.
| Option | Status | Aktuelle Funktionalität |
|---|---|---|
| Unterscheidung nach Groß-/Kleinschreibung | Derzeit nicht unterstützt. | Bei allen durchgeführten Aktionen wird nicht nach Groß-/Kleinschreibung unterschieden. |
| Zeilenanker | Derzeit nicht unterstützt. | Es konnte keine spezifische Position in einer Zeichenfolge bestimmt werden, an der eine Übereinstimmung erfolgen muss. |
Näherung
Der Erklärungstyp "Näherung" hilft Ihrem Modell bei der Identifizierung von Daten, indem er definiert, wie nahe ein anderes Datenelement an ihm liegt. Beispielsweise haben Sie in Ihrem Modell zwei Erklärungen definiert, die sowohl die Straßennummer als auch die Telefonnummer des Kunden bezeichnen.
Beachten Sie, dass die Telefonnummern des Kunden immer vor der Straßennummer steht.
Alex Wilburn
555-555-5555
Langgasse 18
54123 Münchfeld
Verwenden Sie die Näherungserklärung, um festzulegen, wie weit die Erklärung "Telefonnummer" entfernt ist, um die Straßennummer in Ihren Dokumenten besser identifizieren zu können.

Hinweis
Reguläre Ausdrücke können derzeit nicht mit dem Näherungserklärungstyp verwendet werden.
Was sind Token?
Um den Erklärungstyp „Näherung“ verwenden zu können, müssen Sie verstehen, was ein Token ist. Die Anzahl der Token gibt an, wie die Näherungserklärung den Abstand von einer Erklärung zur anderen misst. Ein Token ist eine kontinuierliche Reihe (ohne Leerzeichen oder Interpunktionen) von Buchstaben und Zahlen.
Die folgende Tabelle zeigt Beispiele, wie die Anzahl der Token in einer Phrase ermittelt wird.
| Phrase | Anzahl von Token | Erklärung |
|---|---|---|
Dog |
1 | Ein einzelnes Wort ohne Interpunktionszeichen oder Leerzeichen. |
RMT33W |
1 | Eine Datensatz-Locator-Nummer. Sie könnte Zahlen und Buchstaben beinhalten, hat aber keine Interpunktion. |
425-555-5555 |
5 | Eine Telefonnummer. Jedes Interpunktionszeichen ist ein einzelnes Token, also ist 425-555-5555 5 Tokens:425-555-5555 |
https://luis.ai |
7 | https://luis.ai |
Konfigurieren des Erklärungstyps "Näherung"
Konfigurieren Sie für das Beispiel die Näherungseinstellung, um den Bereich der Anzahl der Token in der Telefonnummer-Erklärung aus der Straßennummer-Erklärung zu definieren. Beachten sie, dass der Mindestbereich „0“ ist, da es keine Token zwischen der Telefonnummer und der Straßenadressnummer gibt.
Einige Telefonnummern in den Beispieldokumenten sind jedoch mit (Mobil) ergänzt.
Nestor Wilke
111-111-1111 (Mobil)
Langgasse 18
54123 Münchfeld
Es gibt drei Token in (Mobil):
| Phrase | Tokenzahl |
|---|---|
| ( | 1 |
| Mobil | 2 |
| ) | 3 |
Konfigurieren Sie die Einstellung für die Näherung so, dass sie einen Wert von 0 bis 3 aufweist.

Konfigurieren Sie, wo Ausdrücke im Dokument vorkommen.
Wenn Sie eine Erklärung erstellen, wird standardmäßig das gesamte Dokument nach dem Ausdruck durchsucht, den Sie extrahieren möchten. Sie können jedoch die erweiterte Einstellung Wo diese Ausdrücke vorkommen verwenden, um eine bestimmte Stelle im Dokument zu isolieren, an der ein Ausdruck vorkommt. Diese Einstellung ist in Situationen hilfreich, in denen ähnliche Instanzen eines Ausdrucks möglicherweise an einer anderen Stelle im Dokument auftreten und Sie sicherstellen möchten, dass der richtige Ausdruck ausgewählt ist.
In unserem Beispiel für das Dokument „Ärztliche Überweisung“ wird der überweisende Arzt immer im ersten Absatz des Dokuments erwähnt. Mit der Einstellung Wo diese Ausdrücke vorkommen können Sie in diesem Beispiel Ihre Erklärung so konfigurieren, dass nach dieser Bezeichnung nur im Anfangsabschnitt des Dokuments oder an einer anderen Stelle gesucht wird, an der sie möglicherweise vorkommt.

Sie können für diese Einstellung die folgenden Optionen auswählen:
An beliebiger Stelle in der Datei: Es wird das gesamte Dokument nach dem Ausdruck durchsucht.
Anfang der Datei: Das Dokument wird vom Anfang bis zum Speicherort des Ausdrucks durchsucht.

Im Viewer können Sie das Auswahlfeld manuell anpassen, um die Position einzugeben, an der die Phase erscheint. Der Endpositionswert wird aktualisiert, um die Anzahl der Token anzuzeigen, die Ihr ausgewählter Bereich enthält. Sie können den Wert der Endposition auch aktualisieren, um den ausgewählten Bereich anzupassen.
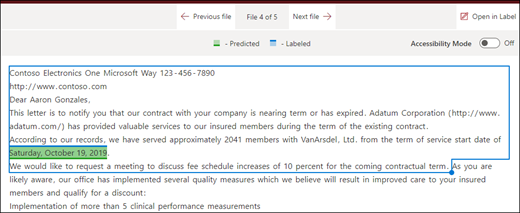
Ende der Datei: Das Dokument wird vom Ende bis zur Position des Ausdrucks durchsucht.

Im Viewer können Sie das Auswahlfeld manuell anpassen, um die Position einzugeben, an der die Phase erscheint. Der Wert der Startposition wird aktualisiert, um die Anzahl der Token anzuzeigen, die Ihr ausgewählter Bereich enthält. Sie können den Wert der Startposition auch aktualisieren, um den ausgewählten Bereich anzupassen.

Benutzerdefiniert: Das Dokument wird innerhalb eines bestimmten Bereichs nach der Position des Ausdrucks durchsucht.

Im Viewer können Sie das Auswahlfeld manuell anpassen, um die Position einzugeben, an der die Phase erscheint. Für diese Einstellung müssen Sie je eine Position Start und Ende auswählen. Diese Werte stellen die Anzahl der Token ab dem Anfang des Dokuments dar. Sie können diese Werte zwar manuell eingeben, doch ist es einfacher, das Auswahlfeld im Viewer manuell anzupassen.
Überlegungen beim Konfigurieren von Erklärungen
Beim Trainieren eines Klassifizierers müssen Sie einige Dinge beachten, die zu besser vorhersagbaren Ergebnissen führen:
Je mehr Dokumente Sie trainieren, desto genauer ist der Klassifizierer. Verwenden Sie nach Möglichkeit mehr als fünf gute Dokumente und mehrere ungültige Dokumente. Wenn die Bibliotheken, mit denen Sie arbeiten, mehrere unterschiedliche Dokumenttypen enthalten, führen mehrere von jedem Typ zu besser vorhersagbaren Ergebnissen.
Die Beschriftung des Dokuments spielt im Trainingsprozess eine wichtige Rolle. Sie werden zusammen mit Erklärungen verwendet, um das Modell zu trainieren. Beim Trainieren eines Klassifizierers mit Dokumenten, die nicht viel Inhalt enthalten, werden möglicherweise einige Anomalien angezeigt. Die Erklärung entspricht möglicherweise nichts im Dokument, aber da es als "gutes" Dokument bezeichnet wurde, können Sie feststellen, dass es sich während des Trainings um eine Übereinstimmung handelt.
Beim Erstellen von Erklärungen wird or-Logik in Kombination mit der Bezeichnung verwendet, um zu bestimmen, ob es sich um eine Übereinstimmung handelt. Reguläre Ausdrücke, die AND-Logik verwenden, sind möglicherweise besser vorhersagbar. Hier ist ein Beispiel für einen regulären Ausdruck, der für echte Dokumente als Training verwendet werden kann. Beachten Sie, dass der rot hervorgehobene Text der oder die Ausdrücke ist, nach dem Sie suchen würden.
(?=.*network provider)(?=.*participating providers).*
Bezeichnungen und Erklärungen arbeiten zusammen und werden beim Trainieren des Modells verwendet. Es handelt sich nicht um eine Reihe von Regeln, die entkoppelt werden können, und genaue Gewichtungen oder Vorhersagen, die auf jede variable, die konfiguriert wurde, angewendet werden können. Je größer die Variation von Dokumenten, die im Training verwendet werden, bietet mehr Genauigkeit im Modell.